文章目录
简介
YOLO系列算法在验证模型时使用了PASCAL VOC数据集,此为PASCAL VOC挑战赛的配套数据集。PASCAL(Pattern Analysis, Statistical Modelling and Computational Learning)即模式分析、统计建模和计算机学习,VOC(Visual Object Classes)即视觉对象类,这个挑战赛的目标是为图像分类、目标检测、语义分割等任务提供统一、高质量的标注数据和标准化评估协议。而YOLO系列算法是目前最火的图片分类算法,采用VOC数据集也是顺理成章的。
PASCAL VOC挑战赛始于2005年,止于2012年,其核心数据集每年都会有所更新,故而目前一般使用VOC 2012版本用于训练;而VOC 2007则是最后一届公开test的数据集,所以现在使用ROC数据集的时候,一般用07和12版本做训练,并用07版的test做测试。
这两个数据集的文件结构如下
bash
VOCdevkit/
└── VOC2012/ (或 VOC2007)
├── Annotations/ # 目标检测的 .xml 标签文件
├── ImageSets/ # 各任务的数据集划分文件 (.txt)
│ ├── Action/
│ ├── Layout/
│ ├── Main/ # train/val/test 划分名单
│ └── Segmentation/
├── JPEGImages/ # 原始图像 (.jpg)
├── SegmentationClass/ # 类别标签 (.png)
└── SegmentationObject/ # 对象标签 (.png)原始图像、类别标签和对象标签图像的区别为
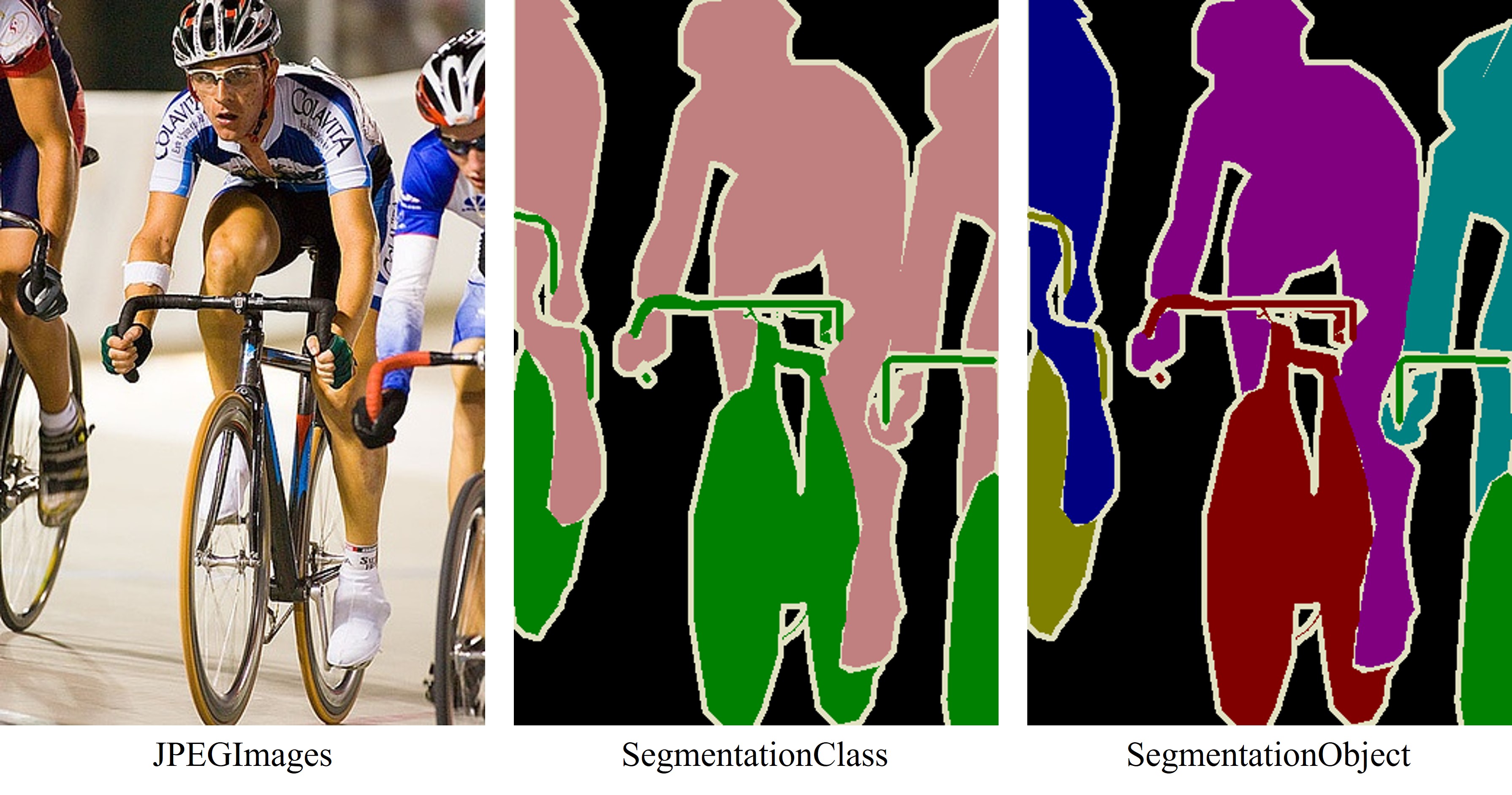
其中,Segmentation图像并非RGB格式,而是单通道的索引图像,每种颜色对应一个整数,具体来说
- 0 表示背景(黑色)
- 1-20 表示VOC的20个具体目标类别
- 255 表示目标边界
这20个具体的类别包括
- aeroplane
- bicycle
- bird
- boat
- bottle
- bus
- car
- cat
- chair
- cow
- diningtable
- dog
- horse
- motorbike
- person
- pottedplant
- sheep
- sofa
- train
- tvmonitor
创建数据集
由于VOC数据集用xml格式标记,其主要参数包括
- filename 图像名称
- size 尺寸
- width 图像宽
- height 图像高
- object 对象
- xmin, ymin, xmax, ymax 框选范围
YOLO在训练的过程中,需要获取图像、标签和预测其掩码,下面以Yolo v1为例,构建其训练用的数据集
python
import xml.etree.ElementTree as ET
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import os
VOC_CLASSES = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
class VOCDataset(Dataset):
def __init__(self, img_dir, ann_dir, img_list, transform=None):
self.img_dir = img_dir
self.ann_dir = ann_dir
self.img_list = img_list
self.transform = transform
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
name = self.img_list[idx]
img = Image.open(os.path.join(self.img_dir, f"{name}.jpg")).convert("RGB")
# 解析 XML
tree = ET.parse(os.path.join(self.ann_dir, f"{name}.xml"))
root = tree.getroot()
h, w = int(root.find("size/height").text), int(root.find("size/width").text)
boxes, labels = [], []
for obj in root.findall("object"):
cls = VOC_CLASSES.index(obj.find("name").text)
bbox = obj.find("bndbox")
xmin = int(bbox.find("xmin").text) / w
ymin = int(bbox.find("ymin").text) / h
xmax = int(bbox.find("xmax").text) / w
ymax = int(bbox.find("ymax").text) / h
cx, cy = (xmin + xmax) / 2, (ymin + ymax) / 2
bw, bh = xmax - xmin, ymax - ymin
boxes.append([cx, cy, bw, bh])
labels.append(cls)
if self.transform:
img = self.transform(img)
# 构建 7x7x30 target
target = torch.zeros(7, 7, 30)
box_mask = torch.zeros(7, 7, 2)
for box, label in zip(boxes, labels):
cx, cy, bw, bh = box
gx, gy = int(cx * 7), int(cy * 7)
gx, gy = min(max(gx, 0), 6), min(max(gy, 0), 6)
p_idx = 0 if box_mask[gy, gx, 0] == 0 else 1
target[gy, gx, 0] = cx * 7 - gx
target[gy, gx, 1] = cy * 7 - gy
target[gy, gx, 2] = math.sqrt(bw)
target[gy, gx, 3] = math.sqrt(bh)
target[gy, gx, 4 + p_idx] = 1.0
target[gy, gx, 6 + label] = 1.0
box_mask[gy, gx, p_idx] = 1.0
return img, target, box_mask由于Yolo v1只关心框选范围内的类别,故而在上述代码中,并未用到Segmentation图像,而是采用了xml中的数据。