笔记摘自:黄佳老师的极客。
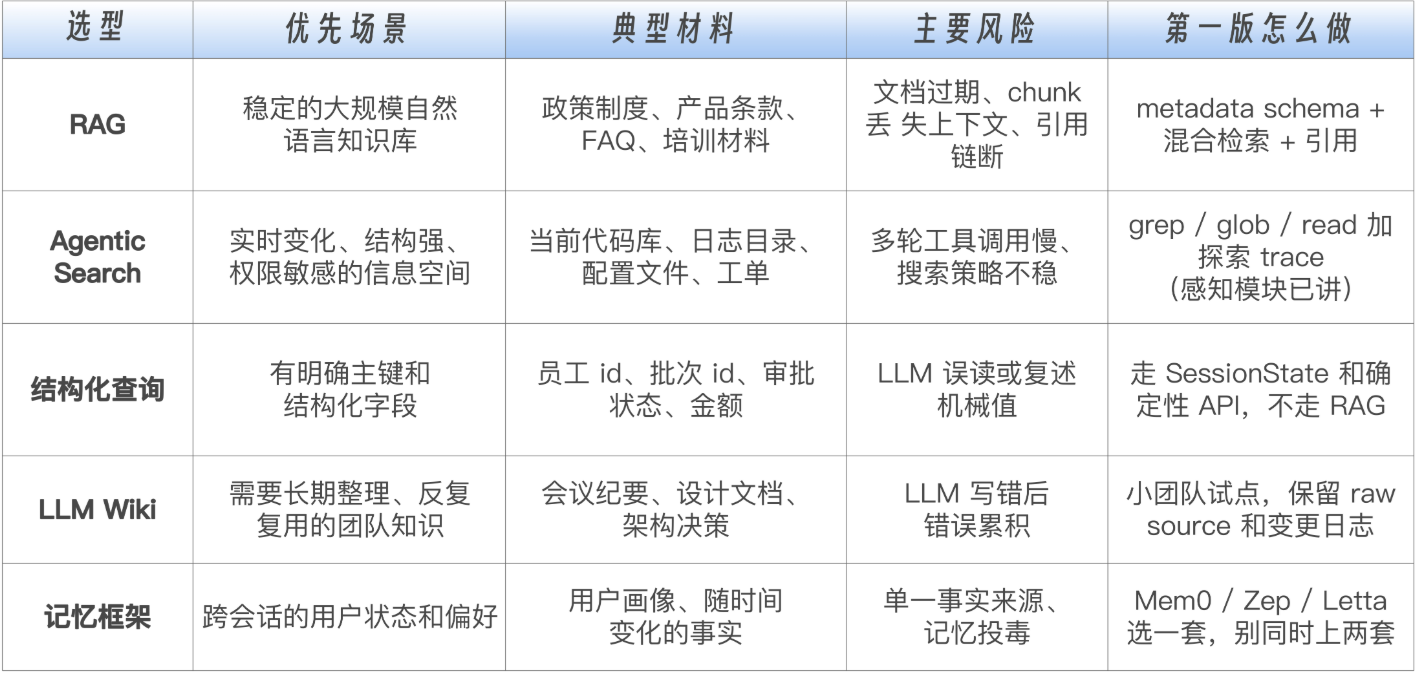
RAG 要解决的问题:公司制度、产品条款、历史政策、FAQ、培训材料、合同模板、研发文档,体量动辄几千份文档、几十万个片段。这些东西不可能常驻上下文窗口,只能在需要时取回来。
区别
步骤
第一步,先做知识源登记。
每份文档进入系统时,不要只给一个文件名。至少要有稳定的 doc_id、source_uri、owner、permission_scope、effective_from、effective_to、source_hash 和 document_status。这些字段看起来像后台管理,但后面会决定 RAG 能不能正确过滤版本、权限和过期材料。
第二步,做可复现的切块。
chunk 不能只靠"今天脚本怎么切就怎么切"。更好的做法是把 parser_version、chunker_version、chunk_index、text_hash 都记录下来,让 chunk_id 能稳定生成。
第三步,建立 ingestion manifest。
manifest 的读者通常是工程团队和运维系统,包含当前版本索引的构建参数。
raw_docs:
- payroll-bonus-policy-2026-v2.pdf
index_manifest:
corpus_version: payroll-policy-2026-06-14
parser_version: pdf-parser-2.4
chunker_version: clause-aware-v2
embedding_model: bge-m3
embedding_dim: 1024
hybrid_index_version: bm25-cn-v1+dense-v3
collection: payroll_rag_20260614_candidate
alias_after_release: payroll_rag_current
source_count: 1842
chunk_count: 53218
golden_set_passed: false上面的列表示例记录了一版索引的全部构建参数:corpus 版本、解析器版本、切块器版本、embedding 模型和维度、混合索引版本、collection 名、源文档数、chunk 数。LlamaIndex 的 ingestion pipeline 会通过 docstore,用 doc_id -> document_hash 的映射判断文档是否变化,hash 变了才重处理,没变就跳过。这也是索引版本控制的起点。
第四步,做候选索引和灰度发布。
不要在生产 collection 里直接重建索引。更稳的做法,是先生成一个候选索引,比如 payroll_rag_20260614_candidate,再用一组 golden questions 做回归测试。这里的 golden questions,不是普通测试用例,而是业务上最容易出错、最需要稳定召回的关键问题。你要检查它们的召回结果是否命中了正确证据,引用是否能追到原文,权限过滤是否生效,过期文档有没有被排除。
第五步,用别名或线上指针做蓝绿切换。
通过回归测试以后,也不要让业务代码直接绑定某个具体 collection。更好的做法,是让应用侧始终访问一个稳定别名,比如 payroll_rag_current。底层可以从旧 collection 切到新 collection,但业务代码不需要知道具体切到哪一版。这和传统软件里的蓝绿部署很像。旧索引是 blue,新索引是 green。新索引先在旁边构建、验证、灰度,通过以后再把 alias 或 current pointer 指过去。Milvus 的 collection alias 就是这类思路的典型工具:应用访问稳定别名,底层 collection 可以动态切换,用于数据更新、A/B 测试和生产环境的平滑发布。LanceDB 则进一步强调版本化写入和 time-travel,让索引可以回到历史版本。这样的索引不再是一坨"建好就放那儿"的向量,而是一份可以发布、灰度、切换、回滚的软件资产。
第六步,处理删除、退休、备份和回滚。
索引发布以后,还要认真处理它的下线和恢复机制。很多 RAG 事故看起来像"新文档没生效",根子却是旧文档还在回答问题。被替换的薪酬规则、废止的审批口径、权限收紧的内部材料,不能继续躺在索引里参与召回。要么从索引中删除,要么用 status、effective_to、permission_scope 这类字段严格过滤,默认不让它进入当前任务的证据集合。