PrologMCP:当 MCP 遇到 Prolog,Agent 推理开始有了形式化外挂
TL;DR
- 场景:MCP 工具层正从「业务能力插座」向「形式化推理子系统」延伸,PrologMCP 把 SWI-Prolog 封装为 MCP Server,让 LLM Agent 通过标准化接口执行符号推理。
- 结论:PrologMCP 不是替代 reasoning model,而是把「语义翻译」留给 LLM、「形式化推理」交给 Prolog、「连接」交给 MCP,组成可执行、可检查、可复现的复合 Agent。
- 产出:在 PARARULE-Plus 多步演绎推理上,Prolog Formalizer 比 Standard LLM 与 Reasoning LLM 更稳定;推理过程可由工具执行、结构化诊断、可复现、可审计。
版本矩阵
| 功能/组件 | 状态 | 说明 |
|---|---|---|
| 论文标题《PrologMCP: A Standardized Prolog Tool Interface for LLM Agents》 | ✅ 已验证 | 文章引用的标题,与 arXiv 提交一致 |
| 论文提交时间 2026-06-12(arXiv) | ✅ 已验证 | 用户原文明确给出 |
| 后端 Prolog 引擎 SWI-Prolog | ✅ 已验证 | SWI-Prolog 自 1987 年起持续维护,是当前主流开源 Prolog 实现 |
| 评估数据集 PARARULE-Plus(多步演绎推理) | ✅ 已验证 | 论文公开实验配置 |
| 评估模型 Claude Sonnet 4.6、GPT-4.1、o4-mini | ✅ 已验证 | 论文公开实验配置 |
工具 consult_text / run_goal / inspect_predicate |
✅ 已验证 | 论文接口设计章节 |
工具 get_source / replace_predicate / list_messages |
✅ 已验证 | 论文接口设计章节 |
工具 run_tests / trace_goal / close_session |
✅ 已验证 | 论文接口设计章节 |
translate → run → inspect → repair 闭环工作流 |
✅ 已验证 | 论文核心机制描述 |
| 每个任务独立 Prolog session,避免状态污染 | ✅ 已验证 | 论文工程属性说明 |
| 诊断信息以结构化 JSON 返回,方便 LLM 修复 | ✅ 已验证 | 论文工程属性说明 |
| 查询受解数量与推理深度约束,避免无限展开 | ✅ 已验证 | 论文工程属性说明 |
| 容器级隔离 / 资源限制 / 审计能力 | ⚠️ 待验证 | 论文仅提到 lexical sandbox,工业级隔离需自行补齐 |
| PrologMCP 全面优于 reasoning model 的断言 | ❌ 不支持 | 论文结果限定在 PARARULE-Plus 等可形式化任务,不构成通用结论 |
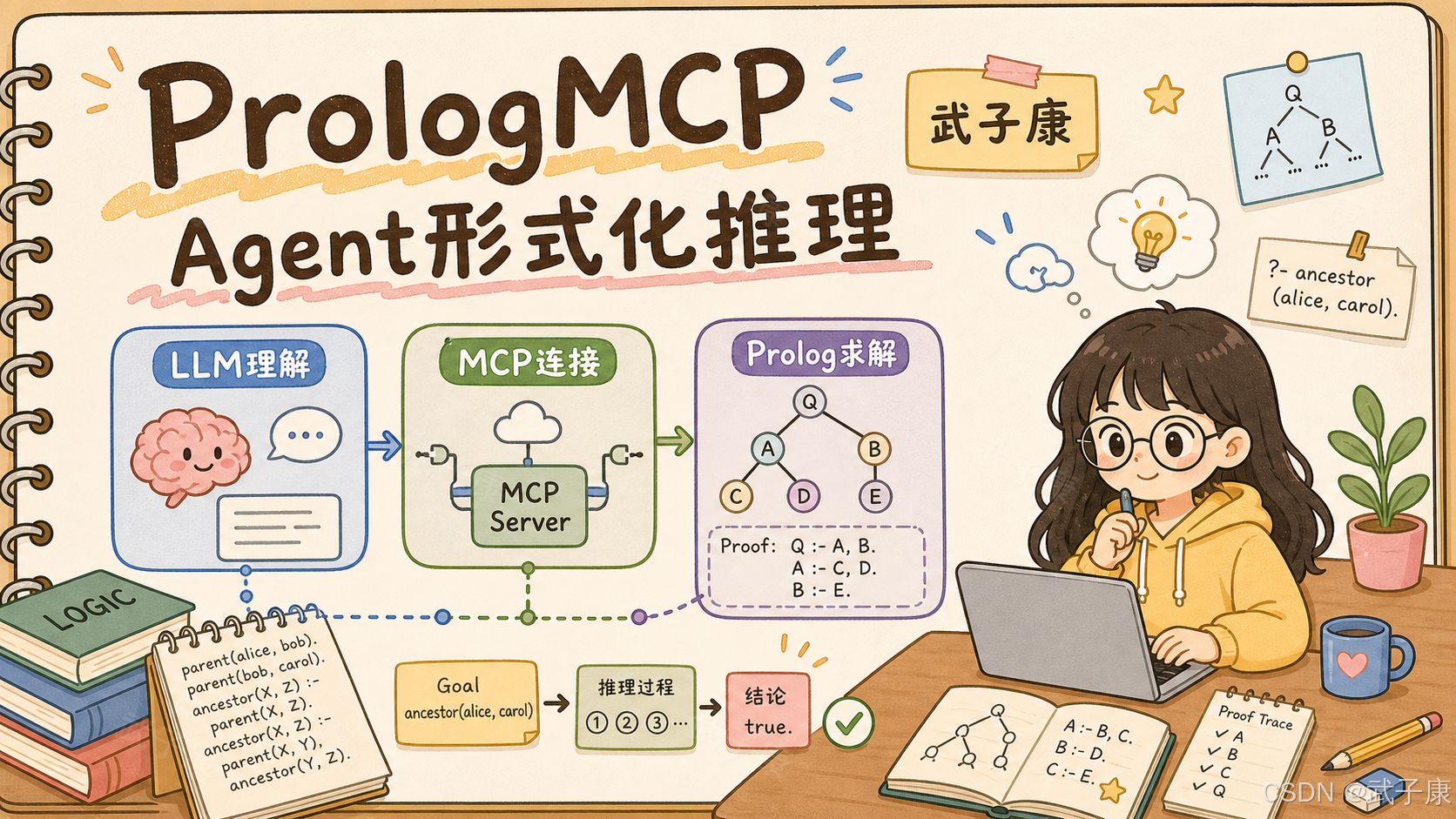
最近看到一篇很值得关注的论文:《PrologMCP: A Standardized Prolog Tool Interface for LLM Agents》。
它在 2026 年 6 月 12 日提交到 arXiv,核心想法并不绕:不要让大模型在自然语言里硬推复杂逻辑,而是让 LLM 把事实、规则和查询翻译成 Prolog,再交给 Prolog 求解器执行符号推理。论文进一步把这套能力封装成 MCP Server,让支持 MCP 的 Agent 可以通过标准工具接口调用 Prolog。
先说结论:
text
PrologMCP 不是要取代 reasoning model。
它更像给 Agent 加了一层可执行、可检查、可复现的形式化推理工具层。这件事有意思的地方,不是"Prolog 又火了",也不是"MCP 又多了一个工具",而是它提示了一个更大的趋势:
text
MCP 正在从工具连接协议,往可验证、可审计、可组合的 Agent 基础设施扩展。过去我们理解 MCP,更多是让 Agent 会查文件、查数据库、调 API、读网页、跑命令。PrologMCP 展示的是另一种方向:把一类严格推理能力接进 Agent,让模型在边界清晰的问题上,不再只依赖自然语言里的"想一想"。
1. PrologMCP 解决的不是工具调用,而是推理责任分配
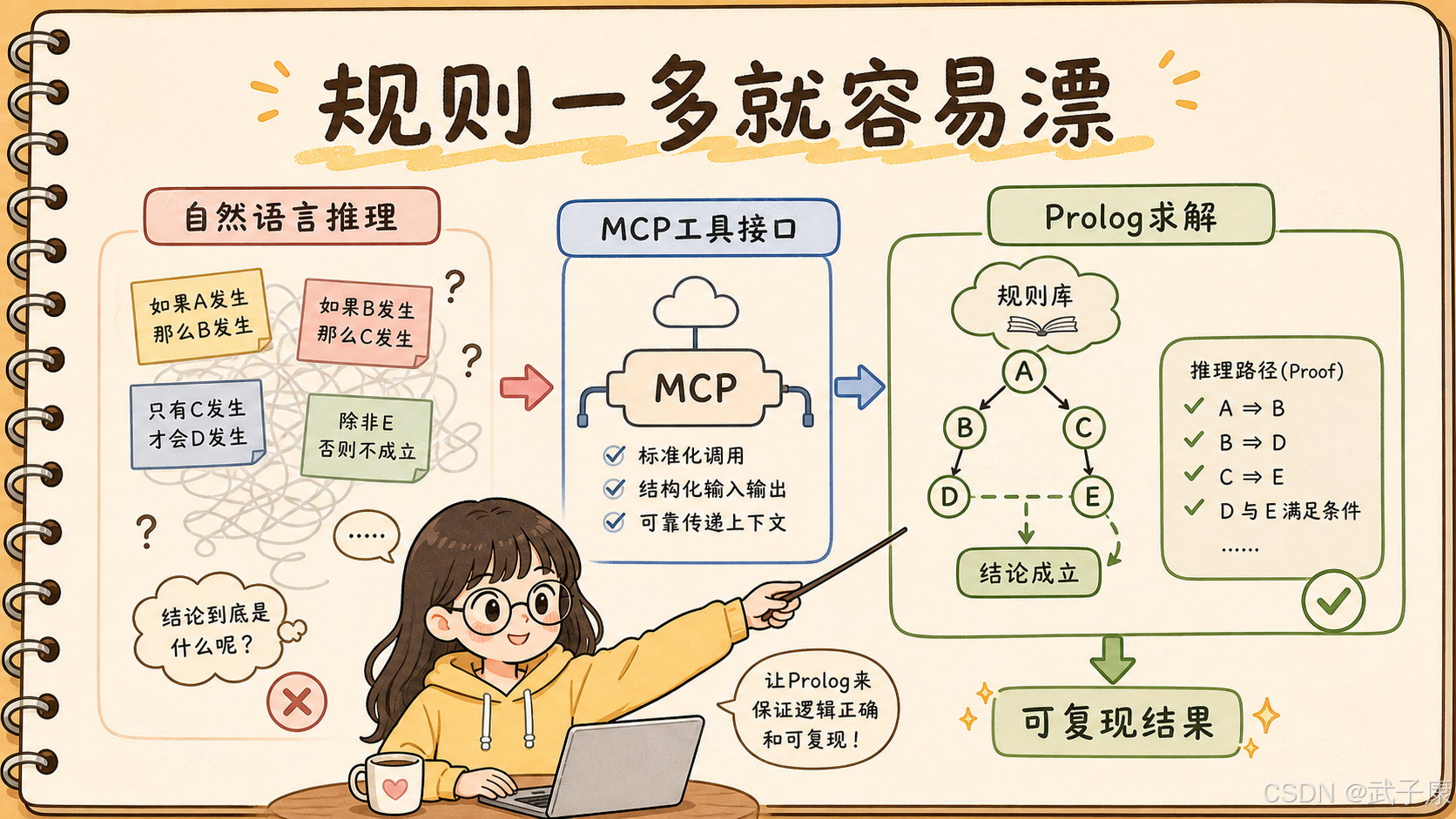
普通工具调用通常是这样:
text
用户问题
→ LLM 判断是否需要工具
→ 调用搜索 / 数据库 / API
→ LLM 汇总答案PrologMCP 的链路更像这样:
text
用户问题
→ LLM 把自然语言事实和规则翻译成 Prolog
→ MCP Server 加载 Prolog 程序
→ Prolog 求解器执行查询
→ 返回结构化结果、错误或证明痕迹
→ LLM 根据结果生成答案这里的关键不是"LLM 又会调用一个新工具",而是推理责任被重新分配了。
LLM 擅长语言理解、语义归纳、上下文整合和格式转换。但它并不擅长在很长的规则链里保持严格一致。尤其是多层规则、否定条件、递归关系、例外条件混在一起时,模型很容易给出一段听起来合理、但逻辑上不稳定的回答。
Prolog 的优势刚好相反。它不懂自然语言,但只要事实、规则和查询被正确形式化,就可以按照明确的逻辑语义执行推理。
举一个简化例子:
text
如果 A 成立,则 B 成立。
如果 B 成立,且 C 不成立,则 D 成立。
现在 A 成立,C 没有被证明成立。
D 是否成立?翻译成 Prolog 可以是:
prolog
b :- a.
d :- b, \+ c.
a.查询:
prolog
d.这类问题让 LLM 直接自然语言推理,规则少时通常没问题;规则一多、否定一多,稳定性就会下降。交给 Prolog 后,只要 formalization 正确,求解器会按照固定语义返回结果。
所以 PrologMCP 的价值,不是让 Prolog 替代大模型,而是让两者站到更适合的位置:
text
LLM 负责理解和翻译
Prolog 负责形式化推理
MCP 负责标准化连接2. 为什么 MCP 需要这种"形式化工具层"?
现在很多 Agent 系统的基本形态是:
text
LLM + Prompt + Tools + Memory + Workflow工具层越来越丰富:搜索、数据库、浏览器、代码执行、文件系统、GitHub、Jira、Slack、日历、企业内部 API。
但这些工具主要解决两类问题:
text
获取信息
执行动作它们并不天然解决第三类问题:
text
保证某个推理结论是由规则严格推出的。这就是 PrologMCP 的切入点。它不是又接了一个业务系统,而是接入一个临时的逻辑世界:
text
事实:哪些对象和属性成立
规则:满足什么条件可以推出什么结论
查询:某个结论是否可推出
诊断:哪里语法错,哪个谓词不存在,是否触发深度限制
修复:替换错误谓词,重新运行
追踪:生成 proof tree 或 trace普通 MCP Server 更像"外部能力插座"。PrologMCP 更像"符号推理子系统"。
这对 Agent 工程很重要。因为越往真实业务走,越不能把所有智能都塞回 prompt 里。
计算应该交给代码解释器。
检索应该交给搜索和向量库。
结构化数据应该交给 SQL。
规则推理可以交给 Prolog、Datalog、SMT 或 SAT。
流程执行应该交给工作流引擎。
状态管理应该交给数据库和事件系统。
LLM 更适合做语义中枢和调度器,而不是一个把理解、推理、执行、审计全部混在一起的超级 Controller。
3. PrologMCP 具体提供了哪些能力?
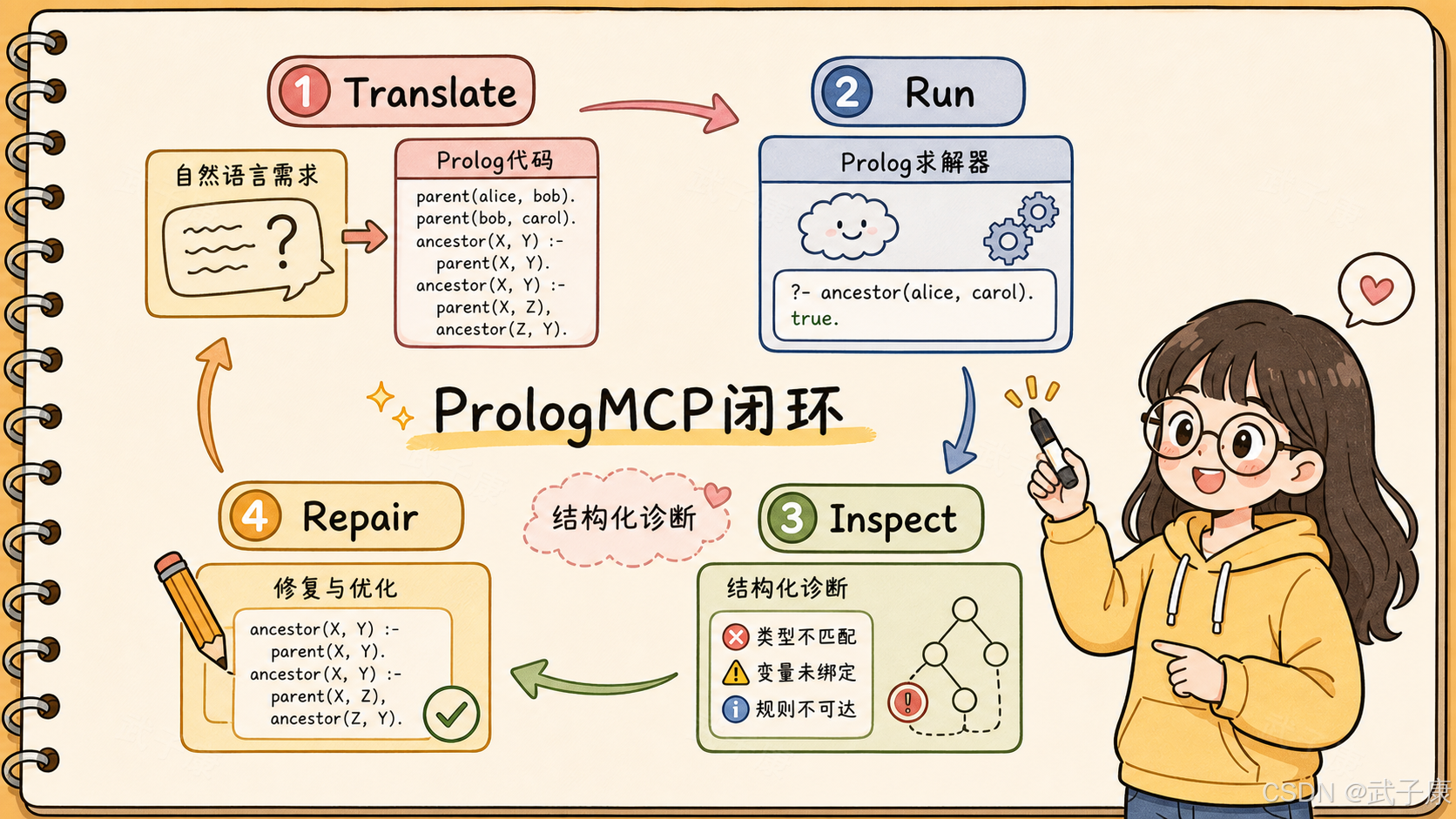
论文里的 PrologMCP 本质上是一个 MCP Server,底层接 SWI-Prolog。它暴露的能力不是普通业务 API,而是一组围绕逻辑程序生命周期设计的工具。
核心能力包括:
text
consult_text:创建会话并加载 Prolog 源码
run_goal:执行目标查询,返回解和状态
inspect_predicate:检查谓词是否存在、arity、规则数量等
get_source:取回当前会话中的 Prolog 源码
replace_predicate:替换某个谓词的定义
list_messages:列出语法、编译、运行时诊断
run_tests:运行 plunit 测试
trace_goal:生成深度受限的证明树
close_session:关闭会话这个接口设计最值得看的地方,是它支持 Agent 进入一个循环:
text
translate
→ run
→ inspect
→ repair也就是:
text
把自然语言翻译成 Prolog
运行查询
检查结构化错误或异常
修复谓词或程序
再次运行这比"一次性生成 Prolog,然后赌它正确"更接近真实 Agent 系统需要的工作方式。
论文还强调了几个工程属性:
text
每个任务有独立 Prolog session,避免状态污染
诊断信息以结构化 JSON 返回,方便 LLM 修复
查询受解数量和推理深度约束,避免无限展开
当前实现支持 SWI-Prolog这些细节说明它不是一个概念 demo,而是在往可复用工具接口靠。
4. 实验结果说明了什么?
论文在 PARARULE-Plus 数据集上做了实验。这个数据集主要测试多步演绎推理,输入是自然语言事实、规则和 true / false 查询。
论文比较了三类系统:
text
Standard LLM:普通模型直接回答 true / false
Reasoning LLM:启用 reasoning / extended thinking 的模型
Formalizer:模型先翻译成 Prolog,再通过 PrologMCP 执行推理从 arXiv 摘要和论文实验配置看,模型包括 Claude Sonnet 4.6、GPT-4.1 和 o4-mini。结果的大方向是:
text
在通用样本上,Prolog Formalizer 达到或接近满分。
GPT-4.1 标准模式明显弱于 Prolog Formalizer。
o4-mini reasoning 已经很强,但 Prolog Formalizer 仍然非常稳。
在更有挑战的语义子集上,Prolog Formalizer 仍保持接近满分,reasoning LLM 有一定下降。这并不意味着"PrologMCP 全面优于 reasoning model"。更准确的判断应该是:
text
对规则明确、语义可形式化、答案可由符号求解器推导的问题,
PrologMCP 提供了一条比自然语言长推理更可控的路径。这里还有一个很现实的点:如果基础模型本身已经足够强,形式化工具带来的准确率收益可能不明显,反而会增加翻译和工具调用成本。但当基础模型直接推理不稳定,或者任务需要审计中间过程时,把推理外包给 Prolog 可能比单纯增加 thinking token 更划算。
5. 真正有价值的是"推理可审计"
大模型自然语言推理有一个长期问题:它能写出一段很像推理过程的文本,但这段文本不一定是严格证明。
Chain-of-Thought 看起来像推理,但它不是形式证明。
Reasoning tokens 变长,也不保证每一步都是有效逻辑后果。
最终答案很自信,也不代表中间步骤可以复现。
PrologMCP 的路线是另一种思路:
text
不要要求 LLM 把所有推理都写在自然语言里,
而是让它把问题翻译到一个可执行的形式系统里。这样至少带来五个好处:
text
推理过程可以由工具执行,而不只是由模型叙述
错误可以结构化返回,方便自动修复
相同事实、规则和查询可以复现相同结果
关键中间产物可以被人类审计
trace 或 proof tree 可以帮助解释结论来源这在一些场景里尤其有价值:
text
权限判断:某用户是否能访问某资源
合规检查:某交易是否触发限制规则
工单路由:某问题应该派给哪个团队
配置推理:某设备组合是否满足约束
诊断规则:某异常是否由一组条件推出
业务状态机:某订单状态迁移是否合法这些问题不是靠模型"像人一样想得更久"就一定能解决的。更工程化的路径,是让模型生成可执行中间表示,再让专门工具执行和反馈。
6. 最大风险:自然语言到 Prolog 的语义保真
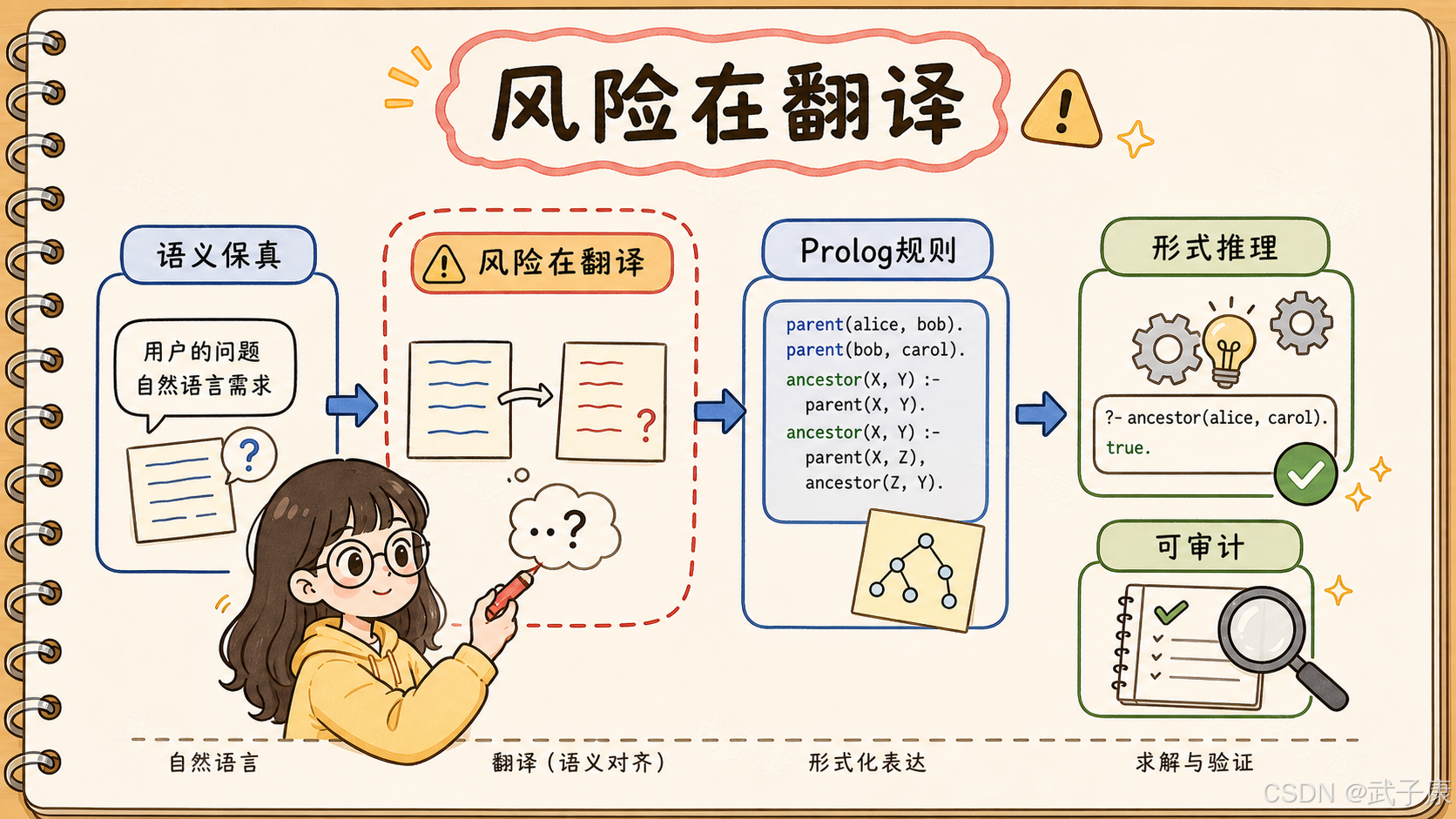
PrologMCP 的短板也很清楚:
text
它只能保证 Prolog 程序按 Prolog 语义执行。
它不能保证 LLM 翻译出来的 Prolog 程序准确表达了用户原意。这就是 autoformalization 的核心风险。
比如用户说:
text
只有高级会员才能访问报表,但管理员不受这个限制。模型可能翻译成:
prolog
can_access(X, report) :- premium(X).
can_access(X, report) :- admin(X).这个翻译看起来合理。但如果真实业务含义是:
text
管理员不受高级会员限制,但仍需要属于该组织。那规则应该是:
prolog
can_access(X, report) :- premium(X), member_of_org(X).
can_access(X, report) :- admin(X), member_of_org(X).如果语义翻译漏掉了组织约束,Prolog 会非常稳定地执行一个错误程序。
所以这类系统的可靠性分两层:
text
语义翻译是否正确:LLM 负责,仍然有风险
形式推理是否正确:Prolog 负责,相对可靠论文真正强化的是第二层,不是彻底解决第一层。
这也是为什么在真实业务里,PrologMCP 不能单独成为可信 Agent 的全部答案。它还需要配合:
text
需求澄清
测试用例
反例检查
人工审计
版本化规则库
执行隔离
资源限制
权限控制
日志追踪尤其是安全边界。论文提到的 lexical sandbox 不是完整安全边界,真正工业化部署需要容器级隔离、资源限制和审计能力。
7. 从后端工程看,它像一个逻辑推理微服务
从 Java 后端或平台工程视角看,PrologMCP 很像一个"逻辑推理微服务",只不过它通过 MCP 暴露给 Agent。
落到企业系统里,可能是这样的结构:
text
用户问题
→ Agent Gateway
→ LLM Planner
→ MCP Router
→ PrologMCP / SQL-MCP / Search-MCP / Workflow-MCP
→ Result Normalizer
→ Answer Generator
→ Trace / Audit Log如果把它和传统工程类比,其实不陌生:
text
Controller 不写复杂业务
Service 不直接拼所有 SQL
规则不散落在一堆 if-else 里
关键执行链路要有日志、监控和审计Agent 工程也一样。LLM 不应该变成一个超级 Controller,把理解、推理、执行和审计全部混在一起。
PrologMCP 的启发是:该抽出来的能力,还是要抽出来。
未来的 Agent 工具层可能会越来越专业化:
text
SQL-MCP
Graph-MCP
Datalog-MCP
SMT-MCP
SAT-MCP
Workflow-MCP
Rules-MCP
Policy-MCP
Simulation-MCPPrologMCP 可以看作这个趋势中的一个样本。
8. 工程师应该怎么使用这类思路?
如果你在做 AI Agent、企业知识库、业务流程自动化或规则型应用,可以先问四个问题:
text
这个问题是否有明确事实和规则?
结论是否需要严格由规则推出?
中间过程是否需要审计?
错误结论是否会带来业务风险?如果答案都是"是",那就不要急着让 LLM 直接回答。更稳的做法是:
text
1. 让 LLM 抽取事实、实体、约束和规则
2. 生成 Prolog / Datalog / SQL / SMT 等中间表示
3. 用专门工具执行
4. 把执行结果、错误和 trace 返回给 LLM
5. 让 LLM 解释结果,而不是替代求解器本身对于 PrologMCP 这类工具,比较适合先从低风险场景试起来:
text
内部规则问答
权限策略解释
配置合法性检查
状态机迁移验证
工单路由规则模拟
教学型逻辑推理演示不建议一开始就放到高风险自动决策链路里。尤其是合规、金融、医疗、权限变更这类场景,必须把规则源、测试集、审计日志和人工复核一起设计进去。
9. 这篇论文的真实信号
我觉得这篇论文真正释放的信号不是"Prolog 要复兴",而是:
text
Agent 系统正在从 Prompt 工程,
走向工具协议、形式化中间表示、符号求解器和可审计执行链路。过去大家更关注:
text
怎么写 Prompt
怎么让模型多思考
怎么调 Function Calling
怎么接更多工具接下来更重要的问题会变成:
text
哪些问题应该交给 LLM?
哪些问题应该交给符号工具?
工具接口如何标准化?
中间结果如何审计?
错误如何反馈给模型修复?
执行环境如何隔离?
形式化结果如何验证语义保真?PrologMCP 只是一个切口,但这个切口很重要。它说明 MCP 不只是"AI 应用的 USB-C",也可能成为 Agent 连接形式化推理系统的基础协议。
总结
PrologMCP 可以理解为一个标准化的 Prolog 推理接口。它把 SWI-Prolog 封装成 MCP Server,让 LLM Agent 可以通过统一工具协议加载逻辑程序、执行查询、检查错误、修复规则、追踪推理。
它解决的不是所有推理问题,而是一类边界清晰的问题:
text
事实和规则可以形式化
答案可以由符号推理得出
中间过程需要更高可审计性它的价值在于把 LLM 的职责从"自己完成所有推理",调整为"把问题翻译成可执行形式,并调用合适的推理工具"。
它的限制也必须承认:自然语言到 Prolog 的语义翻译仍然可能出错;实验主要是合成 benchmark;当前实现基于 SWI-Prolog;工业级安全隔离还需要补齐。
所以对这篇论文最准确的判断是:
text
PrologMCP 不是可信 Agent 的终点,
但它是 MCP 走向形式化推理工具层的一个清晰样本。
未来可靠的 Agent,不一定是更会"想"的单体模型,
而是更会把问题拆给正确工具的复合系统。错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
run_goal 返回 false 但人工推理应该是 true |
LLM 翻译 Prolog 时漏掉了事实、约束或边界条件(如 member_of_org) |
用 inspect_predicate 列出谓词定义,对照原始需求逐条比对 |
调用 replace_predicate 补齐遗漏子句,重跑查询 |
list_messages 报「未定义谓词」 |
LLM 生成了 Prolog 内置或自定义谓词之外的名字(拼写/arity 错误) | 读取 list_messages 中的结构化诊断,结合 inspect_predicate 检查 arity |
修改 Prompt 或调用 replace_predicate 替换为正确谓词 |
run_goal 长时间无返回 |
递归规则无终止条件,触发无限展开 | 论文默认会做推理深度限制,先看是否命中深度上限 | 加终止子句,或拆分谓词;必要时调小深度限制 |
| 不同 session 间事实相互串扰 | 复用了同一个 Prolog session,未做状态隔离 | 检查 MCP Server 会话管理逻辑 | 每个任务开新 session(论文默认行为),完成后调用 close_session |
| 推理正确但结论不可解释 | 只看 run_goal 的最终 true/false,没生成 proof tree |
缺少 trace_goal 输出 |
调用 trace_goal 生成深度受限的证明树,作为审计材料 |
| 容器/进程被恶意 Prolog 代码影响 | 仅有 lexical sandbox,无操作系统级隔离 | 检查部署是否启用容器/cgroups | 增加容器级隔离、资源限制、审计日志;高风险场景人工复核 |
| 形式化推理正确但与业务含义不符 | 自然语言到 Prolog 的语义翻译失真(autoformalization 风险) | 用反例与业务规则库交叉验证 | 在 Prompt 中要求 LLM 输出事实、规则、约束清单,配测试用例与人工审计 |
| Prolog Formalizer 在通用任务上提升不明显 | 任务本身难以形式化,或规则频繁变动 | 看规则是否稳定、能否枚举 | 退回 reasoning LLM 路径,或把任务拆分为「可形式化子任务 + 不可形式化子任务」 |
| LLM 反复生成无效 Prolog 陷入循环 | 没有把 inspect/repair 结果反馈回模型 |
检查 Agent 是否读取 list_messages 与 inspect_predicate 输出 |
强制把结构化诊断拼回下一轮 Prompt,走 translate→run→inspect→repair 闭环 |
plunit 测试失败但生产查询通过 |
测试覆盖了边界条件,生产查询没走到那些分支 | 用 run_tests 与 trace_goal 联合分析 |
把失败用例补进测试集,固化规则库版本 |
作者:武子康的个人博客