Action Chunking with Transformers 精读:低成本双臂机器人的精细操作革命
论文信息
标题 :Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
会议 :Robotics: Science and Systems (RSS) 2023
单位 :Stanford University、UC Berkeley、Meta
一、研究背景:精细操作的"高端病"
机器人做抓取、搬运这种粗活已经很成熟了,但一碰到毫米级的精细操作就"手残"------比如穿扎带、撬杯盖、装电池,既要精准的手眼协调,又要细腻的力接触配合,还要实时闭环反馈。
过去解决这个问题的思路很简单粗暴:堆钱。用几十万的工业机械臂、高精度力传感器、激光跟踪仪,再加上专人校准调试,才能勉强搞定。这就像做精密零件全靠进口五轴机床,普通实验室和小公司根本玩不起。
那能不能换个思路:硬件不够,算法来凑?用几千块的廉价机械臂,靠优秀的模仿学习算法,补上硬件精度的短板,也能完成精细操作?
这篇论文就干成了这件事:
- 搭了一套总成本不到2万美元的双臂遥操作平台 ALOHA,普通人2小时就能组装完成;
- 提出了全新的模仿学习算法 ACT(Action Chunking with Transformers),只用10分钟左右的人类演示数据,就能让这套廉价硬件完成6种精细操作,成功率高达80%-90%。
打个通俗的比方:这就像以前你打电竞必须买上万的旗舰外设,现在有人告诉你,用两百块的入门键鼠,配上优化到极致的操作逻辑,也能打上王者段位。
二、ALOHA:两万刀打造的双臂遥操作神器
要做模仿学习,首先得有高质量的演示数据。论文团队没有用昂贵的动捕设备或者力反馈手套,而是做了一套"主从机械臂"的遥操作方案:你拖动机型更小的主臂,大一点的从臂就会跟着复刻动作。
2.1 设计五大原则
整个硬件设计围绕5个核心目标:
- 低成本:总价对标单台科研机械臂,普通实验室也能负担
- 多功能:能覆盖绝大多数日常精细操作场景
- 易上手:不用复杂培训,普通人很快就能熟练操作
- 易维修:零件都是现成货,坏了自己就能换
- 搭建快:全是现成模块+3D打印件,2小时就能拼完
2.2 硬件配置详情
系统采用"两主两从"共4台机械臂的方案:
- 从臂(干活的):2台 ViperX 6自由度机械臂,单台约5600美元,重复精度1mm,绝对精度5-8mm,负载750g。搭配自研3D打印透明夹爪,既能看清操作细节,又能夹稳薄塑料件。
- 主臂(遥控的):2台更小的 WidowX 机械臂,单台约3300美元,人可以直接拖动,关节和从臂一一对应。
- 视觉系统:4台罗技C922x摄像头,2台装在从臂手腕上(近距离看细节),2台固定在正面和顶部(全局视角),分辨率480×640,30帧。
- 控制频率:50Hz,也就是每秒更新50次动作,保证操作丝滑。
整个系统算上框架、3D打印件、摄像头,总价不到2万美元,和一台Franka Panda科研机械臂差不多,但能完成的精细任务多得多。
通俗备注:为什么不用VR手柄或者视觉动捕?因为廉价机械臂很容易碰到奇异点(类似你胳膊拧到极限的状态),逆运动学算不出来直接卡死。用关节空间一一映射,相当于直接"抄作业",不用算复杂的运动学,延迟低、不翻车,还能自然过滤人手的轻微抖动。
2.3 系统能力展示
图1是ALOHA系统的概览,左边是用户遥操作主臂的场景,右边是系统能完成的任务示例。

图1 ALOHA双臂遥操作系统概览(出自原文Figure 1)
从图中可以看到,这套系统不仅能做穿扎带、NIST装配板这种接触丰富的高精度任务,甚至还能颠乒乓球这种动态任务。论文里提到,其中不少任务是以往10倍价格的遥操作系统才能实现的。
三、ACT算法:用动作分块根治模仿学习的"累积误差病"
硬件搞定了,接下来是核心难题:模仿学习的累积误差。
普通的行为克隆(BC)是"走一步看一步":当前观测输入模型,输出下一步动作。但只要有一步预测偏了一点点,下一个观测就不在训练数据分布里了,误差会越滚越大,最后彻底跑偏------就像新手开车走直线,方向盘稍微歪一点,车就越来越偏,最后冲出车道。精细操作对误差容忍度只有几毫米,这个问题尤其致命。
ACT的核心思路就是:别一步一步预测,一次性预测未来k步的动作序列(动作分块),再通过时序融合让动作丝滑起来,相当于开车的时候提前看好几百米的路,一次性规划好方向盘操作,自然不容易跑偏。
3.1 核心设计1:动作分块(Action Chunking)
公式定义
普通单步策略的建模方式:
πθ(at∣st)\pi_\theta(a_t \mid s_t)πθ(at∣st)
ACT的动作分块策略建模方式:
πθ(at:t+k∣st)\pi_\theta(a_{t:t+k} \mid s_t)πθ(at:t+k∣st)
字母逐项解释:
- πθ\pi_\thetaπθ:参数为θ\thetaθ的策略神经网络
- ata_tat:第ttt时刻的动作,本文中是双臂14个关节的目标角度,14维向量
- sts_tst:第ttt时刻的观测,包含4路RGB图像+双臂当前关节位置
- kkk:分块大小,也就是一次预测的未来动作步数
- at:t+ka_{t:t+k}at:t+k:从第ttt时刻到第t+kt+kt+k时刻,连续kkk个动作组成的序列
通俗备注:这就像你玩闯关游戏,普通BC是走一步看一步,前面有坑才反应跳,经常来不及掉下去;动作分块是你一眼扫完前面的地形,一次性规划好接下来10步的跳跃、移动、转向,容错率直接拉满。任务的有效长度相当于缩短到原来的1/k1/k1/k,累积误差自然大幅降低。
除此之外,动作分块还能解决人类演示里的"非马尔可夫问题"------比如人操作中间会停顿、会微调,单步模型搞不懂为什么不动,动作分块就能把停顿包含在一个块里,不会乱输出。
3.2 核心设计2:时序集成(Temporal Ensembling)
如果每kkk步才观测一次环境、更新一次动作,机器人的动作会一顿一顿的,像卡帧了一样。为了解决这个问题,ACT提出了时序集成:
每一个时间步都预测一次完整的动作块,这样同一个时刻的动作会被多次预测到,把这些预测结果加权平均,就能得到既精准又平滑的动作。
权重计算公式
wi=exp(−m⋅i)w_i = \exp(-m \cdot i)wi=exp(−m⋅i)
字母逐项解释:
- wiw_iwi:第iii个历史预测对应的权重
- exp\expexp:自然指数函数
- mmm:衰减系数,控制新观测的融入速度,mmm越小,新预测的权重占比越高,动作响应越快
- iii:预测的时间偏移量,i=0i=0i=0对应最早的预测,iii越大对应越新的预测
加权平均的时候,所有权重会做归一化,保证总和为1。和普通的时域平滑不同,这里平均的是不同时刻预测的同一个时间步的动作,不会引入滞后偏差。
通俗备注:这就像你开车的时候,不会只盯着眼前这一秒的路打方向,而是会结合前几秒对路线的判断,综合调整方向盘,开出来的轨迹又稳又顺,不会一顿一顿的。
3.3 核心设计3:CVAE建模人类演示的多样性
人类演示不是标准答案------同一个任务,不同的人做轨迹不一样,同一个人做两次也不一样。如果用普通的均方误差损失训练,模型会学一个"平均轨迹",结果就是哪都不挨哪,精度直接崩。
ACT用条件变分自编码器(CVAE) 把策略建模成生成模型,专门处理人类演示的多模态性。
总损失函数
L=Lreconst+β⋅Lreg\mathcal{L} = \mathcal{L}{\text{reconst}} + \beta \cdot \mathcal{L}{\text{reg}}L=Lreconst+β⋅Lreg
字母逐项解释:
- L\mathcal{L}L:模型总训练损失
- Lreconst\mathcal{L}_{\text{reconst}}Lreconst:重构损失,衡量预测动作序列和真实演示序列的误差,论文用L1损失(平均绝对误差),比L2对离群点更不敏感,更适合精细操作
- β\betaβ:正则项权重超参数,控制隐空间的"信息瓶颈",β\betaβ越大,隐变量携带的信息越少,模型输出越保守
- Lreg\mathcal{L}{\text{reg}}Lreg:KL散度正则项,约束隐变量的分布接近标准正态分布,公式如下:
Lreg=DKL(qϕ(z∣at:t+k,oˉt)∥N(0,I))\mathcal{L}{\text{reg}} = D_{\text{KL}}\left(q_\phi(z \mid a_{t:t+k}, \bar{o}_t) \parallel \mathcal{N}(0, I)\right)Lreg=DKL(qϕ(z∣at:t+k,oˉt)∥N(0,I))- DKLD_{\text{KL}}DKL:KL散度,衡量两个概率分布的差异程度
- qϕq_\phiqϕ:CVAE编码器网络,参数为ϕ\phiϕ,输入真实动作序列和本体觉观测,输出隐变量的概率分布
- zzz:32维的风格隐变量,用来编码人类演示的操作风格差异(比如快慢、左右手偏好)
- oˉt\bar{o}_toˉt:不含图像的观测,也就是双臂的关节位置
- N(0,I)\mathcal{N}(0, I)N(0,I):标准正态分布,均值为0,协方差为单位矩阵III
训练的时候,编码器从真实演示里提取风格隐变量zzz,解码器根据当前观测+zzz生成对应的动作序列。测试的时候,直接把zzz设为0(标准正态分布的均值,也就是平均风格),就能输出最稳定、精度最高的动作。
通俗备注:CVAE相当于给模型装了个"风格调节器"。训练的时候它会看懂"原来这个任务有好几种操作方式",不会硬把所有轨迹揉成一团四不像;测试的时候用默认的"稳妥风格",输出最靠谱的动作,不会乱飘。
3.4 Transformer架构实现
动作序列建模天然适合用Transformer,论文用Transformer实现了CVAE的编码器和解码器,完整架构如图2所示。
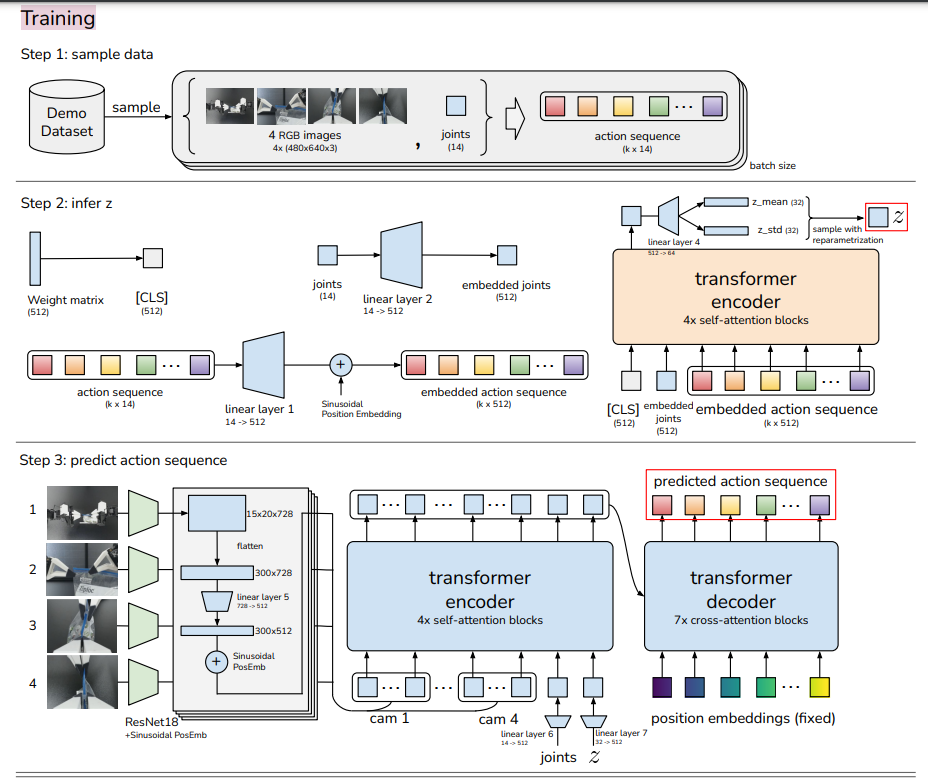
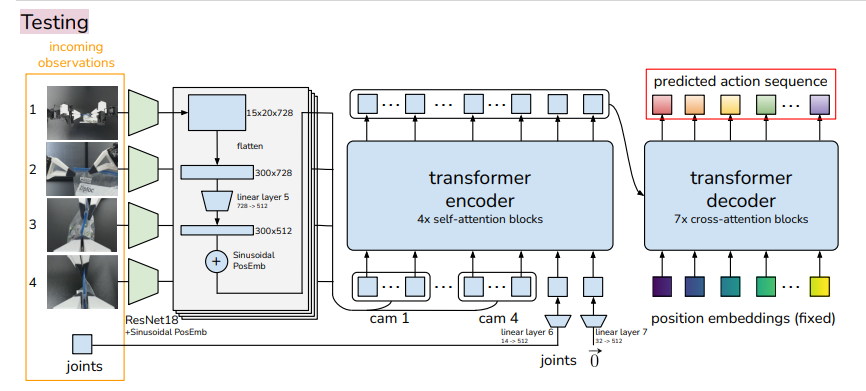
图2 ACT网络架构详情(出自原文Figure 11)
整个网络的推理流程可以分成三步:
- 视觉特征提取:4路图像分别过ResNet18 backbone,提取空间特征,加上二维正弦位置编码,拉平成序列。
- Transformer编码器 :把4路图像特征、关节位置特征、隐变量zzz拼接成一个长序列,通过自注意力融合所有模态的信息。
- Transformer解码器 :输入固定长度的动作位置编码(对应kkk个动作步),通过交叉注意力关注编码器的输出,一次性生成未来kkk步的动作序列。
整个模型约8000万参数,单张11G显存的RTX 2080Ti训练5小时就能完成一个任务,单步推理仅需0.01秒,完全满足50Hz的实时控制要求。
四、实验结果:碾压级的性能提升
论文一共做了8个任务:2个模拟任务+6个真实世界任务,每个任务仅用50条演示(约10分钟操作)训练,和4个主流基线方法做对比。
4.1 任务设置
真实世界的6个任务全是需要毫米级精度的双手操作:
- 开密封袋、装电池、开调料杯、穿魔术贴扎带、剪胶带粘贴、给假脚穿鞋
每个任务都拆成2-4个子步骤,分别统计成功率,更能看出误差累积的影响。
4.2 基线方法
- BC-ConvMLP:最基础的行为克隆,卷积网络提图像特征+MLP输出单步动作
- BeT:Behavior Transformer,当时的模仿学习SOTA,用Transformer+离散动作空间
- RT-1:谷歌的机器人Transformer,大规模预训练的单步预测模型
- VINN:非参数近邻方法,靠检索最相似的观测输出动作
4.3 核心结果分析
表1是2个模拟任务+2个真实任务的完整成功率对比。
表1 模拟与真实任务成功率对比(出自原文Table I)
| 方法 | 模拟方块传递 | 模拟轴孔插入 | 真实开密封袋 | 真实装电池 |
|---|---|---|---|---|
| BC-ConvMLP | 17% | 0% | 1% | 0% |
| BeT | 51% | 1% | 4% | 0% |
| RT-1 | 33% | 0% | 0% | 0% |
| VINN | 9% | 0% | 1% | 0% |
| ACT(本文) | 90% | 50% | 90% | 96% |
从数据里能看到非常夸张的差距:
- 基线方法几乎全崩:真实任务里,所有基线方法基本卡在第一个子步骤,后续步骤成功率全是0,就是因为累积误差让机器人很快就偏离了正常状态。
- ACT碾压式领先:模拟任务比最好的基线高20%-59%,真实任务直接从个位数拉到90%+。
- 对人类数据鲁棒性强:从脚本数据换成人类演示数据,所有方法都掉点,但ACT掉点最少,说明CVAE确实有效处理了人类演示的噪声。
表2是剩下4个更难的真实任务的结果,只和表现最好的基线BeT对比。
表2 剩余真实任务成功率对比(出自原文Table II)
| 方法 | 开调料杯 | 穿魔术贴扎带 | 剪胶带粘贴 | 穿鞋 |
|---|---|---|---|---|
| BeT | 0% | 0% | 0% | 0% |
| ACT(本文) | 84% | 20% | 64% | 92% |
可以看到,难度更高的任务里,基线方法直接零成功,ACT依然能拿到不错的成功率。其中穿扎带最难,只有20%------因为黑色扎带在黑色背景上占比极小,视觉感知难度太大,每一步的小误差都会累积到最后插不进去。
五、消融实验:拆开看看每个模块到底有用没用
为了验证每个设计的必要性,论文做了详细的消融实验,结果如图3所示。
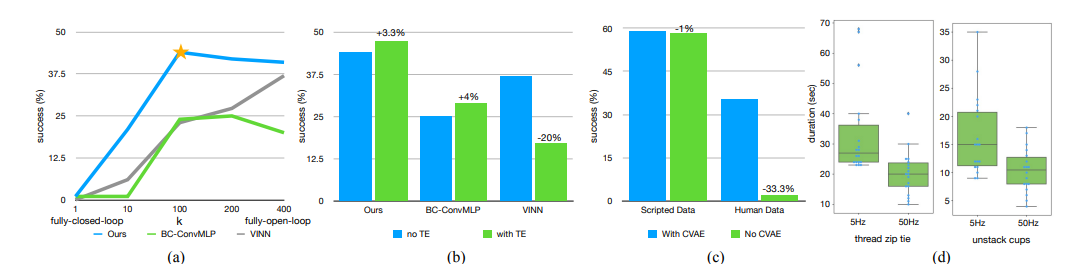
图3 消融实验结果(出自原文Figure 8)
5.1 动作分块大小k的影响(图a)
- k=1k=1k=1就是普通单步预测,成功率只有1%,几乎全失败;
- 随着kkk增大,成功率快速上升,到k=100k=100k=100时达到峰值44%;
- kkk继续增大到200、400,成功率反而轻微下降------因为分块太大就接近开环控制了,失去了闭环反馈的修正能力。
更有意思的是,把动作分块加到BC和VINN这两个基线方法上,它们的性能也大幅提升。说明动作分块是个通用技巧,不是ACT专属,只要用了就能缓解累积误差。
5.2 时序集成的作用(图b)
- ACT加上时序集成,成功率涨了3.3%,动作也更平滑;
- BC-ConvMLP涨了4%,收益更明显;
- VINN反而掉了20%------因为VINN是直接从数据集里取真实动作,本身没有预测噪声,加权平均反而引入了偏差。
结论:参数化模型有预测噪声,时序集成能平滑掉噪声;非参数方法本身精度高,就不需要了。
5.3 CVAE的必要性(图c)
- 用脚本生成的确定性数据训练时,加不加CVAE性能差不多;
- 用人类演示数据训练时,去掉CVAE成功率直接从35.3%掉到2%,几乎完全失效。
这直接证明了:CVAE是处理人类演示多模态性的核心,没有它,模型根本学不准人类的操作。
5.4 控制频率的影响(图d)
论文找了6个受试者,分别用5Hz和50Hz的控制频率做穿扎带、分杯子两个任务。结果50Hz比5Hz的完成时间快了62%,统计检验p值<0.001,差异极其显著。
通俗备注:这就像打游戏,60帧就是比30帧好操作,帧率越高,反馈越及时,精细操作越容易。高频控制是精细操作的基础,很多模仿学习工作只用到5Hz左右,自然做不了高精度任务。
六、核心代码实现
6.1 时序集成推理代码
这是ACT推理时最核心的逻辑,负责缓存历史动作块并加权输出平滑动作:
python
import numpy as np
import torch
class ACTTemporalEnsembler:
"""
ACT时序集成器:缓存历史预测的动作块,指数加权平均得到平滑动作
"""
def __init__(self, chunk_size: int, decay_m: float = 0.1):
self.chunk_size = chunk_size # 动作分块长度k
self.decay_m = decay_m # 指数衰减系数m
self.action_buffer = [] # 动作块缓存,每个元素是[chunk_size, action_dim]的张量
def push_chunk(self, action_chunk: torch.Tensor):
"""
存入新预测的动作块
action_chunk: 未来k步的动作序列,shape [chunk_size, action_dim]
"""
self.action_buffer.append(action_chunk)
# 缓存最多保留chunk_size个块,超出的丢弃最老的
if len(self.action_buffer) > self.chunk_size:
self.action_buffer.pop(0)
def get_current_action(self) -> torch.Tensor:
"""
计算当前时刻的加权平均动作
"""
current_preds = []
weights = []
buffer_len = len(self.action_buffer)
for idx_in_buffer, chunk in enumerate(self.action_buffer):
# 计算当前时刻动作在该块中的位置
step_in_chunk = buffer_len - 1 - idx_in_buffer
if step_in_chunk < len(chunk):
current_preds.append(chunk[step_in_chunk])
# 指数权重:越新的预测权重越高
weight = np.exp(-self.decay_m * (buffer_len - 1 - idx_in_buffer))
weights.append(weight)
# 权重归一化
weights = np.array(weights) / np.sum(weights)
weights = torch.tensor(weights, dtype=action_chunk.dtype, device=action_chunk.device)
# 加权平均得到最终动作
stacked_preds = torch.stack(current_preds, dim=0)
weighted_action = torch.einsum('i,id->d', weights, stacked_preds)
return weighted_action6.2 ACT策略网络核心结构
简化版的ACT解码器网络,展示Transformer生成动作序列的核心逻辑:
python
import torch
import torch.nn as nn
from torchvision import models
class ACTPolicy(nn.Module):
"""
ACT策略网络(CVAE解码器):输入多视角图像与关节角,输出未来k步动作序列
"""
def __init__(self, action_dim=14, chunk_size=100, hidden_dim=512, num_heads=8):
super().__init__()
self.action_dim = action_dim
self.chunk_size = chunk_size
self.hidden_dim = hidden_dim
# 图像特征提取 backbone
self.img_backbone = models.resnet18(pretrained=False)
self.img_backbone.fc = nn.Identity() # 去掉最后一层分类头
self.img_proj = nn.Linear(512, hidden_dim)
# Transformer 编码器:融合多视角图像、关节位置、隐变量z
encoder_layer = nn.TransformerEncoderLayer(
d_model=hidden_dim, nhead=num_heads, dim_feedforward=3200, dropout=0.1
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=4)
# Transformer 解码器:生成动作序列
decoder_layer = nn.TransformerDecoderLayer(
d_model=hidden_dim, nhead=num_heads, dim_feedforward=3200, dropout=0.1
)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=7)
# 动作查询位置编码(可学习)
self.action_queries = nn.Parameter(torch.randn(chunk_size, hidden_dim))
# 输出头:映射到动作维度
self.action_head = nn.Linear(hidden_dim, action_dim)
# 模态投影层
self.joint_proj = nn.Linear(14, hidden_dim)
self.z_proj = nn.Linear(32, hidden_dim)
def forward(self, imgs: torch.Tensor, joint_pos: torch.Tensor, z: torch.Tensor) -> torch.Tensor:
"""
前向传播
imgs: [batch, 4, 3, 480, 640] 4个摄像头的RGB图像
joint_pos: [batch, 14] 双臂关节角度
z: [batch, 32] 风格隐变量
return: [batch, chunk_size, 14] 预测的未来k步动作序列
"""
batch_size = imgs.shape[0]
# 1. 提取4路图像特征并拼接
img_feats = []
for cam_idx in range(4):
cam_img = imgs[:, cam_idx]
feat = self.img_backbone(cam_img) # [batch, 512]
# 注:完整实现会保留空间维度并加2D位置编码,此处做简化
feat = self.img_proj(feat).unsqueeze(1) # [batch, 1, hidden_dim]
img_feats.append(feat)
img_seq = torch.cat(img_feats, dim=1) # [batch, 4, hidden_dim]
# 2. 投影关节位置与隐变量
joint_emb = self.joint_proj(joint_pos).unsqueeze(1) # [batch, 1, hidden_dim]
z_emb = self.z_proj(z).unsqueeze(1) # [batch, 1, hidden_dim]
# 3. 拼接所有序列输入编码器
encoder_input = torch.cat([img_seq, joint_emb, z_emb], dim=1) # [batch, 6, hidden_dim]
# Transformer要求序列维度在前
encoder_input = encoder_input.transpose(0, 1) # [6, batch, hidden_dim]
memory = self.transformer_encoder(encoder_input)
# 4. 解码器生成动作序列
decoder_input = self.action_queries.unsqueeze(1).repeat(1, batch_size, 1) # [chunk_size, batch, hidden_dim]
decoder_output = self.transformer_decoder(decoder_input, memory) # [chunk_size, batch, hidden_dim]
# 5. 输出最终动作
action_seq = self.action_head(decoder_output.transpose(0, 1)) # [batch, chunk_size, action_dim]
return action_seq七、局限性与未来方向
再好的方案也有边界,论文也坦诚了当前的局限:
硬件层面
- 只有平行夹爪,没有灵巧手,做不了需要多手指配合的任务,比如开带卡扣的儿童药瓶;
- 电机扭矩有限,干不了需要大力气的活,比如拧很紧的密封瓶盖;
- 没有力觉传感器,全靠视觉,对需要精确力控制的任务(比如拧螺丝)支持不好。
算法层面
- 强依赖视觉感知,透明、反光、低对比度的物体容易翻车,比如拆糖纸找不到撕口;
- 单任务训练,每个任务要单独收集数据、单独训模型,不能零样本泛化新任务;
- 还是需要人类演示,不能自主探索学习。
八、全文总结
这篇论文是近年具身智能领域非常有影响力的工作,核心贡献可以归纳为两点:
- 把精细操作的硬件门槛打了下来:不到2万美元的开源方案,就能做以往几十万系统才能完成的任务,让更多实验室能参与到双臂操作研究里来。
- 用动作分块极大缓解了模仿学习的老大难问题:结合Transformer的序列建模能力和CVAE的生成式建模,用极少的演示数据就能实现高精度闭环操作,为机器人模仿学习提供了一个非常实用的范式。
后来的Mobile ALOHA、ACT++等工作,都是在这个基础上迭代出来的。某种意义上,它证明了一件事:不用堆昂贵的硬件,靠算法设计也能让廉价机器人拥有灵巧的操作能力------这正是机器人走进真实家庭、走进千行百业的必经之路。