前面的章节系统梳理了基于低代码平台的智能体应用开发,而智能体的核心载体 ------ 大语言模型、计算机视觉、语音交互等能力,本质上都建立在深度学习的技术基础之上。深度学习是机器学习的核心分支,机器学习则是当前人工智能最主流的实现路径。从本篇开始,我们进入机器学习技术体系的学习,从基础概念入手,逐步深入算法原理与工程实现。
本篇作为机器学习系列的开篇,将系统梳理领域内的核心概念、技术边界、标准建模流程与算法分类,搭建完整的知识框架,为后续深入具体算法打下基础。
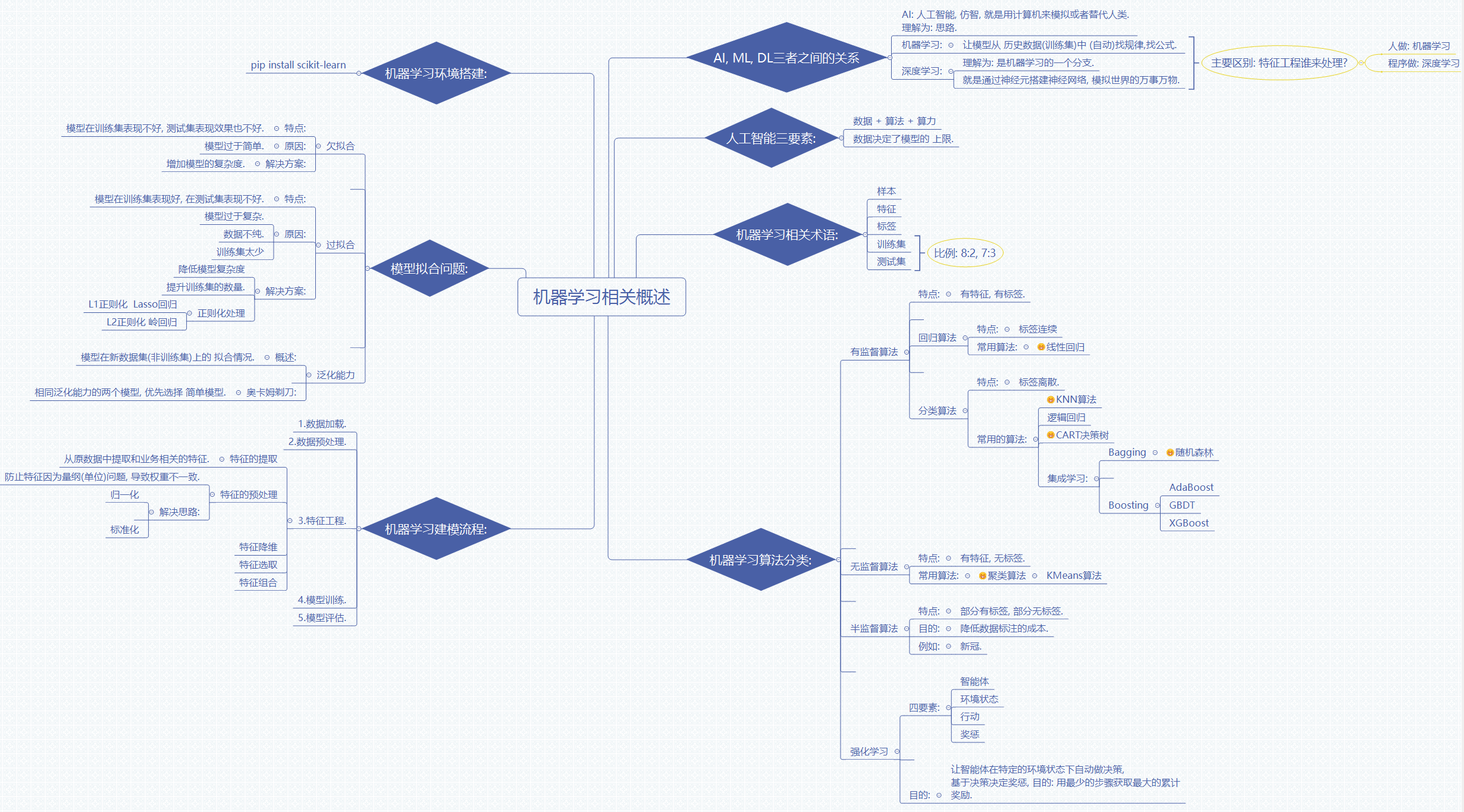
一、AI、ML、DL 的层级关系
人工智能(Artificial Intelligence,AI)是最宽泛的技术范畴,目标是利用计算机模拟或替代人类的智能行为,涵盖感知、推理、决策、生成等各类能力。其实现路径并不唯一,早期的专家系统、规则引擎都属于人工智能的实现方式,机器学习只是其中的一个主流分支。
机器学习(Machine Learning,ML)是人工智能的核心实现路径,核心逻辑是让模型从历史数据中自动学习规律,而非依赖人工编写固定的业务规则。模型的性能上限由数据质量决定,算法的作用是尽可能逼近这个上限。
深度学习(Deep Learning,DL)是机器学习的子领域,以深度神经网络为核心载体,通过多层神经元搭建的网络结构模拟人脑的信息处理机制,能够自动从原始数据中提取分层特征,实现对复杂模式的拟合。
三者最核心的差异体现在特征处理环节:
- 传统机器学习依赖人工完成特征工程,需要领域专家设计并提取有效特征,再输入模型完成训练;
- 深度学习能够端到端地自动完成特征提取与模式学习,无需人工设计特征,更适合处理图像、语音、文本等高维非结构化数据。
二、人工智能的核心三要素
人工智能系统的能力由数据、算法、算力三个核心要素共同决定,三者相辅相成,缺一不可。
2.1 数据
数据是模型学习的原料,决定了模型能力的上限。高质量、大规模、分布合理的数据集,是训练出优秀模型的前提。如果数据存在标注错误、分布偏移、样本缺失等问题,再优秀的算法也无法产出理想的效果。
2.2 算法
算法是模型学习的具体方法,决定了模型逼近数据上限的效率与程度。不同的算法适用于不同的数据形态与业务场景,从经典的线性回归、决策树,到复杂的深度神经网络,各自有其适用边界与优劣势。
2.3 算力
算力是模型训练与推理的硬件基础。尤其是深度学习模型,训练过程需要大量的矩阵运算,高度依赖 GPU 等并行计算硬件。算力的提升,是深度学习能够从理论走向大规模落地的重要硬件支撑。
三、机器学习核心术语
3.1 基础数据概念
- 样本:单条独立的数据记录,是数据集的最小组成单元。
- 特征:描述样本属性的变量,是模型输入的核心内容,也称为自变量。特征的质量直接影响模型最终效果。
- 标签:样本对应的目标结果,是模型需要学习与预测的对象,也称为因变量。
3.2 数据集划分
模型训练过程中,通常将全量数据集按比例划分为两部分,常见划分比例为 8:2 或 7:3:
- 训练集:用于模型参数学习的数据集,占全量数据的主体。模型通过在训练集上的迭代优化,逐步拟合数据规律。
- 测试集:用于评估模型泛化能力的数据集,在训练全程不参与模型参数更新,用于模拟真实场景下的未知数据,客观衡量模型的实际表现。
四、模型拟合问题
拟合是指模型学习数据规律的过程。根据学习程度的不同,会出现欠拟合与过拟合两类典型问题,是模型优化过程中最核心的调试方向。
4.1 欠拟合
表现:模型在训练集上表现不佳,在测试集上表现同样不佳,整体预测精度偏低。对应高偏差的特性。
核心原因:模型容量不足,表达能力有限,无法捕捉数据中的基本规律。常见于用简单线性模型拟合非线性关系的场景。
解决方案:提升模型复杂度,例如选用表达能力更强的算法、增加模型参数规模、扩充有效特征维度等。
4.2 过拟合
表现:模型在训练集上表现非常优异,但在测试集上表现大幅下降,模型泛化能力差。对应高方差的特性。
核心原因:模型过于复杂,不仅学习到了数据的通用规律,还拟合了训练集中的噪声与偶然特征,导致对未知数据的适配能力下降。常见诱因包括训练样本量不足、数据纯度低、模型复杂度过高等。
解决方案:
- 降低模型复杂度,简化模型结构;
- 增加训练样本数量,提升数据多样性;
- 引入正则化约束,限制模型参数的规模。
正则化是缓解过拟合的通用手段,主流分为两类:
- L1 正则化(对应 Lasso 回归):对参数的绝对值之和施加惩罚,会使得部分参数收敛为 0,兼具特征选择的效果;
- L2 正则化(对应岭回归):对参数的平方和施加惩罚,会均匀压缩所有参数的大小,避免单个参数权重过高,是工业界更常用的正则化方式。
4.3 泛化能力与选型原则
泛化能力是衡量模型在未见过的新数据集上的拟合效果,是评估模型实用价值的核心指标。机器学习的核心目标就是提升模型的泛化能力,而非在训练集上追求极致精度。
奥卡姆剃刀原则是模型选型的重要指导思想:在泛化能力相近的多个模型中,优先选择结构更简单的模型。简单模型通常具备更好的可解释性与鲁棒性,在真实生产环境中的稳定性更强。
五、机器学习标准建模流程
一个完整的机器学习项目遵循标准化的执行流程,可分为五个核心阶段。
5.1 数据加载
读取原始数据集,完成数据的初步读取与格式转换,为后续处理提供基础数据输入。
5.2 数据预处理
对原始数据做清洗与规整,处理缺失值、异常值、重复值,统一数据格式,修正数据分布问题,从源头保障数据质量。
5.3 特征工程
特征工程是传统机器学习项目中工作量占比最高的环节,直接决定模型效果的上限,主要包含三类工作:
- 特征提取:从原始数据中提取与业务目标相关的有效特征,将非结构化数据转化为模型可处理的结构化特征。
- 特征预处理:解决特征的量纲不一致问题,避免不同单位的特征权重失衡。常用方法包括:
- 归一化:将数据线性缩放到固定区间内,消除量纲影响;
- 标准化:将数据转换为均值为 0、标准差为 1 的标准分布,适配对数据分布有要求的算法。
- 特征优化:包含特征降维、特征筛选、特征组合等操作,在保留有效信息的前提下降低特征维度,提升训练效率与模型效果。
5.4 模型训练
选择适配业务场景的算法,将处理好的训练集数据输入模型,通过迭代优化调整模型参数,完成对数据规律的学习。
5.5 模型评估
使用独立的测试集评估训练完成的模型,从准确率、误差、召回率等多个维度衡量模型效果,判断是否满足业务要求。若效果不达标,则回溯到前面的环节做优化调整。
六、机器学习算法分类
根据学习方式与数据特点的不同,机器学习算法可分为四大类范式。
6.1 有监督学习
核心特点:训练数据同时包含特征与标签,模型学习从特征到标签的映射关系。是工业界应用最广泛的一类算法。
根据标签类型的不同,又分为两类任务:
- 回归任务:标签为连续数值,用于预测数值结果,典型代表为线性回归、逻辑回归。
- 分类任务:标签为离散类别,用于判断样本所属类别,常用算法包括 K 近邻、逻辑回归、CART 决策树等。
在此基础上,集成学习通过组合多个弱学习器获得更强的泛化能力,分为两大技术路线:
- Bagging 路线:并行训练多个独立基模型,通过投票或平均得到最终结果,代表算法为随机森林;
- Boosting 路线:串行迭代训练,每一轮重点学习上一轮预测错误的样本,逐步提升精度,代表算法包括 AdaBoost、GBDT、XGBoost。
6.2 无监督学习
核心特点:训练数据只有特征、没有标签,模型自主挖掘数据内在的结构与分布规律。
最典型的是聚类算法,根据样本的特征相似度自动划分类别,代表算法为 KMeans。无监督学习常用于数据探索、用户分群、异常检测等没有明确标注标签的场景。
6.3 半监督学习
核心特点:训练数据中部分有标签、部分无标签,通过少量标注数据引导模型学习方向,结合大量无标注数据提升模型效果。
其核心价值是降低数据标注成本,适合标注成本高昂、大量数据无标签的垂直领域,例如医学影像、工业缺陷检测等场景。
6.4 强化学习
核心机制:通过智能体与环境的交互完成学习,包含智能体、环境状态、行动、奖惩四个核心要素。智能体在特定环境状态下做出决策,环境根据决策结果给予奖励或惩罚,智能体通过不断迭代优化策略,目标是用最少的步骤获取最大的累计奖励。
强化学习适合序列决策类场景,例如游戏 AI、机器人控制、自动驾驶决策等领域。
七、逻辑图