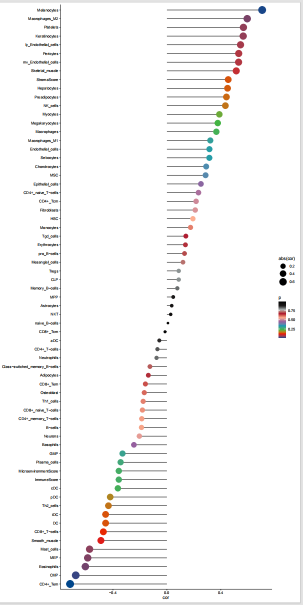
一、使用说明
1.0 数据来源说明
本平台提供两种数据接入方式,您可以根据实际情况选择:
|----------------|-----------------------------------|---------------------------|
| 方式 | 说明 | 适用人群 |
| 选择已有数据 | 选择历史已构建上传至数据库的表达谱数据 | 适合曾联系客服完成数据上传、希望复用历史记录的用户 |
| 上传新数据 | 自行从GEO等公共数据库下载,或通过平台文件上传按钮提交表达谱矩阵 | 适合需要分析自有数据或最新公开数据的用户 |
1.1 数据准备与上传
进行免疫浸润分析前,请准备好您的表达谱矩阵文件。
|--------------|---------------------------------------------------------|
| 项目 | 要求 |
| 文件格式 | txt / txt.gz / csv / csv.gz / tsv / tsv.gz / xls / xlsx |
| 行定义 | 代表基因(Gene Symbol),请使用标准HGNC基因名 |
| 列定义 | 代表样本,列名需唯一 |
| 数值类型 | 推荐使用TPM、FPKM或非log2转化的标准化表达值;不能有空值或负值 |
1.2 处理重复基因
若表达矩阵中存在同一个基因对应多行的情况(例如多探针映射到同一基因),请在下拉菜单中选择合并方式:
|--------------|------------|----------------------|
| 合并方式 | 说明 | 推荐场景 |
| mean(★推荐) | 取多个值的算术平均值 | 通用场景,平衡稳定,适合绝大多数情况 |
| median | 取中位数 | 数据存在极端离群值时,中位数比均值更稳健 |
| max | 取最大值 | 倾向保留最强信号,如侧重检测高表达基因 |
| min | 取最小值 | 倾向保守估计,减少假阳性 |
| sum | 取总和 | 较少使用,可能放大技术噪声 |
| none | 不合并,保留所有行 | 仅当矩阵已确认无任何重复基因时选用 |
1.3 选择免疫浸润分析方法
平台支持多种主流免疫浸润算法,可多选。不同方法基于不同原理和参考数据集,建议交叉验证以增强结果可靠性。
各方法的含义和适用场景如下:
|-----------------------|----------------------------|------------------------------------------|---------------------------------------|
| 方法 | 核心原理 | 输出内容 | 特点与适用场景 |
| CIBERSORT | 基于支持向量回归(SVR),以LM22为参考基因矩阵 | 22种免疫细胞的相对比例(各样本内总和=1) | 经典方法,文献引用最广;要求输入数据规范,建议样本数≥10 |
| CIBERSORT_ABS | 在CIBERSORT基础上增加绝对定量校正 | 22种免疫细胞的绝对含量 | 适合比较不同样本间的总免疫负荷大小 |
| quantiseq | 基于RNA-seq数据优化的反卷积算法 | 约10种免疫细胞+基质细胞的绝对丰度 | 专为RNA-seq设计,对批次效应有一定鲁棒性 |
| mcpcounter | 基于标记基因的富集打分法(非反卷积) | 约8种免疫细胞类型的相对丰度(富集分数,无单位) | 计算极快,对噪声和平台差异鲁棒,适合快速初步筛查 |
| xcell | 基于大量纯化细胞系的RNA-seq参考数据 | 64种免疫细胞+基质细胞的丰度 | 覆盖面最广,包含多种罕见免疫亚型,适合深度挖掘 |
| EPIC | 基于约束最小二乘的反卷积 | 约6种免疫细胞 + 成纤维/内皮等非免疫细胞丰度 | 可同时估算非免疫细胞占比,适合肿瘤微环境多组分分析 |
| ESTIMATE | 基于基因表达特征计算肿瘤微环境纯度 | 免疫评分 、基质评分 、肿瘤纯度 | ⚠️ 不细分免疫细胞类型,仅输出整体免疫负荷,适合宏观初筛 |
| immune_28 | 基于28种免疫细胞标记基因集富集 | 28种免疫细胞的相对丰度(富集分数) | 覆盖更多记忆T细胞亚型,与CIBERSORT形成互补 |
| immune_13 | 精简版13种关键免疫细胞标记基因富集 | 13种免疫细胞的相对丰度(富集分数) | 运算速度快,适合初步快速评估 |
| TME | 肿瘤微环境多维度综合评分 | 免疫评分、基质评分、综合评分(连续值) | ⚠️ 不细分细胞类型,输出宏观TME特征评分 |
1.4 提交运行
选择完毕后,点击【开始计算】按钮提交任务。运行时间通常为 1-5 分钟,具体取决于数据量大小和所选算法数量。任务执行完成后,页面将显示 "immune successful" 的状态提示。
- 结果说明
2.1 结果文件概览
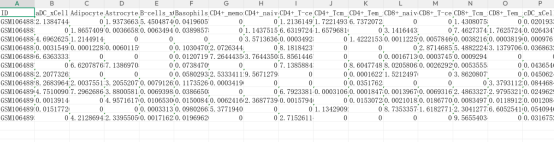
运行完成后,平台会生成包含免疫评分的文本文件(.txt 格式)。每个勾选的方法对应一个结果文件,命名格式为 方法名_result.txt。
示例文件结构(以GSE43523 xCell 算法为例):
|-------------------|-----------------------------------------------------|
| 组成 | 说明 |
| 行(Row) | 每个样本(Sample ID),如 GSM1064882 ~ GSM1064893,共 12 个样本 |
| 列(Column) | 各类细胞类型的丰度评分,每列代表一种细胞类型 |
第二步:比较可视化
完成第一步"多种方法计算免疫浸润"并获得结果文件后,可进入第二步进行可视化分析。本平台支持三种可视化类型:差异比较箱线图、亚群丰度占比图、热图。
一、使用说明
1 .1.1 进入第二步
在平台页面顶部导航栏点击【第二步 比较可视化】,进入可视化分析界面。
1 .1.2 选择任务
在【选择任务】下拉菜单中,选择第一步已完成计算的任务。
1 .1.3 选择绘图类型
在【选择绘图类型】区域,勾选 "差异比较的箱线图" " 亚群丰度占比图 " 或 " 热图"
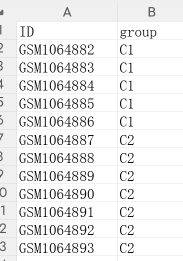
1 .1.4 上传样本分组文件(必填)
|----------------|------------------------------------------------------------|
| 项目 | 说明 |
| 文件格式 | txt / txt.gz / csv / csv.gz / tsv / tsv.gz / xls / xlsx |
| 文件内容要求 | 必须包含两列:第一列 为样本名(Sample ID),第二列为分组标签(Group) |
| 分组命名规范 | 建议使用简洁的英文名称(如 C1、C2、Control、Treatment),避免使用中文或特殊字符 |
| 示例说明 | Control组可标注为 C1,Treat组可标注为 C2 |
分组文件示例(Excel / CSV / TXT 格式均可):
1 .1.5 选择免疫浸润方法
在【选择免疫浸润的方法】区域,勾选第一步中已使用过 的一种或多种方法。不可勾选第一步未使用的方法 ,否则因缺少对应结果文件将导致绘图失败。
1 .1.6 选择比较检验方法
|-------------------------|-------------------|-------------------------------|
| 检验方法 | 适用场景 | 说明 |
| wilcox.test(推荐) | 两组比较,非正态分布或方差不齐 | 非参数检验,对数据分布无严格要求,适用于大多数免疫浸润数据 |
| t.test | 两组比较,正态分布且方差齐性 | 参数检验,要求数据满足正态性和方差齐性假设 |
| kruskal.test | 三组及以上比较 | 非参数检验,用于多组间差异比较 |
| anova | 三组及以上比较,正态分布且方差齐性 | 参数检验,用于多组间差异比较 |
1 .1.7 选择分组对应的颜色
平台预置多套专业配色方案,可直接选用:
|-------------------|----------------|----------------|
| 配色方案 | 风格特点 | 适用场景 |
| JAMA | 医学期刊风格,色彩鲜明 | 通用,适合SCI论文发表 |
| Lancet | 《柳叶刀》系列配色,沉稳专业 | 适合临床研究论文 |
| NEJM | 《新英格兰医学杂志》风格 | 适合高分期刊投稿 |
| AAAS | 《科学》系列配色,科技感强 | 适合综合性期刊 |
| Grayscale | 灰度配色 | 适合黑白打印或色盲友好需求 |
| NPG | Nature出版集团配色 | 适合Nature及其子刊投稿 |
| JCO | 《临床肿瘤学杂志》配色 | 适合肿瘤学领域研究 |
2.1.8 调整图片尺寸
二、结果 说明
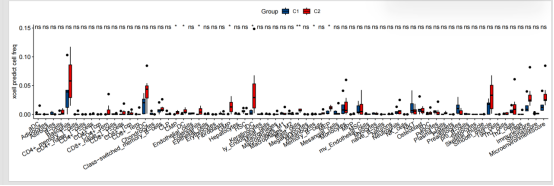
差异比较箱线图
|----------------------|------------------------------------------------------|
| 图表组成 | 对应说明 |
| X轴(横轴) | 分组标签(C1、C2),C1为Control组,C2为Treat组 |
| Y轴(纵轴) | 免疫细胞类型的富集分数(xCell输出的Enrichment Score) |
| 箱体 | 展示该组数据的四分位距(IQR,25%~75%),箱内横线代表中位数 |
| 须线(Whiskers) | 延伸至1.5倍IQR范围内的最远端,表示整体分布区间 |
| 散点(数据点) | 每个点代表一个独立样本在该细胞类型中的实际富集分数 |
| 显著性标记 | * / ** / *** / **** 标注在图表上方,表示组间差异的统计学显著水平 |
亚群丰度占比图
|----------------|----------------------------------|
| 图表组成 | 说明 |
| X轴(横轴) | 每个样本(Sample ID),按分组排列 |
| Y轴(纵轴) | 细胞丰度值(相对比例0~1 或 富集分数) |
| 堆叠色块 | 每种颜色代表一种免疫细胞类型,色块高度表示该细胞在样本中的占比 |
| 样本标签 | 横轴下方显示样本名称,分组信息通常以颜色条或文字标注在顶部/底部 |

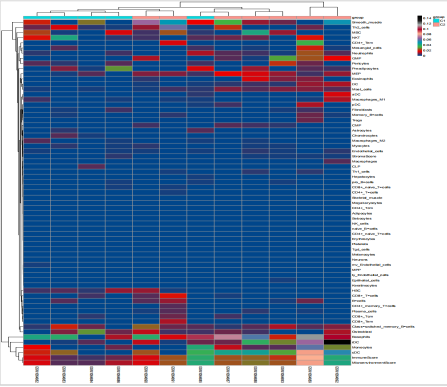
热图
|----------------------|--------------------------------------------------|
| 图表组成 | 说明 |
| 行(Rows) | 免疫细胞类型(由所选方法输出) |
| 列(Columns) | 样本(Sample ID) |
| 颜色映射 | 每个格子的颜色深浅代表该细胞在该样本中的富集分数(标准化后),红色通常表示高富集,蓝色表示低富集 |
| 行聚类树(左侧/上方) | 基于细胞类型丰度模式的相似性进行聚类,树枝越近表示表达模式越相似 |
| 列聚类树(顶部/左侧) | 基于样本免疫谱的相似性进行聚类,树枝越近表示样本间的免疫构成越相似 |
| 分组注释条(顶部或底部) | 若上传了分组文件,显示各样本所属分组(不同颜色区分),便于观察聚类与分组的关系 |
第三步: 相关性可视化
一、使用说明
相关性可视化用于探索基因表达水平 与免疫细胞浸润丰度 之间的关联关系,帮助识别哪些基因的表达可能与特定免疫细胞的浸润相关,从而筛选潜在的功能基因或生物标志物。本平台提供 7 种 相关性可视化图形,以适应不同的分析需求。
1.1 进入第三步并选择任务
在平台页面顶部导航栏点击【第三步 相关性可视化】,进入相关性分析界面。在【选择任务】下拉菜单中,选择第一步已完成计算的任务(页面提示"immune successful")。
1.2 上传基因列表(必填)
|---------------|---------------------------------------------------------|
| 项目 | 说明 |
| 文件格式 | txt / txt.gz / csv / csv.gz / tsv / tsv.gz / xls / xlsx |
| 文件内容 | 一列基因名(Gene Symbol),每行一个基因,首行可含或不含列标题 |
| 基因名要求 | 必须与表达谱矩阵中的基因名完全一致(包括大小写),否则系统无法匹配 |
| 数量限制 | 建议每次上传 3~20 个 基因,过多可能导致图表信息过密 |
示例文件内容(以 ALOX15-AKR1C2-NQO1-AKR1C3.xlsx 为例):
|--------|
| Gene |
| ALOX15 |
| AKR1C2 |
| NQO1 |
| AKR1C3 |
1.3 选择免疫浸润方法(必选)
在【选择免疫浸润的方法】区域,勾选第一步中已使用过 的方法。系统将使用该方法计算出的免疫细胞丰度与基因表达进行相关性分析。
⚠️ 重要 :只能勾选第一步已运行的方法。若某方法未被勾选,系统将无法获取对应的免疫浸润结果,导致绘图失败。
1.4 选择相关性分析方法
|------------------------|-------------------|----------------------------------------------|
| 方法 | 适用场景 | 说明 |
| spearman(默认推荐) | 数据不满足正态分布,或存在离群值 | 非参数检验,基于秩次计算,对数据分布无严格要求,适用于大多数免疫浸润数据 |
| pearson | 两组数据均呈正态分布且线性关系明确 | 参数检验,基于线性相关,要求数据满足正态性和方差齐性假设 |
�� 建议 :优先选择 spearman,因为免疫评分数据通常不符合正态分布,Spearman 方法更为稳健。
1.5 选择配色方案
1 .6 调整图片尺寸
1.7 七种绘图类型操作说明
在【选择绘图类型】区域勾选所需图形,所有图形共享上述通用参数(任务选择、基因列表、免疫浸润方法、相关性方法、配色方案、图片尺寸),无特殊参数 ,勾选后点击【提交】即可生成对应的可视化图形。
|-----------------------|-------------------------------|
| 绘图类型 | 功能说明 |
| 两两相关性散点图1 | 展示单个基因与单种免疫细胞的相关性,散点图 + 拟合曲线 |
| 两两相关性散点图2 | 与散点图1相同,额外在主图顶部和右侧增加边缘密度分布图 |
| 多基因对一细胞相关性散点图 | 同一图中展示多个基因与同一种免疫细胞的相关性,不同颜色区分 |
| 相关性气泡图 | 以气泡图矩阵展示多个基因与多种免疫细胞的相关性结果 |
| 多维度相关性洞察图 | 综合性图形,整合相关性矩阵、聚类和显著性标注 |
| 相关性热图 | 以热图形式展示基因与免疫细胞的相关性矩阵 |
| 相关性点棒图 | 以"点+误差棒"形式展示各基因-细胞对的相关性结果 |
- 结果说明
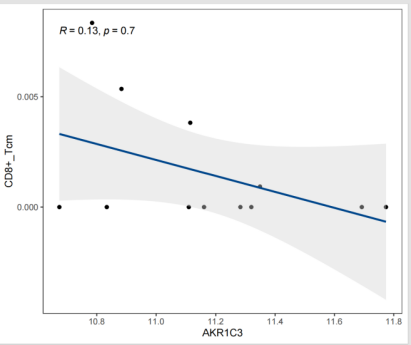
两两相关性散点1
|--------------|----------------------|
| 图表组成 | 说明 |
| X轴 | 基因表达量 |
| Y轴 | 免疫细胞丰度 |
| 散点 | 每个点代表一个样本 |
| 拟合曲线 | 反映基因表达与免疫细胞丰度的整体变化趋势 |
| 统计标注 | 图中标注相关系数(r)和P值 |
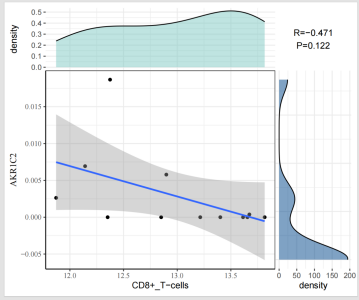
两两相关的散点图2:
|---------------|------------------------------|
| 图表组成 | 说明 |
| 主图区域 | 散点 + 拟合曲线(X轴=基因表达,Y轴=免疫细胞丰度) |
| 顶部密度图 | 基因表达量在各样本中的核密度分布 |
| 右侧密度图 | 免疫细胞丰度在各样本中的核密度分布 |
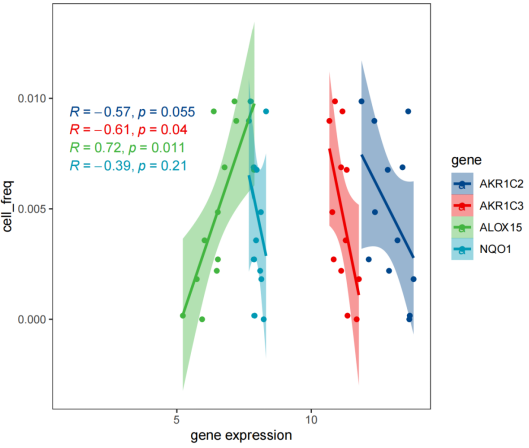
多基因对一细胞相关行散点图:
|-----------------|-------------------------------|
| 图表组成 | 说明 |
| X轴 | 基因表达量(多个基因共用) |
| Y轴 | 同一种免疫细胞丰度 |
| 多组散点与曲线 | 不同颜色代表不同基因,每条拟合曲线对应一个基因的r值和P值 |
相关性气泡图
|--------------------|----------------------|
| 图表组成 | 说明 |
| 行(Rows) | 基因名称 |
| 列(Columns) | 免疫细胞类型 |
| 气泡大小 | 相关系数(r)的绝对值大小 |
| 气泡颜色 | 相关性方向(红色=正相关,蓝色=负相关) |
| 气泡内数值(可选) | 相关系数的具体数值 |

多维度相关性洞察图如下:
同时展示相关性矩阵、聚类关系和显著性标注,用于多基因与多细胞关联模式的综合挖掘

相关性热图
|--------------------|------------------------------|
| 图表组成 | 说明 |
| 行(Rows) | 基因名称 |
| 列(Columns) | 免疫细胞类型 |
| 颜色映射 | 红色=正相关,蓝色=负相关,颜色越深相关性越强 |
| 聚类树 | 可对基因或细胞类型进行聚类,发现具有相似相关性模式的群组 |
相关性点棒图:
|--------------------|--------------------------------|
| 图表组成 | 说明 |
| X轴 | 相关系数(r 值) |
| Y轴 | 基因-免疫细胞对(如 AKR1C3 vs CD8+ Tcm) |
| 点 | 相关系数的点估计值 |
| 棒(Whisker) | 95%置信区间或标准误 |