
请君浏览
-
- 前言
- 一、传输层回顾------再谈端口号
-
- [1.1 五元组:一个通信的唯一标识](#1.1 五元组:一个通信的唯一标识)
- [1.2 端口号范围划分](#1.2 端口号范围划分)
- [1.3 两个经典问题](#1.3 两个经典问题)
- [二、UDP 协议端格式------8 字节的极简主义](#二、UDP 协议端格式——8 字节的极简主义)
-
- [2.1 协议头结构](#2.1 协议头结构)
- [2.2 校验和的计算机制](#2.2 校验和的计算机制)
- [2.3 UDP 与 TCP 协议头对比](#2.3 UDP 与 TCP 协议头对比)
- [三、UDP 的特点------无连接、不可靠、面向数据报](#三、UDP 的特点——无连接、不可靠、面向数据报)
-
- [3.1 无连接](#3.1 无连接)
- [3.2 不可靠------体现在四个层面](#3.2 不可靠——体现在四个层面)
- [3.3 面向数据报------与 TCP 字节流的本质差异](#3.3 面向数据报——与 TCP 字节流的本质差异)
- [四、UDP 的缓冲区------与 TCP 的本质差异](#四、UDP 的缓冲区——与 TCP 的本质差异)
-
- [4.1 UDP 没有发送缓冲区------sendto 直接交内核](#4.1 UDP 没有发送缓冲区——sendto 直接交内核)
- [4.2 UDP 有接收缓冲区------但不保证不乱序](#4.2 UDP 有接收缓冲区——但不保证不乱序)
- [4.3 UDP 的全双工](#4.3 UDP 的全双工)
- [五、64K 限制------UDP 的阿喀琉斯之踵](#五、64K 限制——UDP 的阿喀琉斯之踵)
-
- [5.1 问题的根源](#5.1 问题的根源)
- [5.2 还有一个隐含的限制:MTU](#5.2 还有一个隐含的限制:MTU)
- [5.3 超 64K 怎么办------应用层分包](#5.3 超 64K 怎么办——应用层分包)
- [六、基于 UDP 的经典应用层协议](#六、基于 UDP 的经典应用层协议)
- 七、常见问题与避坑指南
-
- [7.1 为什么 UDP 数据报发不出去](#7.1 为什么 UDP 数据报发不出去)
- [7.2 recvfrom 收到的数据比发送的少](#7.2 recvfrom 收到的数据比发送的少)
- [7.3 UDP 的"连接"------connected UDP](#7.3 UDP 的"连接"——connected UDP)
- [八、UDP Socket 选项详解------从默认行为到性能调优](#八、UDP Socket 选项详解——从默认行为到性能调优)
-
- [8.1 SO_RCVBUF / SO_SNDBUF------调整缓冲区大小](#8.1 SO_RCVBUF / SO_SNDBUF——调整缓冲区大小)
- [8.2 SO_BROADCAST------允许发送广播](#8.2 SO_BROADCAST——允许发送广播)
- [8.3 IP_ADD_MEMBERSHIP------加入组播组](#8.3 IP_ADD_MEMBERSHIP——加入组播组)
- [8.4 SO_RCVTIMEO------设置接收超时](#8.4 SO_RCVTIMEO——设置接收超时)
- [8.5 实战:用 getsockopt 诊断 UDP 丢包](#8.5 实战:用 getsockopt 诊断 UDP 丢包)
- [九、UDP 与 TCP 的选择------一张决策表](#九、UDP 与 TCP 的选择——一张决策表)
- 总结
- 尾声
前言
在 UDP Socket 编程实战中,我们掌握了
socket/bind/recvfrom/sendto的用法,实现了 Echo 服务器、字典服务器和聊天室。那时我们对 UDP 的理解停留在"无连接、不可靠、直发直收"的操作层面。本篇下沉到传输层协议本身,回答根本性问题:UDP 的协议头为什么只有 8 字节?"面向数据报"究竟意味着什么?为什么 UDP 没有发送缓冲区?DNS 和 DHCP 为什么选 UDP 而不是 TCP?读完本文,你将真正理解 UDP 协议的设计哲学------不只是"会写 UDP 程序",而是懂得 UDP 为什么被设计成这样,以及在什么场景下应该选择它。
一、传输层回顾------再谈端口号
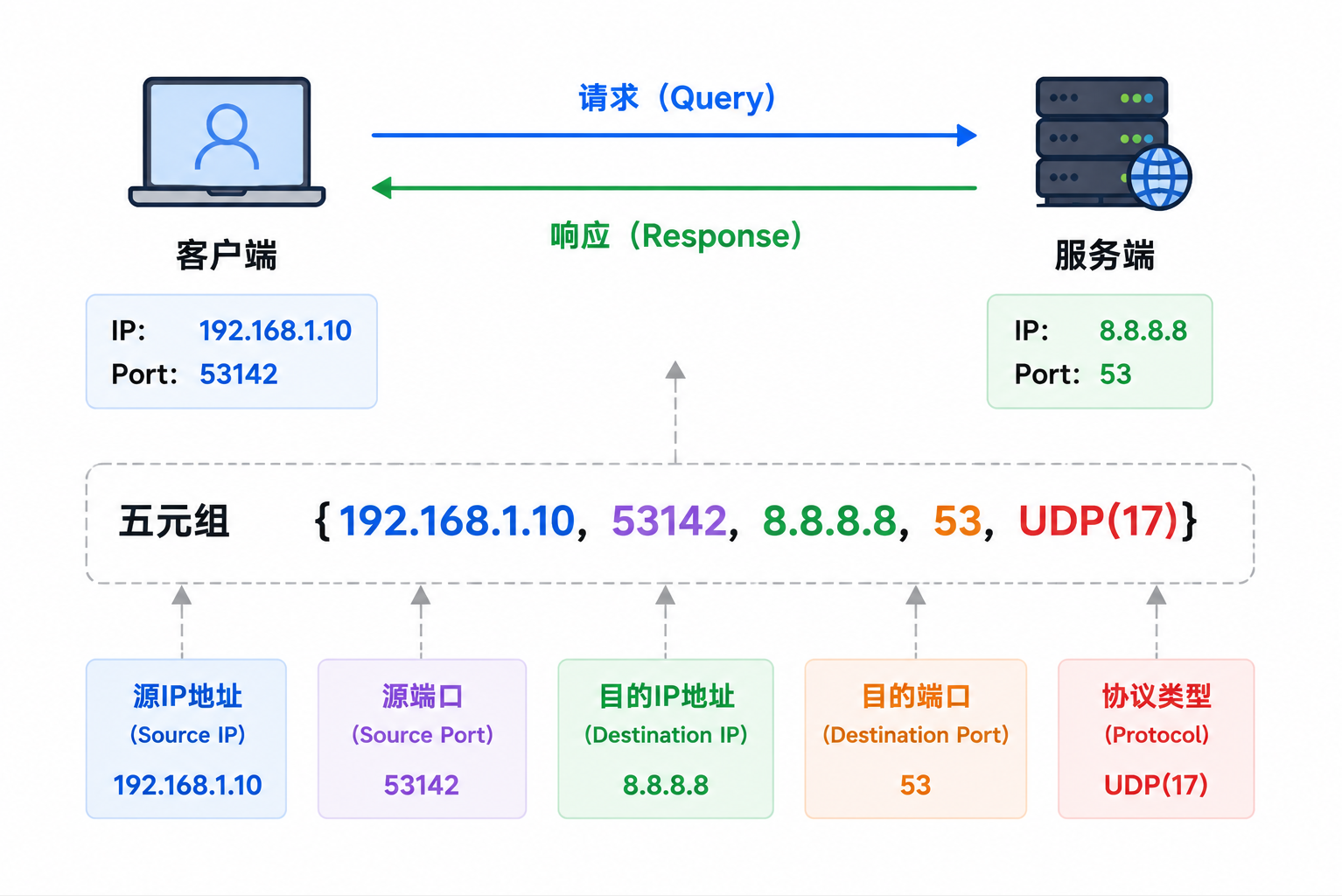
1.1 五元组:一个通信的唯一标识
在 TCP/IP 协议中,一个网络通信由五元组唯一标识:
{源IP, 源端口号, 目的IP, 目的端口号, 协议号}| 元素 | 含义 | 示例 |
|---|---|---|
| 源 IP | 发送方主机地址 | 192.168.1.10 |
| 源端口号 | 发送方进程标识 | 53142(OS 随机分配) |
| 目的 IP | 接收方主机地址 | 8.8.8.8 |
| 目的端口号 | 接收方进程标识 | 53(DNS 服务) |
| 协议号 | 传输层协议类型 | 17(UDP)/ 6(TCP) |
即使源 IP、目的 IP 和目的端口号全部相同,只要源端口号不同,就是两条独立的通信。这也是为什么一台机器能同时打开几十个浏览器 Tab 访问同一个网站------每个浏览器进程分配了不同的源端口号。
可以执行 netstat -n 查看当前系统中所有活跃连接的五元组:
bash
$ netstat -n | head -5
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.168.1.10:53142 142.250.80.14:443 ESTABLISHED
udp 0 0 192.168.1.10:46832 8.8.8.8:53 ESTABLISHED注意第二条:UDP 不像 TCP 有 ESTABLISHED 状态------它是无连接的。但
netstat仍然可以显示它正在通信,因为内核记录了最近一次收发数据的五元组。一旦长时间无数据,UDP 条目就会从netstat中消失。
1.2 端口号范围划分
| 范围 | 分类 | 说明 | 绑定要求 |
|---|---|---|---|
| 0 ~ 1023 | 知名端口号(Well-Known Ports) | HTTP(80)、SSH(22)、FTP(21)、HTTPS(443)、DNS(53) | 需 root 权限 |
| 1024 ~ 49151 | 注册端口(Registered Ports) | MySQL(3306)、Redis(6379)、Tomcat(8080) | 普通用户即可 |
| 49152 ~ 65535 | 动态/私有端口(Dynamic Ports) | 客户端程序自动分配 | OS 自动 |
bash
# 查看系统中注册的知名端口号
$ cat /etc/services | head -20
tcpmux 1/tcp # TCP port service multiplexer
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
ftp 21/tcp
ssh 22/tcp
telnet 23/tcp
smtp 25/tcp mail
domain 53/tcp # DNS over TCP
domain 53/udp # DNS over UDP
# ...自己写程序选择端口号时,要避开知名端口。一般选 8080、8888、9090 这类非标准端口进行开发测试。如果程序将来要部署到生产环境,还需确认没有与系统已有的服务冲突。
1.3 两个经典问题
问题一:一个进程是否可以 bind 多个端口号?
能。 一个进程可以创建多个 socket,每个 socket bind 不同的端口号。典型的例子是 HTTP 和 HTTPS 同服务------Nginx 主进程同时 bind 80 和 443 端口。代码层面也很简单:
cpp
// 进程 A 中
int sock1 = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock1, ..., 8080); // bind 8080
int sock2 = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock2, ..., 9090); // 同一个进程,bind 9090,完全没问题问题二:一个端口号是否可以被多个进程 bind?
通常不能。 端口号在同一时刻只能被一个进程占用------bind 会返回 EADDRINUSE:
cpp
int sock = socket(AF_INET, SOCK_DGRAM, 0);
int ret = bind(sock, ..., 8080);
// 如果 8080 已被占用,ret = -1, errno = EADDRINUSE但有一个例外:通过 SO_REUSEPORT 选项,多个进程/线程可以 bind 同一端口,内核在它们之间进行负载均衡。Nginx 的多 worker 进程模式正是利用了这一机制:
cpp
int opt = 1;
setsockopt(sock, SOL_SOCKET, SO_REUSEPORT, &opt, sizeof(opt));
// 之后多个进程 bind 同一端口不会冲突,内核按哈希分发数据报到不同进程
SO_REUSEADDR和SO_REUSEPORT看起来相似,但作用不同:SO_REUSEADDR允许在 TIME_WAIT 期间重新 bind 端口(重启服务器时常用),SO_REUSEPORT允许多个 socket 同时 bind 同一端口并负载均衡。
二、UDP 协议端格式------8 字节的极简主义
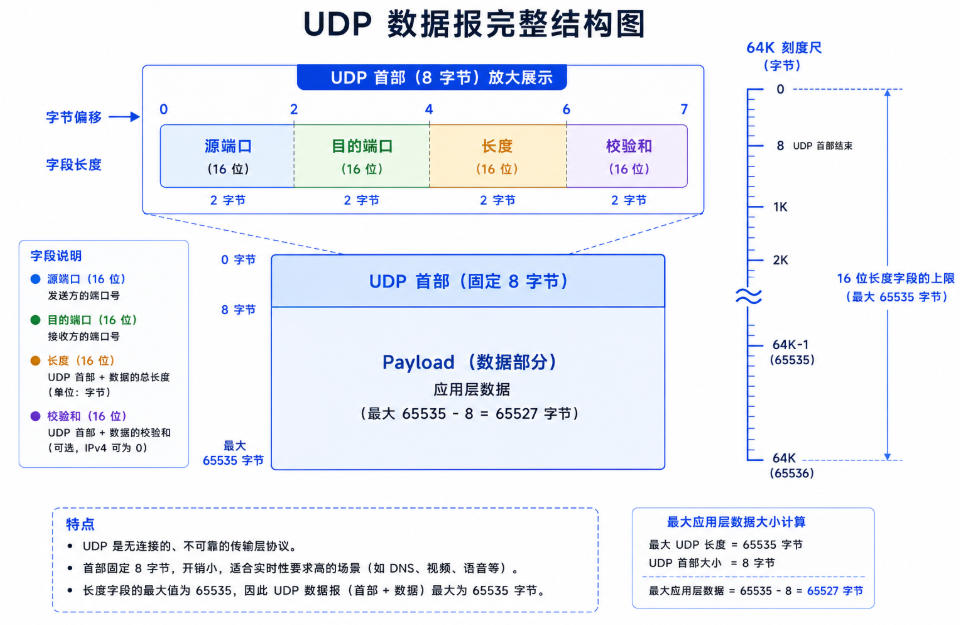
2.1 协议头结构
UDP 协议头只有 8 个字节,分为四个 16 位字段。这是整个传输层协议中最简洁的设计:
0 7 8 15 16 23 24 31
┌─────────┬─────────┬─────────┬─────────┐
│ 源端口号 │ 目的端口号 │
│ (Source Port) │(Dest Port) │
├───────────────┼───────────────┤
│ UDP 长度 │ UDP 校验和 │
│ (Length) │ (Checksum) │
├───────────────┴───────────────┤
│ │
│ 数据载荷 (Payload) │
│ (应用层数据) │
│ │
└───────────────────────────────┘| 字段 | 位宽 | 含义 | 备注 |
|---|---|---|---|
| 源端口号 | 16 位 | 发送进程的端口号 | 客户端通常由 OS 随机分配;不需要回复时可为 0 |
| 目的端口号 | 16 位 | 接收进程的端口号 | 服务端固定;接收方据此将数据交给正确的 socket |
| UDP 长度 | 16 位 | UDP 首部(8) + 数据载荷的总字节数 | 最小值 8(无载荷),最大值 65535(64K) |
| UDP 校验和 | 16 位 | 检测数据传输是否有错 | 可选(IPv4 中可为 0,IPv6 中强制计算);出错则直接静默丢弃 |
与 TCP 的 20~60 字节头相比,UDP 的 8 字节头展现了一种极简主义的设计理念:只提供端口复用和差错检测,别的什么都不做。 没有序列号(不保证顺序),没有确认号(不保证到达),没有窗口大小(不控制流量),没有标志位(SYN/ACK/FIN)------UDP 的设计就是"给你一张邮票,自己贴去"。
UDP 的极简设计提出的一个值得深思的问题:在协议设计中,"少做"比"多做"更难。 设计一个面面俱到的协议需要工程能力------把各种可靠性机制实现正确。但设计一个什么都不做的协议需要克制------清楚地知道哪些事情不该协议层管、应该留给应用层。UDP 的设计者在 1980 年做出了一个在当时看来"偷懒"的决定:只提供多路复用(端口)和可选的校验,其余全部交给上层。四十年后回头看,这个"偷懒"的决定反而成了 UDP 长寿的原因------正是因为 UDP 什么都没做,它才可以被用来做任何事情:DNS 的短查询用它、视频流用它、VPN 隧道用它、QUIC(HTTP/3)在它之上重建了整套可靠传输------每一层都只是利用了 UDP 的"端口复用 + 直接交付"能力,其余全是应用层自由发挥。协议越简洁,生态越丰富。 这个原则解释了为什么 JSON 取代了 XML(尽管 XML 功能更多),为什么 RESTful API 取代了 SOAP(尽管 SOAP 规范更完善),也解释了为什么 UDP 至今不可替代。
2.2 校验和的计算机制
UDP 的校验和看似简单,但它实际上是对伪首部 + UDP 首部 + 数据三部分的合计算。伪首部包含了一些 IP 层的信息,确保数据不仅没有损坏,而且到达了正确的目的地:
伪首部结构(12字节,仅用于校验和计算,不实际传输):
┌─────────────────────────────────────┐
│ 源 IP 地址(4字节) │
├─────────────────────────────────────┤
│ 目的 IP 地址(4字节) │
├────────────┬────────────────────────┤
│ 保留(0x00) │ 协议号(17=UDP)(1字节) │
├────────────┼────────────────────────┤
│ UDP 总长度(2字节) │
└────────────┴────────────────────────┘校验和的计算流程:
- 构造伪首部
- 拼接:伪首部 + UDP 首部 + 数据载荷
- 如果总字节数为奇数,末尾补一个 0 字节
- 以 16 位为一组做二进制反码求和(one's complement sum)
- 对结果取反码,填入校验和字段
- 接收方用同样的方法计算校验和,若结果为 0xFFFF 则校验通过
为什么校验失败的 UDP 报文被静默丢弃------既不通知发送方,也不通知接收方的应用层?因为 UDP 没有错误反馈通道。这正是"不可靠"的体现:丢了就是丢了,上层自己想办法(超时重发或直接接受数据丢失)。
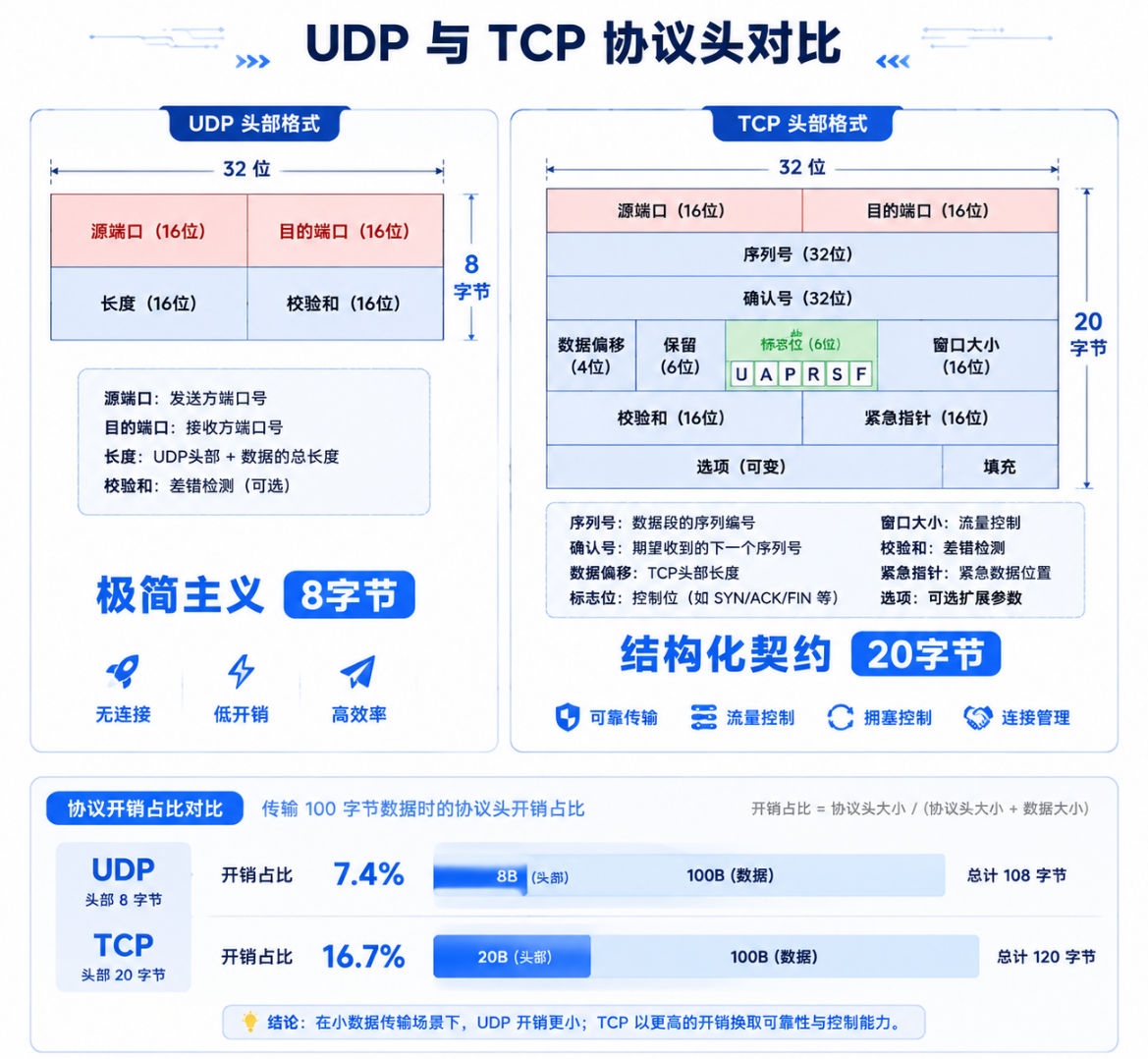
2.3 UDP 与 TCP 协议头对比
把 UDP 和 TCP 的头放在一起比较,两种设计哲学的差异一目了然:
| 对比维度 | UDP | TCP |
|---|---|---|
| 头部大小 | 8 字节(固定) | 20~60 字节(最小 20,选项可达 40) |
| 是否有序列号 | ❌ 无 | ✅ 有(32 位 seq + 32 位 ack) |
| 是否有窗口字段 | ❌ 无 | ✅ 有(16 位,控制流量) |
| 是否有标志位 | ❌ 无 | ✅ 有(SYN/ACK/FIN/RST/PSH/URG 共 6 个) |
| 是否有紧急指针 | ❌ 无 | ✅ 有 |
| 校验和 | 可选(IPv4) | 强制 |
| 功能定位 | 端口复用 + 轻量校验 | 可靠字节流 + 拥塞控制 + 流量控制 |
8 字节 vs 20 字节------如果传输的数据载荷是 100 字节,UDP 的开销是 8/108 ≈ 7.4% ,而 TCP 的开销是 20/120 ≈ 16.7%。对于小数据包(DNS 查询通常只有几十字节),UDP 的效率优势非常明显。
三、UDP 的特点------无连接、不可靠、面向数据报
如果把 TCP 比喻为"打电话"------先拨号接通,逐句确认对方听清了,最后挂断------那么 UDP 就是"寄信":写好收件人地址,投进邮筒,然后默认信能寄到。
3.1 无连接
- 知道对端的 IP 和端口号就直接发送,不需要建立连接。
- 没有握手过程,没有连接状态需要维护。
- 因此 UDP 支持一对一、一对多、多对一、多对多的通信模式------TCP 只能一对一。
一对多(组播)的例子:
cpp
// UDP 组播------一条消息同时发给组内所有成员
struct ip_mreq mreq;
mreq.imr_multiaddr.s_addr = inet_addr("224.0.0.1"); // 组播地址
mreq.imr_interface.s_addr = htonl(INADDR_ANY); // 本机任意网卡
setsockopt(sock, IPPROTO_IP, IP_ADD_MEMBERSHIP, &mreq, sizeof(mreq));
// 之后 sendto 到 224.0.0.1,组内所有成员都能收到组播、广播这些通信模式 TCP 完全无法实现------因为 TCP 必须先建立一对一连接。这也是为什么 DHCP(客户端连 IP 都没有,需要广播请求)必须用 UDP。
3.2 不可靠------体现在四个层面
"不可靠"不是一个抽象的概念,而是可以具体到四个技术细节:
第一层面:无确认应答
TCP 每收到一个数据段,都要回复一个 ACK 告知"已收到,下一个期望的序列号是 X"。UDP 完全不发 ACK------发送方发出后不知道对方有没有收到。如果你用 UDP 连续发送了 1000 个数据报,中间丢了第 47 个,发送方毫不知情,接收方也毫无办法。
第二层面:无超时重传
TCP 发送一个段后启动重传定时器,超时未收到 ACK 则自动重发。UDP 没有定时器,没有重传队列。丢了的报文就永远丢了。
第三层面:校验和失败静默丢弃
UDP 校验和出错时------网络传输中的比特翻转导致的数据损坏------直接丢弃报文,不通知任何人。TCP 也会在检测到损坏时丢弃,但 TCP 会通过序列号发现"少了一段",然后触发重传。UDP 没有序列号,上层根本不知道丢了一段。
第四层面:无拥塞控制
TCP 有慢启动、拥塞避免、快重传、快恢复机制,自动调整发送速率以适应网络状况。UDP 没有这些------应用程序可以以任意速率发送数据,完全不管网络能否承受。这在局域网中通常没问题,但在公网上,过快的 UDP 发送可能导致大量丢包(中间路由器直接丢弃),甚至引发网络拥塞加剧。
"不可靠"听起来是个缺点,但对某些场景来说恰恰是优点:DNS 查询如果丢了,客户端超时重发即可,不需要协议层的重传机制来拖慢速度;实时音视频通话宁愿丢几帧也不愿因为重传导致延迟------丢一帧画面你感觉不到,但卡半秒你就注意到了。
3.3 面向数据报------与 TCP 字节流的本质差异
这是 UDP 区别于 TCP 最核心、也是最容易被忽视的特性:
应用层交 100 字节 → UDP 封装(加8字节头) → 对端 UDP 解封装 → 应用层收 100 字节
发送端:一次 sendto(100 bytes)
接收端:必须一次 recvfrom 拿到完整的 100 字节
❌ 不能循环 10 次 recvfrom,每次收 10 字节------每次 recvfrom 都返回一条完整数据报
❌ 也不会一次 recvfrom 拿到两条合并的 200 字节------UDP 不合并任何数据用代码验证 UDP 的面向数据报特性:
cpp
// 发送端
for (int i = 0; i < 5; i++) {
std::string msg = "packet-" + std::to_string(i);
sendto(sock, msg.c_str(), msg.size(), 0,
(struct sockaddr*)&server, sizeof(server));
// 发送了 5 条独立的数据报
}
// 接收端
char buf[1024];
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
for (int i = 0; i < 5; i++) {
ssize_t n = recvfrom(sock, buf, sizeof(buf)-1, 0,
(struct sockaddr*)&peer, &len);
// 每次 recvfrom 返回刚好一条数据报的长度------8字节(packet-0)或8字节(packet-4)
// 不存在"一次收到所有 5 条"或"只收到半条"的情况
printf("Received %zd bytes: %s\n", n, buf);
}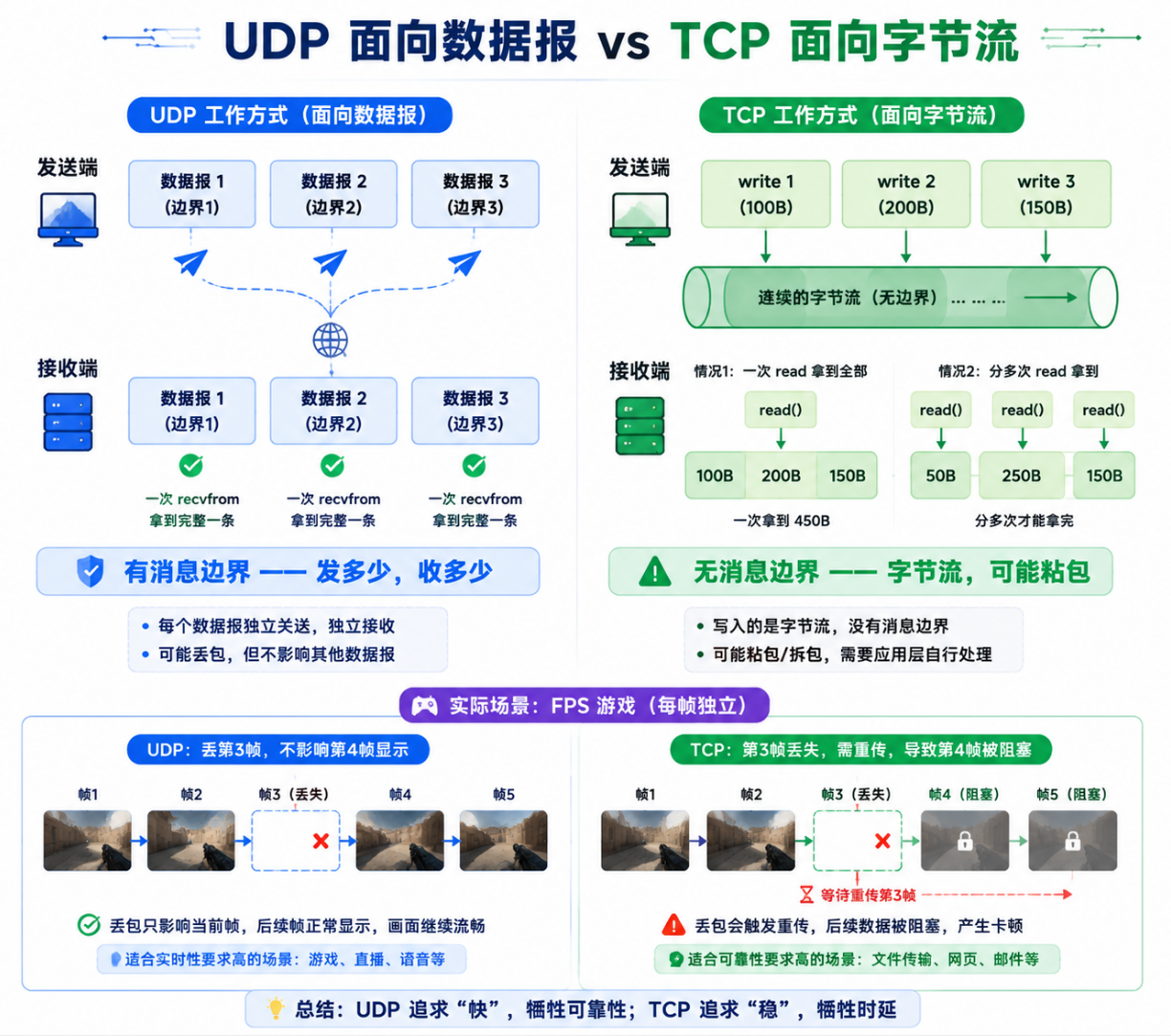
| 特性 | UDP(面向数据报) | TCP(面向字节流) |
|---|---|---|
| 消息边界 | 有边界------发多少,收多少 | 无边界------可能粘包 |
| 发送 100B × 2 | 必须收两次,每次 100B | 可能一次收到 200B,或三次分次收到 |
| 发送 8KB × 1 | 可能收到完整的 8KB,也可能收不到(超过 MTU 被分片后丢失部分则整条丢弃) | 一定分多次收到,但数据不丢失 |
| 协议层处理 | 不拆分、不合并 | 可以任意拆分和合并 |
| 应用层负担 | 需要自己处理丢包和乱序 | 丢包和乱序由 TCP 内核层处理 |
这就是 UDP Socket 编程中不存在"粘包"问题的根本原因------UDP 本身就有消息边界。但也正因为 UDP 什么额外保障都不给,应用层如果需要可靠性,必须自己在协议之上实现确认、重传、排序机制------这本质上就是在造 TCP 的轮子。QUIC 协议(HTTP/3 的底层)正是这样做的:在 UDP 之上重建了一套类似 TCP 的可靠性机制,但避免了 TCP 的队头阻塞问题。
"面向数据报"这个特性还有一个容易被忽略的实际影响:UDP 应用天然适合"最新数据覆盖旧数据"的通信模式。 在一个 FPS 游戏中,玩家的位置每 16ms(60fps)更新一次。如果第 3 帧的位置数据报在网络中丢了,第 4 帧的数据报紧接着到达------对于接收方来说,第 3 帧的数据已经没有任何价值了(因为更新、更准确的位置已经知道)。如果用 TCP,协议层会固执地重传第 3 帧------即使应用层已经不需要它了------导致第 4 帧被挡在重传队列后面等待。这就是 UDP 在实时应用中的核心优势:"过时数据自动失效"的逻辑天然匹配"发送新数据取代旧数据"的业务模式。TCP 的可靠性追求反而成了实时性的障碍------这又一次证明了"可靠性"不是一个绝对值,而是要根据业务场景来定义的。
四、UDP 的缓冲区------与 TCP 的本质差异
缓冲区是理解 UDP 和 TCP 行为差异的关键,也是网络编程面试的高频考点。
| 缓冲区类型 | TCP | UDP |
|---|---|---|
| 发送缓冲区 | ✅ 有。write() 数据进入缓冲区,TCP 负责择机发送、合并、重传 | ❌ 没有。sendto() 直接交内核网络层 |
| 接收缓冲区 | ✅ 有。内核按序重组,应用层按字节流读取 | ✅ 有。但不保证顺序 ,满了就丢弃 |
4.1 UDP 没有发送缓冲区------sendto 直接交内核
调用 sendto 时发生了什么?
应用层 sendto(100 bytes)
→ UDP 层:加 8 字节首部(源端口、目的端口、长度、校验和)
→ IP 层:加 20 字节 IP 头,判断是否超过 MTU(通常 1500 字节)
→ 如果超过 MTU:IP 分片(fragmentation)
→ 如果未超过:直接构建 IP 数据报
→ 交给链路层:加 MAC 头,通过网卡发出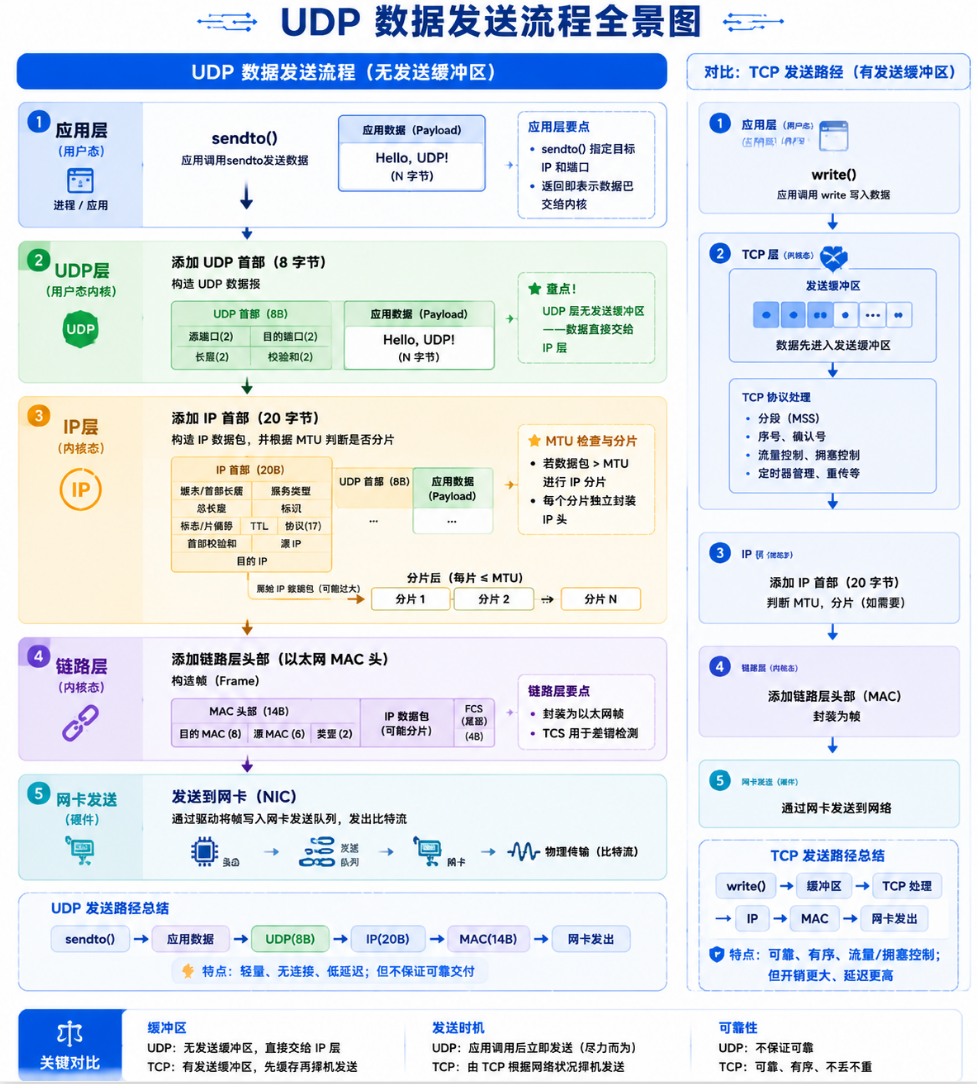
整个过程中,UDP 层没有任何缓冲------数据直接从用户态拷贝到内核,UDP 加上首部,IP 层封装发出。这意味着:
- 发送速率完全由应用程序控制,没有 TCP 的带宽动态协商
- 不会因为"发送缓冲区满了"而导致
sendto阻塞 - 如果发太快超过了网卡速率,IP 层直接丢弃,不会排队
4.2 UDP 有接收缓冲区------但不保证不乱序
接收端的内核会为 UDP socket 维护一个接收缓冲区(可以用 SO_RCVBUF 调整大小):
cpp
// 设置 UDP 接收缓冲区为 256KB
int bufsize = 256 * 1024;
setsockopt(sock, SOL_SOCKET, SO_RCVBUF, &bufsize, sizeof(bufsize));但这个缓冲区的行为与 TCP 完全不同:
① 满了就丢
TCP 接收缓冲区满了→窗口大小通告为 0→发送方暂停。UDP 接收缓冲区满了→后续到达的 UDP 数据报直接被内核丢弃,不通知任何人:
bash
# 查看 UDP 丢包统计
$ cat /proc/net/snmp | grep Udp
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors
Udp: 4592723 65 853 4472918 0 0
# ^^^ ^^^^^^^
# 校验失败丢弃 接收缓冲区满丢弃② 不保证顺序
网络层路由可能会让先发的数据报经过一条拥堵链路后到,而后发的走了畅通链路先到。TCP 靠序列号重排(接收方有一个乱序队列),UDP 直接把数据报交给应用层,不管到达顺序:
发送顺序: [1] [2] [3]
传输路径: [1]走了拥堵链路,[2][3]走了畅通链路
到达顺序: [2] [3] [1] ← UDP: 应用层按这个顺序收到
TCP: 内核重排后按 [1][2][3] 顺序交给应用层4.3 UDP 的全双工
一个 UDP socket 既可以读又可以写------同一个 fd,recvfrom 和 sendto 并行使用,互不阻塞。因为发送路径和接收路径在内核中是独立的两条,各有各的数据结构,不需要锁。
正是因为没有连接的约束,UDP 的全双工比 TCP 更"自由"------你可以从 A 发数据报给 B,同时用同一个 socket 从 C 接收数据报(只要 C 知道你的端口号)。TCP 做不到,因为 TCP socket 一旦建立连接就绑定了一个固定的远程地址。
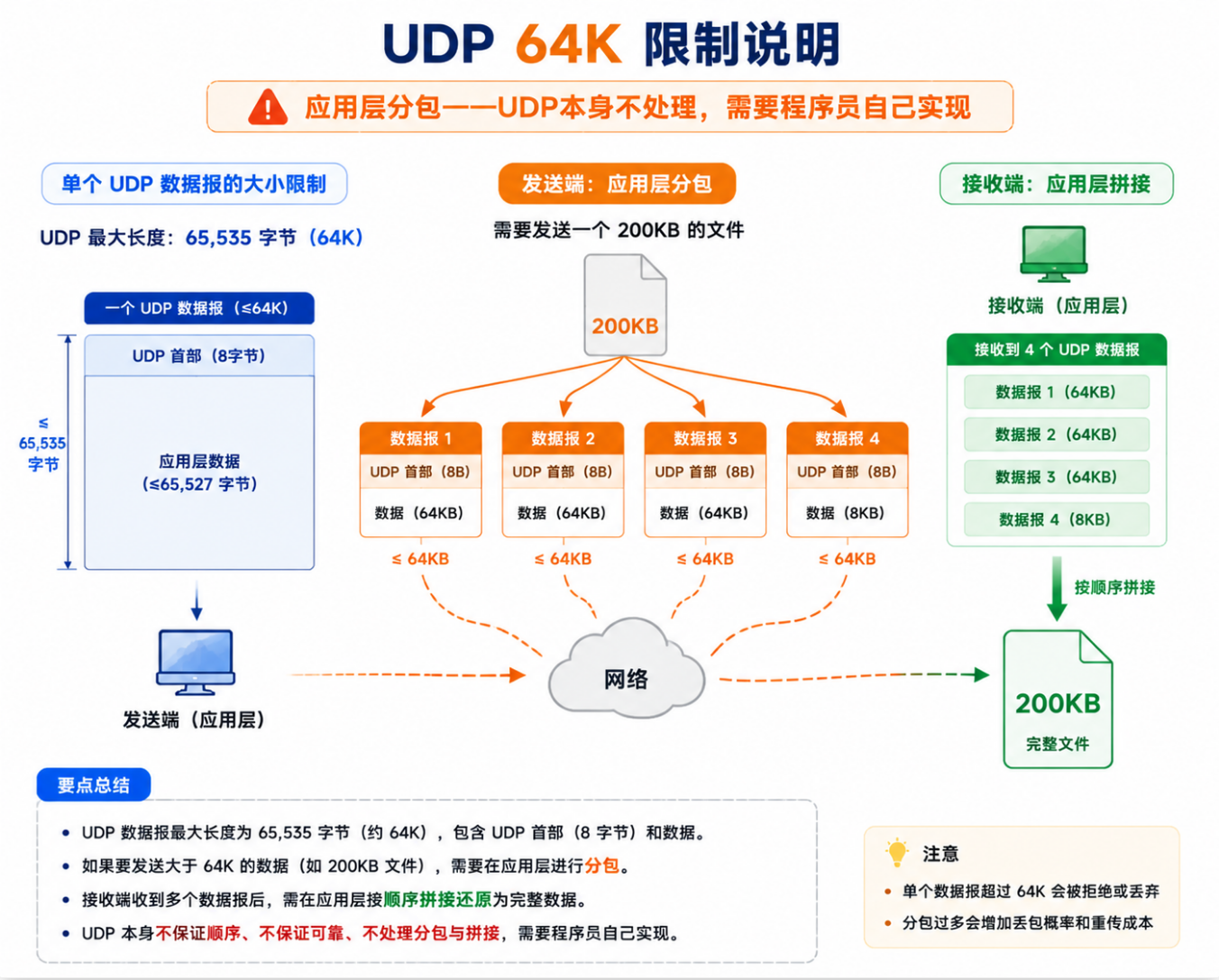
五、64K 限制------UDP 的阿喀琉斯之踵
在深入讨论 64K 限制之前,有必要先理解一个更本质的问题:为什么协议设计者要把 UDP 的长度字段设为 16 位? 答案出奇地简单------1980 年的网络环境。那时候 ARPANET 的骨干带宽是 56Kbps,一个 64KB 的数据报在这种网络上传输需要约 9 秒,根本没有人在实际应用中发这么大的 UDP 数据报。16 位在当时不是限制,而是足够慷慨。但四十年后,网络带宽增加了六个数量级(到 100Gbps),而 UDP 协议头中的长度字段依然是 16 位------不是没人想改,而是改不了,因为改了就不兼容现有的所有 UDP 实现。这就是协议设计的"历史的重量"------当初看似合理的每一个决定,几十年后都可能成为技术债务。HTTP 的 \r\n 分隔符、TCP 的 32 位序列号、IPv4 的 32 位地址,都是类似的例子。这也是为什么新协议(如 QUIC)选择在 UDP 之上重新开始,而不是继续修补 TCP------有时候推倒重来比修补一个四十年前的协议更容易。
5.1 问题的根源
UDP 协议头中的"长度"字段是 16 位,最大值 = 65535(2¹⁶ - 1)。首部固定 8 字节,因此有效载荷最大为 65527 字节。
5.2 还有一个隐含的限制:MTU
实际使用中,很少有人发 64K 的 UDP 数据报。因为 IP 层还有一个更严格的限制:MTU(Maximum Transmission Unit,最大传输单元)。
以太网的 MTU 通常是 1500 字节 。扣除 IP 头(20) 和 UDP 头(8),UDP 的有效载荷如果超过 1472 字节,IP 层就必须分片:
以太网 MTU: 1500 字节
IP 头: -20 字节
UDP 头: -8 字节
UDP 载荷: ≤1472 字节(不需要分片)如果一个 UDP 数据报超过 1472 字节:
发送端 sendto(4000 bytes)
→ IP 层:超过 MTU,分成 3 个片
片1: IP头 + UDP头 + 数据[0~1471]
片2: IP头 + 数据[1472~2943]
片3: IP头 + 数据[2944~3999]
→ 接收端 IP 层:收到 3 个片,重组成完整 IP 数据报,交给 UDP 层
→ 应用层 recvfrom:收到完整的 4000 字节分片的风险: 如果 3 个片中任何一个片丢失,接收端 IP 层的重组失败,整条 UDP 数据报被丢弃。碎片越多,丢包概率越大。所以实践中的建议是:UDP 载荷控制在 1472 字节以内,避免分片。
这也是 DNS 和 DHCP 的典型查询大小设计在 512 字节以内的原因之一------不仅不需要分片,而且对网络带宽的要求极低。
5.3 超 64K 怎么办------应用层分包
cpp
// 应用层分包发送
#define MAX_UDP_PAYLOAD 1400 // 留一些余地,保守值
void SendLargeData(int sock, const char* data, size_t total_size,
struct sockaddr* dest, socklen_t addrlen)
{
// 分包头部:[总包数(2B)][当前包序号(2B)][数据片段]
uint16_t total_packets = (total_size + MAX_UDP_PAYLOAD - 1) / MAX_UDP_PAYLOAD;
for (uint16_t seq = 0; seq < total_packets; seq++)
{
size_t offset = seq * MAX_UDP_PAYLOAD;
size_t chunk_size = std::min((size_t)MAX_UDP_PAYLOAD,
total_size - offset);
char packet[MAX_UDP_PAYLOAD + 4];
memcpy(packet, &total_packets, 2); // 总包数
memcpy(packet + 2, &seq, 2); // 序号
memcpy(packet + 4, data + offset, chunk_size); // 数据片段
sendto(sock, packet, chunk_size + 4, 0, dest, addrlen);
}
}
// 接收端根据 total_packets 和 seq 重组,缺失的包请求重发六、基于 UDP 的经典应用层协议
UDP 虽然简单,但在以下场景中不可替代:
| 协议 | 全称 | 用途 | 为什么用 UDP |
|---|---|---|---|
| DNS | 域名解析协议 | 将域名转为 IP 地址 | 查询体积极小(几十~几百字节),一次往返即可;TCP 三次握手三倍开销不值得;丢包只需客户端重试 |
| DHCP | 动态主机配置协议 | 自动分配 IP 地址 | 客户端连 IP 都没有时,无法建立 TCP 连接;需要广播发现服务器;只能用 UDP |
| NFS | 网络文件系统 | 局域网文件共享 | 局域网低丢包率;UDP 性能优势(无握手,无拥塞控制)超过可靠性损失;现代 NFSv4 也可用 TCP |
| TFTP | 简单文件传输协议 | 无盘设备启动 | 协议栈极简化(ROM 只有几百 KB);UDP 的简单性契合嵌入式需求 |
| RIP | 路由信息协议 | 路由器之间交换路由表 | 周期性广播路由更新;丢失一次不影响(下次更新会刷新);TCP 的连接模型不适合广播 |
| SNMP | 简单网络管理协议 | 网络设备监控管理 | 轮询式查询,每条都短小独立;丢一次不影响(下次轮询会再来) |
包括你自己写的 UDP 自定义协议------当需要低延迟、支持广播/组播、不要求每条都确认送达、且丢包可以接受时,UDP 就是正确的选择。如果这些条件不满足------你还是需要 TCP。
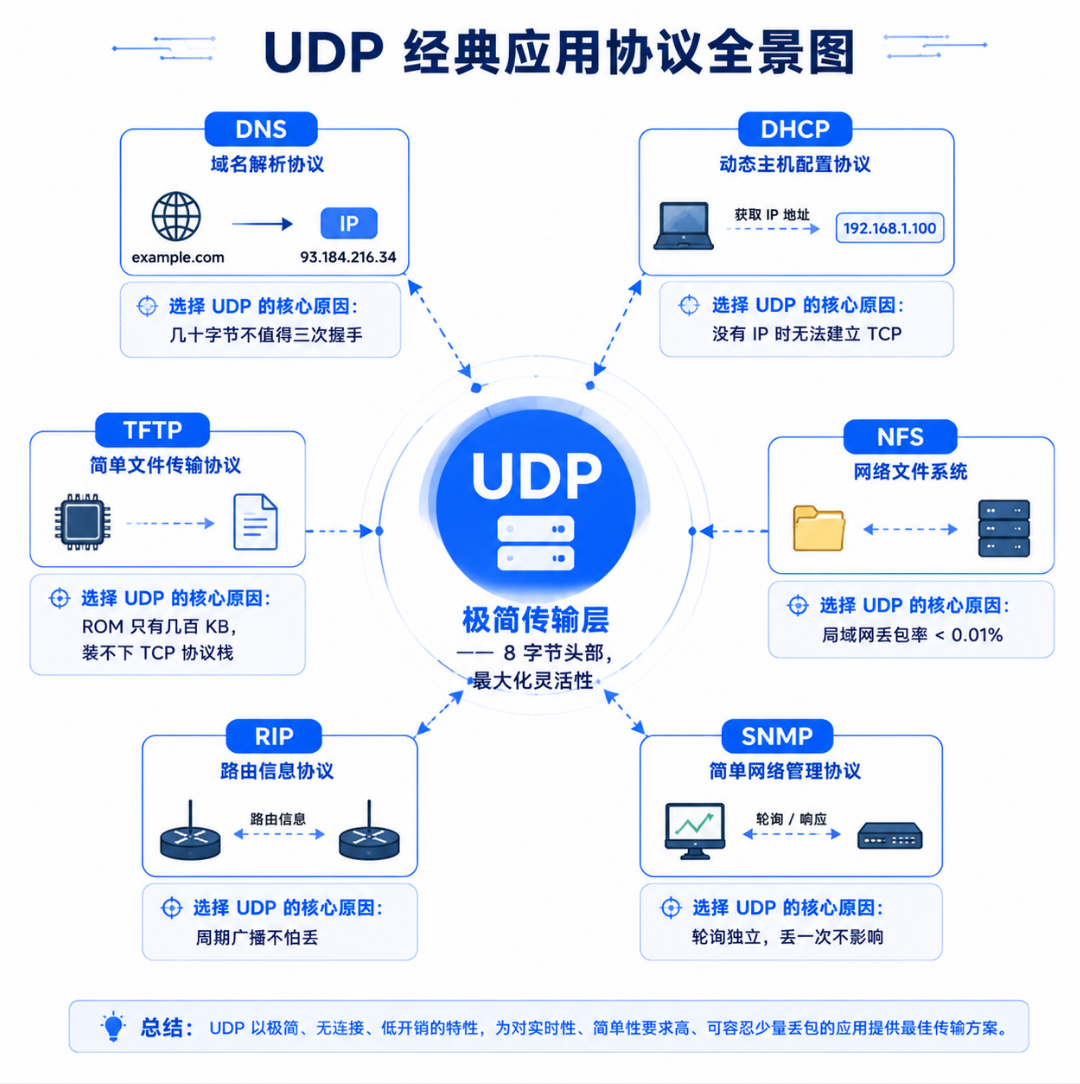
从这些经典协议中能抽象出一个选择 UDP 的通用公式:UDP = 数据可以丢 + 延迟不能高 + 不需要一对一连接。 DNS 可以丢(客户端重试),但不能慢(用户等不起三次握手);DHCP 连 IP 都没有,物理上无法建立 TCP;NFS 在局域网中丢包率极低,TCP 的可靠性保障是多余的代价。这三个条件中,满足任意两个就应该认真考虑 UDP。但如果你要传的是钱、密码、医疗数据------哪怕只满足一个条件也不该用 UDP。最终,协议选择是在数据价值 和传输开销之间做权衡。
七、常见问题与避坑指南
7.1 为什么 UDP 数据报发不出去
现象: sendto 返回 -1,errno = EMSGSIZE(消息太长)。
原因: 数据报太大了,超过了内核允许的处理上限。
解决: 将数据控制在 65507 字节以内(64K - IP头 - UDP头),实践中更建议控制在 1472 字节以内以避免 IP 分片。
7.2 recvfrom 收到的数据比发送的少
现象: 发送了 5000 字节,但 recvfrom 只收到了 2000 字节。
原因: 接收缓冲区不够大。recvfrom 的第三个参数指定了缓冲区大小,如果小于数据报实际大小,多余的数据会被截断并丢弃,不可恢复。
解决: 缓冲区大小要大于预期最大数据报大小。或者先 ioctl(FIONREAD) 查询下一条数据报的大小。
cpp
// 查询下一条 UDP 数据报的大小
int datagram_size;
ioctl(sock, FIONREAD, &datagram_size);
char* buf = new char[datagram_size];
recvfrom(sock, buf, datagram_size, 0, ...);7.3 UDP 的"连接"------connected UDP
虽然 UDP 是无连接的,但 connect() 在 UDP socket 上仍然有意义:
cpp
// "连接" UDP socket------不是真的建立连接,而是绑定一个默认目标地址
connect(sock, (struct sockaddr*)&server, sizeof(server));
// 之后可以用 read/write 替代 recvfrom/sendto
write(sock, buf, len);
read(sock, buf, len); // 只收来自 "connected" 地址的数据
// 好处1: 内核只投递来自该地址的数据报,其他来源的会被丢弃
// 好处2: 收到 ICMP 错误(如"端口不可达")会返回给应用层而非被吞掉
// 好处3: 性能略高------内核不用每次检查数据报是否匹配面试题:"UDP 的 connect 做了什么?"------绑定远程地址,使 socket 只与该地址通信,并能接收 ICMP 错误通知。它不是真正的"连接",只是一层过滤。
八、UDP Socket 选项详解------从默认行为到性能调优
前面几节讲的是 UDP 协议本身,这一节聚焦于 Linux 提供给你控制 UDP 行为的 socket 选项。大部分 UDP 程序的性能问题和 bug 都源于对这些选项不熟悉。
8.1 SO_RCVBUF / SO_SNDBUF------调整缓冲区大小
虽然 UDP 没有真正的发送缓冲区,但 SO_SNDBUF 仍然存在------它限制了 UDP 数据报在 IP 层排队等待发送的最大内存量。SO_RCVBUF 直接控制接收缓冲区:
cpp
// 获取当前缓冲区大小
int bufsize;
socklen_t optlen = sizeof(bufsize);
getsockopt(sock, SOL_SOCKET, SO_RCVBUF, &bufsize, &optlen);
printf("Default recv buffer: %d bytes\n", bufsize);
// Linux 默认值通常是 212992 字节(约 208KB)
// 设置为 1MB
bufsize = 1024 * 1024;
setsockopt(sock, SOL_SOCKET, SO_RCVBUF, &bufsize, sizeof(bufsize));为什么增大接收缓冲区?高吞吐场景下(如视频流),应用层处理速度可能跟不上接收速度。更大的缓冲区意味着在应用层来得及
recvfrom之前,内核能暂存更多数据报,减少丢弃。
注意: Linux 内核会双倍 你设置的值(为内核内部数据结构预留空间),并且受系统上限 net.core.rmem_max 限制:
bash
# 查看和修改系统上限
$ sysctl net.core.rmem_max
net.core.rmem_max = 212992
$ sudo sysctl -w net.core.rmem_max=1048576 # 设为 1MB8.2 SO_BROADCAST------允许发送广播
UDP 天然支持广播(向子网内所有主机发送),但出于安全考虑,默认禁止。必须显式开启:
cpp
int broadcast = 1;
setsockopt(sock, SOL_SOCKET, SO_BROADCAST, &broadcast, sizeof(broadcast));
struct sockaddr_in dest;
dest.sin_family = AF_INET;
dest.sin_port = htons(8888);
dest.sin_addr.s_addr = inet_addr("192.168.1.255"); // 广播地址
// 或者: htonl(INADDR_BROADCAST) = 255.255.255.255
sendto(sock, buf, len, 0, (struct sockaddr*)&dest, sizeof(dest));如果忘了设置
SO_BROADCAST,sendto到广播地址会返回 -1,errno = EACCES(Permission denied)。这是内核的安全机制,防止程序无意间向全网广播。
8.3 IP_ADD_MEMBERSHIP------加入组播组
组播(Multicast)是 UDP 的独门功夫,TCP 完全做不到。接收方需要"订阅"一个组播地址(224.0.0.0 ~ 239.255.255.255):
cpp
// 加入组播组 224.0.0.100
struct ip_mreq mreq;
mreq.imr_multiaddr.s_addr = inet_addr("224.0.0.100"); // 组播地址
mreq.imr_interface.s_addr = htonl(INADDR_ANY); // 本机网卡
if (setsockopt(sock, IPPROTO_IP, IP_ADD_MEMBERSHIP,
&mreq, sizeof(mreq)) < 0) {
perror("IP_ADD_MEMBERSHIP failed");
}
// 之后 bind 到指定端口,就可以接收发往 224.0.0.100 的数据报组播是互联网直播、IPTV、金融行情推送等场景的底层技术------服务端发一条数据报到组播地址,交换机复制给所有订阅者,带宽效率远高于 TCP 的 N 条独立连接。
8.4 SO_RCVTIMEO------设置接收超时
TCP 的心跳和超时机制内建于协议层。UDP 没有这些,但你可以用 SO_RCVTIMEO 给 recvfrom 设置一个超时:
cpp
struct timeval tv;
tv.tv_sec = 5; // 5 秒
tv.tv_usec = 0;
setsockopt(sock, SOL_SOCKET, SO_RCVTIMEO, &tv, sizeof(tv));
// 之后 recvfrom 最多阻塞 5 秒,超时返回 -1, errno = EAGAIN/EWOULDBLOCK
ssize_t n = recvfrom(sock, buf, sizeof(buf), 0, NULL, NULL);
if (n < 0 && (errno == EAGAIN || errno == EWOULDBLOCK)) {
printf("recvfrom timed out after 5 seconds\n");
// 可以做心跳检测、清理资源等操作
}这个选项在"UDP 聊天室"中特别实用:服务器可以定期检查哪些客户端长时间未发消息,将它们从在线列表中移除。
8.5 实战:用 getsockopt 诊断 UDP 丢包
cpp
// 获取 UDP 层的错误统计
int rcvbufErrors, sndbufErrors, noPorts, inErrors;
socklen_t optlen = sizeof(int);
// 这些需要通过 /proc 读取,没有直接的 getsockopt 选项
// 但你可以比较发送前后的计数器差距来判断是否丢包
system("cat /proc/net/snmp | grep Udp: | awk '{print \"InErrors=\"$4\" RcvbufErrors=\"$6}'");或者用 netstat -su 查看 UDP 统计汇总:
bash
$ netstat -su
Udp:
4592723 packets received
65 packets to unknown port received.
853 packet receive errors # 校验失败+缓冲区满
4472918 packets sent
0 receive buffer errors # RcvbufErrors
0 send buffer errors # SndbufErrors九、UDP 与 TCP 的选择------一张决策表
学完 UDP 和 TCP 的协议细节后,面临选择时的场景远不止技术层面的判断。实际工程中,协议选择还受制于部署环境的约束。比如你开发了一款使用自定义 UDP 协议的实时游戏,用户在公司内网可以正常联机,回到家却发现连不上------因为很多企业防火墙和家庭路由器默认只放行 TCP 80/443 端口,UDP 流量被直接丢弃。这是 UDP 在生产环境中最常见的"非技术性阻碍"------不是协议不好,而是网络不让你用。因此很多实时应用(如 Zoom、Microsoft Teams)的工程师们付出了巨大努力来实现"UDP 优先、TCP 降级"的连接策略:先尝试 UDP(QUIC 或 WebRTC),如果 5 秒内连接建立失败,自动切换到 TCP 443(伪装成 HTTPS 流量穿过防火墙)。这种多路径连接策略是生产级实时通信的标配。
学完 UDP 和 TCP 的协议细节后,面临选择时的最终决策依据:
| 场景 | 选 UDP | 选 TCP | 理由 |
|---|---|---|---|
| 文件传输、网页浏览 | ❌ | ✅ | 内容完整性优先于速度 |
| DNS 查询(<512B) | ✅ | ❌ | TCP 握手三倍开销,丢包重试足够 |
| 实时音视频通话 | ✅ | ❌ | 丢帧不影响体验,延迟影响体验 |
| 游戏位置同步(FPS) | ✅ | ❌ | 位置每帧都更新,丢几帧不重要 |
| 登录/支付/交易 | ❌ | ✅ | 钱和密码不能丢 |
| 物联网传感器数据 | 看情况 | 看情况 | 温度每 5 分钟上报一次→UDP(丢一次无所谓);门禁开锁指令→TCP(不能丢) |
| 局域网文件共享 | ✅ | 看情况 | 局域网丢包率 < 0.01%,UDP 性能更好,没必要为可靠性付出 TCP 握手的代价 |
| 需要广播/组播 | ✅ | ❌ | TCP 物理上做不到------必须先一对一建立连接 |
| API 端点 | ❌ | ✅ | 请求-响应模型天然适合 TCP;用 UDP 等于自建 HTTP |
| 远程命令执行(SSH) | ❌ | ✅ | 每条命令必须可靠送达,而且顺序不能乱 |
一个经验法则:
- 如果"每一条数据都必须到达"→TCP
- 如果"最新数据到达就行,旧数据没有意义"→UDP
- 如果"都要"→QUIC(HTTP/3),在 UDP 之上自建可靠性
- 如果"都不要"→考虑用消息队列(RabbitMQ/Kafka),它们处理可靠性传输比你写得好
总结
UDP 协议在互联网协议栈中占据着一个看似矛盾实则必不可少的位置。它提供了最少的机制 (端口复用 + 可选校验),换来了最大的灵活性 ------在 UDP 之上可以构建任何传输模式:不可靠的实时视频流、可靠的文件传输(通过应用层重传)、多播的股市行情、加密的 VPN 隧道。TCP 只提供了一种通信方式(可靠的、有序的、一对一的字节流),而 UDP 提供了"什么都没有"------这个"什么都没有"恰恰是最大的自由。在技术选型时,我们往往倾向于选择"功能更多"的方案------因为"更多"听起来"更安全"。但 UDP 的历史证明了一个反直觉的事实:有时候,"更少"比"更多"更有生命力。 因为"更少"意味着更少的约束、更少的假设、更少的包袱------当网络环境变化、业务需求变化时,"更少"的方案适应能力更强。从 UDP(1980)到 QUIC(2012)的三十年时间线,就是这个道理的最好证明:一个极简的协议,给了后来者充分的空间在上面构建任何他们需要的传输层。
| 维度 | UDP 的本质 |
|---|---|
| 协议头 | 8 字节极简------源端口 + 目的端口 + 长度 + 校验和 |
| 连接 | 无连接------支持单播、广播、组播 |
| 可靠性 | 四个层面不可靠:无确认、无重传、静默丢弃、无拥塞控制 |
| 数据 | 面向数据报------有边界,不拆分不合并,recvfrom 一次一条 |
| 缓冲区 | 无发送缓冲区(交内核即发),有接收缓冲区(满了丢,不排序) |
| 上限 | 64K(协议限制),1472 字节(MTU 友好值) |
| 全双工 | 同一 fd 可以同时收发,且可以跟不同对端通信 |
| 本质 | 最大化简单性和低延迟,代价是放弃一切可靠性保障。选择它不是因为"够用",而是因为"不需要"------不需要的机制就是纯粹的浪费。 |
动手试试
- 用
tcpdump抓取 UDP 数据报,手动解析首部中的四个字段,验证源/目的端口号和长度字段与实际数据是否一致:sudo tcpdump -i lo -X udp port 8888- 写一个程序验证 UDP 分片行为------发送一个 3000 字节的 UDP 数据报,用
tcpdump观察 IP 层的分片过程(提示:tcpdump -i lo -v "ip[6:2] & 0x1fff != 0"只显示有分片标记的数据包)。- 使用
SO_RCVBUF故意设置一个很小的接收缓冲区(如 256 字节),然后快速发送大量 UDP 数据报,通过/proc/net/snmp观察RcvbufErrors的增长(提示:watch -n1 "cat /proc/net/snmp | grep Udp")。
预告: 下一篇将从协议层深挖 TCP 传输控制协议的可靠传输机制------三次握手四次挥手的状态机、确认应答、超时重传、滑动窗口与拥塞控制的完整密码。
尾声
本章讲解就到此结束了,若有纰漏或不足之处欢迎大家在评论区留言或者私信,同时也欢迎各位一起探讨学习。感谢您的观看!