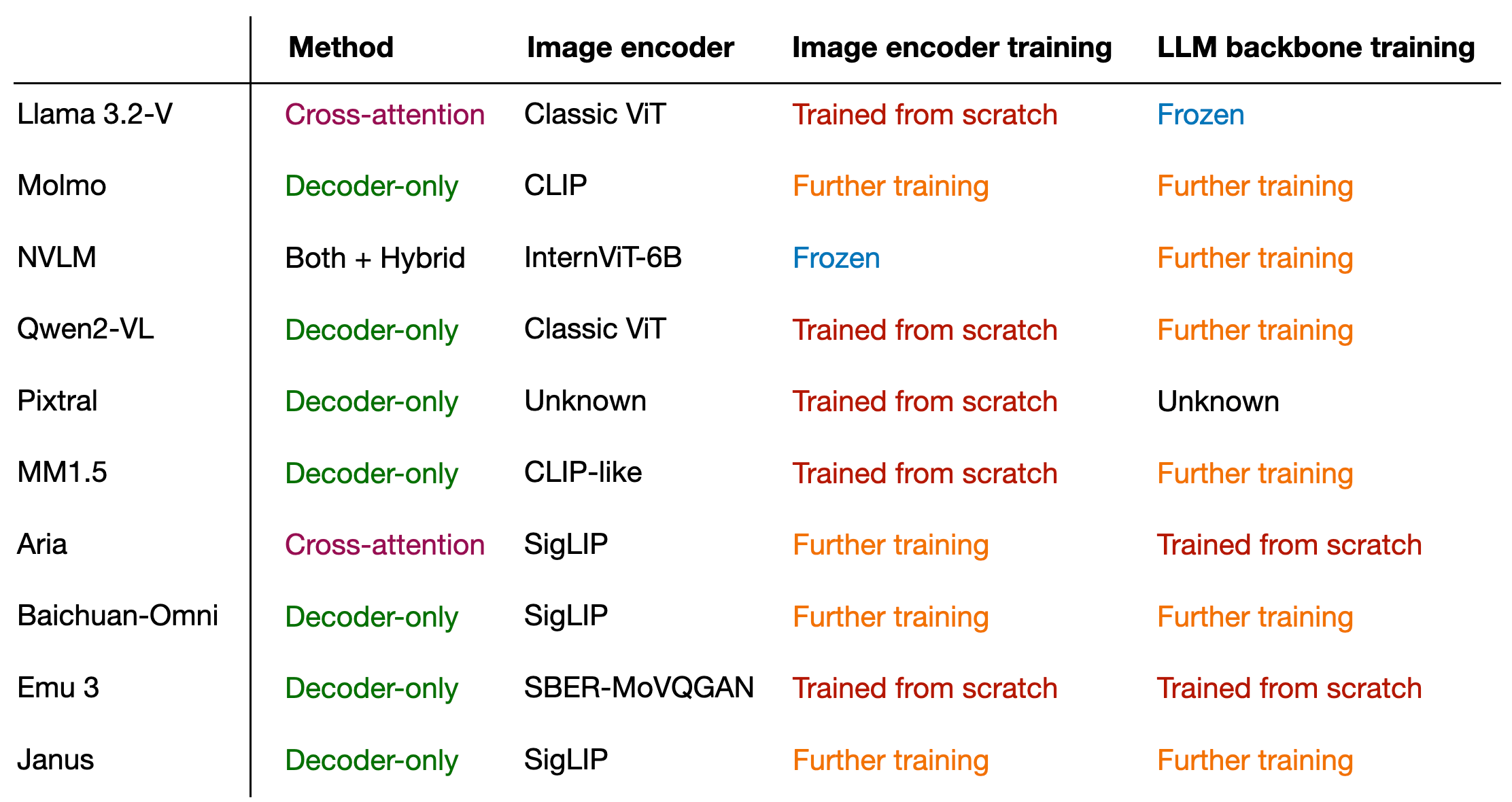
文章目录
- 一、多模态大语言模型的使用场景
- 二、构建多模态大语言模型的常见方法
-
- (一)方法A:统一嵌入解码器架构
-
- [1. 图像编码器](#1. 图像编码器)
- [2. 线性投影模块的作用](#2. 线性投影模块的作用)
- [3. 图像与文本分词](#3. 图像与文本分词)
- (二)方法B:跨模态注意力架构
-
- [1. 交叉注意力机制](#1. 交叉注意力机制)
- 三、统一解码器和交叉注意力模型训练
- 四、近期多模态模型与方法
-
- [(一)Llama 3 模型群](#(一)Llama 3 模型群)
-
- [1. 模型架构](#1. 模型架构)
- [2. 模型训练](#2. 模型训练)
- [(二)Molmo 与 PixMo](#(二)Molmo 与 PixMo)
-
- [1. 模型架构](#1. 模型架构)
- [2. 模型训练](#2. 模型训练)
- (三)NVLM
-
- [1. 模型架构](#1. 模型架构)
- [2. 模型训练](#2. 模型训练)
- (四)Qwen2-VL
-
- [1. 模型架构](#1. 模型架构)
- [2. 模型训练](#2. 模型训练)
- [(五)Pixtral 12B](#(五)Pixtral 12B)
- (六)MM1.5
- (七)Aria
- (八)Baichuan-Omni
- (九)Emu3
- (十)Janus
- 五、总结
前言:参考自Understanding Multimodal LLMs。上述文章聚焦于对多模态大模型的理解,讨论了多模态大语言模型的使用场景和常见的两种构建方式,并介绍了在模型训练中对上述组成部分的处理,最后回顾了近期关于多模态大语言模型的文献,主要关注最新的多模态大预言模型的发展。
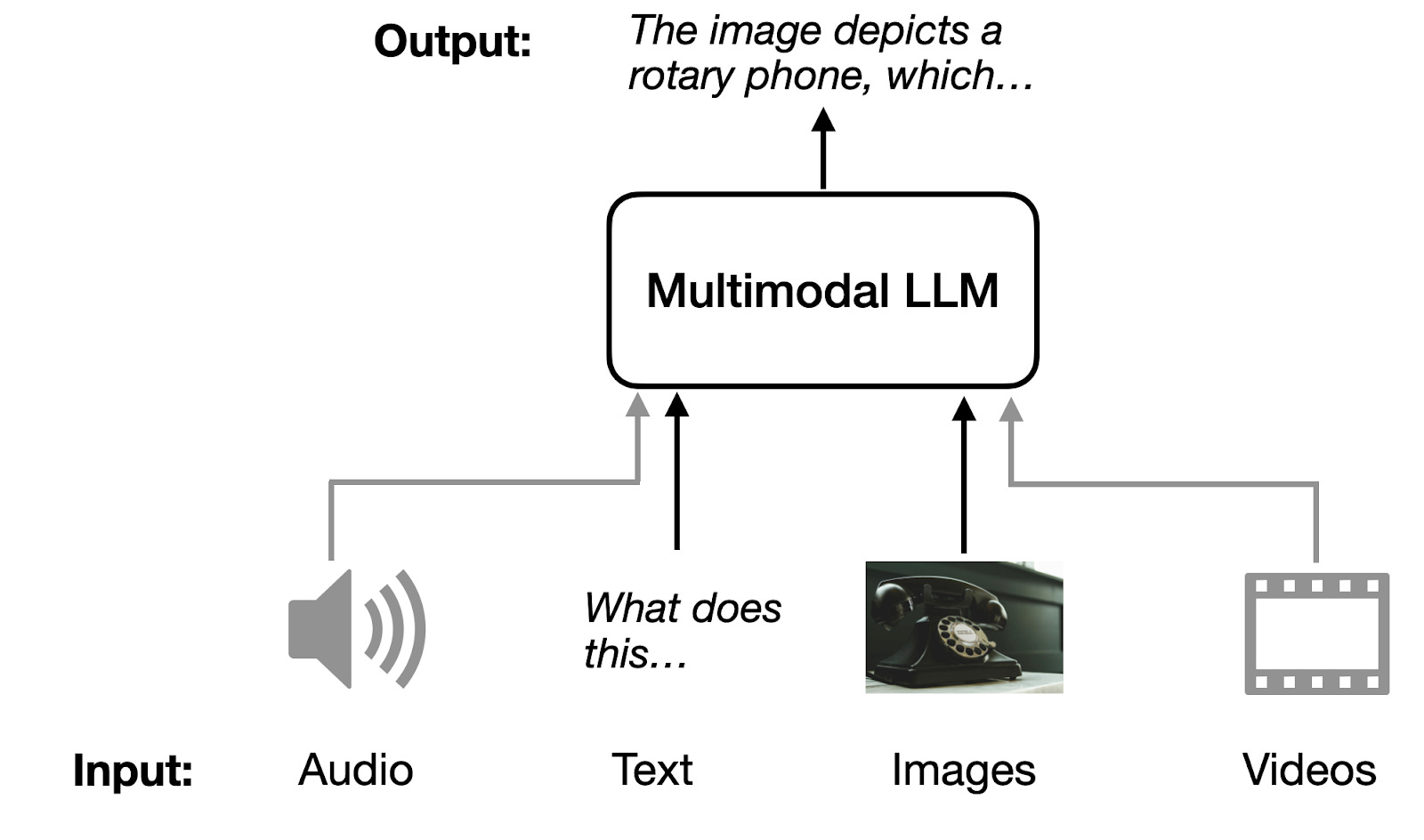
这是一个多模态LLM的示意图,它可以接受不同的输入模态(音频、文本、图像和视频),并返回文本作为输出模态。
一、多模态大语言模型的使用场景
多模态LLM是能够处理多种输入的大型语言模型,每种"模态"指代特定类型的数据------如文本(如传统LLMs)、声音、图像、视频等。这里主要关注图像模态与文本输入。
多模态大语言模型一个经典且直观的应用是图像描述:提供输入图像,然后由模型生成图像描述。

二、构建多模态大语言模型的常见方法
构建构建多模态大型语言模型有两种主要方法:
- 方法A:统一嵌入解码器架构方法: 采用单一解码器模型,类似于未修改的大语言模型架构,如GPT-2或Llama 3.2。图像被转换为与原始文本符号相同的嵌入大小的token,使大型语言模型在连接后能够同时处理文本和图像输入token。
- 方法B:跨模态注意力架构方法: 采用交叉注意力机制,将图像和文本嵌入直接集成在注意力层内
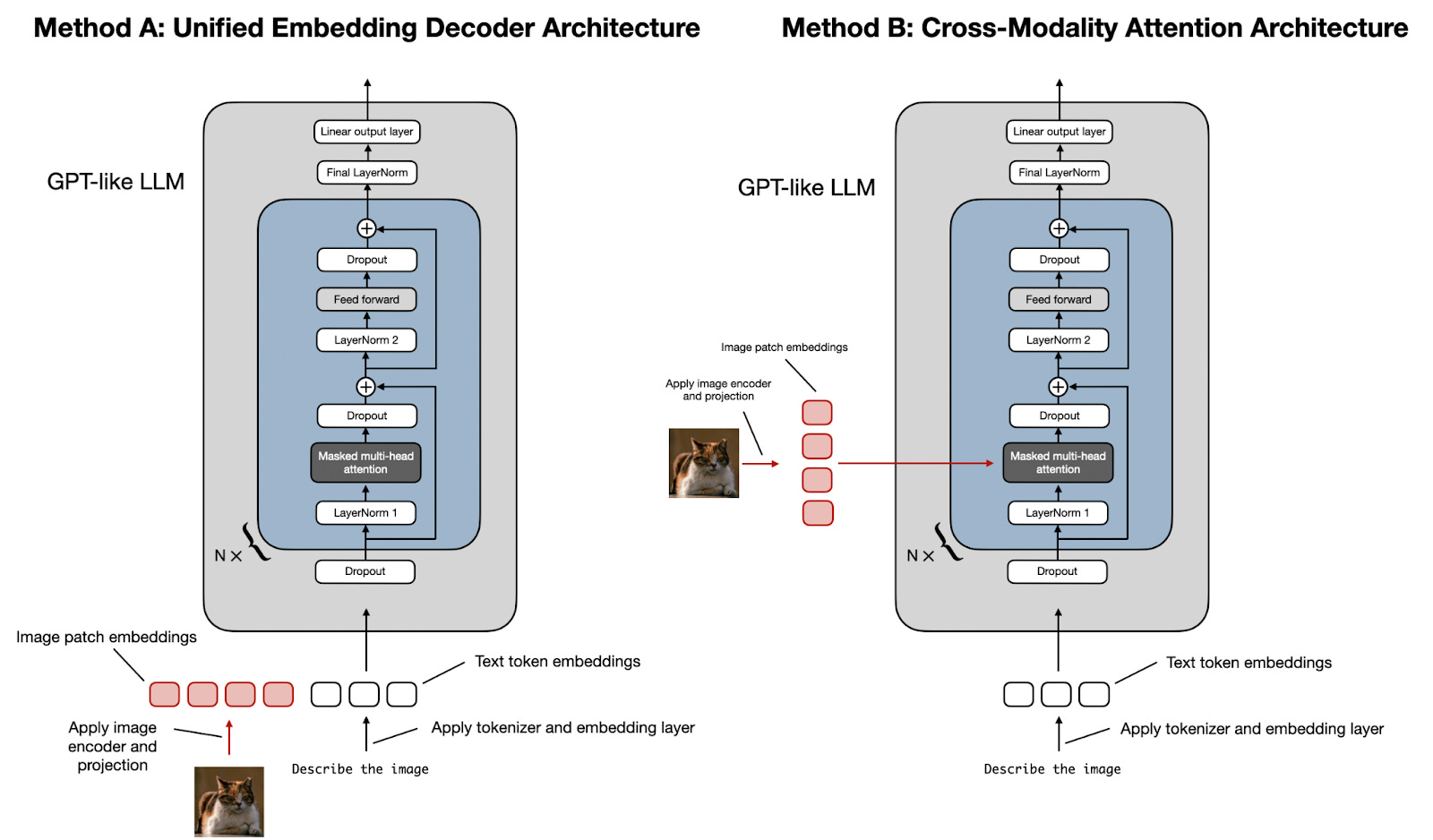
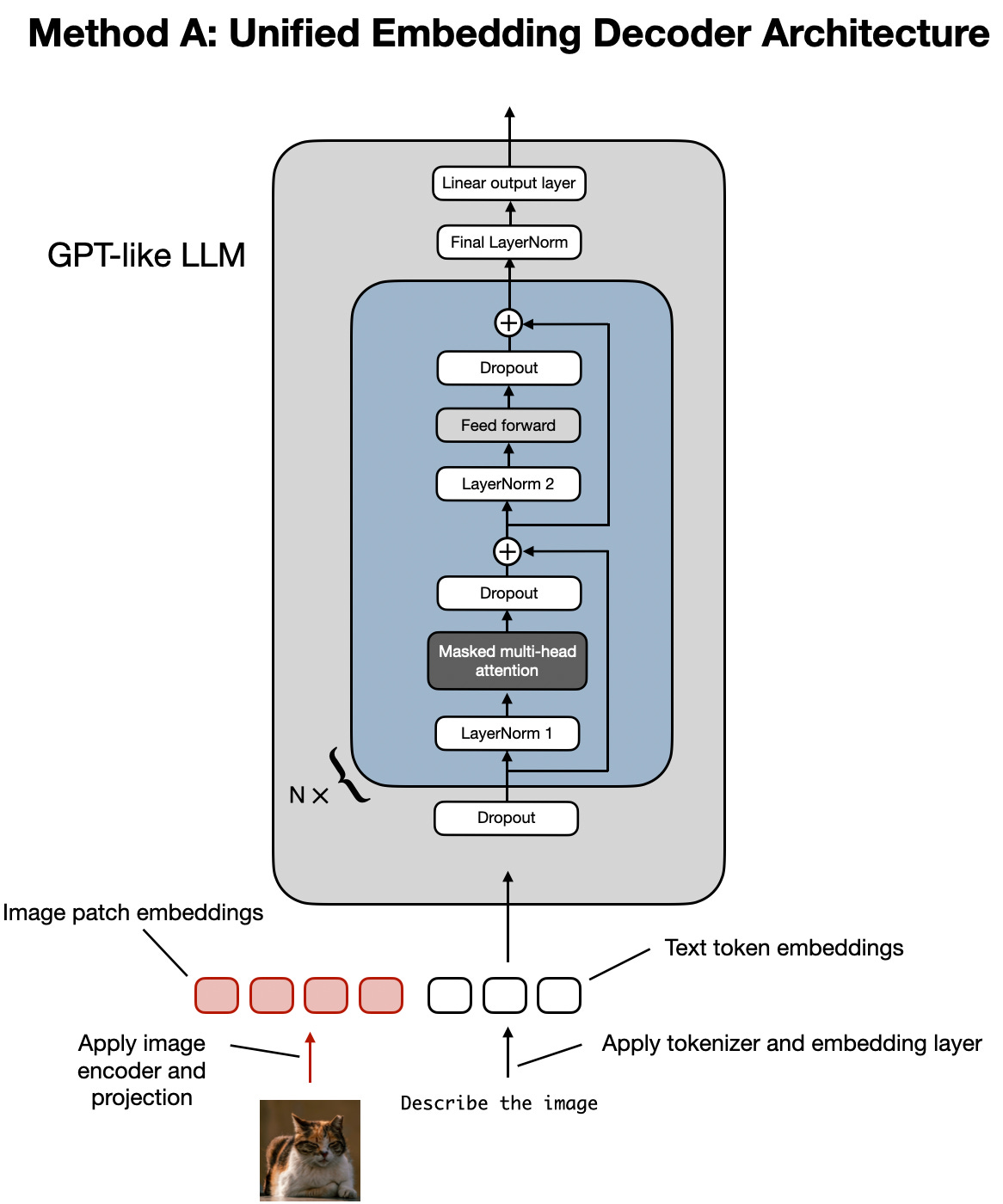
(一)方法A:统一嵌入解码器架构
下图是统一嵌入解码器架构的示意图,这是一种未经修改的解码式大型语言模型(类似GPT-2、Phi-3、Gemma或Llama 3.2),接收由图像token和文本token嵌入组成的输入。
1. 图像编码器
对于典型的纯文本LLM处理文本,文本输入通常会被标记化(例如使用字节对编码),然后通过嵌入层,如下图所示。
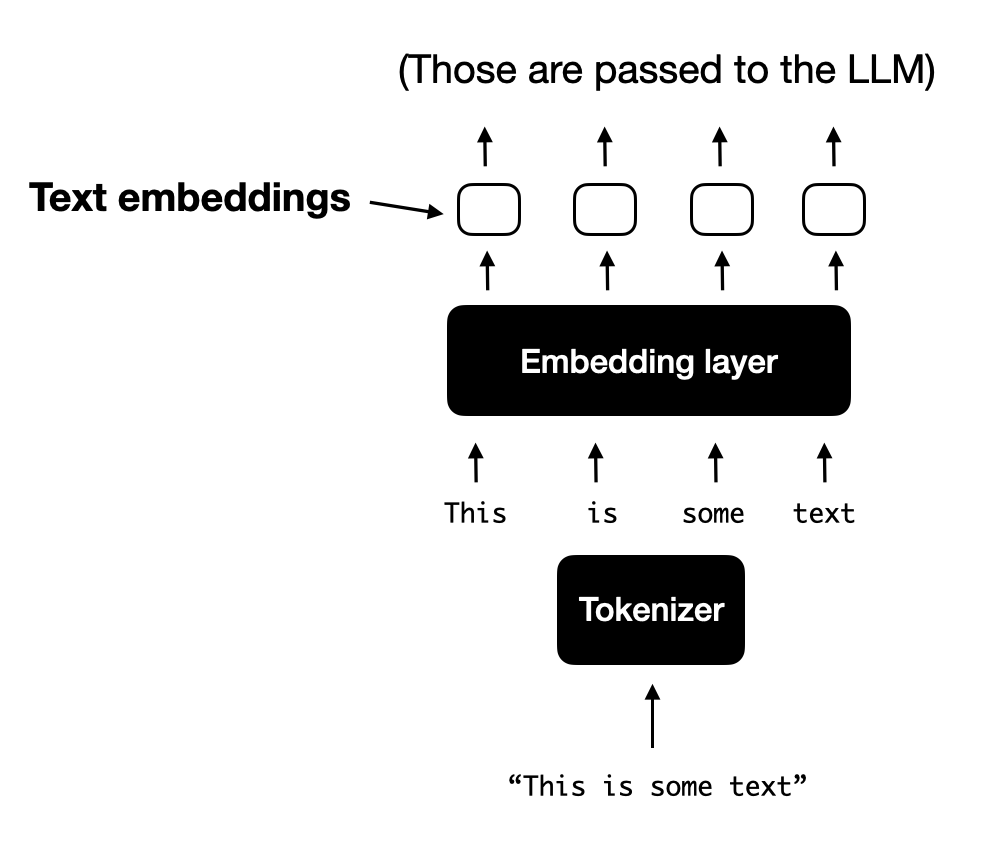
类似于文本的分词和嵌入,图像嵌入是通过图像编码模块生成的,如下图所示:
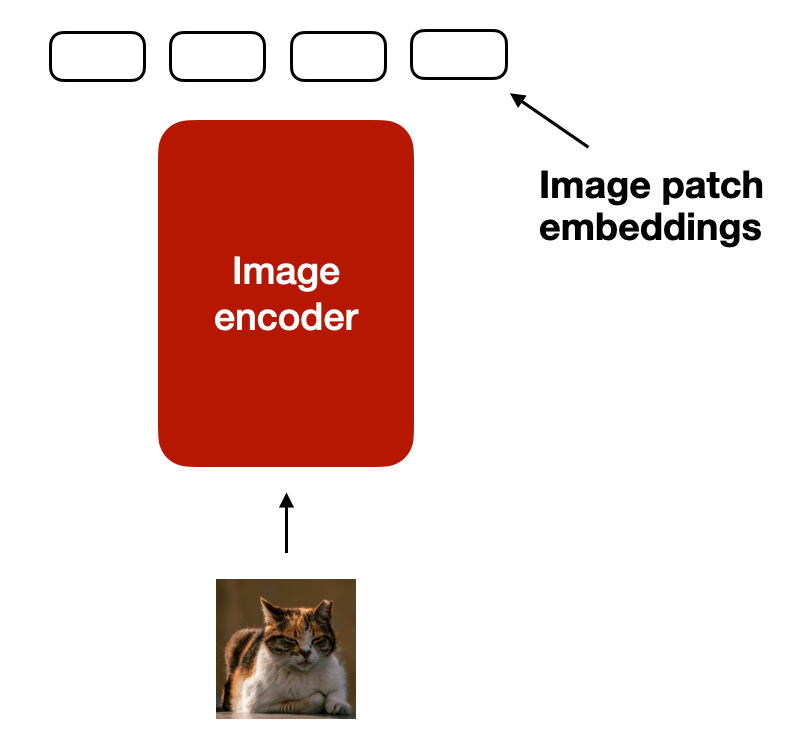
对于图像编码器内部:首先将图像分割成更小的部分(类似文本处理的分词),这些部分(patch)随后通过预训练的vision transformer(ViT)进行编码。
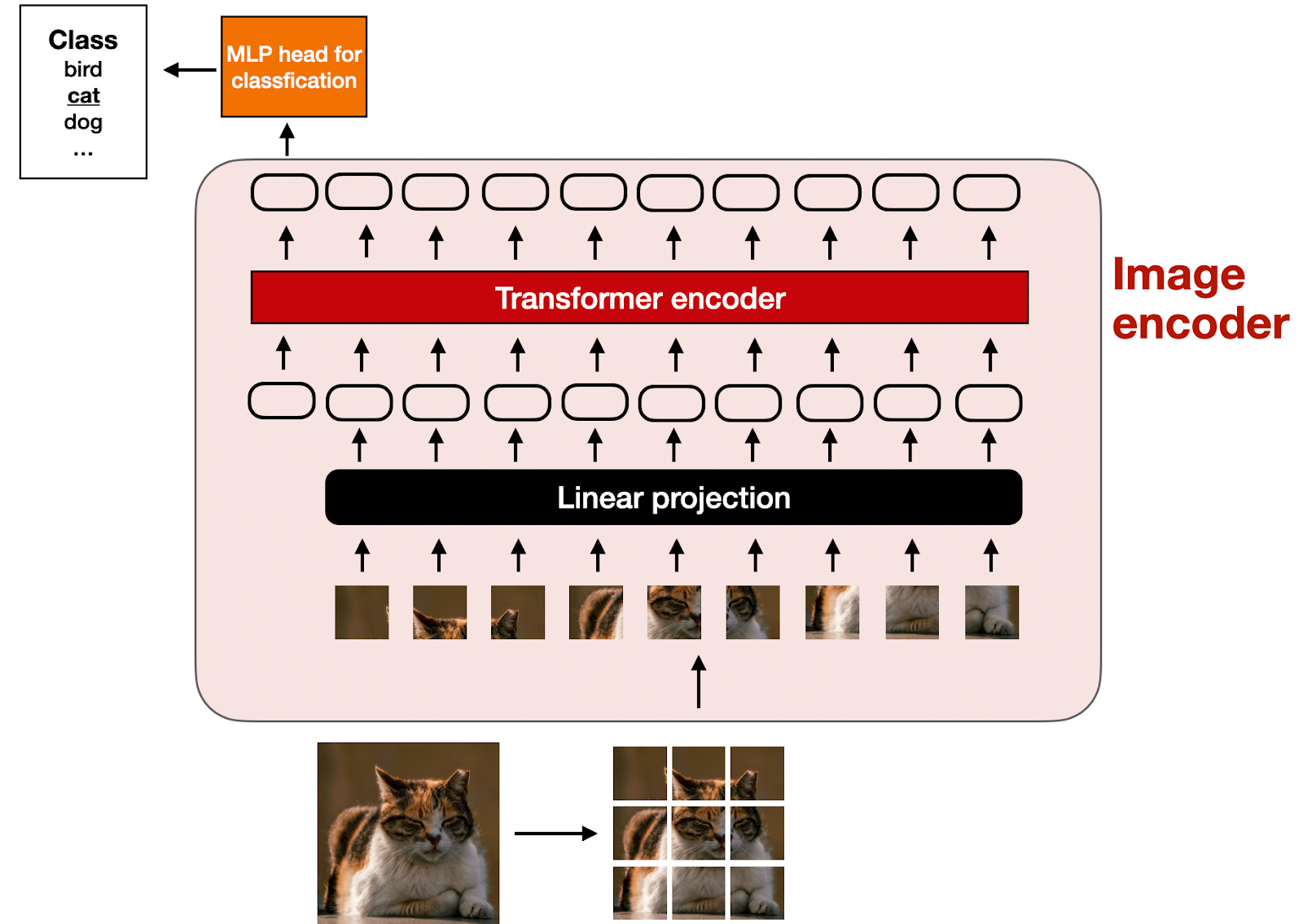
这是经典视觉变换器(ViT)配置的示意图,类似于《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 》(2020)中提出的模型。由于ViT常用于分类任务,这张图里包含了分类头,但是在多模态大模型中,只需要图像编码器部分。
2. 线性投影模块的作用
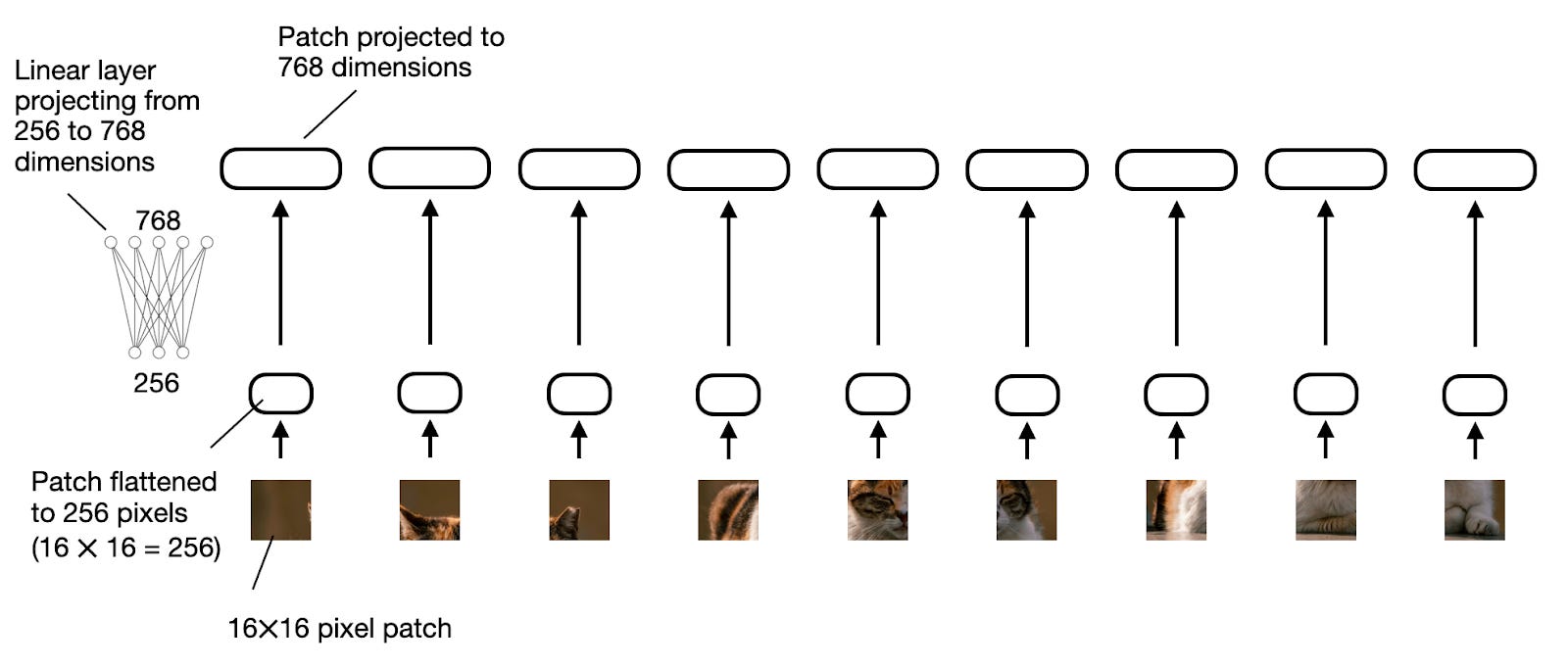
前图所示的"线性投影"由单一线性层(即全连接层)组成。该层的目的是将图像patch(扁平成矢量)投影为与Transformer编码器兼容的嵌入尺寸。这种线性投影如下图所示。图像patch被扁平化为256维矢量后,再向上投影为768维矢量。
3. 图像与文本分词
下图为图像分词化与嵌入和文本分词化与嵌入的对比:
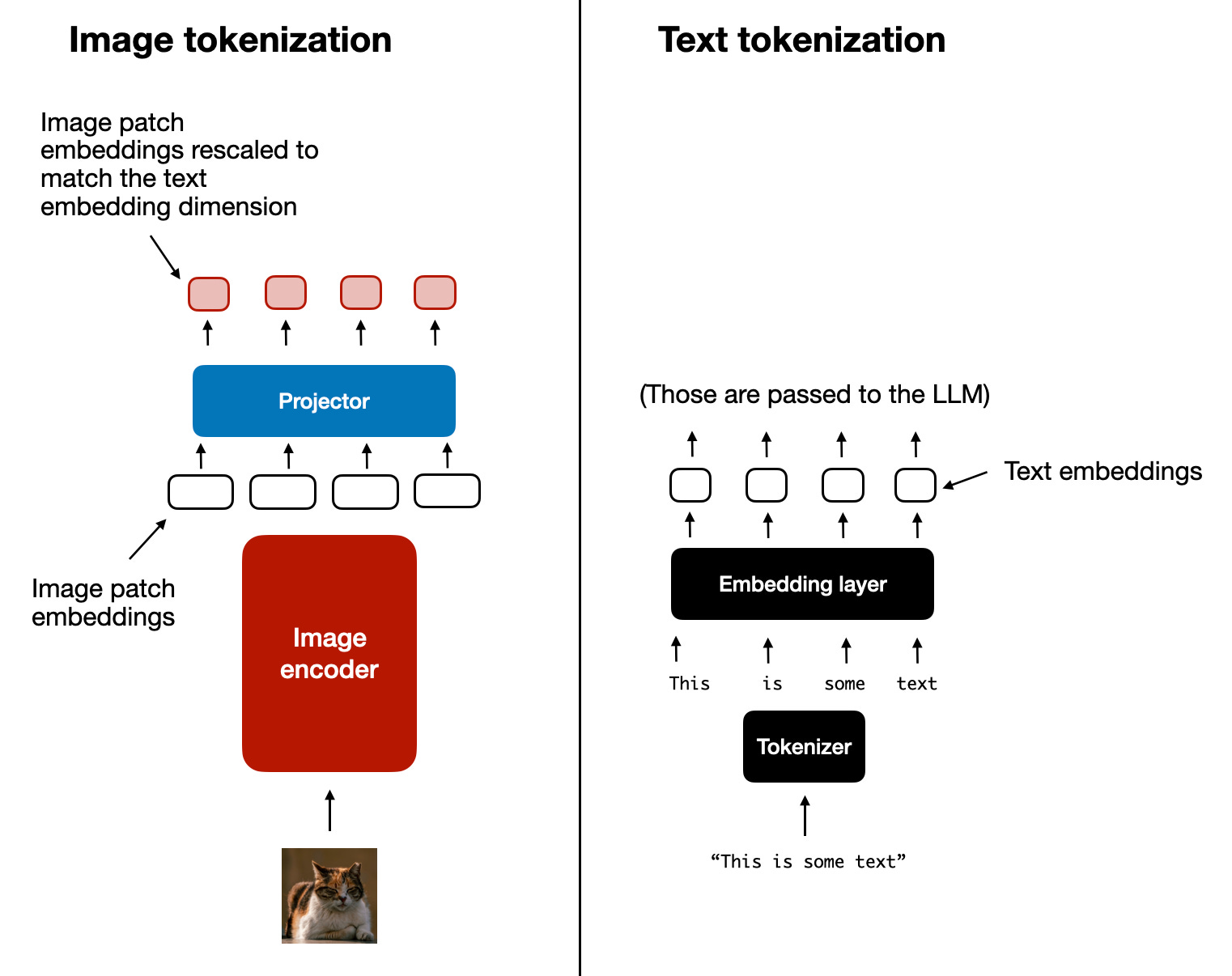
图中左边部分图像处理的Projector其实就是另一个投影线性层,主要用于将图像编码器的输出投影到与嵌入文本token的尺寸相匹配的维度中。这里的Porjector有时候也会被称为adapter, adaptor, 或者 connector。
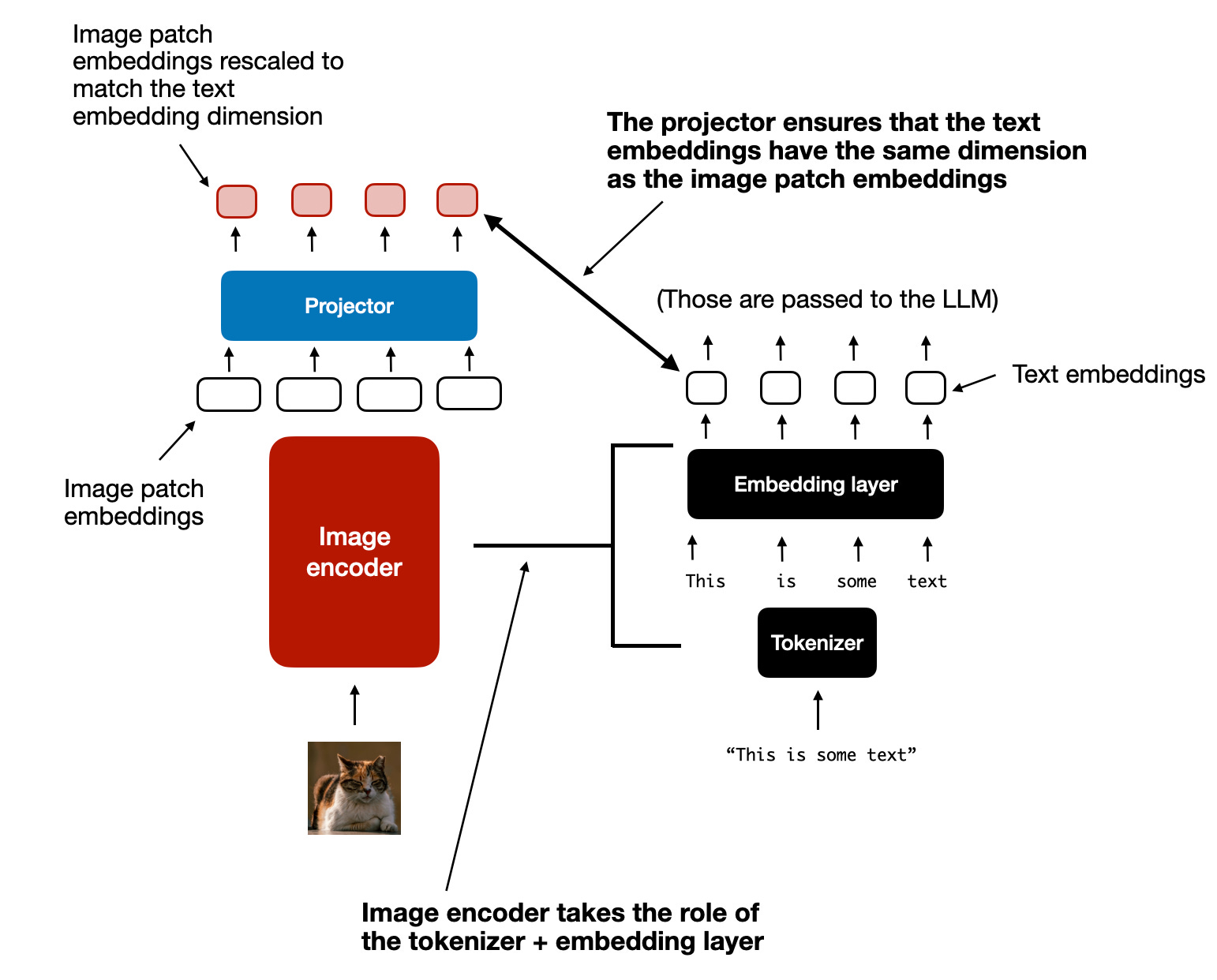
在将图像补丁token投影到与文本token嵌入相同的维度后,就可以简单地将它们作为标准大型语言模型的输入串接。
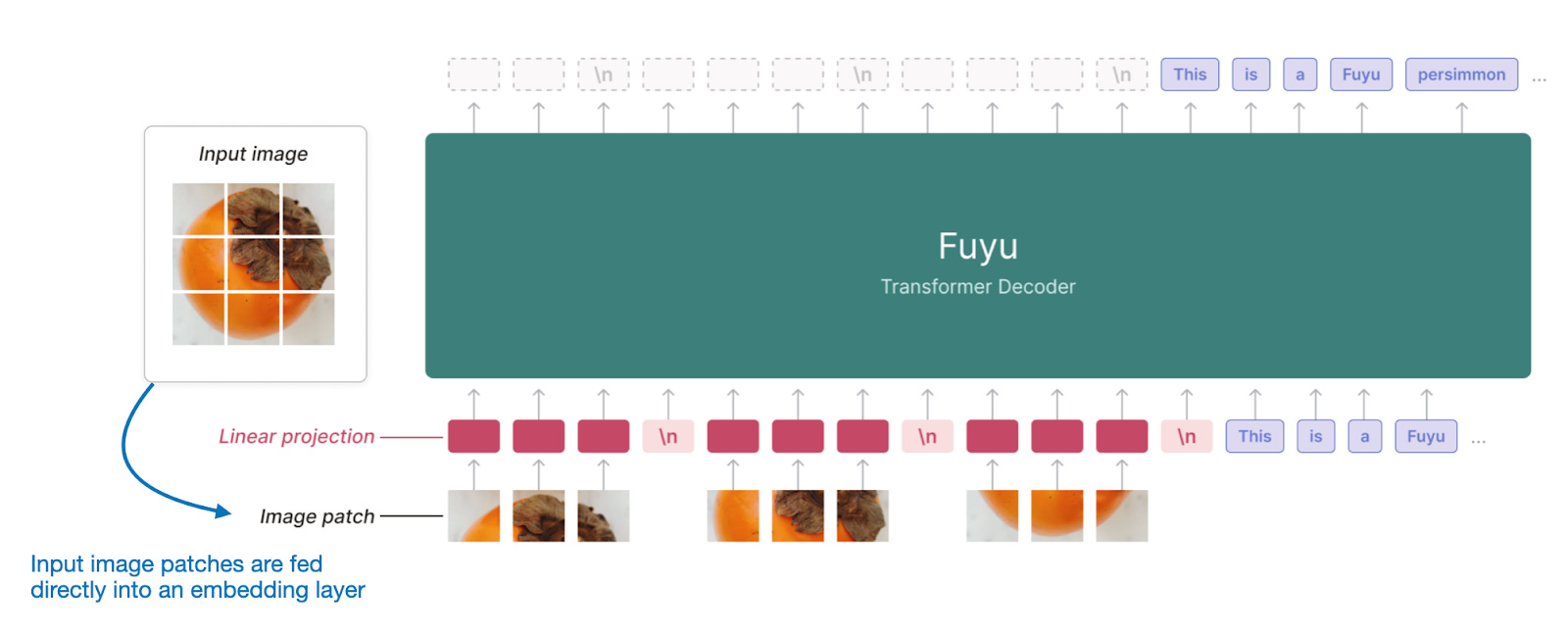
Fuyu多模态大模型直接在图像patch上运行,将输入patch传递到线性投影(或嵌入层)中,以学习自身的图像patch嵌入,而不需要像其他模型和方法那样依赖额外的预训练图像编码器。这大大简化了架构和训练设置。
Fuyu多模态LLM的注释图,直接在图像补丁上运行,无需图像编码器。(注释图来自 https://www.adept.ai/blog/fuyu-8b)
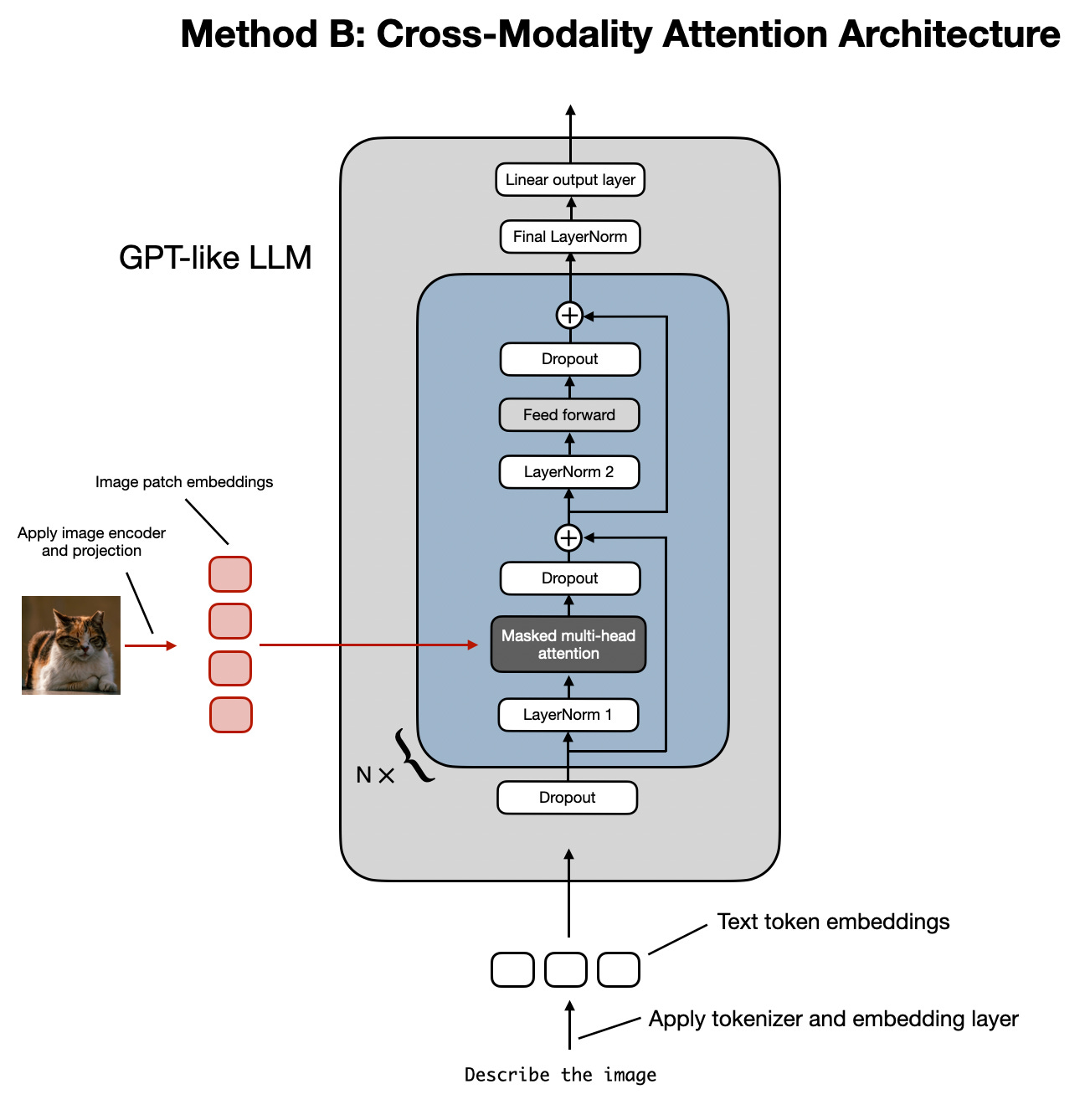
(二)方法B:跨模态注意力架构
跨模态注意力架构的方法使用之前讨论的相同图像编码器配置,但是不是将patch编码为LLM的输入,而是通过交叉注意力机制连接多头注意力层的输入patch。
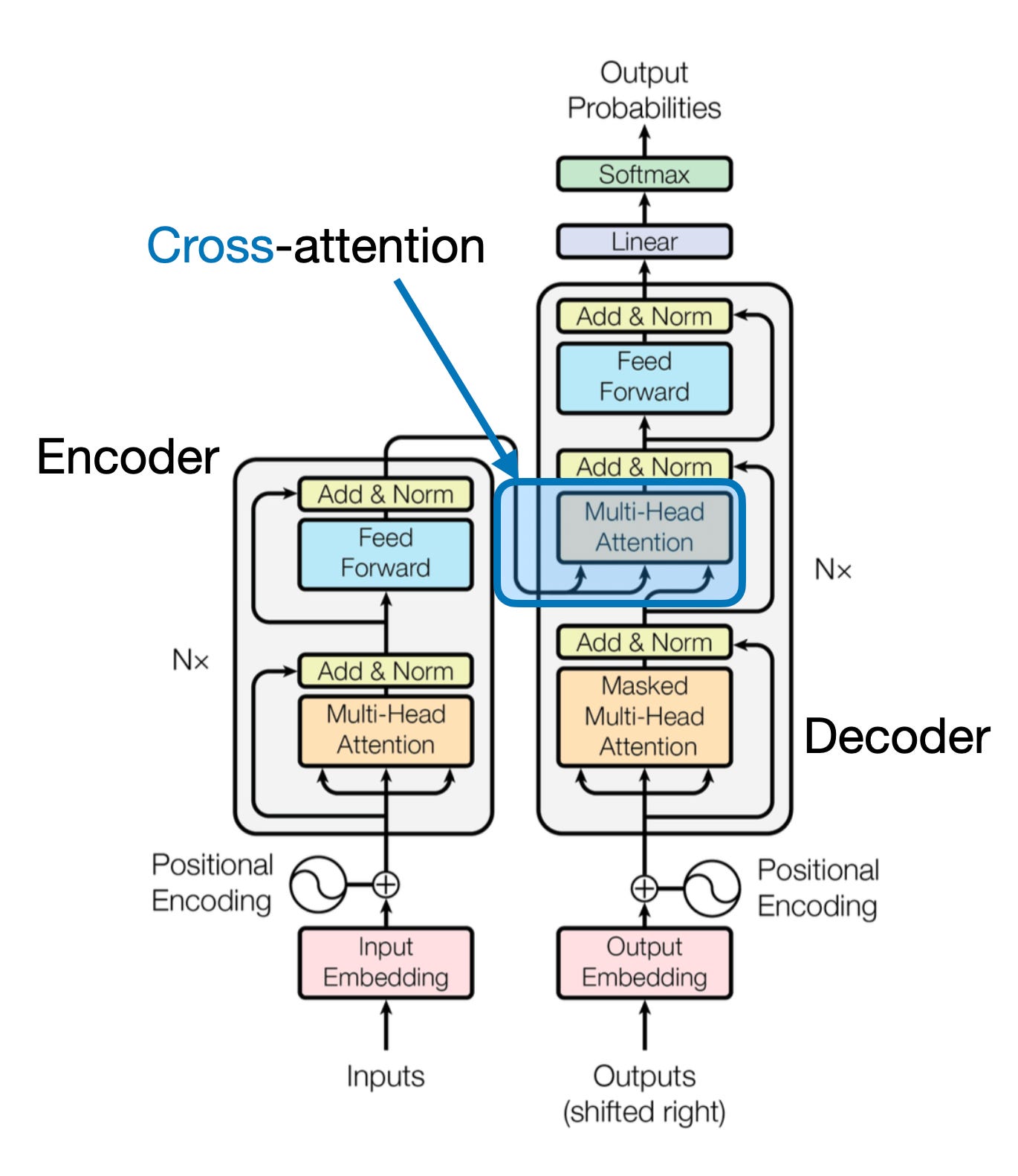
1. 交叉注意力机制
常规自注意力机制的概念图:图中 x x x 是输入, W q W_q Wq 是用于生成查询(Q)的权重矩阵,类似的 K K K 代表键, V V V 代表值, A A A表示注意力分数矩阵。
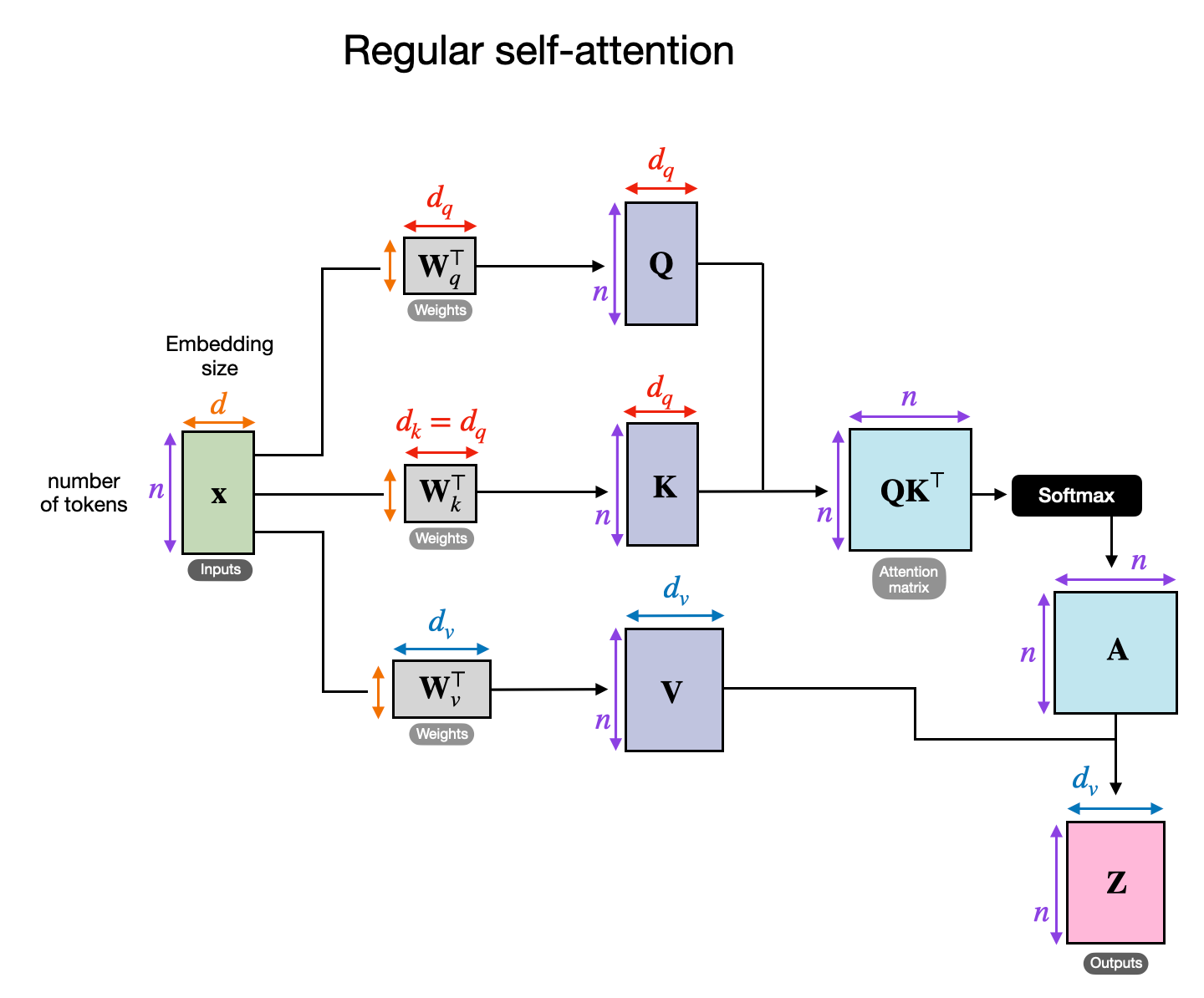
交叉注意力与自注意力不同,自注意力中使用相同的输入序列,而交叉注意力中混合或者组合两个不同的输入序列。
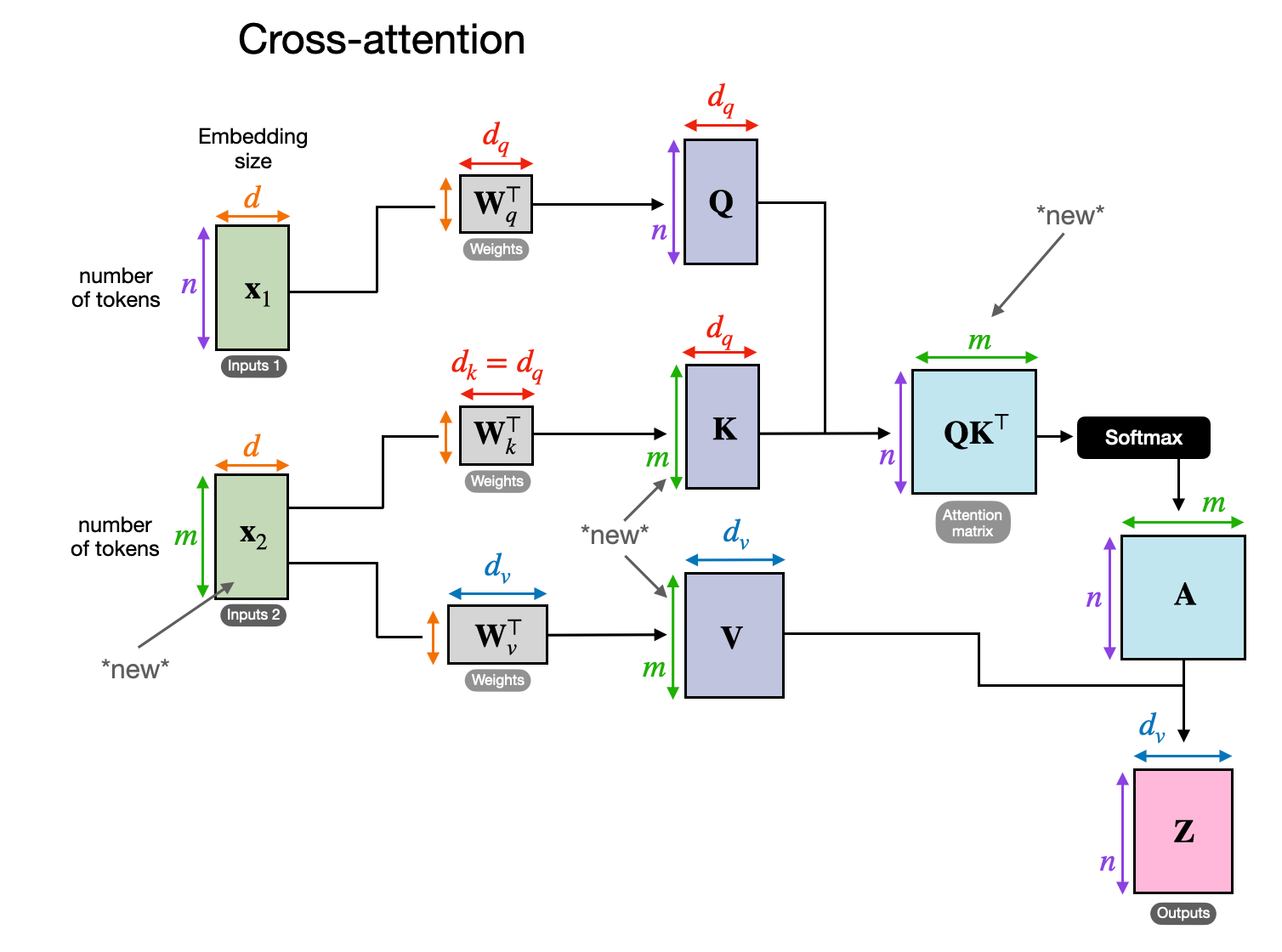
在原始Transformer架构中,两个输入 x 1 x_1 x1和 x 2 x_2 x2分别对应左侧编码模块返回的序列 x 2 x_2 x2以及右侧解码器部分处理的输入序列 x 1 x_1 x1。在多模态大模型中, x 2 x_2 x2是图像编码器的输出。(查询通常来自解码器,键和值通常来自编码器)
三、统一解码器和交叉注意力模型训练
(一)模型训练
针对两种主要的多模态设计方式,我们在模型训练时需要考虑三个主要的组成部分:
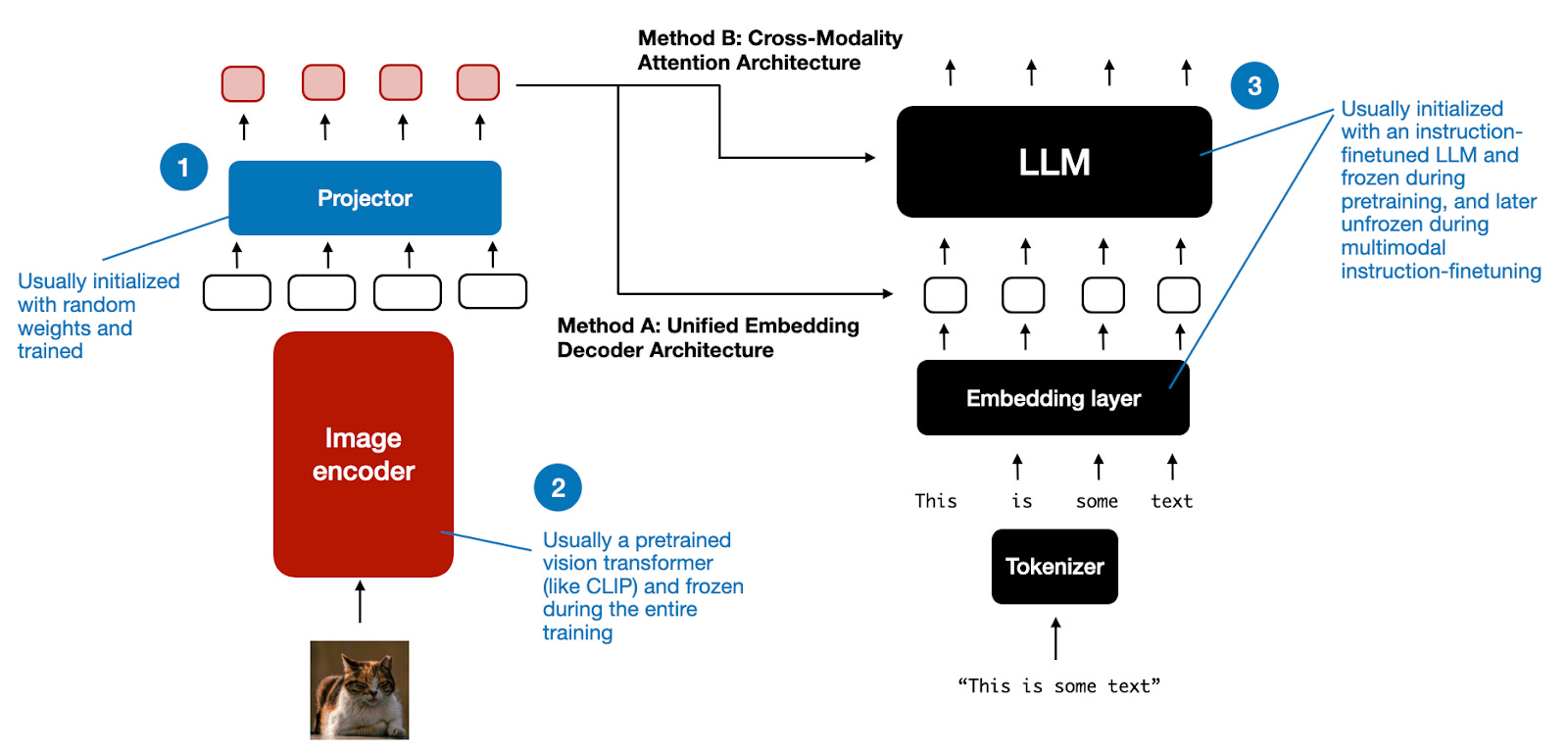
多模态LLM中不同组件的概述。编号为1-3的部件可以在多模态训练过程中冻结或解冻。
与传统纯文本LLM的开发类似,多模态LLM的训练也包含两个阶段:预训练和指令微调。然而,与从零开始不同,多模态LLM训练通常以预训练、经过指令微调的纯文本LLM为基础。
- 对于图像编码器,CLIP是常用的,且在整个训练过程中通常保持不变(存在例外)
- 对于Projector:预训练阶段保持LLM部分冻结也很常见,只专注于训练Projector------先行曾或者小型多层MLP。由于Projector的学习能力有限,LLM通常在多模态指令微调(第二阶段)时解冻,以便进行更全面的更新。
- 在基于交叉注意力的模型(方法B)中,交叉注意力层在整个训练过程中保持解冻状态。
(二)两种方法的对比
- 统一嵌入解码器架构(方法A)通常更容易实现,因为它不需要对LLM架构本身进行修改。
- 跨模式注意力架构(方法B)通常被认为计算效率更高,因为它不会在输入上下文中过载额外的图像token,而是在交叉注意力层后期引入。此外,如果训练过程中保持LLM参数冻结,这种方法还能保持原始LLM的纯文本性能。
四、近期多模态模型与方法
(一)Llama 3 模型群
1. 模型架构
多模态Llama 3.2模型分为110亿和900亿参数版本,是采用上述基于交叉注意力的方法 的图像文本模型,如下图所示。
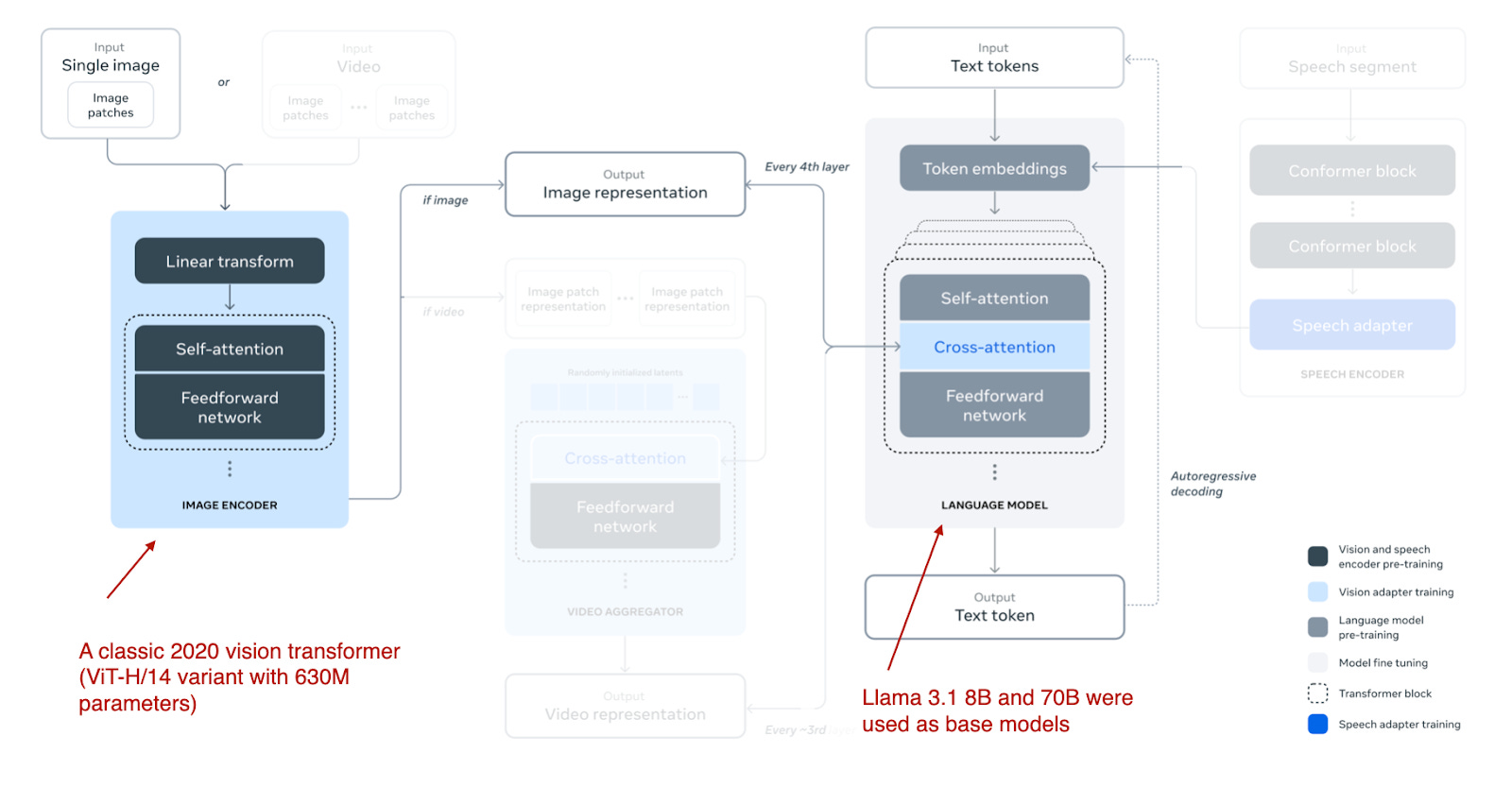
Llama 3.2 所采用的多模态 LLM 方法示意图。(Llama 3论文中的注释图:https://arxiv.org/abs/2407.21783.The 视频和语音部分被视觉遮挡,以聚焦图像部分。)
Llama 3.2采用基于交叉注意力的方法。与之前提到的内容不同,Llama 3.2模型的训练更新了图像编码器,而不更新语言模型的参数。这样做是为了保留原有 Llama 的文本能力,使得 11B 和 90B 的多模态模型在纯文本任务上能够直接替代 Llama 3.1 的 8B 和 70B 模型,同时额外具备图像理解能力。
核心思想是:把视觉能力适配到已经很强的语言模型,而不是去改变语言模型本身。
2. 模型训练
训练过程经过多次迭代:
- 首先是对Llama 3.1文本模型:在添加图像编码器以投影层(adapter)之后,他们使用图像-文本数据对模型进行与训练;
- 其次,类似于Llama 3模型的纯文本训练,这里的训练过程就是指令和偏好微调
Llama 3.2的研究人员没有采用像CLIP这样的预训练模型作为图像编码器,而是使用了从零开始预训练的vision transformer。具体来说,他们使用了经典vision transformer架构中的ViT-H/14变体(6.3亿参数)。然后在5亿图像-文本对数据集上对ViT进行预训练(多于5个epoch);训练完成后再将图像编码器连接到LLM。(图像编码器将224×224分辨率图像分割成14×14像素的网格,每个像素大小为16×16像素。)
另外,由于交叉注意力层会增加大量的参数,Llama 3.2每隔四个Transformer模块才添加这些参数。(对于8B模型,这增加了3B参数;对于70B模型,这增加了200亿个参数)
(二)Molmo 与 PixMo
1. 模型架构
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
这里Molmo指的是模型(多模态开放语言模型),PixMol(Pixels for Molmo)指的是数据集。Molmo的图像编码器采用现成的vision transformer,具体来说是CLIP。这里的"连接connector"指的是将图像特征与语言模型对齐的"projector"。
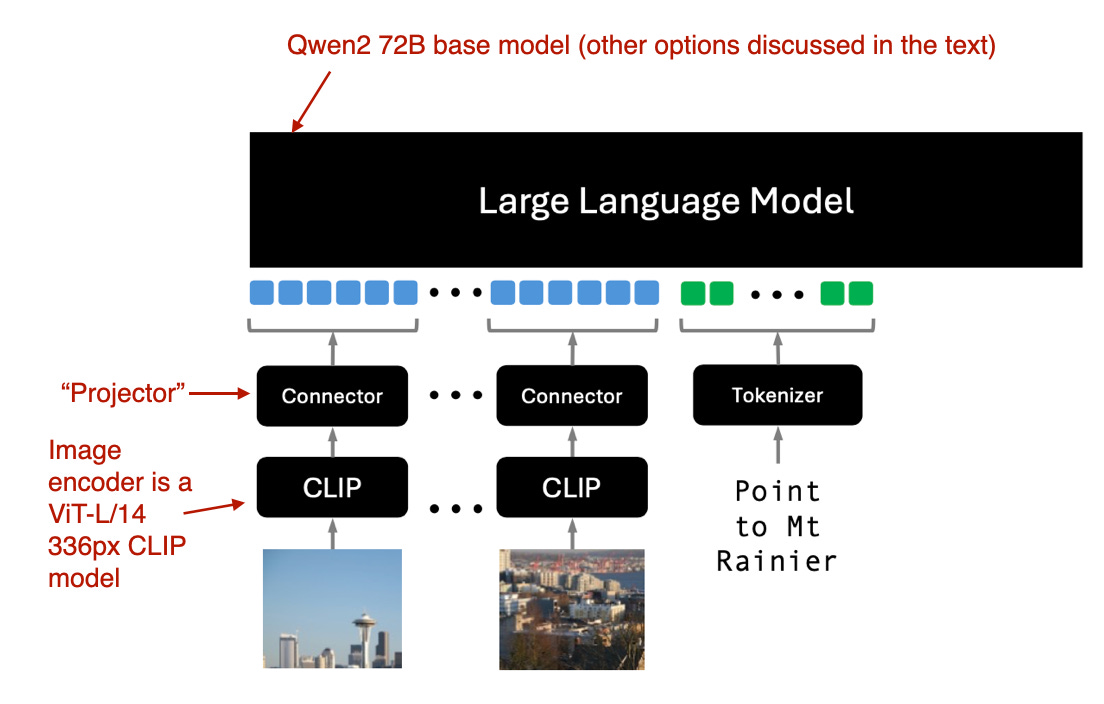
2. 模型训练
Molmo通过避免多个预训练阶段,简化了训练流程,而是选择一个简单的流水线,统一更新所有参数------包括基础LLM、connector和图像编码器的参数。
Molmo团队为基础LLM提供了多种选择:
- OLMo-7B-1024(一款完全开放的模型骨干网)
- OLMoE-1B-7B(专家混合架构;最高效的模型)
- Qwen2 7B(一种性能优于OLMo-7B-1024的开放权重型号)
- Qwen2 72B(一个开权重模型,也是表现最好的模型)
(三)NVLM
1. 模型架构
NVIDIA 2024年9月17日发布的文章NVLM: Open Frontier-Class Multimodal LLMs对两种构建多模态大模型的方法都进行了探讨:
- 方法A:统一嵌入解码器架构("仅解码器架构",NVLM-D)
- 方法B:跨模态注意力架构("基于跨注意力的架构",NVLM-X)
另外,他们也开发了混合方法(NVLM-H),并对三种方法进行了对比: - NVLM-D对应方法A,研究发现NVLM-D在OCR相关任务中实现了更高的准确性
- NVLM-X对应方法B,研究发现NVLM-X 在高分辨率图像中展现出卓越的计算效率
- 混合模型(NVLM-H)的理念是结合两种方法的优势:输入图像缩略图,随后通过动态数量的交叉关注来捕捉更细致的高分辨率细节。
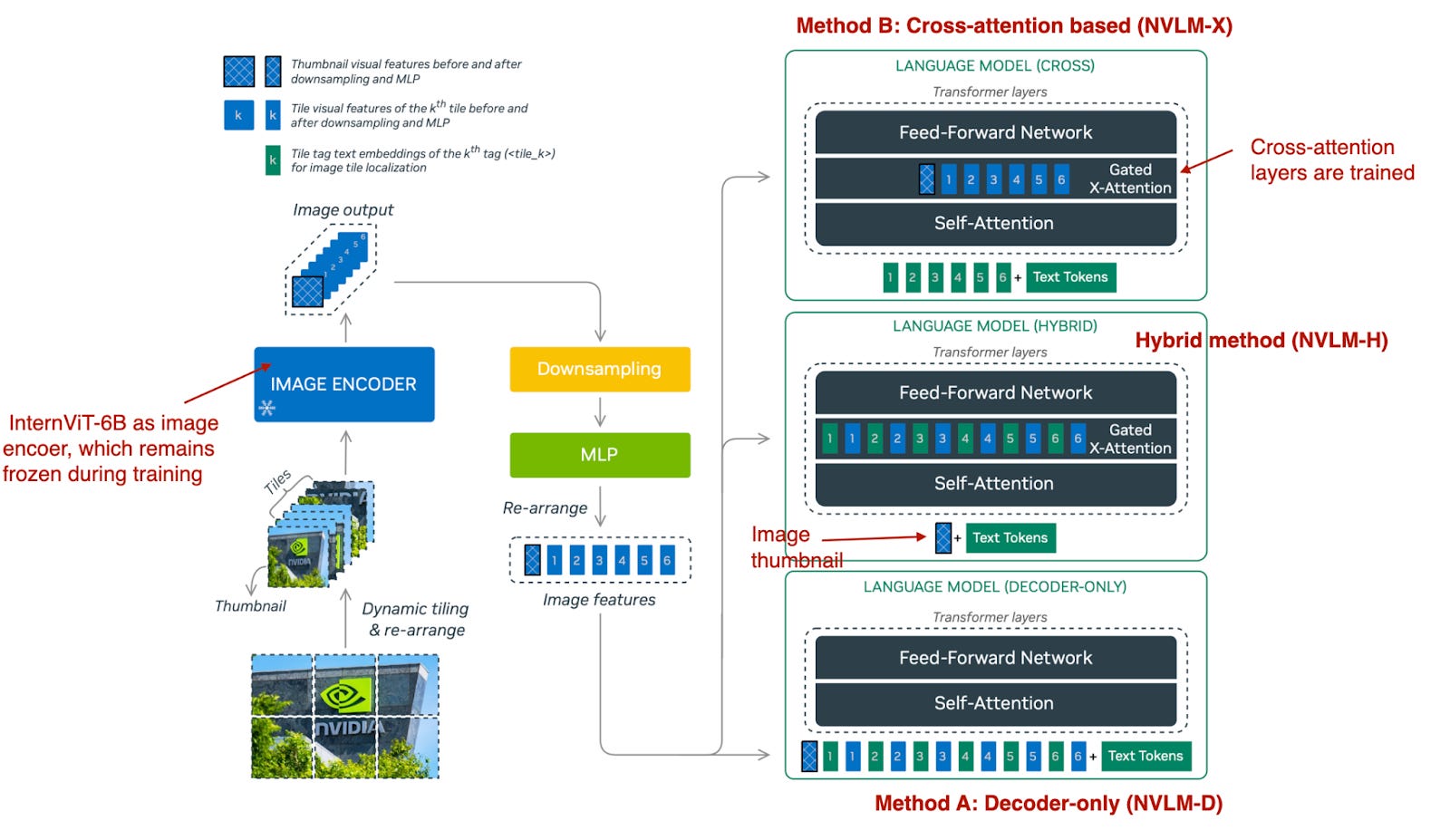
三种多模态方法概述。(注释图取自NVLM: Open Frontier-Class Multimodal LLMs论文:https://arxiv.org/abs/2409.11402)
2. 模型训练
- 类似于Molmo和其他方法,NVLM从纯文本的LLM开始,而不是从零开始预训练多模态模型(因为后者通常表现更好)。此外,他们使用指令调优的大型语言模型(LLM),而不是基础LLM。具体来说,骨干LLM是Qwen2-72B-Instruct(Molmo使用的是Qwen2-72B基础模型)。
- 对于图像编码器,他们没有使用典型的CLIP模型,而是使用InternViT-6B,该部分在所有阶段都保持冻结状态。
- Projector是一个多层MLP,而不是单一线性层
(四)Qwen2-VL
1. 模型架构
Molmo和NVLM都基于Qwen2-72B LLM。Qwen团队在Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution文章发布了自己的多模态大语言模型:Qwen2-VL。
Qwen-VL模型的核心是"Naive Dynamic Resolution",这个机制使得Qwen-VL模型能够直接处理不同分辨率的图像,而不需要降采样,模型从原始分辨率输入图像即可。
- 原生分辨率输入通过修改后的ViT实现,去除了原始的绝对位置嵌入并引入了2D-RoPE。
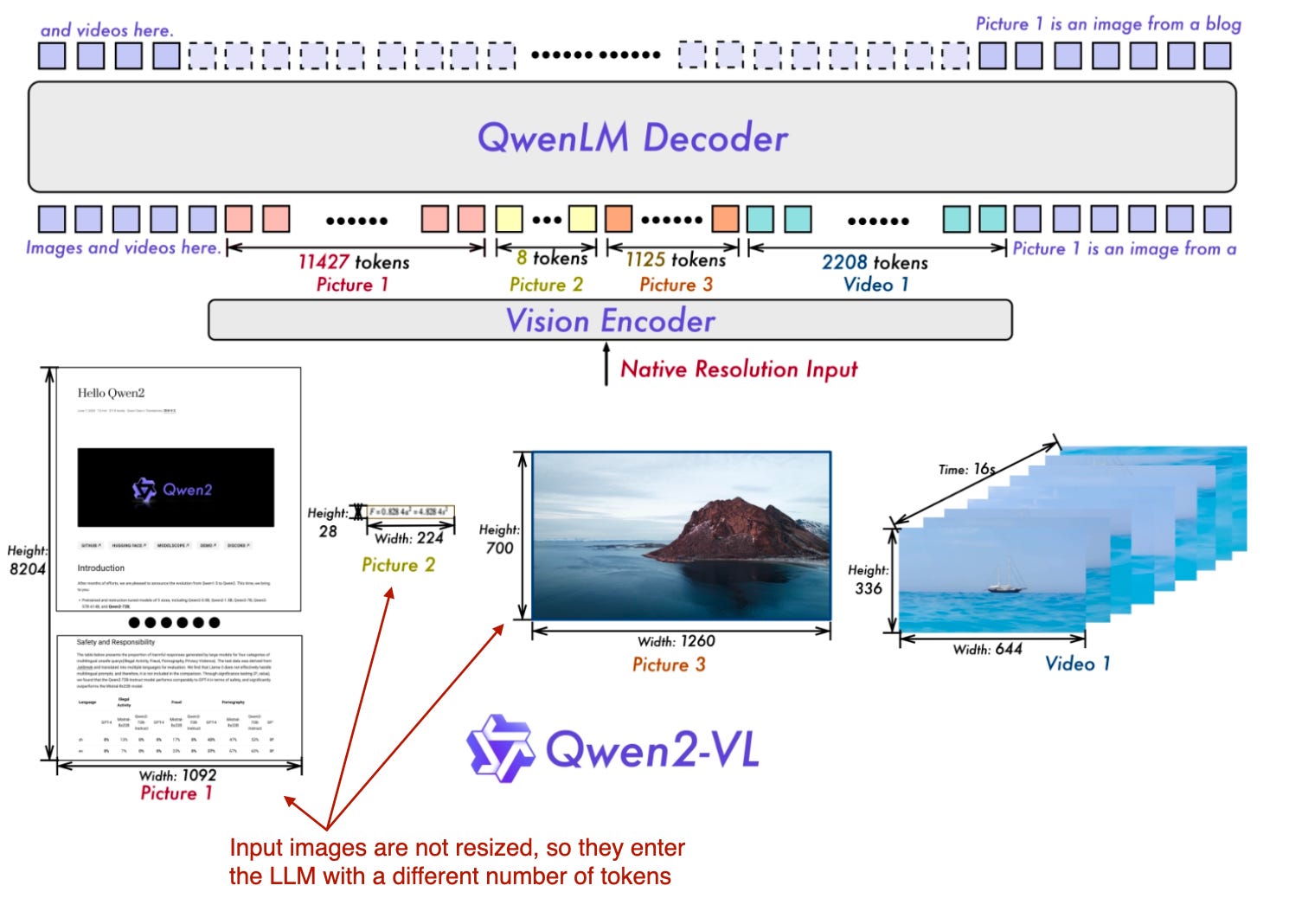
多模态Qwen模型概述,该模型能够原生处理不同分辨率的输入图像。(注释图取自Qwen2-VL论文:https://arxiv.org/abs/2409.12191)
2. 模型训练
训练本身包括三个阶段:
- (1)仅预训练图像编码器,
- (2)解冻所有参数(包括LLM),
- (3)冻结图像编码器并仅对LLM进行指令微调。
(五)Pixtral 12B
Pixtral 12B(2024年9月17日)采用了方法A:统一嵌入解码器架构方法,是Mistral AI的首个多模态模型。Pixtral 12B目前没有技术论文或报告,但Mistral团队在他们的博客文章中分享了一些有趣的细节:
- 他们选择不使用预训练图像编码器,而是从零开始训练一个有4亿参数的图像编码器。
- 对于LLM骨干,他们使用了120亿参数的Mistral NeMo模型。
- 与Qwen2-VL类似,Pixtral也原生支持可变图像尺寸。
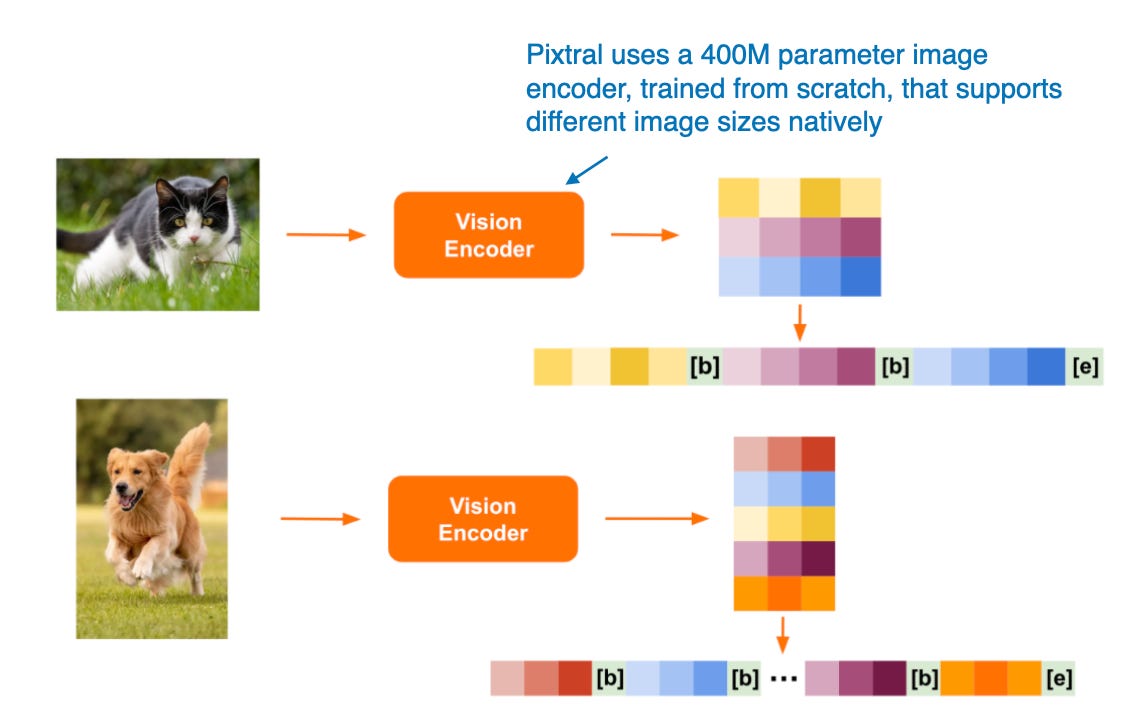
Pixtral 如何处理不同尺寸图像的示意图。(注释图取自Pixtral博客:https://mistral.ai/news/pixtral-12b/)
(六)MM1.5
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning论文总结了很多多模态大模型微调的经验(practical tips),提出了MoE多模态模型和Dense Model(类似Molmo)两类模型。模型规模覆盖从10亿到300亿参数的广泛范围。
文章里提出的模型采用方法A:Unified Embedding Transformer Architecture(统一嵌入 Transformer 架构)。核心思想是把文本 token 和视觉 token 放到同一个序列里,用同一个 Transformer 处理。
此外,论文还通过大量消融实验研究了不同训练数据组合以及坐标 token 对模型性能的影响。
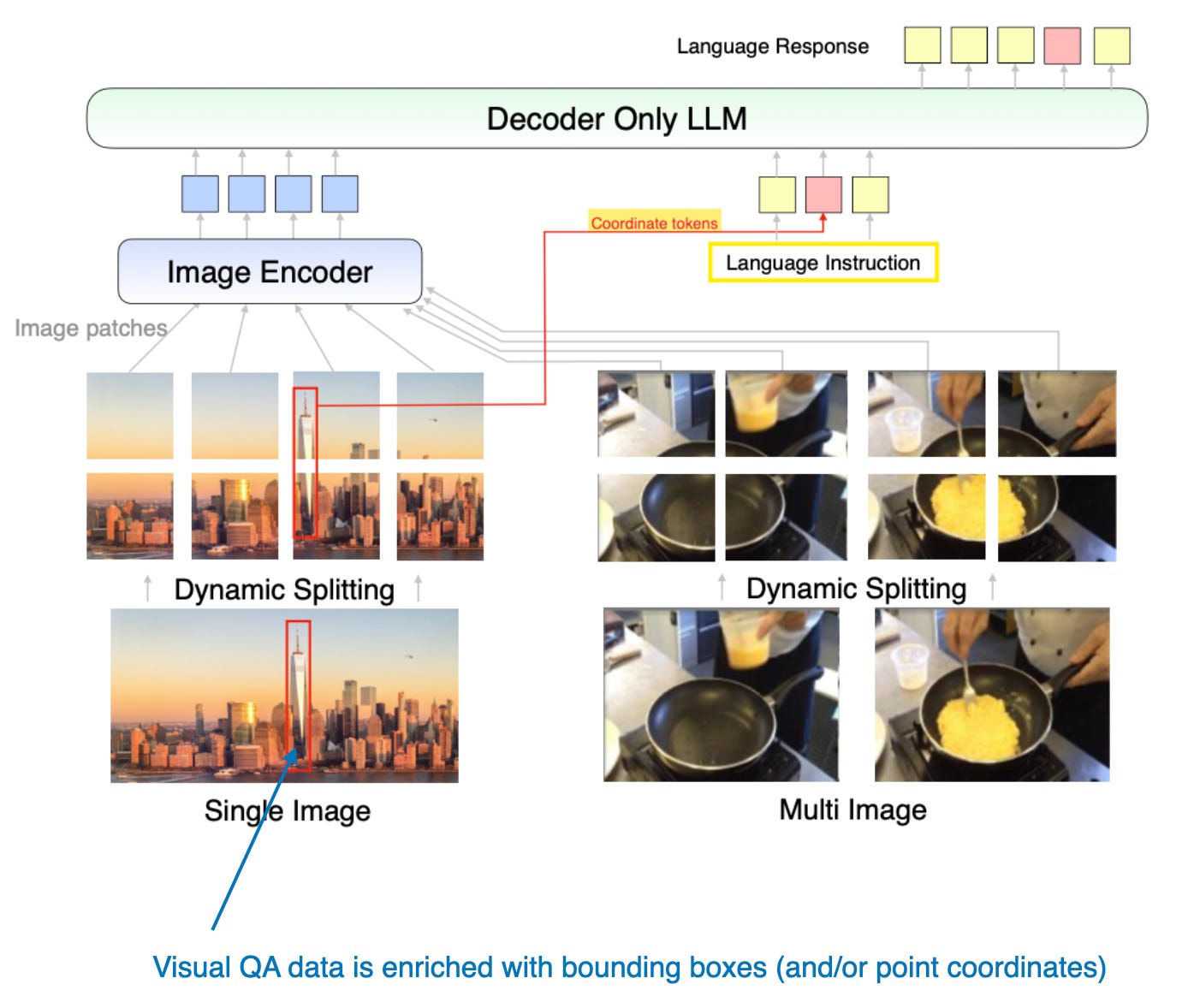
MM1.5方法的示意图,包含额外的坐标符号以表示边界框。(注释图取自MM1.5论文:https://arxiv.org/abs/2409.20566。)
(七)Aria
Aria: An Open Multimodal Native Mixture-of-Experts Model论文提出了另一种MoE模型方法,类似于Molmo和MM1.5系列中的某个变体。
Aria 模型拥有 249 亿个参数,每个文本token分配 35 亿个参数。图像编码器(SigLIP)拥有4.38亿个参数。该模型基于交叉注意力方法,整体训练过程如下:
- 完全从零开始训练LLM骨干。
- 预训练LLM骨干和视觉编码器。
(八)Baichuan-Omni
Baichuan-Omni模型是一种基于方法A:统一嵌入解码器架构方法的70亿参数多模态大型语言模型,如下图所示。
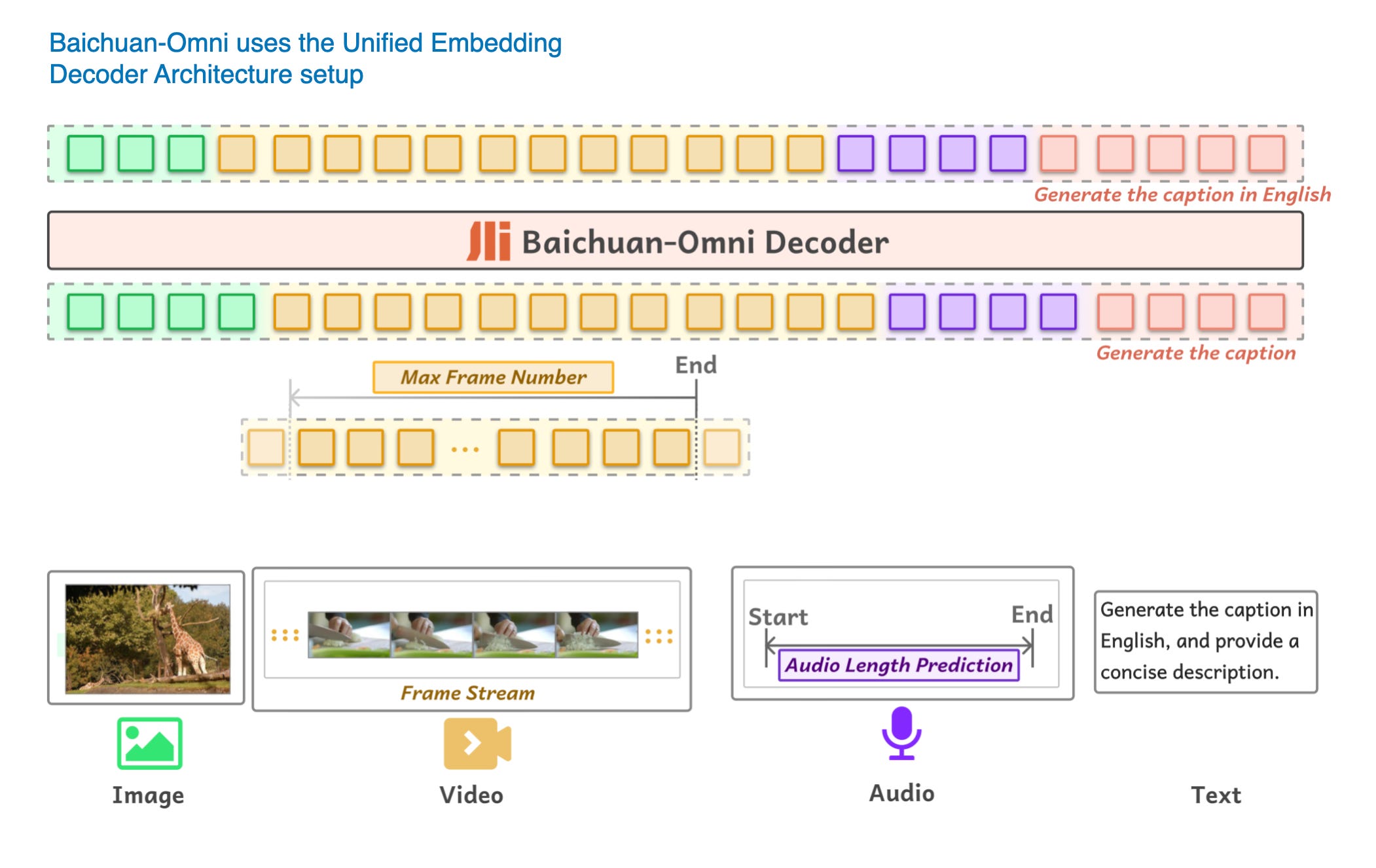
Baichuan-Omni模型的训练过程:
- 训练Projector:最开始只训练Projector,视觉编码器和语言模型LLM保持冻结状态
- 训练视觉编码器:解冻并训练视觉编码器,LLM仍然保持冻结状态
- 全模型训练:LLM解冻,允许整个模型端到端训练
Baichuan-Omni模型使用SigLIP视觉编码器,并集成AnyRes模块,通过下采样技术处理高分辨率图像。虽然报告未明确指定LLM骨干,但根据模型参数大小和命名规范,很可能基于Baichuan 7B大语言模型。
(九)Emu3
Emu3提出了一种令人信服的替代扩散模型的图像生成 方案,该方案完全基于Transformer的解码器架构。虽然它不是传统意义上的多模态大型语言模型(即侧重图像理解而非生成的模型),但Emu3非常有趣,因为它展示了可以用Transformer解码器进行图像生成,而这通常是由扩散方法主导的任务 。(不过,请注意,之前也有类似的方法,例如Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation。)
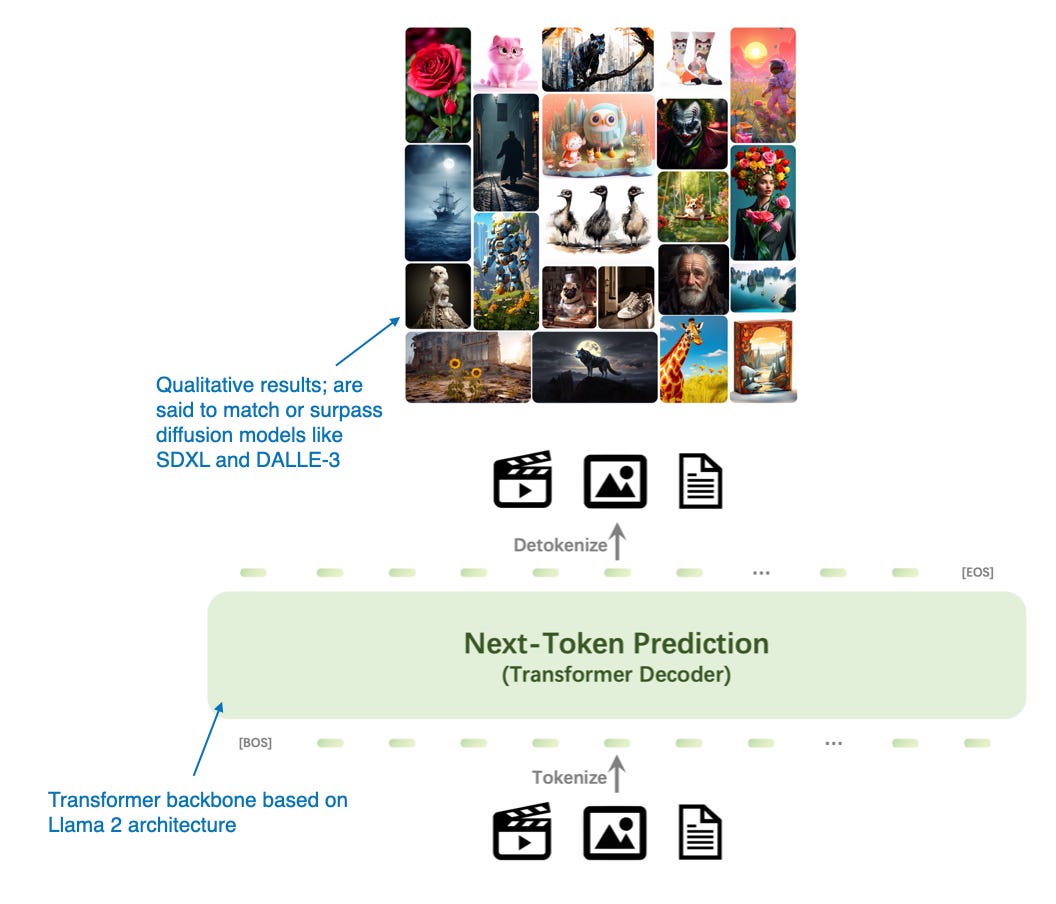
研究人员从零开始训练Emu3,然后使用DPO使模型符合人类偏好。
该架构包含了一个受SBER-MoVQGAN启发的vision tokenizer。核心的LLM架构基于Llama 2,但完全从零开始训练。
(十)Janus
Janus提出了一个框架,将多模态理解和生成任务统一在单一的LLM backbone中。
Janus模型采用了与Baichuan-Omni类似的SigLIP视觉编码器来处理视觉输入。在图像生成方面,它使用矢量量化(VQ)分词器来处理生成过程。Janus的基础LLM是DeepSeek-LLM,拥有13亿参数。
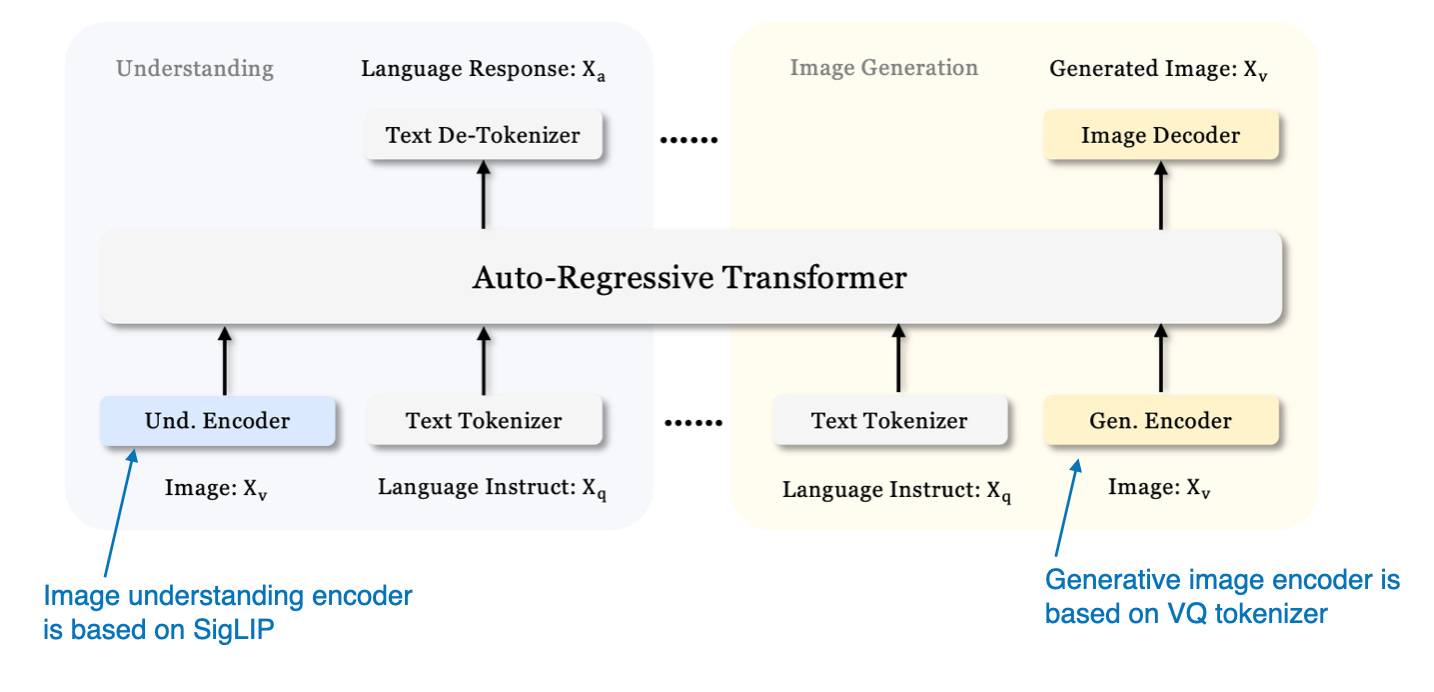
Janus模型的训练过程分为三个阶段:
- 第一阶段:只有Projector层和图像输出层被训练,LLM、Understanding encoder和generation encoder冻结
- 第二阶段:LLM backbone和文本输出层解冻,实现理解和生成任务间的统一预训练
- 第三阶段:整个模型(包括SigLIP图像编码器)解冻,进行监督微调,使模型能够完全集成和完善其多模态能力。
五、总结
多模态LLM可以通过多种不同方式成功构建。下图总结了上述讨论涵盖的模型各个组成部分。