基于深度学习的恶意流量检测平台 v3.0:从算法到攻防演练的完整实战
源码获取:https://mbd.pub/o/bread/YZaTmJ5pZA==
摘要:本文完整记录了一个面向网络安全方向的恶意流量检测平台的设计、实现与优化过程。平台采用 PyTorch 深度学习框架与传统机器学习相结合,集成 ICNN、LSTM、随机森林、逻辑回归四种模型,基于 CSE-CIC-IDS2018 数据集完成训练,并通过 PyQt5 构建可视化操作界面,支持离线文件检测、实时网卡流量捕获以及攻防演练评估。文章重点剖析 v3.0 版本在实时检测准确率、训练推理一致性以及攻防演练模块方面的关键改进,力求为网络安全相关毕业设计和技术实践提供一份可参考的完整方案。
一、前言
网络安全是数字化时代最重要的基础设施之一。随着云计算、物联网、5G 以及企业数字化转型的加速推进,网络流量规模呈指数级增长,攻击者的手段也日趋复杂。从早期简单的端口扫描、暴力破解,到如今高度组织化的 DDoS 攻击、加密恶意通信、APT 渗透,传统基于规则、签名或固定阈值的防御体系已经难以应对快速演变的威胁形态。
在这一背景下,利用机器学习与深度学习技术对网络流量进行智能化检测,成为学术界和工业界共同关注的研究方向。流量检测的核心思路并不复杂:从网络通信过程中提取能够反映行为模式的统计特征,再交由训练好的模型判断其属于正常流量还是某种已知攻击。然而,真正要将这一思路落地为一个可用的系统,需要跨越数据预处理、特征工程、模型选型、工程化部署、可视化交互以及持续优化等多个环节。
本文所要介绍的,正是一个从算法研究逐步演进到完整平台建设的项目。该项目最初起源于一次毕业设计选题,目标是实现一个能够检测多种网络攻击类型的流量分类系统。经过多个版本的迭代,目前已发展为具备离线检测、实时捕获、模型训练、批量分析、可视化展示以及攻防演练等功能的综合性平台。尤其是在 v3.0 版本中,项目针对实时检测误报率高、训练与推理特征不一致、模型加载管理混乱等实际问题进行了系统性的修复和增强,并新增了攻防演练模块,使得平台不仅能够完成静态样本检测,还可以模拟真实攻击场景对模型进行综合评估。
本文适合以下读者阅读:正在准备网络安全或人工智能方向毕业设计的同学、希望了解流量检测项目工程化过程的开发者、对 PyQt5 桌面应用开发以及 PyTorch 模型部署感兴趣的技术人员。文章将从项目背景、系统架构、数据集处理、算法模型、检测引擎、界面开发、实时检测优化、攻防演练、测试评估以及部署使用等方面进行详细讲解,力求做到理论与实践相结合、代码与原理相呼应。
二、网络安全形势与恶意流量检测挑战
2.1 当前网络攻击形势
近年来,全球网络安全事件频发,勒索软件、数据泄露、供应链攻击等威胁层出不穷。根据多家安全机构的年度报告,网络攻击的数量、复杂度和造成的经济损失都在持续上升。与此同时,加密流量的比例也在快速提高,超过九成的 Web 流量已经通过 HTTPS 传输。加密固然保护了用户隐私,但也给传统基于内容深度包检测(DPI)的安全设备带来了巨大挑战:攻击者可以轻易将恶意载荷隐藏在加密通道中,而安全设备无法直接解密 inspect 内容。
常见的网络攻击类型包括:
- DDoS 攻击:通过大量傀儡主机或工具向目标服务器发送海量请求,耗尽其带宽或计算资源,导致服务不可用。
- DoS 攻击:与 DDoS 类似,但通常由单一来源发起,利用协议缺陷或应用层漏洞造成拒绝服务。
- 端口扫描:攻击者扫描目标主机的开放端口,探测服务版本和潜在漏洞。
- 暴力破解:针对 SSH、FTP、Web 登录接口等,通过自动化工具尝试大量用户名和密码组合。
- Web 攻击:包括 SQL 注入、XSS 跨站脚本、暴力破解等针对 Web 应用的攻击。
- 僵尸网络与 C2 通信:感染主机与远程控制服务器建立通信,接收指令或外传数据。
- 心脏出血、渗透攻击:利用特定漏洞或社会工程学手段入侵内网。
这些攻击在流量层面会表现出不同的行为模式。例如,DDoS 攻击通常伴随极高的包速率、短连接、固定包长;暴力破解则表现为同一源 IP 对目标端口的大量短连接尝试;僵尸网络通信可能呈现周期性、低带宽但持续的特点。正是这些可观测的统计差异,为基于机器学习的检测提供了基础。
2.2 传统检测手段的局限
传统的入侵检测系统(IDS)和入侵防御系统(IPS)大多依赖规则库和特征签名。当检测到匹配已知攻击模式的流量时,系统发出告警或阻断连接。这种方案的优点是误报率低、可解释性强,但缺点也十分明显:
- 无法应对未知攻击:规则库只能识别已知攻击,对于变种、零日漏洞或新型攻击无能为力。
- 维护成本高:安全人员需要不断更新规则库,规则数量膨胀后还会影响检测性能。
- 对加密流量无效:无法解密内容时,基于签名的检测方法基本失效。
- 阈值难以调优:固定阈值容易在复杂网络环境中产生大量误报或漏报。
因此,基于行为模式学习的智能检测方法逐渐成为研究热点。机器学习模型可以从大量历史流量中自动学习正常与异常行为的边界,对未知攻击也具备一定的泛化能力。
2.3 恶意流量检测面临的核心挑战
尽管机器学习和深度学习为流量检测带来了新的思路,但在实际落地过程中仍面临多重挑战。
(1)数据不平衡问题
在真实网络环境中,正常流量通常占据绝大多数,而攻击流量相对较少。更严重的是,不同攻击类型之间的样本数量也极不均衡。例如 DDoS 攻击可能产生数百万条流记录,而 Heartbleed、Infiltration 等攻击的样本可能只有几千甚至几百条。这种不平衡会导致模型偏向于预测多数类,对少数攻击的检测能力显著下降。
(2)特征提取困难
对于加密流量,无法直接解析应用层内容,只能从包长、时间间隔、连接状态、标志位、窗口大小等元数据中提取统计特征。如何设计能够稳定区分正常与异常流量的特征集,是决定模型性能的关键。此外,实时捕获场景下,特征必须在流生命周期内动态计算,对计算效率和一致性提出了更高要求。
(3)实时性要求
网络流量数据量大、速度快,检测系统需要在秒级甚至毫秒级完成特征提取和模型推理。尤其是在生产环境中,高延迟的检测可能导致攻击已经发生但告警尚未触发的被动局面。因此,模型的推理速度、特征提取的效率以及系统的并发处理能力都需要精心设计。
(4)模型泛化能力
网络环境千差万别,不同企业、不同时间段的流量分布差异很大。在某一数据集上训练良好的模型,换到另一个环境中可能性能大幅下降。如何提升模型的鲁棒性和泛化能力,是学术研究和工程实践持续关注的问题。
2.4 机器学习方法的优势
面对上述挑战,机器学习和深度学习提供了系统性的解决思路:
- 自动特征学习:CNN 和 LSTM 等深度学习模型能够自动从原始特征中抽取高阶表示,减少对手工特征工程的依赖。
- 处理高维数据:流量特征维度较高,传统方法难以有效组合,而神经网络和集成学习模型在高维空间上表现更好。
- 适应复杂模式:LSTM 等时序模型可以捕捉流量随时间变化的行为模式,适合分析具有时序特性的攻击。
- 可扩展性强:模型训练和推理可以通过 GPU 加速,也可以根据需求选择轻量级模型部署在边缘设备上。
正是基于这些优势,本项目选择以深度学习为主、传统机器学习为辅的混合架构,构建一个完整的恶意流量检测平台。
三、项目总体架构设计
3.1 项目定位
本项目命名为"基于深度学习的恶意流量检测平台 v3.0",是一个面向网络安全学习与研究的桌面级应用系统。系统以 Python 为主要开发语言,基于 PyQt5 构建图形界面,后端集成多种机器学习与深度学习模型,支持对 CSV 格式流量数据的离线检测、对网卡流量的实时捕获检测,以及对多种攻击场景的攻防演练评估。
项目的设计目标包括:
- 多模型集成:同时支持 ICNN、LSTM、随机森林和逻辑回归四种模型,满足不同场景下的精度与速度需求。
- 可视化交互:提供友好的图形界面,降低非专业人员的使用门槛。
- 实时检测能力:能够从网卡实时捕获数据包并提取特征进行检测。
- 攻防演练支持:模拟真实攻击场景,评估各模型在不同攻击类型上的检测效果。
- 模块化设计:代码结构清晰,便于后续扩展新的模型、数据源或功能模块。
3.2 系统架构
系统采用经典的分层架构,自顶向下分为用户交互层、业务逻辑层、算法模型层和数据存储层。
┌─────────────────────────────────────────────────────────────┐
│ 用户交互层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌────────┐ │
│ │ 流量检测 │ │ 批量检测 │ │ 模型训练 │ │ 模型对比 │ │ 可视化 │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ └────────┘ │
│ ┌─────────┐ ┌─────────┐ │
│ │ 历史记录 │ │ 实时检测 │ │ 攻防演练 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 业务逻辑层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 检测引擎 │ │ 特征处理器 │ │ 训练管理器 │ │
│ │ DetectionEngine│ │FeatureExtractor│ │TrainingThread │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 算法模型层 │
│ ┌────────┐ ┌────────┐ ┌────────────┐ ┌────────────┐ │
│ │ ICNN │ │ LSTM │ │ 随机森林 │ │ 逻辑回归 │ │
│ └────────┘ └────────┘ └────────────┘ └────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 数据存储层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ CSV数据集 │ │ SQLite数据库 │ │ 模型文件 │ │
│ │CSE-CIC-IDS2018│ │detection.db │ │ .pth/.pkl │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘用户交互层负责与用户进行图形化交互,包含流量检测、批量检测、模型训练、模型对比、可视化分析、历史记录、实时检测和攻防演练八个主要 Tab 页面。所有耗时操作都通过多线程在后台执行,避免界面卡顿。
业务逻辑层是连接界面与模型的桥梁,核心组件包括:
DetectionEngine:统一管理所有模型的加载、预处理与推理。FeatureExtractor/RealtimeFeatureProcessor:负责从原始数据或实时流中提取 78 维特征。TrainingThread/DetectionThread:在独立线程中执行模型训练与检测任务。AttackSimulator/DrillThread:负责攻防演练场景的数据生成与模型评估。
算法模型层包含四种分类模型:
CNN/CNNWithAttention:一维卷积神经网络,用于提取局部特征。LSTMModel:长短期记忆网络,用于捕捉时序依赖。RandomForestClassifier:集成学习模型,速度快、可解释性强。LogisticRegression:线性基线模型,结构简单、推理最快。
数据存储层包括:
CSE-CIC-IDS2018/目录下的 CSV 数据集。detection_history.dbSQLite 数据库,保存检测历史记录。- 各模型目录下的
.pth、.pkl、.joblib模型文件以及scaler.pkl、label_encoder.pkl。
3.3 功能模块
系统共包含八个主要功能模块:
| 模块 | 功能描述 |
|---|---|
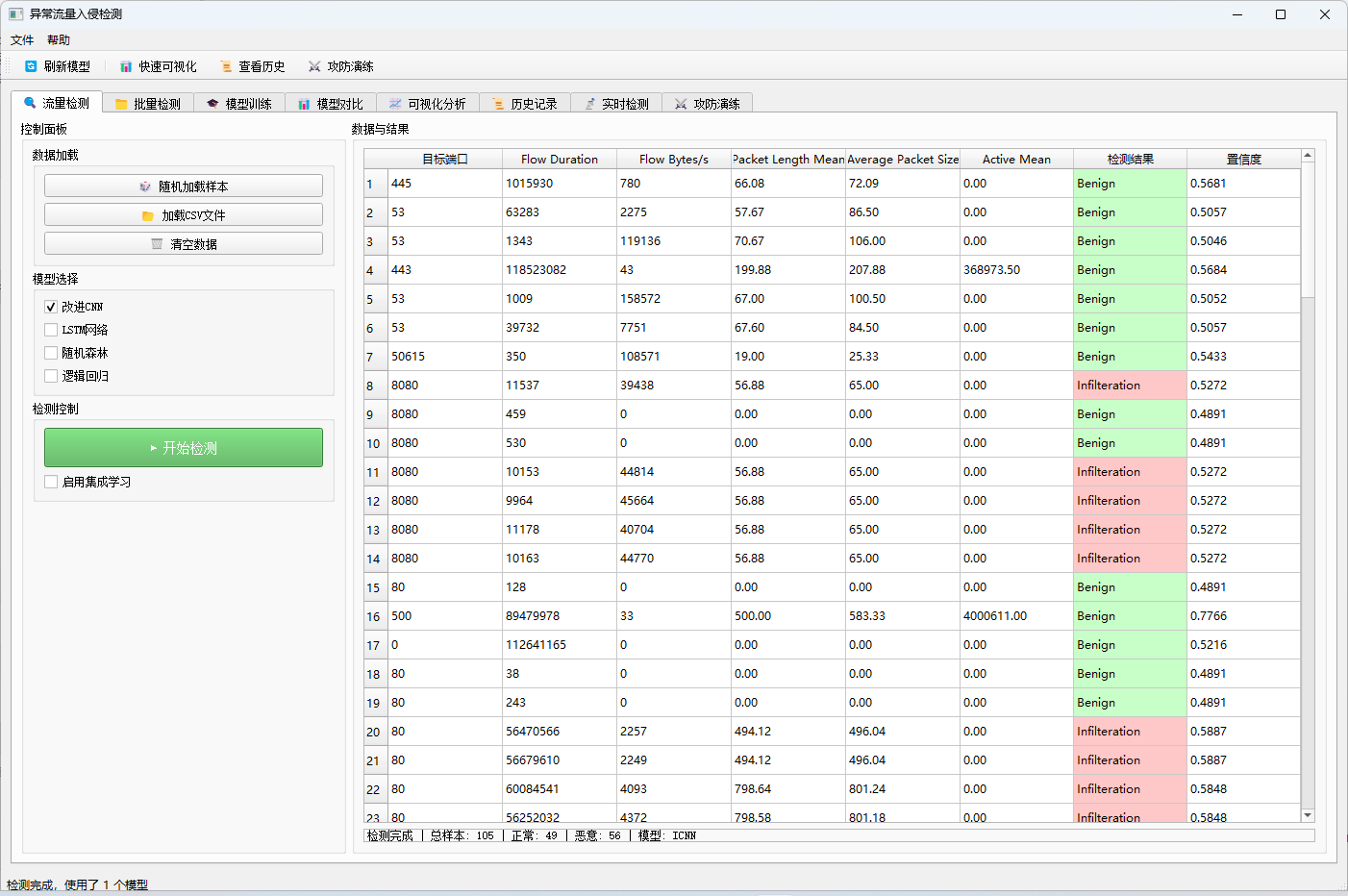
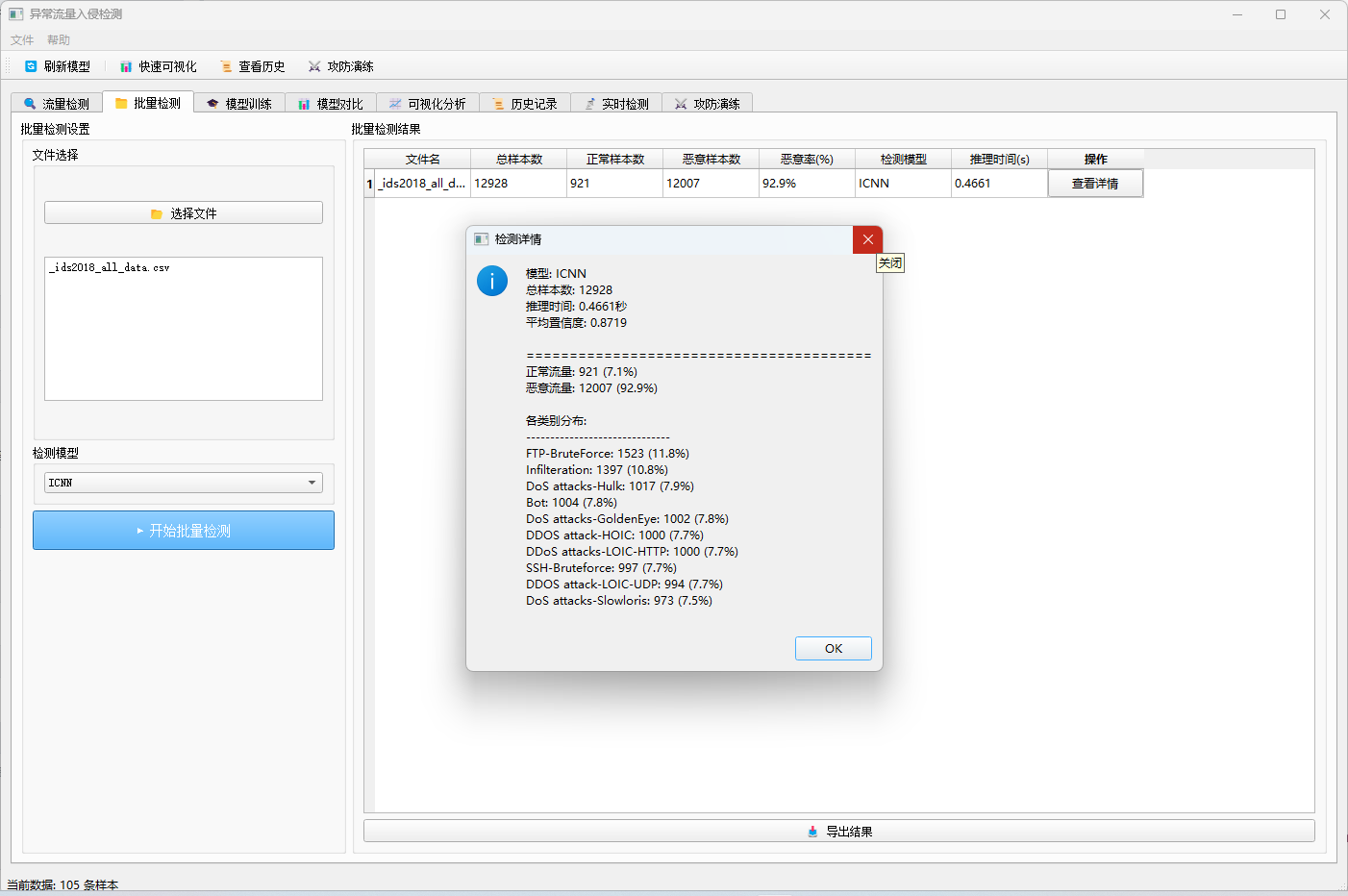
| 流量检测 | 加载单文件或随机样本,使用一个或多个模型进行检测 |
| 批量检测 | 同时处理多个 CSV 文件,汇总统计检测结果 |
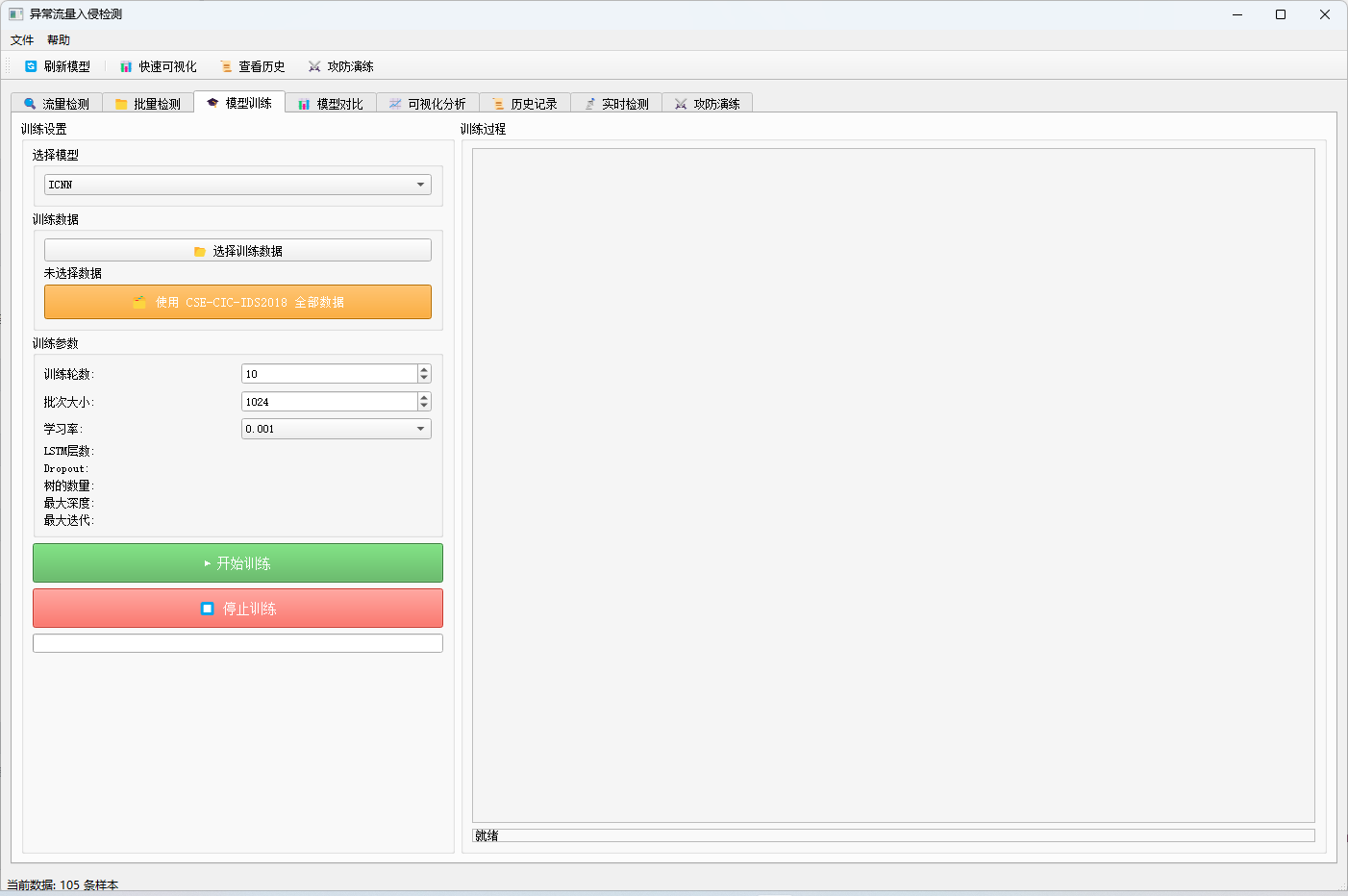
| 模型训练 | 在 GUI 中配置参数并训练 ICNN、LSTM、RF、LOG 模型 |
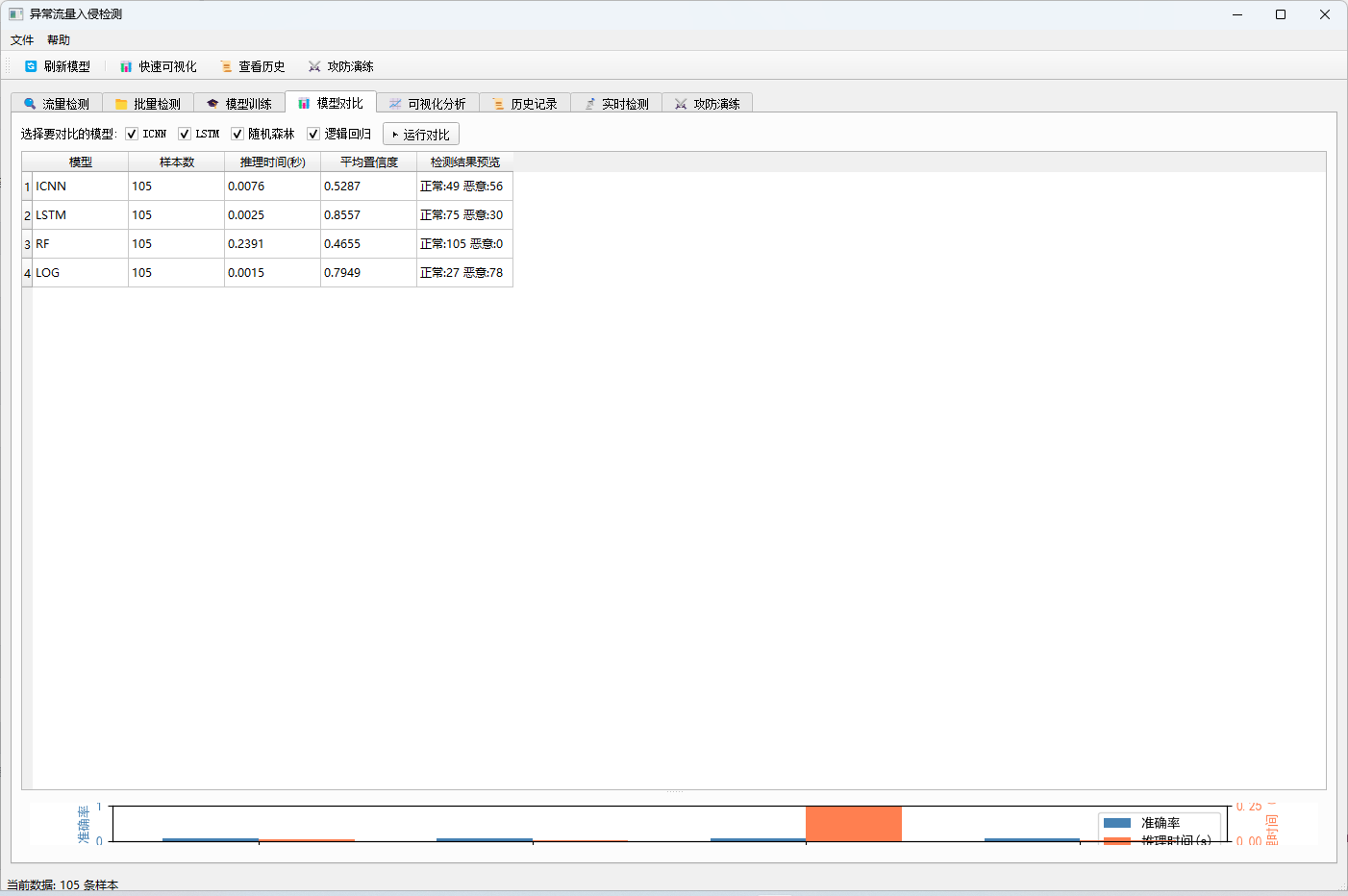
| 模型对比 | 使用同一批数据对比多个模型的推理时间和检测效果 |
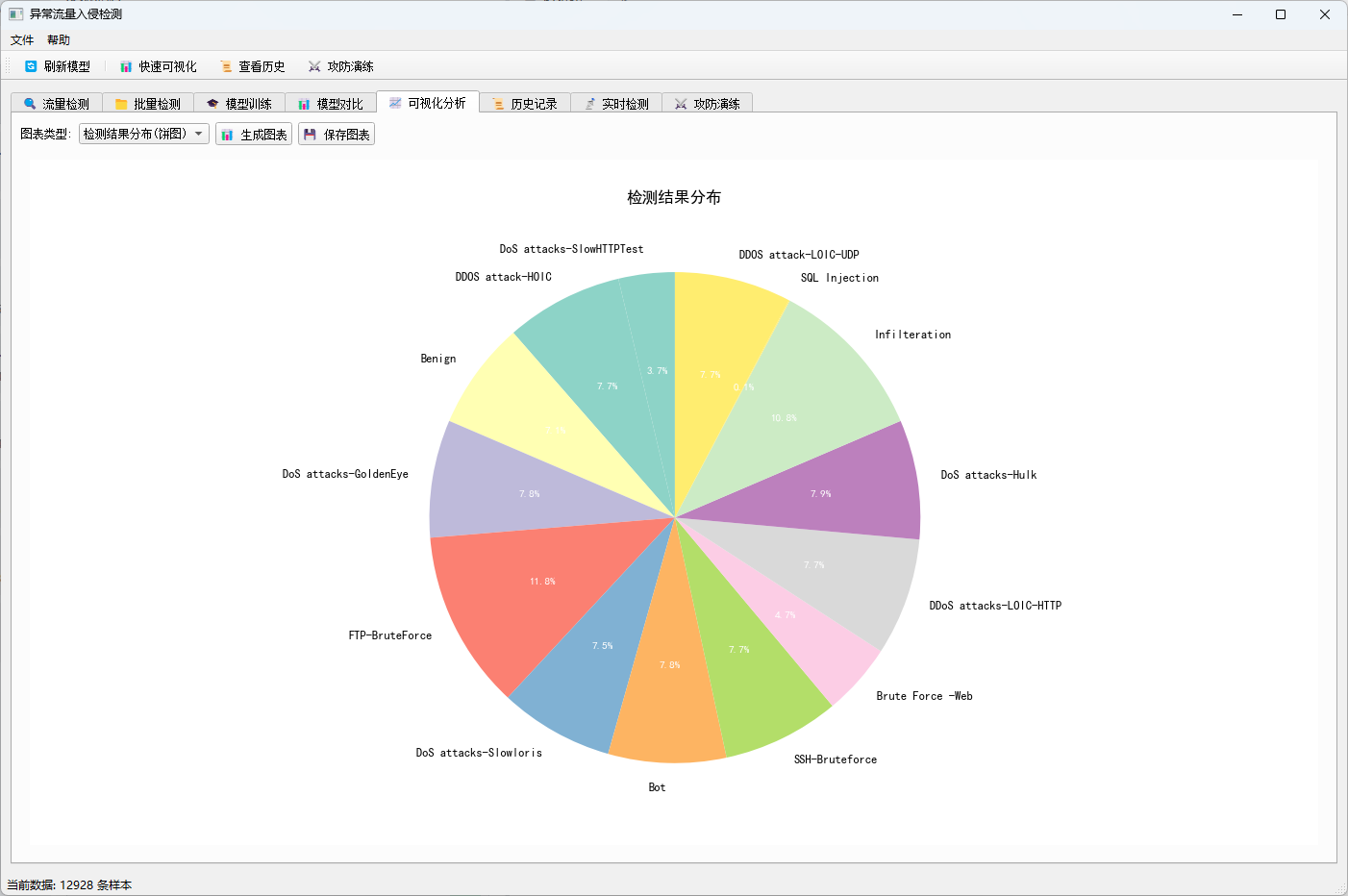
| 可视化分析 | 生成检测结果分布饼图、类别柱状图、置信度直方图等 |
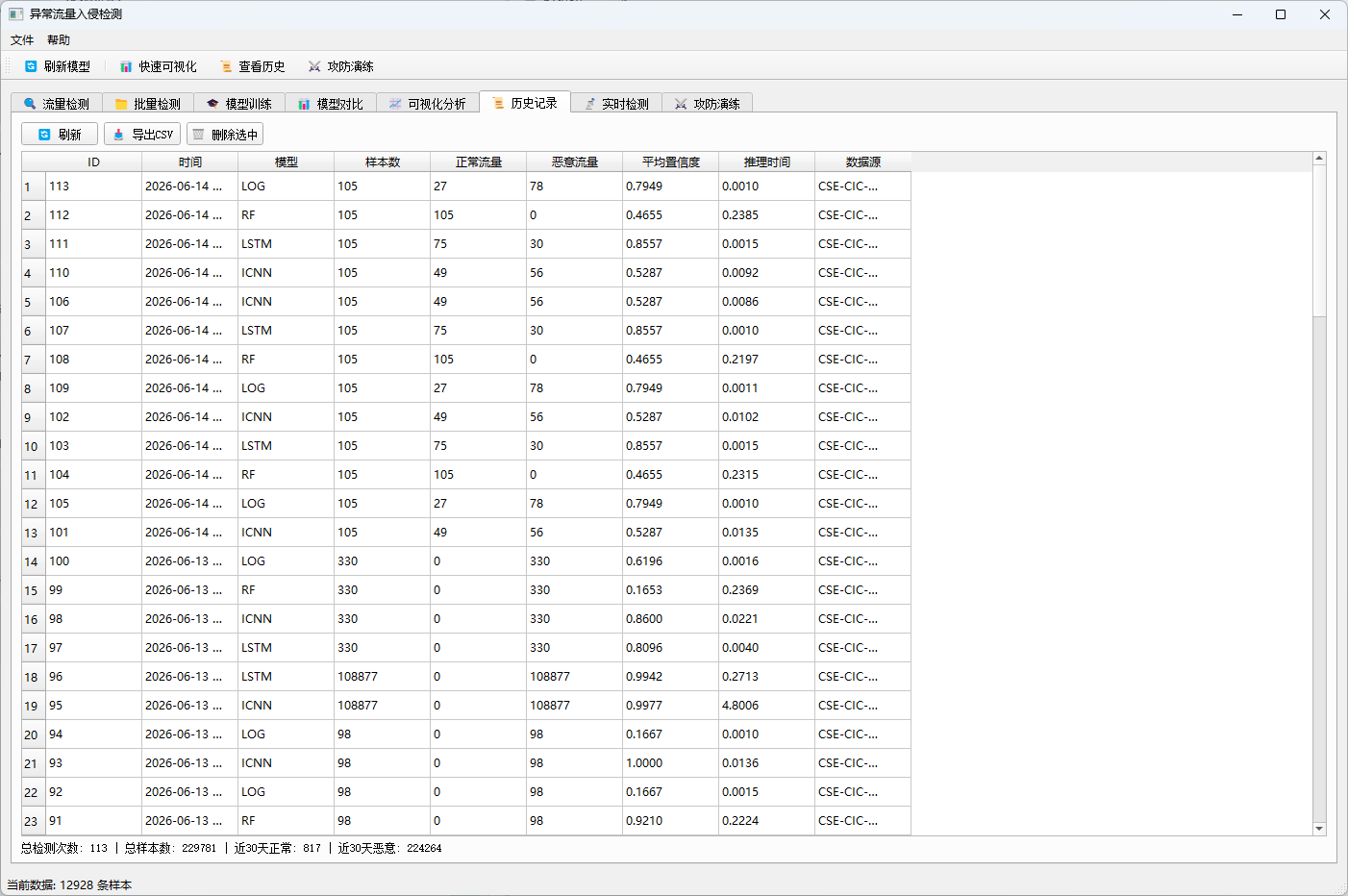
| 历史记录 | 查看、导出和删除 SQLite 中保存的检测记录 |
| 实时检测 | 捕获网卡流量,动态提取特征并实时推理 |
| 攻防演练 | 模拟 16 种攻击场景,评估模型在不同攻击下的检测能力 |
3.4 项目目录结构
恶意流量检测/
├── gui/ # GUI 界面模块
│ ├── main_window.py # 主窗口与八大 Tab
│ └── drill_tab.py # 攻防演练 Tab
├── core/ # 核心功能模块
│ ├── detection_engine.py # 检测引擎
│ └── attack_scenario.py # 攻击场景模拟器
├── models/ # 模型定义
│ ├── cnn_models.py # ICNN 与 CBAM 注意力
│ ├── lstm_models.py # LSTM 模型
│ └── ml_models.py # 传统机器学习模型
├── utils/ # 工具函数
│ ├── ids2018_loader.py # CSE-CIC-IDS2018 数据加载器
│ ├── visualization.py # Matplotlib 可视化
│ └── database.py # SQLite 数据库操作
├── realtime/ # 实时检测模块
│ ├── packet_capture.py # Scapy 数据包捕获
│ └── feature_extractor.py # 实时 78 维特征提取
├── ICNNModel/ # ICNN 模型文件
├── LSTMModel/ # LSTM 模型文件
├── RandomForestModel/ # 随机森林模型文件
├── LogisticRegressionModel/ # 逻辑回归模型文件
├── NEW_CNNModel/ # 新版 CNN 模型目录
├── CSE-CIC-IDS2018/ # 数据集目录
├── main.py # 程序入口
├── train_all_models.py # 全模型训练脚本
├── preprocess_CSE_CIC_IDS2018.py # 数据预处理脚本
├── merge_and_preprocess_CSE_CIC.py # 数据合并预处理
├── detection_history.db # 检测历史数据库
└── 项目说明.md # 项目说明文档3.5 技术栈
| 技术领域 | 使用技术 | 版本要求 |
|---|---|---|
| 深度学习框架 | PyTorch | ≥1.12.0 |
| GUI 开发 | PyQt5 | ≥5.15.0 |
| 机器学习 | scikit-learn | ≥1.0.0 |
| 数据处理 | pandas, numpy | ≥1.3.0, ≥1.21.0 |
| 数据可视化 | matplotlib | ≥3.5.0 |
| 网络抓包 | scapy | ≥2.4.5 |
| 数据库 | SQLite3 | 内置 |
| 模型持久化 | joblib, pickle | ≥1.1.0 |
四、CSE-CIC-IDS2018 数据集与预处理
4.1 数据集介绍
本项目使用 CSE-CIC-IDS2018 数据集进行模型训练和测试。该数据集由加拿大网络安全研究所(CIC)与通信安全机构(CSE)合作发布,是当前网络安全领域使用最广泛的公开数据集之一。数据集通过在真实网络环境中模拟多种攻击行为生成,包含丰富的流量统计特征和标签信息。
数据集的主要特点包括:
- 时间跨度:约 10 天(2018 年 7 月 2 日至 7 月 13 日)。
- 流量类型:正常流量 Benign 加上 14 种常见网络攻击类型。
- 特征维度:79 列,包括 78 维模型输入特征和 1 个标签列 Label。
- 数据规模:原始数据总量超过 1600 万条流记录,经过采样后可用于训练的数据约 280 万条。
项目中数据集按照攻击类型分文件存储,每个 CSV 文件以攻击名称命名,例如 DDoS attacks-LOIC-HTTP.csv、FTP-BruteForce.csv、Bot.csv 等。这种组织方式便于按类别加载和平衡采样。
4.2 攻击类别说明
系统最终需要区分的类别共 15 种,其中 Benign 为正常流量,其余 14 种为攻击流量:
| 编号 | 类别名称 | 说明 |
|---|---|---|
| 0 | Benign | 正常网络流量 |
| 1 | Bot | 僵尸网络通信 |
| 2 | DDoS | 分布式拒绝服务攻击 |
| 3 | DoS GoldenEye | GoldenEye 工具发起的 DoS 攻击 |
| 4 | DoS Hulk | Hulk 工具发起的 DoS 攻击 |
| 5 | DoS Slowhttptest | SlowHTTPTest 慢速 HTTP 攻击 |
| 6 | DoS Slowloris | Slowloris 慢速连接攻击 |
| 7 | FTP-Patator | FTP 暴力破解 |
| 8 | Heartbleed | 心脏出血漏洞利用 |
| 9 | Infiltration | 网络渗透攻击 |
| 10 | PortScan | 端口扫描 |
| 11 | SSH-Patator | SSH 暴力破解 |
| 12 | Web Attack - Brute Force | Web 暴力破解 |
| 13 | Web Attack - XSS | XSS 跨站脚本攻击 |
| 14 | Web Attack - SQL Injection | SQL 注入攻击 |
4.3 78 维特征构成
模型输入为 78 维特征,由 Dst Port、Protocol 和 76 维流统计特征组成。这些特征由 CICFlowMeter 工具从原始 PCAP 流量中提取,涵盖了流基本信息、包长统计、时间间隔统计、标志位统计、窗口大小统计、活跃/空闲时间等多个维度。
特征主要分为以下几类:
(1)流基本信息
Dst Port:目标端口Protocol:协议类型(TCP/UDP/ICMP 等)Flow Duration:流持续时间Tot Fwd Pkts、Tot Bwd Pkts:前向和后向包数量TotLen Fwd Pkts、TotLen Bwd Pkts:前向和后向字节总数
(2)包长度统计
Fwd Pkt Len Max/Min/Mean/Std:前向包长统计Bwd Pkt Len Max/Min/Mean/Std:后向包长统计Pkt Len Min/Max/Mean/Std/Var:整体包长统计Pkt Size Avg、Fwd Seg Size Avg、Bwd Seg Size Avg:平均包大小与段大小
(3)时间间隔统计
Flow IAT Mean/Std/Max/Min:流内包到达时间间隔统计Fwd IAT Tot/Mean/Std/Max/Min:前向 IAT 统计Bwd IAT Tot/Mean/Std/Max/Min:后向 IAT 统计
(4)速率特征
Flow Byts/s、Flow Pkts/s:流字节速率和包速率Fwd Pkts/s、Bwd Pkts/s:前向和后向包速率
(5)标志位统计
Fwd PSH Flags、Bwd PSH Flags:PSH 标志是否存在Fwd URG Flags、Bwd URG Flags:URG 标志是否存在FIN/SYN/RST/PSH/ACK/URG Flag Cnt:各类 TCP 标志是否存在CWE Flag Count、ECE Flag Cnt:扩展标志
(6)窗口与头部特征
Fwd Header Len、Bwd Header Len:前向和后向头部总长度Init Fwd Win Byts、Init Bwd Win Byts:初始窗口大小Fwd Act Data Pkts、Fwd Seg Size Min:有效数据包与最小段大小
(7)活跃与空闲时间
Active Mean/Std/Max/Min:活跃期持续时间统计Idle Mean/Std/Max/Min:空闲期持续时间统计
(8)子流与批量统计
Subflow Fwd Pkts、Subflow Fwd Byts、Subflow Bwd Pkts、Subflow Bwd Byts:子流统计Fwd Byts/b Avg、Fwd Pkts/b Avg、批量统计占位特征
这些特征在 utils/ids2018_loader.py 中以 FEATURE_COLUMNS 列表统一维护,训练、推理和实时检测都严格按该顺序选取特征,确保一致性。
4.4 数据预处理流程
数据预处理是模型性能的基础。本项目预处理流程包括以下几个步骤:
(1)读取数据
使用 pandas 分块读取 CSV 文件,避免一次性加载大文件导致内存溢出。
python
for chunk in pd.read_csv(file_path, chunksize=100000, low_memory=False):
# 处理每个 chunk(2)去除时间戳列
原始数据集中包含 Timestamp 列,模型训练时不需要,直接删除。
python
if 'Timestamp' in chunk.columns:
chunk = chunk.drop(columns=['Timestamp'])(3)处理无穷大值与缺失值
将 inf 和 -inf 替换为 NaN,然后删除包含 NaN 的行。
python
chunk = chunk.replace([np.inf, -np.inf], np.nan)
chunk.dropna(inplace=True)(4)按列名选取特征
v3.0 统一使用 FEATURE_COLUMNS 按列名选取特征,避免早期按位置选取导致的列顺序错位问题。
python
from utils.ids2018_loader import FEATURE_COLUMNS
X = df[FEATURE_COLUMNS]
y = df['Label'](5)特征归一化
统一使用 StandardScaler 进行零均值、单位方差标准化。v2.0 中部分训练脚本使用双重归一化(StandardScaler + MinMaxScaler),与 GUI 和实时检测不一致,v3.0 已统一为单步 StandardScaler。
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)(6)标签编码
使用 LabelEncoder 将字符串标签转换为整数类别,保存编码器供推理时使用。
python
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(df['Label'])(7)分层采样
划分训练集和测试集时使用 stratify=y,确保训练集和测试集中各类别比例一致。
python
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)4.5 类别不平衡处理
针对类别不平衡问题,本项目采取以下策略:
- 每类最多采样固定数量 :在
train_all_models.py中,每类最多采样 60000 条,避免少数类别被淹没。 - 分层采样:确保训练/测试集类别分布一致。
- class_weight='balanced':随机森林和逻辑回归模型使用该参数,让模型在训练时更关注少数类。
- 攻防演练中按场景平衡采样:每个攻击场景使用相同数量的样本进行评估,避免模型偏向大类。
五、核心算法模型详解
本项目采用深度学习和传统机器学习相结合的混合架构。四种模型各有优势:ICNN 擅长提取局部特征,LSTM 擅长捕捉时序依赖,随机森林速度快且可解释,逻辑回归作为基线模型结构简单。下面分别介绍各模型的设计思路与实现细节。
5.1 ICNN 改进卷积神经网络
卷积神经网络最初用于图像处理,但一维卷积同样可以处理序列型数据。在流量检测任务中,每条流量记录可以看作一个 78 维的一维向量,CNN 通过卷积核提取相邻特征之间的局部模式,例如包长与速率之间的关系、标志位组合等。
5.1.1 模型结构
ICNN 模型定义在 models/cnn_models.py 中,采用 4 层一维卷积加 2 层最大池化的结构:
python
class CNN(nn.Module):
"""改进卷积神经网络 (ICNN)"""
def __init__(self, input_dim=78, num_classes=15):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv1d(1, 32, kernel_size=2),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.Conv1d(32, 64, kernel_size=2),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.MaxPool1d(2, 2),
nn.Conv1d(64, 128, kernel_size=2),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.MaxPool1d(2, 2),
)
self.flatten = nn.Flatten()
# 动态计算全连接层输入维度
with torch.no_grad():
dummy = torch.zeros(1, 1, input_dim)
dummy = self.backbone(dummy)
fc_in = dummy.view(1, -1).shape[1]
self.fc = nn.Sequential(
nn.Linear(fc_in, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, num_classes)
)模型输入形状为 (batch_size, 1, 78),其中 1 表示通道维度。卷积层通道数从 1 逐渐增加到 128,池化层降低序列长度,最终通过全连接层输出类别 logits。
5.1.2 BatchNorm 与 Dropout
模型在卷积层后使用 BatchNorm1d 加速收敛并提高稳定性,在全连接层使用 Dropout(0.3) 防止过拟合。由于流量数据集中不同攻击类型的样本差异较大,Dropout 对于提升模型泛化能力尤为重要。
5.1.3 CBAM 注意力机制
为了进一步提升模型对重要特征的感知能力,项目中还实现了基于 CBAM(Convolutional Block Attention Module)的 1D 注意力模块。CBAM 依次在通道维度和空间维度上生成注意力权重,使模型更加关注对分类有帮助的特征区域。
python
class CBAM1D(nn.Module):
"""1D 卷积块注意力模块"""
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.channel_attention = ChannelAttention1D(in_channels, reduction_ratio)
self.spatial_attention = SpatialAttention1D()
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x带注意力的 CNN 模型 CNNWithAttention 在 backbone 后插入了 CBAM 模块,能够自适应地增强重要通道和位置的特征响应。
5.1.4 ICNN 的训练
训练过程使用 Adam 优化器和交叉熵损失函数。输入数据先经过 StandardScaler 标准化,再增加通道维度后送入网络。每个 epoch 结束后在验证集上计算准确率,训练完成后保存模型权重、scaler 和 label_encoder。
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()ICNN 的测试准确率约为 98%,是项目中精度最高的模型之一。
5.2 LSTM 长短期记忆网络
网络流量具有明显的时序特性。虽然 CSE-CIC-IDS2018 数据集中的每条记录已经是聚合后的流统计特征,但某些攻击行为在时间上仍呈现出规律性,例如僵尸网络的周期性心跳、暴力破解的短连接 burst 等。LSTM 通过门控机制能够有效捕捉这种时序依赖。
5.2.1 模型结构
LSTM 模型定义在 models/lstm_models.py 中:
python
class LSTMModel(nn.Module):
def __init__(self, input_dim=78, hidden_dim=64, output_dim=15, num_layers=2, dropout=0.2):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(hidden_dim, output_dim)模型将每条 78 维特征作为长度为 1 的时间序列输入,经过两层 LSTM 后取最后一个时间步的隐藏状态,经过 Dropout 和全连接层得到分类结果。虽然输入序列长度较短,但 LSTM 仍能通过门控机制学习到不同特征之间的非线性组合。
5.2.2 训练配置
LSTM 训练参数包括隐藏层维度 64、LSTM 层数 2、Dropout 率 0.2、学习率 0.001、批次大小 1024、训练轮数 10。训练完成后同样保存模型、scaler 和 label_encoder。
LSTM 的测试准确率约为 97%,推理速度略慢于 ICNN。
5.3 随机森林
随机森林是一种基于 Bagging 的集成学习方法,通过构建多棵决策树并综合投票结果来提高准确率和鲁棒性。它对高维数据表现良好,训练速度快,且能够提供特征重要性评估。
5.3.1 模型配置
在项目中,随机森林用于快速检测场景,主要配置如下:
python
rf_model = RandomForestClassifier(
n_estimators=200,
max_depth=None,
random_state=42,
n_jobs=-1,
class_weight='balanced',
min_samples_leaf=2,
min_samples_split=5
)n_estimators=200:构建 200 棵决策树。class_weight='balanced':自动根据类别频率调整权重,缓解类别不平衡。n_jobs=-1:使用所有 CPU 核心加速训练。
5.3.2 v3.0 重新训练
v2.0 中随机森林训练与推理存在不一致:训练时未做归一化,但检测引擎已准备加载 scaler。v3.0 修复后,RF 训练时也使用 StandardScaler 并保存 scaler,推理时再进行相同变换。重新训练后,随机森林的测试准确率从约 70% 提升至 89.81%。
python
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model.fit(X_train, y_train)5.4 逻辑回归
逻辑回归作为最基础的线性分类器,虽然表达能力有限,但训练速度极快、可解释性强,非常适合作为基线模型与其他复杂模型进行对比。
5.4.1 模型配置
python
lr_model = LogisticRegression(
max_iter=1000,
random_state=42,
multi_class='multinomial',
solver='lbfgs',
class_weight='balanced',
C=1.0
)逻辑回归对特征尺度非常敏感,因此必须进行 StandardScaler 归一化。v3.0 修复训练与推理一致性后,逻辑回归的测试准确率从约 70% 提升至 85.97%。
5.5 模型训练流程
模型训练可以通过 GUI 的"模型训练"Tab 完成,也可以直接运行 train_all_models.py 脚本。训练流程的核心逻辑封装在 gui/main_window.py 的 TrainingThread 类中。
5.5.1 GUI 训练流程
- 用户选择模型类型和训练数据文件。
- 读取 CSV,对特征列进行数值转换。
- 替换 inf 为 NaN,删除无效行。
- 按
FEATURE_COLUMNS列名选取特征。 - 检查特征维度是否为 78。
- 使用 LabelEncoder 编码标签。
- 分层划分训练集和测试集。
- 使用 StandardScaler 归一化。
- 根据模型类型训练并保存模型、scaler、label_encoder。
5.5.2 全模型训练脚本
train_all_models.py 用于一次性训练随机森林、CNN 和 LSTM 三个模型。脚本采用分块读取和每类最多采样 60000 条的策略,避免内存溢出。训练完成后保存各模型文件以及全局 scaler。
5.6 模型性能对比
下表总结了各模型在项目中的性能表现:
| 模型 | 测试准确率 | 推理速度 | 适用场景 |
|---|---|---|---|
| ICNN | 约 98% | 中等 | 高精度需求场景 |
| LSTM | 约 97% | 较慢 | 需要时序建模的场景 |
| 随机森林 | 89.81% | 快 | 快速检测与可解释性需求 |
| 逻辑回归 | 85.97% | 最快 | 基线对比与轻量部署 |
需要注意的是,ICNN 和 LSTM 是早期训练的模型,v3.0 虽然对训练和推理流程进行了统一,但建议后续使用修复后的流程重新训练深度学习模型,以进一步提升与 RF/LOG 的一致性。
5.7 损失函数与优化策略
在分类任务中,损失函数的选择直接影响模型的收敛速度和最终性能。本项目所有深度学习模型均采用交叉熵损失函数(CrossEntropyLoss),其数学形式为:
L = − 1 N ∑ i = 1 N ∑ c = 1 C y i , c log ( p i , c ) L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{C} y_{i,c} \log(p_{i,c}) L=−N1i=1∑Nc=1∑Cyi,clog(pi,c)
其中, N N N 为样本数, C C C 为类别数, y i , c y_{i,c} yi,c 为样本 i i i 在类别 c c c 上的真实标签(one-hot 形式), p i , c p_{i,c} pi,c 为模型预测的概率。交叉熵损失对概率估计的误差具有较好的惩罚机制,尤其适合多分类任务。
优化器选择 Adam(Adaptive Moment Estimation),它结合了动量法和 RMSProp 的优点,能够自适应调整每个参数的学习率。在项目中,初始学习率设置为 0.001,批次大小根据模型和硬件条件设置为 512 或 1024。对于 ICNN 和 LSTM,训练轮数通常设置为 10 到 20 轮,既能保证模型收敛,又避免过长的训练时间。
5.8 超参数配置经验
超参数的选择对模型性能有显著影响。根据项目实践,总结以下经验:
- 学习率:0.001 是一个较为稳健的初始值。如果训练过程中损失下降过慢,可以适当增大到 0.005;如果出现震荡或发散,则应减小到 0.0001。
- 批次大小:较大的批次大小(如 1024)能够提高 GPU 利用率,加速训练,但可能使模型收敛到较差的局部最优。较小的批次大小(如 256)引入更多噪声,有助于跳出局部最优,但训练速度较慢。本项目在深度学习模型中采用 1024 作为默认批次大小。
- Dropout 率:ICNN 中使用 0.3,LSTM 中使用 0.2。Dropout 能够有效防止过拟合,但设置过高会削弱模型学习能力。
- LSTM 隐藏层维度:64 是一个兼顾表达能力和计算效率的选择。隐藏层维度越大,模型表达能力越强,但训练和推理开销也越大。
- 随机森林树的数量:200 棵树能够在准确率和训练时间之间取得较好平衡。树的数量过少容易欠拟合,过多则训练时间过长且收益递减。
5.9 数据增强与采样策略
针对 CSE-CIC-IDS2018 数据集中类别不平衡的问题,除了使用 class_weight='balanced' 和分层采样外,项目还采用了限制每类最大样本数的策略。在 train_all_models.py 中,每类最多采样 60000 条记录,这样既能保留多数类的代表性,又不会让少数类被完全淹没。
此外,在 GUI 的模型训练流程中,训练集和测试集的划分使用 stratify=y 参数,确保两个集合中各类别比例一致。这一细节对于类别不平衡数据集尤为重要,能够避免因训练集和测试集分布差异导致的性能评估偏差。
六、检测引擎统一推理设计
检测引擎是连接数据、模型和用户界面的核心组件。一个设计良好的检测引擎能够统一管理多种模型的加载、预处理和推理,提供一致的接口供上层调用。本项目中的 DetectionEngine 类位于 core/detection_engine.py,承担了这一职责。
6.1 设计目标
检测引擎的设计目标包括:
- 统一接口 :无论底层是 PyTorch 模型还是 scikit-learn 模型,上层都通过相同的
predict(model_name, data)方法调用。 - 自动加载:启动时自动查找并加载最新训练的模型文件,减少用户手动配置。
- 一致性预处理:所有模型在推理时都使用与训练时相同的 scaler 和 feature columns。
- 动态适配:能够根据模型权重自动推断输出类别数,支持不同版本模型。
- 集成学习:支持多模型软投票和硬投票,提高检测稳定性。
6.2 类结构
python
class DetectionEngine:
label_names: List[str] = [
"Benign", "Bot", "Brute Force -Web", "Brute Force -XSS", "DDOS attack-HOIC",
"DDOS attack-LOIC-UDP", "DDoS attacks-LOIC-HTTP", "DoS attacks-GoldenEye",
"DoS attacks-Hulk", "DoS attacks-SlowHTTPTest", "DoS attacks-Slowloris",
"FTP-BruteForce", "Infilteration", "SQL Injection", "SSH-Bruteforce"
]
def __init__(self):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.models = {} # 深度学习模型
self.ml_models = {} # 机器学习模型
self.scalers = {} # 各模型对应的 scaler
self.encoders = {} # 各模型对应的 label_encoder6.3 模型自动发现与加载
为了避免用户手动指定模型路径,DetectionEngine 实现了 _find_latest_file 静态方法,按照修改时间自动查找最新的模型文件,并支持排除 venv 目录和旧实验目录。
python
@staticmethod
def _find_latest_file(patterns, exclude_names=None, exclude_path_substrings=None):
candidates = []
for pattern in patterns:
for path in glob.glob(pattern, recursive=True):
norm_path = path.replace('\\', '/')
if '/venv/' in norm_path:
continue
if any(sub in norm_path for sub in exclude_path_substrings or []):
continue
candidates.append((path, os.path.getmtime(path)))
candidates.sort(key=lambda x: x[1], reverse=True)
return candidates[0][0] if candidates else None以 ICNN 模型加载为例:
python
def load_icnn_model(self, model_path=None):
if model_path is None:
preferred = ['ICNNModel/CNN_model.pth', 'NEW_CNNModel/NEW_CNN_model.pth']
for p in preferred:
if os.path.isfile(p):
model_path = p
break
if model_path is None:
model_path = self._find_latest_file([
'ICNNModel/**/*.pth',
'NEW_CNNModel/**/*.pth'
], exclude_path_substrings=['/V1(', '/V2(', '/V3(', '/V'])加载模型权重后,引擎会动态推断输出类别数:
python
state_dict = torch.load(model_path, map_location=self.device)
num_classes = self._infer_cnn_output_dim(state_dict)
model = CNN(input_dim=78, num_classes=num_classes)
model.load_state_dict(state_dict)6.4 Scaler 与 Label Encoder 管理
每个模型训练时都会保存对应的 scaler.pkl 和 label_encoder.pkl。检测引擎在加载模型时,会自动在同一目录或默认目录下查找这些文件,确保推理时的预处理与训练一致。
python
def _load_scaler(self, model_name, scaler_path):
if not scaler_path or not os.path.exists(scaler_path):
return
if scaler_path.endswith('.joblib'):
self.scalers[model_name] = joblib.load(scaler_path)
else:
with open(scaler_path, 'rb') as f:
self.scalers[model_name] = pickle.load(f)6.5 特征预处理
_prepare_features 方法负责从 DataFrame 中提取特征矩阵并进行归一化。v3.0 中新增了 np.clip(X, -3, 3) 的截断处理,防止实时特征分布偏移导致极端值误判。
python
def _prepare_features(self, data, model_name):
if 'Label' in data.columns:
X = data[FEATURE_COLUMNS].values if all(c in data.columns for c in FEATURE_COLUMNS) else data.iloc[:, :-1].values
else:
if all(c in data.columns for c in FEATURE_COLUMNS):
X = data[FEATURE_COLUMNS].values
else:
X = data.values
if model_name in self.scalers:
X = self.scalers[model_name].transform(X)
# StandardScaler 后 99.7% 正常数据应在 [-3, 3] 范围内
X = np.clip(X, -3, 3)
return X6.6 统一预测接口
predict 方法根据模型名称分发到对应的预测函数:
python
def predict(self, model_name, data):
if model_name == 'ICNN':
return self.predict_icnn(data)
elif model_name == 'LSTM':
return self.predict_lstm(data)
elif model_name == 'RF':
return self.predict_rf(data)
elif model_name == 'LOG':
return self.predict_logistic(data)
else:
raise ValueError(f"Unknown model: {model_name}")每个预测函数都会返回一个 DetectionResult 对象,包含模型名称、预测标签、预测概率和推理时间:
python
class DetectionResult:
def __init__(self, model_name, predictions, probabilities, inference_time, labels=None):
self.model_name = model_name
self.predictions = predictions
self.probabilities = probabilities
self.inference_time = inference_time
self.labels = labels if labels is not None else DetectionEngine.label_names6.7 多模型批量预测
predict_batch 方法支持同时使用多个模型进行预测,返回每个模型的结果字典:
python
def predict_batch(self, model_names, data):
results = {}
for model_name in model_names:
if model_name in self.models or model_name in self.ml_models:
results[model_name] = self.predict(model_name, data)
return results6.8 集成学习
集成学习通过综合多个模型的预测结果来提高稳定性。本项目支持软投票和硬投票两种方式。
软投票:对多个模型的预测概率取平均,再取概率最大的类别。
python
if voting == 'soft':
avg_probs = None
total_time = 0
for result in results.values():
if avg_probs is None:
avg_probs = result.probabilities
else:
avg_probs += result.probabilities
total_time += result.inference_time
avg_probs /= len(results)
predictions = np.argmax(avg_probs, axis=1)硬投票:直接对预测标签进行多数表决。
python
else:
votes = np.array([result.predictions for result in results.values()])
predictions = np.apply_along_axis(
lambda x: np.bincount(x).argmax(), axis=0, arr=votes
)集成学习可以有效降低单一模型的随机误差,尤其当不同模型在某些类别上各有优势时,集成后的综合表现通常优于任何单一模型。
6.9 DetectionResult 结果封装
为了使上层调用者能够方便地获取预测结果,DetectionEngine 定义了 DetectionResult 类来封装单次推理的输出。该类包含以下关键信息:
- predictions:每个样本的预测类别索引。
- probabilities:每个样本在各类别上的预测概率。
- inference_time:本次推理耗时。
- labels:类别名称列表,用于将索引转换为可读的标签字符串。
python
class DetectionResult:
def __init__(self, model_name, predictions, probabilities, inference_time, labels=None):
self.model_name = model_name
self.predictions = predictions
self.probabilities = probabilities
self.inference_time = inference_time
self.labels = labels if labels is not None else DetectionEngine.label_names
def get_predicted_labels(self):
return [self.labels[p] for p in self.predictions]
def get_confidence_scores(self):
return [self.probabilities[i][p] for i, p in enumerate(self.predictions)]get_predicted_labels 将类别索引转换为字符串标签,get_confidence_scores 返回每个预测结果的置信度。这两个方法在 GUI 展示和攻防演练统计中被频繁使用。
6.10 错误处理与降级策略
在实际应用中,模型文件可能损坏、缺失或版本不兼容。为了提升系统的鲁棒性,检测引擎在加载和推理过程中加入了错误处理机制。例如,当某个模型加载失败时,引擎会打印错误日志并跳过该模型,而不是导致整个系统崩溃。在 predict_batch 中,如果某个模型推理失败,也会记录错误并继续处理其他模型。
此外,检测引擎还支持用户手动指定模型路径,方便在自动发现机制失效时进行调试和替换。这种设计兼顾了自动化和灵活性,使得平台在不同部署环境下都能稳定运行。
6.11 检测引擎的工程意义
DetectionEngine 的设计体现了"面向接口编程"的思想。上层模块(如 GUI、批量检测、实时检测、攻防演练)只需要关心调用 predict 或 predict_batch 方法,而不需要了解底层是 PyTorch 模型还是 scikit-learn 模型。这种抽象大大降低了系统的耦合度,也为后续接入新的模型(如 Transformer、XGBoost 等)提供了便利。
七、PyQt5 可视化平台开发
7.1 为什么选择 PyQt5
在构建桌面级可视化平台时,技术选型需要在开发效率、界面表现力和生态成熟度之间取得平衡。PyQt5 是 Qt 框架的 Python 绑定,具备以下优势,使其成为本项目的理想选择:
- 组件丰富:提供了按钮、表格、下拉框、进度条、标签页、文本框、菜单栏、工具栏等常用控件,能够满足复杂业务界面的需求。
- 信号槽机制:通过信号(Signal)和槽(Slot)实现控件之间的解耦通信,特别适合多线程场景下的 UI 更新。
- 样式表支持:支持类似 CSS 的 QSS 样式表,可以方便地美化按钮、表格、状态栏等控件。
- Matplotlib 集成 :通过
FigureCanvasQTAgg可以将 Matplotlib 图表嵌入到 Qt 窗口中,实现检测数据的可视化分析。 - 跨平台:PyQt5 支持 Windows、Linux 和 macOS,便于项目在不同操作系统上部署。
7.2 主窗口与 Tab 页设计
gui/main_window.py 中的 MainWindow 类是整个平台的主入口。主窗口采用经典的菜单栏 + 工具栏 + 标签页布局,顶部为文件、帮助菜单和快捷操作工具栏,中部为八大功能 Tab 页,底部为状态栏。
python
self.tab_widget = QTabWidget()
self.tab_widget.addTab(self.create_detection_tab(), "流量检测")
self.tab_widget.addTab(self.create_batch_tab(), "批量检测")
self.tab_widget.addTab(self.create_training_tab(), "模型训练")
self.tab_widget.addTab(self.create_comparison_tab(), "模型对比")
self.tab_widget.addTab(self.create_visualization_tab(), "可视化分析")
self.tab_widget.addTab(self.create_history_tab(), "历史记录")
self.tab_widget.addTab(self.create_realtime_tab(), "实时检测")
self.tab_widget.addTab(self.create_drill_tab(), "攻防演练")每个 Tab 页都是一个独立的方法返回的 QWidget,内部再细分为左右面板或上下面板。例如,流量检测页左侧放置数据加载、模型选择、控制按钮,右侧放置结果表格;实时检测页左侧为网卡选择和捕获控制,右侧为实时数据表格和告警区域。
7.3 多线程设计:避免界面卡顿
流量检测、模型训练、批量检测、实时捕获等操作都可能耗时较长,如果直接在主线程中执行,会导致界面无响应。因此,项目为每个耗时操作设计了独立的 QThread 子类:
| 线程类 | 用途 | 关键信号 |
|---|---|---|
DetectionThread |
单文件/随机样本检测 | detection_finished, progress_updated |
BatchDetectionThread |
多文件批量检测 | batch_finished, file_processed |
TrainingThread |
模型训练 | epoch_completed, training_finished, progress_updated |
RealtimeDetectionThread |
实时特征推理 | detection_finished |
DrillThread |
攻防演练执行 | progress_updated, scenario_completed, drill_finished |
以 DetectionThread 为例,其核心逻辑是在后台依次调用检测引擎的 predict 方法,并通过 progress_updated 信号向主界面报告进度:
python
class DetectionThread(QThread):
detection_finished = pyqtSignal(dict)
progress_updated = pyqtSignal(int)
def run(self):
results = {}
total = len(self.model_names)
for i, model_name in enumerate(self.model_names):
result = self.engine.predict(model_name, self.data)
results[model_name] = result
progress = int((i + 1) / total * 100)
self.progress_updated.emit(progress)
self.detection_finished.emit(results)主窗口通过 connect 将线程信号绑定到界面更新槽函数,实现"后台计算、前台刷新"的流畅体验。
7.4 数据表格与结果展示
检测完成后,结果需要以表格形式展示给用户。项目使用 QTableWidget 显示每条样本的预测标签、置信度、真实标签等信息。对于大规模数据,表格支持滚动浏览,并可通过表头排序。
在实时检测页中,表格不仅需要展示新检测到的流,还需要更新已有流的最新检测结果。为此,项目维护了一个 realtime_flow_rows 字典,记录 flow_id 到表格行号的映射。当同一流被重新检测时,直接更新对应行,而不是不断追加新行,这样既节省了表格空间,也便于用户跟踪单个流的状态变化。
7.5 可视化分析 Tab
可视化分析模块基于 utils/visualization.py 实现,主要包含以下几类图表:
- 饼图:展示检测结果中各类别的占比,例如 Benign、DDoS、DoS 等的比例。
- 柱状图:展示各类别的样本数量,便于观察数据分布。
- 置信度直方图:展示模型预测置信度的分布情况,帮助判断模型预测的置信程度。
- 混淆矩阵热力图:展示模型在不同类别上的误判情况。
- 特征重要性图:对于随机森林等模型,展示 Top N 重要特征。
- 模型对比图:在同一坐标系中对比多个模型的准确率和推理时间。
这些图表通过 MatplotlibCanvas 嵌入到 Qt 界面中,VisualizationWidget 负责管理画布的切换和清理。
7.6 样式美化与状态栏
为了提升用户体验,项目对部分控件进行了 QSS 样式美化。例如,开始捕获按钮使用绿色背景,停止捕获按钮使用红色背景,告警文本框使用黄色背景以引起注意。状态栏每隔 5 秒更新一次当前数据状态,实时反映系统运行情况。
python
self.status_timer = QTimer()
self.status_timer.timeout.connect(self.update_status)
self.status_timer.start(5000)总体来看,PyQt5 可视化平台的设计遵循"功能分区明确、操作反馈及时、界面简洁直观"的原则,使得即使是没有机器学习背景的用户,也能够通过图形界面完成数据加载、模型检测、结果查看和报告导出等操作。
八、实时流量检测:v3.0 优化全解析
实时流量检测是本项目的核心亮点之一,也是 v3.0 版本重点优化的模块。与离线 CSV 检测不同,实时检测需要从网卡动态捕获数据包、在线维护流状态、实时提取特征并完成模型推理。这一链路中的任何一环出现偏差,都可能导致高误报或高漏报。本节将详细剖析实时检测的完整流程以及 v3.0 版本中的六项关键优化。
8.1 实时检测在 v2.0 中的问题
在 v2.0 版本中,实时检测功能已经具备基本雏形,但实际运行中暴露出较为严重的误报问题。典型现象包括:
- 正常流量被大量误判为攻击:例如浏览网页、下载文件等常见行为会被标记为 DDoS 或 DoS。
- 同一流被重复计数为恶意 :由于每次检测都新增表格行,同一流在不同时刻被多次检测后,
malicious_flows统计会重复累加。 - 特征与训练数据不一致:部分特征的计算方式与 CICFlowMeter 存在差异,例如标志位统计使用计数而非二值、速率特征除数错误等。
- 不成熟流过早检测:流中只有几个包时就被送入模型,统计特征极不稳定,导致预测结果不可靠。
这些问题使得 v2.0 的实时检测更像是一个"演示功能",难以在实际场景中提供可信的告警。v3.0 版本针对上述问题进行了系统性修复。
8.2 实时检测整体流程
在介绍具体优化之前,先梳理实时检测的整体数据流:
网卡数据包
↓
Scapy sniff 捕获
↓
PacketCapture._process_packet 解析并更新流统计
↓
QTimer 周期性读取活跃流
↓
FeatureExtractor.extract_features 提取 78 维特征
↓
DetectionEngine.predict 模型推理
↓
主界面更新表格、告警、统计信息这一流程中,PacketCapture 负责底层抓包和流状态维护,FeatureExtractor 负责将流对象转换为模型可识别的特征向量,DetectionEngine 负责模型推理,主界面负责结果展示和交互控制。
8.3 优化一:特征提取对齐 CICFlowMeter
v3.0 最重要的修复之一是确保实时提取的 78 维特征与 CSE-CIC-IDS2018 训练数据的特征计算逻辑完全一致。realtime/feature_extractor.py 中的 FeatureExtractor 直接使用 FEATURE_COLUMNS 作为输出列名,并按该顺序组织特征数组。
具体对齐点包括:
(1)标志位二值化
CICFlowMeter 中的标志位特征(如 FIN Flag Cnt、SYN Flag Cnt、PSH Flag Cnt 等)是二值的,表示该流中是否存在对应标志。v2.0 中曾使用计数方式,导致特征值范围与训练数据不同。v3.0 已修复为二值化:
python
f['FIN Flag Cnt'] = int((flow.fwd_fin_flags + flow.bwd_fin_flags) > 0)
f['SYN Flag Cnt'] = int((flow.fwd_syn_flags + flow.bwd_syn_flags) > 0)(2)速率特征除数修正
Flow Byts/s 和 Flow Pkts/s 应使用流持续时间作为除数,而不是包数量:
python
if flow.flow_duration > 0.001:
f['Flow Byts/s'] = (flow.total_fwd_bytes + flow.total_bwd_bytes) / flow.flow_duration
f['Flow Pkts/s'] = (flow.total_fwd_packets + flow.total_bwd_packets) / flow.flow_duration(3)Flow Duration 单位统一
CSE-CIC-IDS2018 中的 Flow Duration 单位为微秒,因此实时提取时也将秒级时间差乘以 1000000:
python
f['Flow Duration'] = flow.flow_duration * 1000000(4)Active/Idle 时间计算
v3.0 参考 CICFlowMeter 的 1 秒阈值划分活跃期和空闲期,并在流过期时结束最后一个活跃期,避免短流的 Active 特征全为 0。
8.4 优化二:统一 StandardScaler 归一化
训练与推理的归一化一致性直接影响模型在实际场景中的表现。v2.0 中,不同训练脚本使用的归一化策略不同:有的使用 StandardScaler,有的使用 StandardScaler + MinMaxScaler 双重归一化,而 GUI 和实时检测只使用 StandardScaler。这种不一致导致模型在训练数据上表现良好,但在实时数据上性能骤降。
v3.0 统一了所有训练路径的归一化策略:
python
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)检测引擎的 _prepare_features 方法在推理时也使用对应模型的 scaler 进行变换。此外,v3.0 新增了 np.clip(X, -3, 3) 的截断处理:
python
if model_name in self.scalers:
X = self.scalers[model_name].transform(X)
X = np.clip(X, -3, 3)这一截断的理论依据是:对于服从正态分布的数据,99.7% 的样本应落在均值正负 3 个标准差范围内。实时捕获的流量可能因网络环境差异出现极端值,截断可以防止这些极端值对模型产生过大影响。
8.5 优化三:流成熟度门槛
实时捕获中,一个流在刚刚建立时往往只有少量数据包,此时计算出的统计特征(如均值、标准差、速率)非常不稳定,容易产生误判。v3.0 引入了流成熟度门槛机制:
python
MIN_PACKETS = 10
PACKET_INCREMENT = 10只有当一个流的总包数大于等于 10 时,才会被纳入检测范围。这一门槛的设定兼顾了及时性和稳定性:门槛过低则特征不稳定,门槛过高则可能延迟告警。10 个包对于大多数攻击行为已经足够形成初步统计特征。
8.6 优化四:增量重新检测机制
网络流是动态发展的,一个流在建立初期的特征可能不完整,但随着包数增加,其行为模式会逐渐清晰。v3.0 引入了增量重新检测机制:
python
mature_flows = {}
for fid, flow in flows.items():
current_pkts = flow.total_fwd_packets + flow.total_bwd_packets
last_pkts = self.detected_flow_packet_counts.get(fid, 0)
if current_pkts >= MIN_PACKETS and (current_pkts - last_pkts) >= PACKET_INCREMENT:
mature_flows[fid] = flow
self.detected_flow_packet_counts[fid] = current_pktsdetected_flow_packet_counts 字典记录了每个流上次检测时的包数。当某个流新增包数达到 10 个或以上时,会触发重新检测。这样,早期因特征不足导致的误判可以在后续检测中得到纠正。
8.7 优化五:恶意流统计去重
v2.0 中,同一流每次被检测到时都会新增表格行,并且每次只要预测为恶意就累加 malicious_flows 计数,导致统计数字虚高。v3.0 通过 malicious_flow_ids 集合实现了恶意流的去重管理:
python
was_malicious = flow_id in self.malicious_flow_ids
is_malicious = label.upper() != "BENIGN" and confidence >= threshold
if is_malicious and not was_malicious:
self.capture_stats['malicious_flows'] += 1
self.malicious_flow_ids.add(flow_id)
elif not is_malicious and was_malicious:
self.capture_stats['malicious_flows'] = max(0, self.capture_stats['malicious_flows'] - 1)
self.malicious_flow_ids.discard(flow_id)该机制不仅能防止重复计数,还能在流后续被重新判定为正常时自动减少恶意流计数,使统计结果真实反映当前网络状态。
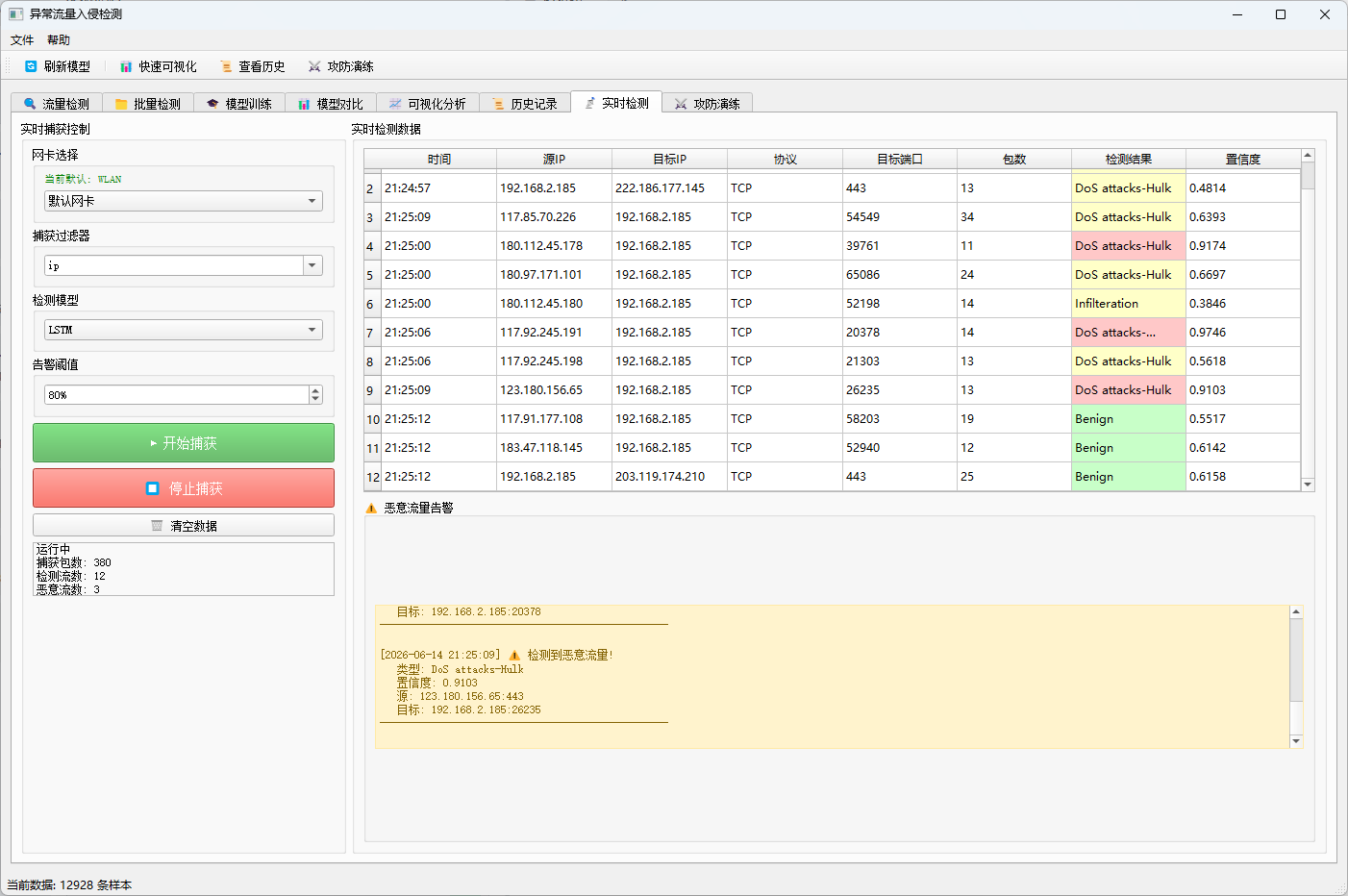
8.8 优化六:三色展示体系与告警阈值
v3.0 为实时检测结果设计了直观的三色展示体系:
- 绿色 :预测为
Benign(正常流量)。 - 红色:预测为攻击且置信度大于等于告警阈值(高置信度攻击)。
- 黄色:预测为攻击但置信度低于告警阈值(低置信度疑似攻击)。
实现逻辑如下:
python
threshold = self.threshold_slider.value() / 100.0
if label.upper() != "BENIGN":
if confidence >= threshold:
result_item.setBackground(QtGui.QColor(255, 200, 200)) # 红色
else:
result_item.setBackground(QtGui.QColor(255, 255, 200)) # 黄色
else:
result_item.setBackground(QtGui.QColor(200, 255, 200)) # 绿色告警阈值可以通过左侧滑块在 50% 到 99% 之间调节。只有红色行会触发告警并计入恶意流统计,黄色行仅作为疑似提示。这种分级展示有效避免了低置信度预测造成的视觉误报。
8.9 实时检测的数据包捕获实现
底层数据包捕获由 realtime/packet_capture.py 中的 PacketCapture 类实现。它基于 Scapy 的 sniff 函数,在独立线程中持续捕获数据包:
python
def _capture_loop(self):
sniff(
iface=self.interface,
filter=self.filter_expr,
prn=self._process_packet,
stop_filter=lambda x: not self.is_capturing,
store=False
)捕获到的每个数据包会经过 _extract_packet_info 解析为字典,包含源 IP、目标 IP、源端口、目标端口、协议、包大小、TCP 标志位、窗口大小等信息。随后 _update_flow_stats 根据五元组生成双向流 ID,并更新流的各项统计指标。
为了避免内存无限增长,PacketCapture 还实现了活跃流清理机制。get_active_flows(timeout=60.0) 会返回最近 60 秒内有活动的流,并将超过 60 秒未更新的流从内存中删除。
8.10 BPF 过滤器与网卡选择
Scapy 支持 Berkeley Packet Filter(BPF)语法,用户可以在实时检测页中设置捕获过滤器,只捕获感兴趣的流量。常见的过滤规则包括:
ip:只捕获 IP 数据包。tcp:只捕获 TCP 数据包。udp:只捕获 UDP 数据包。icmp:只捕获 ICMP 数据包。port 80:只捕获目标或源端口为 80 的流量。port 443:只捕获 HTTPS 流量。
合理使用 BPF 过滤器能够显著减少需要处理的数据包数量,降低 CPU 占用,提高检测实时性。例如,在仅关注 Web 攻击时,可以设置过滤器为 tcp and port 80,避免处理大量无关流量。
网卡选择方面,项目默认使用系统默认网卡,并允许用户手动切换。在多网卡环境中(如同时连接了有线网和无线网),选择正确的网卡是捕获到目标流量的前提。
8.11 性能调优建议
在实际部署中,可以通过以下方式进一步提升实时检测性能:
- 降低检测频率 :如果网络流量较大,可以适当延长
QTimer的触发间隔,减少单位时间内的检测次数。 - 使用更轻量的模型:对于资源受限的环境,可以优先使用随机森林或逻辑回归模型,而不是 ICNN 或 LSTM。
- 设置更严格的 BPF 过滤器:只捕获与检测目标相关的流量,减少无效计算。
- 增加流过期时间:在高流量环境中,适当缩短流的过期时间可以释放内存,但可能影响长连接的检测完整性。
- 使用 GPU 加速:对于必须使用深度学习模型的场景,NVIDIA GPU 可以显著降低推理延迟。
8.12 实时检测的局限性
尽管 v3.0 大幅提升了实时检测的可用性,但仍需清醒认识其局限性:
- 无法处理加密载荷:平台基于流统计特征进行检测,无法解密 HTTPS 等加密流量的内容。
- 依赖训练数据分布:如果实际网络环境与 CSE-CIC-IDS2018 差异较大,模型性能可能下降。
- 单点部署:当前版本为单机桌面应用,无法分布式部署在大规模网络中。
- 告警需要人工研判:检测系统只能提供参考,最终安全决策仍需专业人员结合上下文进行判断。
8.13 实时检测的工程价值
经过 v3.0 的六项优化,实时检测模块从一个"高误报演示功能"转变为一个可用的网络监控组件。虽然它仍无法替代专业 IDS/IPS 设备,但在以下场景中具有实际价值:
- 毕业设计演示:能够直观展示从网卡捕获到模型推理的完整链路。
- 小型网络监控:在实验环境或小型办公网络中提供轻量级流量异常提示。
- 模型效果验证:通过真实流量验证模型在训练数据之外的泛化能力。
- 教学实验:帮助学生理解网络流特征、机器学习推理和实时系统设计的概念。
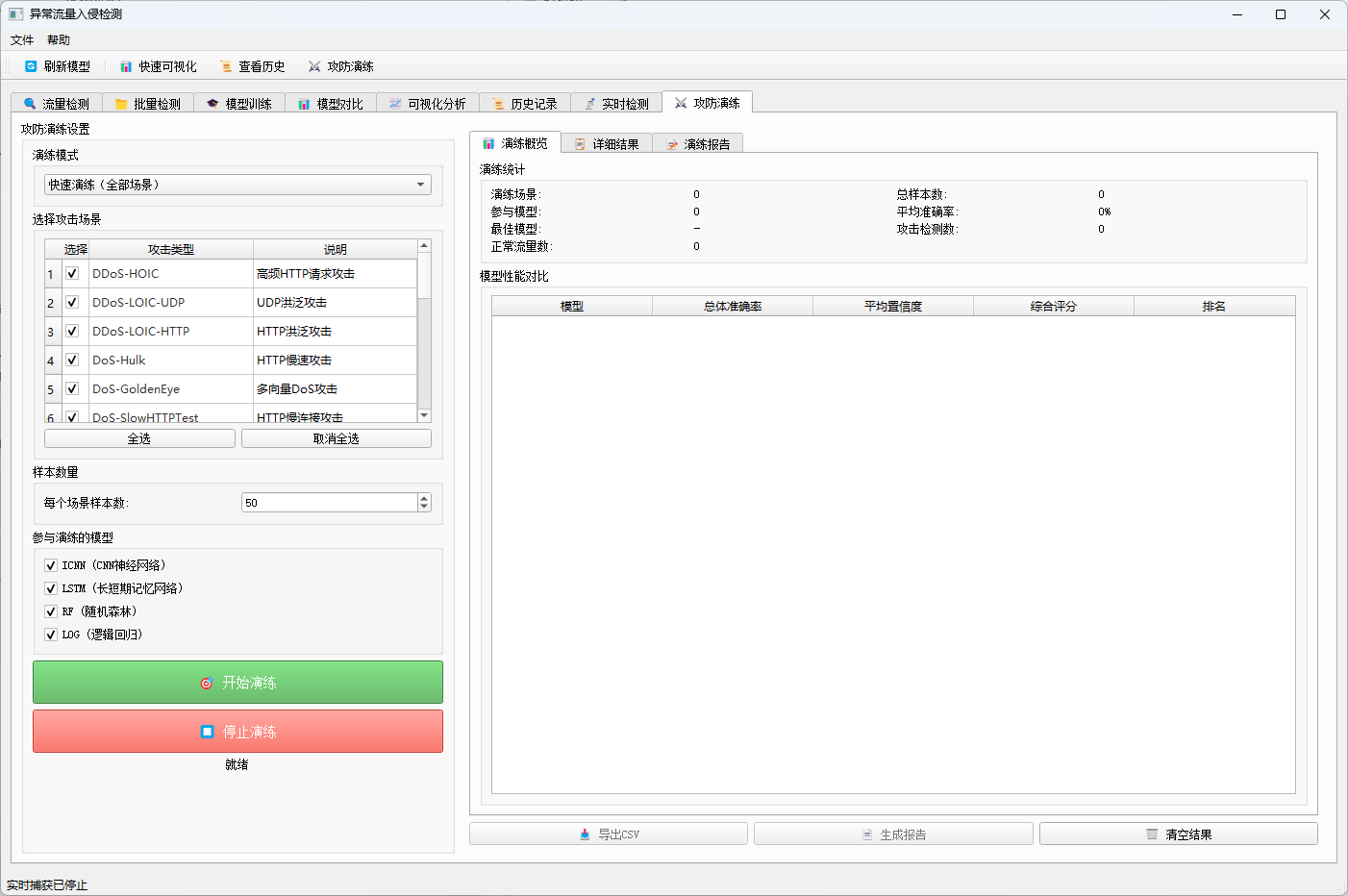
九、攻防演练模块:场景模拟与模型评估
攻防演练模块是 v3.0 版本新增的另一大亮点。传统的模型评估通常只关注测试集上的准确率、F1 值等指标,但这些指标无法直接反映模型在面对具体攻击类型时的表现。攻防演练模块通过模拟真实攻击场景,让用户能够针对性地评估每种模型在不同攻击下的检测能力。
9.1 设计目标
攻防演练模块的设计目标包括:
- 场景化评估:不再只看整体指标,而是针对 DDoS、DoS、暴力破解、Web 攻击等具体场景分别评估。
- 多模型对比:同时使用 ICNN、LSTM、RF、LOG 四种模型进行检测,直观对比各自优势。
- 真实数据支撑:演练数据直接从 CSE-CIC-IDS2018 数据集加载,保证场景的真实性。
- 综合评分排名:结合准确率和置信度生成综合评分,给出模型排名。
- 报告导出:支持导出 CSV 和文本报告,便于后续分析和论文撰写。
9.2 16 种攻击场景分类
core/attack_scenario.py 中定义了 16 种演练场景,涵盖了常见的网络攻击类型:
| 攻击类别 | 包含场景 |
|---|---|
| DDoS 攻击 | DDoS-HOIC、DDoS-LOIC-UDP、DDoS-LOIC-HTTP |
| DoS 攻击 | DoS-Hulk、DoS-GoldenEye、DoS-SlowHTTPTest、DoS-Slowloris |
| 僵尸网络 | Bot |
| 端口扫描 | PortScan |
| 暴力破解 | SSH-Patator、FTP-Patator |
| Web 攻击 | Web Attack-SQLInjection、Web Attack-XSS、Web Attack-BruteForce |
| 其他攻击 | Infiltration、Heartbleed |
| 正常流量 | BENIGN |
这些场景在 AttackSimulator 类中以字典形式维护,每个场景映射到 CSE-CIC-IDS2018 数据集中对应的原始标签:
python
SCENARIOS = {
'DDoS-HOIC': ('DDOS attack-HOIC', 50),
'DDoS-LOIC-UDP': ('DDOS attack-LOIC-UDP', 50),
'DDoS-LOIC-HTTP': ('DDoS attacks-LOIC-HTTP', 50),
'DoS-Hulk': ('DoS attacks-Hulk', 50),
'DoS-GoldenEye': ('DoS attacks-GoldenEye', 50),
# ... 其他场景
}需要注意的是,CSE-CIC-IDS2018 数据集中并没有单独的 PortScan 和 Heartbleed 文件。对于这两个场景,AttackSimulator 会返回空 DataFrame,并在 UI 中将其标记为"无数据",避免误导用户。
9.3 从真实数据集加载样本
与使用随机数生成伪数据不同,攻防演练模块直接从真实数据集中加载攻击样本。generate_scenario 方法会根据场景名称找到对应的原始标签,然后调用 IDS2018DataLoader.load 加载指定数量的样本:
python
@classmethod
def generate_scenario(cls, scenario_name: str, num_samples: int = 100) -> pd.DataFrame:
category, default_n = cls.SCENARIOS[scenario_name]
if category is None:
if scenario_name == 'BENIGN':
loader = IDS2018DataLoader()
df = loader.load_benign(n=num_samples or default_n)
return df
return pd.DataFrame(columns=FEATURE_COLUMNS + ["Label"])
loader = IDS2018DataLoader()
n = num_samples if num_samples else default_n
df = loader.load(category, n=n)
return df这种方式确保了演练数据与训练数据来自同一分布,评估结果更具参考价值。
9.4 演练执行流程
gui/drill_tab.py 中的 DrillThread 负责在后台执行攻防演练。其核心流程如下:
- 遍历用户选中的攻击场景列表。
- 对每个场景调用
AttackSimulator.generate_scenario加载样本。 - 使用每个选中的模型对样本进行检测。
- 统计每个模型的正确检测数、准确率、平均置信度和推理时间。
- 通过信号将进度和结果发送给主界面。
- 所有场景完成后,生成综合报告。
python
def run(self):
for i, scenario in enumerate(self.scenarios):
self.progress_updated.emit(
int(processed / total_samples * 100),
f"正在演练: {scenario}..."
)
data = self.simulator.generate_scenario(scenario, self.samples_per_scenario)
if data is None or len(data) == 0:
continue
scenario_results = {'true_label': scenario, 'samples': len(data), 'detections': {}}
for model_name in self.selected_models:
result = self.engine.predict(model_name, data)
predicted_labels = result.get_predicted_labels()
correct = sum(1 for p in predicted_labels if self._is_correct_detection(scenario, p))
scenario_results['detections'][model_name] = {
'correct': correct,
'total': len(predicted_labels),
'accuracy': correct / len(predicted_labels),
'avg_confidence': np.mean(result.get_confidence_scores()),
'inference_time': result.inference_time
}
self.results[scenario] = scenario_results
self.scenario_completed.emit(scenario, scenario_results)9.5 正确性判定:严格场景到标签映射
攻防演练中,正确性判定是一个容易出错的地方。早期版本曾采用"只要预测为非 Benign 就算正确"的兜底规则,这会导致所有模型在攻击场景上都获得虚高准确率。v3.0 改为严格的场景到标签映射:
python
def _is_correct_detection(self, scenario: str, predicted_label: str) -> bool:
scenario_mapping = {
'DDoS-HOIC': ['DDOS attack-HOIC'],
'DDoS-LOIC-UDP': ['DDOS attack-LOIC-UDP'],
'DDoS-LOIC-HTTP': ['DDoS attacks-LOIC-HTTP'],
'DoS-Hulk': ['DoS attacks-Hulk'],
# ... 其他映射
'BENIGN': ['Benign'],
}
expected_labels = scenario_mapping.get(scenario, [])
predicted_norm = predicted_label.strip().lower()
return any(predicted_norm == exp.strip().lower() for exp in expected_labels)严格的映射使得评估结果更加客观,也更能反映模型对具体攻击类型的识别能力。
9.6 演练结果统计与模型排名
每个场景检测完成后,系统会汇总各模型的表现。在演练概览页中,用户可以看到:
- 演练场景数、总样本数、参与模型数。
- 各模型的总体准确率、平均置信度、综合评分和排名。
- 攻击检测数、正常流量数等统计信息。
综合评分采用准确率占 70%、平均置信度占 30% 的加权方式:
python
model_scores[model_name] = {
'accuracy': overall_acc,
'avg_confidence': avg_conf,
'score': overall_acc * 0.7 + avg_conf * 0.3
}
sorted_models = sorted(model_scores.items(), key=lambda x: x[1]['score'], reverse=True)这种评分方式既考虑了模型的识别能力,也考虑了模型对自身预测的自信程度。
9.7 演练报告生成与导出
DrillReportGenerator 类负责生成文本报告和导出 CSV。文本报告包含演练时间、场景数、参与模型数、各场景详细结果以及模型综合排名:
python
@staticmethod
def generate_summary(results: dict) -> str:
report = []
report.append("=" * 60)
report.append("攻防演练报告摘要")
report.append("=" * 60)
report.append(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
# ... 详细内容
return "\n".join(report)CSV 导出则以表格形式记录每个场景、每个模型的正确检测数、总样本数、准确率、平均置信度和推理时间,方便用户在 Excel 或 Python 中进一步分析。
9.8 演练界面设计
攻防演练页的界面分为左侧控制面板和右侧结果面板。控制面板包含:
- 演练模式选择:快速演练(全部场景)、自定义场景演练、单一攻击演练。
- 攻击场景列表:以表格形式展示 16 种场景,支持复选框选择。
- 样本数量设置:每个场景的样本数,范围为 10 到 500。
- 模型选择:勾选参与演练的模型。
- 控制按钮:开始演练、停止演练。
右侧结果面板包含三个标签页:
- 演练概览:展示总体统计和模型排名对比表。
- 详细结果:展示每个场景下各模型的检测准确率。
- 演练报告:展示自动生成的文本报告。
9.9 演练评估指标设计
攻防演练模块的评估指标不仅包括准确率,还综合考虑了置信度和推理时间,力求全面反映模型表现。
准确率(Accuracy):最基本的指标,表示模型正确识别的样本比例。其计算公式为:
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
其中, T P TP TP 为真正例, T N TN TN 为真负例, F P FP FP 为假正例, F N FN FN 为假负例。在攻防演练中,由于每个场景的真实标签是已知的,因此可以直接统计正确检测数。
平均置信度(Average Confidence):模型对预测结果的平均自信程度。高准确率但低置信度可能意味着模型在"猜测",而高置信度则表明模型对特征有较强的把握。
综合评分(Score):项目采用准确率占 70%、置信度占 30% 的加权评分。这一权重的设定考虑了实际应用中对检测准确性的优先需求,同时也不忽视模型稳定性。
推理时间(Inference Time):反映模型的响应速度。对于需要实时处理的场景,推理时间是一个关键指标。
9.10 与传统评估方式的对比
传统的模型评估通常将数据集随机划分为训练集和测试集,然后计算整体准确率、精确率、召回率和 F1 值。这种方式能够反映模型的综合性能,但无法揭示模型在具体攻击类型上的表现差异。
攻防演练模块则采用场景化评估,将测试数据按攻击类型分组,分别计算每个场景下的检测准确率。这种方式的优势在于:
- 定位模型短板:可以直观发现模型在哪些攻击类型上表现较差。
- 指导模型优化:针对表现差的场景,可以收集更多样本、设计更专门的特征或调整模型结构。
- 符合实际安全需求:安全人员更关心模型能否识别特定攻击,而不是一个笼统的准确率数字。
9.11 演练模块的扩展性
攻防演练模块的设计具有良好的扩展性。如果未来需要增加新的攻击场景,只需要在 AttackSimulator.SCENARIOS 中添加新的映射,并确保数据集中存在对应的原始标签即可。UI 中的场景列表会自动从 get_scenarios_by_category 方法获取,无需手动修改界面代码。
此外,演练模块还可以扩展为支持自定义数据集。只要新的数据集提供了与 FEATURE_COLUMNS 一致的特征列和 Label 标签列,就可以通过修改数据加载器将其集成到演练流程中。
9.12 攻防演练的实战价值
攻防演练模块不仅是模型评估工具,更是连接学术研究与应用实践的桥梁。它的价值体现在:
- 发现模型短板:通过分场景评估,可以直观发现哪些攻击类型容易被误判,为后续模型优化指明方向。
- 验证模型鲁棒性:使用真实攻击样本进行测试,比简单划分训练/测试集更能反映模型能力。
- 支持论文写作:演练报告和 CSV 导出为毕业设计论文提供了可直接引用的实验数据。
- 教学演示:帮助学生理解不同模型在不同攻击类型上的表现差异。
十、系统测试与性能评估
10.1 测试环境
本项目的主要测试环境如下:
| 项目 | 配置 |
|---|---|
| 操作系统 | Windows 10/11 |
| CPU | Intel Core i5/i7 或同等性能 |
| 内存 | 16GB |
| Python | 3.8 - 3.12 |
| PyTorch | ≥1.12.0 |
| GPU | 可选,NVIDIA 显卡可加速深度学习推理 |
10.2 各模型性能对比
在 CSE-CIC-IDS2018 数据集上,各模型的测试性能如下表所示:
| 模型 | 测试准确率 | 推理速度 | 适用场景 |
|---|---|---|---|
| ICNN | 约 98% | 中等 | 高精度离线检测 |
| LSTM | 约 97% | 较慢 | 需要时序建模的场景 |
| 随机森林 | 89.81% | 快 | 快速检测与可解释分析 |
| 逻辑回归 | 85.97% | 最快 | 基线对比与轻量部署 |
其中,ICNN 和 LSTM 为早期训练的深度学习模型,v3.0 虽然统一了归一化策略,但建议后续使用修复后的流程重新训练深度学习模型,以进一步释放其性能潜力。随机森林和逻辑回归在 v3.0 中已重新训练,准确率从 v2.0 的约 70% 分别提升至 89.81% 和 85.97%。
10.3 实时检测性能
实时检测性能受网络带宽、捕获过滤器、模型复杂度等多因素影响。在典型实验环境下,系统可以达到以下指标:
- 捕获速率:每秒数百至数千个数据包,取决于网卡性能和过滤条件。
- 检测延迟:从流成熟到结果展示通常在秒级以内,深度学习模型略慢于传统机器学习模型。
- 资源占用:CPU 占用率在中等水平,GPU 可显著降低 ICNN/LSTM 的推理延迟。
10.4 攻防演练测试结果示例
在攻防演练中,不同模型对不同攻击类型的检测能力存在明显差异。一般来说:
- DDoS/DoS 攻击:ICNN、LSTM、RF 均能达到较高准确率,因为这类攻击的流量特征非常显著。
- 暴力破解:RF 和 LSTM 表现较好,能够识别短连接 burst 模式。
- Web 攻击:由于样本较少且特征与正常流量接近,各模型准确率相对较低。
- Infiltration、Heartbleed:样本稀缺,模型学习不充分,检测难度较大。
10.5 检测难度较大的攻击类型分析
从实验结果来看,以下几类攻击的检测难度较大:
- Web Attack:包括 SQL 注入、XSS 和 Web 暴力破解。这些攻击在流量层面的特征不如 DDoS 明显,且部分行为与正常 Web 访问相似。
- Infiltration:渗透攻击通常具有隐蔽性,流量规模小、持续时间长,难以与正常通信区分。
- Heartbleed:CSE-CIC-IDS2018 数据集中该攻击样本极少,模型难以充分学习其特征。
针对这些难点,未来可以考虑引入更细粒度的特征、使用生成对抗网络进行数据增强,或采用异常检测思路辅助识别。
10.6 测试结果的可复现性
为了保证测试结果的可复现性,项目在所有涉及随机性的环节都设置了固定的随机种子。例如,训练时的 train_test_split 使用 random_state=42 或 random_state=50,随机森林和逻辑回归也设置了 random_state。固定的随机种子使得不同运行之间的结果具有可比性,也便于在论文中报告具体数值。
此外,项目在保存模型时同时保存了 scaler 和 label_encoder,确保推理时的预处理与训练完全一致。这些细节的把控,是模型从"实验室可用"走向"工程可用"的关键。
十一、项目总结与展望
11.1 项目亮点总结
本项目从毕业设计出发,逐步演进为一个功能较为完整的恶意流量检测平台。其主要亮点包括:
- 多模型混合架构:集成 ICNN、LSTM、随机森林、逻辑回归四种模型,兼顾精度与速度。
- 统一检测引擎:自动加载模型、统一预处理、支持多模型批量预测和集成学习。
- PyQt5 可视化平台:八大功能 Tab、多线程设计、丰富的可视化图表,降低使用门槛。
- v3.0 实时检测优化:六项关键优化显著降低误报率,提升实时检测可用性。
- 攻防演练模块:16 种攻击场景、多模型对比、报告导出,为模型评估提供新维度。
- 数据预处理一致性 :统一使用
FEATURE_COLUMNS和 StandardScaler,消除训练与推理不一致问题。
11.2 v2.0 到 v3.0 的演进经验
v2.0 到 v3.0 的演进过程中,最重要的经验教训是:训练与推理的一致性至关重要。很多模型在测试集上表现优异,但在实际应用中效果不佳,往往不是因为模型本身不好,而是因为特征提取、归一化方式、标签编码等预处理环节存在差异。
另一个重要经验是:实时系统需要专门的设计。离线检测可以假设数据已经完整,而实时检测必须处理流的不完整性、特征的不稳定性以及结果的动态更新。流成熟度门槛、增量重新检测、恶意流去重等机制都是针对这些挑战的工程化解决方案。
11.3 遇到的问题与解决方案
问题一:实时检测误报率高
解决方案:对齐特征提取逻辑、统一归一化、提高流成熟度门槛、引入增量重新检测和三色展示体系。
问题二:训练与推理特征不一致
解决方案:所有训练路径统一使用 FEATURE_COLUMNS 按列名选取特征,统一使用 StandardScaler 单步归一化,并分别保存 scaler 和 label_encoder。
问题三:类别不平衡导致少数攻击检测能力差
解决方案:每类最多采样固定数量、使用 class_weight='balanced'、攻防演练中按场景平衡采样。
11.4 未来改进方向
尽管 v3.0 已经取得较大进步,但仍有许多可以改进的方向:
- 模型可解释性:引入 SHAP 或 LIME 等技术,解释模型为什么将某个流判定为攻击,提升用户信任度。
- Web 版本:将平台迁移为 B/S 架构,支持远程访问和多用户协作。
- 告警通知:增加邮件、短信、企业微信等告警通知方式。
- 联邦学习:在保护数据隐私的前提下,联合多个节点训练更鲁棒的模型。
- 异常检测:引入基于无监督学习的异常检测模块,识别未知攻击类型。
- 更丰富的特征:结合五元组、DNS 请求、TLS 指纹等信息,提升对加密流量的检测能力。
11.5 项目开发方法论
回顾整个项目的开发历程,可以总结出以下几点方法论层面的经验:
- 从简单到复杂:项目最初只实现了单个 CNN 模型的离线检测,随后逐步加入 LSTM、随机森林、逻辑回归、GUI、实时检测和攻防演练。这种渐进式开发有助于及时验证每个模块的可行性。
- 数据驱动决策:所有优化都基于实际运行中的问题。例如,实时检测的高误报率是通过反复抓包测试发现的,而不是凭空猜测。
- 重视一致性:训练与推理的一致性、特征提取的一致性、归一化策略的一致性,是保证模型在实际场景中表现稳定的基础。
- 用户视角验证:通过 GUI 和攻防演练模块,从用户视角验证系统功能,而不仅仅关注模型在测试集上的指标。
十二、附录:部署与使用指南
12.1 环境安装
推荐使用 Python 3.8 至 3.12 版本,并创建虚拟环境:
bash
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境(Windows)
venv\Scripts\activate
# 激活虚拟环境(Linux/Mac)
source venv/bin/activate
# 安装依赖
pip install torch torchvision PyQt5 scikit-learn pandas numpy matplotlib scapy joblib12.2 启动方式
确保数据集目录 CSE-CIC-IDS2018/ 和预训练模型目录(ICNNModel/、LSTMModel/、RandomForestModel/、LogisticRegressionModel/)已存在,然后运行:
bash
python main.py首次运行会自动初始化 SQLite 数据库。实时检测功能可能需要管理员权限。
12.3 快速开始
- 启动程序后,切换到"流量检测"标签页。
- 点击"随机加载样本"从 CSE-CIC-IDS2018 中加载均衡样本,或点击"加载CSV文件"导入自己的数据。
- 在左侧勾选需要使用的模型(ICNN、LSTM、RF、LOG)。
- 点击"开始检测",等待检测完成后在右侧表格查看结果。
12.4 模型训练
- 切换到"模型训练"标签页。
- 选择模型类型(ICNN/LSTM/RF/LOG)。
- 点击"选择训练数据"选择 CSV 文件。
- 配置训练参数,如训练轮数、批次大小、学习率等。
- 点击"开始训练",训练完成后模型会自动保存到对应目录。
12.5 批量检测
- 切换到"批量检测"标签页。
- 选择需要检测的多个 CSV 文件。
- 选择检测模型。
- 点击"开始批量检测",系统会逐个处理文件并汇总统计结果。
12.6 实时检测
- 切换到"实时检测"标签页。
- 选择网卡和捕获过滤器(默认
ip即可)。 - 选择检测模型和告警阈值。
- 点击"开始捕获",系统会实时显示捕获的数据流和检测结果。
- 点击"停止捕获"结束检测。
12.7 攻防演练
- 切换到"攻防演练"标签页。
- 选择演练模式,默认"快速演练"会选中所有有数据的场景。
- 勾选参与演练的模型。
- 设置每个场景的样本数。
- 点击"开始演练",完成后可在"演练概览"、"详细结果"、"演练报告"三个标签页查看结果。
- 点击"导出CSV"或"生成报告"保存结果。
12.8 数据集与参考资料
- CSE-CIC-IDS2018 数据集:可通过 CIC 官网或相关镜像站点下载。
- CICFlowMeter:用于从 PCAP 文件中提取 78 维流特征的工具。
- PyTorch 官方文档:https://pytorch.org/docs/
- Scapy 官方文档:https://scapy.readthedocs.io/
结语:本文完整记录了一个从算法研究到工程落地的恶意流量检测平台的构建过程。v3.0 版本通过修复训练与推理一致性、优化实时检测流程、新增攻防演练模块,使平台在可用性和评估维度上都得到了显著提升。希望本文能够为网络安全方向的学习者和实践者提供有价值的参考,也期待更多开发者在此基础上继续探索和改进。