文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 创建Maven项目](#2.1 创建Maven项目)
- [2.2 准备单词数据文件](#2.2 准备单词数据文件)
- [2.3 添加项目依赖](#2.3 添加项目依赖)
- [2.4 添加日志属性文件](#2.4 添加日志属性文件)
- [2.5 在源程序目录里创建包](#2.5 在源程序目录里创建包)
- [2.6 创建`LineSpout`类](#2.6 创建
LineSpout类) - [2.7 创建`SplitLineBolt`类](#2.7 创建
SplitLineBolt类) - [2.8 创建`WordCountBolt`类](#2.8 创建
WordCountBolt类) - [2.9 创建`ReportBolt`类](#2.9 创建
ReportBolt类) - [2.10 创建`WordCountTopology`类](#2.10 创建
WordCountTopology类) - [2.11 运行程序,查看结果](#2.11 运行程序,查看结果)
- [3. 实战总结](#3. 实战总结)
- [4. 拓展练习](#4. 拓展练习)
-
- [4.1 拓展练习一:可靠性增强版(At-Least-Once 语义)](#4.1 拓展练习一:可靠性增强版(At-Least-Once 语义))
-
- [4.1.1 目标](#4.1.1 目标)
- [4.1.2 核心改动点](#4.1.2 核心改动点)
- [4.1.3 代码实现指引](#4.1.3 代码实现指引)
- [4.2 拓展练习二:事务性拓扑版(Exactly-Once 语义)](#4.2 拓展练习二:事务性拓扑版(Exactly-Once 语义))
-
- [4.2.1 目标](#4.2.1 目标)
- [4.2.2 核心概念](#4.2.2 核心概念)
- [4.2.3 代码实现指引](#4.2.3 代码实现指引)
- [4.3 总结与建议](#4.3 总结与建议)
1. 实战概述
- 本次实战基于Maven构建Storm 2.8.8版本的单词计数拓扑。通过创建LineSpout读取本地文件,经SplitLineBolt拆分单词,WordCountBolt统计频次,最终由ReportBolt打印结果。完整演示了Storm流式计算框架的拓扑构建、数据分组策略及本地模式运行流程。
- Maven仓库
Storm最新版本 -2.8.8
2. 实战步骤
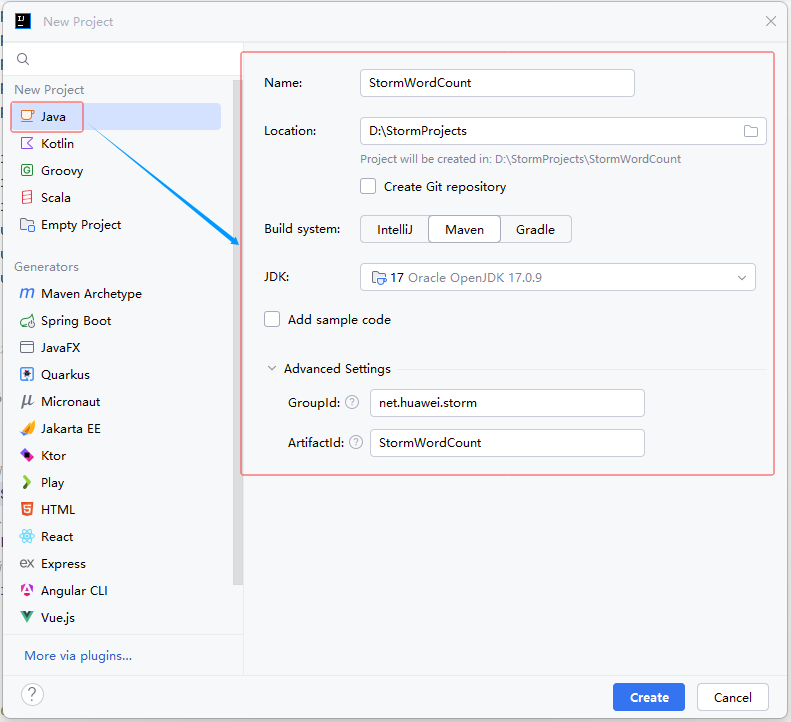
2.1 创建Maven项目
- 配置项目基本信息
- 单击【Create】按钮,生成项目基本骨架
2.2 准备单词数据文件
-
在项目根目录创建
words.txt文件 plain
plainhello world hello storm storm is fast and reliable hello the world of storm let us learn storm framework
2.3 添加项目依赖
- 在
pom.xml文件里添加Storm核心依赖
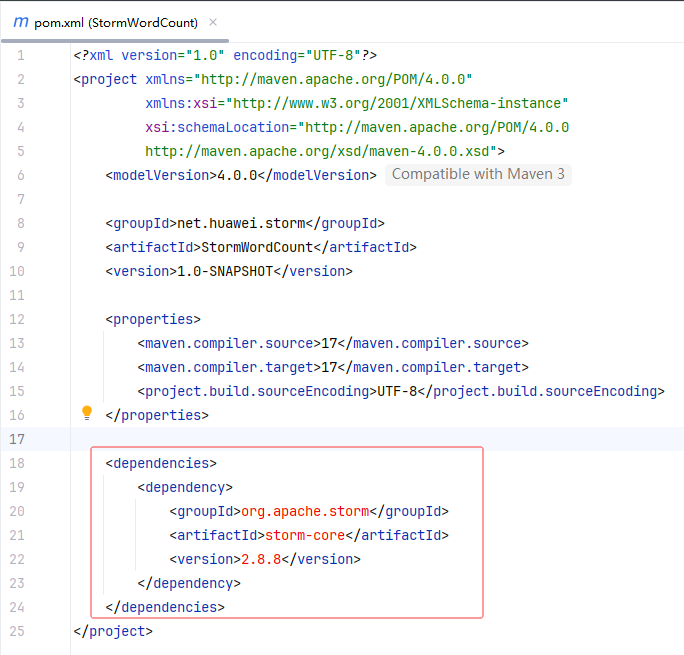
- 刷新项目依赖
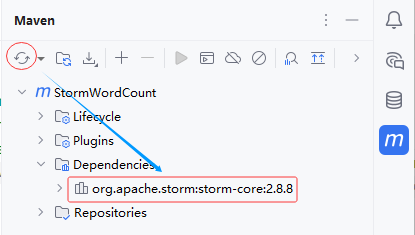
- 此时
pom.xml文件里的依赖不再报红
2.4 添加日志属性文件
-
在
resources里创建log4j2.properties文件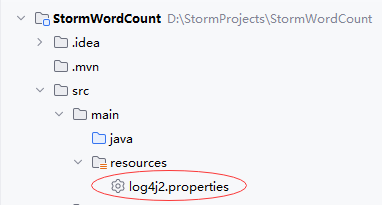 shell
shellrootLogger.level = ERROR rootLogger.appenderRef.stdout.ref = STDOUT appender.console.type = Console appender.console.name = STDOUT appender.console.layout.type = PatternLayout appender.console.layout.pattern = %d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n
2.5 在源程序目录里创建包
- 在
src/main/java里创建net.huawei.storm.wc包
2.6 创建LineSpout类
-
在
net.huawei.storm.wc包里创建LineSpout类 java
javapackage net.huawei.storm.wc; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * 功能:读取本地文件,逐行发送数据 * 作者:华卫 * 日期:2026年06月21日 */ public class LineSpout extends BaseRichSpout { // 用于向下游发送数据的收集器 private SpoutOutputCollector collector; // 存储从文件中读取的所有非空行 private List<String> lines; // 记录当前已发送到第几行(作为行列表的索引指针) private int index = 0; /** * Spout 初始化方法,在任务启动时调用一次 */ @Override public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) { // 初始化输出收集器,用于向下游 Bolt 发送数据元组 this.collector = collector; // 初始化行列表,用于存储从文件中读取的所有非空文本行 this.lines = new ArrayList<>(); // 读取 words.txt 文件,将所有非空行加载到内存中 try (BufferedReader br = new BufferedReader(new FileReader("words.txt"))) { // 声明字符串变量,用于暂存每次从文件中读取的一行文本内容 String nextLine; // 循环读取每一行文本,直到文件末尾(readLine 返回 null) while ((nextLine = br.readLine()) != null) { // 过滤掉空白行或仅包含空格的行 if (!nextLine.trim().isEmpty()) { // 将有效行添加到列表中,供后续发送 lines.add(nextLine); } } } catch (IOException e) { // 捕获 IO 异常并抛出运行时异常,终止 Spout 初始化 throw new RuntimeException("温馨提示:读取文件失败~", e); } } /** * 核心方法:不断被 Storm 调用,用于发射下一条数据 */ @Override public void nextTuple() { // 如果还有未发送的行,就发射出去 if (index < lines.size()) { String line = lines.get(index++); collector.emit(new Values(line)); } else { // 所有行已发送完毕,休眠避免 CPU 空转 try { Thread.sleep(100); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } } /** * 声明该 Spout 输出的字段名,下游 Bolt 通过此名称获取数据 */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("line")); } } -
代码说明 :该类是 Storm 拓扑的数据源组件(Spout),继承自
BaseRichSpout。open()方法在任务启动时读取words.txt文件,将所有非空行加载到内存列表中;nextTuple()方法被 Storm 循环调用,逐行发射数据给下游 Bolt,发送完毕后休眠避免 CPU 空转;declareOutputFields()声明输出字段名为line,供下游组件获取数据。
2.7 创建SplitLineBolt类
-
在
net.huawei.storm.wc包里创建SplitLineBolt类 java
javapackage net.huawei.storm.wc; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.Map; /** * 功能:接收一行文本,按空格拆分单词并逐个发送 * 作者:华卫 * 日期:2026年06月21日 */ public class SplitLineBolt extends BaseRichBolt { // 用于向下游发送处理后的数据 private OutputCollector collector; /** * Bolt 初始化方法,在任务启动时调用一次 */ @Override public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * 核心方法:每收到一条 Tuple 就调用一次 */ @Override public void execute(Tuple input) { // 从上游 Spout 获取一行文本 String line = input.getStringByField("line"); // 按一个或多个空白字符拆分单词 String[] words = line.split("\\s+"); // 逐个发射单词给下游 Bolt for (String word : words) { if (!word.isEmpty()) { collector.emit(new Values(word)); } } } /** * 声明该 Bolt 输出的字段名,下游 Bolt 通过此名称获取数据 */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } } -
代码说明 :该类是 Storm 拓扑的拆分组件(Bolt),继承自
BaseRichBolt。prepare()方法初始化输出收集器;execute()方法接收上游 Spout 发送的一行文本,通过正则\\s+按空白字符拆分为多个单词,并逐个发射给下游 Bolt;declareOutputFields()声明输出字段名为word,供下游组件获取拆分后的单词数据。
2.8 创建WordCountBolt类
-
在
net.huawei.storm.wc包里创建WordCountBolt类 java
javapackage net.huawei.storm.wc; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.HashMap; import java.util.Map; /** * 功能:统计每个单词出现的次数 * 作者:华卫 * 日期:2026年06月21日 */ public class WordCountBolt extends BaseRichBolt { // 用于向下游发送处理后的数据 private OutputCollector collector; // 用于存储每个单词的累计计数 private Map<String, Integer> counts = new HashMap<>(); /** * Bolt 初始化方法,在任务启动时调用一次 */ @Override public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * 核心方法:每收到一条 Tuple 就调用一次 */ @Override public void execute(Tuple input) { // 从上游 Bolt 获取单词 String word = input.getStringByField("word"); // 获取当前单词的已有计数(首次为 null) Integer count = counts.get(word); if (count == null) { count = 0; } // 计数加 1 并更新到 Map 中 count++; counts.put(word, count); // 将最新的统计结果发送给下游 Bolt collector.emit(new Values(word, count)); } /** * 声明该 Bolt 输出的字段名:单词和对应的计数 */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "count")); } } -
代码说明 :该类是 Storm 拓扑的统计组件(Bolt),继承自
BaseRichBolt。prepare()方法初始化输出收集器;execute()方法接收上游发送的单词,使用HashMap累计每个单词的出现次数,并将最新的统计结果(单词、计数)发射给下游;declareOutputFields()声明输出字段名为word和count,供下游组件获取统计结果。
2.9 创建ReportBolt类
-
在
net.huawei.storm.wc包里创建ReportBolt类 java
javapackage net.huawei.storm.wc; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import java.util.*; /** * 功能:打印最终结果到控制台 * 作者:华卫 * 日期:2026年06月21日 */ public class ReportBolt extends BaseRichBolt { // 内存哈希表:存储每个单词及其对应的最新计数值 private HashMap<String, Integer> counts; /** * 初始化方法:在 Bolt 启动时调用一次 */ @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { // 初始化空的 HashMap,准备接收并缓存统计数据 this.counts = new HashMap<String, Integer>(); } /** * 核心处理方法:每接收到一条 Tuple 数据流都会触发 */ @Override public void execute(Tuple tuple) { // 从输入元组中提取"word"字段 String word = tuple.getStringByField("word"); // 从输入元组中提取"count"字段(注意类型需与上游发送的 Integer 一致) Integer count = tuple.getIntegerByField("count"); // 将最新的计数结果存入本地 Map(覆盖旧值) counts.put(word, count); // 实时打印当前收到的更新数据 System.out.println("单词数量发生了变化:(" + word + "," + count + ")"); } /** * 声明输出字段:定义该 Bolt 向外发送的数据结构 */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // 声明输出包含 "word" 和 "count" 两个字段 declarer.declare(new Fields("word", "count")); } /** * 清理方法:在拓扑关闭或 Bolt 销毁前调用一次 * 通常用于输出最终的汇总统计结果 */ @Override public void cleanup() { System.out.println("====词频统计结果===="); // 提取所有单词 Key 到 List 中 List<String> keys = new ArrayList<String>(); keys.addAll(this.counts.keySet()); // 对单词列表进行字典序排序 Collections.sort(keys); // 遍历排序后的 Key,按顺序打印最终统计结果 for (String key : keys) { System.out.println("(" + key + "," + this.counts.get(key) + ")"); } System.out.println("=================="); } } -
代码说明 :该代码定义了 Storm 拓扑中的终端组件
ReportBolt,继承自BaseRichBolt。其核心功能是在本地内存中维护一个HashMap,实时接收并更新单词计数数据。在拓扑运行期间,它会打印数据变化日志;当任务结束触发cleanup()方法时,会对统计结果按字典序排序并输出最终汇总报表。
2.10 创建WordCountTopology类
-
在
net.huawei.storm.wc包里创建WordCountTopology类 java
javapackage net.huawei.storm.wc; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; /** * 功能:组装拓扑并提交运行 * 作者:华卫 * 日期:2026年06月21日 */ public class WordCountTopology { public static void main(String[] args) throws Exception { // 创建拓扑构建器 TopologyBuilder builder = new TopologyBuilder(); // 设置 Spout:负责读取文件并逐行发射数据,并行度为 1 builder.setSpout("spout", new LineSpout(), 1); // 设置 SplitBolt:负责将每行文本拆分为单词,并行度为 2 // shuffleGrouping:随机分发,确保负载均衡 builder.setBolt("split-bolt", new SplitLineBolt(), 2) .shuffleGrouping("spout"); // 设置 CountBolt:负责对单词进行计数,并行度为 2 // fieldsGrouping:按单词字段分组,确保相同单词始终发送到同一个任务 builder.setBolt("count-bolt", new WordCountBolt(), 2) .fieldsGrouping("split-bolt", new Fields("word")); // 设置 ReportBolt:负责打印最终统计结果,并行度为 1 // globalGrouping:将所有数据发送到同一个任务(全局汇总) builder.setBolt("report-bolt", new ReportBolt(), 1) .globalGrouping("count-bolt"); // 创建拓扑配置对象 Config config = new Config(); // 判断运行模式:有参数为集群模式,无参数为本地模式 if (args != null && args.length > 0) { // 集群模式:设置工作进程数为 3,并提交到 Storm 集群 config.setNumWorkers(3); StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.createTopology()); } else { // 本地模式:在本地模拟运行拓扑 System.out.println("--- Starting Local Mode ---"); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("word-count-topology", config, builder.createTopology()); // 运行 60 秒后关闭集群 Thread.sleep(60000); cluster.shutdown(); System.out.println("--- Local Mode Shutdown ---"); } } } -
代码说明 :该类是 Storm 单词计数拓扑的主入口。通过
TopologyBuilder依次组装四个组件:LineSpout读取文件逐行发射,SplitLineBolt拆分单词,WordCountBolt统计计数,ReportBolt打印结果。各组件间分别采用随机分组、字段分组和全局分组策略。最后根据是否有命令行参数,自动选择本地模拟运行或提交到 Storm 集群执行。
2.11 运行程序,查看结果
- 启动
WordCountTopology类
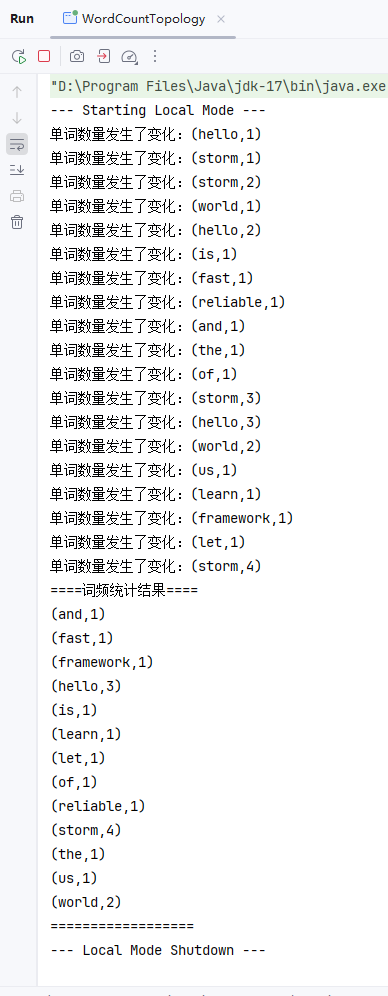
- 结果说明 :截图展示了 Storm 单词计数拓扑在本地模式下的运行结果。程序启动后,控制台首先实时打印了数据流中每个单词计数的更新状态(如
storm从 1 累加至 4)。随后,在任务结束时触发了清理逻辑,输出了按字典序排序的最终词频统计汇总报表,验证了流式计算与结果聚合功能的正确性。
3. 实战总结
- 本次实战成功实现了基于Storm的单词计数拓扑,完整构建了从数据源读取、单词拆分、频次统计到结果打印的流式处理流程。通过LineSpout、SplitLineBolt、WordCountBolt和ReportBolt四个组件的协同工作,深入理解了Storm拓扑的组装机制与数据流转逻辑。实战中重点掌握了Spout的数据发射、Bolt的业务处理、字段分组策略及本地集群的模拟运行,为后续复杂流式计算应用开发奠定了坚实基础。
4. 拓展练习
4.1 拓展练习一:可靠性增强版(At-Least-Once 语义)
4.1.1 目标
- 解决当前版本中如果 Bolt 处理失败会导致数据丢失的问题,利用 Storm 的 Ack/Fail 机制实现数据不丢失。
4.1.2 核心改动点
- LineSpout :需要缓存发送的 Tuple,重写
ack()和fail()方法。如果收到fail,需要重发该 Tuple。 - Bolts :在
execute()方法中,处理成功后调用collector.ack(tuple),捕获异常后调用collector.fail(tuple)。 - Tuple 锚定 :发射新 Tuple 时,必须传入父 Tuple(
collector.emit(input, ...)),建立 Tuple 树。
4.1.3 代码实现指引
-
LineSpout 修改
* 添加成员变量:
Map<Long, List<Object>> pending = new HashMap<>()用于缓存待确认的消息。* 在
nextTuple()中,使用this.collector.emit(new Values(line), msgId)发送,并将msgId作为 Key 存入pending。* 重写
ack(Object msgId):从pending中移除该 ID 的记录。* 重写
fail(Object msgId):关键点 ,从pending中取出该 ID 对应的数据,重新发射(重试)。 -
SplitBolt & CountBolt 修改
- 在
execute(Tuple tuple)中,使用 try-catch 包裹逻辑。 - 成功时:
collector.ack(tuple)。 - 失败时:
collector.fail(tuple)。
- 在
4.2 拓展练习二:事务性拓扑版(Exactly-Once 语义)
4.2.1 目标
- 解决重试机制可能导致的"重复计算"问题(例如单词计数因重试而变多),实现精确的一次处理。
4.2.2 核心概念
- Transaction ID (txid):Storm 为每一批数据分配一个全局唯一的、递增的 ID。
- 批次处理:数据按批次(Batch)处理,而不是单条。
- 强顺序性:保证 txid=1 的批次提交后,txid=2 的批次才能提交。
4.2.3 代码实现指引
-
创建事务 Spout
- 继承
BaseTransactionalSpout<TransactionMetadata>。 - 需要实现
Coordinator:负责切分批次,生成TransactionAttempt(包含 txid 和 attempt id)。 - 需要实现
Emitter:负责根据 txid 发射数据。注意:如果 txid 已经处理过,再次发射时必须发射相同的数据(幂等性)。
- 继承
-
创建 Batch Bolt
- 继承
BaseBatchBolt。 prepare():初始化批次状态。execute():累加当前批次内的单词计数(不要立即更新全局状态)。finishBatch():关键点,当 Storm 确认该批次处理成功后,将累加的结果更新到数据库或全局计数器中。
- 继承
-
状态存储
- 在
ReportBolt或数据库中维护Map<Word, Value>。 - 在更新前检查当前 txid 是否大于已存储的
lastCommittedTxid,如果是,则更新数据并写入lastCommittedTxid。
- 在
4.3 总结与建议
-
这两个练习展示了 Storm 词频统计从"可靠"到"精确"的进阶。练习一 利用 Ack/Fail 机制实现 At-Least-Once 语义,确保数据不丢失但允许重复处理,适用于日志采集等场景;练习二 引入事务 ID 与状态管理实现 Exactly-Once 语义,通过去重保证结果绝对精准,适合金融交易等核心业务。两者在代码复杂度与适用性上形成了鲜明对比。
特性 练习一:可靠性版 练习二:事务版 数据丢失 不会丢失 不会丢失 重复处理 可能发生(At-Least-Once) 通过事务ID去重(Exactly-Once) 代码复杂度 中等(需维护重试逻辑) 高(需维护状态和批次) 适用场景 日志采集、非核心指标 金融交易、核心统计