目录
- 一、分析(目标+抓包+定位+结论)
- 二、扣代码思路拆解
- [三、JS 复现](#三、JS 复现)
- [四、Python 请求测试](#四、Python 请求测试)
-
- [4.1 方法一:Python 调用扣好的 JS 函数](#4.1 方法一:Python 调用扣好的 JS 函数)
- [4.2 方法二:Python 全部改写](#4.2 方法二:Python 全部改写)
- 五、字体反爬:申报时间字段还原
- 六、小结
免责声明:本文内容仅用于合法授权范围内的技术学习、安全研究、逆向分析方法交流与风控防护理解,不针对任何网站、产品或服务提供绕过、攻击、滥用或破坏性使用建议。文中涉及的接口分析、参数加解密、调试定位、代码复现、数据请求等内容,仅用于说明相关技术原理和分析流程。读者应在遵守相关法律法规、平台规则、robots 协议、用户协议以及获得合法授权的前提下进行学习和实验。请勿将本文中的方法、脚本或思路用于未授权访问、批量采集、账号撞库、绕过风控、破坏验证码体系、规避平台限制、侵犯数据权益、商业化滥用或影响线上系统稳定性的行为。对于真实网站案例,读者不应直接复制代码对线上服务进行高频请求或非授权调用。若相关网站、产品方、权利方或平台认为本文内容存在不适宜公开展示之处,可通过评论区、私信或作者主页提供的联系方式联系我;核实后将及时删除、替换或调整相关内容。读者因不当使用本文内容造成的任何法律责任、业务风险或经济损失,均由使用者自行承担,与作者无关。
一、分析(目标+抓包+定位+结论)
需求: 抓取查策网产业政策项目列表,循环采集前 2 页数据。目标页面:
text
https://www.chacewang.com/chanye/index#目标接口:
text
GET https://web.chace-ai.com/api/ccw/project/evaluation/getList/典型参数:
text
page=2
size=20
industry=
area=RegisterArea_HNDQ_Guangdong_SZ
dept=
partition=
pe_name=
currentArea=RegisterArea_HNDQ_Guangdong_SZ
query_date=0
full_search=0
sort_type=0打开 F12 调试工具后,页面会先被一个反调试 debugger 干扰:
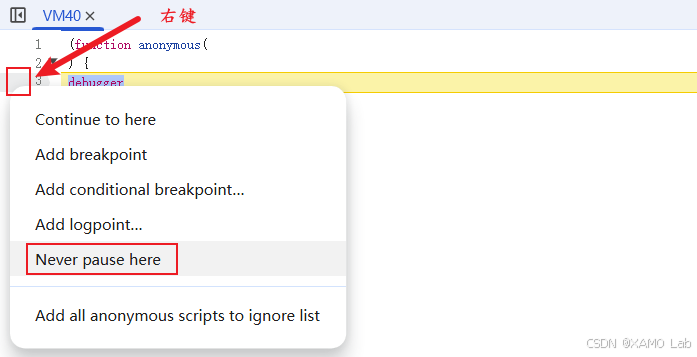
处理方式比较简单,直接在 DevTools 里对这个 debugger 位置做禁用/忽略处理,然后按 F8 继续执行,让页面能正常加载并抓包:
接着看 Network 面板,翻页时能看到列表接口:
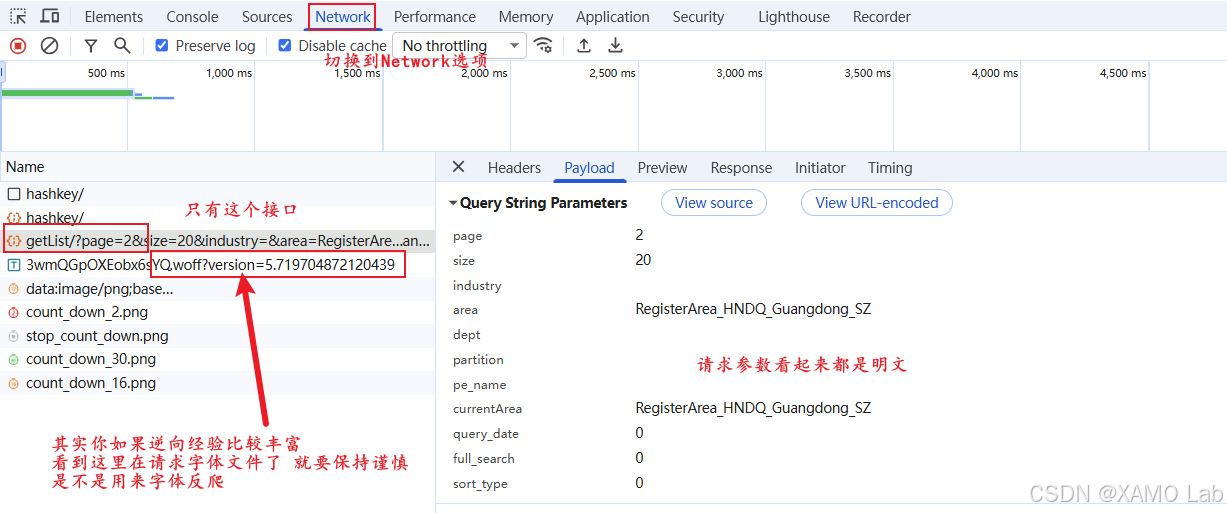
这个请求有一个关键现象:请求参数都在 URL Query 里,page、size、area、query_date 这些字段是明文,没有看到请求体加密,也没有必须参与计算的动态 sign、timestamp 一类字段。但是响应里的 data 字段是密文,接口返回结构大致如下:
json
{
"code": 200,
"message": "成功",
"data": "aXJ4Mm9Sc0srL2Njd2ZwX19fM2U2YzRkZGM2YWJlODQ1ZjVkNGM4...省略...WQxYTljM2UwZTRlMQ==",
"count": 1707,
"pagination": {
"page": "2",
"page_size": "20",
"page_set": "7429db60f70b32...省略...edd72e965f5fce96920ccdbd==",
"keyword": ""
}
}所以这题的主线先不要往 请求参数加密 上想,而是先解决 响应 data 解密。响应解密函数通常可以从两个方向定位:
- Hook
JSON.parse,因为业务代码最后一定要把解密后的 JSON 字符串转成对象。 - 全局搜索
decrypt、myDecrypt、AES.decrypt这类关键词。
这里我实际测试时发现,Hook JSON.parse 命中的业务逻辑比较多,噪声偏大。这个站点更直接的方式是全局搜索 decrypt:
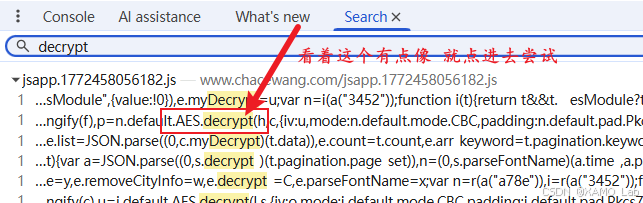
点进去后能看到一个 u(t) 函数。先不要急着扣代码,先在这个函数里打断点,然后回页面翻页,确认列表接口是否真的走到这里:

翻页后断点命中:

这时要做两个验证:
- 看入参
t是否等于接口响应 JSON 里的data密文。 - 看函数末尾的
v是否已经是解密后的 JSON 字符串。
验证结果是匹配的,说明这个 u(t) 就是响应 data 的解密函数:
关键函数如下:
javascript
function u(t) {
var e = s.decode(t)
, a = e.slice(0, 10)
, i = l(a, e)
, r = i.slice(0, 32)
, o = i.slice(32, i.length)
, c = n.default.enc.Utf8.parse(r)
, u = n.default.enc.Utf8.parse(o)
, d = e.slice(50, e.length)
, f = n.default.enc.Hex.parse(d)
, h = n.default.enc.Base64.stringify(f)
, p = n.default.AES.decrypt(h, c, {
iv: u,
mode: n.default.mode.CBC,
padding: n.default.pad.Pkcs7
})
, v = p.toString(n.default.enc.Utf8);
return v.toString()
}从这段代码可以先得到一个大方向:
s.decode(t):先对响应data做解码。l(a, e):根据解码后的字符串派生 key/iv 材料。n.default.AES.decrypt(...):最后走 CryptoJS 的 AES 解密。
具体 s.decode、l()、c() 怎么扣,放到下一节拆开处理。
二、扣代码思路拆解
这一节重点记录扣代码的过程,而不是只贴最终函数。核心思路是:每改一步都和浏览器断点里的变量做对比,确认当前步骤没问题后再继续往下扣。
第一步:先处理解码链路。原始代码是:
javascript
var e = s.decode(t)单步进入 s.decode,可以看到它实际走到下面这条链路:
javascript
D = t => I(L(t))
L = t => y(t.replace(/[-_]/g, t => "-" == t ? "+" : "/"))
// 这里依赖比较多,所以继续往上找,把从 const n 开始定义的相关变量一起扣下来
const n = "3.7.2"
, i = n
, o = "function" === typeof atob
, a = "function" === typeof btoa
, s = "function" === typeof Buffer
, u = "function" === typeof TextDecoder ? new TextDecoder : void 0
, h = "function" === typeof TextEncoder ? new TextEncoder : void 0
, f = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
, c = Array.prototype.slice.call(f)
, l = (t => {
let e = {};
return t.forEach( (t, r) => e[t] = r),
e
}
)(c)
, d = /^(?:[A-Za-z\d+\/]{4})*?(?:[A-Za-z\d+\/]{2}(?:==)?|[A-Za-z\d+\/]{3}=?)?$/
, p = String.fromCharCode.bind(String)
, m = "function" === typeof Uint8Array.from ? Uint8Array.from.bind(Uint8Array) : (t, e=(t => t)) => new Uint8Array(Array.prototype.slice.call(t, 0).map(e))
, v = t => t.replace(/=/g, "").replace(/[+\/]/g, t => "+" == t ? "-" : "_")
, y = t => t.replace(/[^A-Za-z0-9\+\/]/g, "")
, g = t => {
let e, r, n, i, o = "";
const a = t.length % 3;
for (let s = 0; s < t.length; ) {
if ((r = t.charCodeAt(s++)) > 255 || (n = t.charCodeAt(s++)) > 255 || (i = t.charCodeAt(s++)) > 255)
throw new TypeError("invalid character found");
e = r << 16 | n << 8 | i,
o += c[e >> 18 & 63] + c[e >> 12 & 63] + c[e >> 6 & 63] + c[63 & e]
}
return a ? o.slice(0, a - 3) + "===".substring(a) : o
}
, b = a ? t => btoa(t) : s ? t => Buffer.from(t, "binary").toString("base64") : g
, w = s ? t => Buffer.from(t).toString("base64") : t => {
const e = 4096;
let r = [];
for (let n = 0, i = t.length; n < i; n += e)
r.push(p.apply(null, t.subarray(n, n + e)));
return b(r.join(""))
}
, _ = (t, e=!1) => e ? v(w(t)) : w(t)
, M = t => {
if (t.length < 2) {
var e = t.charCodeAt(0);
return e < 128 ? t : e < 2048 ? p(192 | e >>> 6) + p(128 | 63 & e) : p(224 | e >>> 12 & 15) + p(128 | e >>> 6 & 63) + p(128 | 63 & e)
}
e = 65536 + 1024 * (t.charCodeAt(0) - 55296) + (t.charCodeAt(1) - 56320);
return p(240 | e >>> 18 & 7) + p(128 | e >>> 12 & 63) + p(128 | e >>> 6 & 63) + p(128 | 63 & e)
}
, S = /[\uD800-\uDBFF][\uDC00-\uDFFFF]|[^\x00-\x7F]/g
, x = t => t.replace(S, M)
, k = s ? t => Buffer.from(t, "utf8").toString("base64") : h ? t => w(h.encode(t)) : t => b(x(t))
, A = (t, e=!1) => e ? v(k(t)) : k(t)
, E = t => A(t, !0)
, O = /[\xC0-\xDF][\x80-\xBF]|[\xE0-\xEF][\x80-\xBF]{2}|[\xF0-\xF7][\x80-\xBF]{3}/g
, R = t => {
switch (t.length) {
case 4:
var e = (7 & t.charCodeAt(0)) << 18 | (63 & t.charCodeAt(1)) << 12 | (63 & t.charCodeAt(2)) << 6 | 63 & t.charCodeAt(3)
, r = e - 65536;
return p(55296 + (r >>> 10)) + p(56320 + (1023 & r));
case 3:
return p((15 & t.charCodeAt(0)) << 12 | (63 & t.charCodeAt(1)) << 6 | 63 & t.charCodeAt(2));
default:
return p((31 & t.charCodeAt(0)) << 6 | 63 & t.charCodeAt(1))
}
}
, T = t => t.replace(O, R)
, C = t => {
if (t = t.replace(/\s+/g, ""),
!d.test(t))
throw new TypeError("malformed base64.");
t += "==".slice(2 - (3 & t.length));
let e, r, n, i = "";
for (let o = 0; o < t.length; )
e = l[t.charAt(o++)] << 18 | l[t.charAt(o++)] << 12 | (r = l[t.charAt(o++)]) << 6 | (n = l[t.charAt(o++)]),
i += 64 === r ? p(e >> 16 & 255) : 64 === n ? p(e >> 16 & 255, e >> 8 & 255) : p(e >> 16 & 255, e >> 8 & 255, 255 & e);
return i
}
, j = o ? t => atob(y(t)) : s ? t => Buffer.from(t, "base64").toString("binary") : C
, P = s ? t => m(Buffer.from(t, "base64")) : t => m(j(t), t => t.charCodeAt(0))
, B = t => P(L(t))
, I = s ? t => Buffer.from(t, "base64").toString("utf8") : u ? t => u.decode(P(t)) : t => T(j(t))
, L = t => y(t.replace(/[-_]/g, t => "-" == t ? "+" : "/"))
, D = t => I(L(t))
, N = t => {
if ("string" !== typeof t)
return !1;
const e = t.replace(/\s+/g, "").replace(/={0,2}$/, "");
return !/[^\s0-9a-zA-Z\+/]/.test(e) || !/[^\s0-9a-zA-Z\-_]/.test(e)
}
, F = t => ({
value: t,
enumerable: !1,
writable: !0,
configurable: !0
})
, U = function() {
const t = (t, e) => Object.defineProperty(String.prototype, t, F(e));
t("fromBase64", (function() {
return D(this)
}
)),
t("toBase64", (function(t) {
return A(this, t)
}
)),
t("toBase64URI", (function() {
return A(this, !0)
}
)),
t("toBase64URL", (function() {
return A(this, !0)
}
)),
t("toUint8Array", (function() {
return B(this)
}
))
}
, q = function() {
const t = (t, e) => Object.defineProperty(Uint8Array.prototype, t, F(e));
t("toBase64", (function(t) {
return _(this, t)
}
)),
t("toBase64URI", (function() {
return _(this, !0)
}
)),
t("toBase64URL", (function() {
return _(this, !0)
}
))
}
, H = () => {
U(),
q()
}
, z = {
version: n,
VERSION: i,
atob: j,
atobPolyfill: C,
btoa: b,
btoaPolyfill: g,
fromBase64: D,
toBase64: A,
encode: A,
encodeURI: E,
encodeURL: E,
utob: x,
btou: T,
decode: D,
isValid: N,
fromUint8Array: _,
toUint8Array: B,
extendString: U,
extendUint8Array: q,
extendBuiltins: H
}也就是说,当前场景里的 s.decode 最终对应的是 D 函数,所以本地先改写成:
javascript
let e = D(t)验证方式很简单:浏览器断点里打印 e,本地 Node 环境也打印 e,两边结果一致后再继续往下处理。
第二步:确认 slice 都是普通字符串切片。
javascript
let a = e.slice(0, 10)这一步不用继续扣源码,slice 是字符串原生方法。只要上一步的 e 一致,a 基本就不会有问题;但为了稳妥,仍然建议打印一次,避免前面的解码字符集处理错了。
第三步:处理函数名冲突 。接着单步进入 l 函数,代码如下:
javascript
function l(t, e) {
for (var a = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : 48, n = e.slice(18, 50), i = t + n, r = c(i), s = r, o = 0; s.length < a; o++)
r = c(r + i),
s += r;
return s.slice(0, a)
}继续单步可以看到,l 函数内部又调用了 c 函数。再进入 c 函数:
javascript
function c(t) {
var e = o.createHash("md5");
return e.update(t).digest("hex")
}这里要特别注意:前面为了还原 s.decode 扣下来的那段代码里,已经存在变量 c、l;而当前解密模块里也有函数 c()、l()。如果直接合并到同一个文件,很容易发生变量名冲突,所以这里先做重命名:
javascript
function c_(t) {}
function l_(t, e) {}然后把调用同步改掉:
javascript
let i = l_(a, e)这个动作看起来很小,但真实扣代码时非常常见。webpack 压缩后的变量名通常很短,跨模块合并时尤其容易撞名。
第四步:确认浏览器中的 c() 是否为标准 MD5。原始代码:
javascript
function c(t) {
var e = o.createHash("md5");
return e.update(t).digest("hex")
}可以在浏览器里测试:
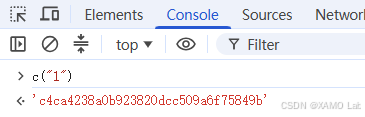
再和标准 MD5 对比:
javascript
CryptoJS.MD5("1").toString()如果结果一致,就说明这里不是魔改 MD5,本地可以直接替换为:
javascript
function c_(t) {
return CryptoJS.MD5(t).toString()
}第五步:拆 Key 和 IV 。这里的 n.default 可以按 CryptoJS 对象来处理,因为后面能看到 enc、AES、mode、pad 这些典型属性。对应代码可以改成:
javascript
let i = l_(a, e)
let r = i.slice(0, 32)
let o = i.slice(32, i.length)
let c = CryptoJS.enc.Utf8.parse(r)
let u = CryptoJS.enc.Utf8.parse(o)这里要注意:r 和 o 虽然长得像 hex 字符串,但 JS 用的是 Utf8.parse。所以 Python 里也应该使用 .encode("utf-8"),不能把它们当成 hex 再 bytes.fromhex()。
第六步:处理密文本体。继续看后面的密文处理逻辑:
javascript
let d = e.slice(50, e.length)
let f = CryptoJS.enc.Hex.parse(d)
let h = CryptoJS.enc.Base64.stringify(f)d 是从解码结果第 50 位开始截出来的 hex 字符串。CryptoJS 的 AES.decrypt 在这里接收的是 Base64 字符串,所以 JS 里先 Hex.parse 转成 WordArray,再 Base64.stringify 转成 Base64。Python 里不用绕这一步,直接把 hex 转成 bytes 即可:
python
ciphertext = bytes.fromhex(decoded_payload[50:])第七步:AES 解密 。最后把 n.default 相关调用替换成 CryptoJS 调用:
javascript
let p = CryptoJS.AES.decrypt(h, c, {
iv: u,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
})
let v = p.toString(CryptoJS.enc.Utf8)三、JS 复现
下面是完整 JS 测试代码,保留了当时扣代码和对照验证的注释,便于回看每一步是怎么来的:
javascript
const n = "3.7.2"
, i = n
, o = "function" === typeof atob
, a = "function" === typeof btoa
, s = "function" === typeof Buffer
, u = "function" === typeof TextDecoder ? new TextDecoder : void 0
, h = "function" === typeof TextEncoder ? new TextEncoder : void 0
, f = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
, c = Array.prototype.slice.call(f)
, l = (t => {
let e = {};
return t.forEach( (t, r) => e[t] = r),
e
}
)(c)
, d = /^(?:[A-Za-z\d+\/]{4})*?(?:[A-Za-z\d+\/]{2}(?:==)?|[A-Za-z\d+\/]{3}=?)?$/
, p = String.fromCharCode.bind(String)
, m = "function" === typeof Uint8Array.from ? Uint8Array.from.bind(Uint8Array) : (t, e=(t => t)) => new Uint8Array(Array.prototype.slice.call(t, 0).map(e))
, v = t => t.replace(/=/g, "").replace(/[+\/]/g, t => "+" == t ? "-" : "_")
, y = t => t.replace(/[^A-Za-z0-9\+\/]/g, "")
, g = t => {
let e, r, n, i, o = "";
const a = t.length % 3;
for (let s = 0; s < t.length; ) {
if ((r = t.charCodeAt(s++)) > 255 || (n = t.charCodeAt(s++)) > 255 || (i = t.charCodeAt(s++)) > 255)
throw new TypeError("invalid character found");
e = r << 16 | n << 8 | i,
o += c[e >> 18 & 63] + c[e >> 12 & 63] + c[e >> 6 & 63] + c[63 & e]
}
return a ? o.slice(0, a - 3) + "===".substring(a) : o
}
, b = a ? t => btoa(t) : s ? t => Buffer.from(t, "binary").toString("base64") : g
, w = s ? t => Buffer.from(t).toString("base64") : t => {
const e = 4096;
let r = [];
for (let n = 0, i = t.length; n < i; n += e)
r.push(p.apply(null, t.subarray(n, n + e)));
return b(r.join(""))
}
, _ = (t, e=!1) => e ? v(w(t)) : w(t)
, M = t => {
if (t.length < 2) {
var e = t.charCodeAt(0);
return e < 128 ? t : e < 2048 ? p(192 | e >>> 6) + p(128 | 63 & e) : p(224 | e >>> 12 & 15) + p(128 | e >>> 6 & 63) + p(128 | 63 & e)
}
e = 65536 + 1024 * (t.charCodeAt(0) - 55296) + (t.charCodeAt(1) - 56320);
return p(240 | e >>> 18 & 7) + p(128 | e >>> 12 & 63) + p(128 | e >>> 6 & 63) + p(128 | 63 & e)
}
, S = /[\uD800-\uDBFF][\uDC00-\uDFFFF]|[^\x00-\x7F]/g
, x = t => t.replace(S, M)
, k = s ? t => Buffer.from(t, "utf8").toString("base64") : h ? t => w(h.encode(t)) : t => b(x(t))
, A = (t, e=!1) => e ? v(k(t)) : k(t)
, E = t => A(t, !0)
, O = /[\xC0-\xDF][\x80-\xBF]|[\xE0-\xEF][\x80-\xBF]{2}|[\xF0-\xF7][\x80-\xBF]{3}/g
, R = t => {
switch (t.length) {
case 4:
var e = (7 & t.charCodeAt(0)) << 18 | (63 & t.charCodeAt(1)) << 12 | (63 & t.charCodeAt(2)) << 6 | 63 & t.charCodeAt(3)
, r = e - 65536;
return p(55296 + (r >>> 10)) + p(56320 + (1023 & r));
case 3:
return p((15 & t.charCodeAt(0)) << 12 | (63 & t.charCodeAt(1)) << 6 | 63 & t.charCodeAt(2));
default:
return p((31 & t.charCodeAt(0)) << 6 | 63 & t.charCodeAt(1))
}
}
, T = t => t.replace(O, R)
, C = t => {
if (t = t.replace(/\s+/g, ""),
!d.test(t))
throw new TypeError("malformed base64.");
t += "==".slice(2 - (3 & t.length));
let e, r, n, i = "";
for (let o = 0; o < t.length; )
e = l[t.charAt(o++)] << 18 | l[t.charAt(o++)] << 12 | (r = l[t.charAt(o++)]) << 6 | (n = l[t.charAt(o++)]),
i += 64 === r ? p(e >> 16 & 255) : 64 === n ? p(e >> 16 & 255, e >> 8 & 255) : p(e >> 16 & 255, e >> 8 & 255, 255 & e);
return i
}
, j = o ? t => atob(y(t)) : s ? t => Buffer.from(t, "base64").toString("binary") : C
, P = s ? t => m(Buffer.from(t, "base64")) : t => m(j(t), t => t.charCodeAt(0))
, B = t => P(L(t))
, I = s ? t => Buffer.from(t, "base64").toString("utf8") : u ? t => u.decode(P(t)) : t => T(j(t))
, L = t => y(t.replace(/[-_]/g, t => "-" == t ? "+" : "/"))
, D = t => I(L(t))
, N = t => {
if ("string" !== typeof t)
return !1;
const e = t.replace(/\s+/g, "").replace(/={0,2}$/, "");
return !/[^\s0-9a-zA-Z\+/]/.test(e) || !/[^\s0-9a-zA-Z\-_]/.test(e)
}
, F = t => ({
value: t,
enumerable: !1,
writable: !0,
configurable: !0
})
, U = function() {
const t = (t, e) => Object.defineProperty(String.prototype, t, F(e));
t("fromBase64", (function() {
return D(this)
}
)),
t("toBase64", (function(t) {
return A(this, t)
}
)),
t("toBase64URI", (function() {
return A(this, !0)
}
)),
t("toBase64URL", (function() {
return A(this, !0)
}
)),
t("toUint8Array", (function() {
return B(this)
}
))
}
, q = function() {
const t = (t, e) => Object.defineProperty(Uint8Array.prototype, t, F(e));
t("toBase64", (function(t) {
return _(this, t)
}
)),
t("toBase64URI", (function() {
return _(this, !0)
}
)),
t("toBase64URL", (function() {
return _(this, !0)
}
))
}
, H = () => {
U(),
q()
}
, z = {
version: n,
VERSION: i,
atob: j,
atobPolyfill: C,
btoa: b,
btoaPolyfill: g,
fromBase64: D,
toBase64: A,
encode: A,
encodeURI: E,
encodeURL: E,
utob: x,
btou: T,
decode: D,
isValid: N,
fromUint8Array: _,
toUint8Array: B,
extendString: U,
extendUint8Array: q,
extendBuiltins: H
}
const CryptoJS = require("./CryptoJS")
// function c(t) {
function c_(t) {
// TODO 3.1.1 这个函数看着是md5的实现 在确认是标准算法之后我们可以用本地的CryptoJS.js 改写
// var e = o.createHash("md5");
// e.update('1').digest("hex") 可以在浏览器中测试这个结果 然后跟标准算法进行对比
// 是标准算法 所以这里可以改写为 CryptoJS
// return e.update(t).digest("hex")
// 测试一样的
// return CryptoJS.MD5('1').toString();
return CryptoJS.MD5(t).toString();
}
function l_(t, e) {
// TODO 3.1 扣这里的时候 很明显看到是需要一个 c函数的
// 单步进入c函数 同理上面一起复制的时候有变量c 所以我们把名字改成c_ ==> TODO 3.1.1
// for (var a = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : 48, n = e.slice(18, 50), i = t + n, r = c(i), s = r, o = 0; s.length < a; o++)
for (var a = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : 48, n = e.slice(18, 50), i = t + n, r = c_(i), s = r, o = 0; s.length < a; o++)
// r = c(r + i),
r = c_(r + i),
s += r;
return s.slice(0, a)
}
function decryptRes(t) {
// var e = s.decode(t)
// TODO 1.改写 s.decode 其实是: D = t => I(L(t)) 则
let e = D(t) // 对比和浏览器中返回的e是一致的
// console.log(e)
// TODO 2.在看slice 是字符串自带的方法 不用管 只需看看和浏览器返回的是否一致
let a = e.slice(0, 10) // e一样的 a应该没啥问题
// console.log(a)
// TODO 3.注意单步调试进入 l函数 不是上面一起复制的那个l 所以需要重新复制 ==> TODO 3.1
// let i = l(a, e) 改写: 为了避免冲突 我们这里调用把l 改为l_
// 改写完成之后测试一下看能否正常调用
let i = l_(a, e) // 和浏览器是一致的 紧接着看下面
// console.log(i)
// TODO 4.i没有问题 那么r和o应该问题不大 测试一下 确实是一样的
let r = i.slice(0, 32)
let o = i.slice(32, i.length)
// console.log(r)
// console.log(o)
// TODO 5.下面这些就简单了 熟悉 CryptoJS 就知道 接下来就做替换操作就行了
// 其实 n.default 就是 CryptoJS 库
// let c = n.default.enc.Utf8.parse(r)
let c = CryptoJS.enc.Utf8.parse(r)
// let u = n.default.enc.Utf8.parse(o)
let u = CryptoJS.enc.Utf8.parse(o)
// 先验证一下数组是否和浏览器中的一致 结果: 一样的
// console.log(c)
// console.log(u)
// 剩余的接着验证就好了 一样的
let d = e.slice(50, e.length)
// console.log(d)
// let f = n.default.enc.Hex.parse(d)
let f = CryptoJS.enc.Hex.parse(d)
// let h = n.default.enc.Base64.stringify(f)
let h = CryptoJS.enc.Base64.stringify(f)
// let p = n.default.AES.decrypt(h, c, {
// iv: u,
// mode: n.default.mode.CBC,
// padding: n.default.pad.Pkcs7
// })
// 替换
let p = CryptoJS.AES.decrypt(h, c, {
iv: u,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
})
// let v = p.toString(n.default.enc.Utf8);
let v = p.toString(CryptoJS.enc.Utf8);
return v.toString()
}
// let e = D('服务端返回的data密文');
// console.log(e)
// 让test_str等于浏览器中u函数传入进来的t 来进行测试
let test_str = '服务端返回的data密文'
// 最后解密成功
console.log(typeof decryptRes(test_str));
console.log(JSON.parse(decryptRes(test_str)));
// console.log(c_('1'));四、Python 请求测试
本案例保留两个测试方法。
4.1 方法一:Python 调用扣好的 JS 函数
思路:
- Python 用
requests请求接口。 - 取响应 JSON 里的
data字段。 - 用
execjs调 JS 里的decryptRes。 json.loads得到列表。
这里我使用的是本地离线版 CryptoJS.js,所以 JS 代码里直接通过 require 引入。实际复现时也可以选择 npm 安装 crypto-js,本质上没有区别,只要最终拿到标准 CryptoJS 对象即可:
javascript
const CryptoJS = require("./CryptoJS")4.2 方法二:Python 全部改写
核心解密代码:
python
def md5_hex(value: str) -> str:
return hashlib.md5(value.encode("utf-8")).hexdigest()
def derive_key_material(prefix: str, decoded_payload: str, length: int = 48) -> str:
middle = decoded_payload[18:50]
seed = prefix + middle
digest = md5_hex(seed)
material = digest
while len(material) < length:
digest = md5_hex(digest + seed)
material += digest
return material[:length]
def decrypt_response_data(encrypted_data: str) -> Any:
padding = "=" * (-len(encrypted_data) % 4)
decoded_bytes = base64.urlsafe_b64decode(encrypted_data + padding)
decoded_payload = decoded_bytes.decode("utf-8")
prefix = decoded_payload[:10]
key_material = derive_key_material(prefix, decoded_payload)
key = key_material[:32].encode("utf-8")
iv = key_material[32:48].encode("utf-8")
ciphertext = bytes.fromhex(decoded_payload[50:])
cipher = AES.new(key, AES.MODE_CBC, iv)
plaintext = unpad(cipher.decrypt(ciphertext), AES.block_size)
return json.loads(plaintext.decode("utf-8"))请求头模拟:
python
HEADERS = {
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://www.chacewang.com",
"Referer": "https://www.chacewang.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "cross-site",
}脚本使用 loguru.logger 输出采集进度,完整 JSON 明细放在 debug 日志中,避免把调试 print 留在正式代码里。验证结果示例:
text
page=1 rows=20 total=1707
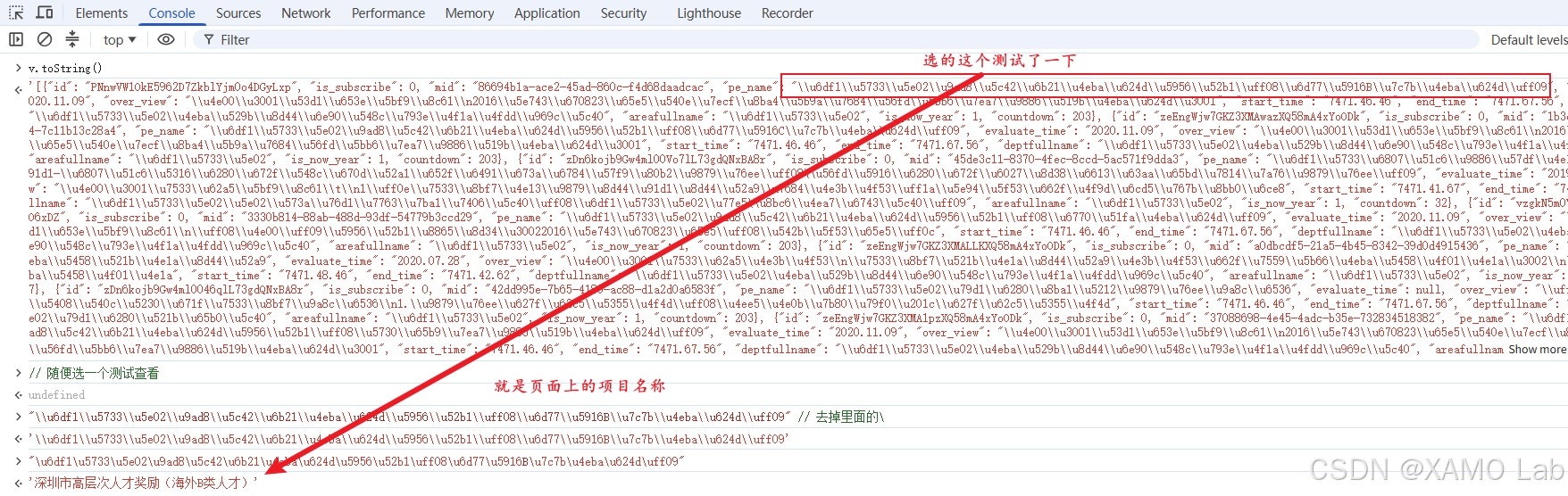
生态环境专项资金项目-污染处理设施更新改造项目 7471.45.46 7471.67.56这里先能确认一件事:接口里的 data 已经被正常解密成列表 JSON。示例里这些数字字段暂时还不能直接和页面展示内容对应,下一节再继续排查它们到底对应页面上的哪个字段。
五、字体反爬:申报时间字段还原
前面把接口数据解出来之后,接下来要继续确认页面上的 申报时间 来自哪里。先回到 Network 面板观察翻页和页面加载过程,看看申报时间是否由其他接口单独返回。实际观察下来,没有发现新的列表详情接口,也没有看到其他专门返回申报时间的请求。这样就需要回到已经解密出来的列表数据里继续找线索。
在列表数据中,可以看到每条记录里都有两个比较像时间字段的名称:
text
start_time
end_time问题是,这两个字段的格式和页面上看到的申报时间完全不一样。例如页面肉眼看到的是:
text
2026.03.01-2026.12.31但接口解密后的字段可能是:
text
start_time: "4549.52.58"
end_time: "4549.84.28"到这里还不能直接下结论说是字体反爬,因为也可能是字段还要经过某种业务映射。于是做一个最简单的验证:直接在页面上选中申报时间并复制。
复制出来的结果不是页面上看到的 2026.03.01-2026.12.31,而是和接口里的假数字格式一致,例如:
text
4041.08.06-4041.64.86这一步就能基本判断:接口解密没有问题,DOM 文本里保存的就是这些假数字;浏览器只是通过自定义字体把这些数字渲染成了真实日期。前面抓包时其实也能看到字体请求,例如:
text
https://web.chace-ai.com/media/fonts/UGsCBCC7QgVMzxgU.woff?version=8.205129435023679所以这里的处理方向就很明确了:下载当前页面使用的 .woff 字体,建立接口假数字 -> 页面真实数字的映射,然后把 start_time、end_time 这类字段统一替换。
如果只是临时处理当前字体,可以人工打开字体文件观察 0-9 的显示效果,然后写一个固定映射。但这种方式不够通用,因为字体文件名和数字映射可能会变化。更稳一点的做法是用 fontTools 读取 glyph 轮廓,把当前字体里的数字轮廓和一个已知模板字体做匹配。示例处理逻辑如下:
python
from pathlib import Path
from typing import Any, Dict
import requests
from fontTools.pens.recordingPen import RecordingPen
from fontTools.ttLib import TTFont
FONT_URL = "https://web.chace-ai.com/media/fonts/{}.woff?version=1"
CACHE_DIR = Path(__file__).with_name(".chace_font_cache")
def glyph_signature(font: TTFont, glyph_name: str) -> tuple:
glyph_set = font.getGlyphSet()
pen = RecordingPen()
glyph_set[glyph_name].draw(pen)
return tuple(pen.value)
def build_digit_templates(reference_font: Path) -> Dict[tuple, str]:
# 这个模板字体需要先人工识别一次:
# source char 0123456789 renders as 2438195067
manual_map = {
"0": "2",
"1": "4",
"2": "3",
"3": "8",
"4": "1",
"5": "9",
"6": "5",
"7": "0",
"8": "6",
"9": "7",
}
font = TTFont(str(reference_font))
return {glyph_signature(font, src): real for src, real in manual_map.items()}
def download_font(session: requests.Session, font_name: str) -> Path:
CACHE_DIR.mkdir(exist_ok=True)
path = CACHE_DIR / f"{font_name}.woff"
if not path.exists():
response = session.get(FONT_URL.format(font_name), timeout=30)
response.raise_for_status()
path.write_bytes(response.content)
return path
def font_digit_map(font_path: Path, templates: Dict[tuple, str]) -> Dict[str, str]:
font = TTFont(str(font_path))
mapping = {}
for src in "0123456789":
mapping[src] = templates[glyph_signature(font, src)]
return mapping
def translate_digits(value: Any, digit_map: Dict[str, str]) -> Any:
if not isinstance(value, str):
return value
return value.translate(str.maketrans(digit_map))实际项目里,字体名不是固定写死的,需要结合接口返回的 pagination.page_set 解出来。最终效果类似:
text
8685.63.60-8685.08.30 -> 2026.03.01-2026.12.31这部分不是本篇重点,真正通用的字体反爬后续会单独展开。这里先知道处理思路即可:先确认复制结果和接口假数字一致,再下载字体,通过 glyph 映射把假数字还原成真实数字。
六、小结
这个案例的主线可以拆成两部分:接口响应解密 和 申报时间字段还原。
接口解密部分的实际分析路径是:
- 打开页面后先处理无限
debugger,保证页面能继续执行并正常抓包。 - 在 Network 面板观察翻页请求,确认列表接口是
getList,请求参数是普通 Query。 - 观察响应结构,发现外层 JSON 是明文,但
data字段是密文。 - 因为
JSON.parse命中位置比较多,所以没有优先走 Hook,而是全局搜索decrypt关键词。 - 搜到解密函数后打断点,翻页触发请求,验证入参
t是否等于接口返回的data,再验证函数末尾v是否为解密后的 JSON 字符串。 - 确认函数后再逐步扣代码:先扣
s.decode,再扣l()和c(),最后替换 CryptoJS AES 解密逻辑。
这部分最后还原出来的逻辑是:
| 步骤 | 处理 |
|---|---|
| 1 | 对响应 data 做 Base64 解码 |
| 2 | 取解码结果前 10 位作为前缀 |
| 3 | 取解码结果 18:50 和前缀拼接,通过 MD5 迭代生成 48 位材料 |
| 4 | 前 32 位作为 AES Key,后 16 位作为 IV |
| 5 | 解码结果第 50 位以后是 hex 密文 |
| 6 | AES-CBC + PKCS7 解密得到 JSON 字符串 |
需要注意的几个坑:
- 不要一开始就假设请求参数被加密 。这个接口请求参数是明文 Query,真正需要处理的是响应
data。 - 搜索关键词定位时要验证调用关系 。搜到
decrypt只是找到候选函数,还必须通过断点确认入参和接口密文一致。 - 扣多个 webpack 模块时要注意变量名冲突 。例如 Base64 模块里已经有
c、l,解密模块里又有c()、l(),合并到本地测试文件时需要重命名。 c()确认是标准 MD5 后再替换 。不要看到createHash("md5")就直接跳过,最好用浏览器结果和本地 CryptoJS/标准 MD5 对一下。- Key/IV 是字符串按 UTF-8 使用,不是 hex 解码 。JS 里是
CryptoJS.enc.Utf8.parse,Python 里对应.encode("utf-8")。 - 申报时间不是接口解密失败 。接口解密后拿到的
start_time、end_time是 DOM 里的假数字,页面通过.woff字体渲染成真实日期。