文章目录
- 一、如何从零构建LLaMA-Factory环境
-
- [1. 进入光合社区](#1. 进入光合社区)
- [2. 选择对应软件下载安装即可](#2. 选择对应软件下载安装即可)
- [3. 搭建LLaMA-Factory的环境](#3. 搭建LLaMA-Factory的环境)
- 二、直接使用超算互联网scnet上已有的LLaMa-Factory镜像
-
- [2.1 、准备训练环境](#2.1 、准备训练环境)
-
- [1. 创建自己的Notebook](#1. 创建自己的Notebook)
- [2. 进入自己的Notebook](#2. 进入自己的Notebook)
- [3. 下载安装llama-factory](#3. 下载安装llama-factory)
- [2.2 构建训练数据](#2.2 构建训练数据)
- [2.3 开展模型微调](#2.3 开展模型微调)
插播广告一条😂🐶:我制作的一个免费 语音识别网站,欢迎体验!
一、如何从零构建LLaMA-Factory环境
1. 进入光合社区
搜索想要的软件,比如vllm
2. 选择对应软件下载安装即可
注意查看DCU的开发版本信息:ls /opt/,我的显示结果是:dtk-25.04.1。
建议在下面的选择时,选择cp311的版本,后面也建立对应的python3.11环境。别问我为什么,我之前用cp310的版本,结果安装vllm 0.8.5时告诉我必须用python3.11,导致又得重来一遍。
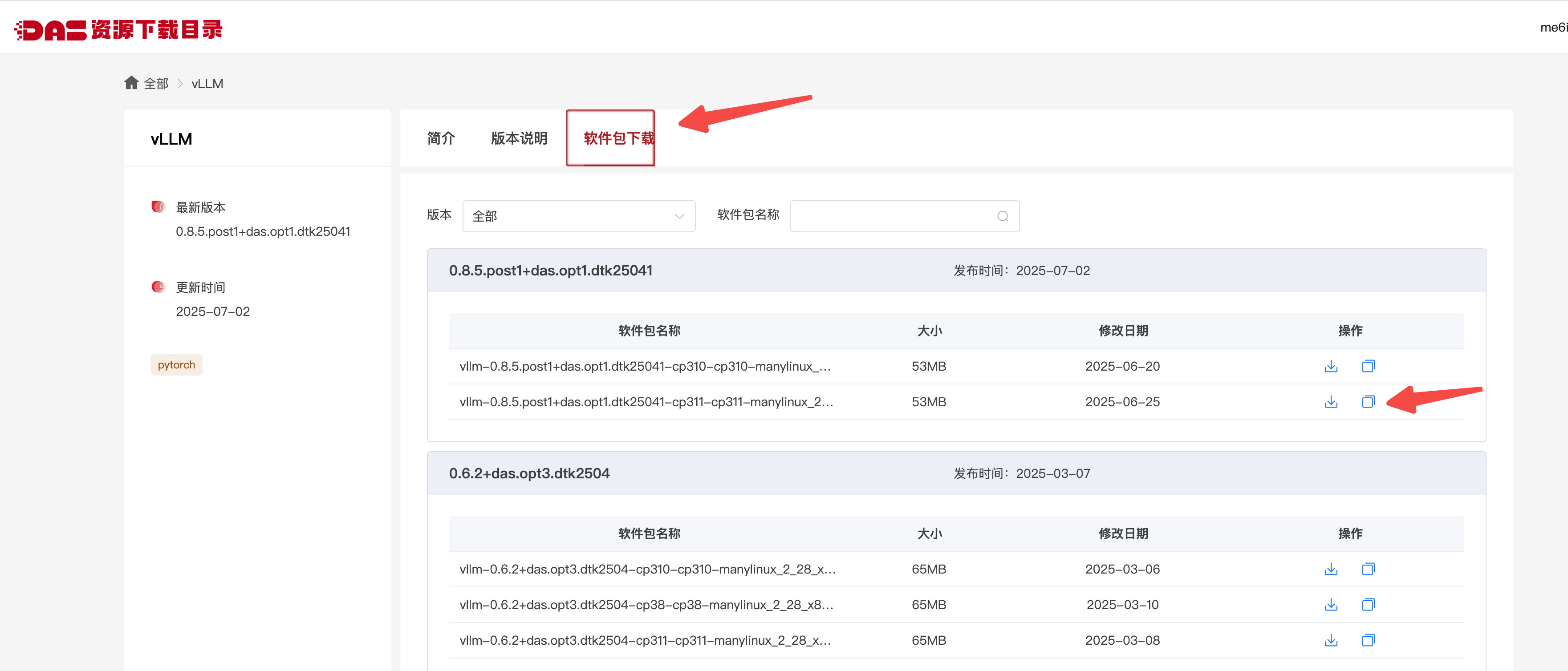
3. 搭建LLaMA-Factory的环境
bash
export LD_LIBRARY_PATH=/opt/dtk-25.04.1/lib/:/opt/dtk-25.04.1/lib64/:$LD_LIBRARY_PATH
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n py311 python=3.11 -y
conda activate py311
pip install -e ".[torch,metrics]" --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch-2.5.1+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torchvision-0.19.1+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl
pip install deepspeed-0.14.2+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install vllm-0.8.5.post1+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl
pip install flash_attn-2.6.1+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl
pip install triton-3.0.0+das.opt1.dtk25041-cp311-cp311-manylinux_2_28_x86_64.whl 二、直接使用超算互联网scnet上已有的LLaMa-Factory镜像
2.1 、准备训练环境
1. 创建自己的Notebook
-
点击:创建Notebook
-
点击:模型镜像
DCU的显卡可以选择下面的镜像:
-
点击右下角的"创建"按钮即可
2. 进入自己的Notebook
- 刷新https://www.scnet.cn/ui/console/index.html#/notebook页面,此时应该可以看到自己创建的Notebook
- 点击"JupyterLab"按钮
- 点击进入终端
出现如下终端页面:
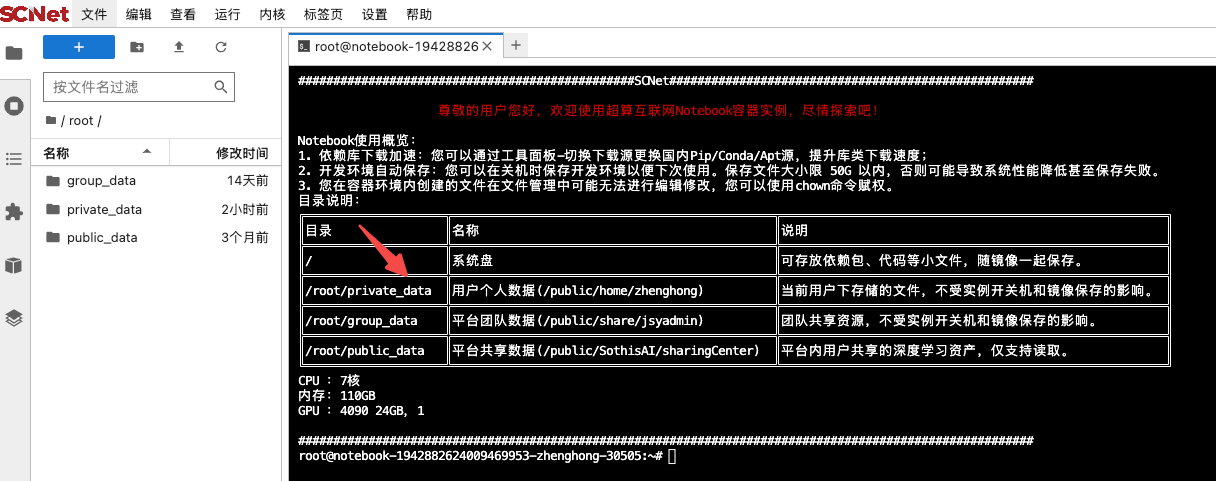
3. 下载安装llama-factory
- 在Notebook的终端中进入个人目录,并下载llama-factory
bash
cd /root/private_data
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git- 进入llama-factory文件夹,开始安装
bash
cd LLaMA-Factory
pip install -r requirements.txt
pip install -e ".[torch,metrics]" --no-build-isolation2.2 构建训练数据
- 在Notebook的终端中进入个人目录,并下载llm_training项目
bash
cd /root/private_data
git clone http://www.easyop.cn/gitlab/ops/data/llm_training.git- 进入模型训练目录,执行run.sh
bash
cd llm_training/scripts/模型训练
sh run.sh 执行成功后,会出现以下反馈:

其中./data/train_sugon.jsonl就是训练数据,./data/dev_sugon.jsonl就是测试数据
2.3 开展模型微调
- 放入训练数据
把上文中的train_sugon.jsonl移动至LLaMA-Factory的data目录
bash
mv /root/private_data/llm_training/scripts/模型训练/data/train_sugon.jsonl /root/private_data/LLaMA-Factory/data
cd /root/private_data/LLaMA-Factory- 配置数据元信息
编辑data目录下的dataset_info.json,加入对train_sugon的描述信息,具体内容如下(注意结尾有个逗号):
bash
"train_sugon": {
"file_name": "train_sugon.jsonl"
},- 配置微调参数
新建examples/train_lora/sugon_lora_sft_qwen3_8B.yaml,该文件的具体内容如下(每个配置项含义下面已有注释):
bash
### model
model_name_or_path: /root/public_data/model/admin/Qwen/Qwen3-8B # 指定预训练模型的路径或名称
trust_remote_code: true # 是否信任远程代码,设置为true允许加载模型定义中的自定义代码
### method
stage: sft # 指定微调阶段,这里是监督微调 (Supervised Fine-Tuning)
do_train: true # 是否执行训练
finetuning_type: lora # 微调方法,这里使用 LoRA (Low-Rank Adaptation)
lora_rank: 8 # LoRA 的秩,影响适配器的参数量和表达能力
lora_target: all # 指定 LoRA 应用的目标模块,all 表示应用于所有支持的模块
#deepspeed: examples/deepspeed/ds_z2_config.json # DeepSpeed 配置文件路径,用于分布式训练和内存优化,当前被注释掉
### dataset
dataset: train_sugon # 使用的数据集名称
template: qwen # 数据集模板,这里是针对 Qwen 模型的模板
cutoff_len: 4096 # 输入序列的最大长度,超过此长度将被截断
max_samples: 5000000 # 用于训练的最大样本数
overwrite_cache: true # 是否覆盖缓存的数据集,设置为true会重新处理数据
preprocessing_num_workers: 16 # 数据预处理时使用的进程数
dataloader_num_workers: 4 # DataLoader 加载数据时使用的进程数
### output
output_dir: saves/Qwen3-8B-Sugon/lora/sft # 模型输出和保存的目录
logging_steps: 10 # 每隔多少步记录一次日志
save_steps: 3000 # 每隔多少步保存一次检查点
plot_loss: true # 是否绘制训练损失曲线
overwrite_output_dir: true # 是否覆盖输出目录,如果为true,会删除现有内容
save_only_model: false # 是否只保存模型权重,不保存优化器状态等
report_to: none # 训练报告工具,例如 wandb, tensorboard 等,none 表示不使用
### train
per_device_train_batch_size: 1 # 每个设备(GPU)的训练批次大小
gradient_accumulation_steps: 1 # 梯度累积步数,用于增大有效批次大小
learning_rate: 1.0e-4 # 学习率
num_train_epochs: 3.0 # 训练的总轮数
lr_scheduler_type: cosine # 学习率调度器类型,这里是 cosine 衰减
warmup_ratio: 0.1 # 学习率预热的比例
bf16: true # 是否使用 BF16 混合精度训练
ddp_timeout: 180000000 # 分布式数据并行 (DDP) 的通信超时时间(毫秒)
resume_from_checkpoint: null # 从指定检查点恢复训练,null 表示不恢复
#### eval
#val_size: 0.1 # 验证集大小的比例,当前被注释掉
#per_device_eval_batch_size: 1 # 每个设备(GPU)的评估批次大小,当前被注释掉
#eval_strategy: steps # 评估策略,按步数进行评估,当前被注释掉
#eval_steps: 500 # 每隔多少步进行一次评估,当前被注释掉-
训练模型
在终端中输入以下命令开始对模型进行训练
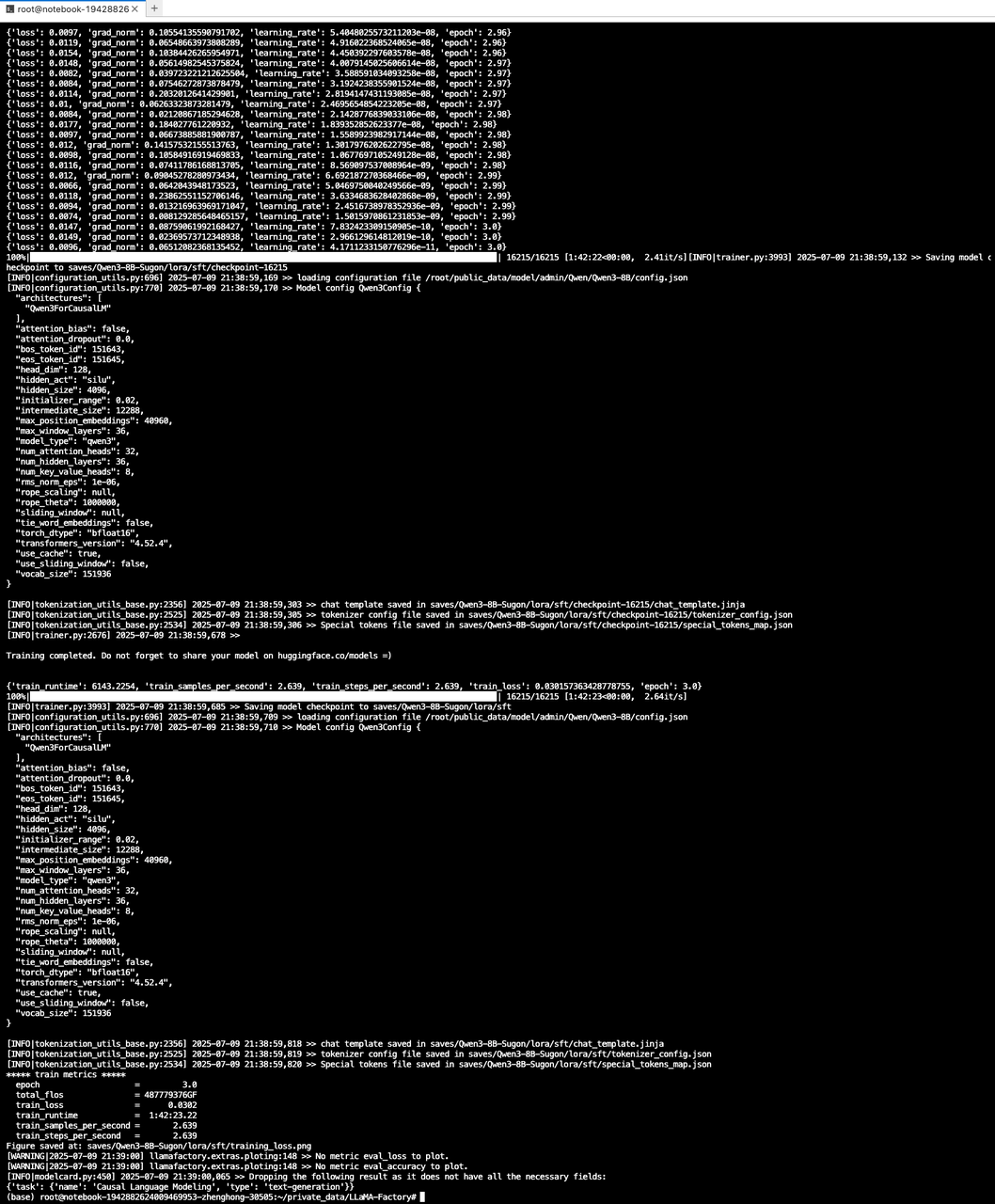
llamafactory-cli train examples/train_lora/sugon_lora_sft_qwen3_8B.yaml
如果运行正常,会有类似下面的结果:
-
部署服务
将训练好的模型以服务形式呈现,可执行下面的命令,它将监听10000端口号:
bash
cd /root/private_data/LLaMA-Factory
API_PORT=10000 llamafactory-cli api ./examples/inference/sugon_merged.yaml其中sugon_merged.yaml的内容如下:
bash
model_name_or_path: /root/public_data/model/admin/Qwen/Qwen3-8B # 指定预训练模型的路径
adapter_name_or_path: /root/private_data/LLaMA-Factory/saves/Qwen3-8B-Sugon/lora/sft # 指定微调后的LoRA适配器(adapter)的路径
template: qwen # 指定模型对话的模板,这里是Qwen模型对应的模板
infer_backend: huggingface # choices: [huggingface, vllm] # 指定推理后端,这里选择Hugging Face Transformers
#infer_backend: vllm # choices: [huggingface, vllm] # 另一个可选的推理后端是vLLM,通常用于高性能推理
trust_remote_code: true # 是否信任远程代码,当模型或适配器加载的代码不在本地时,设置为true- 测试模型
bash
cd /root/private_data/llm_training/scripts/模型训练
#在自测模型时,注意需要修改utils.py中的url为:
#url = 'http://127.0.0.1:10000/v1/chat/completions'
python test_precision.py ./data/dev_data.jsonl 如果运行正常,就会显示类似如下的结果信息:
