- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
文章目录
- [1. ResNetV2 vs V1 核心区别](#1. ResNetV2 vs V1 核心区别)
- [2. 环境](#2. 环境)
- [3. 代码实现](#3. 代码实现)
-
- [3.1 前期准备](#3.1 前期准备)
-
- [3.1.1 设置GPU & 导入库](#3.1.1 设置GPU & 导入库)
- [3.1.2 数据加载](#3.1.2 数据加载)
- [3.2 模型建立与训练](#3.2 模型建立与训练)
-
- [3.2.1 定义 ResNet50V2 残差块](#3.2.1 定义 ResNet50V2 残差块)
- [3.2.2 定义完整 ResNet50V2 模型](#3.2.2 定义完整 ResNet50V2 模型)
- [3.2.2 模型结构概览](#3.2.2 模型结构概览)
- [3.2.3 定义训练和测试函数](#3.2.3 定义训练和测试函数)
- [3.2.4 训练模型](#3.2.4 训练模型)
- [4. 模型评估](#4. 模型评估)
-
- [4.1 可视化训练过程](#4.1 可视化训练过程)
- [4.2 加载最优模型并评估](#4.2 加载最优模型并评估)
- 5.改进思路探索
-
- [5.1 预激活思想的迁移](#5.1 预激活思想的迁移)
- [5.2 核心原理](#5.2 核心原理)
1. ResNetV2 vs V1 核心区别
| ResNetV1 | ResNetV2 | |
|---|---|---|
| 残差块内部顺序 | Conv → BN → ReLU | BN → ReLU → Conv |
| Shortcut | Conv → BN (无激活) | Conv (无BN、无激活) |
| 首层卷积后 | BN → ReLU → MaxPool | 直接 MaxPool (BN+ReLU 移到最后) |
| 最终分类前 | 直接 GAP | BN → ReLU → GAP |
为什么 V2 更好? 预激活设计让梯度在 shortcut 上畅通无阻地回传,避免了 BN 层对梯度的缩放干扰,训练更深网络时收敛更稳定。
2. 环境
- 语言环境:Python 3.14.6
- 编译器:Jupyter Notebook
- 深度学习环境:PyTorch ( torch 2.12.1 + torchvision 0.27.1 )
3. 代码实现
3.1 前期准备
3.1.1 设置GPU & 导入库
导入 PyTorch、torchvision 等深度学习库,配置 matplotlib 中文字体,自动选择 GPU/CPU 设备.
python
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
import copy
import matplotlib.pyplot as plt
from PIL import Image
from datetime import datetime
warnings.filterwarnings("ignore")
plt.rcParams["figure.dpi"] = 100
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device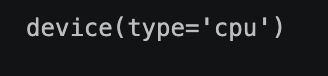
3.1.2 数据加载
python
data_dir = './Data/data/'
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
print(f"Classes: {total_data.class_to_idx}")
print(f"Total samples: {len(total_data)}")
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
for X, y in test_dl:
print(f"Batch shape: {X.shape}, Labels: {y.shape}")
break
3.2 模型建立与训练
3.2.1 定义 ResNet50V2 残差块
关键区别:BN → ReLU → Conv(预激活)
block2: 单个瓶颈残差块,支持conv_shortcut选择是否用 1x1 卷积调整 shortcut 维度stack2: 堆叠多个 block2,第一个 block 负责下采样,后续 block 使用 identity shortcut
python
class Block2(nn.Module):
"""ResNetV2 pre-activation bottleneck block.
V2 order: BN -> ReLU -> Conv (vs V1: Conv -> BN -> ReLU)
Shortcut is clean: no BN, no activation on the shortcut path.
"""
def __init__(self, in_channels, filters, kernel_size=3, stride=1, conv_shortcut=True):
super().__init__()
out_channels = 4 * filters
if conv_shortcut:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride=stride, bias=False),
# V2 shortcut: Conv only, no BN
)
else:
self.shortcut = nn.Identity()
# Pre-activation: BN -> ReLU -> Conv
self.bn1 = nn.BatchNorm2d(in_channels, eps=1e-5)
self.conv1 = nn.Conv2d(in_channels, filters, 1, stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(filters, eps=1e-5)
self.conv2 = nn.Conv2d(filters, filters, kernel_size, padding=kernel_size // 2, bias=False)
self.bn3 = nn.BatchNorm2d(filters, eps=1e-5)
self.conv3 = nn.Conv2d(filters, out_channels, 1, bias=False)
def forward(self, x):
shortcut = self.shortcut(x)
x = self.bn1(x)
x = torch.relu(x)
x = self.conv1(x)
x = self.bn2(x)
x = torch.relu(x)
x = self.conv2(x)
x = self.bn3(x)
x = torch.relu(x)
x = self.conv3(x)
return x + shortcut
class Stack2(nn.Module):
"""Stack of ResNetV2 blocks. First block downsamples, rest use identity shortcut."""
def __init__(self, in_channels, filters, blocks, stride1=2):
super().__init__()
layers = [Block2(in_channels, filters, stride=stride1, conv_shortcut=True)]
for _ in range(1, blocks):
layers.append(Block2(4 * filters, filters, conv_shortcut=False))
self.stack = nn.Sequential(*layers)
def forward(self, x):
return self.stack(x)3.2.2 定义完整 ResNet50V2 模型
python
class ResNet50V2(nn.Module):
def __init__(self, preact=True, classes=1000):
super().__init__()
self.preact = preact
# Stem: 7x7 conv, no BN immediately after (BN moved to pre-activation)
self.conv1_pad = nn.ZeroPad2d(3)
self.conv1 = nn.Conv2d(3, 64, 7, stride=2, bias=True)
if not preact:
self.conv1_bn = nn.BatchNorm2d(64, eps=1e-5)
self.pool1_pad = nn.ZeroPad2d(1)
self.pool1 = nn.MaxPool2d(3, stride=2)
# Stages
self.conv2 = Stack2(64, 64, 3, stride1=1)
self.conv3 = Stack2(256, 128, 4, stride1=2)
self.conv4 = Stack2(512, 256, 6, stride1=2)
self.conv5 = Stack2(1024, 512, 3, stride1=1)
# Post-activation (V2 style)
if preact:
self.post_bn = nn.BatchNorm2d(2048, eps=1e-5)
# Head
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(2048, classes)
def forward(self, x):
x = self.conv1_pad(x)
x = self.conv1(x)
if not self.preact:
x = self.conv1_bn(x)
x = torch.relu(x)
x = self.pool1_pad(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
if self.preact:
x = self.post_bn(x)
x = torch.relu(x)
x = self.avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
model = ResNet50V2(classes=3).to(device)
model
bash
ResNet50V2(
(conv1_pad): ZeroPad2d((3, 3, 3, 3))
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2))
(pool1_pad): ZeroPad2d((1, 1, 1, 1))
(pool1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Stack2(
(stack): Sequential(
(0): Block2(
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): Block2(
(shortcut): Identity()
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
...
)
(post_bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, bias=True, track_running_stats=True)
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Linear(in_features=2048, out_features=3, bias=True)
)3.2.2 模型结构概览
python
# 测试前向传播
x = torch.randn(1, 3, 224, 224).to(device)
out = model(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {out.shape}")
# 参数量统计
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total params: {total_params:,}")
print(f"Trainable params: {trainable_params:,}")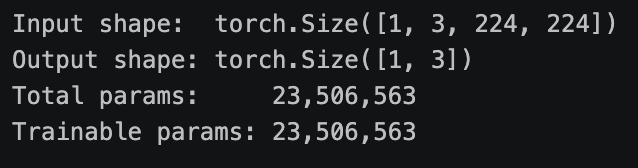
3.2.3 定义训练和测试函数
- train():遍历训练集,前向传播 → 计算损失 → 反向传播 → 更新参数,累计损失和正确预测数
- test() :在
torch.no_grad()下遍历测试集,只做前向传播,不更新梯度
python
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
return train_loss / num_batches, train_acc / size
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_loss += loss.item()
return test_loss / num_batches, test_acc / size3.2.4 训练模型
定义优化器(AdamW)、损失函数(交叉熵),进行 10 个 epoch 的训练。每个 epoch 结束后在测试集上评估,保存最优模型权重。
python
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 10
train_loss, train_acc = [], []
test_loss, test_acc = [], []
best_acc = 0
for epoch in range(epochs):
model.train()
train_epoch_loss, train_epoch_acc = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_loss, epoch_test_acc = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model_wts = copy.deepcopy(model)
train_acc.append(train_epoch_acc)
train_loss.append(train_epoch_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.param_groups[0]['lr']
print(f"Epoch: {epoch+1:2d}, Train_acc: {train_epoch_acc*100:.1f}%, Train_loss: {train_epoch_loss:.3f}, "
f"Test_acc: {epoch_test_acc*100:.1f}%, Test_loss: {epoch_test_loss:.3f}, Lr: {lr:.2E}")
PATH = './best_resnet50v2.pth'
torch.save(best_model_wts.state_dict(), PATH)
print('Done.')
bash
Epoch: 1, Train_acc: 66.8%, Train_loss: 0.824, Test_acc: 43.2%, Test_loss: 1.286, Lr: 1.00E-04
Epoch: 2, Train_acc: 71.5%, Train_loss: 0.729, Test_acc: 78.7%, Test_loss: 0.915, Lr: 1.00E-04
Epoch: 3, Train_acc: 75.5%, Train_loss: 0.642, Test_acc: 64.6%, Test_loss: 1.635, Lr: 1.00E-04
Epoch: 4, Train_acc: 78.0%, Train_loss: 0.571, Test_acc: 85.3%, Test_loss: 0.387, Lr: 1.00E-04
Epoch: 5, Train_acc: 81.3%, Train_loss: 0.505, Test_acc: 79.3%, Test_loss: 0.502, Lr: 1.00E-04
Epoch: 6, Train_acc: 82.2%, Train_loss: 0.477, Test_acc: 86.2%, Test_loss: 0.597, Lr: 1.00E-04
Epoch: 7, Train_acc: 84.2%, Train_loss: 0.425, Test_acc: 85.0%, Test_loss: 0.402, Lr: 1.00E-04
Epoch: 8, Train_acc: 85.7%, Train_loss: 0.415, Test_acc: 86.5%, Test_loss: 0.334, Lr: 1.00E-04
Epoch: 9, Train_acc: 86.7%, Train_loss: 0.368, Test_acc: 71.5%, Test_loss: 0.836, Lr: 1.00E-04
Epoch: 10, Train_acc: 87.3%, Train_loss: 0.349, Test_acc: 82.0%, Test_loss: 0.899, Lr: 1.00E-04
Done.4. 模型评估
4.1 可视化训练过程
绘制训练和测试的准确率、损失曲线,并使用 Matplotlib 将训练集与验证集的准确率(Accuracy)和损失值(Loss)随时间变化的趋势绘制成了两幅直观的折线图。
python
current_time = datetime.now()
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()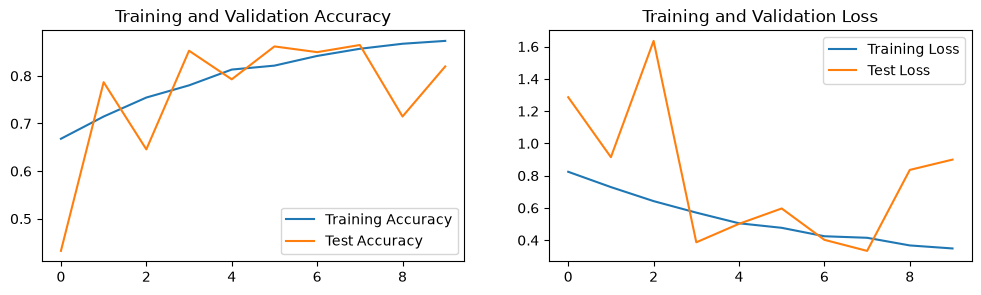
4.2 加载最优模型并评估
加载训练过程中保存的最优模型权重,在测试集上进行最终评估,输出测试准确率和损失值。
python
best_model_wts.load_state_dict(torch.load(PATH, map_location=device))
test_epoch_loss, test_epoch_acc = test(test_dl, best_model_wts, loss_fn)
print(f"Best model - Test Acc: {test_epoch_acc*100:.1f}%, Test Loss: {test_epoch_loss:.3f}")
bash
Best model - Test Acc: 86.5%, Test Loss: 0.3345.改进思路探索
5.1 预激活思想的迁移
ResNetV2 的 BN → ReLU → Conv 预激活设计可以迁移到:
- DenseNet:DenseNet 本身就是预激活设计,但可以在 Dense Block 内部进一步优化
- UNet:将 UNet 的 encoder/decoder 中的 Conv-BN-ReLU 改为 BN-ReLU-Conv,提升医学图像分割效果
- Transformer 中的 Pre-Norm:Transformer 的 Pre-LN(LayerNorm 在 Attention/FFN 之前)和 ResNetV2 的预激活是同一思想------让残差路径上的梯度更通畅
- MobileNet / EfficientNet:在轻量级网络中使用预激活,可能改善小模型的训练稳定性
5.2 核心原理
预激活的本质是让 shortcut 路径完全干净(无非线性变换),使得梯度可以通过恒等映射直接回传,缓解深层网络的梯度消失问题。这个"干净 shortcut"原则是现代深度网络设计的通用准则。