一、引言
Flink 作为主流的流计算引擎,与 Kafka 的集成是最常见的架构模式。
Flink Kafka Connector 承担了数据摄入(Source)与数据输出(Sink)的核心职责,其内部机制涉及分区发现、偏移量管理、精确一次语义保障等关键环节。
本文将深入剖析 Connector 的内部原理,详解关键配置项,并结合生产实践给出调优建议。
二、Connector原理详解
1.整体架构
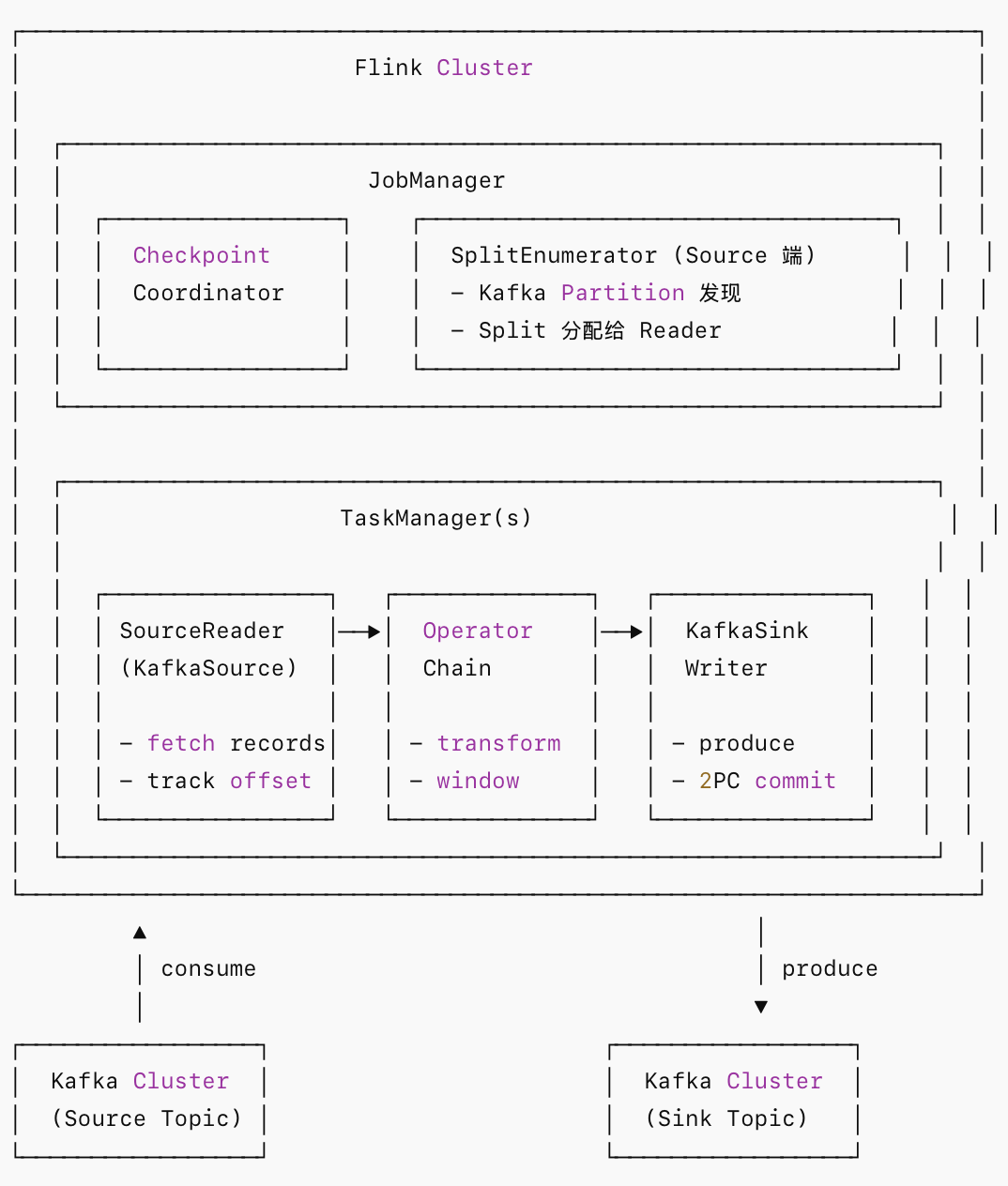
核心组件说明:
- SplitEnumerator:运行在 JobManager,负责发现 Kafka 分区并将其作为 Split 分配给各 SourceReader
- SourceReader:运行在 TaskManager,实际执行 Kafka 消费逻辑
- KafkaSink Writer:负责将记录写入 Kafka,配合 Committer 实现事务提交
2.Source 端原理详解
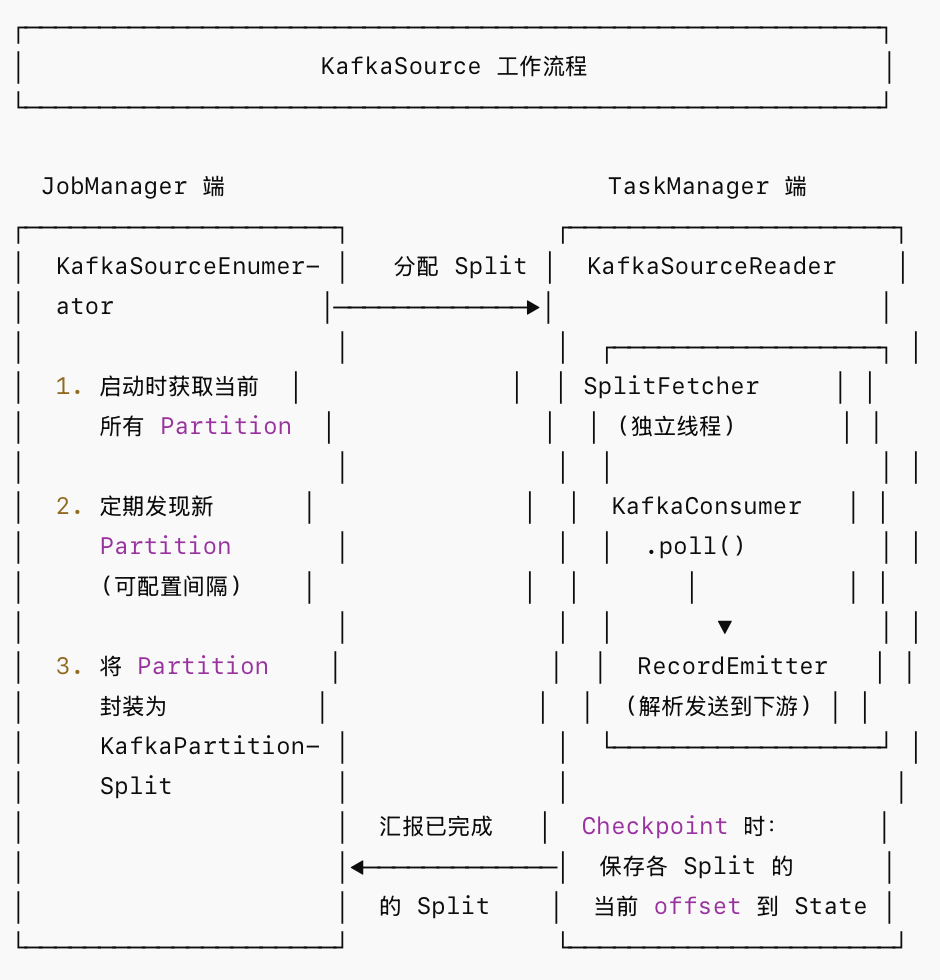
分区发现(Partition Discovery):
- Enumerator 启动时通过 Kafka AdminClient 获取订阅 Topic 的所有 Partition
- 可配置定期发现间隔(partition.discovery.interval.ms),支持运行时动态发现新增分区
- 新发现的分区根据策略分配给负载最轻的 Reader
偏移量管理(Offset Management):
- 偏移量保存在 Flink 的 State 中(而非依赖 Kafka 的 __consumer_offsets)
- Checkpoint 成功后,可选择性地将 offset 提交回 Kafka(仅用于监控,非恢复依据)
- 起始消费位置支持:earliest、latest、timestamp、specific-offsets、committed-offsets
数据读取:
-
每个 SourceReader 内部维护一个 KafkaConsumer 实例
-
通过 SplitFetcher 线程调用 poll() 拉取数据
-
拉取的记录通过 RecordEmitter 反序列化后发往下游
KafkaSource
source = KafkaSource. builder()
.setBootstrapServers("broker1:9092,broker2:9092")
.setTopics("input-topic")
.setGroupId("flink-consumer-group")
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class))
.setProperty("partition.discovery.interval.ms", "30000")
.build();DataStream
stream = env.fromSource(
source,
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5)),
"Kafka Source"
);
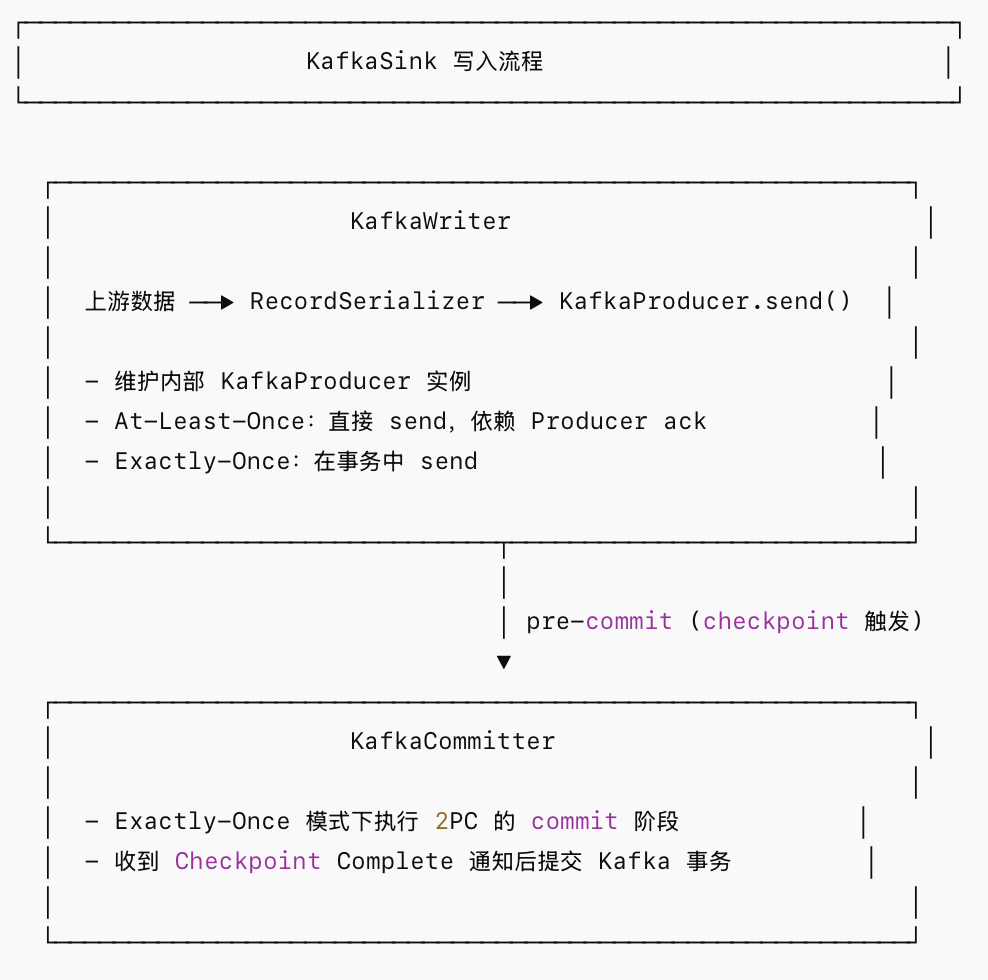
3.Sink 端原理详解
|---------------|-------------------------------|-------------|-------|
| 语义 | 实现方式 | 性能 | 数据保障 |
| At-Least-Once | acks=all + Checkpoint 恢复后可能重发 | 高 | 可能有重复 |
| Exactly-Once | Kafka 事务 + 两阶段提交(2PC) | 较低(受事务开销影响) | 精确一次 |
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("broker1:9092,broker2:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic("output-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("flink-sink-txn")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, "900000")
.build();
stream.sinkTo(sink);4.精确一次语义(Exactly-Once)实现机制
两阶段提交(2PC)流程:
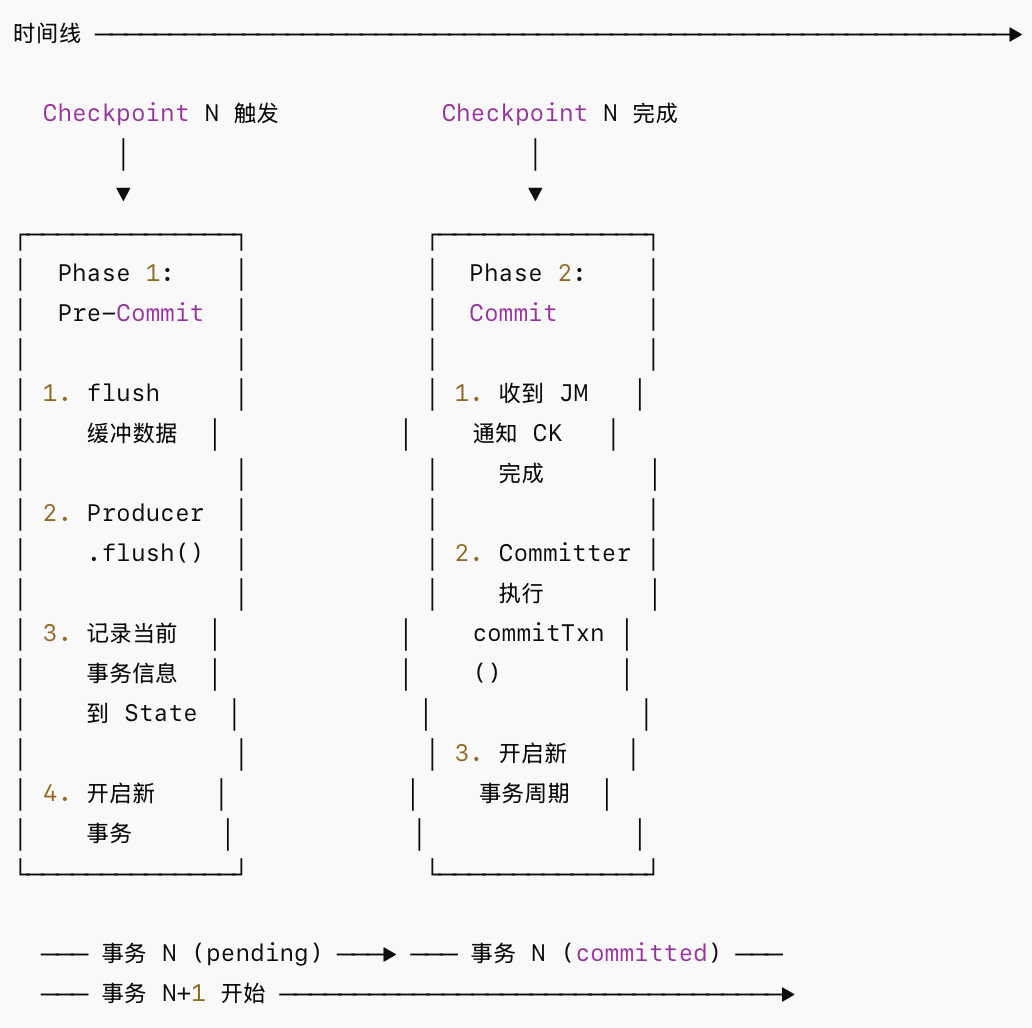
- transaction.timeout.ms 必须大于 Checkpoint 间隔:否则事务超时被 Kafka Broker abort,导致数据丢失
- Broker 端 transaction.max.timeout.ms 限制:默认 15 分钟,Flink 设置的事务超时不能超过此值
- 下游消费者需设置 isolation.level=read_committed:否则会读到未提交的事务数据
三、核心配置详解
1.Source 端关键配置
|---------------------------------|---------|-----------------------------------------|
| 配置项 | 默认值 | 说明 |
| partition.discovery.interval.ms | 不开启(-1) | 动态分区发现间隔。生产建议设为 30000~60000ms |
| register.consumer.metrics | true | 是否注册 Kafka Consumer 指标到 Flink Metrics |
| commit.offsets.on.checkpoint | true | Checkpoint 成功后是否提交 offset 到 Kafka(仅监控用) |
| fetch.min.bytes(Kafka 原生) | 1 | 最小拉取字节数,增大可减少请求频率 |
| fetch.max.wait.ms(Kafka 原生) | 500 | 配合 fetch.min.bytes,控制拉取等待时间 |
| max.poll.records(Kafka 原生) | 500 | 单次 poll 最大记录数 |
2.Sink 端关键配置
|-------------------------|---------------|----------------------------------------------------------------|
| 配置项 | 默认值 | 说明 |
| delivery.guarantee | AT_LEAST_ONCE | 投递语义:NONE / AT_LEAST_ONCE / EXACTLY_ONCE |
| transactional.id.prefix | --- | Exactly-Once 必填,事务 ID 前缀 |
| transaction.timeout.ms | 3600000(1h) | 事务超时,需 > Checkpoint 间隔,< Broker 的 transaction.max.timeout.ms |
| acks(Kafka 原生) | -1 (all) | Exactly-Once 时强制为 all |
| batch.size(Kafka 原生) | 16384 | Producer 批次大小,影响吞吐 |
| linger.ms(Kafka 原生) | 0 | 发送延迟,增大可提升批次效率 |
| buffer.memory(Kafka 原生) | 33554432 | Producer 缓冲区大小 |
3.Checkpoint 相关配置(影响端到端语义)
env.enableCheckpointing(60000); // 60s 间隔
env.getCheckpointConfig().setCheckpointTimeout(120000); // 超时 120s
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000); // 最小间隔 30s
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // Exactly-Once 需要设为 1
env.getCheckpointConfig().setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);四、生产最佳实践
1.容量规划与并行度设置
推荐原则:Source 并行度 ≤ Kafka 分区数
┌─────────────────────────────────────────────────────────┐
│ Kafka Topic: 12 Partitions │
│ │
│ P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11 │
│ │ │ │ │ │ │ │ │ │ │ │ │ │
│ └───┼───┘ └───┼───┘ └───┼───┘ └───┼────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ Reader0 Reader1 Reader2 Reader3 │
│ (P0,P1,P2) (P3,P4,P5) (P6,P7,P8) (P9,P10,P11) │
│ │
│ Source 并行度 = 4 │
└─────────────────────────────────────────────────────────┘- Source 并行度超过分区数时,多余的 Reader 空闲浪费资源
- 建议 Source 并行度为分区数的因子(整除关系),确保负载均匀
2.吞吐调优
// Source 端:增大单次拉取量
sourceProperties.setProperty("fetch.min.bytes", "1048576"); // 1MB
sourceProperties.setProperty("fetch.max.wait.ms", "500");
sourceProperties.setProperty("max.poll.records", "2000");
// Sink 端:增大批次与延迟
sinkProperties.setProperty("batch.size", "65536"); // 64KB
sinkProperties.setProperty("linger.ms", "50"); // 50ms 聚批
sinkProperties.setProperty("buffer.memory", "67108864"); // 64MB
sinkProperties.setProperty("compression.type", "lz4"); // 压缩3.Exactly-Once 最佳配置模板
// 1. Checkpoint 配置
env.enableCheckpointing(60_000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(180_000L);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30_000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 2. Sink 配置
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("myapp-sink")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, "600000") // 10min
.setProperty(ProducerConfig.ACKS_CONFIG, "all")
.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")
.setRecordSerializer(...)
.build();
// 3. Broker 端需确认
// transaction.max.timeout.ms >= 600000 (需运维确认)4.常用监控指标
|-------------------------------------------------|-----------------|----------------|
| 指标 | 含义 | 告警建议 |
| KafkaSourceReader.KafkaConsumer.records-lag-max | 最大消费延迟(条数) | 持续增长需扩容 |
| KafkaSourceReader.KafkaConsumer.fetch-rate | 拉取速率 | 骤降可能有网络问题 |
| numRecordsOutPerSecond | Sink 输出 TPS | 监控写入能力 |
| numberOfFailedCheckpoints | Checkpoint 失败次数 | > 0 需排查 |
| lastCheckpointDuration | 上次 CK 耗时 | 接近 timeout 需关注 |
5.常见问题与排查
|-------------------------|-----------------------------|-----------------------------------------------|
| 问题现象 | 可能原因 | 排查方向 |
| 消费延迟持续增大 | 并行度不足 / 下游算子反压 | 检查 backpressure 指标,扩并行度或优化处理逻辑 |
| Checkpoint 超时失败 | Source 端数据量过大,barrier 对齐时间长 | 开启 Unaligned Checkpoint 或增大 timeout |
| Exactly-Once 下数据丢失 | 事务超时被 abort | 检查 transaction.timeout.ms 与 Broker 端配置 |
| ProducerFencedException | transactional.id 冲突 | 确保 prefix 唯一,避免多 Job 共用 |
| 新增分区未被消费 | 未启用动态分区发现 | 设置 partition.discovery.interval.ms |
| Topic 不存在导致启动失败 | 自动创建未开启 | Broker 端 auto.create.topics.enable 或提前建 Topic |