1 前言
1.1 选题背景及意义
1.1.1 选题背景
心血管疾病已成为威胁全球居民健康的"头号杀手"。根据《中国心血管健康与疾病报告2023》数据显示,中国心血管病患病率处于持续上升阶段,现患人数约为3.3亿,其中冠心病患者数量超过1100万。心血管疾病不仅给患者家庭带来沉重的经济负担,也对社会医疗资源形成了巨大压力。更为严峻的是,由于生活方式改变、工作压力增大以及人口老龄化加剧,心血管疾病的发病呈现年轻化趋势,大量处于"亚健康"状态的中青年群体正面临着潜在的突发风险。然而,目前临床实践中对于心脏病的诊断仍主要依赖于医生基于心电图、血液指标及影像学检查的综合判断,此类传统模式不仅对医疗资源依赖性高,而且缺乏对患者长期数据变化的动态追踪,难以实现对高危人群的早期识别与干预。尤其是在基层医疗机构,专业心血管医生资源匮乏,往往导致病情发现滞后,错过最佳治疗时机。
在信息技术与医疗健康深度融合的背景下,利用机器学习技术对历史病历数据进行挖掘分析,构建可量化的风险评估模型,成为提升心血管疾病早期筛查能力的重要方向。近年来,国内外学者已开展了大量基于UCI、Kaggle等公开心脏病数据集的研究工作,从最初单一的逻辑回归模型,逐步发展到集成学习、深度神经网络等复杂算法的应用,研究焦点也从单纯追求预测准确率,向模型可解释性、特征重要性分析及临床实用性等维度拓展。然而,通过分析现有研究可以发现,多数工作仍停留在算法层面的对比优化,缺乏对完整业务流程的整合。具体表现为:模型训练与数据探索环节割裂,用户难以直观理解各指标对风险的贡献程度;预测结果仅输出一个概率值,缺乏针对个体特征的个性化健康指导;系统缺少用户交互与管理功能,难以模拟真实的临床应用场景。这些不足使得研究成果多停留在实验室阶段,与真正落地应用于健康管理或临床辅助诊断尚存在一定距离。
针对上述问题,本研究旨在设计并实现一个集数据分析、特征工程、多模型训练与智能问答于一体的心脏病风险预测系统。在借鉴现有分类模型研究成果的基础上,将重点解决以下问题:一是构建从数据导入到模型部署的完整技术链路,提升系统的可用性与完整性;二是引入大语言模型生成个性化健康建议,使预测结果更具实用价值;三是设计直观的可视化交互界面,帮助非专业用户理解医疗指标与疾病风险的关联机制。通过以上探索,期望为心血管疾病的早期预警与健康管理提供一种新的技术解决方案。
1.1.2 选题意义
从实践应用层面来看,本研究的价值首先体现在对个人健康管理的赋能。当前,公众对心血管健康的关注度日益提升,但多数人对自身体检指标与心脏病风险之间的关联缺乏科学认知。本系统通过提供便捷的在线预测入口,允许用户自主输入年龄、血压、胆固醇等关键指标,并实时获得风险概率评估及个性化健康建议,能够帮助用户直观了解自身健康状况,增强健康意识,促进从"被动治疗"向"主动预防"的就医观念转变。对于基层医疗卫生机构而言,该系统可作为辅助诊断工具,为全科医生提供客观的数据参考,在一定程度上缓解专业心内科医生资源分布不均的问题,提升基层医疗服务效能。
从技术探索角度来看,本研究具有明确的方法论创新意义。一方面,系统集成了多种经典机器学习模型,并通过可视化对比方式展示各模型的性能差异,有助于理解不同算法在处理医疗数据时的适用场景与局限性,为后续研究者在模型选择上提供了直观的参考依据。另一方面,本研究创新性地将大语言模型引入医疗健康预测领域,探索了人工智能技术从"数据识别"向"知识生成"延伸的可能性。通过将结构化的医学指标转化为通俗易懂的健康建议,这一尝试为人工智能在健康科普、患者教育等场景的应用提供了新的思路。
从学科融合的角度分析,本研究也体现了计算机科学与临床医学交叉融合的典型特征。医疗数据具有高维度、非线性、样本分布不均衡等特点,本系统在数据预处理与特征选择环节所采用的方法,如相关性分析、递归特征消除等,对于处理此类数据具有较好的普适性,可为糖尿病、高血压等其他慢性病预测系统的开发提供可复用的技术框架。综合来看,本研究在推动人工智能技术向医疗健康领域转化、促进数据驱动决策在基层医疗中落地等方面,具有一定的现实意义与推广价值。
1. 2 国内外发展现状
近年来,随着医疗信息化水平的提升与人工智能技术的快速发展,机器学习在心血管疾病预测领域的研究呈现出爆发式增长态势,国内外学者围绕不同应用场景、算法优化与临床转化等问题展开了广泛而深入的探索。
国外研究起步较早,研究重点已从基础分类问题向更具临床价值的细分方向延伸。Javeed等(2023)聚焦于心脏病患者死亡率预测,针对数据集中类别高度不平衡的问题,引入合成少数类过采样技术(SMOTE)构建临床决策支持系统,有效缓解了模型偏倚问题。Liza等(2025)基于克利夫兰心脏病数据集,对比了逻辑回归、随机森林与XGBoost三种算法,实验表明XGBoost在训练准确率与泛化能力上表现均衡,并探讨了将预测模型嵌入电子健康档案系统、应用于远程医疗场景的可行性。Yongli(2025)同样验证了逻辑回归与随机森林在心脏病预测任务中的实用价值,并提出未来可通过模型堆叠与数据源优化提升性能。值得注意的是,部分研究也暴露出学术不端问题,Kanimozhi等(2024)发表的文章因内容无意义、参考文献不相关等问题被期刊撤稿,这从侧面反映出该领域在快速发展的同时,仍面临研究质量参差不齐的挑战。
国内学者在机器学习与心脏病预测交叉领域的研究呈现多样化特征。在基础预测模型方面,蒋美艳与张辉(2024)利用克利夫兰数据集,通过皮尔逊相关系数筛选特征,比较了判定树、随机森林、支持向量机、K近邻与朴素贝叶斯五种算法,结果显示随机森林综合性能最优。毕吉霖等(2025)创新性地提出卷积神经网络与多种机器学习算法投票融合的预测模型,在准确率、精确率等指标上取得较好效果。针对特定患者群体的研究逐步深入,朱坤等(2024)基于中国心血管外科注册登记数据库,采用多种机器学习算法构建老年瓣膜性心脏病患者术后院内死亡风险预测模型,样本量达7千余例,体现了真实世界数据与机器学习结合的潜力。宋学武(2025)与张凯等(2025)分别聚焦老年缺血性心脏病患者预后与慢性心脏病患者认知衰弱预测,进一步拓展了机器学习在心血管疾病管理中的应用边界。此外,黄越等(2025)将预测模型转化为在线应用,利用ShinyApp工具实现缺血性心脏病住院费用预测,为研究成果向临床工具转化提供了有益探索。
综合来看,国内外研究已从单一算法对比向多模态数据融合、特定人群精准预测及临床工具开发等方向演进,但仍面临数据稀缺、模型可解释性不足、多中心验证缺乏等共性问题。。
2 相关技术及理论基础
2 .1 机器学习算法
机器学习算法是构建心脏病预测模型的核心。根据任务特点与数据类型,本研究选取了逻辑回归、支持向量机、随机森林、XGBoost及CatBoost五种经典算法进行对比研究。
2 . 1.1 逻辑回归
逻辑回归是一种广泛应用于二分类问题的线性模型,其本质是在线性回归的基础上引入Sigmoid函数将预测值映射到0到1区间,输出结果可解释为样本属于正类的概率。该算法通过极大似然估计求解模型参数,具有计算效率高、模型可解释性强、不易过拟合等优点。在医疗预测任务中,逻辑回归因其良好的可解释性常被用作基线模型,能够帮助理解各特征对预测结果的贡献程度。本系统中逻辑回归作为基础对比模型,通过网格搜索优化正则化系数C与惩罚项类型,提升其在心脏病数据上的适应能力。
2 . 1.2 支持向量机
支持向量机通过寻找能够最大化分类间隔的超平面来实现样本划分,其核心思想是将原始特征空间映射到高维空间,在该空间中构造最优分离超平面。通过引入核函数,SVM能够有效处理非线性分类问题。常用的核函数包括线性核、多项式核与径向基核函数,其中径向基核因其对非线性关系的拟合能力较强而被广泛使用。SVM在小样本、高维数据场景下表现出较好的泛化能力。本系统采用径向基核函数,同时通过网格搜索优化惩罚系数与核函数参数,提升模型对心脏病数据的分类性能。
2 . 1.3 随机森林
随机森林是一种基于决策树的集成学习算法,通过Bootstrap抽样从原始数据集中生成多个子样本,对每个子样本构建决策树,并在节点分裂时随机选取特征子集进行最佳分割。最终预测结果由所有决策树的预测结果通过投票或平均的方式确定。随机森林能够有效降低单棵决策树的过拟合风险,具有较强的抗噪声能力,同时可输出特征重要性排序,便于进行特征筛选。本系统利用随机森林进行特征重要性分析,并通过网格搜索优化决策树数量、最大深度等参数。
2 . 1.4 XGBoost
XGBoost(极端梯度提升)是基于梯度提升框架的集成学习算法,通过迭代地训练新模型拟合前序模型的残差,并将多个弱学习器的结果加权求和得到最终预测。该算法在损失函数中引入正则化项控制模型复杂度,能够有效防止过拟合。此外,XGBoost支持并行计算、内置处理缺失值、提供特征重要性评估等功能,在各类数据挖掘竞赛与实际应用中表现出优异的性能。本系统将XGBoost作为核心对比模型之一,通过网格搜索优化学习率、树深度与迭代次数等超参数。
2 . 1. 5 CatBoost
CatBoost(类别型特征梯度提升)是专门针对类别型特征设计的梯度提升算法。与传统梯度提升方法相比,CatBoost采用有序提升与对称树结构,能够自动处理类别特征,无需进行额外编码处理,同时通过组合类别特征减少过拟合风险。该算法在训练效率和预测精度方面均有较好表现,尤其适用于医疗数据中常包含类别型特征(如胸痛类型、心电图结果等)的应用场景。本系统利用CatBoost对类别特征的自适应处理能力,简化数据预处理流程,并通过网格搜索优化迭代次数与树深度等参数。
2 . 2 特征工程方法
特征工程是连接原始数据与机器学习模型的关键环节,合理的特征处理能够显著提升模型性能。
2 . 2 . 1 数据标准化
不同特征的量纲与数值范围差异较大,直接用于模型训练可能导致部分特征对损失函数影响过大,影响模型收敛与预测准确性。数据标准化通过线性变换将特征值映射到同一量级,消除量纲影响。本系统采用标准差标准化方法,将每个特征减去其均值后除以标准差,使处理后数据服从均值为0、方差为1的标准正态分布。标准化处理在模型训练前进行,且将训练集的均值与标准差保存,用于后续对新样本的标准化处理。
2 . 2 . 2 特征选择
特征选择通过筛选与目标变量关联性较强的特征,剔除冗余信息,降低数据维度,从而提升模型训练效率与泛化能力。本系统实现过滤法与嵌入法两种特征选择方法。过滤法采用方差分析计算各特征与目标变量的统计相关性,按得分高低选取特征子集,计算效率高但未考虑特征间交互关系。嵌入法采用递归特征消除策略,基于逻辑回归模型迭代训练,每次剔除权重系数最小的特征,直至保留指定数量特征,能够考虑特征间的联合影响。两种方法分别适用于初步筛选与精细化选择场景,用户可根据实际需求选择。
2 . 3 Web开发框架与可视化工具
2 . 3 . 1 Flask框架
Flask是用Python编写的轻量级Web应用框架,核心设计理念是简洁与可扩展。框架本身仅提供路由、请求响应、模板渲染等基础功能,数据库操作、表单验证等扩展功能可通过第三方插件灵活集成。与传统全栈框架相比,Flask具有学习成本低、开发灵活、性能开销小等特点,适合构建中小型Web应用。本系统基于Flask构建后端服务,通过定义路由接口响应前端请求,调用机器学习模型完成预测任务,并利用模板引擎渲染前端页面。
2 . 3 . 2 ECharts可视化库
ECharts是百度开源的数据可视化库,基于JavaScript实现,支持折线图、柱状图、散点图、热力图、雷达图等多种图表类型,并具有良好的交互性与跨平台兼容性。该工具通过配置方式快速构建可视化图表,支持数据动态更新与图表联动。本系统利用ECharts实现数据集概览统计、相关性热力图、特征分布图、特征重要性排序图以及模型性能对比雷达图等多类可视化图表,帮助用户直观理解数据特征与模型表现。
2 . 4 本章小结
本章介绍了系统开发涉及的关键技术与理论基础,包括五种机器学习算法的基本原理与适用场景、特征工程的核心方法、Flask框架的Web开发能力以及ECharts可视化工具的应用价值。上述技术共同构成了本系统的技术栈,为后续系统设计、功能实现与性能优化提供了理论支撑与技术保障。
3 系统需求分析
3 .1 可行性分析
系统开发前的可行性分析是确保项目能够顺利实施的重要环节,主要从经济、技术、操作三个维度进行论证。
经济可行性分析主要评估系统开发成本与预期效益之间的关系。本系统开发基于Python语言与Flask框架,采用MySQL与SQLite作为数据存储方案,所使用的技术栈均为开源技术,无需购置商业软件授权。开发工具方面,PyCharm Community版与VS Code可免费获取,硬件环境仅需普通个人计算机即可满足开发需求,整体开发成本较低。从效益角度分析,系统建成后可应用于医疗机构健康管理、基层医院辅助诊断以及个人健康监测等场景,能够降低人工筛查成本,提升风险评估效率。若后续部署为在线服务平台,可通过提供健康咨询、风险评估报告等服务获得持续收益。综上所述,系统从经济上是可行的。
技术可行性分析旨在判断系统在当前技术条件下能否顺利实现。本系统采用的技术路线清晰、成熟度较高。后端基于Flask框架开发,该框架轻量灵活,能够快速构建Web服务。机器学习算法通过scikit-learn、XGBoost、CatBoost等开源库实现,这些库提供了完善的算法接口与参数调优功能,降低了算法实现的技术门槛。前端采用Bootstrap响应式布局与ECharts可视化库,能够实现跨设备适配与丰富的数据图表展示。数据库操作通过SQLAlchemy完成,保证了数据访问的规范性与安全性。上述技术均有详尽的官方文档与社区支持,技术风险可控。综上所述,系统从技术上是可行的。
操作可行性分析研究系统在实际使用中是否便于操作与维护。从用户角度分析,系统前端界面设计遵循直观易用的原则,数据录入采用表单输入与下拉选择相结合的方式,操作流程清晰。各功能模块通过侧边导航栏组织,用户无需学习即可快速定位所需功能。预测结果以卡片形式展示,并配以颜色区分风险等级,结果解读门槛较低。从管理员角度分析,模型训练接口提供参数配置选项,用户可根据需求灵活调整测试集比例、特征选择数量等参数,训练结果实时反馈,便于进行模型优化。综上所述,系统从操作上是可行的。
3 . 2 需求分析
3.2.1 业务流程分析
本系统围绕心脏病风险预测这一核心任务,设计了数据探索分析、特征工程处理、模型训练与对比、风险预测、用户管理五个核心业务流程。
数据探索分析业务流程:用户进入数据分析页面后,系统从数据库读取心脏病数据集,以统计图表形式展示样本总量、患病比例、特征分布情况以及特征间相关性。用户可切换不同特征查看分布直方图,通过分页表格浏览原始数据,实现对数据集的全面了解。
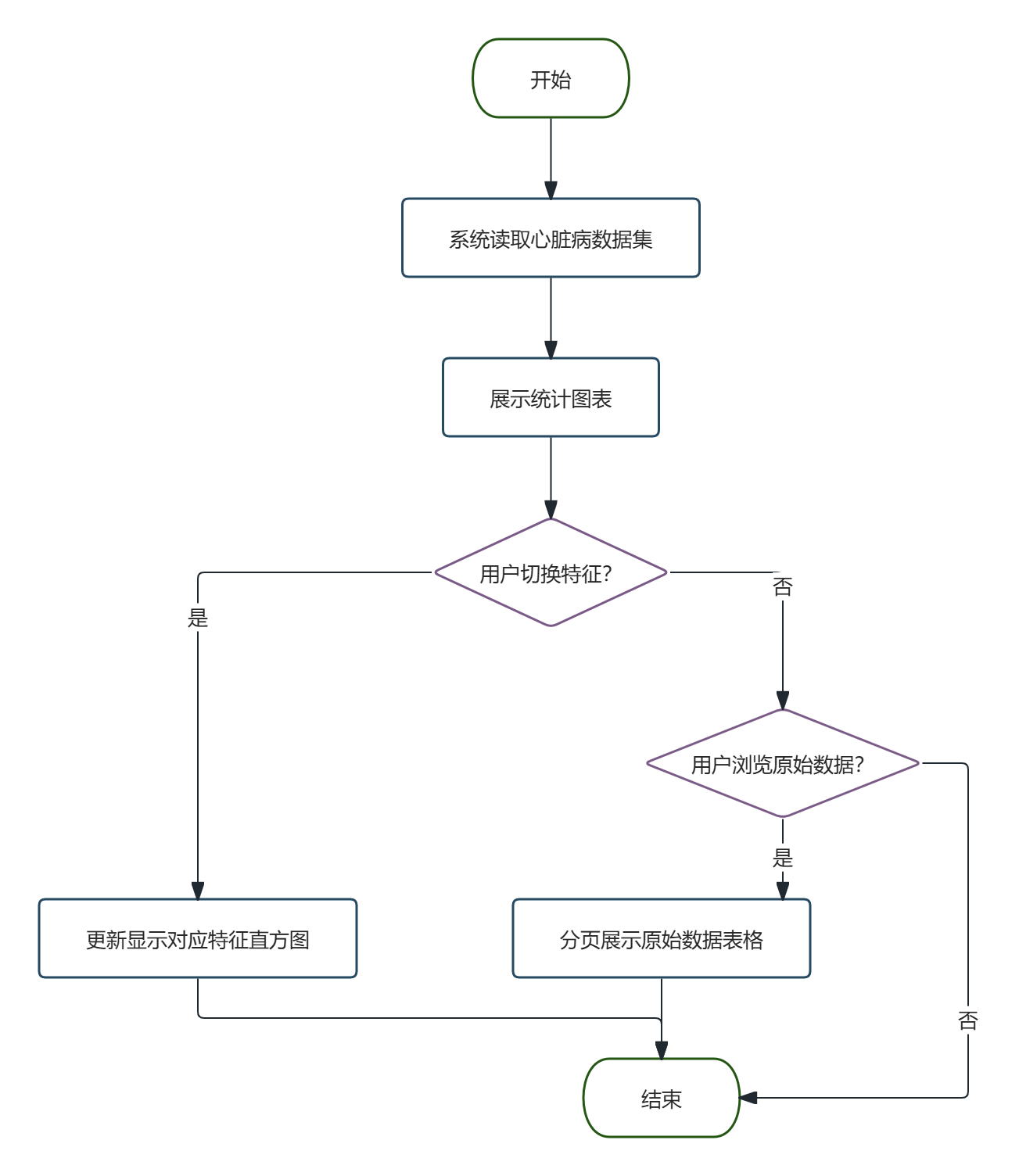
特征工程业务流程:用户进入特征工程页面后,系统加载数据集并进行初步处理,展示缺失值检测结果与特征说明。用户可选择过滤法或嵌入法进行特征选择,并指定保留的特征数量。系统根据选择的方法计算特征得分,返回筛选结果并更新特征得分图表,帮助用户识别对模型贡献度较高的特征。
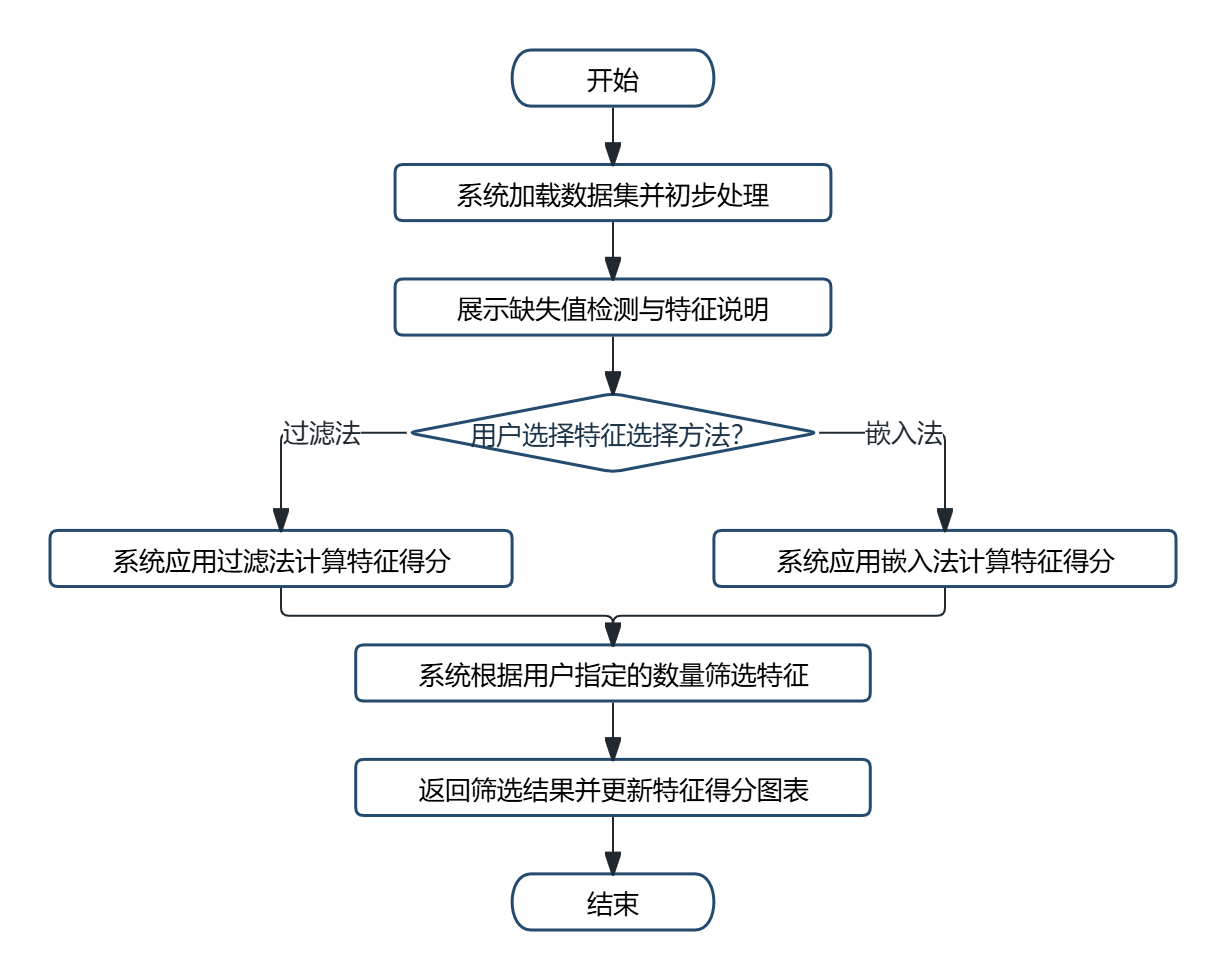
模型训练与对比业务流程:用户在模型训练页面选择待训练的算法类型,设置测试集比例与使用的特征集合,提交训练请求后,系统进行数据分割、标准化、网格搜索与交叉验证,返回模型评估指标与混淆矩阵。训练完成的模型保存至本地,并在模型对比页面集中展示各模型的性能指标与排名,便于用户选择最优模型。
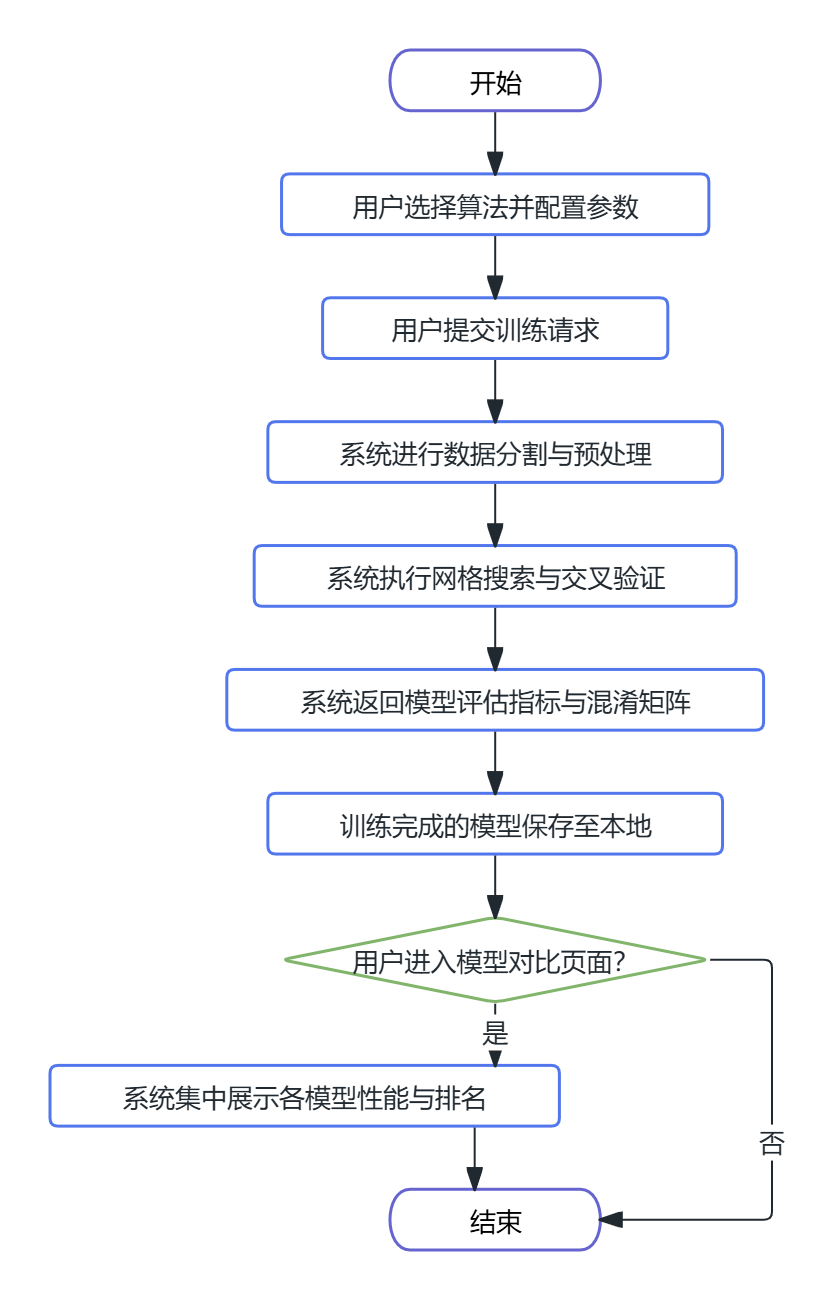
风险预测业务流程:用户选择预测模型与关联用户后,填写年龄、性别、胸痛类型、血压、胆固醇等13项临床指标。系统对输入数据进行标准化处理,调用指定模型完成预测,返回风险概率与风险等级,并调用大语言模型生成个性化健康建议,同时将预测记录保存至数据库。
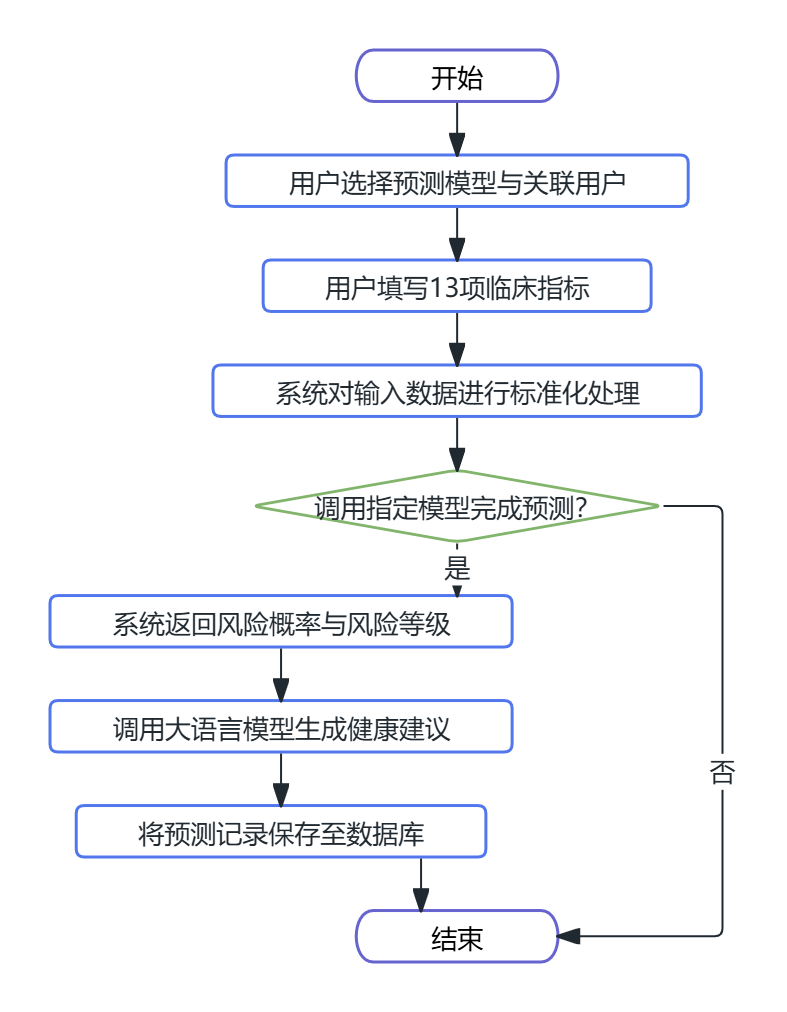
用户管理业务流程:管理员可创建新用户并查看用户列表,系统记录用户的预测次数。用户可在预测记录页面筛选查看历史预测详情,包括输入数据与生成的健康建议。
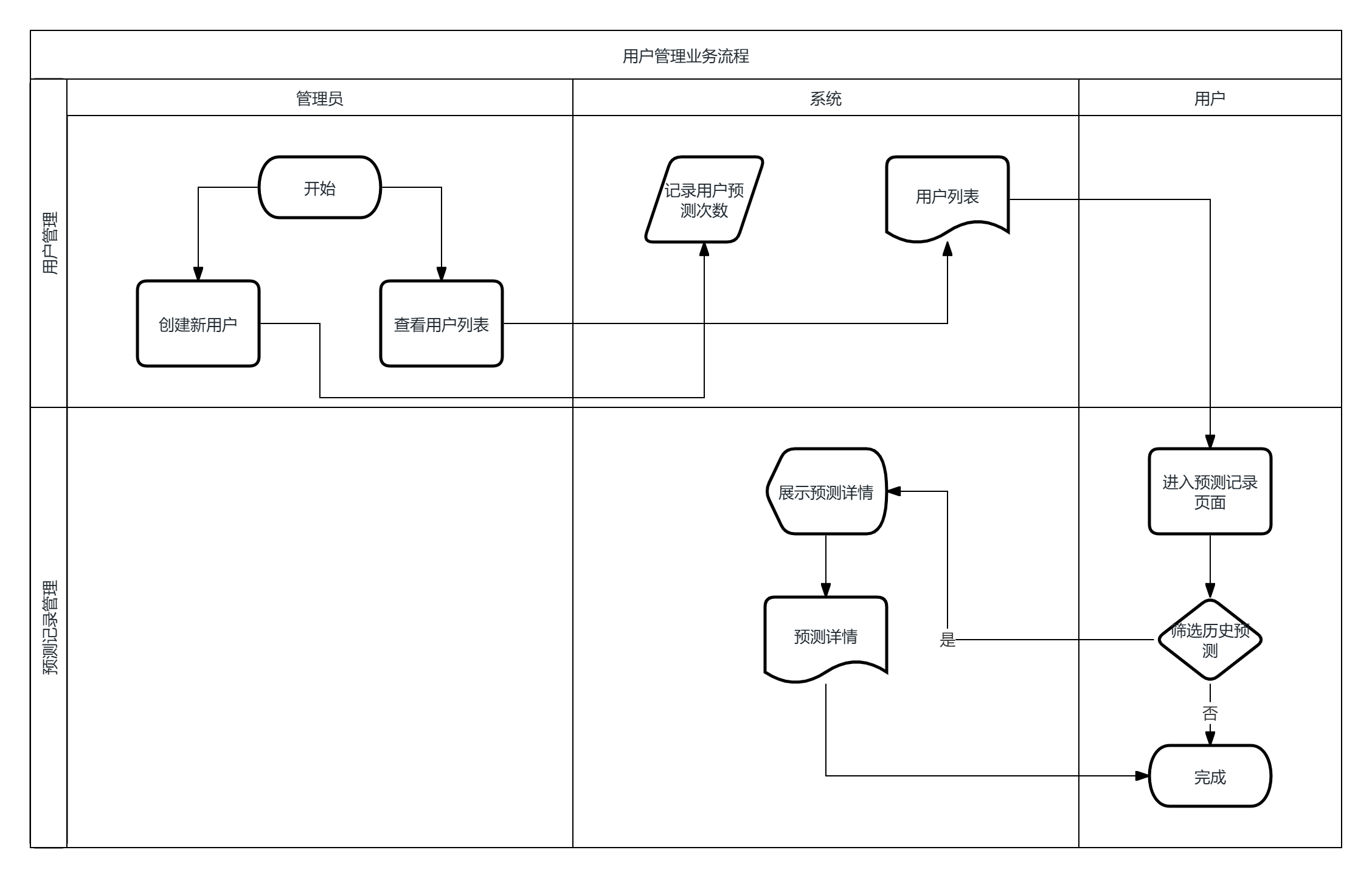
图3-1至图3-5分别展示了上述五个核心业务的流程图,各模块相互独立又通过数据层实现关联,共同构成完整的系统功能体系。
3.2.2 功能需求分析
根据业务流程分析结果,本系统的用户角色可划分为两类:访客用户与系统用户。
访客用户无需登录即可使用系统的核心功能,主要包括数据分析、特征工程、模型训练与对比、风险预测等。数据分析功能要求系统能够对心脏病数据集进行概览统计、特征分布可视化、相关性分析以及数据分页展示。特征工程功能要求系统支持缺失值检测、特征选择(过滤法与嵌入法)以及特征得分可视化。模型训练与对比功能要求系统支持多算法训练、参数网格搜索、交叉验证、模型保存以及性能指标对比。风险预测功能要求系统支持用户输入临床指标、调用选定模型进行预测、生成健康建议以及记录预测结果。
系统用户除具备访客用户所有功能外,还拥有用户管理权限,包括用户创建、用户列表查看、预测记录筛选与查询等功能。系统用户可查看各用户的预测次数与历史预测详情,便于进行用户健康数据追踪与管理。
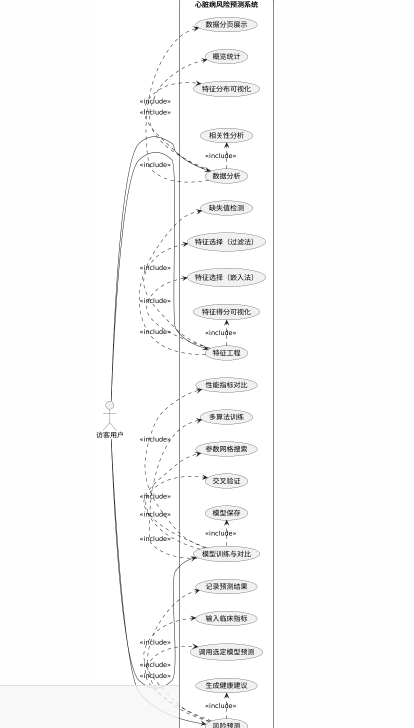
展示了访客用户与系统用户的用例图,明确了不同角色与系统功能之间的交互关系。访客用户主要与数据分析、特征工程、模型训练、预测等用例交互,系统用户在此基础上增加用户管理相关用例。
3 . 3 非功能性需求分析
非功能性需求是保证系统稳定运行与良好用户体验的关键因素,本系统主要从以下维度进行约束。
性能需求:系统核心功能响应时间应控制在可接受范围内,其中数据分析页面数据加载、模型训练与预测接口应在合理时间内完成。对于模型训练等计算密集型操作,系统应提供进度提示,避免用户长时间等待无反馈。
可靠性需求:系统应保证数据处理的准确性,预测结果应与模型实际输出保持一致。在用户输入异常数据或超出合理范围时,系统应给出明确的错误提示,防止程序崩溃。数据库操作应保证事务一致性,避免因异常导致数据不完整。
可扩展性需求:系统架构应支持新算法的灵活集成,模型训练模块通过配置文件管理算法参数,便于后续增加新的机器学习模型。特征工程模块应支持自定义特征处理方法,为后续功能扩展预留接口。
安全性需求:用户预测记录应保证隐私性,不同用户之间无法查阅他人预测详情。系统应防止SQL注入与跨站脚本攻击,对用户输入数据进行必要的过滤与转义。
易用性需求:系统界面布局应清晰合理,功能模块导航明确。图表展示应具有交互性,支持缩放、悬停提示等操作。预测结果应提供可读性强的文本说明,帮助用户理解风险含义与后续建议。
4 系统设计 与实现
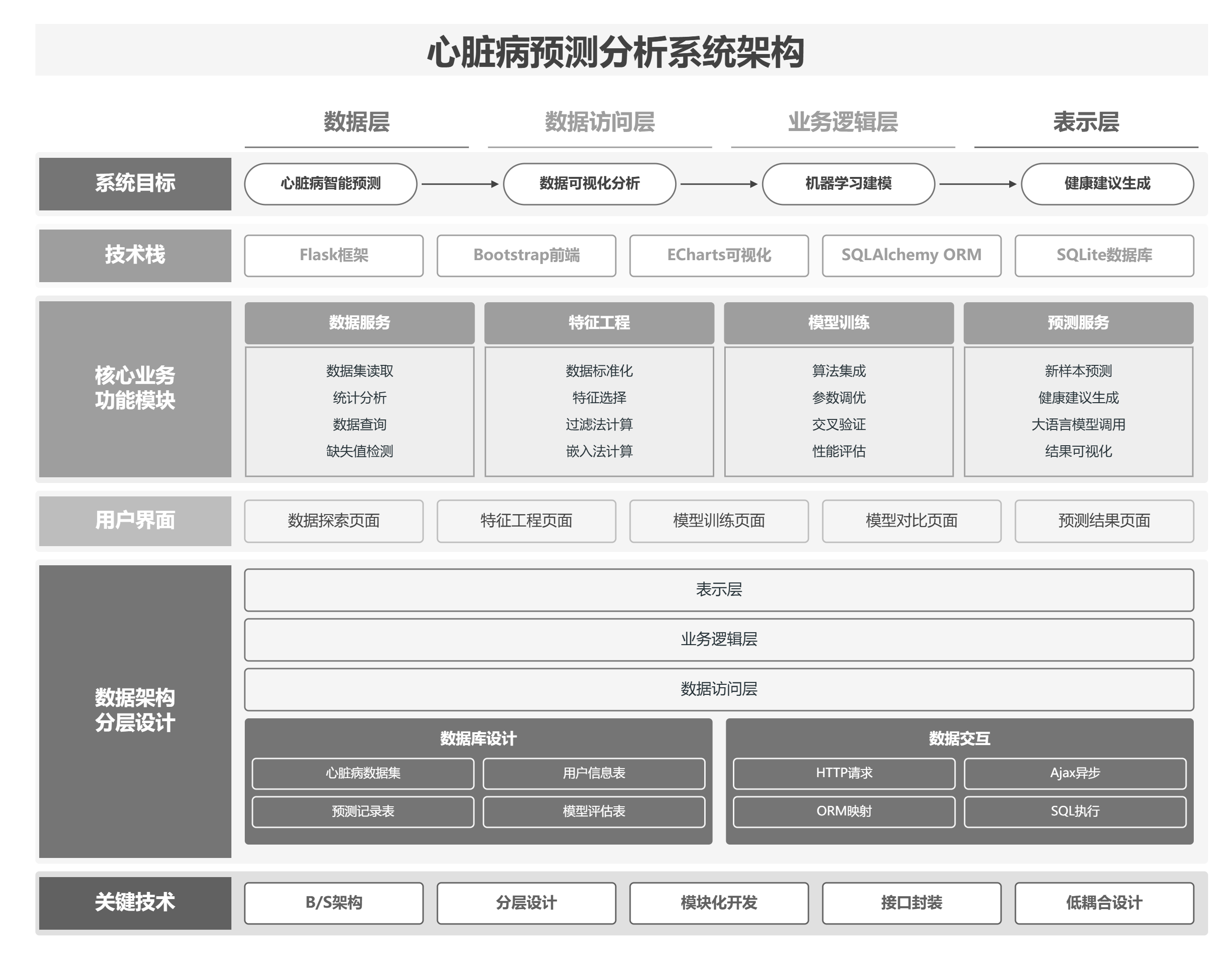
4 .1 架构设计
本系统采用经典的B/S架构模式,基于Flask框架构建分层结构。按照数据流动方向,系统架构自顶向下划分为表示层、业务逻辑层、数据访问层与数据层四个层次。
表示层负责前端页面渲染与用户交互。该层采用Bootstrap框架构建响应式用户界面,通过ECharts库实现数据可视化展示,使用Ajax技术完成与后端的异步数据交互。用户通过浏览器访问各功能页面,提交表单数据或发起请求,表示层将用户操作转换为HTTP请求发送至业务逻辑层,并将返回结果以可视化形式呈现。
业务逻辑层是整个系统的核心处理层,负责接收表示层的请求、调用相应功能模块完成业务处理、封装处理结果并返回。该层包含数据服务模块、特征工程模块、模型训练模块、预测服务模块与用户管理模块。数据服务模块负责数据集的读取、统计与查询;特征工程模块实现数据标准化与特征选择功能;模型训练模块集成多种机器学习算法,完成模型训练、参数调优与性能评估;预测服务模块调用训练好的模型对新样本进行预测,并调用大语言模型生成健康建议;用户管理模块处理用户创建与预测记录查询请求。
数据访问层封装数据库操作,通过SQLAlchemy对象关系映射框架实现对底层数据库的读写访问。该层将业务逻辑层的对象操作转换为SQL语句,执行数据持久化任务,并将查询结果封装为Python对象返回。
数据层采用SQLite关系型数据库,存储原始心脏病数据、用户信息、预测记录以及模型评估结果。各层之间通过定义清晰的接口进行交互,降低了模块间的耦合度,便于后续维护与功能扩展。系统整体架构如图4-1所示。
4 . 2 功能模块设计
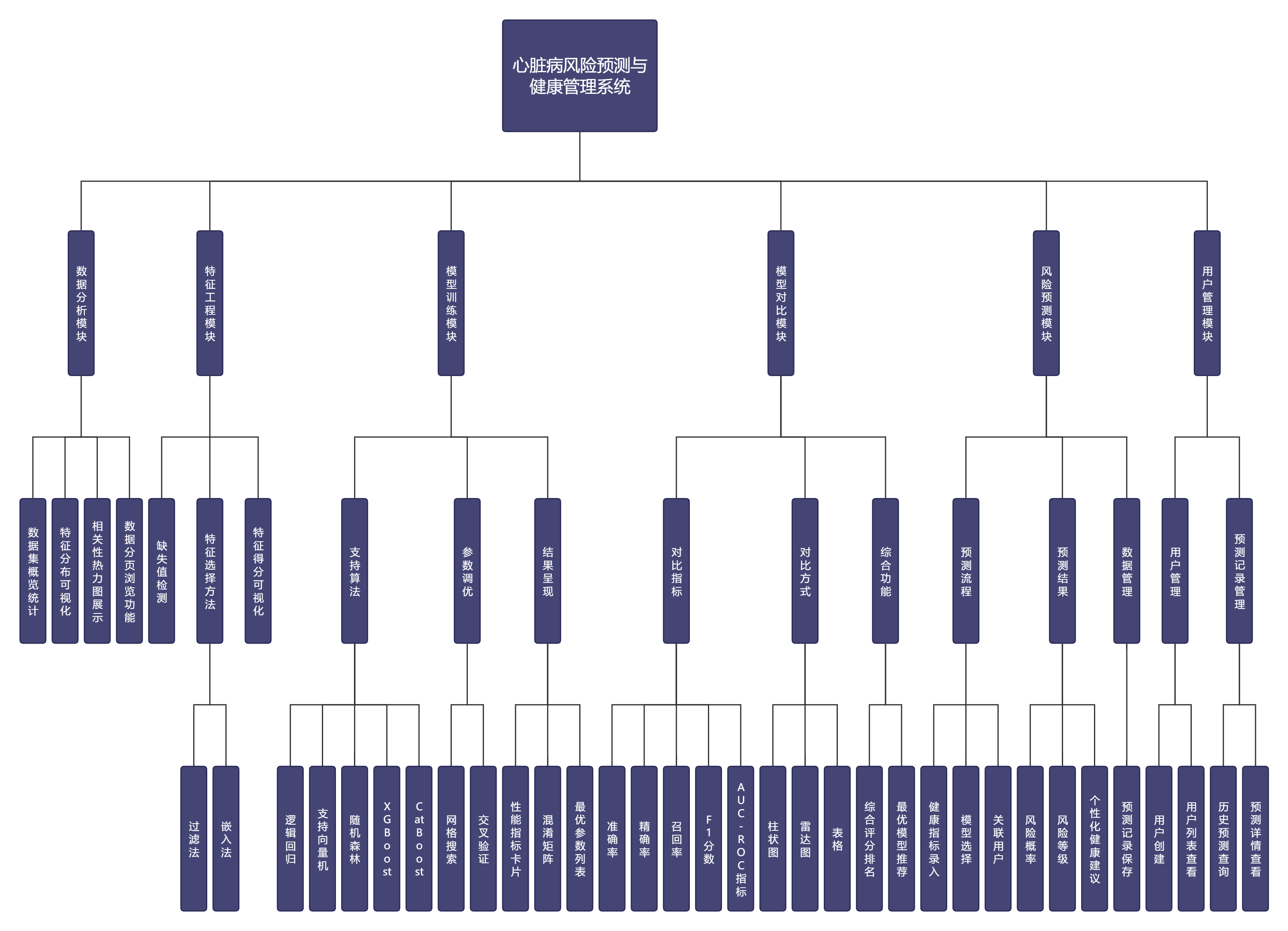
本系统旨在为用户提供一站式的心脏病风险预测与健康管理服务,围绕数据探索分析、特征工程处理、模型训练对比、风险预测评估与用户信息管理等核心任务,构建了功能完备的软件系统。
根据需求分析结果,系统功能模块划分为以下五个核心部分:
数据分析模块:实现数据集概览统计、特征分布可视化、相关性热力图展示以及数据分页浏览功能。该模块帮助用户快速了解数据整体特征与各指标间的关联关系。
特征工程模块:提供缺失值检测、特征选择(过滤法与嵌入法)以及特征得分可视化功能。用户可根据特征重要性排序筛选对预测贡献较大的特征子集。
模型训练模块:支持逻辑回归、支持向量机、随机森林、XGBoost与CatBoost五种算法的训练与参数调优。模块内置网格搜索与交叉验证机制,可自动寻找最优参数组合,并保存训练好的模型文件。训练结果以性能指标卡片、混淆矩阵与最优参数列表形式呈现。
模型对比模块:聚合各模型的历史训练记录,通过柱状图、雷达图与表格等多种方式展示准确率、精确率、召回率、F1分数与AUC-ROC指标对比,给出综合评分排名与最优模型推荐。
风险预测模块:提供健康指标录入界面,支持用户选择预测模型与关联用户。调用已训练模型完成风险预测,返回风险概率与风险等级,通过大语言模型生成个性化健康建议,并将预测记录保存至数据库。
用户管理模块:支持用户创建、用户列表查看与预测记录查询功能。用户可筛选查看历史预测详情,包括输入数据与生成的健康建议。
系统功能模块结构如图4-2所示。
4.3数据库设计
4.3.1 数据关系设计
本系统采用SQLite关系型数据库进行数据存储。数据库设计遵循第三范式,通过外键关联建立表间联系。系统共包含四张数据表:heart_data_zhangsan(心脏病原始数据表)、user_zhangsan(用户表)、prediction_zhangsan(预测记录表)、model_result_zhangsan(模型评估结果表)。
数据关系设计如下:用户表与预测记录表通过用户ID字段建立一对多关系,一个用户可产生多条预测记录;模型评估结果表独立存储各次训练的评估指标,与用户表、预测记录表无直接关联;心脏病原始数据表存储基础样本数据,不与其他表建立外键关系,作为独立的数据源使用。数据关系如图4-3所示。
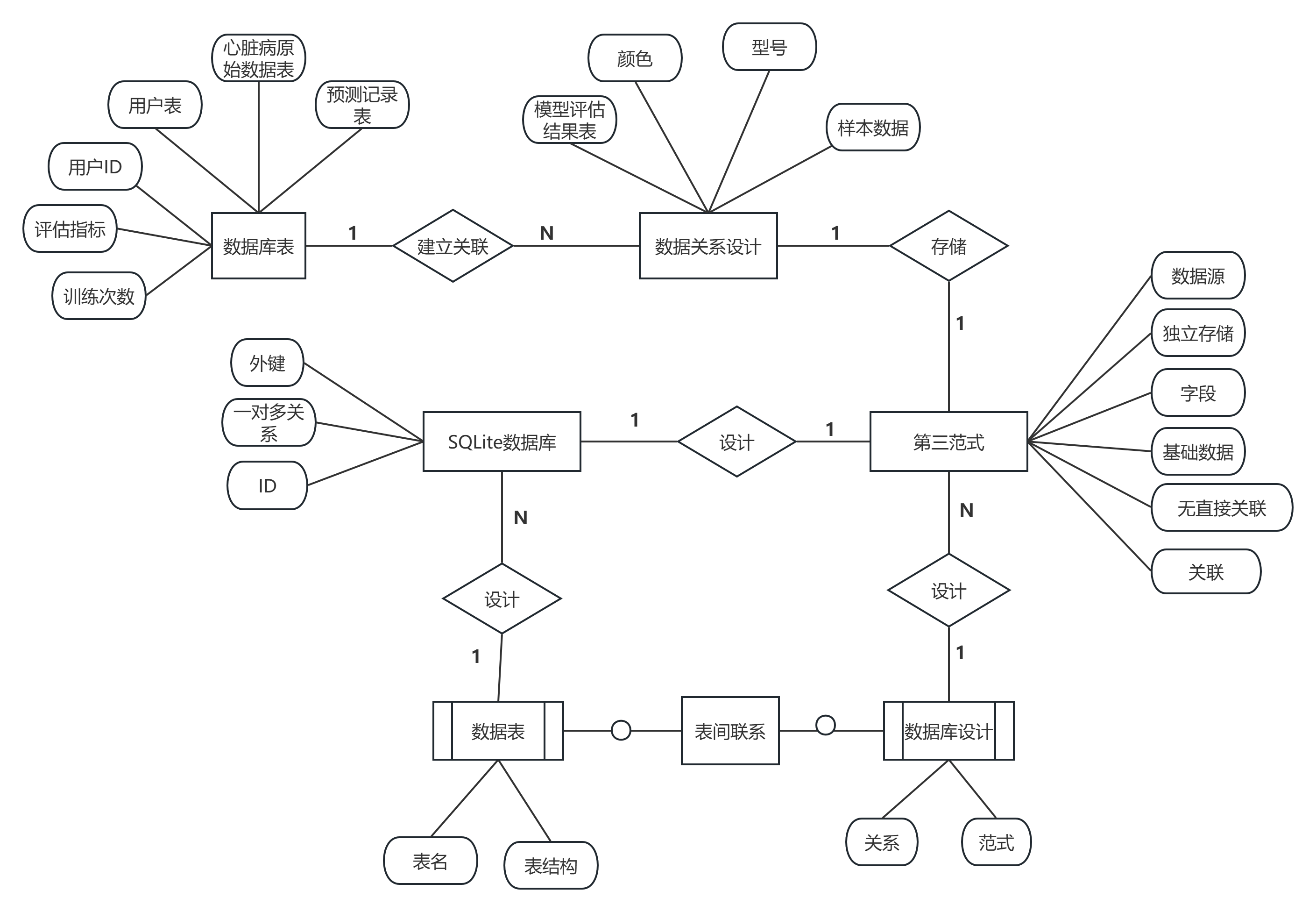
图 4-3 E-R图
4.3.2 数据库表设计
系统数据表由heart_data_zhangsan(心脏病原始数据表)、user_zhangsan(用户表)、prediction_zhangsan(预测记录表)以及model_result_zhangsan(模型评估结果表)组成。以下是各数据库表的详细设计信息。
1、heart_data_zhangsan表记录心脏病数据集中每份样本的临床指标与诊断结果,包含年龄、性别、胸痛类型、静息血压、胆固醇、空腹血糖、静息心电图、最大心率、运动心绞痛、ST段下降、ST段斜率、主要血管数、地中海贫血、患病标签等字段。该表作为系统的基础数据源,在首次启动时自动从CSV文件导入。heart_data_zhangsan数据表结构如表4.1所示。
2、user_zhangsan表记录系统用户的标识信息与创建时间,包含用户唯一标识、用户名与创建时间戳等字段。该表用于区分不同用户的预测记录,支持用户维度的数据统计与筛选。user_zhangsan数据表结构如表4.2所示。
3、prediction_zhangsan表记录每次预测操作的详细信息,包含预测记录标识、关联用户标识、使用的模型名称、用户输入的原始数据、预测结果、风险概率、生成的健康建议与创建时间等字段。其中关联用户标识为外键,参照user_zhangsan表的主键。prediction_zhangsan数据表结构如表4.3所示。
4、model_result_zhangsan表记录每次模型训练的评估指标,包含模型名称、准确率、精确率、召回率、F1分数、AUC-ROC与创建时间等字段。该表用于支持模型性能的历史追溯与对比分析。model_result_zhangsan数据表结构如表4.4所示。
表 4-1 heart_data_zhangsan表
|----------|---------|---------------------------|-------------------------|
| 字段名 | 数据类型 | 约束 | 描述 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 记录唯一标识 |
| age | INTEGER | | 年龄 |
| sex | INTEGER | | 性别(1:男,0:女) |
| cp | INTEGER | | 胸痛类型(0-3) |
| trestbps | INTEGER | | 静息血压(mmHg) |
| chol | INTEGER | | 胆固醇(mg/dl) |
| fbs | INTEGER | | 空腹血糖>120mg/dl(1:是,0:否) |
| restecg | INTEGER | | 静息心电图(0-2) |
| thalach | INTEGER | | 最大心率 |
| exang | INTEGER | | 运动诱发心绞痛(1:是,0:否) |
| oldpeak | REAL | | ST段下降 |
| slope | INTEGER | | ST段斜率(0-2) |
| ca | INTEGER | | 主要血管显色数量(0-3) |
| thal | INTEGER | | 地中海贫血类型(1-3) |
| target | INTEGER | | 患病标签(1:患病,0:健康) |
表 4-2 user_zhangsan表(用户表)
|------------|-----------|---------------------------|--------|
| 字段名 | 数据类型 | 约束 | 描述 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户唯一标识 |
| username | TEXT | UNIQUE | 用户名 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
表 4-3 prediction_zhangsan表(预测记录表)
|-------------|-----------|------------------------------------------|-------------------|
| 字段名 | 数据类型 | 约束 | 描述 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 预测记录唯一标识 |
| user_id | INTEGER | FOREIGN KEY REFERENCES user_zhangsan(id) | 关联用户ID |
| model_name | TEXT | | 使用的模型名称 |
| input_data | TEXT | | 用户输入的原始数据(JSON格式) |
| prediction | INTEGER | | 预测结果(1:高风险,0:低风险) |
| probability | REAL | | 风险概率 |
| solution | TEXT | | 生成的健康建议 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
表 4-4 model_result_zhangsan表(模型评估结果表)
|------------|-----------|---------------------------|----------|
| 字段名 | 数据类型 | 约束 | 描述 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 评估记录唯一标识 |
| model_name | TEXT | | 模型名称 |
| accuracy | REAL | | 准确率 |
| precision | REAL | | 精确率 |
| recall | REAL | | 召回率 |
| f1_score | REAL | | F1分数 |
| auc_roc | REAL | | AUC-ROC值 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
4 . 4 模型设计与实现
4.4.1 数据集信息
本研究所采用的数据集来源于UCI心脑血管疾病数据库,包含303份样本记录,每份样本涵盖14项临床指标与诊断结果。特征维度包括年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖、静息心电图结果、最大心率、运动诱发心绞痛、ST段下降幅度、ST段斜率、主要血管显色数量、地中海贫血类型。目标变量为是否患有心脏病,其中患病样本165例,健康样本138例,样本分布相对均衡。
4.4.2 数据集划分
为保证模型评估的可靠性,采用分层抽样策略将数据集划分为训练集与测试集。分层抽样确保训练集与测试集中正负样本比例与原数据集保持一致,避免因样本分布不均导致的评估偏差。默认划分比例为训练集80%、测试集20%,用户可在界面中调整该比例。划分后的训练集用于模型训练与交叉验证,测试集用于最终性能评估。
4.4.3 数据处理
数据处理阶段主要完成标准化与特征选择两项工作。采用标准差标准化方法对数值型特征进行归一化处理,使各特征量纲统一到相同尺度。标准化参数(均值与标准差)基于训练集计算,并保存用于测试集与预测样本的标准化处理。特征选择提供过滤法与嵌入法两种策略。过滤法基于方差分析计算各特征与目标变量的统计相关性,选取得分最高的K个特征。嵌入法采用递归特征消除策略,基于逻辑回归模型迭代训练,每次剔除权重最小的特征直至保留指定数量特征。
4.4.4 模型搭建设计
系统集成逻辑回归、支持向量机、随机森林、XGBoost与CatBoost五种机器学习模型。各模型采用统一的接口设计,通过配置参数调用对应的算法实现。逻辑回归模型采用L2正则化,通过网格搜索优化正则化系数C与惩罚项类型。支持向量机采用径向基核函数,通过网格搜索优化惩罚系数与核函数参数。随机森林模型通过网格搜索优化决策树数量与最大深度。XGBoost与CatBoost模型通过网格搜索优化学习率、树深度与迭代次数等超参数。模型训练采用五折交叉验证评估模型稳定性,并基于网格搜索选取最优参数组合。
4.4.5 模型训练评估
模型训练流程包括数据加载、特征选择、标准化、数据集划分、网格搜索、交叉验证、模型保存与评估指标计算。评估指标包括准确率、精确率、召回率、F1分数与AUC-ROC。准确率衡量整体预测正确比例,精确率关注预测为正类的样本中实际为正类的比例,召回率反映实际正类被正确识别的比例,F1分数是精确率与召回率的调和平均,AUC-ROC衡量模型区分正负类的能力。实验结果显示,集成模型(随机森林、XGBoost、CatBoost)在各项指标上均优于单一模型,其中XGBoost在AUC-ROC指标上表现最优,表明其在正负类区分能力方面具有较好性能。
4.4.6 模型消融实验
为验证特征选择与数据标准化对模型性能的影响,设计消融实验进行对比分析。实验设置三组对比条件:原始特征集与标准化处理组合、特征选择与标准化处理组合、原始特征集与未标准化组合。实验结果表明,标准化处理对梯度优化类算法(逻辑回归、支持向量机)性能提升明显,对树模型影响相对较小。特征选择在去除冗余特征后,能够在保持或略提升模型精度的同时缩短训练时间。嵌入法特征选择在多数算法上的效果优于过滤法,表明考虑特征交互关系有助于筛选更具预测能力的特征子集。消融实验验证了本系统所采用的数据处理流程对模型性能的正面影响。
5 系统开发与实现
5 .1 开发环境
本系统采用B/S架构模式进行开发,后端基于Python 3.9与Flask 2.3框架构建,数据库选用轻量级嵌入式数据库SQLite 3.39,前端采用HTML5、CSS3与JavaScript技术栈,数据可视化基于ECharts 5.4库实现。系统开发环境如表5.1所示。
表 5-1 系统开发环境
|--------------------------|-------------------------------------------------------|
| 硬件环境 | 软件环境 |
| CPU:Intel Core i7-12700H | 操作系统:Windows 11 专业版 22H2 |
| 内存:16GB DDR4 3200MHz | 数据库:SQLite 3.39.4 |
| 硬盘:512GB NVMe SSD | Python版本:3.9.13 |
| 显示器分辨率:1920×1080 | Flask版本:2.3.2 |
| 网络环境:局域网/互联网 | 浏览器:Chrome 120.0、Edge 120.0 |
| - | 开发工具:PyCharm Professional 2023.3、VS Code 1.85 |
| - | 机器学习库:scikit-learn 1.3.2、XGBoost 2.0.3、CatBoost 1.2.2 |
5 . 2 功能模块实现
本系统围绕数据分析、特征工程、模型训练、风险预测与用户管理五个核心功能模块进行实现。各模块代码实现遵循模块化设计原则,通过清晰的数据流转路径完成功能闭环
5.2.1 数据分析模块实现
数据分析模块负责从数据库读取心脏病原始数据,进行统计计算与可视化展示。该模块在Flask路由中定义/api/data/overview、/api/data/correlation、/api/data/distribution/<feature>与/api/data/list四个接口,分别提供数据概览统计、相关性矩阵、特征分布与数据分页查询功能。
数据概览接口实现时,通过pandas的read_sql_query方法从数据库中读取全量数据,利用describe方法生成统计信息,通过value_counts统计目标变量分布,通过isnull().sum()检测缺失值。相关性矩阵接口基于DataFrame的corr方法计算皮尔逊相关系数,返回列名与相关系数矩阵供前端热力图渲染。
特征分布接口根据前端传入的特征名称,返回该特征的值列表与对应的目标变量值,前端据此绘制分组直方图展示健康与患病群体的分布差异。数据分页查询接口接收页码与每页记录数参数,通过SQL的LIMIT与OFFSET子句实现分页查询,同时返回总记录数与总页数用于分页控件渲染:

实现效果如图5.1所示。页面顶部展示样本总数、患病人数、健康人数与患病率四个统计卡片,中部左侧显示相关性热力图,右侧显示特征重要性排序图,底部展示数据预览表格与分页控件。
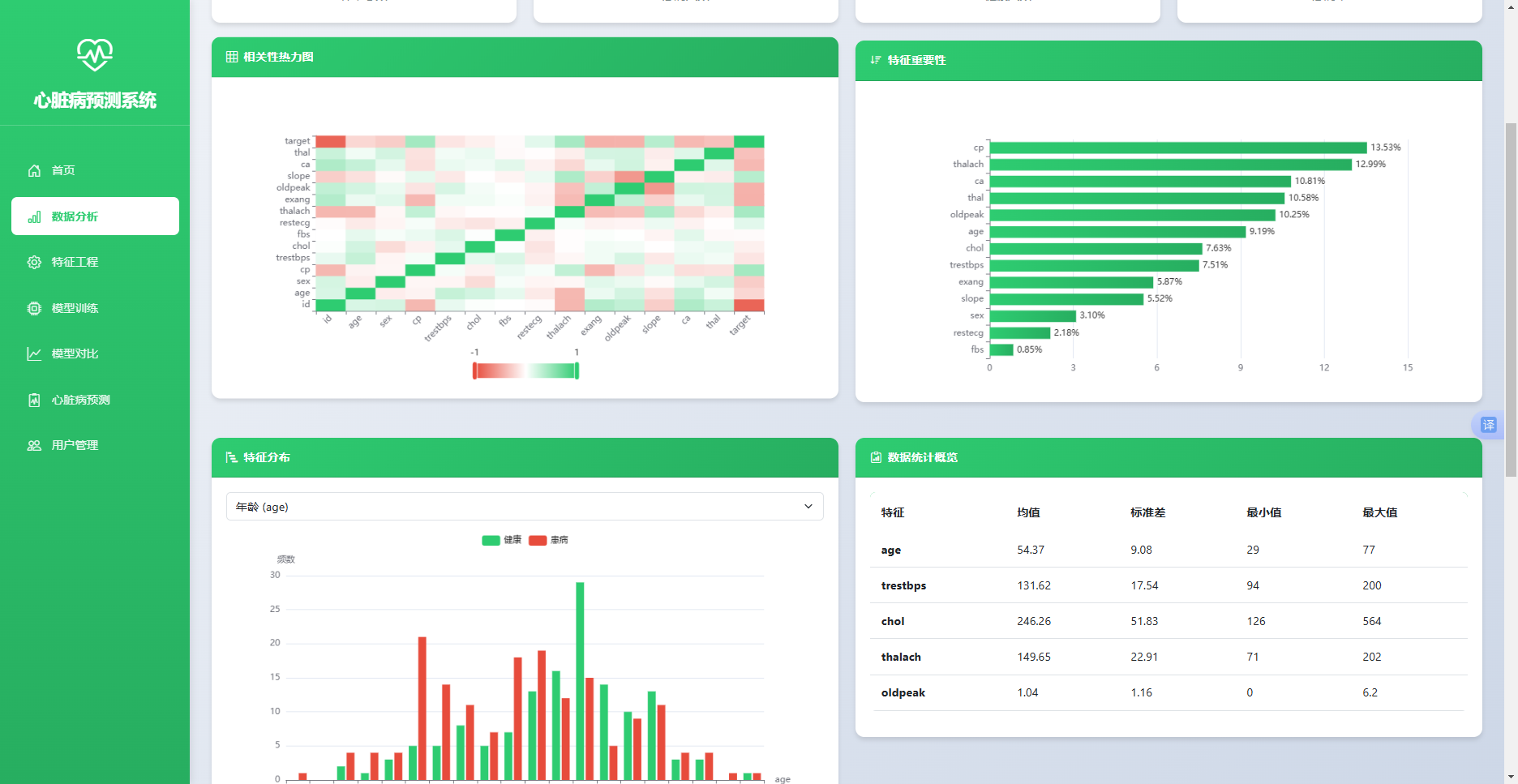
图 5-1 数据分析 模块
5.2.2 特征工程模块实现
特征工程模块提供缺失值检测、特征选择(过滤法与嵌入法)与特征得分可视化功能。特征选择接口/api/feature/select接收方法类型与保留特征数量参数,根据选择的方法调用不同的特征选择算法。
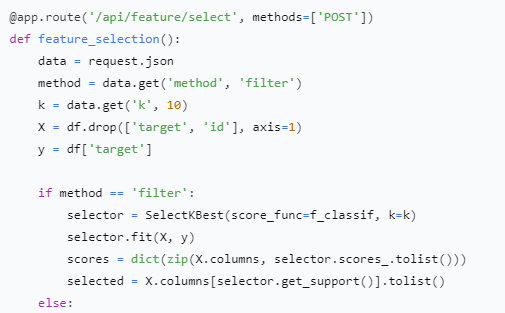
过滤法采用SelectKBest结合f_classif评分函数,计算每个特征与目标变量的方差分析F值,选取得分最高的K个特征。嵌入法采用RFE递归特征消除策略,以逻辑回归为基学习器,通过迭代训练逐步剔除权重系数最小的特征,直至保留指定数量特征。特征选择结果返回特征得分字典与选中的特征列表,前端据此更新特征得分图表,选中的特征以绿色高亮显示。
核心代码如下所示:
实现效果如图5.2所示。用户可在特征选择面板中选择方法类型与特征数量,点击执行后,右侧特征得分图表展示各特征得分,选中的特征以绿色柱状图呈现,选中特征列表以标签形式展示于筛选结果区域。
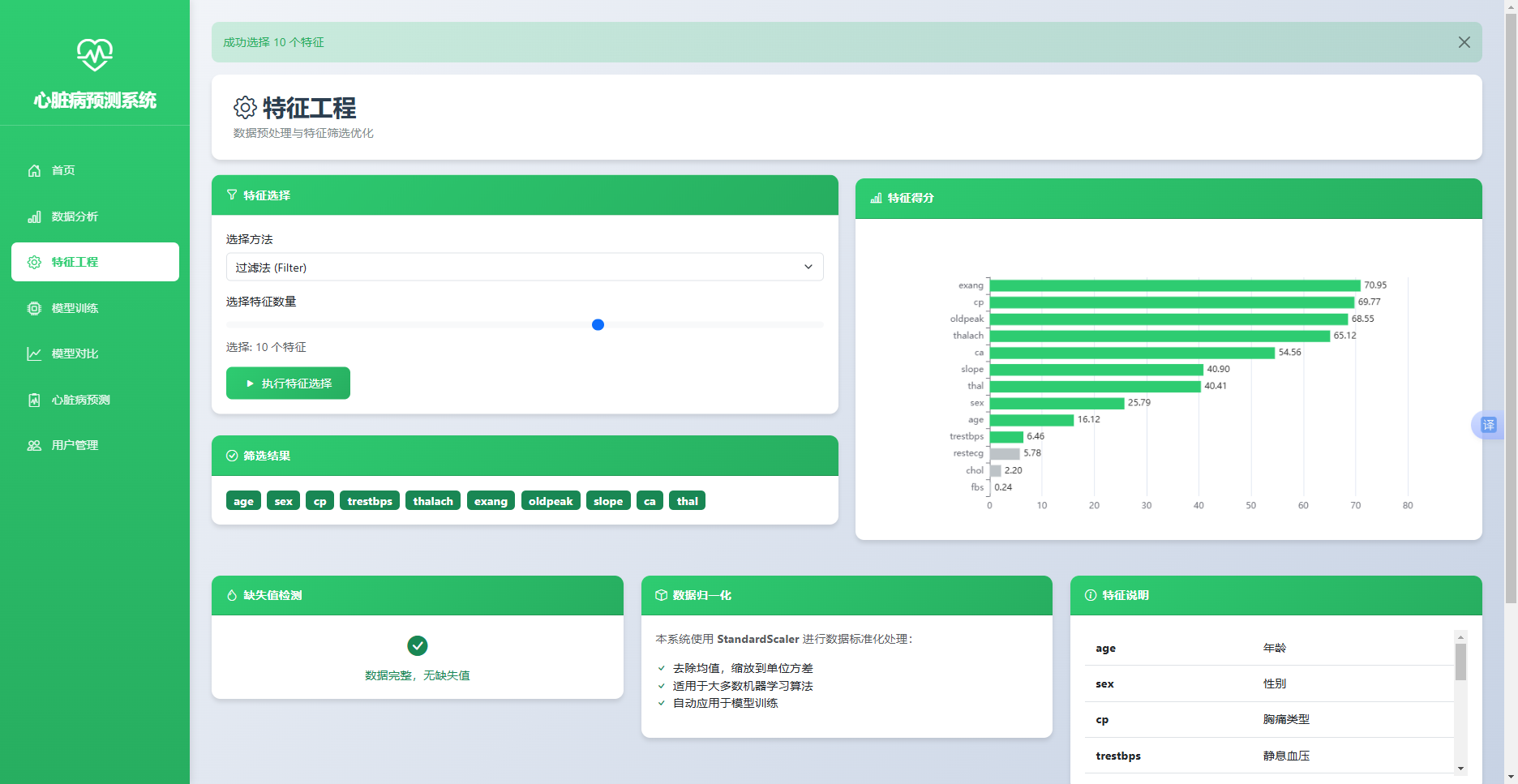
图 5-2 特征工程模块
5.2.3 模型训练与对比模块实现
模型训练模块是系统的核心计算部分,通过/api/model/train接口接收模型类型、特征列表与测试集比例参数,完成数据预处理、模型训练、参数调优与评估指标计算。
训练流程首先根据传入的特征列表从数据集中提取特征矩阵,调用StandardScaler进行标准化处理,通过train_test_split划分训练集与测试集。根据模型类型创建对应的分类器实例,定义网格搜索参数空间,调用GridSearchCV进行五折交叉验证搜索最优参数。训练完成后,最优模型通过joblib持久化保存至models目录,标准化器同样保存用于预测阶段的预处理。
评估指标计算包括准确率、精确率、召回率、F1分数与AUC-ROC,通过accuracy_score、precision_score、recall_score、f1_score与roc_auc_score函数计算。混淆矩阵通过confusion_matrix计算并以二维列表形式返回。模型评估结果同时写入model_results表用于历史追溯与对比展示。
核心代码如下所示:

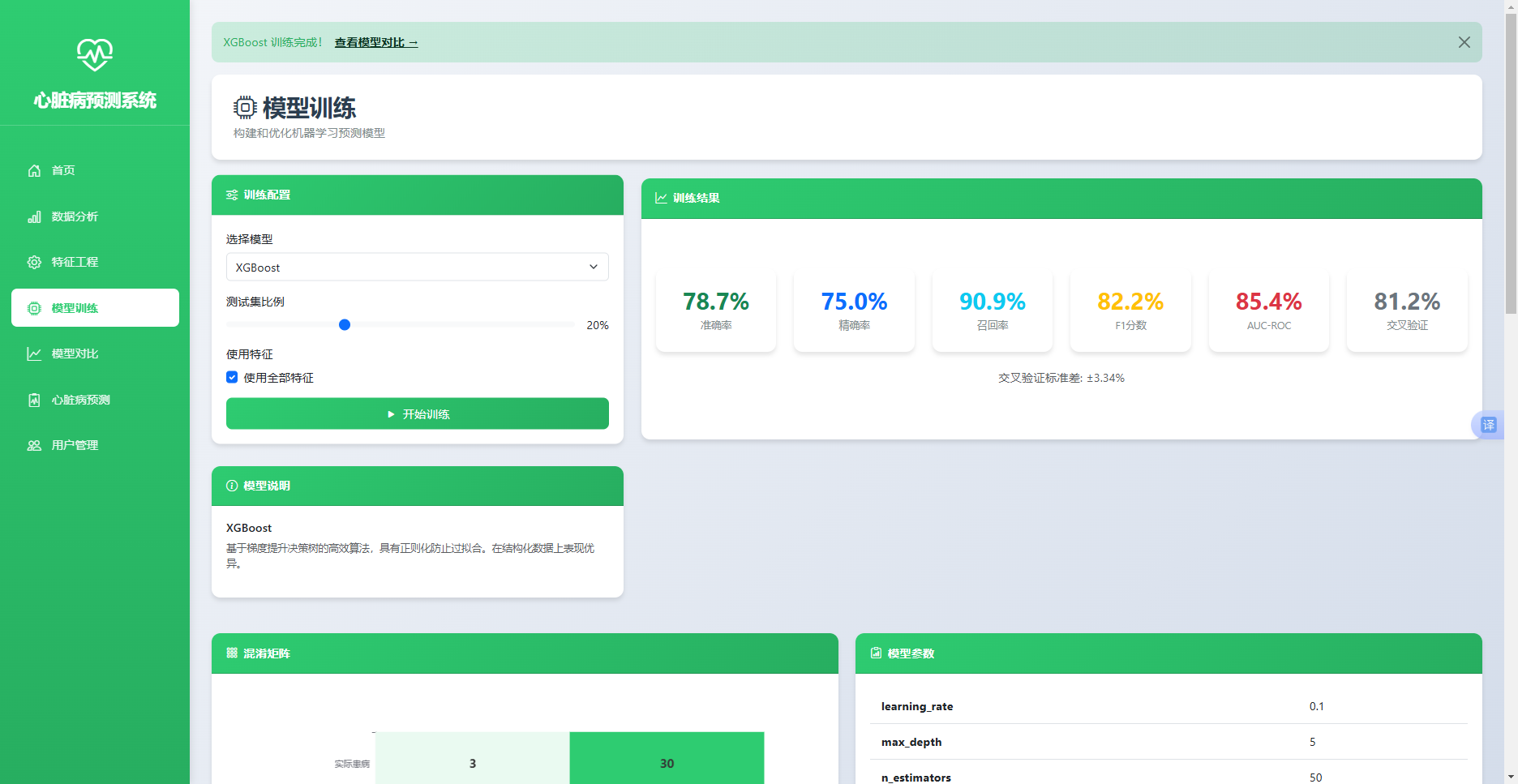
图 5-3 模型训练
模型训练实现效果如图5.3所示。训练页面左侧提供模型选择、测试集比例调节与特征选择面板,右侧以卡片形式展示准确率、精确率、召回率、F1分数、AUC-ROC与交叉验证均值六项指标。底部混淆矩阵以热力图形式呈现,模型参数区域展示网格搜索选出的最优超参数组合。
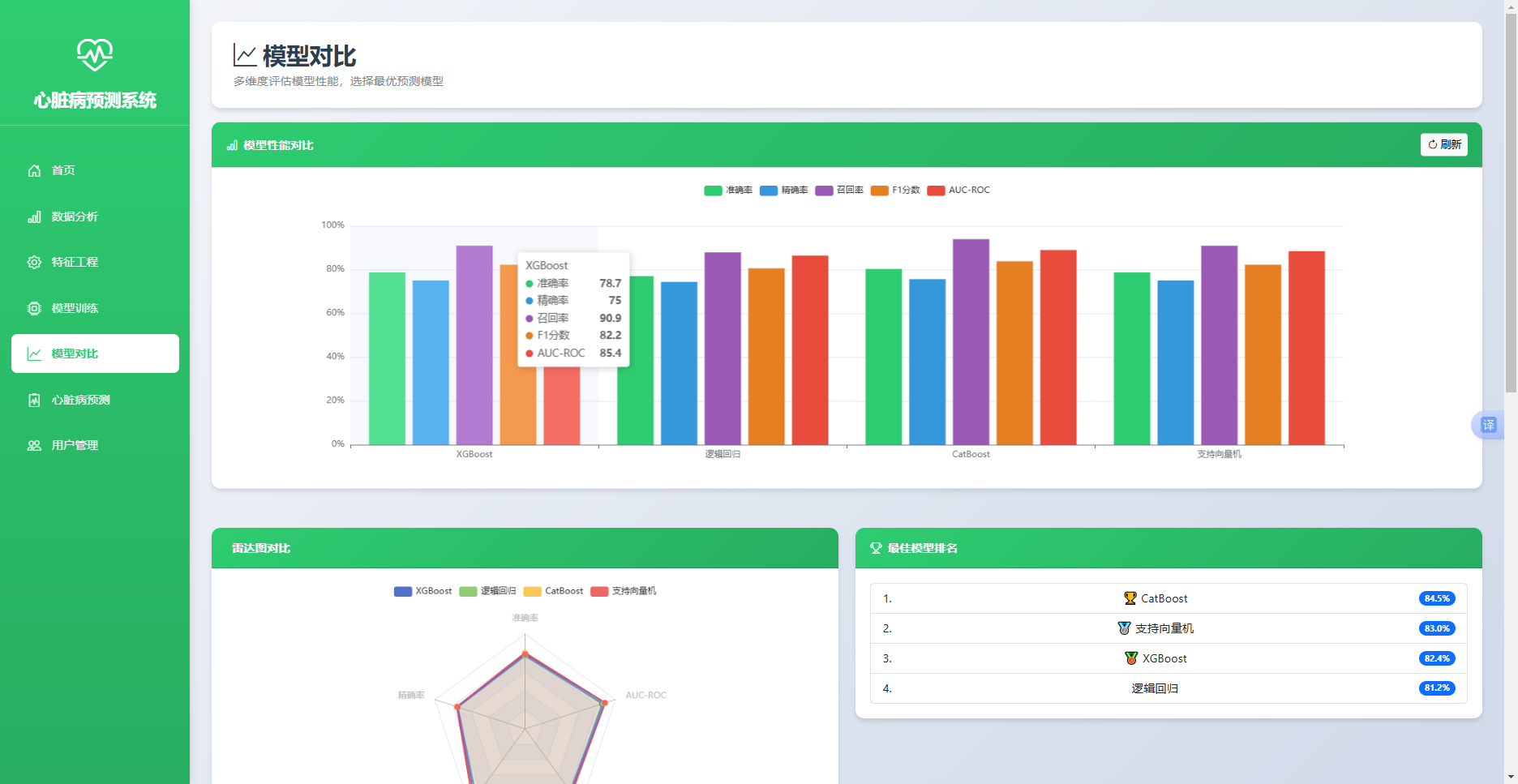
模型对比模块通过/api/model/results接口获取历史训练记录,前端聚合各模型的最新训练结果,通过柱状图对比五项指标,通过雷达图展示各模型在多维指标上的综合表现,并以表格形式列出详细指标与综合评分排名,推荐综合评分最高的模型用于预测。实现效果如图5.4所示。
5.2.4 风险预测模块实现
风险预测模块是系统面向用户的核心功能接口,通过/api/predict接收模型选择、用户标识与输入数据,完成预测并生成健康建议。
预测流程首先根据模型名称加载对应的模型文件与标准化器,将用户输入的13项临床指标按固定特征顺序构建为NumPy数组,调用标准化器的transform方法进行标准化处理。标准化后的特征输入模型,通过predict方法获取预测类别,通过predict_proba方法获取风险概率。预测结果以整数形式返回,风险概率保留浮点数格式。
健康建议生成是本模块的创新部分,通过调用DeepSeek大语言模型API实现。系统将用户输入的临床指标与预测结果组装为结构化提示词,向API发送请求,设置温度为0.7控制生成文本的随机性,设置最大令牌数为1000控制回答长度。API返回的内容经解析后作为健康建议保存至预测记录。若API调用失败或网络异常,系统自动切换至备用方案,根据风险等级生成预设的健康建议模板,确保功能可用性。
核心代码如下所示:

图 5-4 模型预测
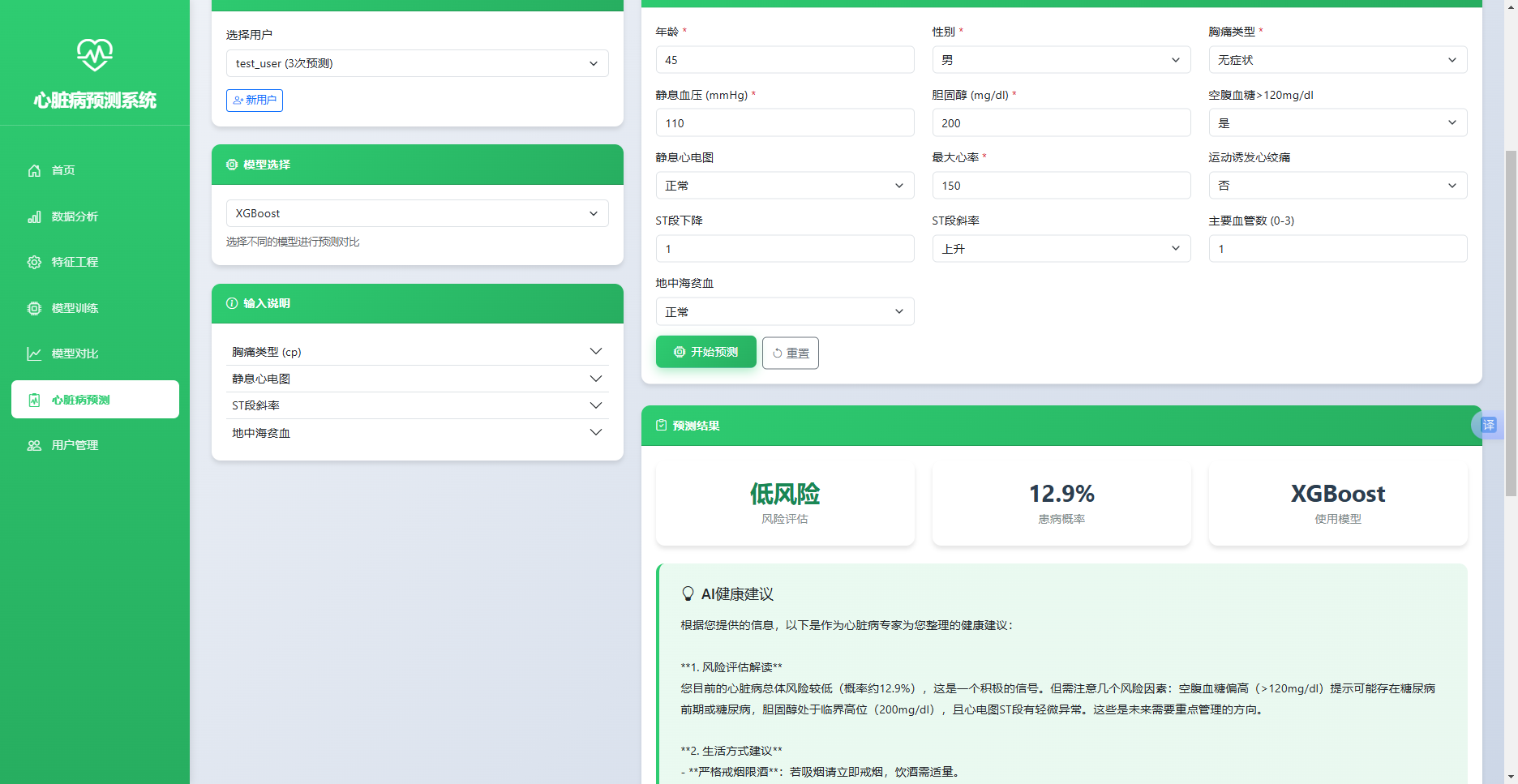
实现效果如图5.5所示。预测页面左侧提供用户选择、模型选择与输入字段说明,右侧表单包含13项健康指标输入框。提交预测后,结果区域展示风险等级、风险概率与使用模型,底部以卡片形式展示大语言模型生成的个性化健康建议,内容涵盖风险评估解读、生活方式建议、饮食建议、运动建议、后续检查建议与紧急情况处理六大模块。
5.2.5 用户管理模块实现
用户管理模块通过/api/users接口实现用户创建与列表查询功能。用户创建接口接收用户名参数,校验非空与唯一性约束后插入user表,返回新用户ID与用户名。用户列表接口通过左连接查询用户表与预测记录表,统计各用户的预测次数,按创建时间倒序排列。
预测记录查询接口/api/predictions支持用户筛选参数,根据用户ID过滤记录后返回预测历史,每条记录包含模型名称、预测结果、风险概率、生成时间与健康建议详情。前端通过模态框展示预测详情的输入数据与健康建议内容。实现效果如图5.6所示。
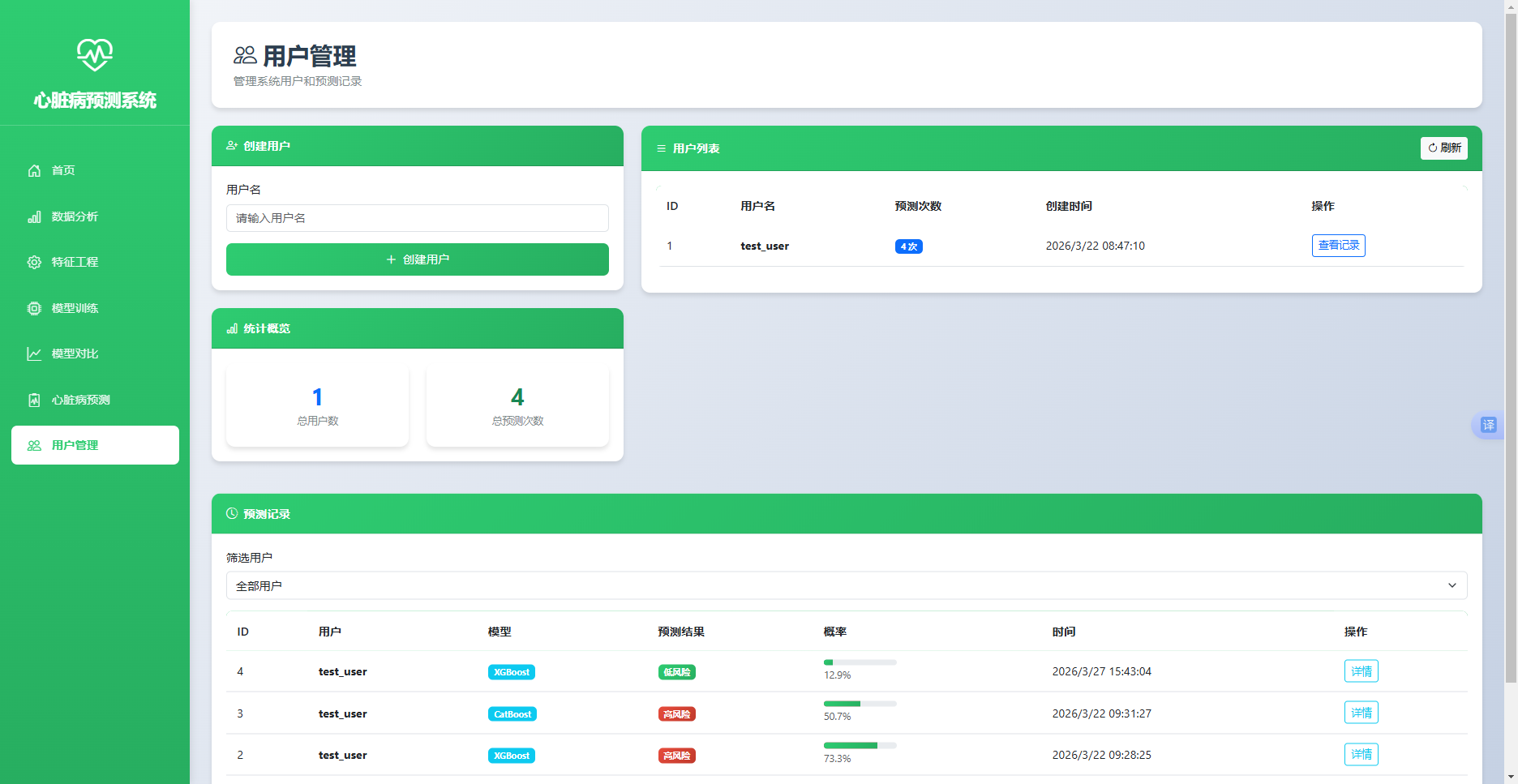
用户管理页面顶部提供创建用户表单与统计概览,用户列表展示用户ID、用户名、预测次数与创建时间,支持点击查看记录筛选。底部预测记录表格支持按用户筛选,每条记录后提供详情按钮,点击后在模态框中展示原始输入数据与AI生成的健康建议完整内容。