作者注 :本文基于 Langflow 官方模板 Interactive Data Dashboards 进行深度技术拆解,结合 Langflow 框架的最新文档与工程实践,为 AI 应用开发者提供一份可直接落地的技术指南。

一、为什么需要 Langflow 来做数据仪表盘?
传统的数据仪表盘开发链路冗长:业务需求 → SQL 编写 → 后端接口 → 前端图表组件 → 联调部署。每次需求变更都要走一遍完整流程。
Langflow 提供了一种全新的范式:自然语言驱动的双阶段智能体架构。用户只需用一句话提问------"展示本季度各产品线的收入趋势"------系统就能自动完成 SQL 生成、数据库查询、可视化方案选择、图表代码生成与渲染,端到端交付结果。
这背后的核心是 Langflow 作为低代码 AI 工作流平台的能力:
- 可视化拖拽构建:无需手写编排逻辑,通过画布连接组件即可定义数据流
- 多 Agent 协同:支持将复杂任务拆分为多个专职 Agent 串联/并联执行
- Python 原生扩展:任何组件都可深入到代码级别自定义
- API 自动生成:每个工作流一键转为 RESTful 端点,无缝集成到现有系统
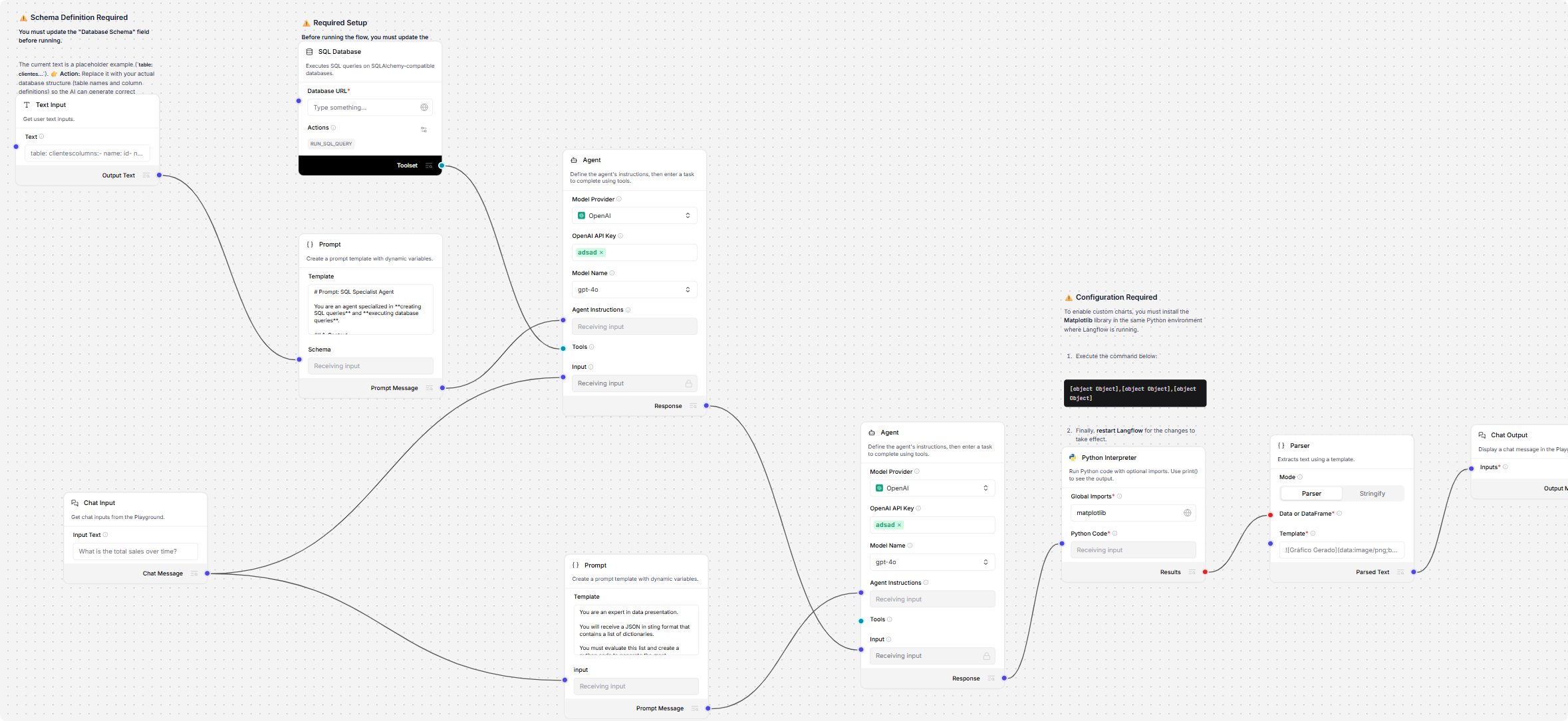
二、架构全景:双阶段 Agent 流水线
该模板的核心设计是一个顺序执行的双阶段 Agent 架构,每个阶段各司其职:
┌──────────────────────────────────────────────────────────────────┐
│ 用户自然语言问题 │
│ "展示本季度各产品线的收入趋势" │
└──────────────────────┬───────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ 阶段一:SQL 专家智能体 │
│ │
│ ┌─────────────┐ ┌───────────────┐ ┌─────────────────┐ │
│ │ Chat Input │───▶│ Prompt │───▶│ SQL Database │ │
│ │ (用户问题) │ │ Template │ │ Tool │ │
│ └─────────────┘ │ (Schema + │ │ (执行查询) │ │
│ │ 角色指令) │ └────────┬────────┘ │
│ └───────────────┘ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Structured │ │
│ │ Output (JSON) │ │
│ └────────┬────────┘ │
└──────────────────────────────────────────────────┼──────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ 阶段二:数据可视化智能体 │
│ │
│ ┌─────────────────┐ ┌───────────────┐ ┌────────────────┐ │
│ │ JSON 查询结果 │───▶│ Prompt │───▶│ Code Generator │ │
│ │ (阶段一输出) │ │ Template │ │ (Python代码) │ │
│ └─────────────────┘ │ (可视化决策) │ └───────┬────────┘ │
│ └───────────────┘ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Matplotlib │ │
│ │ 图表渲染 │ │
│ └───────┬────────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Base64 图表 │ │
│ │ → 返回用户 │ │
│ └────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
设计哲学:关注点分离
这个架构的精妙之处在于关注点分离:
| 维度 | 阶段一(SQL Agent) | 阶段二(可视化 Agent) |
|---|---|---|
| 职责 | 理解意图 → 生成 SQL → 执行查询 | 理解数据 → 选择图表 → 生成代码 |
| 输入 | 自然语言 + 数据库 Schema | JSON 格式的查询结果 |
| 输出 | 结构化 JSON 数据 | Base64 编码的图表图像 |
| 核心能力 | SQL 生成 + 数据库操作 | 数据分析 + Matplotlib 编程 |
| 错误边界 | SQL 语法错误、权限问题 | 图表类型选择不当、代码执行失败 |
分离的好处是显而易见的:每个 Agent 的 Prompt 可以高度聚焦,LLM 不需要同时处理"如何写 SQL"和"如何画图"两个复杂任务,大幅降低了出错率。
三、阶段一深度解析:SQL 专家智能体
3.1 核心组件清单
SQL Agent 的构建依赖以下 Langflow 核心组件:
| 组件 | 功能 | 关键配置 |
|---|---|---|
| Chat Input | 捕获用户自然语言问题 | 支持多轮对话上下文 |
| Prompt Template | 塑造 Agent 角色与指令 | 包含数据库 Schema 注入 |
| SQL Database Tool | 连接数据库并执行 SQL | 需配置 Database URL |
| Structured Output | 将结果格式化为 JSON | 定义输出 Schema |
3.2 数据库 Schema 注入:让 LLM "看见"你的表结构
SQL Agent 能生成正确查询的前提是它理解数据库结构。Langflow 通过 Prompt Template 将 Schema 信息动态注入到 LLM 上下文中。
一个典型的 Schema 提示词结构如下:
text
你是一个 SQL 专家智能体。你的任务是根据用户的自然语言问题,
分析数据库 Schema 并生成正确的 SQL 查询语句。
## 数据库 Schema
{database_schema}
## 规则
1. 只生成 SELECT 语句,禁止执行任何修改数据的操作
2. 使用标准 SQL 语法,兼容 SQLite/PostgreSQL
3. 如果用户的问题涉及不存在的表或字段,返回错误说明
4. 查询结果以 JSON 数组格式返回,每个元素是一行记录
## 用户问题
{user_question}
## 输出格式
请先输出 SQL 语句,然后输出查询结果的 JSON。其中 {database_schema} 和 {user_question} 是动态变量,由 Langflow 在运行时注入。
3.3 SQL Database Tool 配置
Langflow 内置了 SQL Database 组件,支持 SQLite、PostgreSQL、MySQL 等主流数据库。配置步骤:
- 在画布上拖入 SQL Database 组件
- 配置 Database URL :
- SQLite:
sqlite:///path/to/database.db - PostgreSQL:
postgresql://user:password@host:5432/dbname - MySQL:
mysql://user:password@host:3306/dbname
- SQLite:
- 注入 Schema:组件会自动读取数据库的表结构信息
- 连接到 Agent 的 Prompt Template
3.4 结构化输出:JSON 格式约定
阶段一的输出必须能被阶段二正确消费。Langflow 的 Structured Output 组件可以约束 LLM 的输出格式:
python
# Structured Output 的 Schema 定义示例
output_schema = {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "生成的 SQL 查询语句"
},
"query_results": {
"type": "array",
"items": {
"type": "object"
},
"description": "查询结果,每行一个对象"
},
"row_count": {
"type": "integer",
"description": "结果行数"
}
},
"required": ["sql_query", "query_results"]
}这确保了无论用户的提问方式如何变化,阶段一的输出始终是结构化的 JSON,阶段二可以稳定解析。
四、阶段二深度解析:数据可视化智能体
4.1 可视化决策:如何选择正确的图表类型
第二阶段的 Agent 接收到 JSON 数据后,需要做出一个关键决策:用哪种图表展示这组数据最合适?
这个决策依赖于 LLM 对数据的"理解":
| 数据特征 | 推荐图表 | 典型场景 |
|---|---|---|
| 时间序列数据 | 折线图 | 收入趋势、访问量变化 |
| 分类对比数据 | 柱状图 | 各渠道转化率对比 |
| 占比/构成数据 | 饼图 | 部门支出占比 |
| 分布数据 | 直方图/箱线图 | 客户年龄分布 |
| 多维关联 | 散点图 | 价格与销量关系 |
| 排名数据 | 水平条形图 | Top 10 产品排名 |
Prompt Template 中的关键指令:
text
你是一个数据可视化专家。你将收到一个 JSON 格式的数据库查询结果,
以及用户的原始问题。
## 你的任务
1. 分析数据的结构和特征(行数、列数、数据类型、时间维度等)
2. 结合用户意图,选择最合适的图表类型
3. 生成 Python 代码,使用 Matplotlib 绘制图表
## 图表选择规则
- 时间序列 → 折线图(marker='o')
- 分类对比 → 柱状图(垂直或水平)
- 占比构成 → 饼图(autopct='%1.1f%%')
- 超过 10 个类别的占比 → 水平条形图
- 双变量关系 → 散点图
## 代码要求
1. 图表大小:figsize=(10, 6)
2. 包含标题、坐标轴标签、图例
3. 使用 plt.tight_layout() 防止标签溢出
4. 中文字体:设置 font.sans-serif 为 SimHei
5. 将图表保存为 Base64 编码的 PNG 字符串
## 输入数据
{query_results_json}
## 用户原始问题
{user_question}4.2 动态代码生成与执行
可视化 Agent 的输出是 Python 代码,这些代码在 Langflow 的执行环境中动态运行。以下是一个典型的生成代码示例:
python
import matplotlib
matplotlib.use('Agg') # 非交互式后端
import matplotlib.pyplot as plt
import base64
from io import BytesIO
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 模拟查询结果数据
data = [
{"product_category": "电子产品", "month": "2025-Q1", "revenue": 1250000},
{"product_category": "电子产品", "month": "2025-Q2", "revenue": 1380000},
{"product_category": "服装", "month": "2025-Q1", "revenue": 890000},
{"product_category": "服装", "month": "2025-Q2", "revenue": 950000},
{"product_category": "食品", "month": "2025-Q1", "revenue": 670000},
{"product_category": "食品", "month": "2025-Q2", "revenue": 720000},
]
# 数据处理
categories = list(set(d["product_category"] for d in data))
months = sorted(set(d["month"] for d in data))
fig, ax = plt.subplots(figsize=(10, 6))
for category in categories:
values = [next(d["revenue"] for d in data
if d["product_category"] == category and d["month"] == month)
for month in months]
ax.plot(months, values, marker='o', linewidth=2, label=category)
ax.set_title('本季度各产品线收入趋势', fontsize=14, fontweight='bold')
ax.set_xlabel('季度', fontsize=12)
ax.set_ylabel('收入 (¥)', fontsize=12)
ax.legend(loc='upper left')
ax.grid(True, alpha=0.3)
# 格式化 Y 轴
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{x/10000:.0f}万'))
plt.tight_layout()
# 转换为 Base64
buffer = BytesIO()
plt.savefig(buffer, format='png', dpi=150, bbox_inches='tight')
buffer.seek(0)
chart_base64 = base64.b64encode(buffer.read()).decode('utf-8')
plt.close()
print(f"data:image/png;base64,{chart_base64[:80]}...")4.3 图表传递机制
生成的图表以 Base64 编码 的 PNG 字符串返回,这种方式有两个优势:
- 无需文件系统:所有数据在内存中完成编码,适合容器化部署
- 前端直接渲染 :前端只需将 Base64 字符串塞入
<img src="data:image/png;base64,...">即可显示
五、API 集成:将工作流嵌入你的应用
5.1 Langflow API 架构
Langflow 基于 FastAPI 构建,每个保存的工作流都会自动生成 RESTful API 端点。核心接口如下:
| 端点 | 方法 | 用途 |
|---|---|---|
/api/v1/run/{flow_id} |
POST | 运行指定工作流 |
/api/v1/run/advanced/{flow_id} |
POST | 高级运行(显式传入 inputs/outputs/tweaks) |
/api/v1/webhook/{flow_id} |
POST | Webhook 触发(事件驱动场景) |
/api/v1/responses |
POST | 兼容 OpenAI 格式的接口 |
/health_check |
GET | 健康检查(含数据库和聊天服务状态) |
/api/v1/version |
GET | 获取 Langflow 版本信息 |
/api/v1/all |
GET | 获取所有可用组件列表 |
5.2 Python 客户端集成
以下是将交互式仪表盘工作流集成到 Python 应用的完整示例:
python
import os
import requests
import json
# 环境变量配置
LANGFLOW_SERVER_URL = os.environ.get("LANGFLOW_SERVER_URL", "http://localhost:7860")
FLOW_ID = os.environ.get("DASHBOARD_FLOW_ID", "your-flow-id-here")
API_KEY = os.environ.get("LANGFLOW_API_KEY", "")
def query_dashboard(natural_language_question: str) -> dict:
"""
通过自然语言查询数据仪表盘。
Args:
natural_language_question: 用户的自然语言问题
Returns:
包含 SQL 查询、结果数据和 Base64 图表的字典
"""
url = f"{LANGFLOW_SERVER_URL}/api/v1/run/{FLOW_ID}?stream=false"
headers = {
"Content-Type": "application/json",
"x-api-key": API_KEY,
}
payload = {
"input_value": natural_language_question,
"output_type": "chat",
"input_type": "chat",
}
response = requests.post(url, headers=headers, json=payload, timeout=120)
response.raise_for_status()
return response.json()
def render_chart(base64_image: str, output_path: str = None):
"""将 Base64 图像渲染为文件或显示"""
import base64
from PIL import Image
from io import BytesIO
image_data = base64.b64decode(base64_image)
image = Image.open(BytesIO(image_data))
if output_path:
image.save(output_path)
print(f"图表已保存至: {output_path}")
else:
image.show()
# ========== 使用示例 ==========
if __name__ == "__main__":
# 场景一:销售趋势分析
result = query_dashboard("展示本季度各产品线的收入趋势")
print(f"查询结果: {json.dumps(result, ensure_ascii=False, indent=2)[:500]}")
# 场景二:费用占比分析
result = query_dashboard("各部门的支出占比情况")
# 场景三:库存水平查询
result = query_dashboard("按仓库位置展示当前库存水平")5.3 JavaScript / 前端集成
javascript
/**
* 前端调用 Langflow 仪表盘工作流
*/
async function queryDashboard(question) {
const url = `${import.meta.env.VITE_LANGFLOW_URL}/api/v1/run/${import.meta.env.VITE_DASHBOARD_FLOW_ID}?stream=false`;
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-key': import.meta.env.VITE_LANGFLOW_API_KEY,
},
body: JSON.stringify({
input_value: question,
output_type: 'chat',
input_type: 'chat',
}),
});
if (!response.ok) {
throw new Error(`HTTP ${response.status}: ${await response.text()}`);
}
const data = await response.json();
return data;
}
/**
* 在页面中渲染返回的 Base64 图表
*/
function renderChart(base64Image, containerId) {
const container = document.getElementById(containerId);
const img = document.createElement('img');
img.src = `data:image/png;base64,${base64Image}`;
img.style.maxWidth = '100%';
img.style.borderRadius = '8px';
img.style.boxShadow = '0 2px 8px rgba(0,0,0,0.1)';
container.innerHTML = '';
container.appendChild(img);
}
// 使用示例
queryDashboard('展示本季度各产品线的收入趋势')
.then(data => {
// 从响应中提取 Base64 图表
const chartBase64 = extractChartFromResponse(data);
renderChart(chartBase64, 'dashboard-container');
})
.catch(err => console.error('查询失败:', err));5.4 curl 快速验证
bash
# 设置环境变量
export LANGFLOW_SERVER_URL="http://localhost:7860"
export FLOW_ID="your-flow-id"
export LANGFLOW_API_KEY="your-api-key"
# 运行工作流
curl --request POST \
--url "$LANGFLOW_SERVER_URL/api/v1/run/$FLOW_ID?stream=false" \
--header "Content-Type: application/json" \
--header "x-api-key: $LANGFLOW_API_KEY" \
--data '{
"input_value": "展示本季度各产品线的收入趋势",
"output_type": "chat",
"input_type": "chat"
}'
# 健康检查
curl -X GET "$LANGFLOW_SERVER_URL/health_check" -H "accept: application/json"
# 获取版本
curl -X GET "$LANGFLOW_SERVER_URL/api/v1/version" -H "accept: application/json"5.5 运行时参数覆盖(Tweaks)
Langflow 支持在 API 调用时动态覆盖组件参数,无需修改工作流本身:
python
payload = {
"input_value": "展示本季度收入趋势",
"output_type": "chat",
"input_type": "chat",
"tweaks": {
"SQLDatabase-xxxx": {
"database_url": "postgresql://user:pass@newhost:5432/prod_db"
},
"ChatOutput-xxxx": {
"should_store_message": True
}
}
}这个能力在生产环境中极为实用------同一个工作流可以连接不同的数据库实例,只需在调用时切换 database_url 即可。
六、自定义组件开发:扩展 Langflow 的能力边界
当内置组件无法满足需求时,Langflow 支持用 Python 编写自定义组件。这是该平台最强大的扩展能力之一。
6.1 自定义组件基本结构
每个自定义组件需要继承 langflow.custom.Component,并通过 inputs 和 outputs 定义接口契约:
python
from langflow.custom import Component
from langflow.io import StrInput, Output, DropdownInput
from langflow.schema import Data
import matplotlib.pyplot as plt
import base64
from io import BytesIO
class ChartGenerator(Component):
"""自定义图表生成组件:接收数据并输出 Base64 图表"""
display_name = "图表生成器"
description = "接收 JSON 数据,生成 Matplotlib 图表并返回 Base64 编码"
inputs = [
DropdownInput(
name="chart_type",
display_name="图表类型",
options=["折线图", "柱状图", "饼图", "散点图"],
value="折线图"
),
StrInput(
name="title",
display_name="图表标题",
value="数据可视化"
),
StrInput(
name="data_json",
display_name="数据 (JSON)",
info="传入 JSON 格式的数据",
multiline=True
)
]
outputs = [
Output(
display_name="Base64 图表",
name="chart_output",
method="generate_chart"
)
]
def generate_chart(self) -> Data:
import json
# 解析输入数据
data = json.loads(self.data_json)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots(figsize=(10, 6))
if self.chart_type == "折线图":
labels = [item.get('label', str(i)) for i, item in enumerate(data)]
values = [item.get('value', 0) for item in data]
ax.plot(labels, values, marker='o', linewidth=2, color='#2196F3')
elif self.chart_type == "柱状图":
labels = [item.get('label', str(i)) for i, item in enumerate(data)]
values = [item.get('value', 0) for item in data]
ax.bar(labels, values, color='#4CAF50')
elif self.chart_type == "饼图":
labels = [item.get('label', str(i)) for i, item in enumerate(data)]
values = [item.get('value', 0) for item in data]
ax.pie(values, labels=labels, autopct='%1.1f%%', startangle=90)
elif self.chart_type == "散点图":
x = [item.get('x', 0) for item in data]
y = [item.get('y', 0) for item in data]
ax.scatter(x, y, color='#FF9800', s=100, alpha=0.7)
ax.set_title(self.title, fontsize=14, fontweight='bold')
plt.tight_layout()
# 编码为 Base64
buffer = BytesIO()
plt.savefig(buffer, format='png', dpi=150, bbox_inches='tight')
buffer.seek(0)
chart_base64 = base64.b64encode(buffer.read()).decode('utf-8')
plt.close()
self.status = f"已生成 {self.chart_type},数据点: {len(data)}"
return Data(
data={"chart_base64": chart_base64, "chart_type": self.chart_type},
text=f"data:image/png;base64,{chart_base64[:100]}..."
)6.2 组件存放规范
自定义组件必须放在 LANGFLOW_COMPONENTS_PATH 环境变量指定的目录下,且必须是二级子目录结构:
/custom_components/
├── data_tools/
│ ├── chart_generator.py # 显示在 "Data Tools" 分类下
│ └── sql_optimizer.py
├── ai_agents/
│ └── viz_agent.py # 显示在 "AI Agents" 分类下
└── integrations/
└── webhook_trigger.py关键规则 :根目录下的
.py文件会被忽略。目录名会自动转换为 UI 中的分类名称(下划线转空格,首字母大写)。
6.3 输入控件类型速查
| 输入类型 | 适用场景 | 关键特性 |
|---|---|---|
StrInput |
文本输入 | 支持 multiline=True |
SecretStrInput |
API Key 等敏感信息 | 自动掩码 |
DropdownInput |
枚举选择 | 支持静态选项 |
BoolInput |
开关控制 | 复选框形式 |
IntInput / FloatInput |
数值调节 | 可设范围、步长 |
MessageTextInput |
消息文本 | 适合聊天场景 |
6.4 性能优化策略
对于处理大规模数据的组件,建议采用以下优化手段:
python
class DataProcessor(Component):
display_name = "数据处理器"
inputs = [StrInput(name="input_data", display_name="输入数据")]
outputs = [Output(method="process", display_name="处理结果")]
def process(self):
# 策略一:结果缓存
if not hasattr(self, '_cache'):
self._cache = self._heavy_processing(self.input_data)
return self._cache
def _heavy_processing(self, data):
# 策略二:懒加载重型资源
if not hasattr(self, '_model'):
from transformers import pipeline
self._model = pipeline("text-classification")
return self._model(data)
def batch_process(self, texts):
# 策略三:并行处理
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(self._single_analyze, texts))
return results七、典型应用场景
双阶段 Agent 架构适用于所有"自然语言 → 数据查询 → 可视化"的场景:
| 团队 | 示例问题 | 预期输出 |
|---|---|---|
| 销售团队 | "展示本季度各产品线的收入趋势" | 折线图 + 数据表 |
| 营销分析 | "对比上个月各渠道的转化率" | 柱状图 + 指标对比 |
| 运营管理 | "按仓库位置展示当前库存水平" | 条形图 + 地理分布 |
| 财务团队 | "各部门的支出占比情况" | 饼图 + 明细表 |
| 客户服务 | "展示工单量按优先级的变化趋势" | 时间序列图 + 统计 |
八、高级扩展方向
基础的双阶段架构可以通过以下方向进行深度扩展:
8.1 智能路由:多路径分发
在阶段一之前增加一个路由 Agent,根据问题类型将请求分发到不同的处理路径:
用户问题
│
▼
┌──────────────┐
│ 路由 Agent │
│ (意图分类) │
└──┬───┬───┬───┘
│ │ │
▼ ▼ ▼
SQL RAG API
路径 路径 路径- SQL 路径:结构化数据库查询(本文介绍的核心路径)
- RAG 路径:非结构化文档问答(PDF、Word 等文档检索)
- API 路径:外部 API 数据拉取与整合
8.2 Webhook 触发:自动化报告
使用 Langflow 的 Webhook 端点,可以实现定时自动报告:
python
# 通过定时任务触发 Webhook
import requests
import schedule
import time
def generate_daily_report():
"""每日早上 9 点自动生成销售日报"""
response = requests.post(
f"{LANGFLOW_URL}/api/v1/webhook/{FLOW_ID}",
json={
"trigger_type": "scheduled_daily_report",
"params": {
"date_range": "yesterday",
"report_type": "sales_summary"
}
},
headers={"x-api-key": API_KEY}
)
# 将结果发送到企业微信/钉钉/邮件...
schedule.every().day.at("09:00").do(generate_daily_report)
while True:
schedule.run_pending()
time.sleep(60)8.3 多数据源整合
通过添加 API Request 组件 和 DataFrame 操作组件,可以实现跨数据源整合:
python
# 自定义多数据源聚合组件
class MultiSourceAggregator(Component):
display_name = "多数据源聚合"
inputs = [
StrInput(name="sources", display_name="数据源列表 (JSON)"),
StrInput(name="merge_key", display_name="合并字段")
]
outputs = [Output(method="aggregate", display_name="聚合结果")]
def aggregate(self):
import json
import pandas as pd
sources = json.loads(self.sources)
dfs = []
for source in sources:
# 从不同来源获取数据
if source["type"] == "database":
df = pd.read_sql(source["query"], source["connection"])
elif source["type"] == "api":
df = pd.DataFrame(requests.get(source["url"]).json())
elif source["type"] == "csv":
df = pd.read_csv(source["path"])
dfs.append(df)
# 按指定字段合并
merged = dfs[0]
for df in dfs[1:]:
merged = merged.merge(df, on=self.merge_key, how="outer")
self.status = f"已聚合 {len(dfs)} 个数据源,共 {len(merged)} 行"
return Data(data=merged.to_dict('records'))九、部署实践
9.1 Docker 快速部署
yaml
# docker-compose.yml
version: "3.8"
services:
langflow:
image: langflowai/langflow:latest
ports:
- "7860:7860"
environment:
- LANGFLOW_DATABASE_URL=postgresql://langflow:langflow@postgres:5432/langflow
- LANGFLOW_COMPONENTS_PATH=/app/custom_components
- LANGFLOW_AUTO_SAVING=true
volumes:
- ./custom_components:/app/custom_components
- ./flows:/app/flows
depends_on:
- postgres
postgres:
image: postgres:16
environment:
- POSTGRES_USER=langflow
- POSTGRES_PASSWORD=langflow
- POSTGRES_DB=langflow
volumes:
- langflow_pgdata:/var/lib/postgresql/data
volumes:
langflow_pgdata:启动命令:
bash
# 启动服务
docker compose up -d
# 检查健康状态
curl http://localhost:7860/health_check
# 预期输出: {"status":"ok","chat":"ok","db":"ok"}9.2 生产环境注意事项
| 维度 | 建议 |
|---|---|
| 数据库安全 | SQL Agent 应使用只读账户,禁止 DDL/DML 操作 |
| API 鉴权 | 生产环境务必启用 x-api-key 认证 |
| 速率限制 | 通过 Nginx 或 API Gateway 设置请求频率限制 |
| 图表渲染 | 容器中需安装 matplotlib 及中文字体包 |
| 超时配置 | API 调用 timeout 建议设为 120s(可视化阶段耗时较长) |
| 可观测性 | 集成 LangSmith / LangFuse 追踪 Agent 运行状态 |
十、最佳实践总结
10.1 Prompt Engineering
- Schema 精简:不要把整个数据库的 Schema 都塞给 LLM,只传入相关表的 DDL
- Few-shot 示例:在 Prompt 中提供 2-3 个"问题 → SQL"的示例,显著提升生成质量
- 护栏设计:明确禁止 INSERT/UPDATE/DELETE 等危险操作
10.2 Agent 协作
- JSON Schema 约束:阶段间使用 Structured Output 确保数据格式一致
- 错误处理:在每个阶段增加异常捕获与重试逻辑
- 上下文传递:用户原始问题应传递到所有阶段,避免信息丢失
10.3 性能优化
- 模型选择:SQL 生成使用推理能力强的模型(如 GPT-4o / Claude 3.5),图表代码生成可使用更轻量的模型
- 缓存策略:相同问题的查询结果可缓存,避免重复计算
- 异步执行:长耗时的图表生成使用异步任务队列,避免阻塞 API 响应
10.4 安全加固
- SQL 注入防护:在 SQL Database Tool 上层增加 SQL 语句审计
- 数据脱敏:对于敏感字段(手机号、身份证等),在返回前进行脱敏处理
- 权限隔离:不同用户/角色连接不同的数据库账户,实现行级权限控制
结语
Langflow 的交互式数据仪表盘模板展示了一个重要的趋势:AI Agent 正在从"聊天工具"进化为"数据工程师"。通过双阶段 Agent 架构,我们将一个原本需要前后端团队协作数天的需求,压缩到了一次自然语言交互。
但这只是起点。结合智能路由、多数据源整合、Webhook 自动化触发等扩展能力,这套架构可以演变为企业级的自助式数据分析平台------每个业务人员都是自己的数据分析师,每个数据分析师都可以专注于更高价值的洞察工作。最后生成图表也可以在前端界面完成,生成可交互图表(echarts),这种方案用户体验更好,欢迎一起交流学习。