引述
前面提到,我们通过神经网络的前向传播,让数据从输入层传播到输出层,最终得到预测值 y ^ \hat{y} y^ 。但问题是:我们为每个神经元设置的权重和偏置一开始都是随机初始化的,预测值 y ^ \hat{y} y^ 与真实值 y y y 之间必然存在偏差。
那么我们应该如何调整这些权重和偏置,才能让预测值尽可能逼近真实值,更好地模拟现实呢?如果网络很小、参数很少,或许可以逐个穷举尝试。但是现实中的神经网络动辄有成千上万的参数,人工参数根本不现实,这就需要神经网络自己去探索什么样的参数最合适。这个过程,就是神经网络的学习。
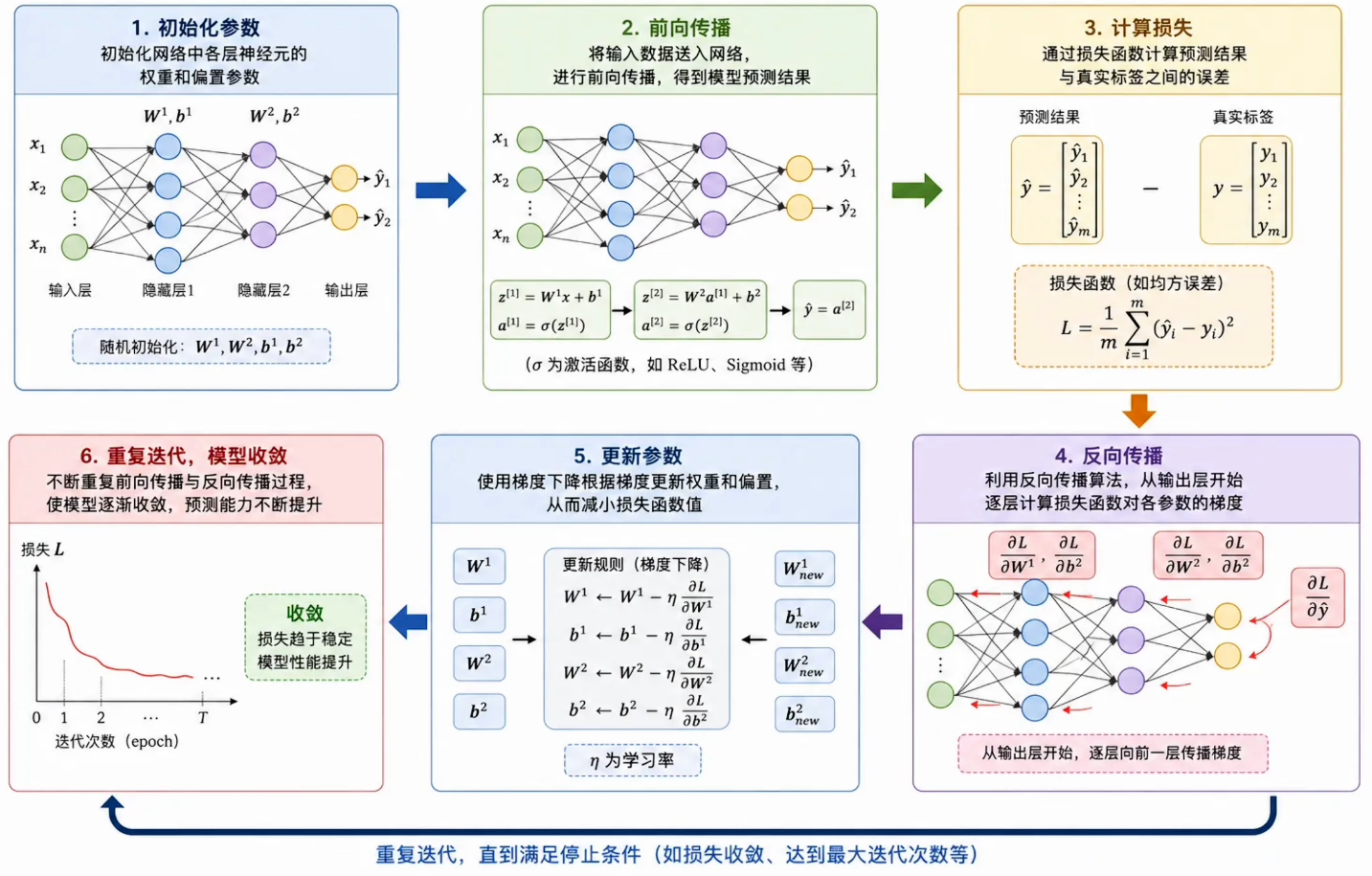
上面是神经网络的整个流程,对网络的学习阶段,更加细化,可以具体分为下面 4 4 4 个步骤:
- 计算损失 ------ 通过人为设置计算公式(损失函数),量化输出值与真实标签的偏差
- 反向传播 ------ 从输出层反向计算到输入层,逐层计算损失函数对各参数的梯度
- 更新参数 ------ 使用梯度下降,神经网络根据梯度更新权重和偏置,从而减小损失函数值
- 重复迭代 ------ 不断重复使用前向和反向传播过程,使模型逐渐收敛(即与真实标签的误差越来越小),提高预测能力
下面介绍学习的第一个步骤,计算损失函数。
损失函数
神经网络通过损失函数 来衡量当前预测与真实值的差距 L \mathcal{L} L ,学习的目标就是最小化损失函数
数据形式
-
当神经网络输入一个样本时,其输出数据和监督数据的形式如下:
所谓监督 数据就是正确 答案------每张训练图像在采集时由人标注好的真实标签,是神经网络学习的参照标准
-
输出数据 y y y ------ y y y 是每个标签的概率分布,是一维数组
如输入一张图片,判断是猫、狗、鸟、兔、人。网络的输出为
[0.1, 0.05, 0.7, 0.05, 0.1],依次表示每个标签的概率单个数据 批处理(N 个数据) [0.1, 0.05, 0.7, 0.05, 0.1](一维数组)[[0.1, 0.05, 0.7, ...], [0.8, 0.02, 0.01, ...], ...](二维数组,形状(N, C)) -
监督数据 t t t ------ 两种形式: o n e one one- h o t hot hot 向量 和 标签索引
-
o n e one one- h o t hot hot 向量 ------ 监督数据 t t t 把正确类别对应的位置存为
1,其余为0,是一维数组如一张鸟的摄影照片,监督数据为
[0, 0, 1, 0, 0],仅鸟所在标签的位置为1,表示该类别正确,其他均错误 -
标签索引 ------ 监督数据 t t t 直接存类别索引,是标量
如一张鸟的摄影照片,监督数据为整数
2,表示索引2所在的标签(鸟)是正确的
-
均方误差(Mean Squared Error)
-
数学表达 ------ 对于输出向量 y = y 1 , y 2 , . . . , y m T y = \begin{bmatrix} y_1 , y_2 , ... , y_m \end{bmatrix}^T y=y1,y2,...,ymT,真实标签 $t = \begin{bmatrix}
t_1 , t_2 , ... , t_m \end{bmatrix}^T $,均方误差 L \mathcal{L} L 为:
L = 1 m ∑ i = 1 m ( y i − t i ) 2 \mathcal{L} = \frac{1}{m}\sum_{i=1}^{m} (y_i - t_i)^2 L=m1i=1∑m(yi−ti)2
其含义是,计算所有输出值 y i y_i yi 与真实值 t i t_i ti 的差值平方 的平均值
-
代码实现
pythondef mean_squared_error(y, t): return 0.5 * np.sum((y - t)**2)pythont = np.array([0, 0, 1, 0, 0]) # 正确标签是"2" y1 = np.array([0.1, 0.05, 0.6, 0.05, 0.2]) # 预测正确 y2 = np.array([0.1, 0.05, 0.1, 0.05, 0.7]) # 预测错误pythonprint(f"正确预测: {mean_squared_error(y1, t):.4f}") print(f"错误预测: {mean_squared_error(y2, t):.4f}")
交叉熵误差(Cross Entropy Error)
标签形式
-
标签索引 ------ 对于输出向量 y = y 1 , y 2 , . . . , y m T y = \begin{bmatrix} y_1 , y_2 , ... , y_m \end{bmatrix}^T y=y1,y2,...,ymT,真实标签 t t t 为类别索引( t ∈ { 0 , 1 , . . . , m − 1 } t \in \{0, 1, ..., m-1\} t∈{0,1,...,m−1}),误差 L \mathcal{L} L 为
L = − log ( y t ) \mathcal{L} = -\log(y_t) L=−log(yt)
其中, y t y_t yt 即正确类别 t t t 对应的输出概率
-
代码实现
pythondef cross_entropy_error(y, t): return -np.log(y[t] + 1e-7 )直接通过索引 t t t 取出 y t y_t yt 进行计算即可:
y[t]
one-hot 向量形式
-
数学表达 ------ 对于输出向量 y = y 1 , y 2 , . . . , y m T y = \begin{bmatrix} y_1 , y_2 , ... , y_m \end{bmatrix}^T y=y1,y2,...,ymT(概率分布),真实标签 t = t 1 , t 2 , . . . , t m T t = \begin{bmatrix} t_1 , t_2 , ... , t_m \end{bmatrix}^T t=t1,t2,...,tmT,误差 L \mathcal{L} L 为
L = − ∑ i = 1 m t i log ( y i ) \mathcal{L} = -\sum_{i=1}^{m} t_i \log({y_i}) L=−i=1∑mtilog(yi)
!NOTE
由于 t t t 是
one-hot编码(正确类别对应的位置为1,其余为0)故错误类别项为 − 0 ⋅ l o g ( y i ^ ) = 0 -0 \cdot log(\hat{y_i}) = 0 −0⋅log(yi^)=0 ,直接消去。该公式本质上等价于标签形式的误差 E = − log ( y k ) E = -\log({y_k}) E=−log(yk),如:
- y = 0.1 , 0.6 , 0.3 T {y} = \begin{bmatrix} 0.1 , 0.6 , 0.3 \end{bmatrix}^T y=0.1,0.6,0.3T, t = 1 , 0 , 0 T t = \begin{bmatrix} 1 , 0 , 0 \end{bmatrix}^T t=1,0,0T,误差值为 − ( 1 ⋅ l o g ( 0.1 ) + 0 ⋅ l o g ( 0.6 ) + 0 ⋅ l o g ( 0.3 ) = − l o g ( 0.1 ) = 2.30 -(1 \cdot log(0.1)+0 \cdot log(0.6)+0 \cdot log(0.3) = -log(0.1) = 2.30 −(1⋅log(0.1)+0⋅log(0.6)+0⋅log(0.3)=−log(0.1)=2.30
- y = 0.1 , 0.6 , 0.3 T {y} = \begin{bmatrix} 0.1 , 0.6 , 0.3 \end{bmatrix}^T y=0.1,0.6,0.3T, t = 0 , 1 , 0 T t = \begin{bmatrix} 0 , 1 , 0 \end{bmatrix}^T t=0,1,0T,误差值为 − ( 0 ⋅ l o g ( 0.1 ) + 1 ⋅ l o g ( 0.6 ) + 0 ⋅ l o g ( 0.3 ) = − l o g ( 0.6 ) = 0.51 -(0 \cdot log(0.1)+1 \cdot log(0.6)+0 \cdot log(0.3) = -log(0.6) = 0.51 −(0⋅log(0.1)+1⋅log(0.6)+0⋅log(0.3)=−log(0.6)=0.51
-
代码实现
pythondef cross_entropy_error(y, t): return -np.sum(t * np.log(y + 1e-7)) # 添加极小值 1e-7 防止 log(0) 导致数值溢出pythont = np.array([0, 0, 1, 0, 0]) # 正确标签是"2" y1 = np.array([0.1, 0.05, 0.6, 0.05, 0.2]) # 预测正确(最大概率在索引2) y2 = np.array([0.1, 0.05, 0.1, 0.05, 0.7]) # 预测错误(最大概率在索引4)pythonprint(f"正确预测: {cross_entropy_error(y1, t):.4f}") # 输出 0.5108 print(f"错误预测: {cross_entropy_error(y2, t):.4f}") # 输出 2.3026可以看到,当预测正确(正确类别的概率 y k {y_k} yk 较高)时,误差较小;当预测错误(正确类别的概率很低)时,误差显著增大
M i n i − b a t c h Mini-batch Mini−batch 学习
背景
-
神经网络的学习目标是:针对所有训练数据计算损失函数,找出使损失尽可能小的参数。
-
以交叉熵误差为例:
-
前面的公式考虑的都是针对单个训练数据的损失函数:
L = − ∑ i = 1 m t i log ( y i ^ ) \mathcal{L} = -\sum_{i=1}^{m} t_i \log(\hat{y_i}) L=−i=1∑mtilog(yi^)
-
若训练数据有 N N N 个,总损失可以是所有样本损失的平均值 :
L = − 1 N ∑ n = 1 N ∑ i = 1 m t n i log ( y n i ^ ) \mathcal{L} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{i=1}^{m} t_{ni } \log (\hat{y_{ni}}) L=−N1n=1∑Ni=1∑mtnilog(yni^)
-
-
一次计算所有训练数据再取平均值的理念是好的,但现实是残酷的------ M N I S T MNIST MNIST 训练集有 60000 60000 60000 张图, I m a g e N e t ImageNet ImageNet 有百万级,大模型训练数据更是以 T B TB TB 计。每次参数更新都算一遍全部数据,计算量不可接受,训练一步就要等半天。
-
m i n i mini mini- b a t c h batch batch 学习的思路是:每次从训练数据中随机抽取一小批,用这批数据的平均损失作为整体损失的近似,然后更新参数
就像调查收视率不需要问遍全国,随机选 1000 1000 1000 户就能近似整体
m i n i − b a t c h mini-batch mini−batch 版数据读取
-
前面读入 M N I S T MNIST MNIST 数据集的代码如下,训练数据 60000 60000 60000 个,输入 784 784 784 维( 28 × 28 28×28 28×28 展平),监督标签 10 10 10 维( o n e one one- h o t hot hot 表示)
pythonimport numpy as np from dataset.mnist import load_mnist (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) print(x_train.shape) # (60000, 784) print(t_train.shape) # (60000, 10) -
现在采用如下方法,随机抽取 10 10 10 笔数据,代码如下:
- 初始化 t r a i n _ s i z e train\_size train_size 和 b a t c h _ s i z e batch\_size batch_size 参数,分别表示总样本数( 60000 60000 60000)和抽取样本数( 10 10 10)
- 采用
np.random.choice(60000, 10)方法从 0 − 59999 0-59999 0−59999 中随机选 10 10 10 个索引 - 用产生的索引取出 x _ b a t c h x\_batch x_batch 、 t _ b a t c h t\_batch t_batch 对应的数据
pythonimport numpy as np train_size = x_train.shape[0] # 60000 batch_size = 10 batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] # 随机抽取的 10 笔输入 t_batch = t_train[batch_mask] # 对应的 10 笔标签
m i n i − b a t c h mini-batch mini−batch 版交叉熵误差
数据形式
-
当采用 m i n i − b a t c h mini-batch mini−batch 形式时,神经网络的数据形式有所变化
-
输出数据 y y y ------ 多样本时, y y y 包括了 N N N 样本 C C C 个标签的概率分布,整体变为二维数组
单个数据 批处理(N 个数据) [0.1, 0.05, 0.7, 0.05, 0.1](一维数组,形状(C,))[[0.1, 0.05, 0.7, ...], [0.8, 0.02, 0.01, ...], ...](二维数组,形状(N, C)) -
监督数据 t t t
-
o n e one one- h o t hot hot 向量 ------ 监督数据 t t t 把正确类别对应的位置存为
1,其余为0单数据时:
[0, 0, 1, 0, 0](一维向量)批处理时:
[[0, 0, 1, 0, 0], [1, 0, 0, 0, 0], ...](二维矩阵) -
标签索引 ------ 监督数据 t t t 直接存类别索引
单数据时:
2(一个整数)批处理时:
[2, 7, 0, 9, 4](一维数组,每个元素是一个样本的正确类别编号,如2表示第1个样本第2个类别正确,7表示第2个样本第7个类别正确,以此类推)
单个数据 批处理(N 个数据) o n e − h o t one-hot one−hot 形式 [0, 0, 1, 0, 0](一维数组,形状(C,))[[0,0,1,0,0], [1,0,0,0,0], ...](二维数组,形状(N, C))标签形式 2(单个整数)[2, 0, 7, ...](一维数组,形状(N,)) -
o n e − h o t one-hot one−hot 形式的交叉熵误差
-
代码实现
pythondef cross_entropy_error(y, t): # 单个数据时整形为批处理形式 if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 除以 batch 数求平均 batch_size = y.shape[0] return -np.sum(t * np.log(y + 1e-7)) / batch_size- 当输入为单个数据时( y y y 的维度为 1 1 1),需要通过
reshape改变数据的形状 - 当输入为 m i n i mini mini- b a t c h batch batch 时,使用 b a t c h batch batch 的个数进行正规化,计算单个数据的平均交叉熵误差
- 当输入为单个数据时( y y y 的维度为 1 1 1),需要通过
标签形式的交叉熵误差
-
代码实现
pythondef cross_entropy_error(y, t): if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 只取正确标签对应位置的输出求 log batch_size = y.shape[0] return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size-
当输入为单个数据时( y y y 的维度为 1 1 1),同上
-
当输入为 m i n i mini mini- b a t c h batch batch 时,需要使用
y[np.arange(batch_size), t]方法获取正确标签处的输出python-np.sum(np.log(y[np.arange(batch_size), t])) / batch_sizenp.arange(batch_size)生成行号[0, 1, 2, 3, 4]------ 代表第 0 0 0 个样本、第 1 1 1 个样本 ......t是每个样本的正确标签[2, 7, 0, 9, 4]------ 代表每个样本的正确答案在第几列- 两者组合起来,就是从 y y y 中依次取:第 0 0 0 行第 2 2 2 列、第 1 1 1 行第 7 7 7 列、第 2 2 2 行第 0 0 0 列 ...... ,恰好对应每个样本在正确标签位置上的预测概率
-
举例说明
pythony = np.array([ [0.1, 0.05, 0.7, 0.05, 0.02, 0.03, 0.01, 0.02, 0.01, 0.01], # 样本0 [0.01, 0.02, 0.01, 0.03, 0.05, 0.02, 0.1, 0.7, 0.04, 0.02], # 样本1 [0.9, 0.02, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01], # 样本2 [0.01, 0.02, 0.03, 0.04, 0.05, 0.02, 0.03, 0.02, 0.01, 0.7], # 样本3 [0.02, 0.01, 0.03, 0.05, 0.9, 0.01, 0.02, 0.01, 0.03, 0.01], # 样本4 ]) t = np.array([2, 7, 0, 9, 4]) result = y[np.arange(5), t] # 等价于逐个取:y[0,2], y[1,7], y[2,0], y[3,9]、y[4,4], 输出 [0.7, 0.7, 0.9, 0.7, 0.9]
-
参考文献:
1 斋藤康毅. 深度学习入门:基于Python的理论与实现M. 陆宇杰, 译. 北京: 人民邮电出版社, 2018.
2 谦行AIing. "反向传播:海量参数的神经网络如何训练." 小红书 , 2026.5.17, http://xhslink.com/o/AGMk0k28BwZ