Redis 的存取速度为什么这么快
目录
- 因素一:内存,不是磁盘
- 因素二:高效的数据结构
- 因素三:单线程,反而更快
- [因素四:IO 多路复用](#因素四:IO 多路复用)
- [因素五:RESP 协议够简单](#因素五:RESP 协议够简单)
- 常见误区
- 小结
redis常常用于缓存,是因为它的存取速度非常之快,它比mysql快特别多
有多快?一条 SQL 查询用户信息,执行时间 200ms。换成 Redis 的 GET user:1001,耗时 0.1ms。同样是"从存储里取一个值",差了 2000 倍。
你可能有听过:Redis 用的内存,MySQL 用的磁盘,所以快。这个回答是正确的,但只对了五分之一。Redis 快不是单一因素的结果,而是五个设计决策叠加出来的。本篇文章就从这五个因素来探讨一下Redis为什么这么快。
因素一:存取于内存
这是最直观、最主要的一个因素,也是所有其他因素的前提。
CPU 访问内存大约需要 100 纳秒,访问磁盘需要 10 毫秒。差了十万倍。
MySQL 的数据存在磁盘上。即使有 Buffer Pool 缓存热数据,但 Buffer Pool 的大小有限,不可能把整张表都放进去。一旦查询的数据不在缓存中,就得触发磁盘 IO。
Redis 把所有数据都放在内存里 。客户端发来一个 GET 命令,Redis 直接从内存中读取值返回,没有任何磁盘 IO 的参与。这就是 0.1ms 级响应时间的基础。
但"在内存里"只是入场券。 同样是内存数据库,设计不好一样慢。接下来的四个因素决定了 Redis 在内存之上能做到多快。
因素二:高效的数据结构
Redis 不是一个简单的 key-value 缓存。它支持 String、Hash、List、Set、ZSet 等多种数据类型,每种类型底层都用了专门优化过的数据结构。
这些数据结构决定了操作的时间复杂度,而时间复杂度决定了性能上限。
以 String 类型为例,Redis 没有直接用 C 语言原生的字符串(char*),而是自己设计了 SDS(Simple Dynamic String)。SDS 多存了一个 len 字段记录字符串长度,获取长度的操作从 O(n) 变成了 O(1)。同时 SDS 预分配了多余空间,追加字符串时不需要每次都重新分配内存。
再看 Hash 类型。当字段数量较少时,Redis 用 ziplist(压缩列表)存储,所有数据紧凑排列在一块连续内存中,节省空间。当字段数量超过阈值,自动转成哈希表,查找复杂度是 O(1)。
最值得一提的是 ZSet(有序集合)。ZSet 需要同时支持"按 score 排序"和"按 member 查找"两个需求,Redis 用了两个数据结构组合实现:
- 哈希表:member → score 的映射,O(1) 查分值
- 跳表:按 score 排序的多层链表,支持 O(log n) 的范围查询
因素三:单线程处理
Redis 处理命令是单线程的。同一时刻只有一个命令在执行。
这听起来很反直觉。单线程不是应该更慢吗?为什么不用多线程,让多个命令同时执行?
因为Redis的瓶颈不在 CPU,而在网络 IO 和内存访问。Redis 的每个命令执行时间是纳秒到微秒级别,CPU 根本不是瓶颈。真正花时间的是等客户端的请求通过网络到达。多线程不但帮不上忙,反而会引入额外开销:
1. 锁竞争
多线程同时修改一个哈希表,必须加锁。加锁意味着线程要等、要争抢,这些等待时间可能比命令本身的执行时间还长。
2. 上下文切换
CPU 在不同线程之间切换时,需要保存和恢复寄存器、缓存等上下文信息。这个过程本身就有开销,而且会导致 CPU 缓存失效,增加内存访问延迟。
3. 数据结构复杂度上升
为了让数据结构线程安全,要么加锁,要么用无锁算法(CAS)。前者影响性能,后者增加代码复杂度。单线程下,这些都不需要考虑。
单线程的好处是显而易见的:没有锁、没有上下文切换、代码简单、调试方便。Redis 的作者 antirez 说过,单线程是他做出的最正确的设计决策之一。
Redis 6.0 时引入了多线程 IO,但命令执行仍然是单线程。多线程只负责网络数据的读写,把数据从 socket 读出来、把响应写回 socket。命令执行那一步,还是单线程串行。这说明 Redis 团队也认为,命令执行用单线程是正确的,瓶颈已经转移到了网络 IO 层面。
因素四:IO 多路复用
Redis使用多路复用的IO模型,使其可以单线程就处理上万个客户端连接。
传统的阻塞 IO 模型下,一个线程处理一个连接。线程调用 read() 等数据到达,如果没有数据,线程就阻塞着干不了别的。要同时处理 1000 个连接,就得 1000 个线程。
IO 多路复用改变了这个模型。它的核心思想是:一个线程同时监听多个连接,哪个连接有数据到达就处理哪个,其他的继续等。
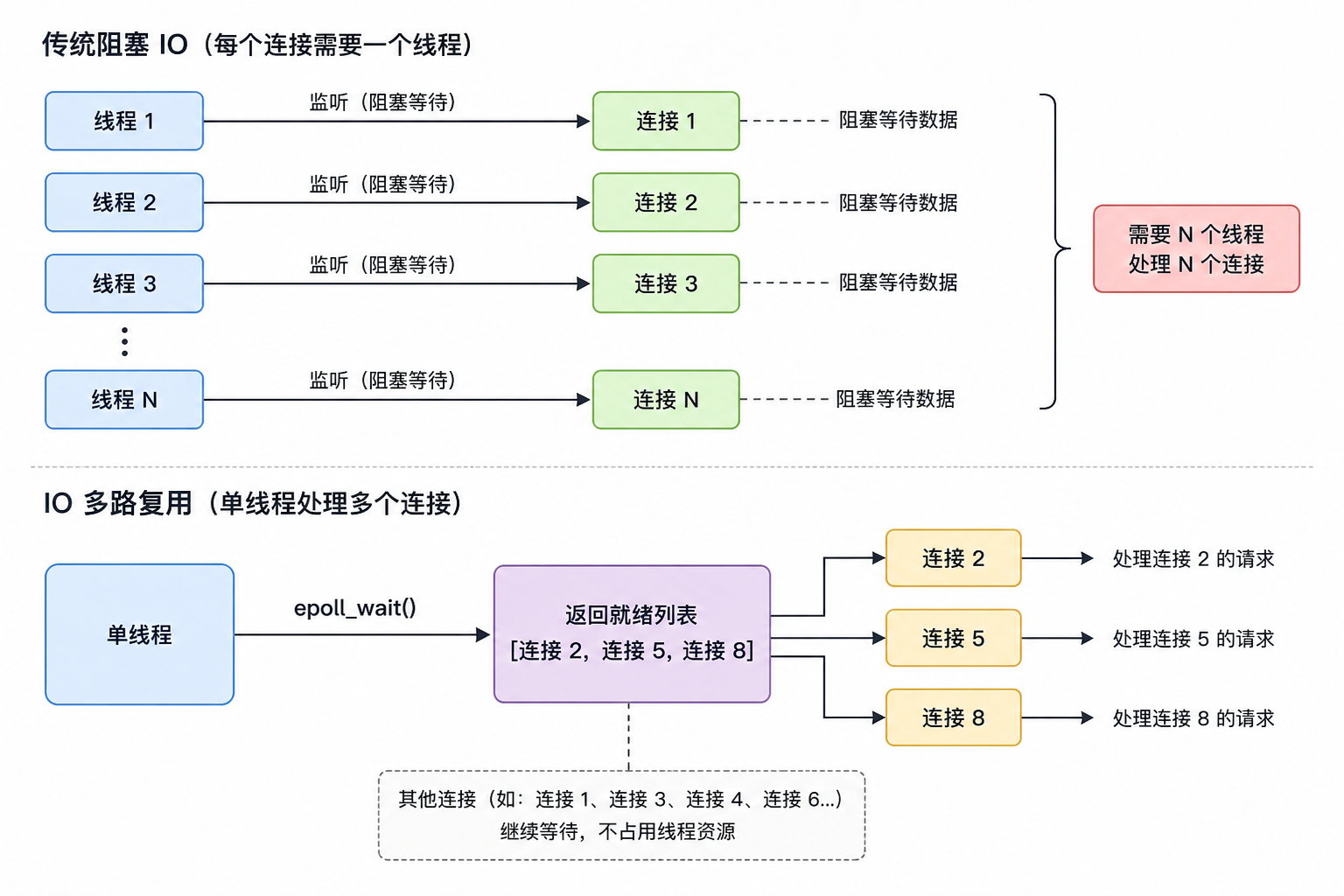
在 Linux 上,Redis 用 epoll 实现 IO 多路复用。epoll_wait() 会返回所有就绪的连接列表,Redis 遍历这个列表,依次执行每个连接发来的命令。因为命令执行本身很快(微秒级),所以这个遍历过程也很快,一个线程就能撑住数万并发连接。
这也是为什么 Redis 的性能瓶颈通常不在 CPU,而在网络。 单线程处理命令绰绰有余,但网络带宽和延迟是有上限的。所以生产环境中,Redis 通常部署在内网,用连接池复用连接,减少网络开销。
因素五:RESP 协议够简单
Redis 和客户端之间通信用的是 RESP(Redis Serialization Protocol)协议。这个协议设计得极其简单:
+OK\r\n → 简单字符串
-ERR unknown command\r\n → 错误
:1000\r\n → 整数
$5\r\nhello\r\n → 批量字符串(5字节)
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n → 数组客户端发给 Redis 的命令,本质上就是一个字符串数组。比如 GET user:1001,序列化后就是:
*2\r\n$3\r\nGET\r\n$10\r\nuser:1001\r\n解析过程非常简单:按行读、读到 $ 就读长度、再按长度读数据。不需要复杂的状态机,不需要处理嵌套结构,解析成本极低。
对比一下 HTTP 协议。一个 HTTP 请求要解析请求行、请求头、空行、请求体,请求头是键值对但格式灵活,还有各种编码方式(chunked、gzip)。解析一个 HTTP 请求的开销远大于解析一个 RESP 请求。
协议越简单,解析越快,CPU 开销越小。 RESP 就是专门为 Redis 的使用场景设计的------命令都是简单的字符串数组,不需要 HTTP 那么强的表达能力。
小结
Redis 快的本质是:在内存之上,用最合适的工具做最合适的事。 高效的数据结构保证了操作的时间复杂度接近理论最优,单线程模型避免了锁竞争和上下文切换的开销,IO 多路复用让一个线程就能管理成千上万的连接,RESP 协议把通信解析的成本压到最低。这五个因素不是孤立的,它们互相配合,构成了一个没有明显短板的系统。