阿里甩出"语言世界模型"重磅炸弹:Qwen-AgentWorld 全面解析,七域统一、性能超 GPT-5.4
发布日期: 2026-06-24
标签:
Qwen大模型AI Agent语言世界模型LLM开源摘要: 阿里通义千问今日发布首个原生语言世界模型 Qwen-AgentWorld,单一模型覆盖 7 大智能体交互领域,旗舰版 397B 在 AgentWorldBench 评测中超越 GPT-5.4、Claude Opus 4.8,全面开源。本文从背景、技术架构、性能对比、部署实战四个维度深度解析。
一、背景:为什么需要"语言世界模型"?
近两年,AI Agent 赛道爆发式增长------从网页操作、终端命令、手机自动化到软件工程,智能体正在从"聊天工具"变成"能干活的数字员工"。然而,训练一个优秀的 Agent 需要海量真实环境交互,成本极高:
- 搭环境繁琐,维护代价大
- 数据收集慢,无法快速扩展
- 真实环境存在风险,不便注入受控扰动进行对抗训练
语言世界模型(Language World Model, LWM) 正是为解决上述痛点而生------让一个大模型直接扮演"环境"的角色 ,预测智能体执行某个动作后的下一个环境状态,从而在纯模拟中训练和评估智能体,彻底绕开真实环境的限制。
2026年6月24日,阿里通义千问(QwenLM)正式发布 Qwen-AgentWorld ,这是业界首个原生 语言世界模型,也是首个在单一模型内统一七大交互领域 的世界模型。配套评测基准 AgentWorldBench 同步开源。
📌 技术报告 :arXiv:2606.24597
📌 GitHub :QwenLM/Qwen-AgentWorld
📌 HuggingFace :Qwen/Qwen-AgentWorld
📌 ModelScope :Qwen-AgentWorld
二、核心理念:何为"原生"世界模型?
"原生"是 Qwen-AgentWorld 最关键的标签,与同类工作的本质区别在于:
| 对比维度 | 传统做法(事后适配) | Qwen-AgentWorld(原生) |
|---|---|---|
| 训练起点 | 通用 LLM 微调 | 从 CPT 阶段即以环境建模为目标 |
| 训练流程 | 仅 SFT / RL | CPT → SFT → RL 全流程贯通 |
| 环境知识注入 | 数据增强 | 预训练级别的知识内化 |
| 领域覆盖 | 单一/少量领域 | 七大领域一个模型 |
换言之,Qwen-AgentWorld 并非拿一个通用模型来"套模板",而是从最底层的预训练阶段就将**"我是环境,我要预测下一个状态"**作为核心训练目标。这使得模型对环境动态的理解更深入、更系统。
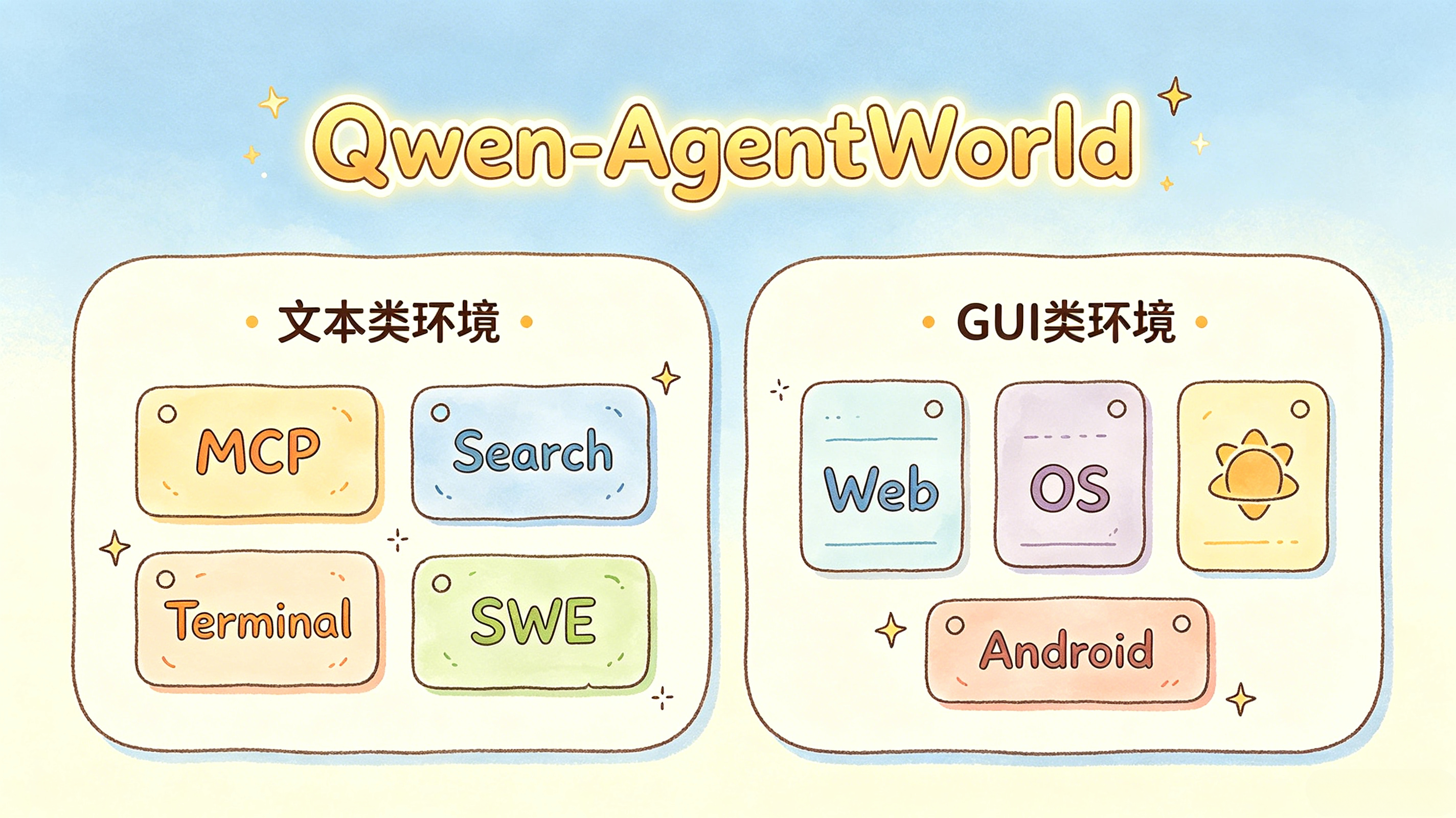
三、七大领域:文本 + GUI 全覆盖
Qwen-AgentWorld 将智能体交互场景拆分为两大类、七个领域:
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ 文本类环境 GUI 类环境 │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Search │ │ OS │ │
│ │ Terminal│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘| 领域 | 类型 | 说明 |
|---|---|---|
| MCP | 文本 | 工具调用(Model Context Protocol) |
| Search | 文本 | 网络搜索交互 |
| Terminal | 文本 | Linux 终端命令执行 |
| SWE | 文本 | 软件工程任务(代码修复等) |
| Web | GUI | 网页浏览操作 |
| OS | GUI | 桌面操作系统交互 |
| Android | GUI | 移动端应用操作 |
⚙️ 特别设计 :针对三个 GUI 领域,环境观测以可渲染代码而非像素帧呈现,从而让纯文本世界建模也能覆盖视觉环境,降低了模型的输入复杂度。
训练数据方面,模型基于超过 1000 万条真实世界交互轨迹进行训练。
四、三阶段训练流水线
Qwen-AgentWorld 的核心技术亮点是贯通 CPT → SFT → RL 的三阶段训练管线:
阶段一:CPT(持续预训练)------ 注入环境知识
- 通过学习大量真实环境交互轨迹,将"环境动态知识"嵌入模型权重
- 引入轮次级别的信息论损失掩码,精准识别真正承载环境信息的对话轮,避免干扰轮次带来噪声
阶段二:SFT(监督微调)------ 激活链式推理
- 将"下一状态预测"能力激活为思维链(Chain-of-Thought)推理模式
- 模型学会"先想为什么,再预测结果",而非直接输出答案
阶段三:RL(强化学习)------ 精炼保真度
- 采用混合奖励信号(GSPO 算法)优化输出质量
- 重点提升模拟的格式规范性、事实准确性、上下文一致性、真实感和整体质量
💡 涌现能力:研究团队发现,训练后模型涌现出三种有趣的推理模式:
- 🔄 自我修正:使用 "Wait!" 作为自我纠错的触发信号
- 🛡️ 信息泄漏防护:在 Search 领域能防止摘要意外透露目标答案
- 🔗 多步因果推理:预测某些特定命令输出需要一条 6 步推理链
五、开源模型清单
| 模型 | 参数规模 | 激活参数 | 上下文长度 | 定位 |
|---|---|---|---|---|
| Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K tokens | 轻量高效版 |
| Qwen-AgentWorld-397B-A17B | 397B | 17B | --- | 旗舰性能版 |
| AgentWorldBench | --- | --- | --- | 配套评测数据集 |
35B-A3B 模型架构细节
- 基座模型:Qwen3.5-35B-A3B-Base
- 架构类型:因果语言模型(混合线性注意力 + MoE)
- 隐藏维度:2048
- 层数:40 层(每 4 层为一组:3×GatedDeltaNet + 1×GatedAttention + MoE)
- 专家数量:256 个,每次激活 8 个路由专家 + 1 个共享专家
- 上下文长度:262,144 tokens(建议最低保持 128K)
六、性能对比:AgentWorldBench 评测结果
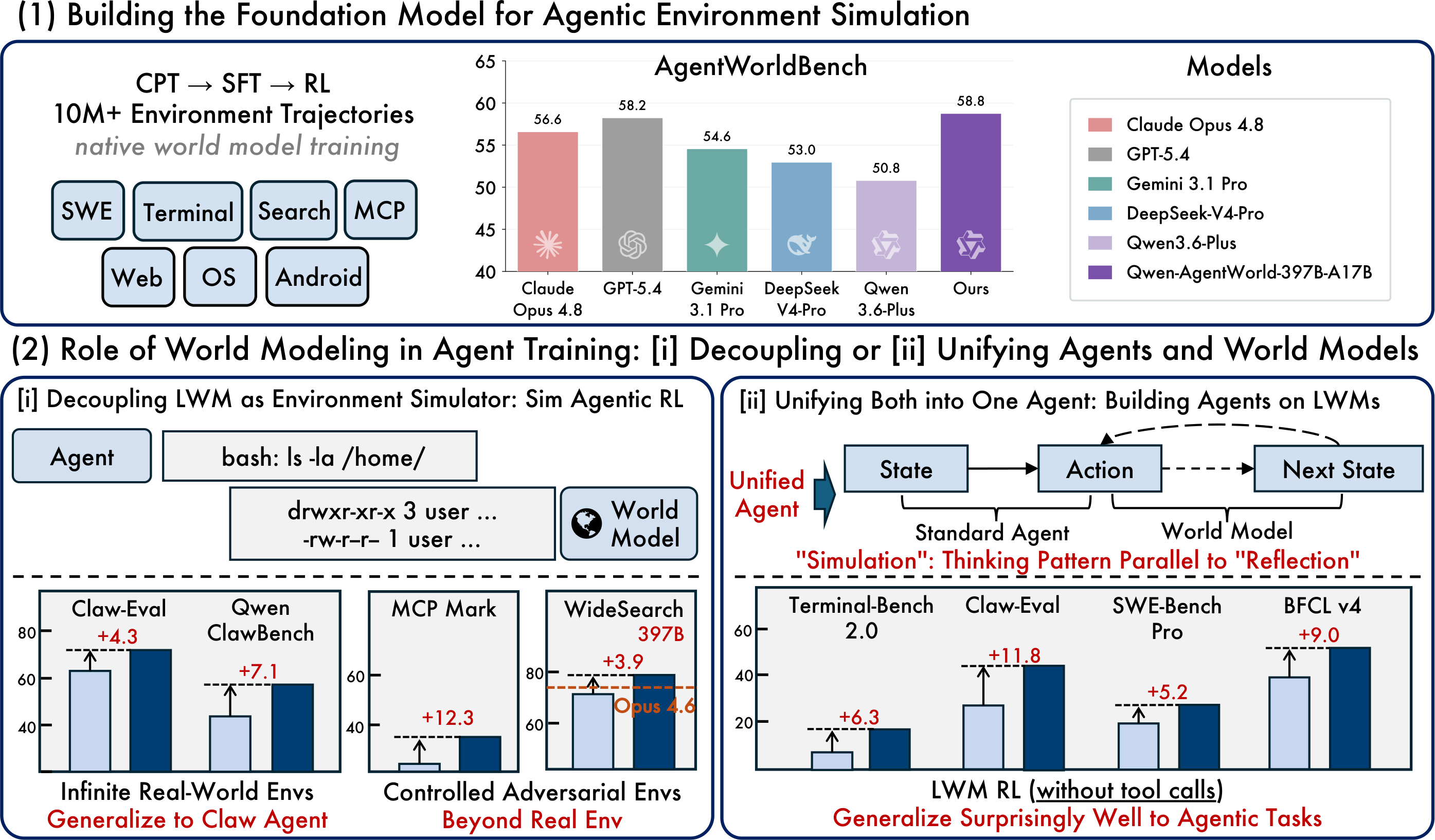
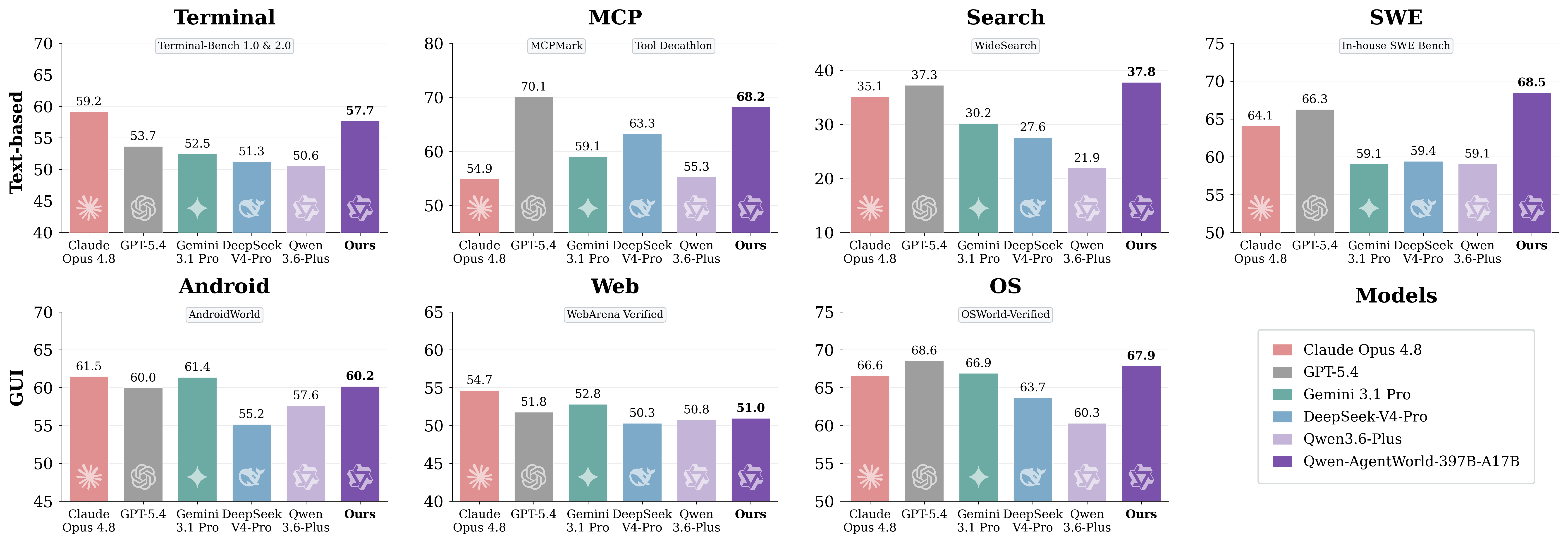
AgentWorldBench 从五个维度评分(Format、Factuality、Consistency、Realism、Quality),归一化至 0--100 分,得分越高越好。
完整排行榜(Overall 降序)
| 模型 | MCP | Search | Terminal | SWE | Android | Web | OS | Overall |
|---|---|---|---|---|---|---|---|---|
| Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 🏆 |
| GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
| Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
| Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
| Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
| Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
| Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
| Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 60.85 | 54.74 |
| DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
| Qwen3.5-35B-A3B(基础版) | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
核心结论:
- 🏆
Qwen-AgentWorld-397B-A17B整体得分 58.71 ,超越 GPT-5.4(58.25),登顶榜首 - 🚀
Qwen-AgentWorld-35B-A3B在相同 35B 规模下,相比基础版Qwen3.5-35B-A3B提升 +8.66 分,超越 Claude Sonnet 4.6
七、四大应用范式与实验数据
范式一:可泛化的 OOD 环境扩展
用 Qwen-AgentWorld-397B-A17B 在 4000 个分布外 OpenClaw 环境上进行 Sim RL,零样本泛化到全新领域:
| 训练方式 | Claw-Eval | QwenClawBench |
|---|---|---|
| 基础 SFT | 65.4 | 47.9 |
| Sim RL(通用模型模拟器) | 66.7 | 47.8 |
| Sim RL(Qwen-AgentWorld 模拟器) | 69.7 | 55.0 |
| 提升量 Δ | +4.3 | +7.1 |
范式二:可控模拟 ------ MCP 定向扰动
通过注入定向扰动暴露智能体弱点,优于无扰动的真实环境训练:
| 配置 | Tool Decathlon | MCPMark |
|---|---|---|
| 基础 SFT | 32.4 | 21.5 |
| Sim RL(无控制) | 31.5 | 24.6 |
| Sim RL(有控制) | 36.1 | 33.8 |
| 提升量 Δ | +3.7 | +12.3 |
范式三:虚构世界构建 ------ Search 领域
在完全虚构但自洽的搜索世界中训练,泛化到真实搜索任务:
| 配置 | WideSearch F1 Item | WideSearch F1 Row |
|---|---|---|
| 基础 SFT(35B) | 34.02 | 13.72 |
| + Sim RL 虚构世界 | 50.31 | 24.21 |
| 提升量 Δ | +16.29 | +10.49 |
范式四:智能体基础模型 ------ LWM RL 热身迁移
使用 LWM RL 热身,无需在智能体任务上做额外 RL 微调,即可全面提升下游性能:
| 指标 | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
|---|---|---|---|---|---|---|
| 基础 SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
| + LWM RL 热身 | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
| Δ | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
📌 亮点 :LWM RL 热身训练来源于单轮、非智能体轨迹,却成功迁移到多轮工具调用的复杂 Agent 任务,包括 3 个完全域外任务,说明世界建模知识具有强迁移性。
八、快速上手部署
方法一:SGLang 部署(推荐,速度快)
pip install sglang
python -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3启动后,OpenAI 兼容 API 地址:http://localhost:8000/v1
方法二:vLLM 部署
pip install vllm
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-code方法三:Transformers 本地推理
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
# 以 Terminal 域为例:让模型预测命令输出
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)方法四:通过 API 调用(配合 SGLang/vLLM)
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)💡 最佳实践:
- 采样参数推荐:
temperature=0.6、top_p=0.95、top_k=20- 推荐输出长度:32,768 tokens(长轨迹可适当增大)
- 使用 GitHub 仓库
prompts/目录下的七领域专用系统提示以获得最佳模拟效果- 上下文长度至少保持 128K(模型默认 256K),否则影响多轮模拟质量
九、AgentWorldBench 评测流程
如果你希望在 AgentWorldBench 上测试自己的世界模型,三步搞定:
# 1. 克隆评测仓库
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. 下载评测数据集
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. 安装依赖
pip install openai
cd eval
# Step 1:世界模型推理
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Step 2:LLM 裁判评分(需要 OpenAI API Key)
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Step 3:汇总输出分数
python eval.py score --predictions ./results/judged.jsonl每条测试样本均配备真实环境执行所得的 ground-truth 观测数据,五个维度全面评估世界建模能力。
十、微调建议
如果你希望针对特定领域对模型进行进一步定制,推荐使用以下三个主流框架:
| 框架 | 特点 | 适用场景 |
|---|---|---|
| Swift | 阿里 ModelScope 出品,集成度高 | 快速实验 |
| LLaMA-Factory | 社区最活跃,支持多种训练策略 | 工程落地 |
| UnSloth | 显存优化极致,同等硬件更大模型 | 资源受限场景 |
十一、总结与展望
Qwen-AgentWorld 的发布,标志着 AI Agent 领域进入一个新阶段------不再仅仅追求更强的 Agent,而是同步构建能够高保真模拟世界的 LWM。其核心价值在于:
| 价值维度 | 具体表现 |
|---|---|
| 📦 开源普惠 | 两个规格的世界模型 + 评测基准全面开源,Apache 2.0 协议 |
| 🌍 七域统一 | 首个同时覆盖文本与 GUI 七大 Agent 交互领域的单一模型 |
| 🧪 训练加速 | 为 Agent RL 提供高效可扩展的模拟环境,大幅降低真实环境依赖 |
| 🎯 可控实验 | 支持受控扰动与虚构世界构建,解锁真实环境无法实现的训练场景 |
| 🔄 迁移能力 | LWM RL 热身可迁移至域外 Agent 任务,具备强泛化性 |
| 🏆 顶尖性能 | 397B 旗舰版整体超越 GPT-5.4,35B 版超越 Claude Sonnet 4.6 |
如果你正在开发 AI Agent、研究强化学习训练环境,或是希望深入理解世界模型方向的最新进展,Qwen-AgentWorld 是当前最值得关注的开源项目之一。
参考资料
- Qwen-AgentWorld 技术报告 (arXiv:2606.24597)
- GitHub 仓库:QwenLM/Qwen-AgentWorld
- HuggingFace 模型页:Qwen/Qwen-AgentWorld-35B-A3B
- 百度百科:Qwen-AgentWorld
- 通义千问发布首个语言世界模型 Qwen-AgentWorld(百家号)
免责声明:本文为技术介绍性文章,性能数据均来自官方评测基准 AgentWorldBench,实际应用效果因场景而异。