目录
[1. HTTP](#1. HTTP)
[1.2 HTTP是什么](#1.2 HTTP是什么)
[1.3 理解"应用层协议"](#1.3 理解“应用层协议”)
[1.4 理解 HTTP 协议的工作过程](#1.4 理解 HTTP 协议的工作过程)
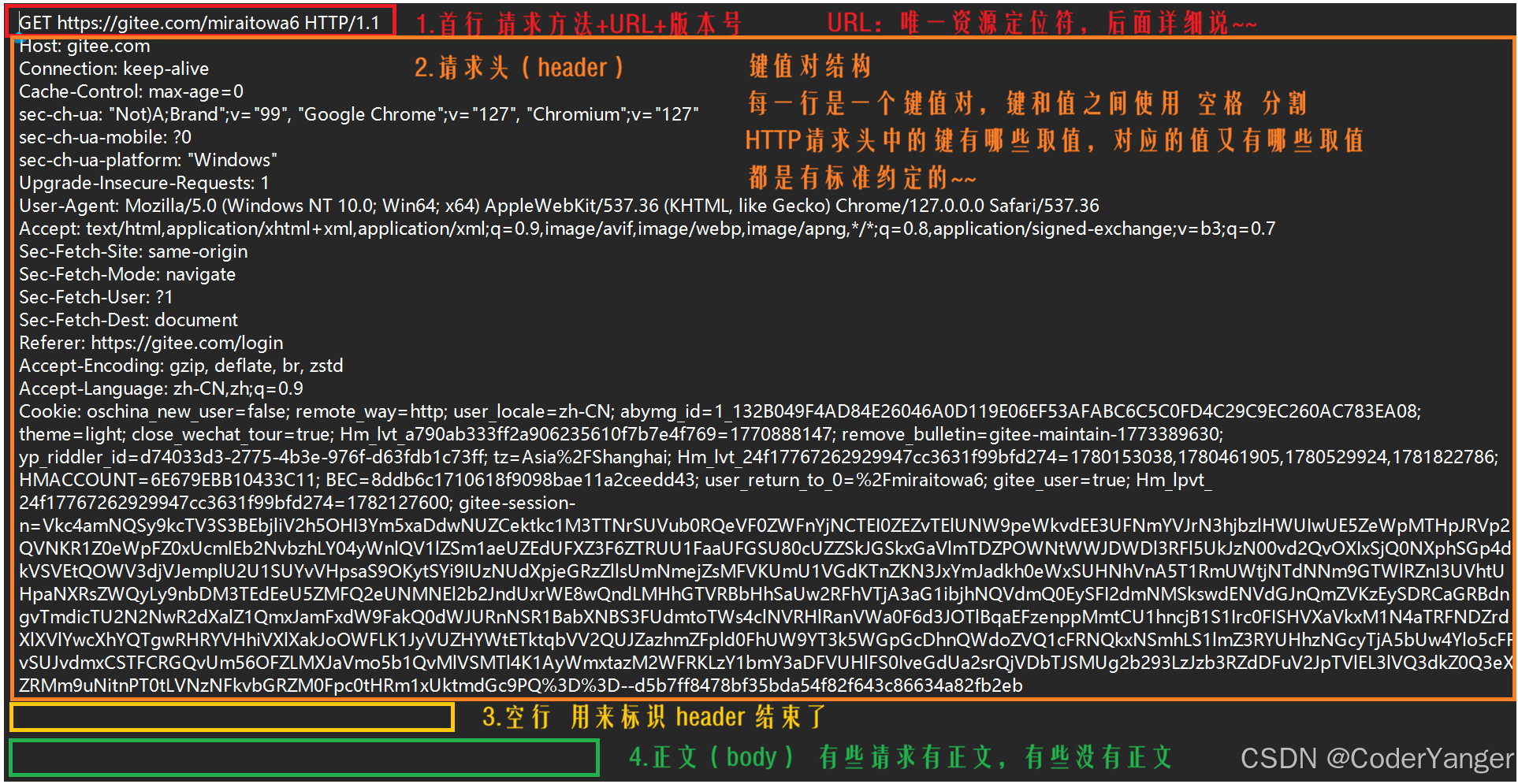
[1.5 HTTP 协议格式](#1.5 HTTP 协议格式)
[1.5.1 抓包工具的使用](#1.5.1 抓包工具的使用)
[Fiddler 的下载:](#Fiddler 的下载:)
方式一:官网下载(由于官网服务器在海外,可能一直转圈圈,加载不出来)
[方式二:命令行下载(适合 Windows 10/11)](#方式二:命令行下载(适合 Windows 10/11))
[简单设置一下,让 Fiddler 支持 https](#简单设置一下,让 Fiddler 支持 https)
[HTTP 协议格式](#HTTP 协议格式)
1. HTTP
1.2 HTTP是什么
HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议
HTTP 诞生于 1991年,目前已经发展为最主流使用的一种应用层协议
闲聊:1991年,是一个神奇的年份,计算机圈子中的 奇迹年~~
这一年诞生了Java、Python、Linux、Qt、Vim、HTTP......
HTTP/1.1 虽然是20年前的东西,但目前仍然是最流行的HTTP版本~~
最新的版本HTTP/3.0也在完善中,但是普及程度不高,因为存在新的机制,正如企业中都不怎么用最新的,因为谁都不想当那个小白鼠~~
所以我们以 1.1 版本展开介绍~~
HTTP:一问一答 模式的协议~~
客户端发一个请求,服务器就返回一个响应,请求和响应一一对应
就像你跟女神聊天:
你吃了嘛?→吃了
你在干啥?→闲着
明天看电影好不好?→不好
女神你今天开心吗?→我去洗澡了
如果你说一句,妹子咔咔回很多句,就很有戏,否则这种形态,就很凉~~刚开始这样还算正常,后面一直这样,就趁早放弃~~
网络通信中也有其他的模型
多问一答
比如上传大文件,把这个大文件拆成多个请求,发给服务器,然后服务器返回一个响应结果
一问多答
比如下载大文件,我传过去一个下载的请求,对方把这一个文件拆成多个部分,分成多个响应返回给我
多问多答
比如远程控制(ToDesk),你的多个操作会生成多个请求,对方就会形成多个画面响应给你
浏览器打开网页的场景 / 手机app 加载数据的场景
就属于典型的一问一答场景~~
使用 HTTP 就非常合适~~
课件内容
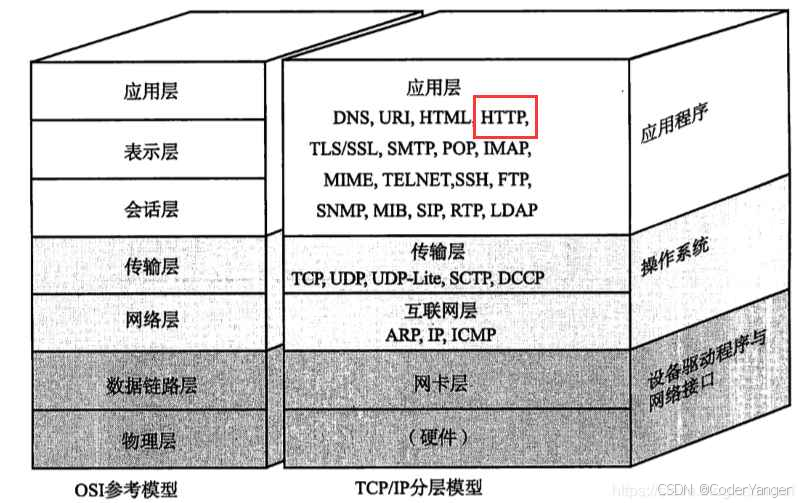
HTTP 往往是基于传输层的 TCP 协议实现的(HTTP1.0,HTTP1.1,HTTP2.0 均为TCP,HTTP3基于 UDP 实现)
目前我们主要使用的还是 HTTP1.1 和 HTTP2.0,当前课堂上讨论的 HTTP 以 1.1 版本为主,我们平时打开一个网站,就是通过 HTTP 协议来传输数据的
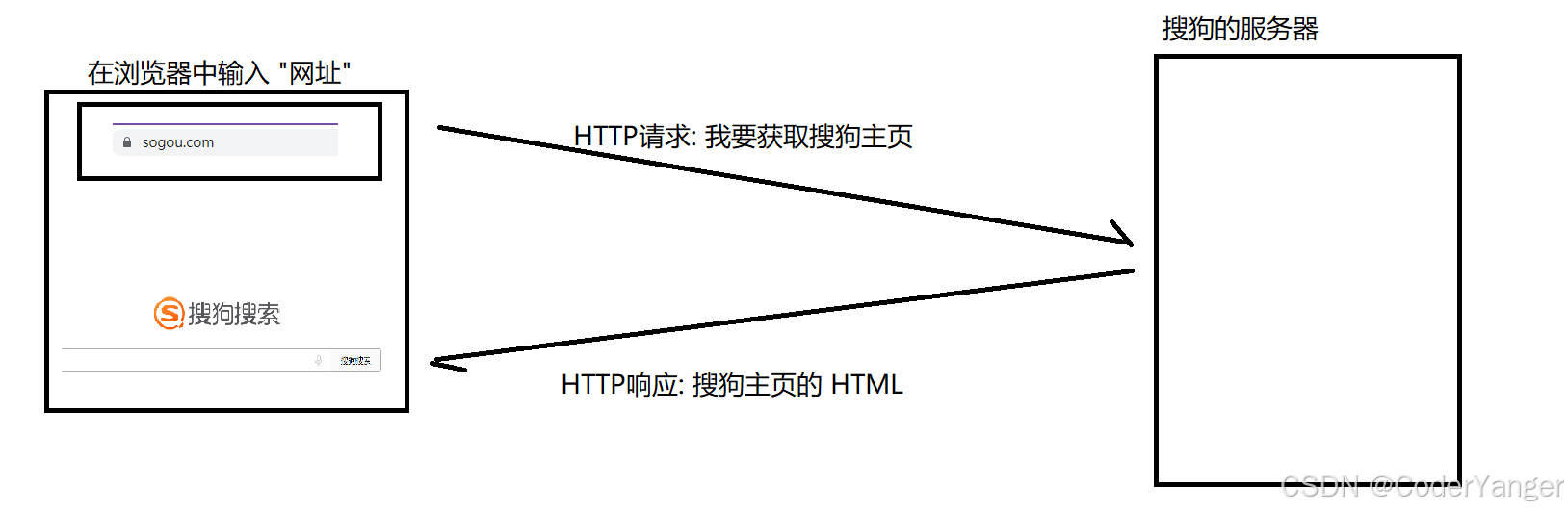
当我们在浏览器中输入一个搜狗搜索的"网址"(URL)时,浏览器就给搜狗的服务器发送了一个 HTTP 请求,搜狗的服务器返回了一个 HTTP 响应
这个响应结果被浏览器解析之后,就展示成我们看到的页面内容(这个过程中浏览器可能会给服务器发送多个 HTTP 请求,服务器会对应返回多个响应,这些响应里就包含了页面 HTML、CSS、JavaScript、图片、字体等信息)
所谓"超文本"的含义,就是传输的内容不仅仅是文本(比如 hrml、css这个就是文本),还可以是一些其他的资源,比如图片、视频、音频等二进制的数据
1.3 理解"应用层协议"
我们已经学过 TCP/IP ,已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程IP+Port
可是,仅仅把数据从A点传送到B点就完了吗?
这就好比,在淘宝上买了一部手机,卖家客户端把手机通过顺丰传送+路径选择送到买家服务器手里就完了吗?
当然不是,买家还要使用这款产品,还要在使用之后,给卖家打分评论
所以,我们把数据从A端传送到B端,TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用,所以我们还需要一层协议,不关心通信细节,关心应用细节!!
这层协议就叫做应用层协议,而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议之一的HTTP就是其中的佼佼者
再回到我们刚刚说的买手机的例子,顺丰相当于 TCP/IP 的功能,那么买回来的手机都附带了说明书产品介绍,使用介绍,注意事项等,而该说明书指导用户该如何使用手机虽然我们都不看,但是父母辈有部分是有看说明书的习惯的,此时的说明书可以理解为应用层协议
1.4 理解 HTTP 协议的工作过程
当我们在浏览器中输入一个"网址",此时浏览器就会给对应的服务器发送一个 HTTP 请求,对方服务器收到这个请求之后,经过计算处理,就会返回一个 HTTP 响应
事实上,当我们访问一个网站的时候,可能涉及不止一次的 HTTP 请求/响应 的交互过程
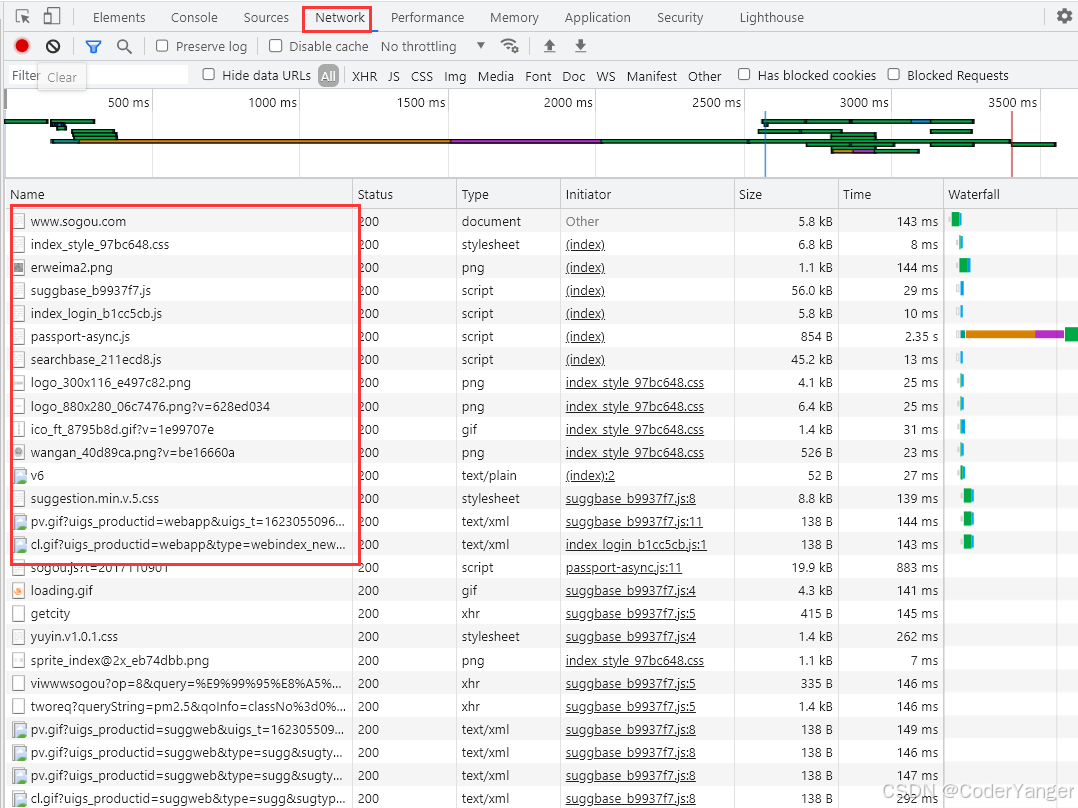
可以通过 chrome 的开发者工具观察到这个详细的过程
通过 F12 打开 chrome 的开发者工具,切换到 Network 标签页,然后刷新页面即可看到如下图效果,每一条记录都是一次 HTTP 请求/响应
注意,当前 搜狗主页 是通过 https 来进行通信的,https 是在 http 基础之上做了一个加密解密的工作,后面再介绍


1.5 HTTP 协议格式
HTTP 是一个文本格式的协议,可以通过 Chrome 开发者工具 或者 Fiddler 抓包,分析 HTTP 请求/响应 的细节
你电脑上所有的网络通信,都会先发给这个抓包程序,抓包程序再把数据转发给服务器
下面我们搭配抓包工具来进行讲解
答疑
Q1:啥是抓包??
抓包就是获取到网络的数据包,把详细的格式都解析出来了
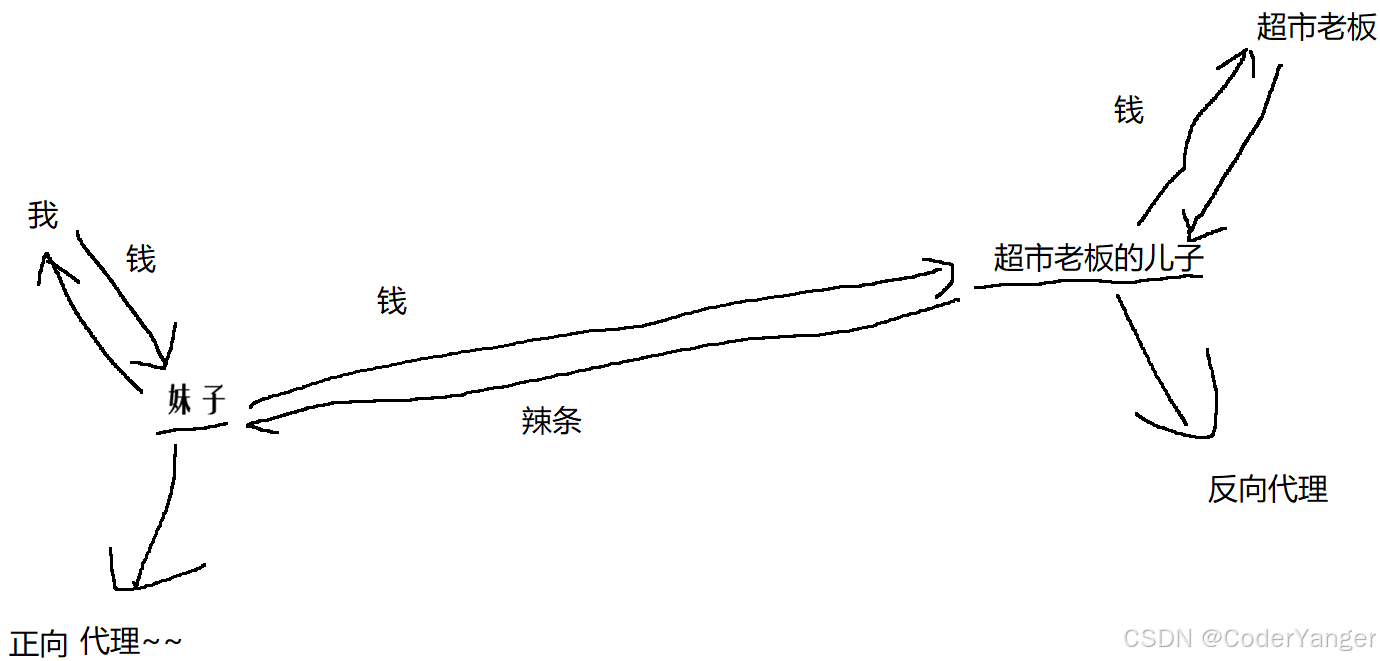
抓包工具,就相当于"代理"
比如,俺想买包辣条,我又懒得动,就让俺妹子去买~~
但是这个代理,也分正向和反向
正向代理:代表客户端干活
反向代理:代表服务器干活
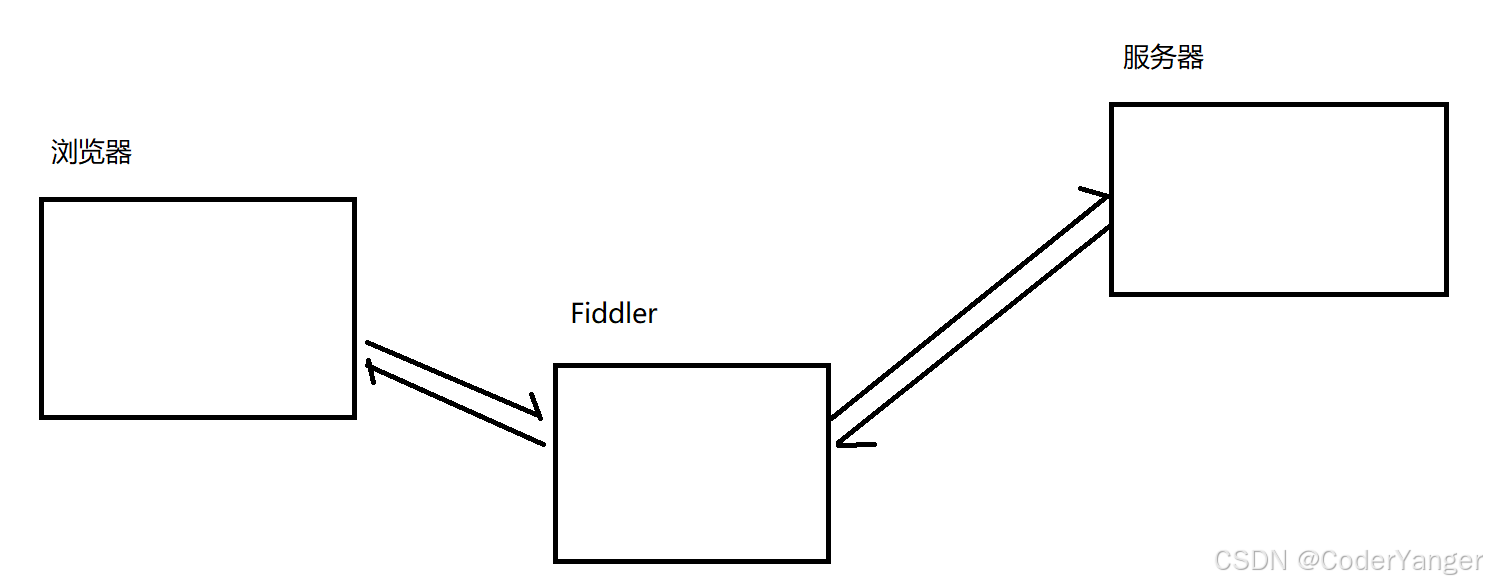
Fidder 相当于一个"代理",当浏览器访问网页的时候,就会把 HTTP 请求先发给 Fiddler,Fiddler 再把请求转发给 服务器,当服务器返回数据时,Fiddler 拿到返回数据,再把数据交给浏览器
因此 Fiddler 对于浏览器和服务器之间交互的数据细节,都是非常清楚的
Q2:这样跨太多数据不会丢失吗??
本身网络传输,就是要经过很多节点转发的,不在乎中间多个一次两次~~
Q3:这个程序运行者,什么是会影响其他软件使用网络??
一般来说是没有影响的~~
但是不排除特殊软件会产生冲突~~
Q4:和梯子那个软件一样?
梯子本质上也是代理,可能就会和抓包工具冲突~~
后续使用抓包的时候,一定要关闭梯子/梯子类的浏览器插件~~
Q5:开梯子CCtalk 自己就断了(不能后台)
基操,基本的反爬机制~~
细思极恐~~
你自己装抓包工具,在你自己的授权的情况,进行抓包~~
是否有可能,你电脑上有些程序在未经你授权的情况下,进行抓包??
你的 路由器上 / 运营商路由器上,是否有可能存在未经授权的抓包情况??
这是极有可能的!!
信息安全,是当前互联网世界,非常大的挑战~~
尤其是大家在外面,尽量不要连公共场合额WiFi~~
千万要谨慎,谁知道这个WiFi里面是谁的形状呢??
答疑
Q1:我的信息没啥价值,他抓呗~~
现在这个阶段,雀食是这样,但是进了公司之后,尤其是你的工作电脑,很可能涉及公司机密~~
Q2:黑客都是天才,大佬~~
也不见得~~大佬研究了很多成熟的工具和程序
使得即使你技术没那么牛逼,通过大佬的工具也能发起一些攻击~~


1.5.1 抓包工具的使用
比如说 wireshark 就是知名的抓包工具~~
能抓很多协议,比如 HTTP、TCP、UDP、IP、以太网数据帧......
但是使用起来门槛比较高,比较麻烦~~
而 fiddler 是专门抓 http 的,功能更简单(也足够用了),使用也更简单,能够覆盖我们工作的绝大部分场景~~
Fiddler 的下载:
方式一:官网下载(由于官网服务器在海外,可能一直转圈圈,加载不出来)
下载地址:Web Debugging Proxy and Troubleshooting Tools | Fiddler
免费版下载地址(填写左边的):Download Fiddler Web Debugging Tool for Free by Telerik
下载完成后一路 next 即可~~
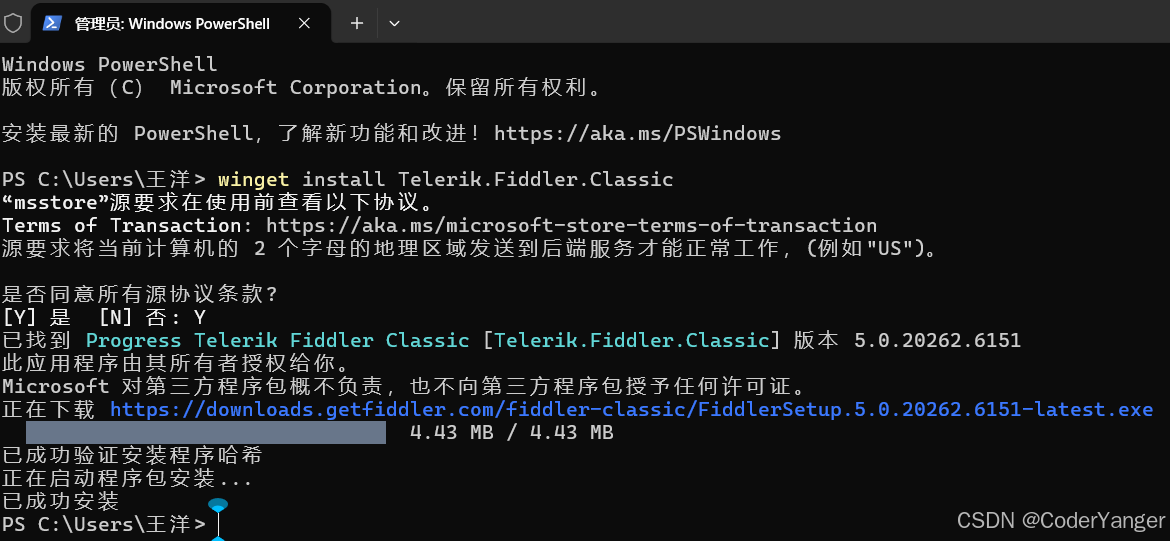
方式二:命令行下载(适合 Windows 10/11)
按下 Win+X,打开 终端(管理员),输入以下命令回车,会自动下载安装官方正版👇
winget install Telerik.Fiddler.Classic方法三:搜狗应用中下载
国内的下载网站,一般不要点~~很容易搞出 p2p 下崽器~~小鸟壁纸~~
但搜狗下载是其中为数不多的一股清流~~
搜狗应用中搜索 fiddler,会找到 Fiddler 的旧版本,Fiddler4👇
安装后可在开始菜单中找到👇
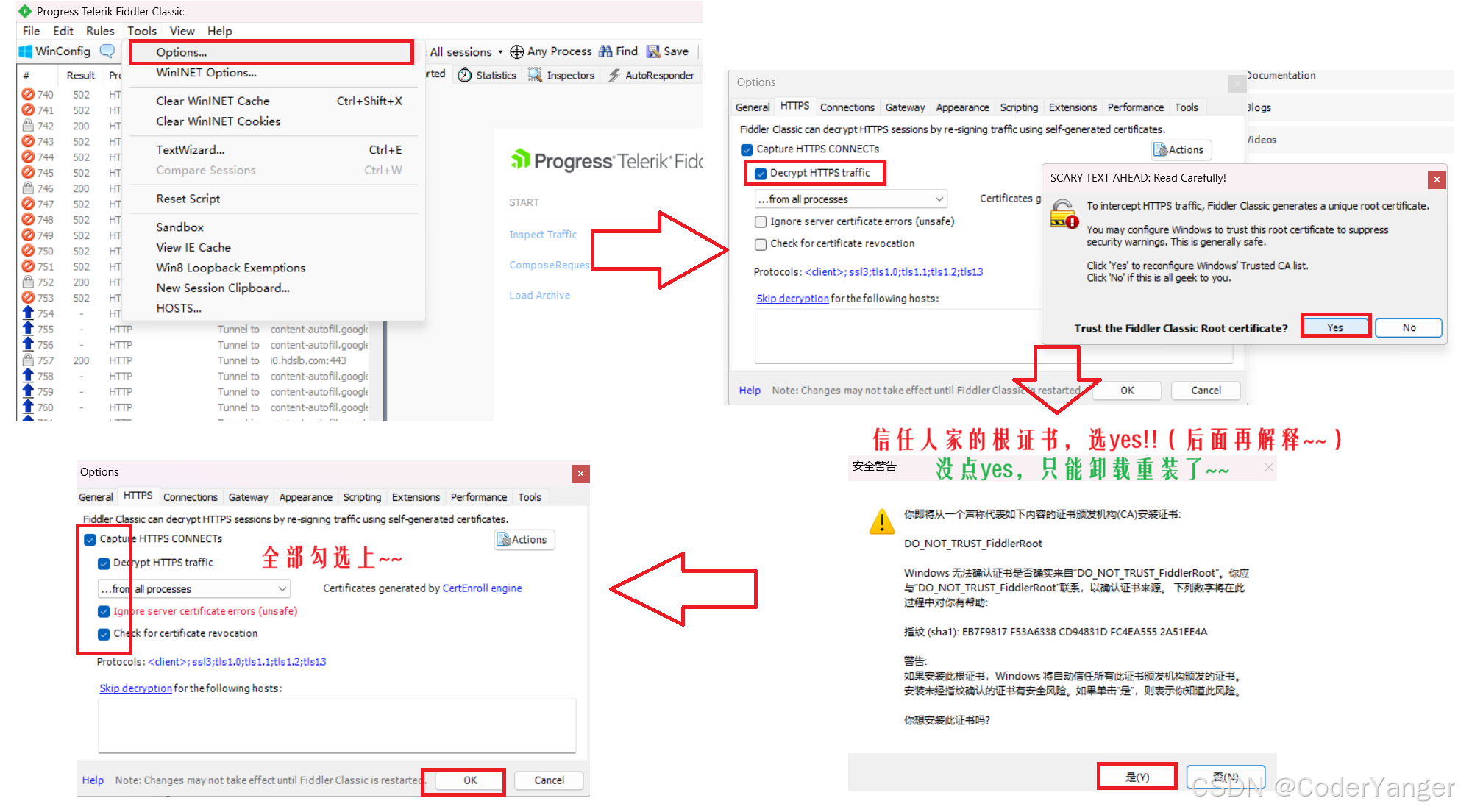
简单设置一下,让 Fiddler 支持 https
当我们打开 Fiddler 并且设置之后,可以看到,就算我们什么都不做,也会显示很多信息,这些信息都是抓包抓到的信息👇
换句话说,电脑上很多程序,都不安分,都在后台悄悄的做一些事情~~
我们可以通过域名知道大概是哪个公司,哪个软件~~
太多看不完,咱就随便选中一个,按 Ctrl+A 全选,再 Delete 清空就好了👇
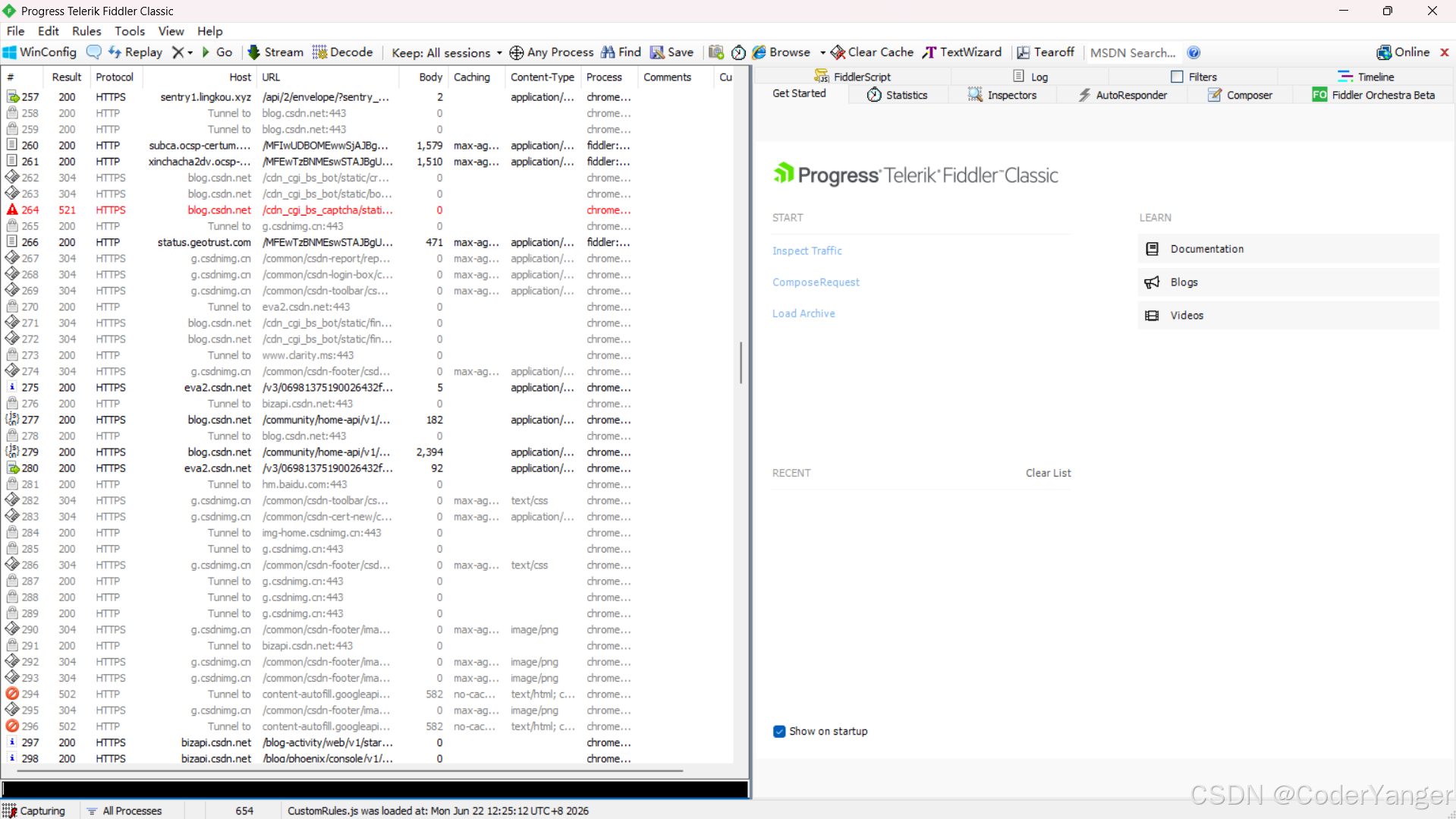
接下来可以通过这个抓包工具抓一些网站的交互过程👇
Fiddler抓包网页演示
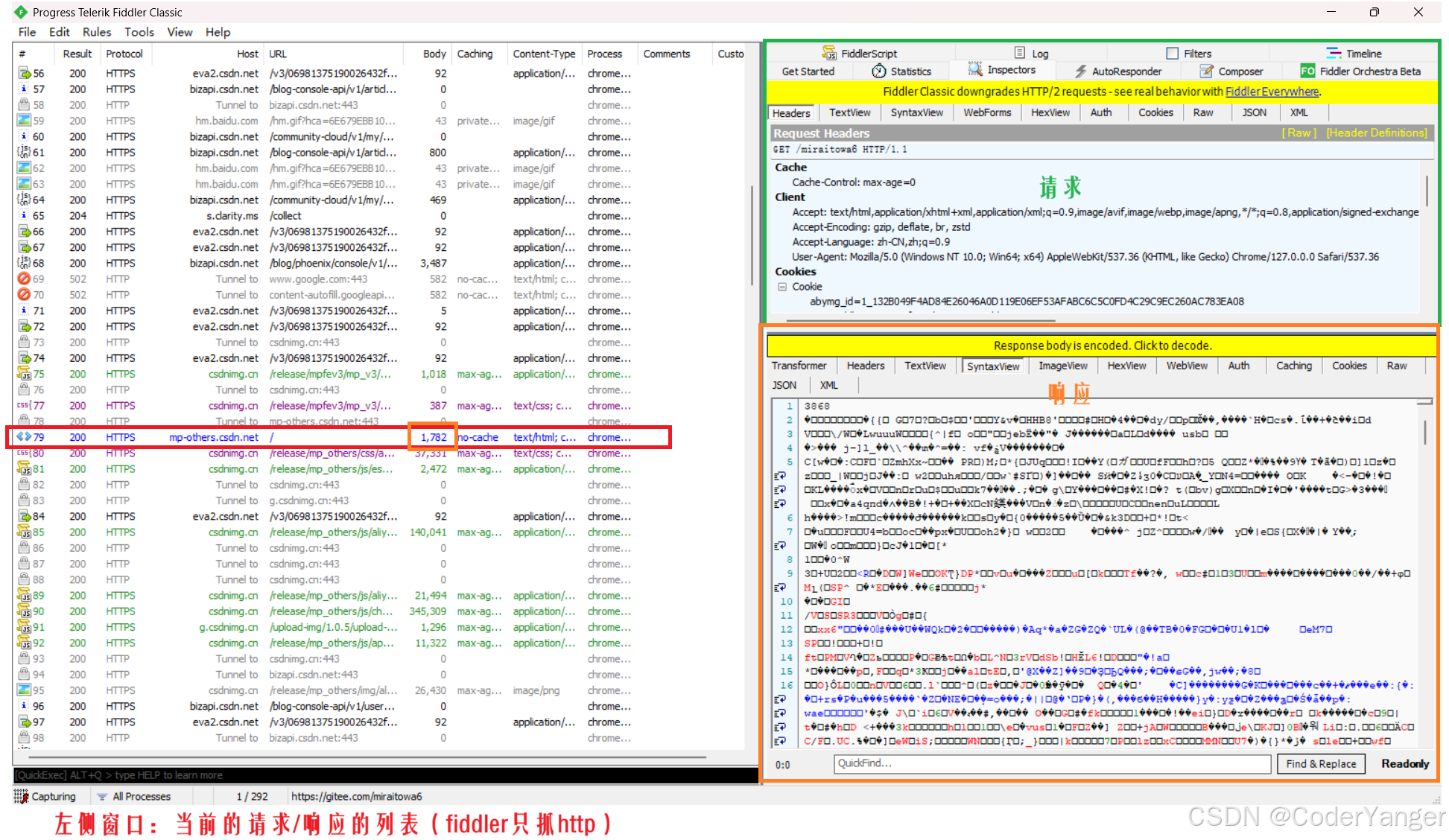
我们先清空一下,找到一个网页,刷新一下,对应的请求响应信息就在Fiddler中显示出来了
关键请求:蓝色的,且数据比较大的,此处是我们演示视频中访问Gitee的请求
红色的:报错了
蓝色的:这个请求得到了一个网页
绿色的:得到了一个 JS
紫色的:得到了一个 CSS
灰色的:这个响应的数据已经被缓存了
由于每个标签页都是不一样的,我们需要找到正确的标签页查看👇
看不清的话还可以自行调整👇
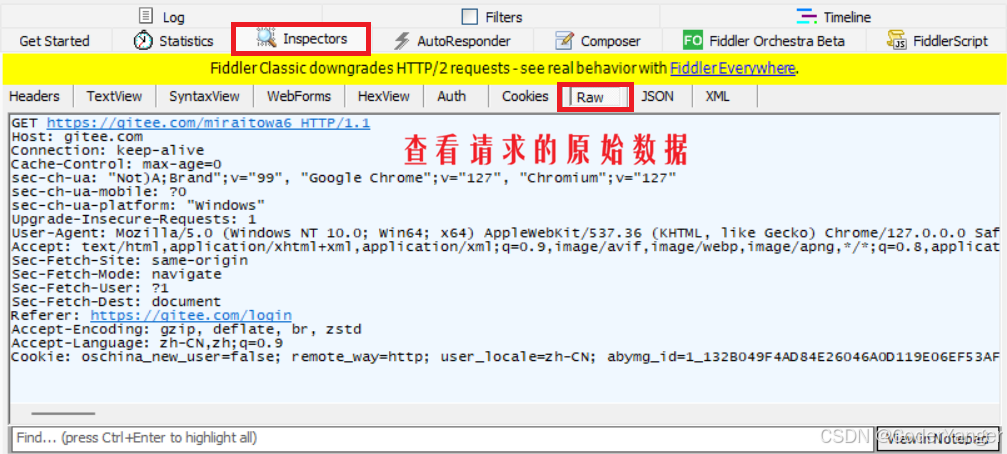
Fiddler查看请求
而我们后续就是在学习这些内容👇
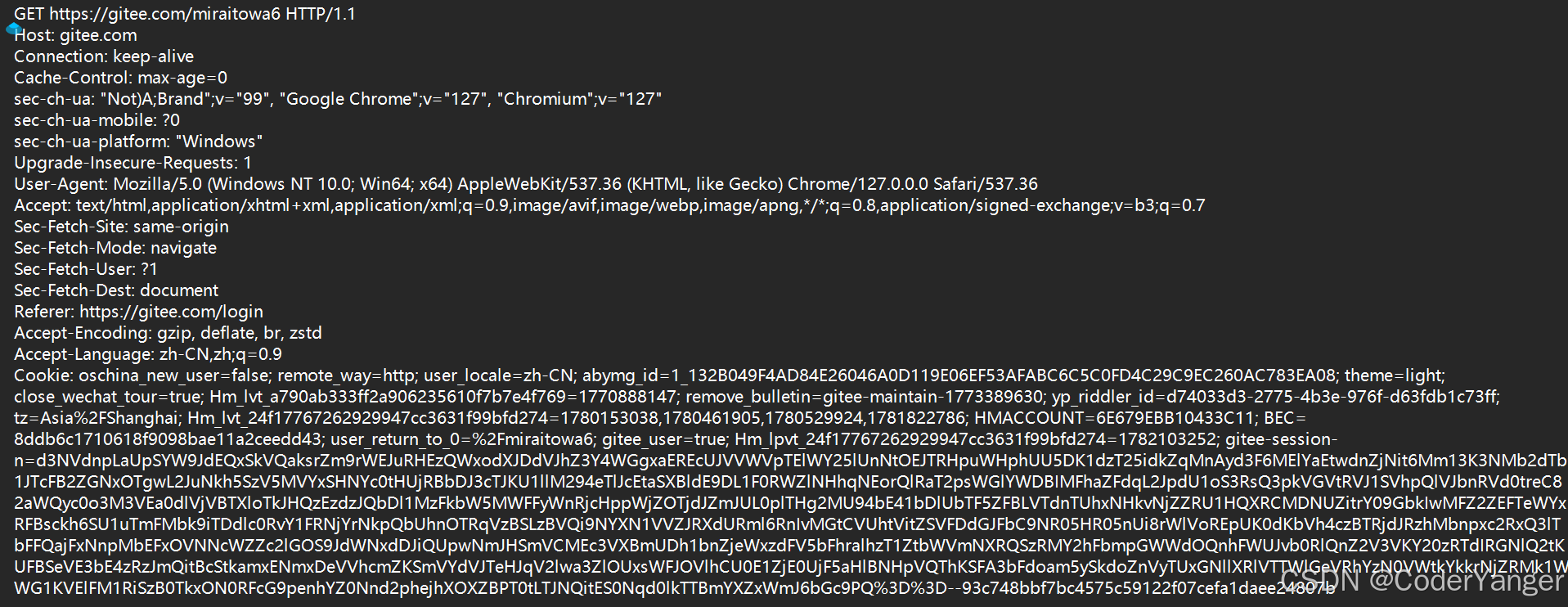
类似的,可以在 Raw 标签页查看响应的原始数据👇
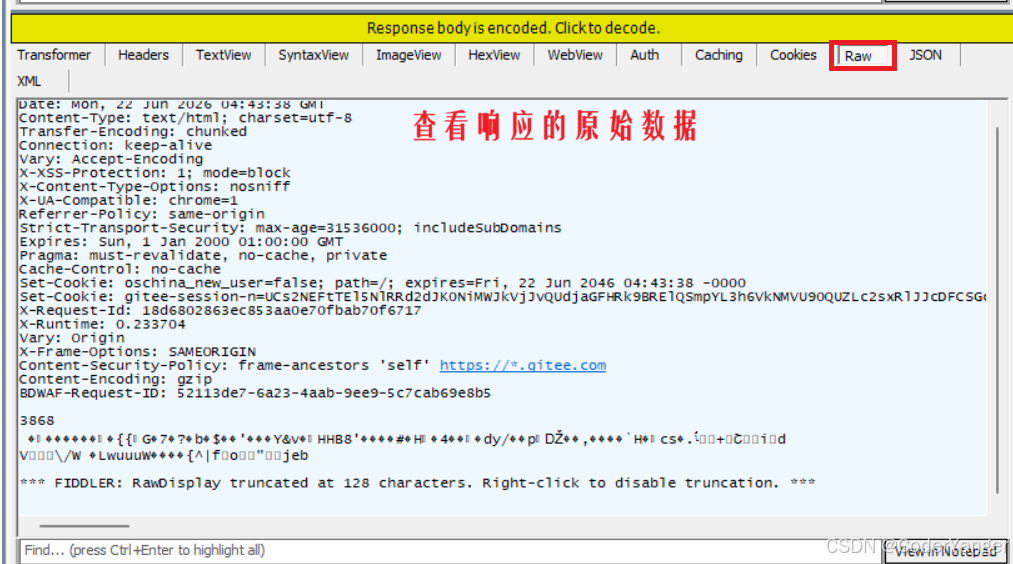
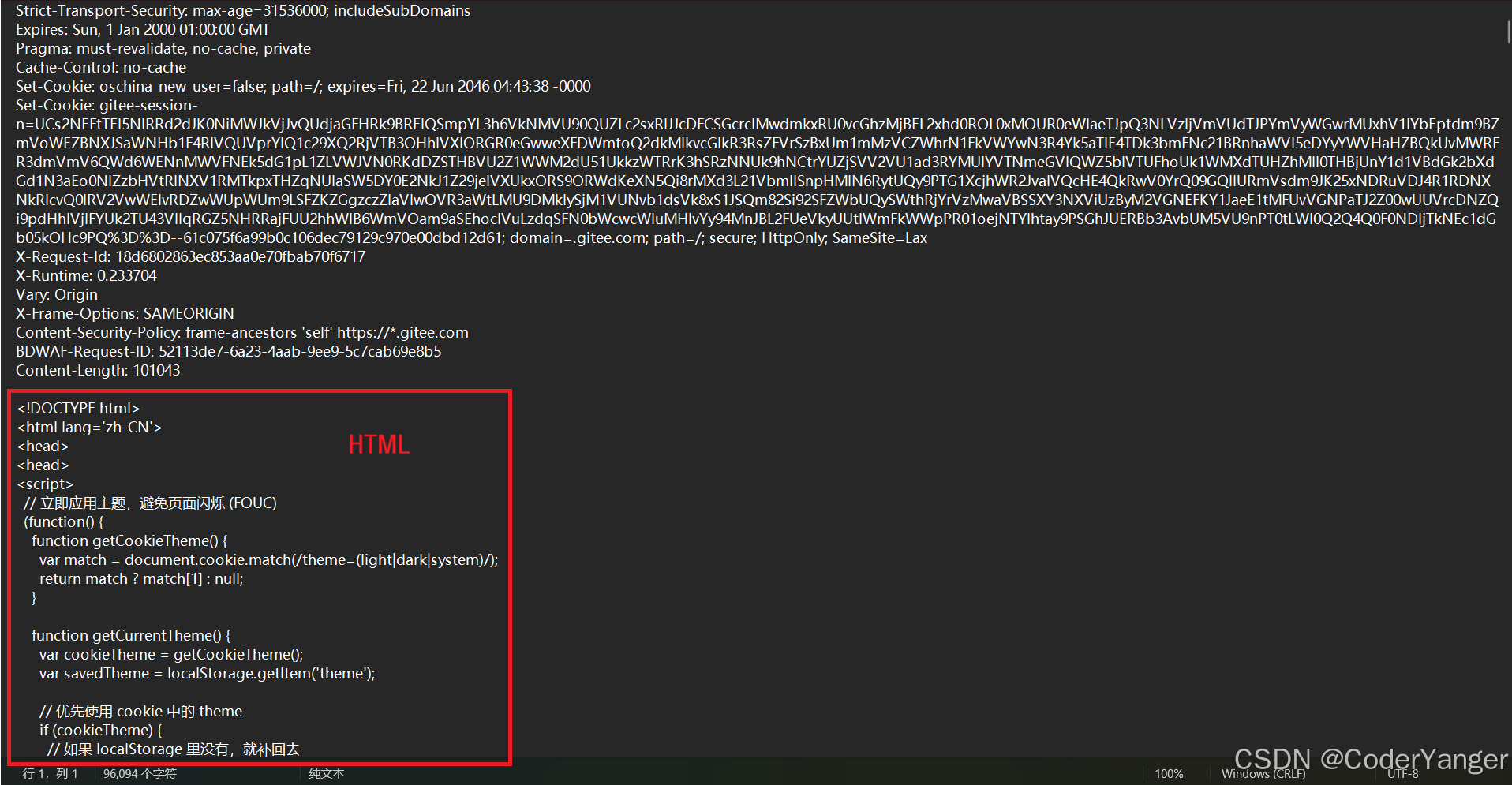
但是我们点进去会发现,里面会存在一些二进制数据的乱码👇
这是因为响应数据经常是压缩后传输的,为啥压缩??为了节省网络带宽~~
那么我们怎样看到解压缩之后的情况呢??点击上面的小黄条👇
我们再点开来看,发现被压缩的内容其实就是 HTML~~
我们通过浏览器打开网页的过程,本质上就是服务器给浏览器(通过HTTP协议)返回一个HTML,浏览器拿到HTML再进行解析,再将HTML转换成界面上的各种效果~~
闲聊:其实通过 Fiddler 可以做到很多事情的~~
爬虫 本质上就是 HTTP 的客户端(自己代码实现的)
自己写代码,伪造出差不多的请求,就可以达成类似的功能效果了~~
不止Python能搞,这只是网上有些卖课的是用Python写,其实只要能操作网络,就能写爬虫,Java当然也能写,用Java构造出HTTP请求就行~~
比如说给你自己的博客点赞、互赞朋友的评论、抢票、抢茅台~~
甚至可以自动判大家的作业~~
而这里最大的问题,就是法律风险~~
很多爬虫程序是非法的,有些爬虫可能把人家网站给爬挂了,这样就妥妥要吃官司的~~
真把人家搞挂了,人家有100种方法抓到你的~~
而且基于 HTTP 这种爬虫方式,目前业界有很多反爬虫的手段了~~
其实,还有另外更高端的爬虫实现方式......(测试课会涉及到~~)
Q1:四六级对于找工作是否有影响??
概率事件,大部分公司对于四六级没要求
少数公司,要求 面试/入职 的时候带着 四六级成绩单
但至少四级尽量考过~~
Q2:有些学校要求,四级达到"校线"才能发毕业证
这个需要和导员确认好,自己学校的情况~~
因为毕业证特别重要,各个公司必看,没有毕业证,就算你秋招找的再好,也入职不了
Q3:确定想考,怎样考过??
一定不要裸考,刷真题:过去10年左右的真题~~
Q4:怎么找实习??在boss直聘发过,HR不理人~
1)各个公司的官网/公众号
2)主流招聘网站(牛客/boss......)(不是你回一句这个对话就结束了,注意沟通技巧~~)
3)比特的内推=>关注比特的知识星球,不定期会有内推机会
至于投了简历有没有回应:10%~20%
概率多少取决于你的学校学历
如果你是 985/211 这种,会>20%,但不会超过50%
如果是不知名,尤其是学校带有"学院"俩字,做好低于10%的准备~~
这就意味着我们要多投海投,投100份简历,总会有10~20个回应~~
这个概率和行情关系不大,前些年行情好的时候,回应概率也就是20~30左右~~
Q5:咱们找实习什么时候??
实习的时间:大三上学期+大三下学期=>实习到秋招(大四上学期)
找实习的时间窗口:大三上学期9月到大三下学期4月
Q6:那就是暑假投,开学去实习~~
也不见得,开始投简历,到你入职,需要2~3个月的时间周期
9月开始投,可能11~12月甚至年后才能入职~~
也是正因为没那么容易,所以含金量才高~~
所以你有实习和没实习,在秋招种的情况是截然不同的~~
Q7:大四组织集训强制我们参加
学校的生产实习 != 咱们说的实习,没有任何的关联关系~~
Q8:怎么逃课啊啊啊啊学校管很严~~
你先拿到实习offer再说~~
你拿到 offer 这个事情可能比从学校溜走,要难很多~~
就算你拿到 offer,学校把你盯紧了你去不了,前面投简历面试的过程,已经是质变了~~
在这个过程中,你的心态经过了充分历练~~
其实决定工作找到咋样,技术只是次要的,更关键的是你的心态~~
实际上大多数同学根本就不敢投简历,太怂了~~
要么就是好不容易简历投出去了,但是被面试官虐了几下就emo了,所以说心态还是很重要~~
Q9:面试得全国跑啊,车费都拉满了
这个不用太担心,大部分都是线上面试~~
Q10:我们这里还有学长伪造毕业证,这得蹲号子吧??
这已经不是违法行为了,这是妥妥的犯罪行为,伪造国家公文印章罪~~一定会进去的~~
Q11:想只在假期的实习~~
这种你就别想了,还不如不实习,去复习复习学过的基础知识~~
假期实习==0~~
实习的意义:
1)能转正留用,俗话说得好"不以结婚为目的的恋爱都是耍流氓~~"
只要实习时间足够长(半年以上),转正概率都是非常高的(90%+)
秋招有保底,秋招有保底和秋招没保底的打法是截然不同的
而你只是假期去实习,不可能有转正
2)提升技术能力
像一些商业项目,复杂程度,是远远超出咱们现有接触的所有代码的~~
需要 2~3 个月才能上手
前 2~3 个月主要就是在学习,没法给公司带来任何价值的(说白了就是打杂,打杂过程提升很小的~~)
上手之后,真正能承担业务需求了,才开始真正进入了"职场人的节奏"
这个时候你还不知道项目是啥呢,下一次去面试的时候,你的实习经历都没法给面试官讲清楚~~
这时候你简历上写有个实习经历,面试官只会觉得你是在吹~~反而带来负面影响~~
Q12:鑫哥说过,大部分时间都是CRUD~~
代码逻辑是 CRUD,但我们这里说的是公司的业务,你为什么要写这个CRUD,你通过这一系列CRUD能解决什么问题,为什么你解决这些问题就能满足客户的价值,人家愿意给你付钱~~这一系列来龙去脉公司的业务,以及说我们围绕这些业务怎么去设置架构,这一系列东西是怎么从无到有搞出来的,这一摊子事儿没几个月时间是消化不了的,你要是就指望假期实习两三个月,趁早打消这个念头,没啥卵用~~
Q13:为啥 Host 没被 DNS解析成 IP 地址??
DNS 也是一个应用层协议,它负责进行域名解析,不是 HTTP 干的活~~

阶段性小结
网络原理~
HTTP协议~
非常重要的协议,虽然我们自己也能设计协议,但是直接使用大佬搞好的协议,也是蛮香的嘛~~
而且HTTP协议自身也有很强的扩展性,我们可以基于这些再去做一些扩充来满足不同的业务需求~~
因此非常广泛的使用在 Web开发 / app开发中~~(日常工作中几乎天天都在用~~)
协议格式~~
借助抓包工具 Fiddler 查看~~
HTTP 协议格式
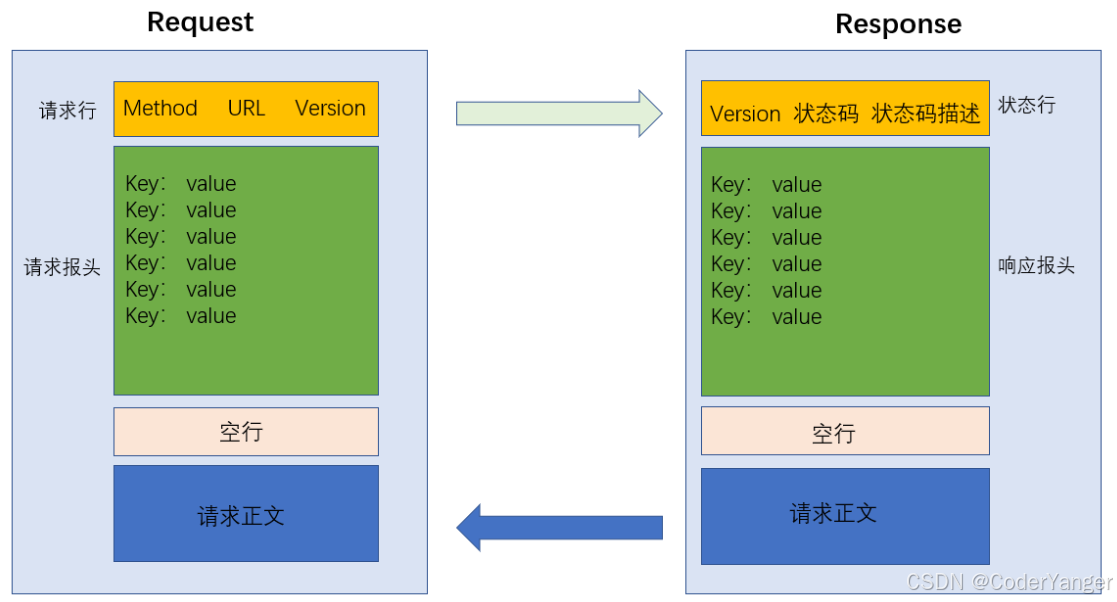
请求:
接下来我们用 Fiddler 抓一个带请求正文的,登录Gitee👇
展示带请求正文的
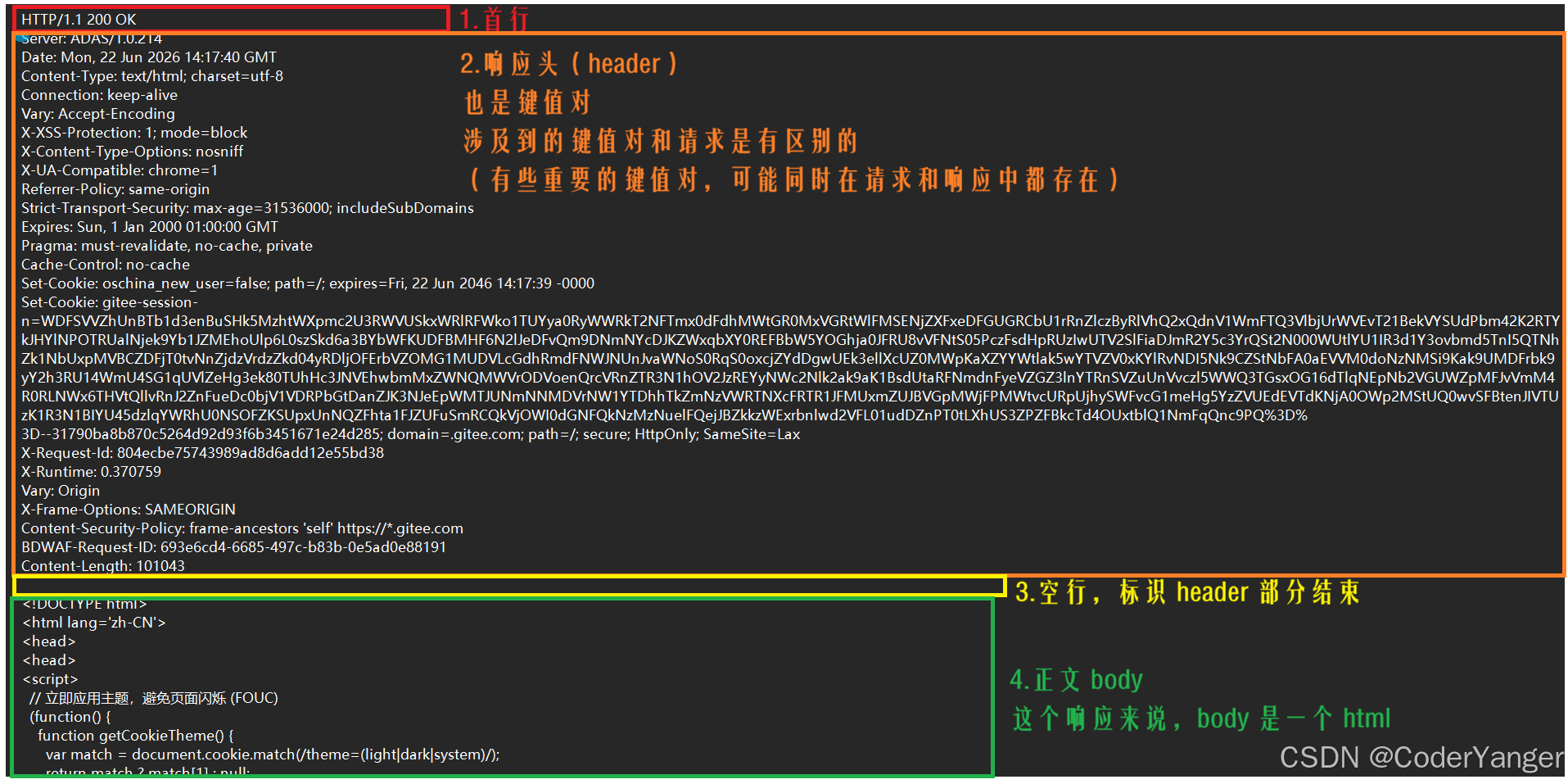
响应:
那为什么 HTTP 报文中要存在"空行"??
因为 HTTP 协议并没有规定报头部分的键值对有多少个,空行就相当于是"报头的结束标记",或者是"报头和正文之间的分隔符"
HTTP 在传输层依赖 TCP 协议,TCP 是面向字节流的,如果没有这个空行,就会出现"粘包问题"
HTTP 协议是一个"文本格式的协议"
请求:1.首行,2.请求头,3.空行,4.正文
响应:1.首行,2.响应头,3.空行,4.正文
虽然面试的时候一般不会考你请求格式响应格式,但是在我们以后 开发/调试 相关程序的时候,这些知识都是非常重要、常用的~~