M N I S T MNIST MNIST 手写数字识别的训练实现
前面的章节中,我们实现了一个简单的神经网络推理过程。但那时网络的权重参数直接引用了外部的 sample_weight.pkl 文件,相当于拿了一个"已经训练好的成品模型"来用,网络本身并没有学习能力。
现在,我们将结合前面学到的损失函数、反向传播、梯度下降等知识,让神经网络从数据中自己学习 。具体来说,网络将经历完整的训练流程:
随机初始化参数 → 前向传播计算预测值 → 损失函数量化误差 → 反向传播计算梯度 → 根据梯度更新参数 → 反复迭代直到模型收敛 随机初始化参数 → 前向传播计算预测值 → 损失函数量化误差 → 反向传播计算梯度 → 根据梯度更新参数 → 反复迭代直到模型收敛 随机初始化参数→前向传播计算预测值→损失函数量化误差→反向传播计算梯度→根据梯度更新参数→反复迭代直到模型收敛
最终网络自行训练出权重参数,不再依赖外部文件,真正具备"从数据中学习"的能力。
本文的相关
mnist数据集等详见附录,本文代码位于项目目录train/fcnn下
数据集
-
介绍 ------
MNIST是深度学习领域最经典的入门数据集之一,由美国国家标准与技术研究所收集整理。它包含70000张手写数字灰度图像: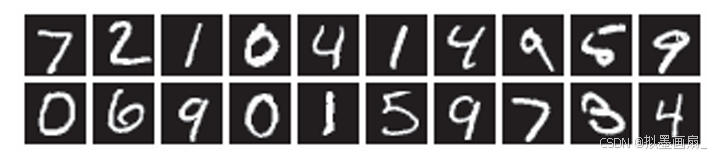
-
结构 ------
MNIST的图像数据是28×28像素的手写数字灰度图像(1通道),各个像素取值在0到255之间,每个图像数据都相应地标有7、2、1等标签。训练图像有6万张, 测试图像有1万张。属性 说明 属性 说明 图像内容 手写数字 0~9--- --- 图像尺寸 28 × 28像素(灰度图)每张图像 784个像素值(28×28展平)训练集 60000张测试集 10000张
网络设计
-
目标 ------ 设计并实现一个完整的神经网络,使其具备从数据中学习 和对新数据进行推理的能力:
- 训练 :在 M N I S T MNIST MNIST 数据集上自行学习,无需依赖外部权重文件,最终保存训练好的参数。
- 推理 :输入一张
28×28的手写数字图像,网络基于训练阶段学到的知识,输出它属于0~9中哪个数字。
-
网络结构
- 设计的神经网络的输入层有 784 784 784 个神经元,输出层有 10 10 10 个神经元
- 有 1 1 1 个隐藏层,隐藏层神经元数可自由设定(如 50 50 50)
- 隐藏层采用
Sigmoid函数,输出层采用Softmax函数 - 网络结构如下:
I n p u t ( 784 ) → A f f i n e → S i g m o i d → A f f i n e → S o f t m a x → O u t p u t ( 10 ) Input(784) → Affine → Sigmoid → Affine → Softmax → Output(10) Input(784)→Affine→Sigmoid→Affine→Softmax→Output(10)
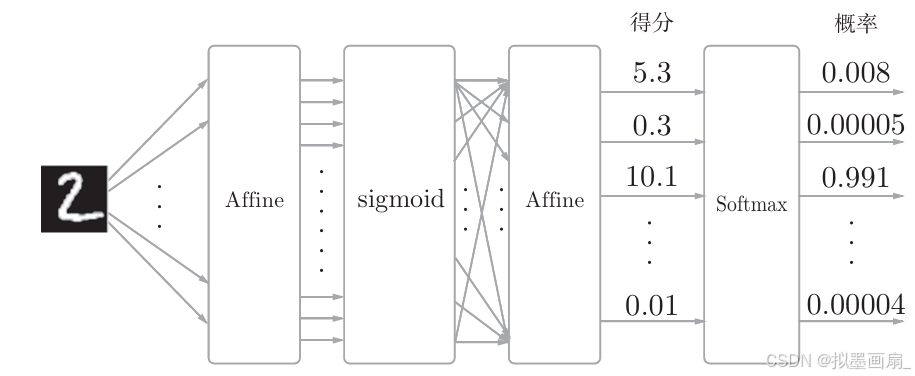
与前面前向传播的三层网络(两个隐藏层)相比,
SimpleFCNet是一个更简单的两层全连接网络,可以视作前文ThreeLayerNet的简化版本
网络实现
初始化参数
-
初始化神经网络的参数
- 权重参数 ------ 随机生成权重,其中
weight_init_std参数用于控制正态分布随机值的分散程度 - 偏置参数 ------ 置零
pythonclass TwoLayerNet: """ 简单两层全连接神经网络 Fully-Connected Neural Network, FCNN 网络结构:[Affine → Sigmoid] → [Affine → Softmax] """ def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01): """ 初始化两层全连接神经网络,随机生成权重并置零偏置。 :param input_size: 输入层神经元数量(如 MNIST 为 784) :param hidden_size: 隐藏层神经元数量(可自由设定,如 50) :param output_size: 输出层神经元数量(分类任务为类别数,如 MNIST 为 10) :param weight_init_std: 权重初始化的标准差,用于控制正态分布随机值的分散程度(默认为 0.01) """ self.params = { 'W1': weight_init_std * np.random.randn(input_size, hidden_size), 'b1': np.zeros(hidden_size), 'W2': weight_init_std * np.random.randn(hidden_size, output_size), 'b2': np.zeros(output_size) } - 权重参数 ------ 随机生成权重,其中
前向传播
-
定义神经网络结构,用于前向传播。这里的网络共两层,具体如下:
pythondef predict(self, x): """ 前向传播,结构:Input → [Affine → Sigmoid] → [Affine → Softmax] → Output :param x: 输入数据 :return: 每个类别的概率值 """ W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = softmax(a2) return y
损失函数
-
计算损失函数,采用交叉熵误差 C r o s s E n t r o p y E r r o r Cross Entropy Error CrossEntropyError 方法,方法实现由
common\functions.py引入pythondef loss(self, x, t): """ 计算损失函数,采用交叉熵误差 Cross Entropy Error :param x: 输入数据 :param t: 监督标签 :return: 前向传播的损失值 """ y = self.predict(x) return cross_entropy_error(y, t)
识别准确率
-
计算神经网络的识别准确率
pythondef accuracy(self, x, t): """ 计算识别准确率 :param x: 输入数据 :param t: 监督标签 :return: 准确率 """ y = self.predict(x) y = np.argmax(y, axis=1) t = np.argmax(t, axis=1) return np.sum(y == t) / float(x.shape[0])
梯度计算
-
在神经网络中,计算梯度主要有两种方法:
- 数值微分法 ------ 基于导数定义。实现简单、结果可靠,常用于验证反向传播是否正确,但计算量大,训练时不采用
- 误差反向传播法 ------ 基于链式法则,一次前向加一次反向即可算出所有参数的梯度,训练的实际选择
pythondef numerical_gradient(self, x, t): """ 梯度计算(数值微分法) :param x: 输入数据 :param t: 教师标签 :return: 具有各层的梯度的字典变量 grads['W1']、grads['W2']、...是各层的权重 grads['b1']、grads['b2']、...是各层的偏置 """ loss_W = lambda W: self.loss(x, t) grads = { 'W1': numerical_gradient(loss_W, self.params['W1']), 'b1': numerical_gradient(loss_W, self.params['b1']), 'W2': numerical_gradient(loss_W, self.params['W2']), 'b2': numerical_gradient(loss_W, self.params['b2'])} return gradspythondef gradient(self, x, t): """ 梯度计算(误差反向传播法) :param x: 输入数据 :param t: 教师标签 :return: 具有各层的梯度的字典变量 grads['W1']、grads['W2']、...是各层的权重 grads['b1']、grads['b2']、...是各层的偏置 """ W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] grads = {} batch_num = x.shape[0] # 正向传播 a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = softmax(a2) # 反向传播 dy = (y - t) / batch_num grads['W2'] = np.dot(z1.T, dy) grads['b2'] = np.sum(dy, axis=0) da1 = np.dot(dy, W2.T) dz1 = sigmoid_grad(a1) * da1 grads['W1'] = np.dot(x.T, dz1) grads['b1'] = np.sum(dz1, axis=0) return grads
保存参数
-
使用
pickle库,把训练好的参数进行保存,用于后续推理pythondef save_params(self, file_name="params.pkl"): """ 保存训练好的参数到文件 :param file_name: 保存的文件名,默认为 "params.pkl" :return: None """ params = {} for key, val in self.params.items(): params[key] = val with open(file_name, 'wb') as f: pickle.dump(params, f)
网络训练
基本实现
-
如何训练神经网络?一个最朴素的想法是,一次把全部训练数据喂给网络,让网络去学习:
- 每轮( e p o c h epoch epoch)用整个训练集做一次前向传播、计算损失、反向传播、更新参数。
- 训练到一定轮数,神经网络的参数自然就拟合
-
基于上面的思想,实现代码:
- 读取数据集,初始化神经网络
- 初始化训练超参数,设置轮数 e p o c h s epochs epochs 为 100 100 100 轮,学习率 l e a r n i n g _ r a t e learning\_rate learning_rate 为 0.8 0.8 0.8
- 设置数组记录训练过程的数据,用于可视化
train_loss_list------ 训练损失列表train_acc_list------ 训练集准确率列表test_acc_list------ 测试集准确率列表
- 开始训练,使用
for循环epochs次,每一次都是一次完整的前向传播、计算损失、反向传播、更新参数流程 - 最后根据训练过程数据绘制图像,展示训练过程准确率
accuracy的变化
pythonimport numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from TwoLayerNet import TwoLayerNet # 读入数据 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) # 初始化全连接神经网络 network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) # 初始化训练参数 epochs = 100 # 对所有训练集数据训练 1000 次 learning_rate = 0.8 # 学习率 # 记录训练数据 train_loss_list = [] train_acc_list = [] test_acc_list = [] # 开始训练 for epoch in range(epochs): # 计算梯度(一次性使用全部 60000 张图) grad = network.gradient(x_train, t_train) # 更新参数 for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] # 计算损失(全部数据) loss = network.loss(x_train, t_train) train_loss_list.append(loss) # 评估准确率 train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) print(f"epoch {epoch + 1}/{epochs} | loss: {loss:.4f} | train acc: {train_acc:.4f} | test acc: {test_acc:.4f}") # 绘制训练图形 x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show() -
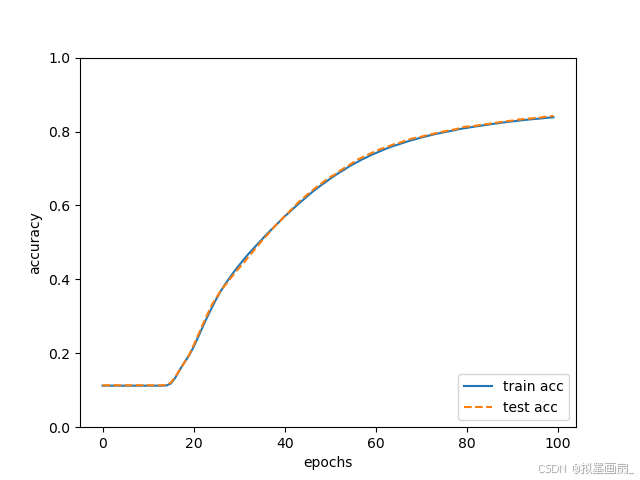
运行结果
 python
pythonepoch 1/100 | loss: 2.3008 | train acc: 0.1124 | test acc: 0.1135 epoch 2/100 | loss: 2.3003 | train acc: 0.1124 | test acc: 0.1135 epoch 3/100 | loss: 2.2997 | train acc: 0.1124 | test acc: 0.1135 ... epoch 99/100 | loss: 0.6485 | train acc: 0.8376 | test acc: 0.8413 epoch 100/100 | loss: 0.6429 | train acc: 0.8387 | test acc: 0.8421 -
存在的问题
- 可以看到,准确率确实在逐步提高 ------ 从起初的 11 % 11\% 11% 到最终的 84 % 84\% 84%,说明神经网络正在学习
- 但是这里有一个致命问题 ------ 训练过程太慢,计算量太大,一次训练要几分钟以上
- 原因在于,网络每步要把全部 60000 60000 60000 张图算一遍梯度才能更新一次参数,每次更新都代价高昂 ------ 内存压力大、单步耗时长,这就导致了每次迭代的时间都慢得难以忍受
基于 m i n i − b a t c h mini-batch mini−batch 的实现
-
基于上面的问题,我们换个思路:
- 不再一次性使用全部 60000 张图,而是每次只从训练集中随机抽取一小批数据
- 用这批数据的平均梯度作为整体梯度的近似,来更新参数
-
基于上面的思想,引入几个关键概念
-
批( b a t c h _ s i z e batch\_size batch_size) ------ 每次参数更新所使用的一批样本数量。下面的代码中取 100 100 100,表示每次只用 100 100 100 张图片来估算梯度,远小于训练集总量 60000 60000 60000 张图片
-
步( i t e r iter iter) ------ 用一批( b a t c h batch batch)数据进行的一次完整的前向传播、计算损失、反向传播、更新参数的过程,称为一步
-
轮( e p o c h epoch epoch)------ 全部训练数据被完整遍历一遍,称为一轮
一轮不再是指一次完整的训练流程(更新),而是指把全部 60000 60000 60000 张图都用过一遍
每步用一批 100 100 100 个数据, 600 600 600 步下来, 60000 60000 60000 张图刚好全部参与过一次训练
-
步每轮( i t e r _ p e r _ e p o c h iter\_per\_epoch iter_per_epoch)------ 把全部训练数据都用过一遍需要多少步
-
-
根据上面的概念,我们可以得到下面的关系式:
i t e r _ p e r _ e p o c h = t r a i n _ s i z e b a t c h _ s i z e iter\_per\_epoch = \frac{train\_size}{batch\_size} iter_per_epoch=batch_sizetrain_size
i t e r s = e p o c h s × i t e r _ p e r _ e p o c h iters = epochs \times iter\_per\_epoch iters=epochs×iter_per_epoch
以 M I N I S T MINIST MINIST 数据集为例,假设:
- 训练集总量 t r a i n _ s i z e = 600000 train\_size=600000 train_size=600000 张图片,一批取 b a t c h _ s i z e = 100 batch\_size=100 batch_size=100 张图片
- 设定进行 e p o c h = 20 epoch=20 epoch=20 轮,即把全部 60000 60000 60000 张图遍历 20 20 20 轮
那么有:
- 一轮包含 60000 / 100 = 600 60000/100=600 60000/100=600 步,即 i t e r _ p e r _ e p o c h = 600 iter\_per\_epoch = 600 iter_per_epoch=600
- 20 20 20 轮一共有 20 × 600 = 12000 20 \times 600=12000 20×600=12000 步,即 i t e r = 12000 iter=12000 iter=12000
-
基于上面的思想,实现代码:
-
读取数据集,初始化神经网络
-
初始化训练超参数,设置轮数 e p o c h s epochs epochs 为 20 20 20 轮,学习率 l e a r n i n g _ r a t e learning\_rate learning_rate 为 0.1 0.1 0.1,其他参数计算可得
pythonepochs = 20 # 训练轮数:整个训练集被完整遍历 20 次 learning_rate = 0.1 train_size = x_train.shape[0] # 训练集图片数:MNIST 共 60000 张 batch_size = 100 # 批大小:每步随机抽取 100 张图 iter_per_epoch = max(train_size / batch_size, 1) # 一轮包括 60000张 / 100张 = 600步 iters = int(epochs * iter_per_epoch) # 20轮包括 20轮 × 600步 = 12000步 -
设置数组记录训练过程的数据,用于可视化
-
开始训练,使用
for循环iter次,每次取一批数据,进行一次一次完整的训练流程pythonbatch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] -
最后根据训练过程数据绘制图像,展示训练过程准确率
accuracy的变化
pythonimport numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from TwoLayerNet import TwoLayerNet # 读入数据 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) # 初始化全连接神经网络 network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) # 初始化训练参数 epochs = 20 # 训练轮数:整个训练集被完整遍历 20 次 learning_rate = 0.1 train_size = x_train.shape[0] # 训练集图片数:MNIST 共 60000 张 batch_size = 100 # 批大小:每步随机抽取 100 张图 iter_per_epoch = max(train_size / batch_size, 1) # 一轮包括 60000/100=600步 iters = int(epochs * iter_per_epoch) # 20轮包括 20×600=12000步 # 记录训练数据 train_loss_list = [] train_acc_list = [] test_acc_list = [] # 开始训练 current_epoch = 0 for current_iter in range(iters): # 批处理 batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 神经网络计算梯度 grad = network.gradient(x_batch, t_batch) # 神经网络更新参数 for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] # 神经网络计算损失 loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) # 评估准确率:每完成一轮(epoch)才评估一次,不在每一步都记录 if current_iter % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) current_epoch += 1 print(f"epoch {current_epoch}/{epochs} | loss: {loss:.4f} | train acc:{train_acc:.4f} | test acc: {test_acc:.4f}") # 绘制训练图形 x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show() -
-
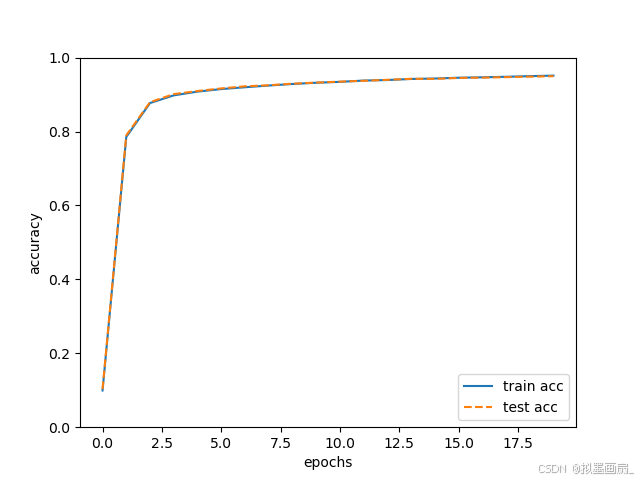
运行结果
 python
pythonepoch 1/20 | loss: 2.2924 | train acc:0.0993 | test acc: 0.1032 epoch 2/20 | loss: 0.7921 | train acc:0.7853 | test acc: 0.7897 epoch 3/20 | loss: 0.4136 | train acc:0.8770 | test acc: 0.8794 ... epoch 18/20 | loss: 0.2125 | train acc:0.9481 | test acc: 0.9471 epoch 19/20 | loss: 0.1322 | train acc:0.9498 | test acc: 0.9484 epoch 20/20 | loss: 0.2213 | train acc:0.9513 | test acc: 0.9497可以看到,我们仅使用了 20 20 20 轮便使准确率达到了
0.9513,并且计算和收敛速度明显加快,这便是 m i n i − b a t c h mini-batch mini−batch 的优势
封装为类
将上面训练的代码整理为一个名为
Trainer的类,统一封装核心的训练流程,方便后续训练和测试时调用
类的定义
python
import numpy as np
import matplotlib.pyplot as plt
class Trainer:
def __init__(self, network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100, learning_rate=0.1,
evaluate_sample_num_per_epoch=None, verbose=True):
"""
训练器类:封装了神经网络的完整训练流程(数据洗牌、小批量迭代、参数更新、定期评估)
:param network: 待训练的神经网络实例
:param x_train: 训练集输入数据,形状 (N_train, input_size)
:param t_train: 训练集标签数据,形状 (N_train,)
:param x_test: 测试集输入数据,形状 (N_test, input_size)
:param t_test: 测试集标签数据,形状 (N_test,)
:param epochs: 训练的总轮数,即完整遍历整个训练集的次数
:param mini_batch_size: 每次梯度更新使用的小批量样本数
:param learning_rate: 学习率
:param evaluate_sample_num_per_epoch: 每轮评估时抽样的样本数,None 表示使用全部测试集
:param verbose: 是否在训练过程中打印详细日志(损失值、准确率等)
"""
# 初始化网络
self.network = network
# 初始化数据
self.x_train = x_train
self.t_train = t_train
self.x_test = x_test
self.t_test = t_test
# 初始化训练相关参数
self.epochs = epochs
self.learning_rate = learning_rate
self.batch_size = mini_batch_size
self.train_size = x_train.shape[0]
self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)
self.iter = int(epochs * self.iter_per_epoch)
self.current_epoch = 0 # 轮数计数器
self.current_iter = 0 # 步数计数器
# 记录训练过程数据
self.train_loss_list = [] # 训练损失列表,记录每个mini-batch训练后的损失值
self.train_acc_list = [] # 训练准确率列表,记录每个epoch结束时的训练集准确率
self.test_acc_list = [] # 测试准确率列表,记录每个epoch结束时的测试集准确率
# 是否打印训练过程详细信息
self.verbose = verbose
# 初始化相关配置
self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch # 每轮评估时使用的样本数(None表示使用全部数据)
def train_step(self):
# 批处理
batch_mask = np.random.choice(self.train_size, self.batch_size) # 随机生成批次大小的索引
x_batch = self.x_train[batch_mask] # 获取批次输入数据
t_batch = self.t_train[batch_mask] # 获取批次标签数据
# 神经网络计算梯度
grads = self.network.gradient(x_batch, t_batch)
# 神经网络更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
self.network.params[key] -= self.learning_rate * grads[key]
# 神经网络计算损失
loss = self.network.loss(x_batch, t_batch)
self.train_loss_list.append(loss) # 记录当前批次的损失值
if self.verbose: print("train loss: " + str(loss)) # 打印训练损失
# 判断是否完成一个epoch:当迭代次数达到每个epoch应有的迭代次数时
if self.current_iter % self.iter_per_epoch == 0:
self.current_epoch += 1
# 准备评估数据:默认使用全部数据,如果指定了评估样本数则使用前N个样本
x_train_sample, t_train_sample = self.x_train, self.t_train
x_test_sample, t_test_sample = self.x_test, self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t = self.evaluate_sample_num_per_epoch # 获取评估样本数
x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t] # 取前t个训练样本
x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t] # 取前t个测试样本
# 计算准确率:分别计算训练集和测试集上的准确率
train_acc = self.network.accuracy(x_train_sample, t_train_sample)
test_acc = self.network.accuracy(x_test_sample, t_test_sample)
self.train_acc_list.append(train_acc) # 记录训练准确率
self.test_acc_list.append(test_acc) # 记录测试准确率
if self.verbose:
print("=== epoch:" + str(self.current_epoch) +
", train acc:" + str(train_acc) +
", test acc:" + str(test_acc) + " ===\n")
self.current_iter += 1
def display_accuracy(self):
x = np.arange(len(self.train_acc_list))
plt.plot(x, self.train_acc_list, label='train acc')
plt.plot(x, self.test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
def train(self):
# 循环执行训练步骤,直到达到总迭代次数
for i in range(self.iter):
self.train_step() # 执行一步训练(包含前向传播、反向传播、参数更新)
# 计算准确率
test_acc = self.network.accuracy(self.x_test, self.t_test)
# 展示结果
if self.verbose:
print("\n=============== Final Test Accuracy ===============")
print("test acc:" + str(test_acc))
print("===================================================")
self.display_accuracy()类的使用
python
from dataset.mnist import load_mnist
from TwoLayerNet import TwoLayerNet
from trainer import *
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 初始化全连接神经网络FCNN
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
# 初始化训练类
max_epochs = 20
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
learning_rate=0.1, evaluate_sample_num_per_epoch=1000)
# 开始训练
trainer.train()附录 :手写数字识别 Demo 项目地址:MnistRecognition: A simple handwritten digit recognition system using the MNIST dataset and a neural network.
参考文献:1 斋藤康毅. 深度学习入门:基于Python的理论与实现M. 陆宇杰, 译. 北京: 人民邮电出版社, 2018.