一、回顾
Primary backup 需要 consensus 来做 leader election
问题引入:
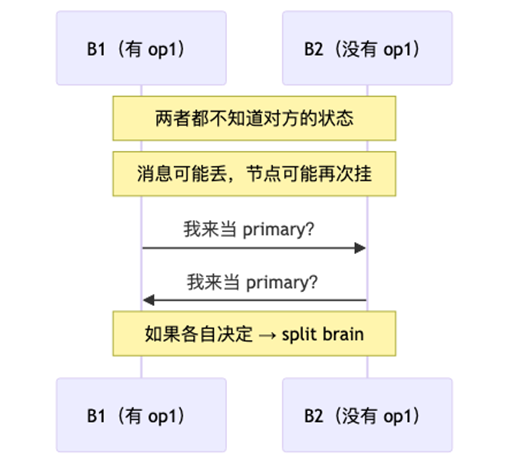
Primary 收到写操作 op1,把它发给了 B1,还没发给 B2 就挂了。
P → B1: op1 ✓
P → B2: op1 ✗(P 挂了)
现在 B1 和 B2 都想当新 primary:
谁来当?怎么选?
op1 算不算已提交?
新 primary 的 log 应该以谁为准?
可能的结果:
-
B1 和 B2 无法区分"对方挂了"和"消息慢了"
-
各自决定 → 两个 primary → split brain
-
都等对方 → 可能永远等下去
二、广播协议
Primary 把操作发给所有 backup,本质上就是广播
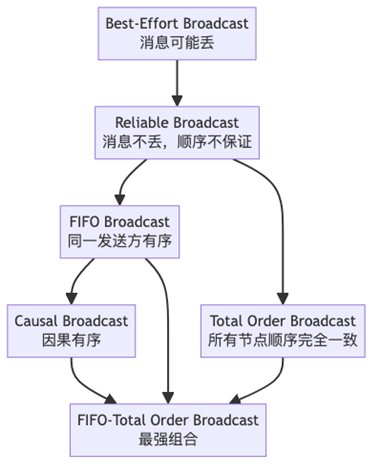
五种广播协议(由弱到强)
| 广播类型 | 保证什么 | 对应问题 |
|---|---|---|
| Best-Effort Broadcast | 尽力发送,不重试 | 最朴素复制 |
| Reliable Broadcast | 要么都收到,要么都收不到 | 消息不丢 |
| FIFO Broadcast | 同一发送方的消息顺序一致 | 单个 primary 不产生乱序 |
| Causal Broadcast | 有因果关系的消息顺序一致 | 跨节点因果依赖 |
| Total Order Broadcast | 所有节点完全相同的顺序 | 所有 backup 状态一致 |
1、Best-Effort Broadcast(尽力广播)(最弱)
定义:发送方尽力发送,不重试。发送方崩溃或网络丢包 → 部分节点收不到。
比喻:你在群里发消息,发完就不管了,有的人收到了有的人没收到。
2、Reliable Broadcast(可靠广播)
定义:第一次收到消息时,转发给所有其他节点。只要有一个非故障节点收到,所有非故障节点最终都会收到。
比喻:收到消息的人帮转发给群里的所有人,确保大家都收到
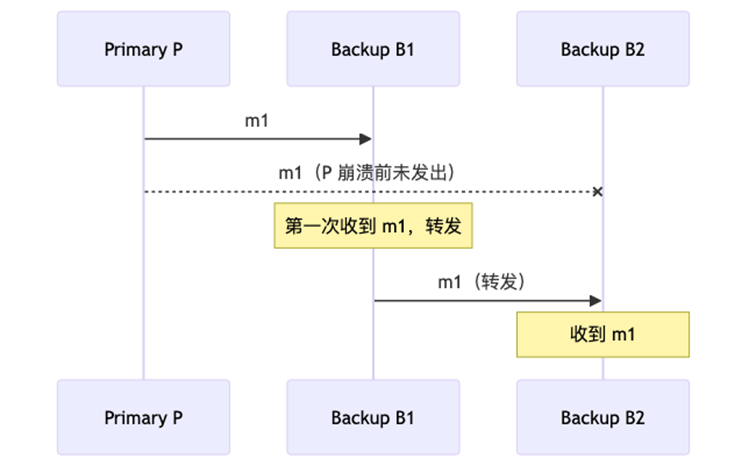
缺点: 最多O(n²) 条消息;顺序还没保证
3、FIFO Broadcast(FIFO 广播)
定义:同一发送方的消息,按发送顺序 deliver。不同发送方的消息,顺序不保证。
解决了单个 primary 的乱序问题
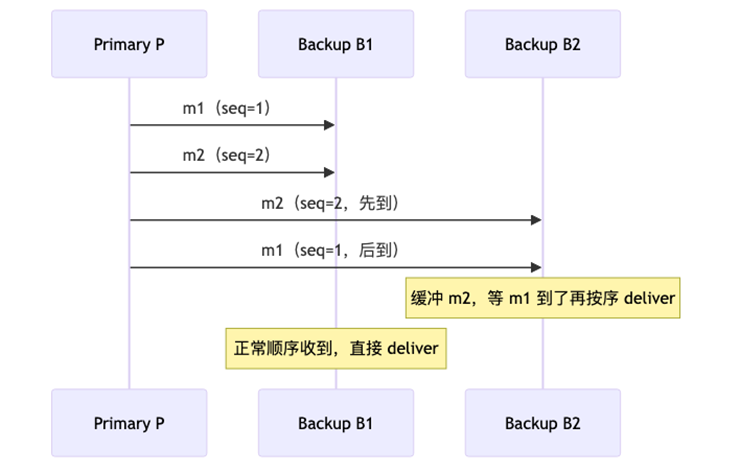
比喻:同一个人发的消息按顺序收到,但不同人发的消息可能穿插。
4、Causal Broadcast(因果广播)
定义:有因果关系的消息,必须按因果顺序 deliver。因果无关的消息可以任意顺序。
比 FIFO 更强:跨节点的因果依赖也要保证。
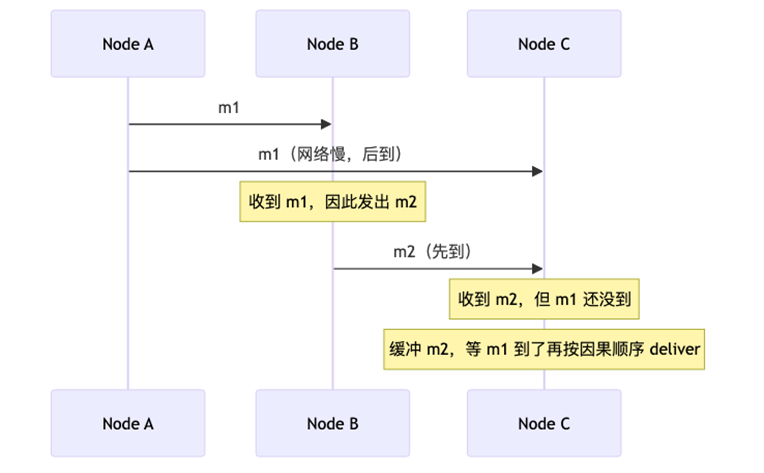
例子:
-
A 发消息 m1:"晚上一起吃饭?"
-
B 看到 m1 后发 m2:"好啊"
-
所有节点必须先 deliver m1,再 deliver m2(即使 m2 先到)
5、Total Order Broadcast(全序广播)
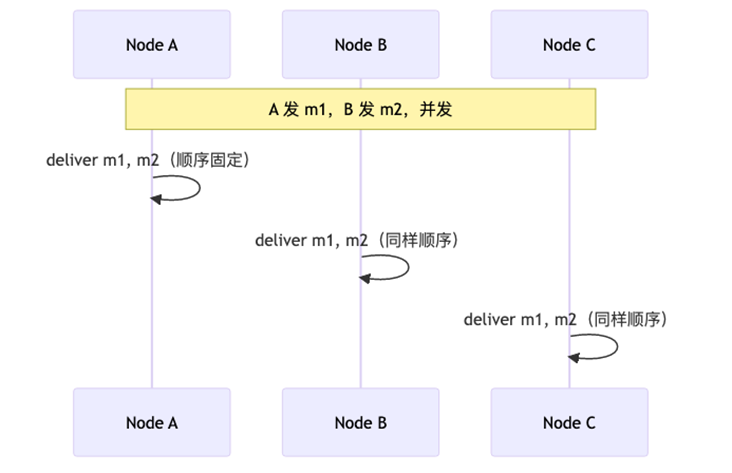
定义 :所有节点以完全相同的顺序 deliver 所有消息。包括并发消息------必须有一个全局一致的顺序。
这是 primary-backup 最核心的需求:所有 backup 按同样顺序执行操作。
总结
|-------------|---------------------------|
| 广播协议 | 解决的 primary-backup 问题 |
| Best-effort | 朴素复制,消息可能丢 |
| Reliable | 保证所有 backup 最终收到 |
| FIFO | Primary 的操作顺序不乱 |
| Causal | 跨节点的因果操作有序 |
| Total order | 所有 backup 状态完全一致 |
Primary-backup 正常运行时,primary 就是 total order broadcast 的 sequencer(排序器)。
有了 consensus,就能实现 total order broadcast

-
Total order → consensus:每次所有节点 deliver 同一条消息,就是对"这条消息排第几"达成了共识
-
Consensus → total order:每一轮 consensus 决定下一条要 deliver 的消息,串起来就是 total order
三、Consensus共识
用途:
-
选 leader:谁来当 primary?
-
决定消息顺序:下一条 deliver 哪条消息?
-
分布式锁:谁拿到锁?
Consensus 要求:最后只能有一个决定
1、共识的三条性质
| 性质 | 含义 | 类型 |
|---|---|---|
| Agreement(一致性) | 所有做出决定的节点,决定的是同一个值 | Safety |
| Validity(合法性) | 决定的值必须是某个节点提议过的 | Safety |
| Termination(终止性) | 所有非故障节点最终都会做出决定 | Liveness |
用 leader election 理解
| 性质 | 违反的例子 |
|---|---|
| Agreement(一致性) | A 认为 A 是 leader,B 认为 B 是 leader |
| Validity(合法性) | 凭空决定 D 是 leader(没人提议过 D) |
| Termination(终止性) | 所有人一直卡住,谁也不当 leader |
2、Safetyness 和 Liveness
| 概念 | 含义 | 比喻 |
|---|---|---|
| Safety | 不能发生坏事 | 不能选出两个 leader |
| Liveness | 好事最终要发生 | 最终一定选出 leader |
Paxos、Raft 的基本取舍:网络不确定时,先保证不答错,再等待条件恢复来推进
3、FLP 不可能性
什么是 FLP?
Fischer, Lynch, Paterson,一篇分布式系统理论的里程碑论文
论文结论:在完全异步 的 crash-stop 系统中,不存在一个确定性的 consensus 算法能保证 termination。即使最多只有 1 个节点可能崩溃,也不行
人话:如果网络没有时间限制(消息可能无限期延迟),那么就算只有一台机器可能挂掉,你也不可能设计出一个总能达成共识的算法。
FLP的关键困难:
完全异步系统里,没有消息延迟上限。一个节点没回复,其他节点分不清:
-
它真的崩溃了
-
它没崩溃,只是消息非常慢
-
它的回复已经发出,但还在路上
FLP 说的是:在纯异步模型里,不能无条件保证 termination
| 情况 | FLP 怎么说 |
|---|---|
| 能不能在"大部分情况"下达成共识? | ✅ 能(Paxos、Raft 都做到了) |
| 能不能在"所有可能情况"下都保证达成共识? | ❌ 不能(FLP 说不存在这样的算法) |
FLP 否定的是 termination(liveness),不是 agreement(safety)
解释:FLP 认为,在完全异步的模型中,能保证 Safety(不能选出两个 leader);但不能保证最终一定能达成共识(liveness)
FLP 说的是纯异步系统。实践中的解法:
-
引入部分同步假设------网络最终会恢复,有超时机制
-
Safety 不依赖时钟,liveness 依赖超时
-
宁可暂时选不出 leader,也不选出两个
4、实现 consensus 的朴素想法
3 个节点,每个节点提议一个值,投票,多数派赢。
但如果有的节点崩溃、消息丢失,投票会出问题,如下:
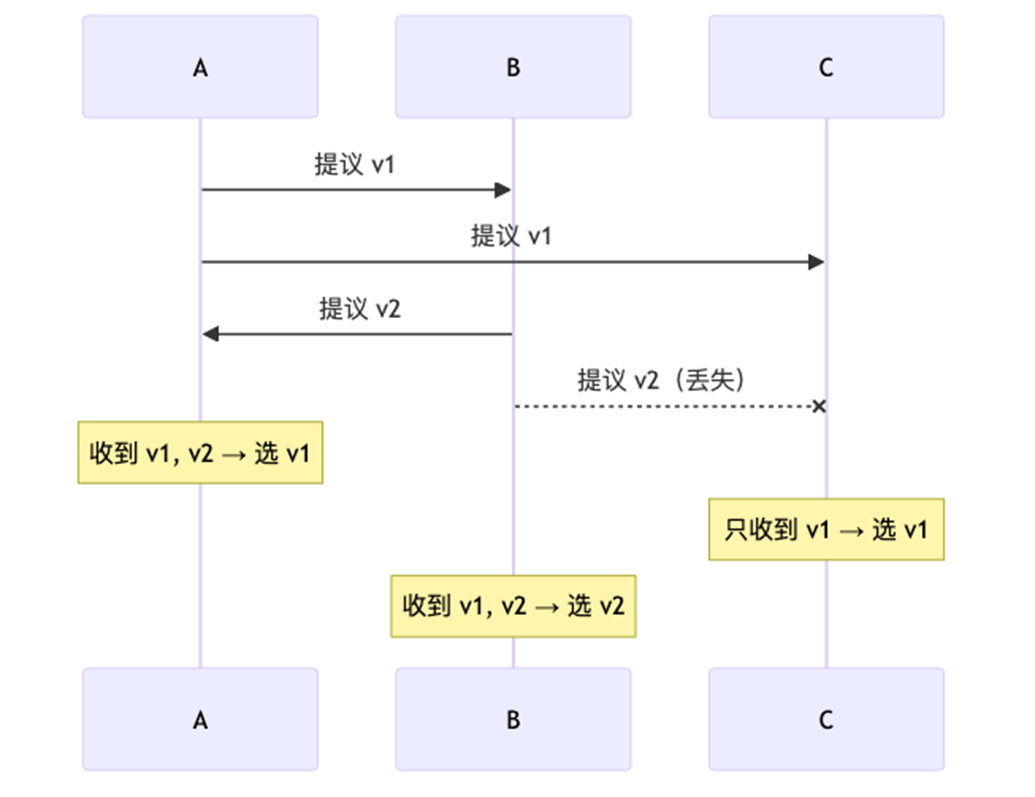
A 提议 v1
B 提议 v2
C 提议 v1
但网络出问题了:
A 和 C 能互相通信,它们都选 v1
B 只能和一部分节点通信,它选 v2
结果:
| 节点 | 看到的情况 | 认为谁赢了 |
|---|---|---|
| A | 自己投 v1,C 也投 v1 | v1 赢了 ✅ |
| B | 自己投 v2,没收到别人的消息 | v2 赢了 ✅ |
| C | 自己投 v1,A 也投 v1 | v1 赢了 ✅ |
A 和 C 认为 v1 赢了,B 认为 v2 赢了 → 违反 Agreement!
根本原因:节点在信息不完整的情况下就做了决定。
如何解决?
答:决定之前,先看多数派那里有没有历史。
核心思路:
-
不要急着做决定
-
先问一圈:"你们之前已经接受过什么值?"
-
如果有人已经接受过某个值,沿用那个值
-
如果没人接受过,才用自己的新值
比喻:
你去投票,不是直接投。而是先问:
-
"之前大家已经选过什么了?"
-
如果之前已经有人选了川菜,你就跟着选川菜
-
如果之前没人选过,你才提议自己的
目标是 reach consensus(达成共识),不是 win(赢)。
5、Paxos
核心思想:如果某个值已经可能被选中,后面的人必须继续用它。如果还没有任何值被选中,proposer 才能用自己的值。
理解:
场景 1:没人接受过值
A 问 B、C:"你们接受过什么吗?"
B 说:"没有"
C 说:"没有"
A 说:"好,那我提议 v1"
场景 2:有人接受过值
A 问 B、C:"你们接受过什么吗?"
B 说:"我接受过 v2(编号 5)"
C 说:"我接受过 v2(编号 5)"
A 说:"好,那我必须继续提议 v2"
1)Paxos 的角色分工
| 角色 | 职责 | 比喻 |
|---|---|---|
| Proposer(提议者) | 提出一个值 | 提议人 |
| Acceptor(接受者) | 接受或拒绝 proposal | 投票者 |
| Learner(学习者) | 学习最终 chosen 的值 | 围观群众 |
实际系统里,一个节点通常同时扮演多个角色
2)Proposer
Paxos 里提案不是单独一个值,而是一对:(proposal number, value) = (n, v)
| 部分 | 含义 | 例子 |
|---|---|---|
| proposal number(提案编号) | 全局唯一,越来越大 | 5, 7, 9... |
| value(值) | 真正要提议的内容 | v1, v2... |
为什么要用编号?
-
编号决定优先级:编号越大越新
-
编号帮助去重:同一个编号的提案只会被处理一次
-
编号帮助承诺:Acceptor 承诺不再接受比它小的编号
3)Paxos 的两个阶段
-
Phase 1(Prepare):先问多数派,有没有接受过历史值
-
Phase 2(Accept):再把一个值写入多数派
即:先探测历史,再决定自己能不能用新值。
阶段一:
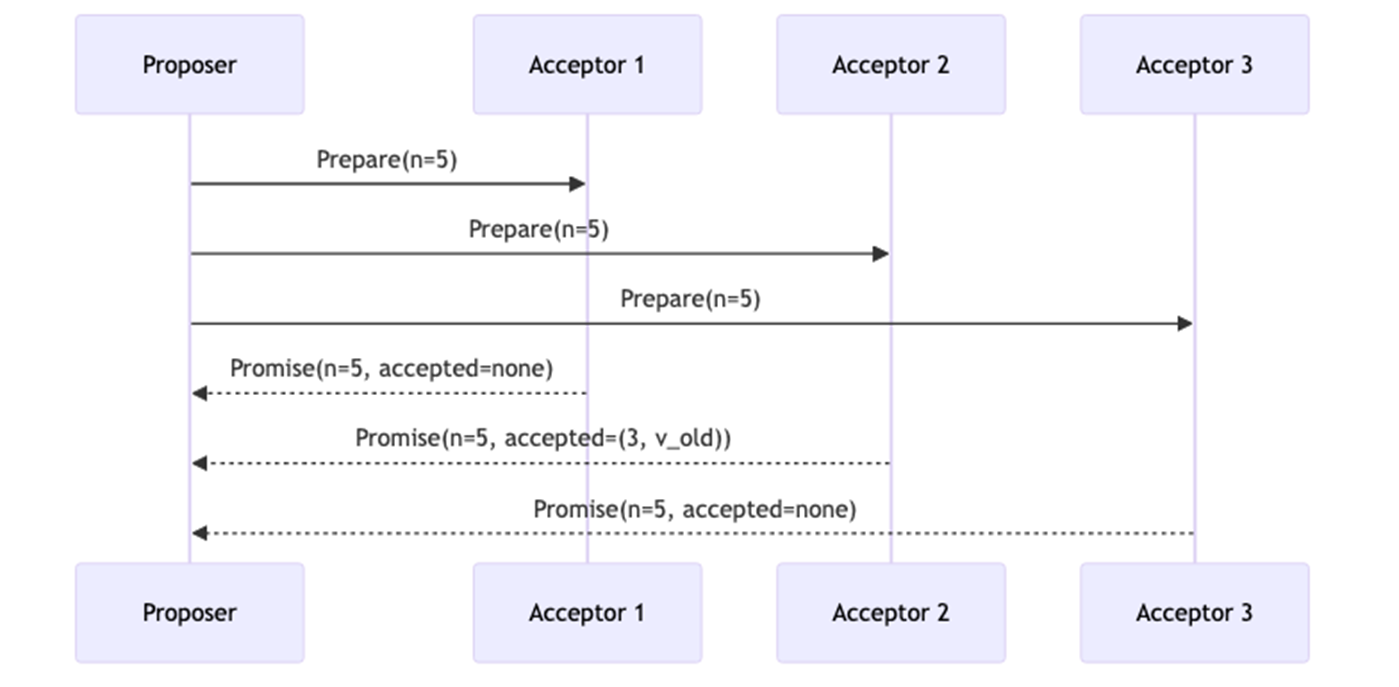
-
Proposer 选一个唯一递增的提案号
n(比之前所有编号都大) -
向所有 Acceptor 发送
Prepare(n) -
Acceptor 如果没见过更大的编号 ,就回复 Promise(承诺)
-
承诺内容:
-
不再接受编号
< n的 proposal -
返回自己已经接受过的最高编号 proposal(如果有的话)
-
-
-
Proposer 收到多数派的 promise 后,进入 Phase 2
4)Acceptor
Acceptor 会记住自己 promise 过的最大编号 。如果已经 promise 过更大的 n,就不能再接受更小的 n。
这条规则让旧 proposal 不能回头覆盖新 proposal
5)阶段一结束后的 Proposer 选值
| 多数派返回的情况 | Proposer 的做法 |
|---|---|
| 没有人返回已接受值 | 使用自己的值 v |
| 有人返回已接受值 | 必须选编号最高的那个 accepted value |
这一步是 Paxos safety(安全性)的关键。
6)阶段二
-
Proposer 发送
Accept(n, v)给所有 Acceptor-
n:提案编号 -
v:Phase 1 决定的值(要么是自己的,要么是历史最高编号的值)
-
-
Acceptor 如果没有承诺过更大的编号,就接受这个 proposal
-
多数派接受 → 值被选定(Chosen)
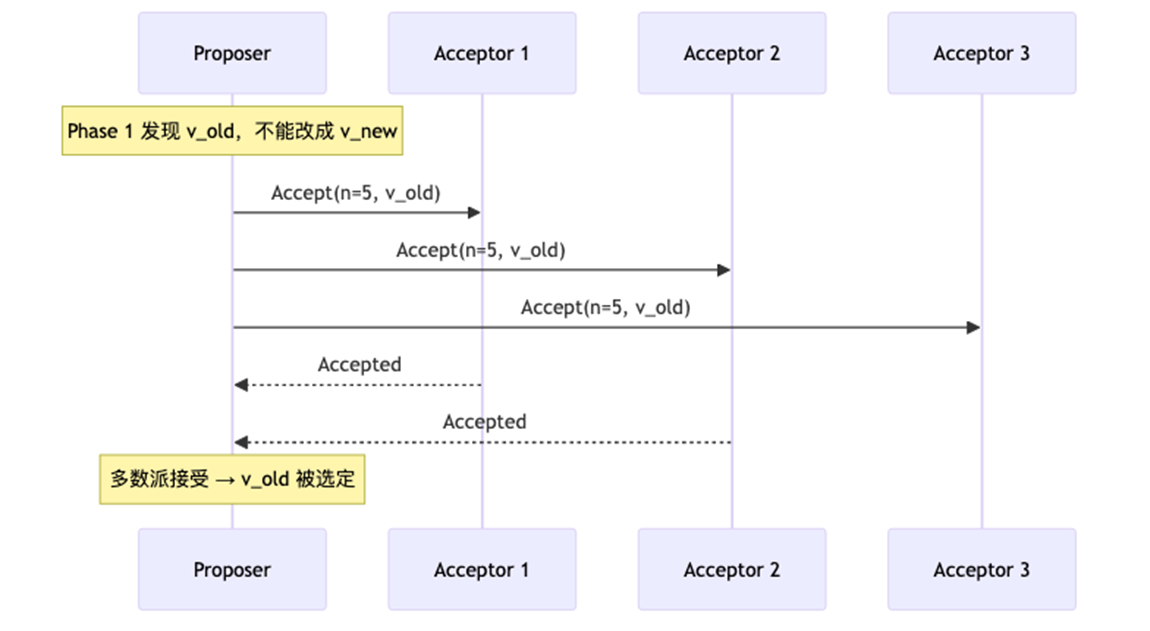
Chosen = 这个 value 已经不能再被换掉。即为选定了。
7)为什么Paxos是安全的
任意两个多数派(quorum)必有交集,交集节点保留了历史信息,保证了已选中的值不会被覆盖。
8)Paxos 的 Liveness 问题
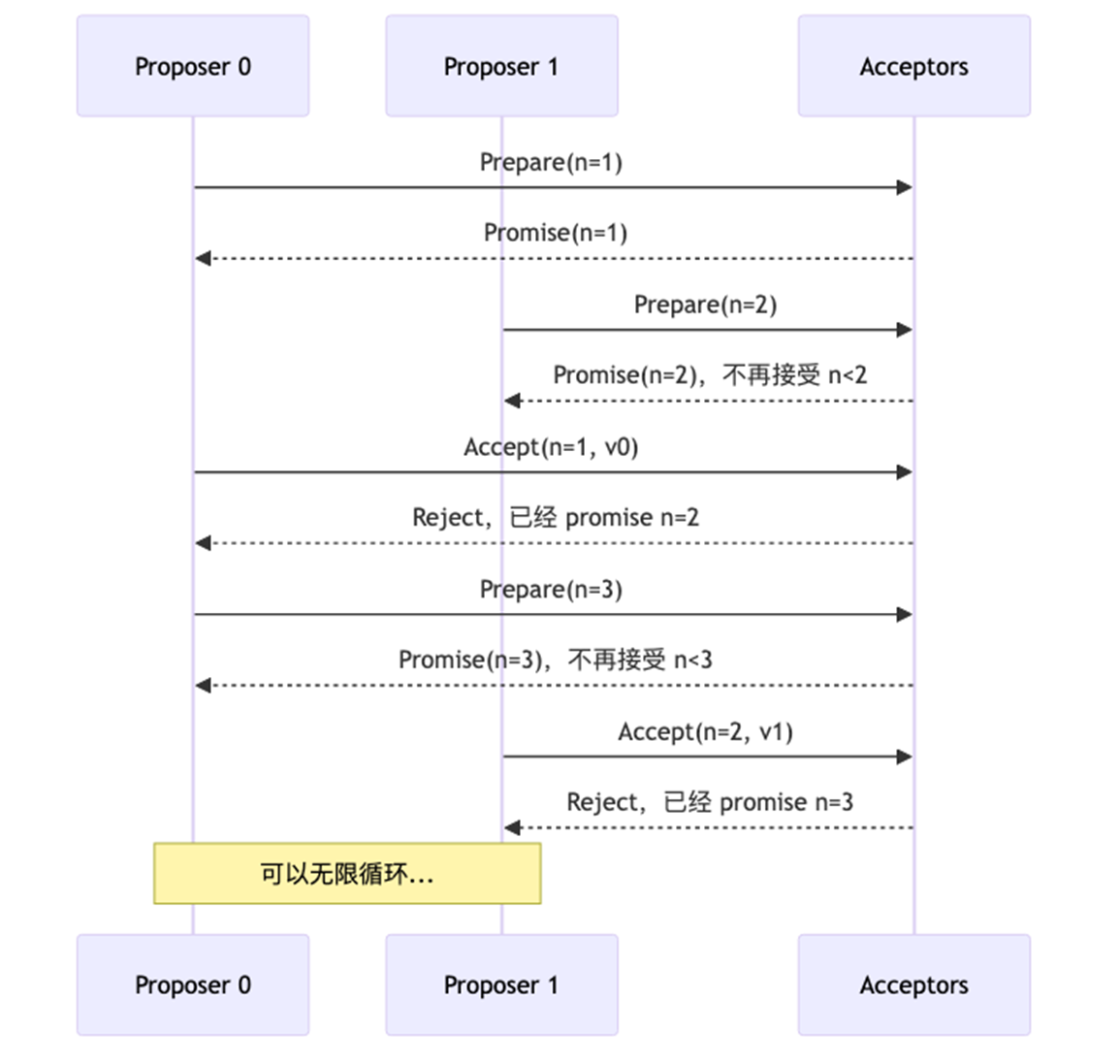
两个 proposer 互相抢,不断用更高编号的 prepare 使对方失效。永远达不成共识。
常见解法 :选出一个 distinguished proposer(leader),尽量只让它提案。
这就是为什么 Raft 要引入明确的 Leader 选举机制。
9)Paxos 决定的是 value
Paxos 本身不关心 value 代表什么。只保证"大家投出同一个结果"
10)从 Value 到操作顺序
实际复制系统里,最重要的是操作顺序。
每个位置都需要大家达成一致。把这些位置串起来,就是 replicated log。
6、Basic Paxos 到 Multi-Paxos
Basic Paxos的问题:每决定一个位置,都跑完整 Phase 1 + Phase 2。
导致代价太高。
如何解决?
找一个稳定的 Leader
-
leader 先用一个足够大的编号拿到多数派 promise
-
这个 promise 覆盖后续一段时间的提案
-
只要 leader 稳定,后续操作可以直接走 Phase 2
7、Leader 挂了怎么办
多数派来解决
新 leader 必须知道:
-
哪些操作已经不能丢
-
哪些操作还不能算提交
-
新操作应该接在谁后面
Leader 排序,多数派确认。
8、Multi-Paxos:稳定时只走 Accept
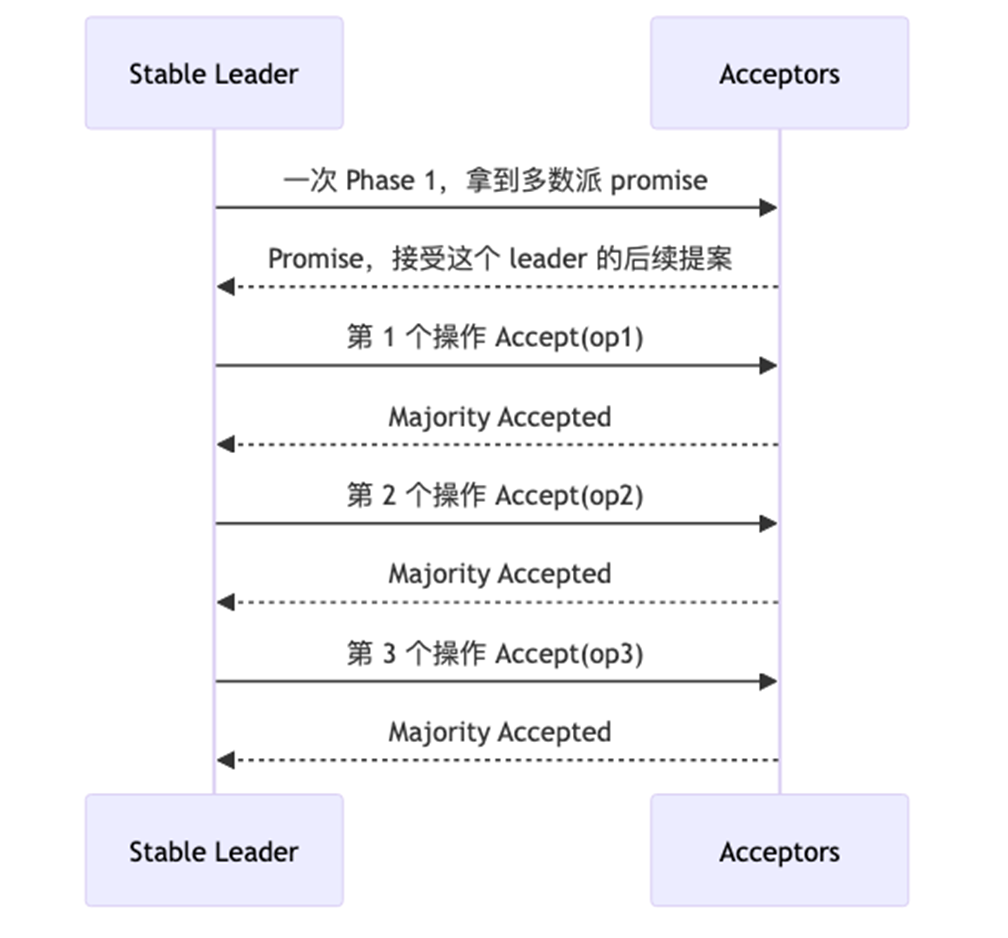
Basic Paxos(每个位置都两轮):prepare ------ accept
位置1: Prepare → Accept
位置2: Prepare → Accept
位置3: Prepare → Accept
Multi-Paxos(稳定时只走 Accept)
位置1: Prepare → Accept(建立 leader)
位置2: Accept(直接用 leader 权限)
位置3: Accept(直接用 leader 权限)
9、Multi-Paxos 什么时候还要 Phase 1?
-
leader 崩溃
-
网络分区后出现新 leader
-
新 leader 不知道旧 leader 已经复制了哪些操作
10、Multi-Paxos 与 Raft
Raft 本质上就是把 Multi-Paxos 拆分得更清晰:
-
Leader Election:用更明确的方式选出 leader
-
Log Replication:leader 决定顺序,多数派确认
| Multi-Paxos | Raft | |
|---|---|---|
| Leader Election | 隐含在 Phase 1 中 | 独立的 RequestVote RPC |
| Log Replication | Phase 2(Accept) | AppendEntries RPC |
| 可理解性 | 较难理解 | 拆分清晰,更易懂 |
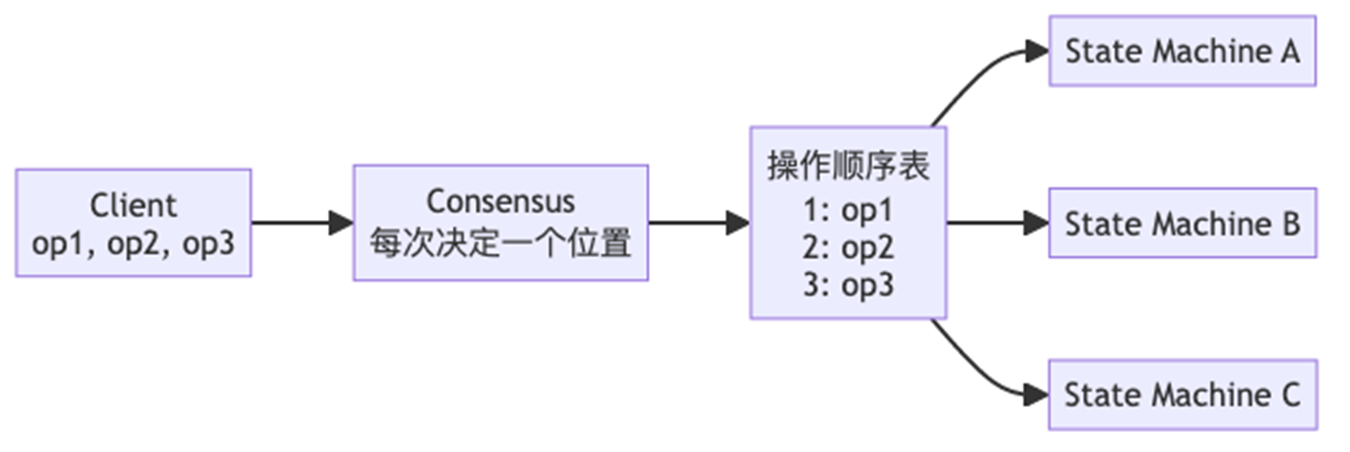
11、State Machine Replication(状态机复制)
所有节点执行相同的操作序列,从相同初始状态出发。操作是确定性的 → 所有节点最终状态相同。
Replicated log = 所有节点共同认可的操作顺序表。
四、总结
1、广播协议谱系:best-effort → reliable → FIFO → causal → total order(弱到强)
| 广播类型 | 一句话解释 |
|---|---|
| Best-Effort | 发了就不管,丢了就丢了 |
| Reliable | 保证所有人都能收到 |
| FIFO | 同一个人发的消息顺序不乱 |
| Causal | 有因果关系的消息顺序不乱 |
| Total Order | 所有人看到的顺序完全一样 |
2、每种广播对应 primary-backup 的一个具体需求
| 广播类型 | 解决 Primary-Backup 的什么问题 |
|---|---|
| Reliable | 备份节点不能丢数据 |
| FIFO | 同一个 Primary 发的操作顺序不乱 |
| Total Order | 所有 Backup 按相同顺序执行 → 状态一致 |
最核心的需求是 Total Order Broadcast:所有 Backup 必须按相同顺序执行操作,否则状态会不一致。
3、Total order broadcast ≡ Consensus(形式等价)
4、Consensus 三条性质:termination、agreement、validity
| 性质 | 含义 | 类型 | 类比 |
|---|---|---|---|
| Agreement | 所有人都选同一个值 | Safety | 不能选出两个 leader |
| Validity | 选的值必须是有人提议过的 | Safety | 不能凭空选一个不存在的人 |
| Termination | 最终一定能选出值 | Liveness | 不能永远吵不完 |
5、FLP:纯异步系统中 consensus 无法保证终止;实践用部分同步解决
FLP 卡住的是 Liveness(最终完成),不是 Safety(不出错)。
6、Paxos 两阶段:prepare 探测历史并拿 promise,accept 把值写入多数派
| 阶段 | 做什么 | 为什么 |
|---|---|---|
| Prepare | 问多数派:之前接受过什么? | 不能覆盖已选中的值 |
| Accept | 把值写入多数派 | 让值被正式选定(Chosen) |
先问后写------先问历史,再写多数派。
7、Multi-Paxos:稳定 leader 期间复用 Phase 1 的结果,后续操作直接复制
| Basic Paxos | Multi-Paxos |
|---|---|
| 每个位置都跑 Prepare + Accept | 只跑一次 Prepare,后续直接 Accept |
| 慢 | 快 |
8、Raft:用更清晰的 leader election + log replication 实现 replicated log
| Raft 模块 | 对应 Paxos 的什么 |
|---|---|
| Leader Election | Paxos Phase 1(选谁做主) |
| Log Replication | Paxos Phase 2(复制操作) |
Raft = Multi-Paxos 的工程化版本,把 Paxos 拆成更易懂的模块。