构建基于 Node.js 的大语言模型对话系统:从无状态本质到上下文工程
- [1. 项目初始化与环境配置](#1. 项目初始化与环境配置)
-
- [1.1 依赖安装与项目初始化](#1.1 依赖安装与项目初始化)
- [1.2 环境变量安全管理](#1.2 环境变量安全管理)
- [2. 理解大语言模型的"无状态(Stateless)"本质](#2. 理解大语言模型的“无状态(Stateless)”本质)
- [3. 两种调用方式的直观代码对比](#3. 两种调用方式的直观代码对比)
-
- [3.1 版本 A:无记忆的独立请求](#3.1 版本 A:无记忆的独立请求)
- [3.2 版本 B:具备记忆模拟的上下文请求](#3.2 版本 B:具备记忆模拟的上下文请求)
- [4. 关键核心逻辑细致拆解](#4. 关键核心逻辑细致拆解)
-
- [4.1 环境配置与客户端初始化](#4.1 环境配置与客户端初始化)
- [4.2 记忆模拟的队列上演进机制(重点)](#4.2 记忆模拟的队列上演进机制(重点))
- [4.3 异步控制与异常捕获](#4.3 异步控制与异常捕获)
- [5. 对话历史(Chat History)管理的现实挑战](#5. 对话历史(Chat History)管理的现实挑战)
在构建现代人工智能应用时,理解大语言模型(LLM)的底层通信机制是至关重要的第一步。本文将聚焦于如何使用 Node.js 与大语言模型 API 进行交互,通过深入剖析 LLM 的"无状态"本质,对比有无历史上下文的调用差异,并详细讲解如何通过代码维护一个具备动态记忆的对话历史队列。
1. 项目初始化与环境配置
大语言模型 API 服务的本质是基于 HTTP 协议的算力提供形式。在开发前,我们需要通过规范的工程化步骤初始化项目,并妥善管理 API 密钥等敏感信息。
1.1 依赖安装与项目初始化
首先,在空白工作目录下执行以下命令以初始化项目并安装核心依赖:
bash
pnpm init
pnpm add openai dotenvpnpm init:创建package.json文件,初始化 Node.js 项目元数据。openai:官方提供的 SDK,用于简化与 OpenAI 兼容接口(如 DeepSeek、OpenAI 等)的 HTTP 请求构建与响应解析。dotenv:环境变量管理库,用于从本地配置文件中加载机密数据。
1.2 环境变量安全管理
在实际生产中,绝对不能将 API 密钥(API Key)硬编码在代码文件中。为此,我们需要在项目根目录下创建一个名为 .env 的文件,专门用于存储私密配置:
bash
DEEPSEEK_API_KEY=your_actual_api_key_here
DEEPSEEK_API_BASE_URL=https://api.deepseek.com/v1通过引入 .env 文件,不仅实现了代码与配置的分离,还防止了敏感凭证随代码仓库(如 GitHub)意外泄露的安全风险。
2. 理解大语言模型的"无状态(Stateless)"本质
在传统的 Web 开发中,HTTP 协议本身是无状态的(Stateless)。每一次 GET 或 POST 请求都是完全独立的,服务器不会主动保留上一次请求的任何客户端状态。如果需要识别用户身份,通常必须在请求头(Header)中携带 Cookie 或 Authorization Token。
大语言模型的运行底层同样严格遵循这一规则:
- 单次独立性:大模型服务器在接收到一条 Prompt(提示词)并计算生成结果后,其内存会立即释放该次请求的上下文。
- 服务器水平扩展:正因为无状态,后端服务器不需要在内存中维护成千上万用户的对话状态,请求被分发到任何一台算力服务器上运行,其结果都是等价的。这极大提升了高并发与高可用架构的调度效率。
然而,日常使用中如同人类般流畅的"连续对话"体验,实际上是一种在客户端(或应用后端)通过特定工程手段模拟出的"有状态"错觉。
3. 两种调用方式的直观代码对比
为了让读者切身感受到"无状态"对连续对话的影响,下面我们将分别展示无记忆的独立请求 与具备记忆模拟的上下文请求两种具体的实现代码。
3.1 版本 A:无记忆的独立请求
在此版本中,我们不维护任何外部历史队列。每次向大模型发送请求时,只传入当前那一句孤立的话。
javascript
import OpenAI from 'openai';
import { config } from 'dotenv';
config();
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL,
});
async function testStatelessWithoutHistory() {
console.log('第一次请求,告诉模型一个信息');
const response = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [
{ role: 'system', content: '你是一个严谨的助手' },
{ role: 'user', content: '请记住,我的名字叫moss' }
]
});
console.log('模型回复:', response.choices[0].message.content);
console.log('第二次请求,直接问我是谁');
const response2 = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [
{ role: 'user', content: '请问我的名字是什么?' }
]
});
console.log('模型回复:', response2.choices[0].message.content);
}
testStatelessWithoutHistory().catch(err => { console.error(err); });运行结果分析
在 版本 A 中,第二次请求发出的消息数组里只有一条孤零零的提问 请问我的名字是什么?。由于大模型 API 本身的无状态特性,服务器接收到该请求时,已经彻底遗忘了第一次请求中 "我的名字叫moss" 的记忆。因此,模型将无法正确回答该问题,通常会回复"对不起,我不知道您的名字"。
3.2 版本 B:具备记忆模拟的上下文请求
为了让模型拥有连续对话的能力,我们需要在客户端建立一个动态数组 chatHistory。每次对话时,都将完整的历史记录作为参数传递给 API。
javascript
import OpenAI from 'openai';
import { config } from 'dotenv';
config();
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL,
});
// 初始化对话历史队列,确立系统角色
const chatHistory = [
{ role: 'system', content: '你是一个严谨的助手' }
];
async function testStatelessWithHistory() {
console.log('第一次请求,告诉模型一个信息');
// 1. 将用户的第一次提问推入历史队列
chatHistory.push({
role: 'user',
content: '请记住,我的名字叫moss'
});
// 2. 发起第一次 API 调用,传递完整队列
const response = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: chatHistory
});
// 3. 将模型的第一次回复推入历史队列
chatHistory.push({
role: 'assistant',
content: response.choices[0].message.content
});
console.log('模型回复:', response.choices[0].message.content);
console.log('第二次请求,直接问我是谁');
// 4. 将用户的第二次提问推入历史队列
chatHistory.push({
role: 'user',
content: '请问我的名字是什么?'
});
// 5. 发起第二次 API 调用,同样传递完整队列
const response2 = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: chatHistory
});
// 6. 将模型的第二次回复推入历史队列
chatHistory.push({
role: 'assistant',
content: response2.choices[0].message.content
});
console.log('模型回复:', response2.choices[0].message.content);
console.log('chatHistory',chatHistory);
}
testStatelessWithHistory().catch(err => { console.error(err); });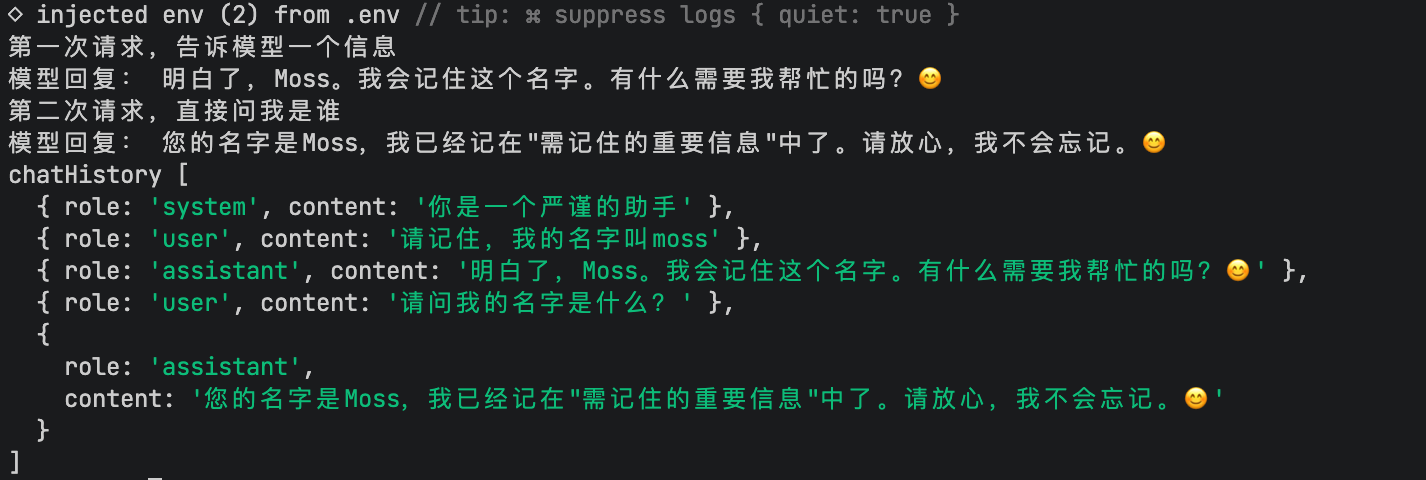
4. 关键核心逻辑细致拆解
4.1 环境配置与客户端初始化
两个版本均在顶层调用了 config(),这是 dotenv 库的核心方法。它负责读取根目录下的 .env 文件,并将变量注入到 Node.js 进程的 process.env 对象中。在初始化 new OpenAI 实例时,采用 process.env.DEEPSEEK_API_KEY 动态赋值,实现了密钥的安全隔离。
4.2 记忆模拟的队列上演进机制(重点)
在 版本 B 中,程序通过对 chatHistory 数组的动态操作,成功在无状态的协议之上模拟出了"有状态"的连续对话:
- 用户提问入栈:
javascript
chatHistory.push({ role: 'user', content: '请记住,我的名字叫moss' });- 模型回复入栈:
javascript
chatHistory.push({ role: 'assistant', content: response.choices[0].message.content });核心细节 :不仅用户的提问需要记录,模型自身的回复(角色为
assistant)也必须同步推入队列。大模型需要依据自身先前的回答来确保后续输出的逻辑连贯性与角色一致性。
- 二次请求的上下文合集 :当执行到第二次请求发送时,传给 API 的
messages参数实际上已经包含了以下完整序列:
[system, user(第一次提问), assistant(第一次回复), user(第二次提问)]。
模型通过阅读这个完整的文本序列,在上下文中找到了"moss"这一关键信息,从而做出了正确的应答。
4.3 异步控制与异常捕获
由于网络请求属于典型的异步 I/O 操作,代码使用 async/await 语法使得异步流程的编写如同同步代码般直观。而在函数的末尾:
代码片
通过向 Promise 实例尾部挂载 .catch() 方法,能够有效截获网络超时、API 凭证失效或配额不足等导致的异常(Reject 状态),防止 Node.js 进程由于未捕获的异常而意外崩溃。
5. 对话历史(Chat History)管理的现实挑战
尽管通过在客户端维护 chatHistory 数组成功模拟出了连续对话的效果,但在实际业务场景中,这种模式面临以下三个核心局限性:
- Token 开销呈指数级增长 :大语言模型是按照 Token 数量计费的。随着对话轮次的增加,每次请求所携带的
chatHistory数组体积将越来越大。这意味着,即使由于用户只说了一句"谢谢",由于需要将之前累积的几万字历史全部重新发送给服务器,单次请求的成本也会变得极高。 - 上下文窗口限制(Capacity):任何大模型都有其最大支持的上下文 Token 长度上限(例如 8k、32k 或 128k)。一旦对话长久持续,超出窗口限制的部分将被系统强制截断,导致模型出现严重的"遗忘"现象。
- 缓存与淘汰机制(如 LRU 策略) :为了在长对话中控制成本与容量,实际工程中通常需要引入 LRU(Least Recently Used,最近最少使用) 类似的裁剪算法。其基本逻辑为:设置一个最大容量阈值,保留最近发生的对话轮次,而将较早之前、与当前任务不直接相关的陈旧对话历史从队列中适当剔除,从而在记忆连贯性与经济成本之间取得最佳平衡。
本期分享到此结束,我们下期再见👋