1. 为什么网球是人形机器人最难的运动考题
在所有运动场景中,网球对人形机器人的挑战几乎是全方位的。来球时速可达数十公里,从球离开对手球拍到落地弹起再到机器人必须完成击球,留给决策和执行的时间窗口极其狭窄。与此同时,网球并非站桩式运动------运动员需要在半场范围内高速移动,急停变向,然后在毫秒级的球拍-球接触时间内完成精准击球。这意味着机器人必须同时具备三种能力:快速感知与决策、全身协调运动、以及高精度末端控制。
对比已有的机器人运动研究,乒乓球机器人(如 Google DeepMind 的工作)通常只需要上半身运动,活动范围有限;羽毛球机器人的场地虽大但球速相对可控;足球机器人则不需要手持工具的精细操作。网球几乎把这些挑战全部叠加在了一起:大范围跑动(半场覆盖)、高速反应(来球速度 15-30 m/s)、全身协调(上下半身联动)、以及毫秒级的击球精度。这使得网球成为检验人形机器人运动智能的一块试金石。
LATENT 项目正是在这一背景下诞生的。它由银河通用机器人(Galbot)与清华大学联合提出,首次在人形机器人上实现了高动态网球对打------机器人不仅能击球,还能在真实球场上与人类选手完成多回合连续对拉。项目主页:https://zzk273.github.io/LATENT/,开源代码:https://github.com/GalaxyGeneralRobotics/LATENT
2. 核心问题:完美数据不可得,不完美数据能否用
传统的机器人运动学习有两条主流路径。第一条是遥操作模仿学习:人类操作员通过遥操作设备控制机器人完成目标动作,机器人记录并学习这些动作。但网球的高动态特性使得遥操作几乎不可行------没有人能通过遥操作让机器人以 6 m/s 的速度冲刺并精准挥拍。第二条是动作捕捉模仿学习:用高精度动捕系统记录人类运动员的完整比赛动作,然后让机器人模仿。但要完整捕捉一场网球比赛的全部动作,需要覆盖整个半场(约 11m x 6m)的大范围动捕系统,同时还要精确记录运动员击球时的手腕微动作,这在工程上极其昂贵且几乎不可实现。
LATENT 的核心洞察在于:我们不需要完美的数据。研究团队邀请了五名业余网球选手,在一个仅 3m x 5m 的小型光学动捕空间内,分别录制了正手击球、反手击球、横向移步、交叉步等基础动作片段,总计约五小时。这些数据有两个显著的"不完美"之处:
- 不精确(Imprecise):由于动捕系统的局限和人-机器人之间的体型差异(cross-embodiment gap),击球时的手腕动作记录存在较大误差。
- 不完整(Incomplete):这些只是孤立的动作片段,不包含任何关于"如何在比赛中组合使用这些动作"的信息。
但团队认为,尽管不完美,这些数据仍然提供了关于人类基本运动技能的先验知识------人类跑步的步态是什么样的、挥拍的大致轨迹如何、身体协调的基本模式是什么。只要能在此基础上进行修正和组合,就有可能让机器人学会超越原始数据的运动技能。
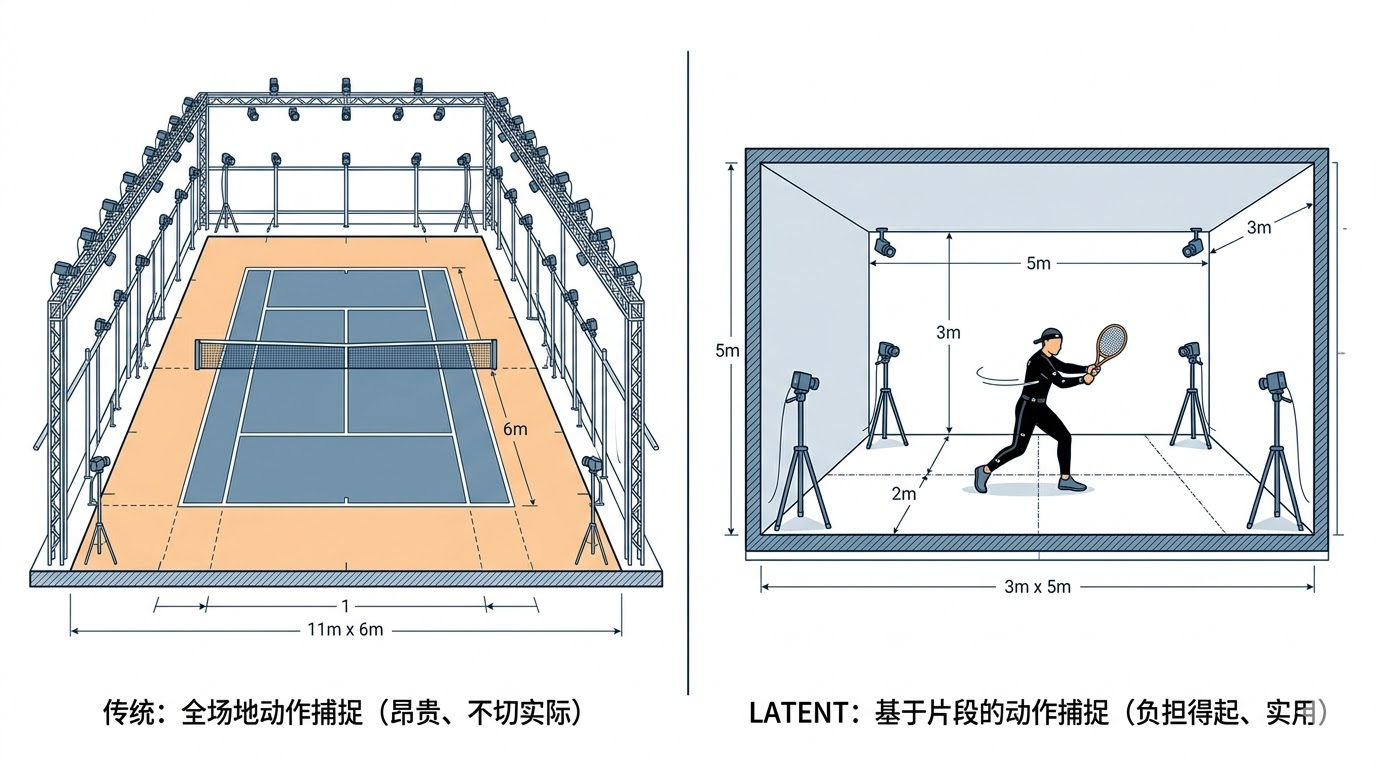
图1:传统全场动捕(左)与 LATENT 碎片化动作采集(右)的对比。后者仅需 3m x 5m 的小型空间,成本大幅降低。
3. 技术架构:三阶段训练流水线
LATENT 的技术方案分为三个阶段,每个阶段解决一个核心问题。整个系统基于 MuJoCo 物理仿真器和 JAX 框架构建,使用 PPO(Proximal Policy Optimization)作为强化学习算法,在 8 块 GPU 上并行训练。
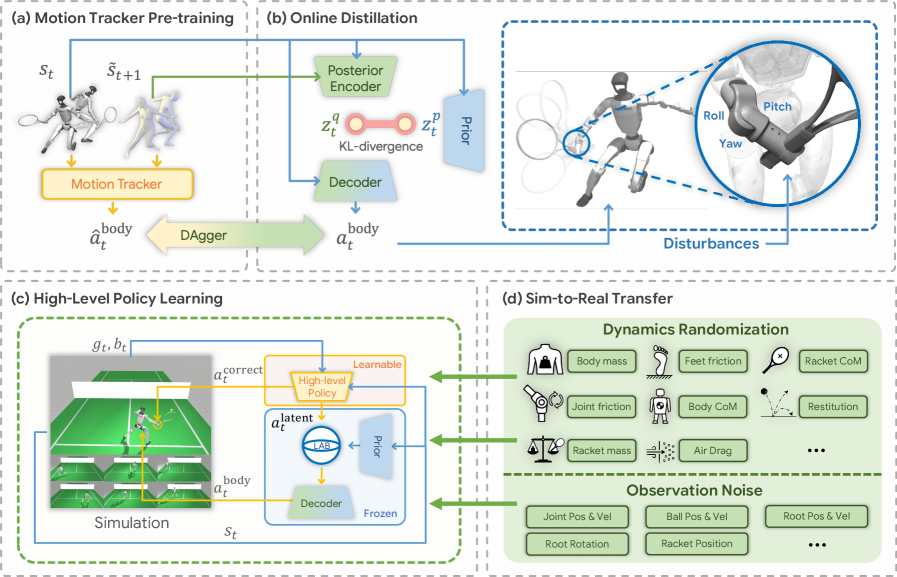
图:LATENT 三阶段训练流水线概念图。从动作追踪器预训练,到隐空间构建,再到高层策略学习。
3.1 阶段一:动作追踪器预训练(Motion Tracker Pre-training)
第一步是把采集到的不完美人类动作数据转化为机器人可执行的基础技能。研究团队训练了一个动作追踪器(Motion Tracker),它本质上是一个强化学习策略,输入机器人当前状态和目标动作,输出关节控制指令。
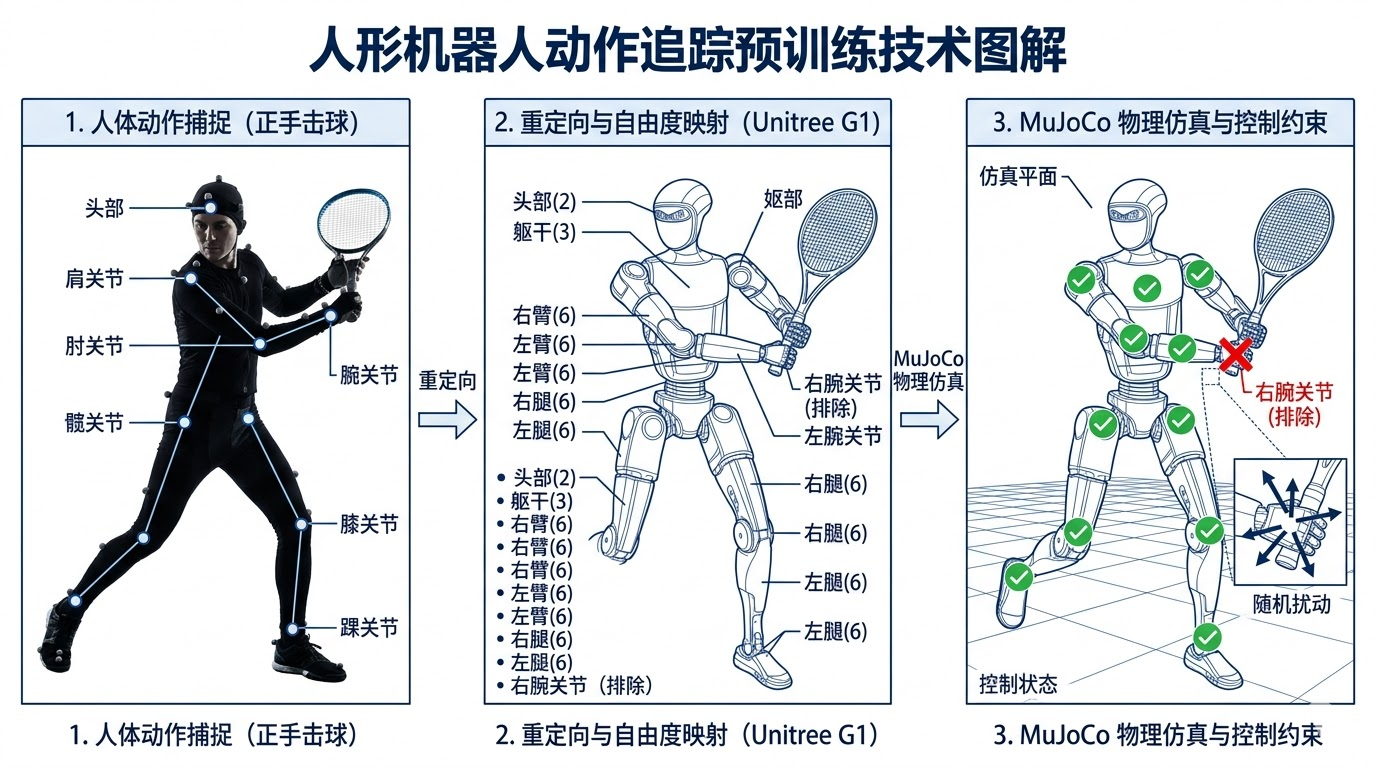
图2:阶段一流程。人类动作经过重定向映射到 G1 机器人,追踪器学习模仿 26 个关节的运动(右手腕 3 个关节被排除并施加随机扰动)。
从开源代码中可以看到,追踪器的核心实现位于 g1_env_tracking_tennis.py。机器人模型是宇树 G1,具有 29 个自由度(定义于 g1_tracking_constants_tennis.py)。追踪器控制其中 26 个关节(排除了右手腕的 3 个关节),并通过 PD 控制器将策略输出转化为关节力矩:
python
# 来源:latent_mj/envs/g1_tracking/train/g1_env_tracking_tennis.py
# 动作空间定义:策略输出是相对于参考动作的偏差
active_motor_targets = traj_data.qpos[7:][self.active_actuator_ids] + action * self._config.action_scale
motor_targets = self._default_qpos.copy()
motor_targets = motor_targets.at[self.active_actuator_ids].set(active_motor_targets)
# 对排除的右手腕关节施加随机 PD 目标(关键设计)
motor_targets = jax.lax.cond(
excluded_cfg.enable_random_targets & (len(self._excluded_actuator_ids) > 0),
lambda _: motor_targets.at[self._excluded_actuator_ids].set(excluded_targets),
lambda _: motor_targets,
operand=None
)PD 控制器的实现使用 jax.lax.scan 进行高效的多子步仿真:
python
# 来源:latent_mj/envs/g1_tracking/train/g1_env_tracking_tennis.py
def torque_step(rng, model, data, qpos_des, kps, kds, torque_limit, n_substeps=1):
def single_step(carry, _):
rng, data, _ = carry
# PD 控制:位置误差 × Kp + 速度误差 × Kd
pos_err = qpos_des - data.qpos[7:]
vel_err = -data.qvel[6:]
torque = kps * pos_err + kds * vel_err
torque = jp.clip(torque, -torque_limit, torque_limit)
data = data.replace(ctrl=torque)
data = mjx.step(model, data)
return (rng, data, torque), None
initial_torque = jp.zeros_like(torque_limit)
(final_rng, final_data, final_torque), _ = jax.lax.scan(
single_step, (rng, data, initial_torque), (), n_substeps
)
return final_rng, final_data, final_torque这里有一个关键设计:训练时故意排除右手腕的控制信号,并对右手腕关节施加随机扰动。这样做的目的是让追踪器学会在手腕动作不确定的情况下仍然保持身体其他部分的稳定运动。这为后续高层策略对手腕动作的修正留出了空间。
追踪器的奖励函数是一组加权的追踪误差项,使用指数核函数 exp(-error/sigma) 来衡量各个身体部位的位置、旋转、速度等与参考动作的匹配程度。以下是奖励计算的核心代码:
python
# 来源:latent_mj/envs/g1_tracking/train/g1_env_tracking_tennis.py
def _get_reward(self, data, traj_data, action, motor_targets, torque, info):
# 计算各身体部位与参考动作的差异
dif_rigid_body_pos = gmth.calculate_dif_rigid_body_pos_local(data, traj_data)
dif_rigid_body_rot = gmth.calculate_dif_rigid_body_rot_local(data, traj_data)
dif_joint_pos = traj_data.qpos[7:] - data.qpos[7:]
reward_dict = {
# 追踪奖励(指数核函数)
"rigid_body_pos_tracking_upper": self._reward_rigid_body_pos_tracking_upper(dif_rigid_body_pos),
"rigid_body_pos_tracking_lower": self._reward_rigid_body_pos_tracking_lower(dif_rigid_body_pos),
"feet_pos_tracking": self._reward_feet_pos_tracking(dif_rigid_body_pos), # 权重最高: 2.1
"joint_pos_tracking": self._reward_joint_pos_tracking(dif_joint_pos),
# 惩罚项
"penalty_torque": self._reward_penalty_torque(torque),
"penalty_action_rate": self._reward_penalty_action_rate(motor_targets, info["last_motor_targets"]),
"termination": self._reward_termination(termination),
# ... 共 20+ 项
}
return reward_dict
# 指数核函数示例:脚部位置追踪
def _reward_feet_pos_tracking(self, dif_rigid_body_pos):
feet_pos_diff = dif_rigid_body_pos[self.feet_ids, :]
feet_pos_dist = jp.sum(jp.abs(feet_pos_diff), axis=(-2, -1))
return jp.exp(-feet_pos_dist / self._config.reward_config.auxiliary.feet_pos_sigma)其中脚部位置追踪的权重最高(2.1),因为步伐的准确性对整体运动质量至关重要。
3.2 阶段二:可修正隐空间构建(Correctable Latent Action Space)
追踪器学会了模仿各种基础动作后,下一步是将这些分散的技能压缩到一个结构化的隐空间(Latent Space)中。这一步使用了在线蒸馏(Online Distillation)方法,具体采用 DAgger 算法配合变分信息瓶颈(Variational Information Bottleneck)。
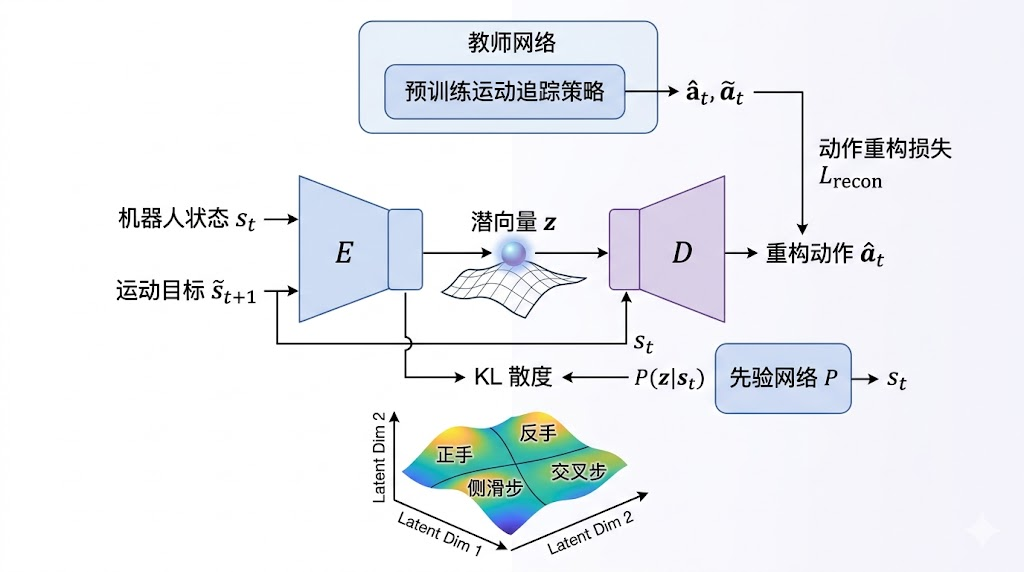
图3:阶段二流程。通过在线蒸馏将追踪器的技能压缩到隐空间中,编码器-解码器框架配合可学习的条件先验网络。
整个过程可以理解为一个编码器-解码器框架:
- 编码器 E ( z t q ∣ s t , s ~ t + 1 ) = N ( z t q ; μ e ( s t , s ~ t + 1 ) , σ e ( s t , s ~ t + 1 ) ) \mathcal{E}(z_t^q | s_t, \tilde{s}{t+1}) = \mathcal{N}(z_t^q; \mu^e(s_t, \tilde{s}{t+1}), \sigma^e(s_t, \tilde{s}_{t+1})) E(ztq∣st,s~t+1)=N(ztq;μe(st,s~t+1),σe(st,s~t+1)):将当前状态和目标动作编码为隐空间向量 z z z
- 解码器 D ( a ^ t body ∣ s t , z t q ) \mathcal{D}(\hat{a}_t^{\text{body}} | s_t, z_t^q) D(a^tbody∣st,ztq):从隐空间向量解码出关节动作
- 先验网络 P ( z t p ∣ s t ) = N ( z t p ; μ p ( s t ) , σ p ( s t ) ) \mathcal{P}(z_t^p | s_t) = \mathcal{N}(z_t^p; \mu^p(s_t), \sigma^p(s_t)) P(ztp∣st)=N(ztp;μp(st),σp(st)):学习一个依赖状态的先验分布
训练目标由两部分组成:
L = λ 1 L action + λ 2 L KL \mathcal{L} = \lambda_1 \mathcal{L}{\text{action}} + \lambda_2 \mathcal{L}{\text{KL}} L=λ1Laction+λ2LKL
其中:
L action = E ( s t , a ^ t body ) ∼ D agg ∥ a \^ t body − a t body ∥ 2 \mathcal{L}{\text{action}} = \mathbb{E}{(s_t, \hat{a}t^{\text{body}}) \sim \mathcal{D}{\text{agg}}} \left \\\| \\hat{a}_t\^{\\text{body}} - a_t\^{\\text{body}} \\\|\^2 \\right Laction=E(st,a^tbody)∼Dagg∥a\^tbody−atbody∥2
L KL = D KL ( E ( z t q ∣ s t , s ~ t + 1 ) ∥ P ( z t p ∣ s t ) ) \mathcal{L}{\text{KL}} = D{\text{KL}} \left( \mathcal{E}(z_t^q | s_t, \tilde{s}_{t+1}) \| \mathcal{P}(z_t^p | s_t) \right) LKL=DKL(E(ztq∣st,s~t+1)∥P(ztp∣st))
L action \mathcal{L}{\text{action}} Laction 是基于 DAgger 在线蒸馏的动作重建损失, L KL \mathcal{L}{\text{KL}} LKL 则约束编码后验分布接近可学习的条件先验分布。
这里的先验网络 P \mathcal{P} P 不是固定的标准高斯分布,而是一个可学习的条件先验------它根据机器人当前状态输出不同的分布参数。这很重要,因为机器人在横向移步时和挥拍击球时的合理动作分布是完全不同的。
同样,在蒸馏过程中也保持了对右手腕关节的随机扰动,确保隐空间对手腕修正具有鲁棒性。
虽然 DAgger 蒸馏的完整代码尚未开源(在项目 TODO 列表中),但根据论文描述,其训练流程的核心逻辑如下:
值得注意的是, a ^ t body \hat{a}_t^{\text{body}} a^tbody 和 a t body a_t^{\text{body}} atbody 都不包含右手腕的控制信号------蒸馏过程中同样保持对右手腕的随机扰动,使得隐空间天然具备对手腕修正的鲁棒性。
3.3 阶段三:高层策略学习(High-Level Policy Learning)
有了隐空间之后,最后一步是训练一个高层规划器(High-Level Planner),它在隐空间中采样和组合动作,完成网球回击任务。
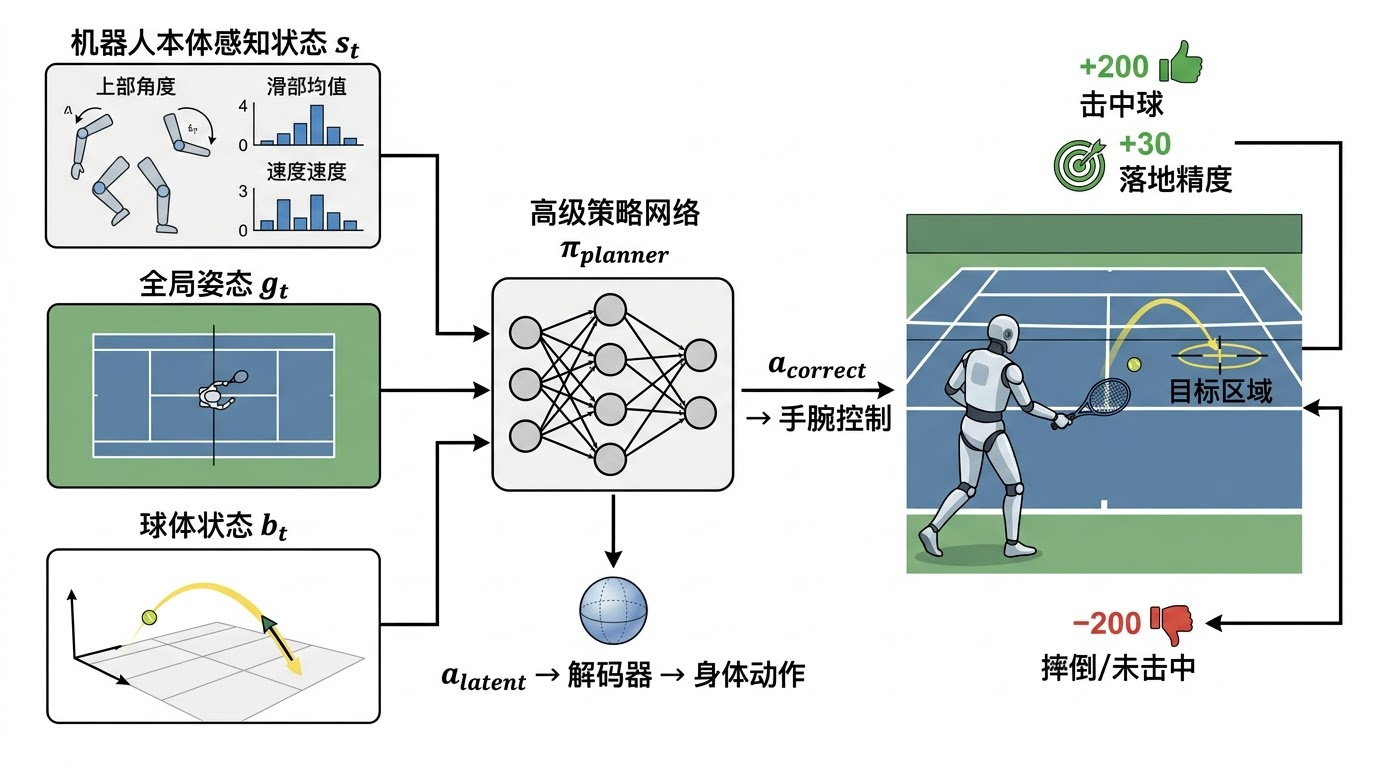
图4:阶段三流程。高层策略接收机器人状态、全局位姿和网球状态,输出隐空间动作和手腕修正指令。
高层策略的输入包括三部分:机器人本体状态 s t s_t st、全局位姿信息 g t g_t gt、以及网球状态 b t b_t bt。输出则是两部分:
a t planner = a t latent , a t correct a_t^{\text{planner}} = a_t\^{\\text{latent}}, a_t\^{\\text{correct}} atplanner=atlatent,atcorrect
其中 a t latent a_t^{\text{latent}} atlatent 是隐空间中的动作向量,用于选择和组合基础运动技能; a t correct a_t^{\text{correct}} atcorrect 是右手腕的直接控制指令,用于修正击球动作。
最终的关节控制指令通过以下方式生成:
a t full = D ( s t , μ t p + λ σ t p ⋅ tanh ( a t latent ) ) , a t correct a_t^{\text{full}} = \left \\mathcal{D}(s_t, \\mu_t\^p + \\lambda \\sigma_t\^p \\cdot \\tanh(a_t\^{\\text{latent}})),\\ a_t\^{\\text{correct}} \\right atfull=D(st,μtp+λσtp⋅tanh(atlatent)), atcorrect
其中 D \mathcal{D} D 是解码器, μ t p \mu_t^p μtp 和 σ t p \sigma_t^p σtp 是先验网络输出的均值和标准差, λ \lambda λ 是控制探索范围的超参数, tanh \tanh tanh 函数将探索限制在有界范围内。
训练环境的设置是:每个 episode 中,机器人需要连续回击 8 个网球,每个球以不同的位置和速度发出,间隔 2 秒。奖励函数包含三类共 20 余项:
| 类别 | 代表性奖励项 | 权重 |
|---|---|---|
| 任务奖励 | 击球成功 | +200.0 |
| 任务奖励 | 落点精度 | +30.0 |
| 正则化 | 关节力矩惩罚 | -2e-5 |
| 正则化 | 动作平滑度 | -2e-6 |
| 终止惩罚 | 摔倒 | -200.0 |
| 终止惩罚 | 漏球 | -200.0 |
从开源代码中可以看到,观测空间的构建非常精细,分为策略观测和价值函数观测两个流(非对称 Actor-Critic):
python
# 来源:latent_mj/envs/g1_tracking/train/g1_env_tracking_tennis.py
def _get_obs(self, data, traj_data, info):
# 本体感知
gyro_pelvis = self.get_gyro(data, "pelvis") # 骨盆角速度
gvec_pelvis = data.site_xmat[self._pelvis_imu_site_id].T @ jp.array([0, 0, -1]) # 重力方向
joint_pos = data.qpos[7:] # 关节位置
joint_vel = data.qvel[6:] # 关节速度
# 与参考动作的差异
dif_joint_pos = traj_data.qpos[7:] - joint_pos
dif_joint_vel = traj_data.qvel[6:] - joint_vel
# 添加观测噪声(Sim-to-Real 关键设计)
noisy_gyro_pelvis = gyro_pelvis + uniform_noise * noise_scales.gyro
noisy_joint_pos = joint_pos + uniform_noise * noise_scales.joint_pos
# 策略观测(带噪声):用于 Actor 网络
state = [noisy_gyro_pelvis, noisy_gvec_pelvis, noisy_joint_pos, ...]
# 价值函数观测(无噪声 + 额外信息):用于 Critic 网络
privileged_state = [gyro_pelvis, gvec_pelvis, joint_pos,
dif_rigid_body_pos_local, feet_contact, linvel_pelvis, ...]终止条件的判定同样来自代码库:
python
# 来源:latent_mj/envs/g1_tracking/train/g1_env_tracking_tennis.py
def _get_termination(self, data, traj_data, info):
# 根部高度偏差过大 → 判定为摔倒
fall_termination = jp.abs(data.qpos[2] - traj_data.qpos[2]) > 0.3
# 任意刚体位置偏差超过阈值 → 终止
dif_rigid_body_pos_local = gmth.calculate_dif_rigid_body_pos_local(data, traj_data)
norm_dif = jp.linalg.norm(dif_rigid_body_pos_local[self.valid_body_ids, :], axis=-1)
rigid_body_position_termination = jp.any(norm_dif > 0.5)
return fall_termination | jp.isnan(data.qpos).any() | rigid_body_position_termination4. 隐空间动作屏障(Latent Action Barrier):平衡任务性能与动作质量
LATENT 最核心的技术贡献之一是隐空间动作屏障(Latent Action Barrier, LAB)。这个设计解决了一个在强化学习中非常普遍的问题:策略在优化任务奖励时,往往会找到一些"投机取巧"的解决方案。
具体到网球场景,如果不加约束,高层策略可能会在隐空间中采样出远离先验分布的动作------比如在跑向来球时频繁切换不同的移动模式,或者用不自然的抖动动作勉强击中球。虽然任务完成了,但动作质量严重下降,这在真实机器人上可能导致硬件损坏或不稳定。
LAB 的设计思路是:用先验分布来约束高层策略的探索范围,但不是简单地限制欧氏距离,而是基于马氏距离(Mahalanobis Distance)进行约束。这是因为先验分布的标准差在不同状态和不同隐空间维度上差异很大------某些维度的合理变化范围大,某些维度则很小。
用数学语言表达:
a t full = D ( s t , μ p ( s t ) + λ ⋅ σ p ( s t ) ⋅ tanh ( a t latent ) ) a_t^{\text{full}} = \mathcal{D}\left(s_t,\ \mu^p(s_t) + \lambda \cdot \sigma^p(s_t) \cdot \tanh(a_t^{\text{latent}})\right) atfull=D(st, μp(st)+λ⋅σp(st)⋅tanh(atlatent))