目录
[1. 多表查询回顾](#1. 多表查询回顾)
[2. 笛卡尔积问题](#2. 笛卡尔积问题)
[3. 什么是连接查询](#3. 什么是连接查询)
[1. 内连接概念与语法](#1. 内连接概念与语法)
[2. 内连接执行过程](#2. 内连接执行过程)
[3. 学生与班级案例](#3. 学生与班级案例)
[1. 外连接概念](#1. 外连接概念)
[2. 左外连接](#2. 左外连接)
[3. 左外连接使用案例](#3. 左外连接使用案例)
[4. 右外连接与实战案例](#4. 右外连接与实战案例)
[5. 外连接的底层特点](#5. 外连接的底层特点)
[1. 查询所有学生对应班级](#1. 查询所有学生对应班级)
[2. 查询没有班级的学生](#2. 查询没有班级的学生)
[3. 查询没有学生的班级](#3. 查询没有学生的班级)
[4. 综合练习](#4. 综合练习)
[1. LeetCode 178. 分数排名 (Rank Scores)](#1. LeetCode 178. 分数排名 (Rank Scores))
[1.1 题目分析](#1.1 题目分析)
[1.2 解题思路](#1.2 解题思路)
[1.3 SQL 实现](#1.3 SQL 实现)
[2. LeetCode 626. 换座位 (Exchange Seats)](#2. LeetCode 626. 换座位 (Exchange Seats))
[2.1 题目分析](#2.1 题目分析)
[2.2 解题思路](#2.2 解题思路)
[2.3 SQL 实现](#2.3 SQL 实现)
一、为什么需要连接查询
在关系型数据库的设计架构中,"数据解耦" 与 "结构规范化" 是核心的设计原则。为了减少数据冗余并维护数据一致性,不同的业务实体通常会被隔离在不同的数据表中
然而,在实际的业务报表和数据分析场景中,我们往往需要恢复这些实体之间的内在关联。为了实现高效率、可维护的跨表数据重组,我们需要深入掌握 SQL 标准中的连接查询技术
为了配合案例演示,我们首先构建一套全新的教务管理数据集
sql
-- 创建班级表
CREATE TABLE classes (
class_id INT PRIMARY KEY COMMENT '班级编号',
class_name VARCHAR(50) NOT NULL COMMENT '班级名称'
) COMMENT '班级信息表';
-- 创建学生表
CREATE TABLE students (
student_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '学生学号',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
class_id INT COMMENT '所属班级编号'
) COMMENT '学生信息表';
-- 插入基础演示数据
INSERT INTO classes VALUES
(1, '计算机应用2601班'),
(2, '人工智能2602班'),
(3, '高维数据挖掘3班'),
(4, '暂无学生空置班');
INSERT INTO students (student_name, class_id) VALUES
('玄奘', 1),
('悟空', 1),
('八戒', 2),
('沙僧', 2),
('自由学者', NULL);1. 多表查询回顾
在原始的 SQL 语法中,如果需要跨表检索多表数据,开发人员通常会采用隐式内连接的方式。其表现形式是在 FROM 子句中列出所有需要关联的表名,并使用逗号进行分隔,最后在 WHERE 子句中通过等值条件来建立关联链条:
sql
-- 隐式多表查询示例
SELECT students.student_name, classes.class_name
FROM students, classes
WHERE students.class_id = classes.class_id;这种编写方式虽然能够满足基本的数据获取需求,但它在底层的执行逻辑上存在严重的性能和结构缺陷,必须通过笛卡尔积来进行解析
2. 笛卡尔积问题
当我们在 FROM 子句中引入多张表,却缺失 WHERE 过滤条件,或者连接条件编写错误时,关系型数据库引擎会退化到最初始的代数运算状态,产生笛卡尔积
底层特征
在物理存储层,笛卡尔积是一个无差别的横向组合过程。如果表 A 包含 M 条记录,表 B 包含 N 条记录,则两张表进行笛卡尔积运算后产生的结果集将包含 M * N 条记录
在我们当前构建的教务沙盒中,学生表有 5 条记录,班级表有 4 条记录。执行无条件的多表盲查:
sql
SELECT * FROM students, classes;-
MySQL 会强行产出 5 * 4 = 20 条数据。在这 20 条记录中,包含了完全错误的逻辑逻辑行
-
**性能代价:**随着数据量的线性增长,笛卡尔积指数级爆发。如果两张百万级数据的表发生笛卡尔积,将会瞬间生成万亿条临时数据,直接导致数据库服务器的 CPU 飙升与内存溢出
3. 什么是连接查询
为了解决隐式多表查询的代码结构混乱问题,并更精确地控制跨表数据的检索行为,标准 SQL 正式引入了显式连接查询
连接查询是指通过特定的连接关键字,并在专用的 ON 子句中显式指定关联物理纽带的查询方式
sql
-- 显式连接查询标准形态
SELECT s.student_name, c.class_name
FROM students AS s
INNER JOIN classes AS c -- 显式声明连接类型
ON s.class_id = c.class_id; -- 显式隔离连接条件核心优势
-
逻辑解耦: 显式连接查询将连接条件与过滤条件进行了严格分离。ON 子句专门负责建立表与表之间的拓扑网络,而 WHERE 专门负责对筛选后的结果集进行过滤。这极大地提升了复杂 SQL 语句的可读性与后期维护效率
-
执行优化可控: 显式连接使得查询优化器能够更清晰地识别真实意图,从而在解析时更高效地选择索引扫描策略,避免在内存中生成不必要的中间态笛卡尔积,保障线上系统的吞吐量
二、内连接
内连接是多表关联查询中最基础、也是最常用的连接方式。它代表了多张表之间最严格的交集逻辑
1. 内连接概念与语法
内连接(INNER JOIN)是指只有当参与连接的两张表都满足连接条件时,才会返回对应的行
如果在左表(如 students)中发现某条记录的关联字段在右表(如 classes)中找不到匹配项,或者右表的某条记录在左表中无对应匹配,这些无法闭环的 "孤儿数据" 都会在最终的结果集中丢弃
标准语法
在 SQL-92 标准中,显式内连接使用 INNER JOIN 关键字来连接表,并使用 ON 关键字来承载连接条件:
sql
SELECT
投影列1,
投影列2, ...
FROM 表名A
INNER JOIN 表名B -- INNER 关键字可以省略,单独写 JOIN 默认即为内连接
ON 表名A.关联字段 = 表名B.关联字段;2. 内连接执行过程
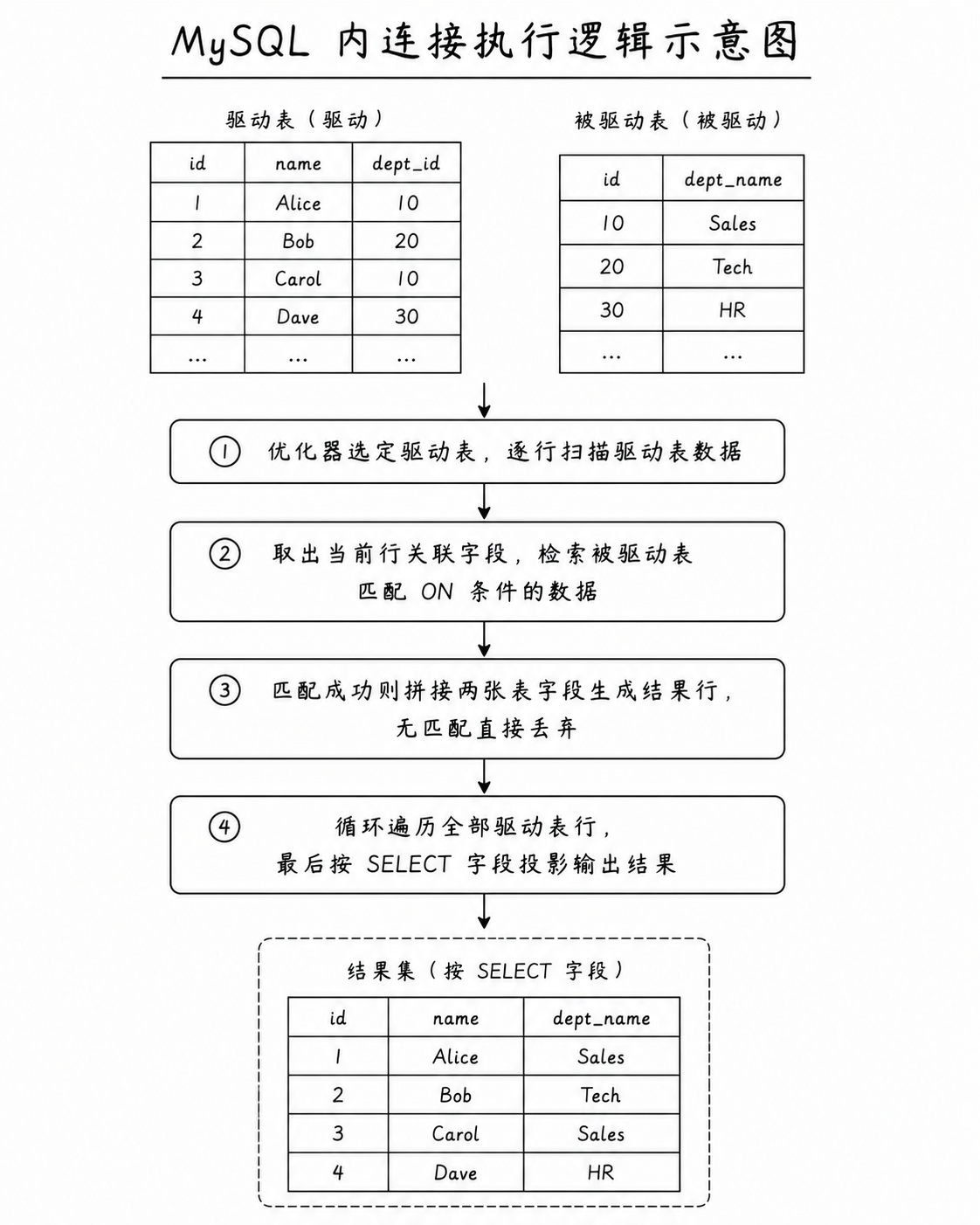
当 MySQL 执行引擎处理一条 INNER JOIN 语句时,其内部的逻辑大致分为以下几个步骤:
-
扫描驱动表: 优化器会根据索引和表大小,选择其中一张表作为 "驱动表"(Driver Table),开始逐行扫描
-
条件判定与匹配: 针对驱动表中的每一行数据,引擎会拿着其关联字段的值,去另一张表(被驱动表)中检索满足 ON 条件的记录
-
行组装: 如果在被驱动表中找到了匹配的行,则将两张表的字段横向拼接,合成结果集中的一行;如果找不到,则丢弃当前驱动表的这一行
-
输出投影: 重复上述过程直到驱动表扫描完毕,最后根据 SELECT 后面的字段进行列投影输出
3. 学生与班级案例
我们使用上一章初始化的教务管理系统数据集,查询所有建立了明确班级归属的学生姓名及其对应的班级名称
sql
SELECT
s.student_id AS 学号,
s.student_name AS 学生姓名,
c.class_name AS 班级名称
FROM students AS s
INNER JOIN classes AS c
ON s.class_id = c.class_id;执行结果:
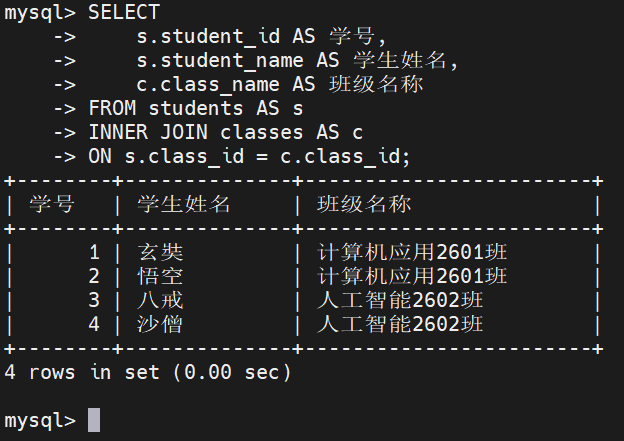
输出分析:
可以发现最终结果仅输出了 4 条记录。以下两条边界数据在内连接中被自动过滤:
-
**学生表的 "自由学者":**由于其 class_id 为 NULL,在 classes 表中匹配不到任何物理班级,因此未在结果中出现
-
班级表的 "高维数据挖掘3班" 与 "暂无学生空置班": 由于在 students 表中没有任何一名学生的 class_id 与之对应,同样不满足 ON 条件而被过滤
内连接的特点总结
-
对等性与对称性: 内连接在逻辑上是完全对称的。这意味着 FROM students INNER JOIN classes 与 FROM classes INNER JOIN students 的结果集行数与核心数据是完全一致的(仅左右列的排列顺序因声明顺序不同而有差异)
-
数据交集: 它只能用来探查多表之间全量匹配的健康数据。如果业务需求需要保留未匹配的边界数据(例如:查出所有学生,哪怕他没有班级),内连接则无法胜任,此时必须升级使用外连接(OUTER JOIN)
三、外连接
在内连接中,只有完全满足 ON 条件的交集数据才能被检索输出。但在许多实际业务中,我们需要获取某张表的全量视图,即使它在另一张表中缺失对应的关联记录。例如:在统计教务报表时,既要列出所有学生的选课情况,也必须完整保留那些 "尚未选课" 的学生信息
为了应对这种非对称的数据组合需求,标准 SQL 引入了外连接。本段将左外连接与右外连接的运行机理及特点进行合并对比解析
1. 外连接概念
外连接分为左外连接和右外连接 。其核心逻辑在于:指定其中一张表为 "主表"(保留全量行),另一张表为 "从表"(进行匹配)
-
如果主表的某行记录在从表中找到了匹配项,则正常横向拼接输出
-
如果主表的某行记录在从表中找不到任何匹配项 ,由于主表具备全量保留的权利,系统不会丢弃该行,而是自动在对应的从表投影列中填充 NULL 值
2. 左外连接
左外连接以 FROM 子句中写在左侧的表为主表,写在右侧的表为从表
sql
SELECT 投影列1, 投影列2, ...
FROM 表A AS s
LEFT OUTER JOIN 表B AS c -- OUTER 关键字通常省略
ON s.关联字段 = c.关联字段;执行过程:
-
引擎以左表(表A)作为驱动表,进行全表行扫描
-
拿着左表的关联键值去右表(表B)中匹配
-
若匹配成功,输出组合行;若匹配失败,保留左表数据,右表字段全部以 NULL 填充
3. 左外连接使用案例
业务需求: 获取所有学生的学号、姓名以及他们所属的班级名称。如果该学生尚未分配班级,也需要将其列出
sql
SELECT
s.student_id AS 学号,
s.student_name AS 学生姓名,
c.class_name AS 班级名称
FROM students AS s
LEFT JOIN classes AS c -- students 为左表,全量保留
ON s.class_id = c.class_id;执行结果:
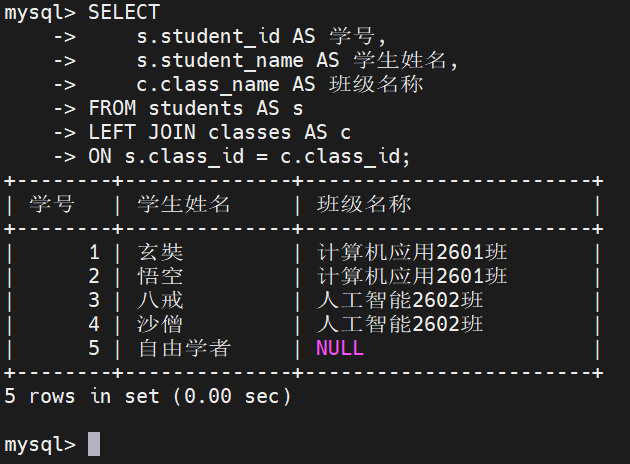
**输出分析:**结果集共输出 5 行。原本在内连接中被过滤掉的 "自由学者",由于此时处于 LEFT JOIN 的主表端,其记录被完整保留,同时其对应的 "班级名称" 列被自动填充为 NULL
4. 右外连接与实战案例
右外连接与左外连接的逻辑恰好相反,它以写在 JOIN 关键字右侧的表为主表,全量保留其所有行
sql
SELECT 投影列1, 投影列2, ...
FROM 表A AS s
RIGHT JOIN 表B AS c -- 表B 为右表,全量保留
ON s.关联字段 = c.关联字段;业务需求: 导出所有班级的架构分布表,要求列出每一个班级的名称及其内部包含的学生姓名。如果某个班级目前是空置状态(没有学生),也必须将班级名称展示出来
sql
SELECT
c.class_id AS 班级编号,
c.class_name AS 班级名称,
s.student_name AS 学生姓名
FROM students AS s
RIGHT JOIN classes AS c -- classes 为右表,全量保留
ON s.class_id = c.class_id;执行结果:
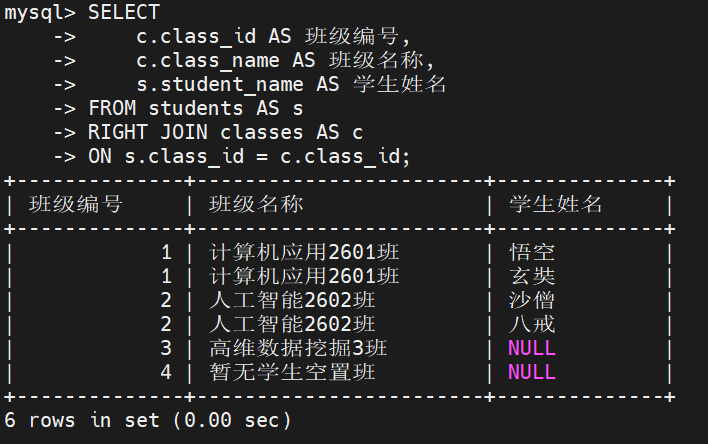
**输出分析:**结果集共输出 6 行。因为一个班级可能对应多名学生(如 2601 班对应玄奘与悟空),所以这两行会正常横向展开。而 "高维数据挖掘3班" 与 "暂无学生空置班" 由于没有任何学生,其对应的 "学生姓名" 列被自动填充为 NULL。同时,没有班级的 "自由学者" 在右连接中被自动过滤
5. 外连接的底层特点
在逻辑本质上,左外连接与右外连接是完全对称且可以相互转换的。 也就是说,以下两条 SQL 语句在执行引擎内部生成的执行计划和最终产出的数据集是完全等价的:
sql
-- 语句 A:左连接
FROM students AS s LEFT JOIN classes AS c ON s.class_id = c.class_id;
-- 语句 B:右连接(调换表顺序,将 LEFT 改为 RIGHT)
FROM classes AS c RIGHT JOIN students AS s ON s.class_id = c.class_id;虽然右连接在语法上完全成立,但在行业实际工程开发中,绝大多数架构师和开发人员会统一使用 LEFT JOIN
原因在于: 人类的思维和阅读习惯通常是从左向右、自上而下。使用 LEFT JOIN 时,排在最前面的 FROM 表A 就是最核心的主业务表,后续所有的 LEFT JOIN 都是基于这张主表进行维度的横向扩展,代码的线性流向非常清晰。混合使用 LEFT JOIN 和 RIGHT JOIN 会导致代码可读性严重下降,容易引入逻辑 Bug
四、连接查询练习题
在真实的工程开发中,连接查询最核心的物理应用主要集中在两类场景:多维全量数据对齐 与边界孤岛数据探测(Anti-Join 模式)
下面我们基于前面已经建立的教务数据集,通过 4 个业务练习来拆解连接查询的解题套路
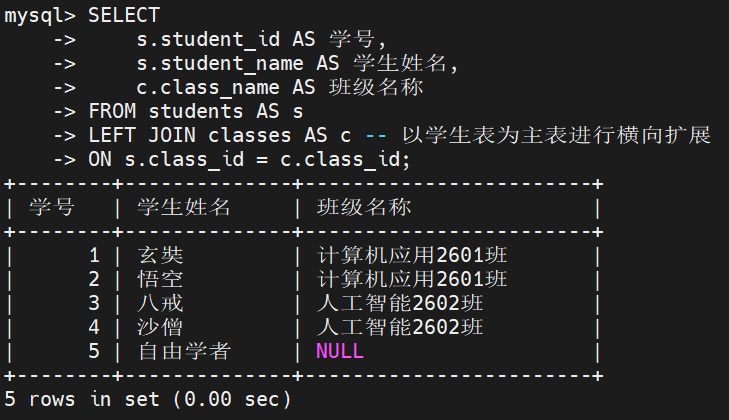
1. 查询所有学生对应班级
业务需求: 学校管理层需要导出一份全量学生名册,要求展示学生的学号、姓名以及班级名称。为了防止人员遗漏,即便该学生目前属于 "自由学者" 或尚未分配任何班级,也必须保留在名册中
解题思路: 需求的关键字在于 "所有学生"。这明确指示了必须以学生表(students)作为主表进行全量保留。因此,应当使用左外连接,将 students 置于左侧
SQL 实现
sql
SELECT
s.student_id AS 学号,
s.student_name AS 学生姓名,
c.class_name AS 班级名称
FROM students AS s
LEFT JOIN classes AS c -- 以学生表为主表进行横向扩展
ON s.class_id = c.class_id;执行结果:
2. 查询没有班级的学生
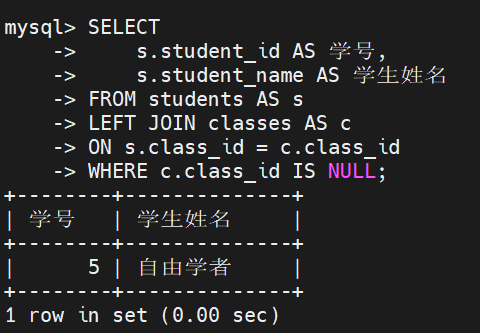
业务需求: 学籍管理中心需要进行准入合规性检查,查出目前尚未被分配到任何行政班级的学生
解题思路: 这是一种经典的反连接(Anti-Join) 架构
-
首先,重复练习一的步骤,使用 LEFT JOIN 将学生表与班级表强行拼接,暴露出包含 NULL 的全量视图
-
其次,利用 WHERE 子句进行后置拦截。那些没有班级的学生,在连接后其右侧属于班级表的字段(如 c.class_id)必然会被自动填充为 NULL。我们只需精准捕获这个特征即可
SQL 实现
sql
SELECT
s.student_id AS 学号,
s.student_name AS 学生姓名
FROM students AS s
LEFT JOIN classes AS c
ON s.class_id = c.class_id
WHERE c.class_id IS NULL; -- 只保留右表对齐失败的记录执行结果:
3. 查询没有学生的班级
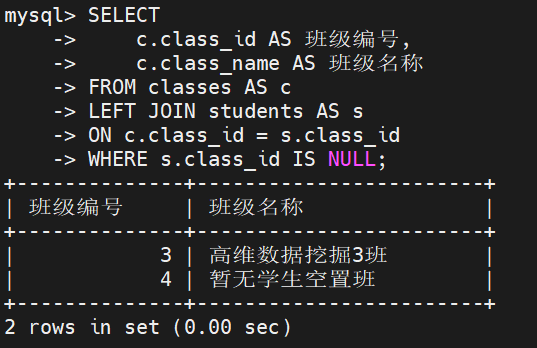
业务需求: 资产管理部需要盘点教学资源,要求找出当前没有任何学生入驻的空置行政班级,以便重新规划教室排课
解题思路: 本题同样属于反连接场景,但主体发生了调换。这一次需要全量保留的是班级数据
-
为了保持从左到右的阅读习惯,我们将班级表(classes)作为左表,LEFT JOIN 学生表(students)
-
连接建立后,如果某个班级没有学生,其右侧的学生主键(s.student_id)必然为 NULL
SQL 实现
sql
SELECT
c.class_id AS 班级编号,
c.class_name AS 班级名称
FROM classes AS c
LEFT JOIN students AS s
ON c.class_id = s.class_id
WHERE s.student_id IS NULL; -- 过滤出没有学生填补的空壳班级执行结果:
4. 综合练习
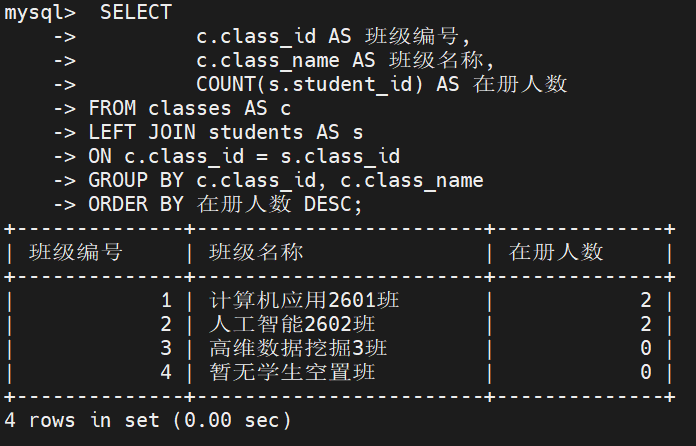
业务需求: 教务长需要查看一份精细化的班级人数统计报表,要求输出:班级编号、班级名称、对应在册人数
-
特殊边界: 为了报表的严密性,没有学生的空置班级也必须输出,且人数显示为 0
-
非功能需求: 结果集必须按照在册人数从高到低进行降序排列
解题思路:
-
**跨表:**要确保 "没有学生的班级" 不丢失,必须以 classes 为主表进行 LEFT JOIN
-
**聚合维度:**按照班级进行分组,因此需要附加 GROUP BY c.class_id, c.class_name
-
核心考点: 统计人数时,绝对不能使用 COUNT(*),而必须使用 COUNT(s.student_id)
为什么不能用 COUNT(*)?
COUNT(*) 统计的是最终结果集中的物理行数。在左连接后,像 "高维数据挖掘3班" 这种空置班级虽然右侧全为 NULL,但它依然占据了结果集中的 1 行空间。如果使用 COUNT(*),该班级的人数会被错误地统计为 1
而 COUNT(列名) 在执行时会自动忽略 NULL 值。由于空置班级的 s.student_id 为 NULL,COUNT 计算后会准确反馈为 0
SQL 实现
sql
SELECT
c.class_id AS 班级编号,
c.class_name AS 班级名称,
COUNT(s.student_id) AS 在册人数 -- 核心:只统计学生有效主键的数量
FROM classes AS c
LEFT JOIN students AS s
ON c.class_id = s.class_id
GROUP BY c.class_id, c.class_name
ORDER BY 在册人数 DESC; -- 降序排列执行结果:
五、实战OJ
1. LeetCode 178. 分数排名 (Rank Scores)
1.1 题目分析
题目要求对 Scores 表中的分数进行降序排列,并生成对应的排名。排名必须遵循以下三条规则:
-
分数从高到低排列
-
如果两个分数相同,则两者的排名相同
-
在出现并列排名之后,下一个名次应当是连续的整数(即:1、2、2、3,这种排名方式在统计学中被称为密集排名 Dense Rank)
数据表结构:Scores
| Column Name | Type |
|---|---|
| id | int (Primary Key) |
| score | decimal |
1.2 解题思路
虽然在现代 MySQL 中可以直接使用窗口函数 DENSE_RANK() 解决此问题,但为了锻炼关系型代数思维,本节重点解析如何利用非等值内连接与分组聚合来攻克此题
-
排名的数学本质: 某一个分数 S1 的密集排名,实际上等于全表大于或等于 S1 的 "去重后的分数" 的总个数
-
例如:若分数集合为 {10, 9, 9, 8}
-
大于等于 10 的去重集合为 {10},计数为 1,排名第 1
-
大于等于 9 的去重集合为 {10, 9},计数为 2,排名第 2
-
大于等于 8 的去重集合为 {10, 9, 8},计数为 3,排名第 3
-
-
连接构建: 将 Scores 表进行自连接,分别起别名为 s1 和 s2
-
连接条件: ON s2.score >= s1.score。通过这种方式,对于 s1 中的每一行分数,s2 都会匹配出所有大于或等于该分数的行
-
分组与去重统计: 按照 s1.id 和 s1.score 进行分组(GROUP BY),随后利用 COUNT(DISTINCT s2.score) 统计出有多少个不同的更高分数
1.3 SQL 实现
sql
SELECT
s1.score,
COUNT(DISTINCT s2.score) AS `rank` -- 核心:统计大于等于当前分数的去重分数个数
FROM Scores AS s1
INNER JOIN Scores AS s2
ON s2.score >= s1.score -- 非等值自连接条件
GROUP BY s1.id, s1.score -- 按照物理主键与数值分组,确保全面兼容 ONLY_FULL_GROUP_BY 模式
ORDER BY s1.score DESC; -- 依照题目要求降序排列2. LeetCode 626. 换座位 (Exchange Seats)
2.1 题目分析
在一间教室内,连续座位的学生想要交换相邻的座位。编写一个 SQL 查询来交换每两个连续学生的座位。如果学生总人数是奇数,则最后一个学生的座位不需要交换。最终结果需按座位 id 升序排列
数据表结构:Seat
| Column Name | Type |
|---|---|
| id | int (Primary Key, Increment) |
| student | varchar |
样本输入:
| id | student |
|---|---|
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
2.2 解题思路
本题的核心难点在于,数据行的相互调换通常属于应用层的逻辑,而在 SQL 中,我们必须通过控制连接条件的映射网络来达成数据的错位重组。这里使用左外连接能够提供一种优雅的解法
-
逻辑映射规则拆解:
-
连接条件复合化: 将上述两条映射规则通过 OR 连接,写入 ON 子句中
-
**边界条件控制:**若总人数为奇数(例如总共 3 人),当左表 s1.id = 3 时,依据规则它会尝试连接 s2.id = 4。但由于 4 号不存在,右表对应的 s2.student 将返回 NULL。 为了保留 3 号座位原本的学生,我们使用 IFNULL(s2.student, s1.student)
2.3 SQL 实现
sql
SELECT
s1.id,
IFNULL(s2.student, s1.student) AS student -- 若右表匹配失败(如奇数末尾行),则保留原学生姓名
FROM Seat AS s1
LEFT JOIN Seat AS s2 -- 使用左外连接,确保左表所有的座位框架行不丢失
ON (s1.id % 2 = 1 AND s2.id = s1.id + 1) -- 规则1:奇数座位匹配下一个偶数座位
OR (s1.id % 2 = 0 AND s2.id = s1.id - 1) -- 规则2:偶数座位匹配上一个奇数座位
ORDER BY s1.id ASC; -- 结果集要求按座位号升序排列总结
综上所述,我们学习了 MySQL 中最常用的连接查询方式,包括内连接、左外连接以及右外连接,并通过多个案例理解了它们在数据关联过程中的区别与适用场景
从本质上来看,连接查询解决的是如何将分散在不同数据表中的数据重新组织起来
而内连接与外连接的区别,则在于是否保留那些没有成功匹配的数据记录
与此同时,通过练习题和 LeetCode 实战题,我们进一步体会到了连接查询在实际业务开发中的重要性。可以说,多表关联能力已经是数据库开发中的一项核心技能
不过,随着数据量不断增大,一个新的问题也随之出现:
为什么有些查询几乎瞬间完成?而有些查询却需要等待数秒甚至更久?数据库究竟是如何快速找到我们需要的数据的?
这些问题的答案都指向数据库中最重要的性能优化机制------索引
因此,在下一篇中,我们将正式进入 MySQL 索引专题,从索引的基本概念、作用以及底层思想开始,逐步揭开数据库高效查询背后的秘密
