1. 为什么需要模仿学习
近年来,人形机器人在运动控制领域取得了令人瞩目的进展。我们已经能够看到机器人完成打拳、跑步、跳舞等高度动态的动作。这些成果的背后,隐藏着一个核心技术命题:如何让机器人像人一样自然地运动?
传统的强化学习方法通过手工设计奖励函数来引导机器人学习动作。然而,对于复杂的全身运动行为,手工奖励函数的设计极其困难------研究者需要精确量化"什么是自然的行走"、"什么是协调的手臂摆动",这些看似直觉性的判断在数学上难以表达。更棘手的是,不恰当的奖励函数往往导致机器人发展出"投机取巧"的策略:虽然在数值上最大化了奖励,但产生的动作极不自然,甚至在物理上不可行。

图:ASAP项目展示的模仿投篮动作,机器人通过学习人类运动数据实现了自然的投篮姿态
模仿学习(Imitation Learning, IL)提供了一条不同的路径。其核心思想是:与其费力定义"好的运动是什么样的",不如直接让机器人观察人类的运动数据,从中学习运动的规律。形式化地说,模仿学习的优化目标是最小化策略分布与专家策略分布之间的差异:
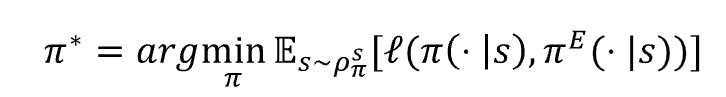
这一思路的优势在于:人类的运动捕捉数据天然包含了"自然运动"的全部信息------关节的协调配合、重心的平稳转移、步态的节奏韵律------这些信息无需研究者逐一编码,而是由数据本身隐式提供。
2. 两条技术路线的分野:跟踪奖励 vs 对抗模仿
当前机器人模仿学习领域存在两条主流技术路线,它们在方法论上有着根本性的差异。
2.1 基于跟踪奖励函数的方法
以DeepMimic、H2O(Human to Humanoid)、ExBody为代表的方法,其核心思路是"逐帧跟踪"。系统在每个时间步将机器人的当前姿态与参考轨迹中的目标姿态进行比较,计算姿态误差作为奖励信号。策略网络的训练目标是最小化这个跟踪误差,使机器人的运动尽可能精确地复现参考轨迹。
图:H2O及其后续工作omniH2O、ASAP,以及ExBody系列工作,均采用基于跟踪奖励函数的方法
这类方法的优势在于训练稳定、收敛可靠,能够高保真地复现参考动作。但其局限性同样明显:
- 策略网络在推理阶段仍然需要持续提供参考轨迹作为输入,这限制了机器人的自主性;
- 对数据集规模和策略网络参数规模要求较高,如果两者不足,策略在数据集域外的动作上难以保证泛化性;
- 需要精心设计相位同步机制,将策略网络与参考动作对齐。
BeyondMimic:跟踪路线的最新进化
在跟踪奖励方法的谱系中,2025年发表的 BeyondMimic(From Motion Tracking to Versatile Humanoid Control via Guided Diffusion )代表了这条路线的最新进化方向。它不满足于"仅仅跟踪",而是试图回答一个更深层的问题:跟踪学到的运动技能,能否被复用到全新的任务中?
BeyondMimic 的架构分为两个阶段:
第一阶段:大规模运动跟踪管线。 与DeepMimic/H2O类似,BeyondMimic首先训练一组高质量的运动跟踪策略,能够在真机(Unitree G1)上复现跳跃旋转、冲刺、侧手翻等高动态动作。关键改进在于其管线的可扩展性------使用统一的MDP配置和共享超参数,无需为每个动作片段单独调参,即可处理数分钟长的动捕序列。
第二阶段:引导扩散策略蒸馏。 这是BeyondMimic真正"Beyond"的地方。它将第一阶段学到的运动原语(motion primitives)蒸馏到一个统一的扩散策略(Diffusion Policy)中。这个扩散策略在推理时可以通过简单的代价函数实现零样本(zero-shot)任务适配------无需重新训练,机器人就能完成路径点导航、摇杆遥操作、避障等下游任务。
BeyondMimic 的两阶段架构:
阶段1:运动跟踪(与传统方法一致)
人类动捕数据 → 跟踪奖励训练 → 高质量运动策略
↓
阶段2:扩散策略蒸馏(核心创新)
多个运动策略 → 蒸馏为统一扩散模型 → 引导采样实现零样本任务适配
↓
导航 / 遥操作 / 避障...这意味着BeyondMimic在保留跟踪方法"高保真复现"优势的同时,通过扩散模型解决了传统跟踪方法"推理时仍需参考轨迹"的核心局限。从某种意义上说,BeyondMimic证明了跟踪路线并非死胡同------只要在上层引入足够强大的生成模型,跟踪策略学到的运动技能完全可以被泛化和复用。
2.2 基于生成式对抗模仿学习的方法(AMP)
AMP(Adversarial Motion Priors)代表了另一条截然不同的路线。它不要求机器人逐帧跟踪某条特定轨迹,而是训练一个判别器网络来学习参考数据的"运动风格"。判别器的任务是区分"来自真实数据的运动"和"策略网络生成的运动",而策略网络的目标则是"欺骗"判别器,使自己生成的运动在统计分布上与真实数据无法区分。
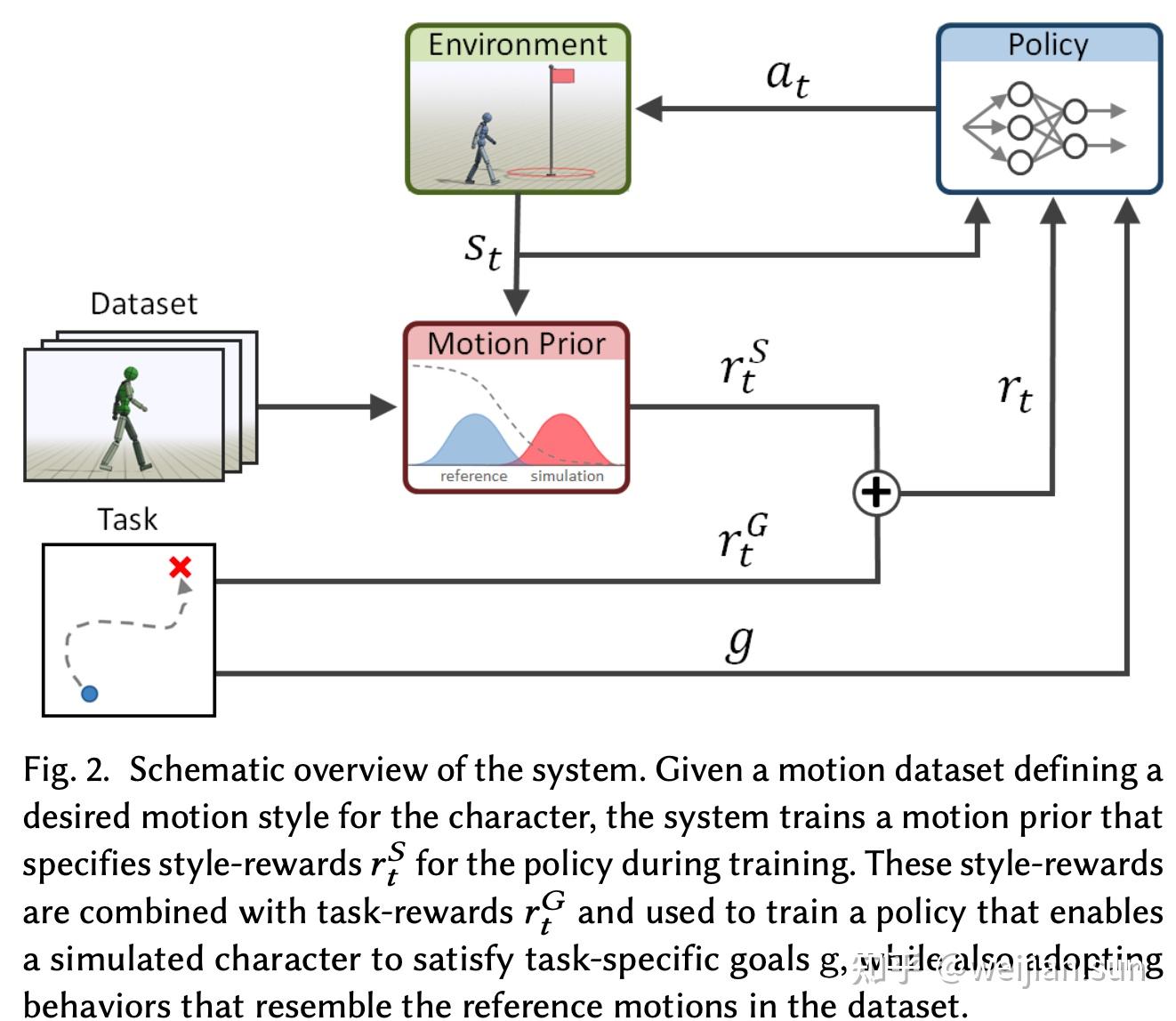
图:AMP系统架构示意图。运动数据集M提供风格参考,判别器D区分真实与生成运动,策略网络在任务奖励和风格奖励的共同驱动下学习
这种方法的本质区别在于:跟踪方法学习的是"如何精确复现一条轨迹",而AMP学习的是"什么样的运动看起来是自然的"。前者是轨迹级别的模仿,后者是分布级别的模仿。这意味着AMP只需少量参考数据即可完成单一风格的动作学习,并且在使用阶段不需要持续提供参考轨迹------风格信息已经内化到了策略网络中。
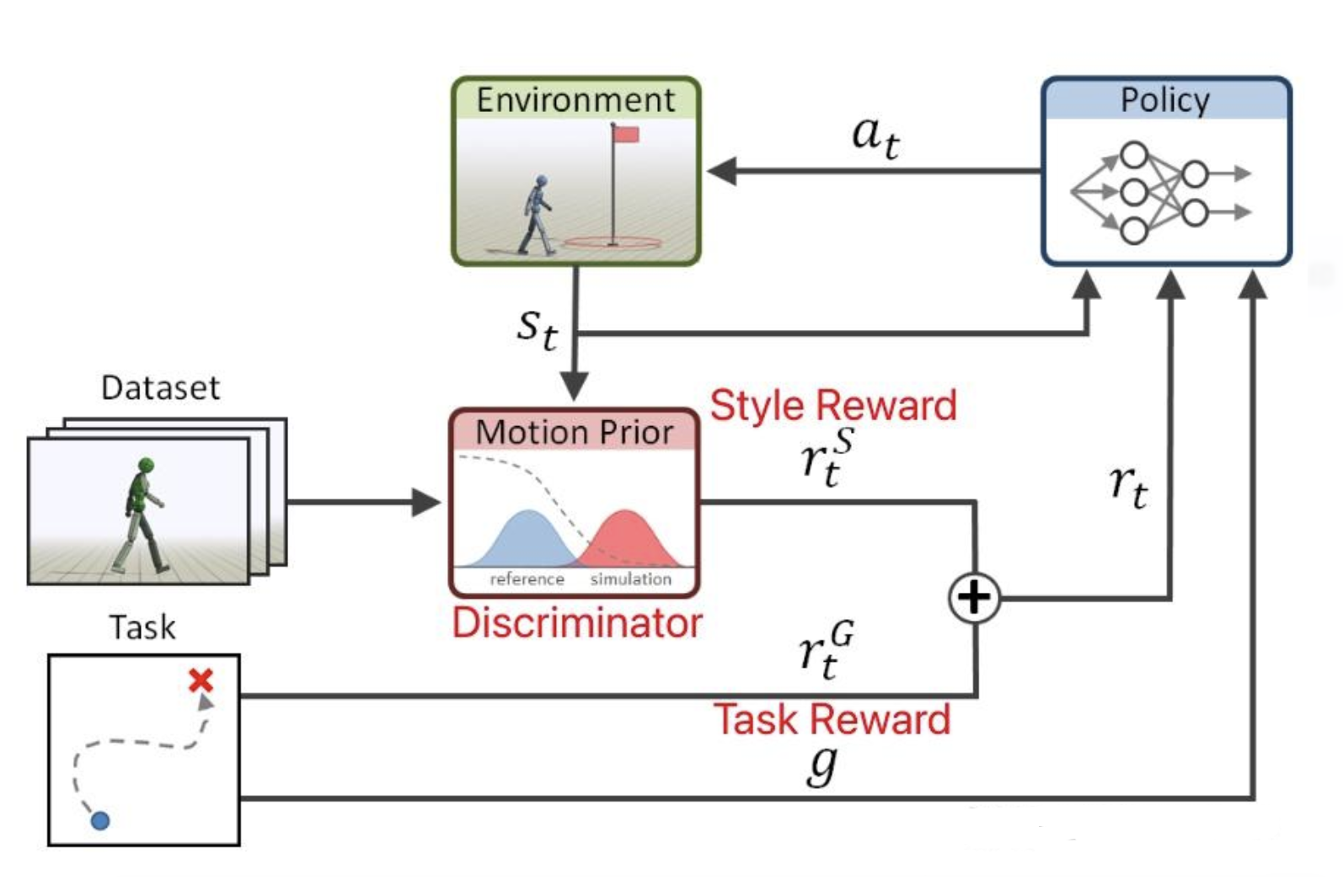
图:AMP能够通过少量动作片段实现多个动作的顺滑拼接,无需显式的动作规划器
下表总结了两种方法的核心差异:
| 维度 | 跟踪奖励方法(DeepMimic/H2O/ExBody) | 对抗模仿方法(AMP) |
|---|---|---|
| 模仿粒度 | 逐帧跟踪特定轨迹 | 学习运动分布的风格特征 |
| 推理依赖 | 需要持续提供参考轨迹 | 无需参考轨迹,风格已内化 |
| 数据需求 | 大规模高质量数据集 | 少量风格片段即可 |
| 泛化能力 | 受限于数据集覆盖范围 | 可自动组合和泛化动作 |
| 训练难度 | 相对稳定 | 对抗训练存在不稳定性 |
| 核心机制 | 姿态误差最小化 | GAN判别器 + 风格奖励 |
2.3 为什么两条路线并存?------选择背后的工程权衡
一个自然的问题是:既然AMP看起来更"优雅"(不需要逐帧跟踪、数据需求更少),为什么跟踪方法不仅没有被淘汰,反而在BeyondMimic等工作中持续进化?
答案在于:两条路线优化的目标函数本质不同,适用的场景也不同。
跟踪方法的核心优势:动作保真度。 当你需要机器人精确复现一个特定动作(比如一个标准的太极拳起势、一个精确的工业装配动作),跟踪方法是更可靠的选择。它的优化目标是最小化与参考轨迹的逐帧误差,这意味着输出动作与参考动作之间有明确的、可量化的对应关系。BeyondMimic在Unitree G1上实现的跳跃旋转和侧手翻,正是这种高保真度的体现------这些高动态动作对关节角度和时序的精度要求极高,AMP的分布级模仿难以保证这种精度。
AMP的核心优势:风格泛化与任务解耦。 当你的目标不是"精确复现动作A",而是"让机器人以自然的方式完成任务B"时,AMP更有优势。例如,你希望机器人"像人一样走路去拿一个杯子"------这里"像人一样走路"是风格约束,"去拿杯子"是任务目标。AMP天然支持这种风格-任务解耦:判别器负责风格,任务奖励负责目标,两者通过权重平衡。而跟踪方法需要预先规划一条"走向杯子"的参考轨迹,这在动态环境中并不现实。
下表从工程实践角度总结了选择依据:
| 决策维度 | 选跟踪方法(DeepMimic/BeyondMimic) | 选AMP |
|---|---|---|
| 动作精度要求 | 高(需要精确复现特定动作) | 中(只需"看起来自然") |
| 参考数据量 | 充足(大规模动捕数据集可用) | 有限(只有少量风格片段) |
| 任务类型 | 动作复现、技能展示、遥操作 | 目标导向任务(导航、搬运) |
| 环境动态性 | 低(预知环境,可预规划轨迹) | 高(需要实时适应未知环境) |
| 动作多样性 | 需要大量数据覆盖 | 可从少量数据自动组合 |
| 训练稳定性 | 高(监督学习范式,收敛可靠) | 中(对抗训练存在不稳定性) |
| 推理时依赖 | 传统方法需要参考轨迹;BeyondMimic通过扩散策略解耦 | 无需参考轨迹 |
| 真机部署难度 | 较低(误差可量化、可调试) | 较高(风格奖励难以直接调试) |
一个关键趋势:两条路线正在融合。 BeyondMimic的扩散策略蒸馏本质上是在跟踪方法的基础上引入了生成模型的灵活性;而beyondAMP项目继承了BeyondMimic的数据管线,将核心算法替换为对抗模仿。这种"共享数据管线、切换核心算法"的设计,使得研究者可以在同一数据集上直接对比两种路线的表现,也暗示了未来可能出现更深层次的融合------例如用跟踪方法生成高质量的"种子轨迹",再用AMP学习这些轨迹的风格分布,兼得精度与泛化。
3. AMP算法原理深度剖析
3.1 问题建模
AMP将机器人运动控制建模为一个目标条件强化学习问题。在每个时间步t,智能体观察系统状态 s t s_t st,根据策略网络输出动作 a t a_t at,环境返回下一状态 s t + 1 s_{t+1} st+1和奖励 r t r_t rt。AMP的核心创新在于奖励函数的设计------它由两部分组成:
r t = w G ⋅ r t G + w S ⋅ r t S r_t = w^G \cdot r_t^G + w^S \cdot r_t^S rt=wG⋅rtG+wS⋅rtS
其中 r t G r_t^G rtG 是任务奖励(如朝目标方向移动), r t S r_t^S rtS 是风格奖励(由判别器输出计算)。权重 w G w^G wG 和 w S w^S wS 控制任务完成度与运动自然度之间的平衡。在TienKung-Lab的实现中,两者默认均设为0.5。
3.2 对抗运动先验的核心机制
AMP的判别器 D D D 接收状态转移对 ( s t , s t + 1 ) (s_t, s_{t+1}) (st,st+1) 作为输入------注意这里使用的是连续两帧的状态而非单帧,这是因为运动的风格特征不仅体现在静态姿态上,更体现在帧间的动态变化中。判别器的训练目标是:
min D E d M ( D ( s , s ′ ) − 1 ) 2 + E d π ( D ( s , s ′ ) + 1 ) 2 \min_D \; \mathbb{E}{d^M}\left(D(s,s') - 1)\^2\\right + \mathbb{E}{d^\pi}\left(D(s,s') + 1)\^2\\right DminEdM(D(s,s′)−1)2+Edπ(D(s,s′)+1)2
这是一个最小二乘判别器(Least-Squares Discriminator),相比传统GAN的交叉熵损失,它在整个优化过程中提供更平滑的梯度,避免了sigmoid函数在输出极端值时的梯度饱和问题。判别器对真实运动数据输出接近+1的值,对策略生成的运动输出接近-1的值。
风格奖励基于判别器输出计算:
r t S = max 0 , 1 − 1 4 ( D ( s t , s t + 1 ) − 1 ) 2 r_t^S = \max\left0, \\; 1 - \\frac{1}{4}(D(s_t, s_{t+1}) - 1)\^2\\right rtS=max0,1−41(D(st,st+1)−1)2
这个公式将奖励限制在 0 , 1 0, 1 0,1 区间。当判别器认为当前运动来自真实数据( D D D 输出接近1)时,奖励达到最大值1;当判别器认为运动是策略生成的( D D D 输出接近-1)时,奖励为0。
以下是TienKung-Lab中判别器的实际实现代码:
python
# TienKung-Lab: rsl_rl/rsl_rl/modules/discriminator.py
class Discriminator(nn.Module):
def __init__(self, input_dim, amp_reward_coef, hidden_layer_sizes, device, task_reward_lerp=0.0):
super().__init__()
self.amp_reward_coef = amp_reward_coef
# 构建MLP主干网络
amp_layers = []
curr_in_dim = input_dim
for hidden_dim in hidden_layer_sizes:
amp_layers.append(nn.Linear(curr_in_dim, hidden_dim))
amp_layers.append(nn.ReLU())
curr_in_dim = hidden_dim
self.trunk = nn.Sequential(*amp_layers).to(device)
self.amp_linear = nn.Linear(hidden_layer_sizes[-1], 1).to(device)
self.task_reward_lerp = task_reward_lerp
def predict_amp_reward(self, state, next_state, task_reward, normalizer=None):
with torch.no_grad():
self.eval()
if normalizer is not None:
state = normalizer.normalize_torch(state, self.device)
next_state = normalizer.normalize_torch(next_state, self.device)
d = self.amp_linear(self.trunk(torch.cat([state, next_state], dim=-1)))
reward = self.amp_reward_coef * torch.clamp(1 - (1/4) * torch.square(d - 1), min=0)
if self.task_reward_lerp > 0:
reward = (1.0 - self.task_reward_lerp) * reward + self.task_reward_lerp * task_reward.unsqueeze(-1)
self.train()
return reward.squeeze(), d这段代码清晰地展示了AMP奖励的计算流程:将当前状态和下一状态拼接后送入判别器网络,得到判别分数d,再通过公式转换为风格奖励。task_reward_lerp参数控制任务奖励与风格奖励的插值比例------训练初期可设为较低值(如0.3)优先保证步态自然,训练后期调高(如0.8)优先保证任务完成。
3.3 梯度惩罚:稳定对抗训练的关键
GAN训练的一个经典难题是不稳定性。判别器可能在真实数据的流形上产生非零梯度,导致策略网络"过度追逐"判别器的评分而偏离真实运动分布。AMP引入梯度惩罚机制来解决这个问题:
python
# TienKung-Lab: rsl_rl/rsl_rl/modules/discriminator.py
def compute_grad_pen(self, expert_state, expert_next_state, lambda_=10):
expert_data = torch.cat([expert_state, expert_next_state], dim=-1)
expert_data.requires_grad = True
disc = self.amp_linear(self.trunk(expert_data))
ones = torch.ones(disc.size(), device=disc.device)
grad = autograd.grad(
outputs=disc, inputs=expert_data, grad_outputs=ones,
create_graph=True, retain_graph=True, only_inputs=True
)[0]
# 惩罚判别器在真实数据上的梯度范数
grad_pen = lambda_ * (grad.norm(2, dim=1) - 0).pow(2).mean()
return grad_pen梯度惩罚的物理含义是:要求判别器在真实运动数据附近的"地形"尽可能平坦。如果判别器在真实数据点上的梯度过大,意味着策略网络只要稍微偏离真实分布就会受到剧烈的奖励变化,这会导致训练振荡。通过惩罚梯度范数,判别器被迫在真实数据附近保持平滑,从而为策略网络提供稳定的学习信号。
4. AMP+PPO联合训练流程
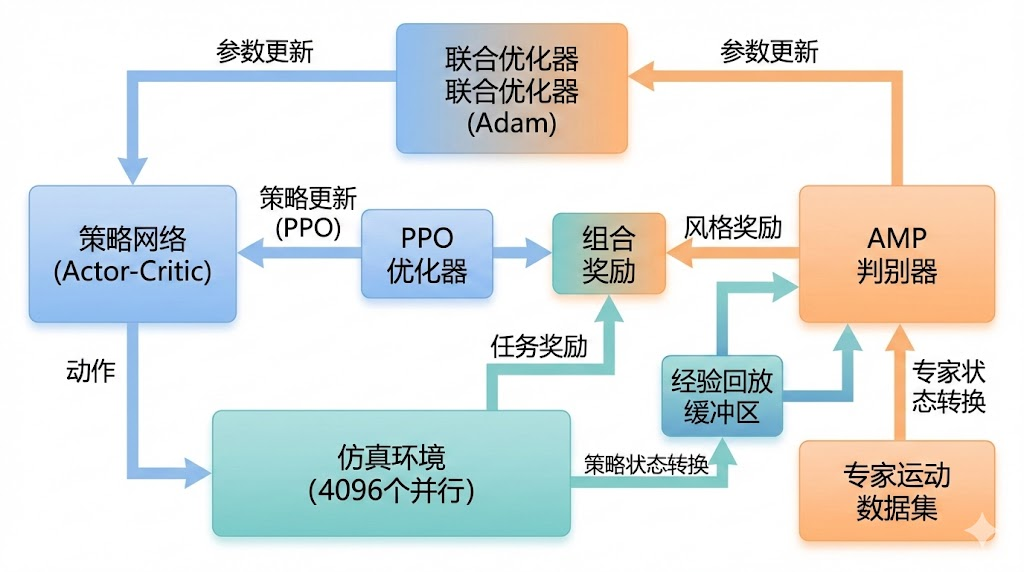
图:AMP+PPO联合训练的整体架构------策略网络、判别器和环境三者协同工作,通过任务奖励和风格奖励的双重驱动实现自然运动控制
理解了AMP的核心原理后,我们来看完整的训练流程是如何将对抗学习与强化学习融合在一起的。以下以TienKung-Lab的实际代码为基础进行解析。
4.1 训练循环的整体架构
AMP的训练循环可以概括为三个交替执行的阶段:数据采集、判别器更新、策略更新。下面是TienKung-Lab中AMPPPO类的核心更新逻辑(简化后的关键路径):
python
# TienKung-Lab: rsl_rl/rsl_rl/algorithms/amp_ppo.py(核心训练循环)
def update(self):
# 1. 构建三路数据生成器
generator = self.storage.mini_batch_generator(self.num_mini_batches, self.num_learning_epochs)
amp_policy_generator = self.amp_storage.feed_forward_generator(...) # 策略生成的运动
amp_expert_generator = self.amp_data.feed_forward_generator(...) # 专家参考运动
for sample, sample_amp_policy, sample_amp_expert in zip(
generator, amp_policy_generator, amp_expert_generator
):
# 2. 标准PPO损失计算
ratio = torch.exp(actions_log_prob_batch - old_actions_log_prob_batch)
surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
value_loss = (returns_batch - value_batch).pow(2).mean()
loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()
# 3. AMP判别器损失计算(核心)
policy_state, policy_next_state = sample_amp_policy
expert_state, expert_next_state = sample_amp_expert
# 观测标准化
if self.amp_normalizer is not None:
policy_state = self.amp_normalizer.normalize_torch(policy_state, self.device)
expert_state = self.amp_normalizer.normalize_torch(expert_state, self.device)
# ... next_state同理
# 判别器前向传播
policy_d = self.discriminator(torch.cat([policy_state, policy_next_state], dim=-1))
expert_d = self.discriminator(torch.cat([expert_state, expert_next_state], dim=-1))
# 最小二乘损失:专家数据→+1,策略数据→-1
expert_loss = torch.nn.MSELoss()(expert_d, torch.ones(expert_d.size(), device=self.device))
policy_loss = torch.nn.MSELoss()(policy_d, -1 * torch.ones(policy_d.size(), device=self.device))
amp_loss = 0.5 * (expert_loss + policy_loss)
grad_pen_loss = self.discriminator.compute_grad_pen(*sample_amp_expert, lambda_=10)
# 4. 总损失 = PPO损失 + AMP损失 + 梯度惩罚
loss += self.amploss_coef * amp_loss + self.amploss_coef * grad_pen_loss
# 5. 反向传播与参数更新
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.policy.parameters(), self.max_grad_norm)
self.optimizer.step()这段代码揭示了一个重要的工程设计:TienKung-Lab将策略网络和判别器的参数放在同一个优化器中联合更新,而非交替训练。具体来说,优化器包含三组参数:
python
params = [
{"params": self.policy.parameters(), "name": "policy"},
{"params": self.discriminator.trunk.parameters(), "weight_decay": 10e-4, "name": "amp_trunk"},
{"params": self.discriminator.amp_linear.parameters(), "weight_decay": 10e-2, "name": "amp_head"},
]
self.optimizer = optim.Adam(params, lr=learning_rate)注意判别器的输出层(amp_head)使用了比主干网络(amp_trunk)大一个数量级的权重衰减(10e-2 vs 10e-4),这是为了防止判别器的最终输出过于极端,保持奖励信号的平滑性。
4.2 运动数据加载与采样机制
AMP训练的另一个关键环节是如何高效地从参考运动数据集中采样状态转移对。TienKung-Lab的AMPLoader实现了一套完整的加载、插值和采样机制:
python
# TienKung-Lab: rsl_rl/rsl_rl/utils/motion_loader.py
class AMPLoader:
# 运动特征维度定义
JOINT_POS_SIZE = 20 # 20个关节角度
JOINT_VEL_SIZE = 20 # 20个关节速度
END_EFFECTOR_POS_SIZE = 12 # 6个末端执行器 x 3D坐标
def __init__(self, device, time_between_frames, motion_files, ...):
for motion_file in motion_files:
with open(motion_file) as f:
motion_json = json.load(f)
motion_data = np.array(motion_json["Frames"])
# 每帧包含52维特征:20关节角 + 20关节速度 + 12末端位置
self.trajectories.append(
torch.tensor(motion_data[:, :AMPLoader.END_POS_END_IDX],
dtype=torch.float32, device=device))
self.trajectory_weights.append(float(motion_json["MotionWeight"]))
frame_duration = float(motion_json["FrameDuration"])
self.trajectory_frame_durations.append(frame_duration)运动数据以JSON格式存储,每个文件包含一段完整的运动轨迹。每帧数据是一个52维向量,由三部分拼接而成:20维关节角度、20维关节速度、12维末端执行器位置(左右手、左右脚、头部、骨盆各3D坐标)。MotionWeight字段允许对不同运动片段赋予不同的采样权重,使训练过程可以侧重某些特定风格。
采样过程分为两步:首先按权重随机选择一条轨迹,然后在该轨迹的时间范围内随机采样一个时间点,通过线性插值获取该时刻的精确帧数据:
python
def feed_forward_generator(self, num_mini_batch, mini_batch_size):
"""为判别器训练生成(s_t, s_{t+1})状态转移对"""
for _ in range(num_mini_batch):
if self.preload_transitions:
idxs = np.random.choice(self.preloaded_s.shape[0], size=mini_batch_size)
s = self.preloaded_s[idxs, :]
s_next = self.preloaded_s_next[idxs, :]
else:
traj_idxs = self.weighted_traj_idx_sample_batch(mini_batch_size)
times = self.traj_time_sample_batch(traj_idxs)
for traj_idx, frame_time in zip(traj_idxs, times):
s.append(self.get_frame_at_time(traj_idx, frame_time))
s_next.append(self.get_frame_at_time(traj_idx, frame_time + self.time_between_frames))
yield s, s_next这里有一个重要的工程优化:preload_transitions选项允许在训练开始前预加载100万个状态转移对到GPU显存中,避免训练过程中频繁的CPU-GPU数据传输。对于大规模并行训练(如4096个环境),这个优化能显著提升训练吞吐量。
同时,策略网络在训练过程中生成的运动数据也会被存入一个回放缓冲区(ReplayBuffer),供判别器训练使用。这个设计防止判别器过拟合策略的最新一批轨迹,提升训练稳定性:
python
# 策略与环境交互后,将AMP观测存入回放缓冲区
def process_env_step(self, rewards, dones, infos, amp_obs):
self.amp_storage.insert(self.amp_transition.observations, amp_obs)5. 数据管线:从人类动捕到机器人可用数据
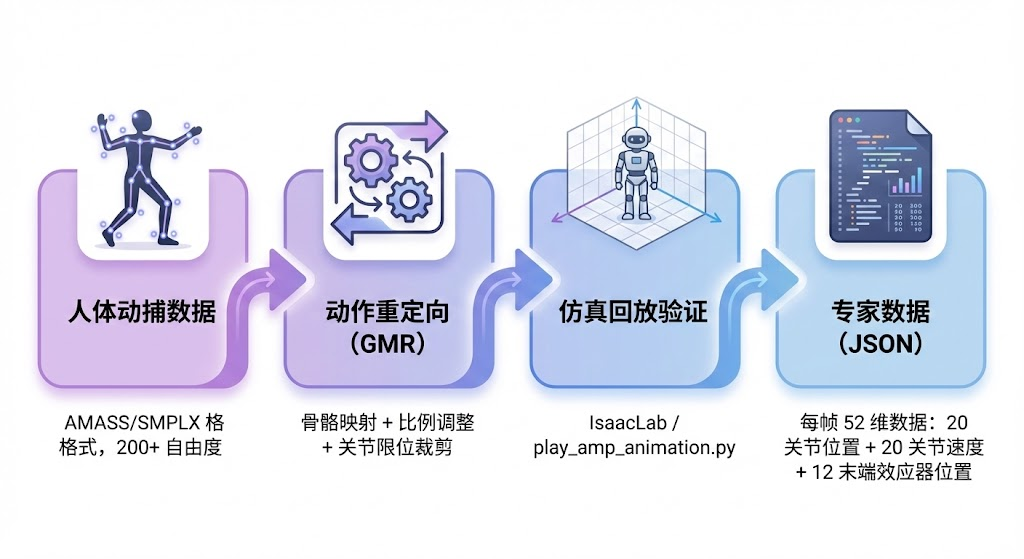
图:从人类动捕数据到机器人可用的AMP训练数据,需要经过重定向、验证、格式转换等多个环节
AMP算法的效果高度依赖参考运动数据的质量。然而,我们没有原生的机器人动作数据------人类的运动捕捉数据需要经过一系列处理才能被机器人使用。这条数据管线是整个训练流程中最容易被忽视、却至关重要的环节。
5.1 SMPLX与人类动捕数据
当前主流的人类运动数据集(如AMASS)使用SMPL/SMPLX参数化人体模型来表示运动。SMPLX模型将人体表示为一组骨骼关节的旋转参数加上体型参数,能够紧凑地编码人体的全身姿态。一个典型的SMPLX运动序列包含:
- 全局根节点的位置和朝向(6维)
- 身体关节的局部旋转(每个关节3维轴角表示,共21个关节 = 63维)
- 手部关节旋转(每只手15个关节 = 90维)
- 面部表情参数(10维)
然而,SMPLX模型的关节结构与任何具体的机器人都不相同。人类有超过200个自由度,而天工机器人只有20个可控关节。因此,直接使用SMPLX数据是不可行的,必须经过运动重定向(Motion Retargeting)。
5.2 运动重定向:弥合人机差异
运动重定向的核心任务是将人类骨骼的运动映射到机器人骨骼上,同时保持运动的语义一致性。这个过程面临三个主要挑战:
第一,骨骼拓扑差异。人类的肩关节有3个自由度,而某些机器人可能只有2个;人类的脊柱是柔性的多关节链,而机器人的躯干通常是刚性的。
第二,骨骼尺寸差异。人类的腿长、臂展与机器人不同,直接复制关节角度会导致末端执行器(手、脚)的位置偏差。
第三,关节限制差异。机器人的关节有明确的角度限制和力矩限制,人类的某些动作可能超出机器人的物理能力。
TienKung-Lab采用GMR(Gaussian Mixture Regression)工具完成重定向,其数据转换流程如下:
AMASS/OMOMO动捕数据 (SMPLX格式)
|
v
GMR重定向工具
(骨骼映射 + 尺寸缩放 + 关节限制裁剪)
|
v
robot_data.pkl (机器人关节角度序列)
|
v
gmr_data_conversion.py
(添加速度信息 + 末端执行器位置)
|
v
play_amp_animation.py
(在仿真中回放验证 + 导出专家数据)
|
v
motion_amp_expert/*.txt (AMP训练用JSON格式)最终的专家数据文件格式如下:
json
{
"Frames": [
[dof_pos_0, ..., dof_pos_19, dof_vel_0, ..., dof_vel_19, ee_x0, ee_y0, ee_z0, ...],
...
],
"MotionWeight": 1.0,
"FrameDuration": 0.033
}每帧52维:20个关节角度 + 20个关节速度 + 12个末端执行器坐标。FrameDuration表示帧间时间间隔(30fps对应0.033秒),MotionWeight控制该运动片段在训练中的采样权重。
5.3 beyondAMP的数据管线设计
beyondAMP项目在数据管线上做了进一步的模块化设计。它使用npz格式存储运动数据,每个文件包含更丰富的运动表示:
python
# beyondAMP的运动数据格式(npz文件)
{
"joint_pos": # 关节位置序列
"joint_vel": # 关节速度序列
"body_pos_w": # 世界坐标系下的身体部位位置
"body_quat_w": # 世界坐标系下的身体部位四元数朝向
"body_lin_vel_w": # 世界坐标系下的线速度
"body_ang_vel_w": # 世界坐标系下的角速度
"fps": # 帧率
}beyondAMP的一个关键设计是支持多种坐标系下的运动表示。它提供了世界坐标系(world frame)、锚点坐标系(anchor frame,以机器人根节点为原点)和身体局部坐标系(body-local frame)三种参考系的自动转换。这使得研究者可以根据不同的任务需求选择最合适的运动表示方式。
6. 奖励函数工程:AMP之外的关键设计
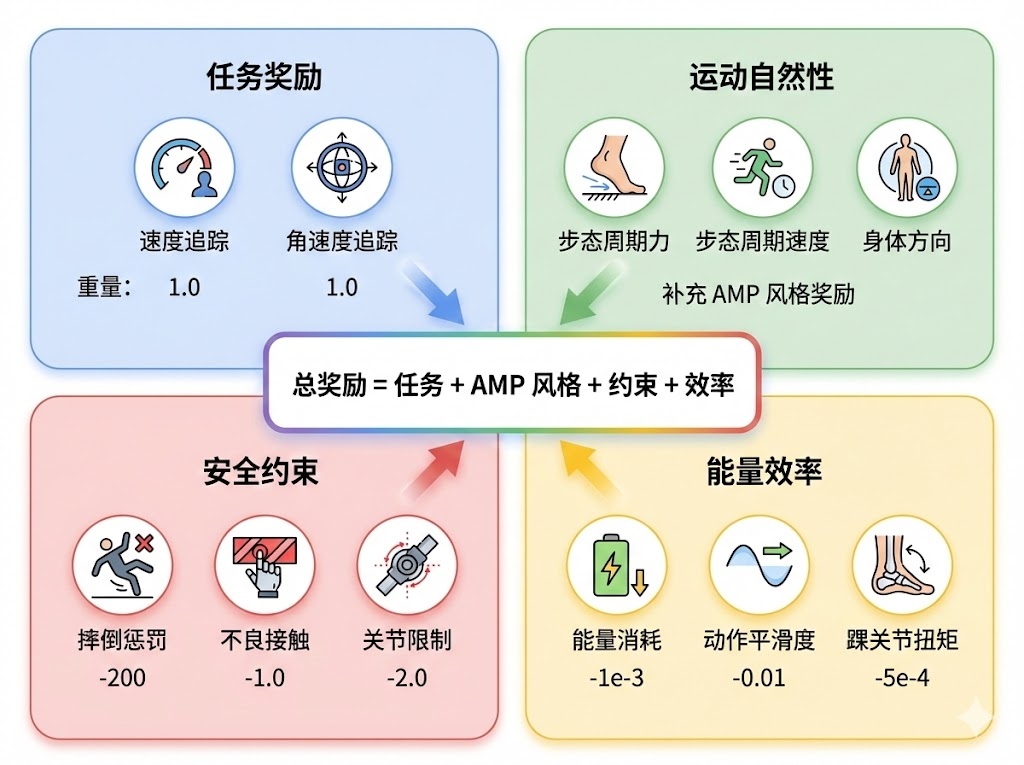
图:完整的奖励体系由任务奖励、风格奖励、安全约束和能效优化四大类组成,共同驱动策略网络学习稳定且自然的运动
AMP的风格奖励解决了"运动是否自然"的问题,但一个完整的机器人运动控制系统还需要任务奖励来驱动机器人完成具体目标。TienKung-Lab在任务奖励的设计上积累了丰富的工程经验,这些设计与AMP的风格奖励互补,共同构成了训练的完整奖励体系。
6.1 速度跟踪奖励
速度跟踪是行走/跑步任务的核心目标。TienKung-Lab采用指数形式的奖励函数,而非简单的线性误差:
python
# TienKung-Lab: legged_lab/mdp/rewards.py
def track_lin_vel_xy_yaw_frame_exp(env, std: float = 0.5):
asset = env.scene["robot"]
# 关键:将世界坐标系速度转换到机体坐标系
vel_yaw = math_utils.quat_rotate_inverse(
math_utils.yaw_quat(asset.data.root_quat_w),
asset.data.root_lin_vel_w[:, :3]
)
# 计算与指令速度的误差
lin_vel_error = torch.sum(
torch.square(env.command_generator.command[:, :2] - vel_yaw[:, :2]), dim=1
)
# 指数奖励:小误差时奖励接近1,大误差时快速衰减
return torch.exp(-lin_vel_error / std**2)这里有一个容易被忽略的细节:速度误差是在机体坐标系(yaw frame)下计算的,而非世界坐标系。这意味着"前进方向"始终是机器人自身的朝向,而非世界坐标系的某个固定轴。当机器人转弯时,机体坐标系的x轴随之旋转,确保速度跟踪的语义始终正确。