引述
上一篇我们介绍了损失函数 ------ 它给模型的表现打了一个分数,告诉我们"预测得有多差"。但光知道分数还不够,我们想知道:每个参数对这个分数贡献了多少"责任"? 应该把哪个参数调大、哪个调小,才能让损失降下来?
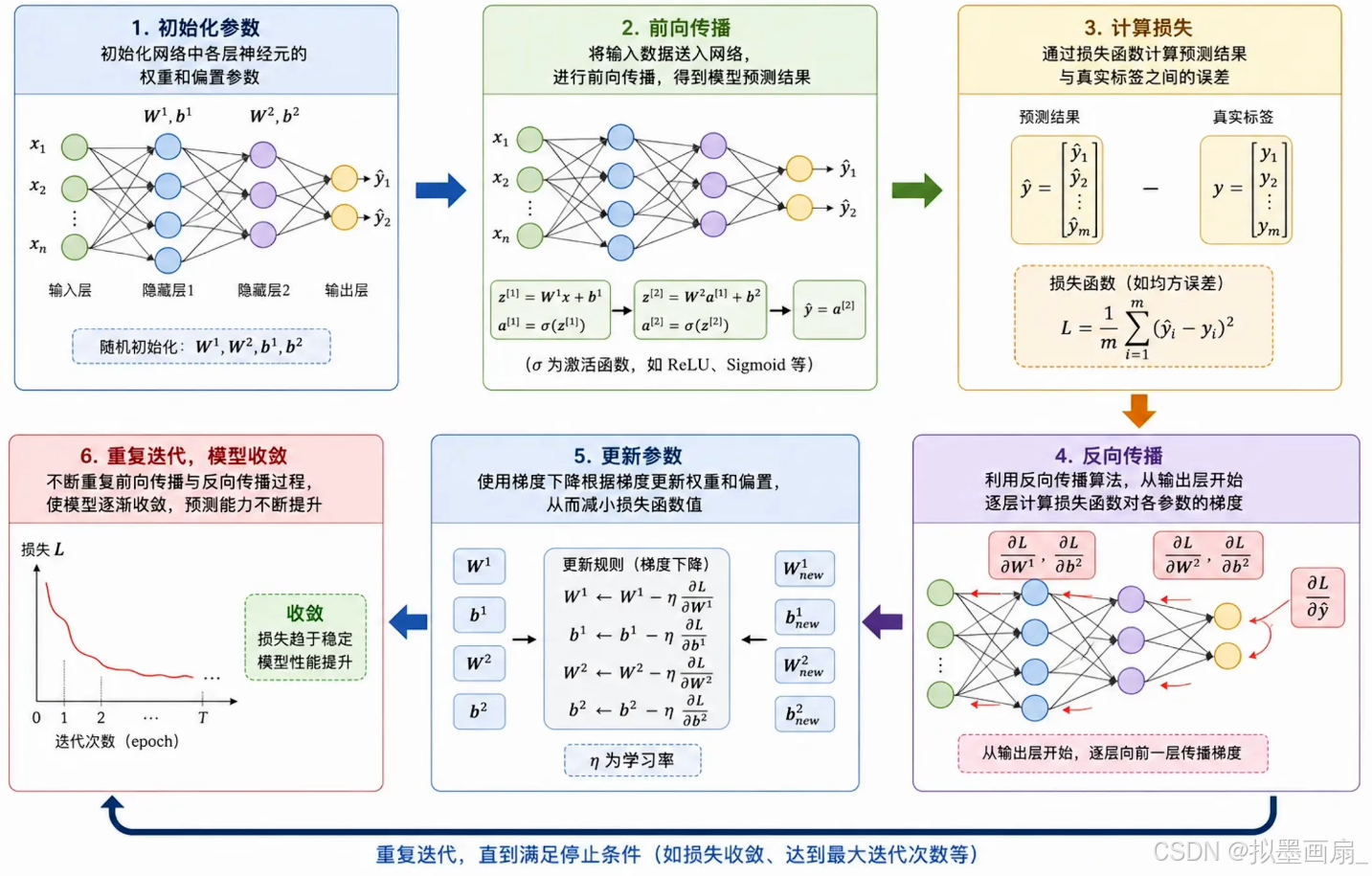
答案就是反向传播 。它做的事只有一件:把损失值从输出层一路传回输入层,逐层算出每个参数对最终损失的偏导数 。这些偏导数组成的向量就是梯度------它指明了损失上升最快的方向。有了梯度,后面介绍的优化器就能沿反方向更新参数,让损失一步步下降。
反向传播之所以高效,是因为它利用了微积分中的链式法则:把复杂函数的求导拆成一个个简单节点局部导数的乘积,一次前向、一次反向,就能算出全部参数的梯度------无论网络有多深、参数有多少。
反向传播
通过计算得到的损失值 L\mathcal{L}L 越大,说明误差越离谱。那么应该如何调节神经网络中的权重矩阵 WWW 和偏置 bbb ,才能使 L\mathcal{L}L 变小?
神经网络的做法是梯度下降 ,通过计算损失对每个参数的偏导,组成向量 ------ 梯度,即指向损失上升最快的方向 。要使损失下降,令其沿负梯度的方向走一小步即可:
W'←W−η⋅∂L∂W W' ← W-η\cdot\frac{\partial\mathcal{L}}{\partial{W}} W'←W−η⋅∂W∂L
上面的公式中,WWW 即为权重,ηηη 即为学习率(控制每次更新的一小步是多少)
梯度概念
- 概念 ------ 梯度 是向量,指向函数值增加最快的方向。神经网络中,我们关心损失函数关于参数的梯度,并沿着负梯度方向更新参数
- 示例 ------ 对于函数 f(x0,x1)=x02+x12f(x_0, x_1) = x_0^2 + x_1^2f(x0,x1)=x02+x12,梯度为 (∂f∂x0,∂f∂x1)=(2x0,2x1)\left(\frac{\partial f}{\partial x_0}, \frac{\partial f}{\partial x_1}\right) = (2x_0, 2x_1)(∂x0∂f,∂x1∂f)=(2x0,2x1)
数值微分法
数学原理:导数定义
-
导数表示函数在某一点的变化率,即"输入变化一丁点,输出变化多少"
f′(x)=limh→0f(x+h)−f(x)h f'(x) = \lim_{h \to 0} \frac{f(x + h) - f(x)}{h} f′(x)=h→0limhf(x+h)−f(x)
这个公式的意思是:在
x处加一个极小量h,通过f(x)的变化量除以h就是平均变化率。当h无限趋近于 0 时,比值趋近于精确的导数 -
但计算机有两个做不到的事:
-
无法处理极限 ------ 计算机只能处理离散值,不能真的让
h"趋近于零" -
不能解析求导 ------ 计算机不知道
f(x) = x²的导数是2x,它只会算具体的数值
所以,计算机退而求其次:用一个非常小的
h代替 极限趋近于零 ,直接算出差商作为导数的近似值 -
-
更进一步,用中心差分 公式(左右各扰动一次)比单侧差分精度更高:
∂L∂w≈L(w+h)−L(w−h)2h \frac{\partial L}{\partial w} \approx \frac{L(w + h) - L(w - h)}{2h} ∂w∂L≈2hL(w+h)−L(w−h)
直观理解 :在参数
w左右各加一个微小扰动(分别往正、负方向挪一小步),观察损失函数在两点之间的变化。两点的损失值之差除以两点之间的距离,即为该处的平均坡度------也就是我们想要的梯度近似值
代码实现
-
定义
numerical_gradient方法,传入函数f(x) = x²,求在x=3处的导数pythondef numerical_gradient(f, x, h=1e-4): """ f: 损失函数,输入为 numpy 数组 x,输出标量 x: 待求梯度的参数,numpy 数组 h: 微小扰动量 """ grad = np.zeros_like(x) # 初始化梯度数组,形状与 x 相同 # 遍历 x 中的每一个元素 for i in range(x.size): # 保存原始值 tmp = x.flat[i] # 计算 f(x + h) x.flat[i] = tmp + h fxh1 = f(x) # 计算 f(x - h) x.flat[i] = tmp - h fxh2 = f(x) # 中心差分公式 grad.flat[i] = (fxh1 - fxh2) / (2 * h) # 恢复原始值 x.flat[i] = tmp return gradpython# 示例:求 f(x) = x² 在 x=3 处的导数 def f(x): return x**2 x = np.array([3.0]) grad = numerical_gradient(f, x)pythonprint(f"数值梯度: {grad[0]}") # 约 6.0000 print(f"解析梯度: {2 * x[0]}") # 6.0000
致命缺点
- 计算量随参数数量线性增长,根本无法用于实际训练 ❌
- 对每个参数都要分别做两次 前向传播(一次
w+h,一次w-h) - 一个
ResNet-50有约2000万参数,一次梯度计算是4000万次前向 ------ 这是完全不可行的!
- 对每个参数都要分别做两次 前向传播(一次
误差反向传播法
数学原理:链式法则
-
链式法则是微积分中处理复合函数求导的定理,若 z=f(g(x))z = f(g(x))z=f(g(x)),有:
dzdx=dzdg⋅dgdx \frac{dz}{dx} = \frac{dz}{dg} \cdot \frac{dg}{dx} dxdz=dgdz⋅dxdg
-
推广到多层复合函数,有:
∂L∂W1=∂L∂yn⋅∂yn∂yn−1⋅...⋅∂y2∂y1⋅∂y1∂W1 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial y_n} \cdot \frac{\partial y_n}{\partial y_{n-1}} \cdot ... \cdot \frac{\partial y_2}{\partial y_1} \cdot \frac{\partial y_1}{\partial W_1} ∂W1∂L=∂yn∂L⋅∂yn−1∂yn⋅...⋅∂y1∂y2⋅∂W1∂y1
-
神经网络本质上就是一个多层复合函数(输入经过一层又一层变换,最终得到损失)
-
链式法则说明:最终损失对任意参数的梯度,可以分解为"从输出到该参数路径上每一层的局部梯度"的乘积
数学工具:计算图
- 计算图将计算过程可视化为节点和边的图形工具,其中
- 节点表示操作(加法、乘法、激活函数等)
- 边表示数据流向
计算图与买苹果
-
实例 ------ 太郎在超市买了 222 个 100100100 日元一个的苹果,消费税是 10%10\%10%,
-
正向传播 ------ 计算太郎需要支付金额
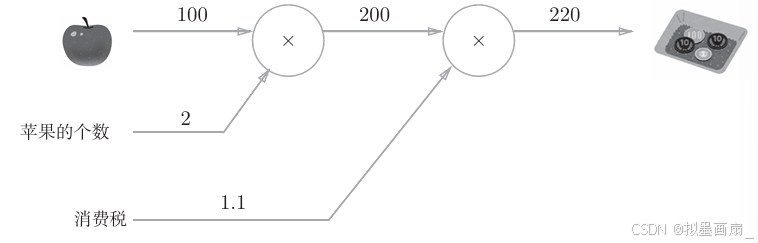
- 开始时,苹果的 100100100 日元流到 ×2×2×2 节点,变成 200200200 日元,然后被传递给下一个节点
- 接着,200200200 日元流向 ×1.1×1.1×1.1 节点,变成 220220220 日元
- 因此,从计算图的结果可知,答案为 220220220 日元
-
反向传播 ------ 已经知道 222 个苹果要 220220220 日元,如果苹果价格上涨,最终支付金额会涨多少
设苹果的价格为 xxx,支付金额为 LLL,则相当于求导数 ∂L∂x\frac{\partial L}{\partial x}∂x∂L,即是支付金额关于苹果价格的导数
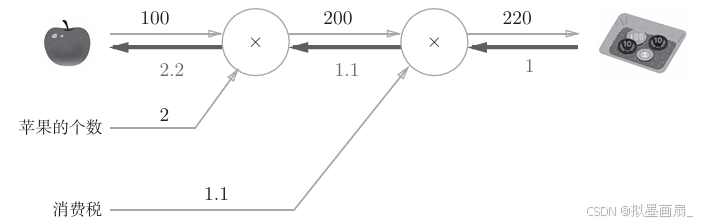
- 假设苹果上涨 111 日元,反向传播从右向左传递,从 1→1.1→2.21→1.1→2.21→1.1→2.2
- 这意味着,苹果每上涨 111 日元, 最终支付增加 2.22.22.2 日元
计算图与链式法则
-
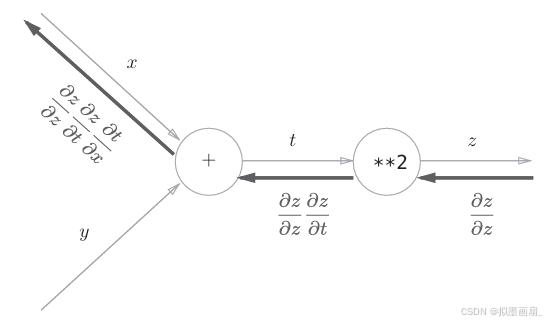
实例 ------ 对复合函数 z=(x+y)2z=(x+y)^2z=(x+y)2 由两个式子组成:
z=t2t=x+y z=t^2\\t=x+y z=t2t=x+y
-
链式法则过程 ------ ∂z∂x\frac{\partial z}{\partial x}∂x∂z(zzz 对 xxx 的导数)可以由 ∂z∂t\frac{\partial z}{\partial t}∂t∂z(zzz 关于 ttt 的导数)和 ∂t∂x\frac{\partial t}{\partial x}∂x∂t(ttt 关于 xxx 的导数)的乘积表示,即
∂z∂x=∂z∂t∂t∂x \frac{\partial z}{\partial x} = \frac{\partial z}{\partial t}\frac{\partial t}{\partial x} ∂x∂z=∂t∂z∂x∂t
又由于 ∂z∂t=2z\frac{\partial z}{\partial t}=2z∂t∂z=2z,∂t∂x=1\frac{\partial t}{\partial x}=1∂x∂t=1,故
∂z∂x=∂z∂t∂t∂x=2t⋅1=2(x+y) \frac{\partial z}{\partial x} = \frac{\partial z}{\partial t}\frac{\partial t}{\partial x}=2t\cdot1=2(x+y) ∂x∂z=∂t∂z∂x∂t=2t⋅1=2(x+y)
-
计算图过程
-
正向传播 ------ 从左往右,依次计算每个节点的输出。
- 输入 xxx 和 yyy,经过节点 +++,输出 t=x+yt = x + yt=x+y
- ttt 进入节点 ∗∗2**2∗∗2,输出 z=t2z = t^2z=t2
-
反向传播 ------ 从右往左,将上游传来的梯度乘以当前节点的局部导数,传递给下游节点
- 起始信号:最右端传来的梯度恒为 ∂z∂z=1\frac{\partial z}{\partial z} = 1∂z∂z=1,表示损失对自己的导数永远是 1,是反向传播的起点
- 节点(∗∗2**2∗∗2)
- 输入是上游传来的梯度 ∂z∂z\frac{\partial z}{\partial z}∂z∂z,将其乘以该节点的局部导数
- 正向传播时输入是 ttt、输出是 z=t2z = t^2z=t2,所以局部导数为 ∂z∂t=2t\frac{\partial z}{\partial t} = 2t∂t∂z=2t
- 因此输出为 1×2t=2t1 \times 2t = 2t1×2t=2t,传递给下一个节点
- 节点(+++)
- 输入是上游传来的梯度 2t2t2t,将其乘以该节点的局部导数
- 正向传播时输入是 xxx 和 yyy、输出是 t=x+yt = x + yt=x+y,所以局部导数为 ∂t∂x=1\frac{\partial t}{\partial x} = 1∂x∂t=1、∂t∂y=1\frac{\partial t}{\partial y} = 1∂y∂t=1
- 因此输出
- 传给 xxx 的梯度:2t×1=2t=2(x+y)2t \times 1 = 2t = 2(x+y)2t×1=2t=2(x+y)
- 传给 yyy 的梯度:2t×1=2t=2(x+y)2t \times 1 = 2t = 2(x+y)2t×1=2t=2(x+y)
- 最终结果:∂z∂x=2(x+y)\frac{\partial z}{\partial x} = 2(x+y)∂x∂z=2(x+y),∂z∂y=2(x+y)\frac{\partial z}{\partial y} = 2(x+y)∂y∂z=2(x+y),与链式法则的解析结果一致
-
隐藏层的反向传播实现
仿射变换层
加法节点
-
理论 ------ 以 z=x+yz=x+yz=x+y 为对象,其偏导数可由下式解析性地计算出来:
∂z∂x=1,∂z∂y=1 \frac{\partial z}{\partial x}=1,\frac{\partial z}{\partial y}=1 ∂x∂z=1,∂y∂z=1
由计算图,可以表述如下:
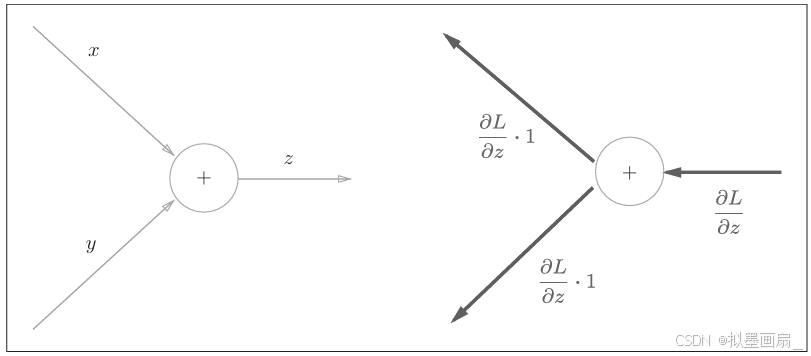
这里把从上游传过来的导数的值设为 ∂L∂z\frac{\partial L}{\partial z}∂z∂L ,是因为 z=x+yz=x+yz=x+y 的计算位于某个最终输出值为 LLL 大型计算图的某个地方,故该节点从上游读取 ∂L∂z\frac{\partial L}{\partial z}∂z∂L ,传递给下游 ∂L∂x\frac{\partial L}{\partial x}∂x∂L 和 ∂L∂y\frac{\partial L}{\partial y}∂y∂L
-
实例 ------ 假设有 10+5=1510+5=1510+5=15 这一计算,反向传播时,从上游会传来值 1.31.31.3,那么计算图表示如下:
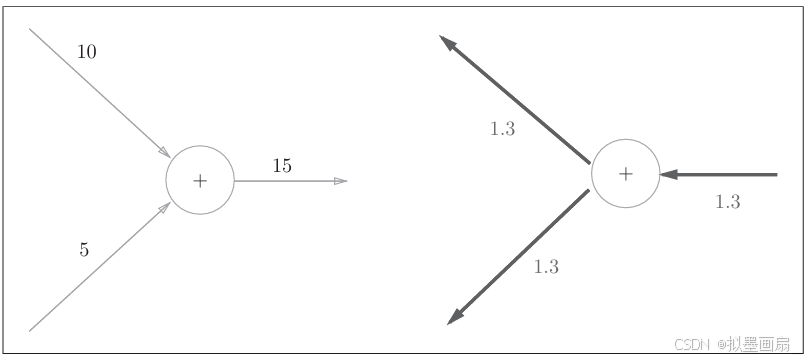
-
代码实现 ------ 通过上面的论述,可以实现加法层的
forward和backward代码pythonclass AddLayer: def __init__(self): pass def forward(self, x, y): out = x + y return out def backward(self, dout): dx = dout * 1 dy = dout * 1 return dx, dy
乘法节点
-
理论 ------ 以 z=xyz=xyz=xy 为对象,其偏导数可由下式解析性地计算出来:
∂z∂x=y,∂z∂y=x \frac{\partial z}{\partial x}=y,\frac{\partial z}{\partial y}=x ∂x∂z=y,∂y∂z=x
由计算图,可以表述如下:
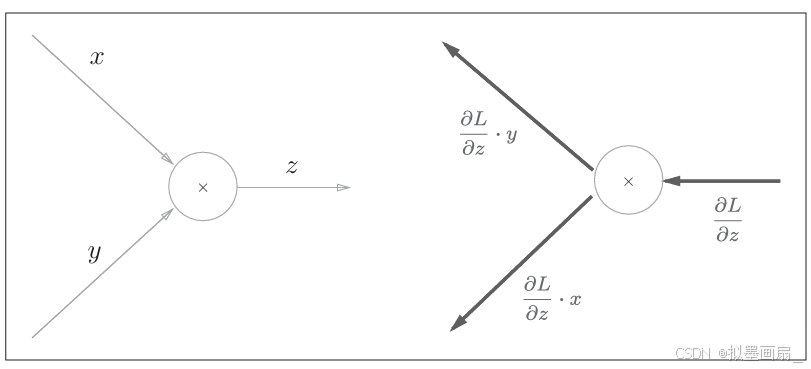
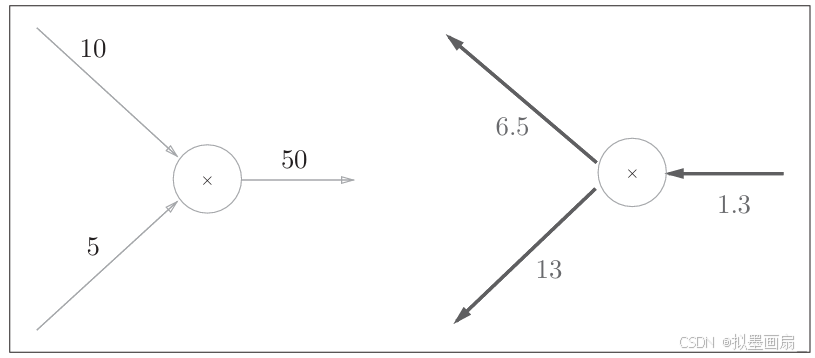
-
实例 ------ 假设有 10×5=5010×5=5010×5=50 这一计算,反向传播时,从上游会传来值 1.31.31.3,那么计算图表示如下:
-
代码实现 ------ 通过上面的论述,可以实现乘法层的
forward和backward代码pythonclass MulLayer: def __init__(self): self.x = None self.y = None def forward(self, x, y): self.x = x self.y = y out = x * y return out def backward(self, dout): dx = dout * self.y # 翻转x和y dy = dout * self.x return dx, dy
买苹果的例子
-
现在考虑下面买苹果和橘子的例子:
-
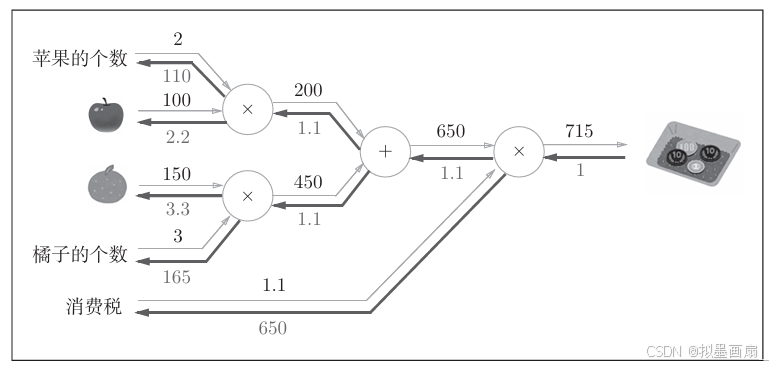
前向传播 ------ 太郎在超市买了 222 个 100100100 日元一个的苹果, 333 个 150150150 日元一个的橘子,消费税是 10%10\%10%,计算太郎需要支付金额
-
反向传播 ------ 已经知道 222 个苹果和 333 个橘子要 750750750 日元,如果苹果和橘子价格上涨,最终支付金额会涨多少
-
用计算图表示,如下:
-
-
代码实现 ------ 根据上面的计算图,使用代码实现:
python# 输入以及权重 apple = 100 apple_num = 2 orange = 150 orange_num = 3 tax = 1.1 # 简单层 mul_apple_layer = MulLayer() mul_orange_layer = MulLayer() add_apple_orange_layer = AddLayer() mul_tax_layer = MulLayer() # 前向传播 apple_price = mul_apple_layer.forward(apple, apple_num) #(1) orange_price = mul_orange_layer.forward(orange, orange_num) #(2) all_price = add_apple_orange_layer.forward(apple_price, orange_price) #(3) price = mul_tax_layer.forward(all_price, tax) #(4) # 反向传播 dprice = 1 dall_price, dtax = mul_tax_layer.backward(dprice) #(4) dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price) #(3) dorange, dorange_num = mul_orange_layer.backward(dorange_price) #(2) dapple, dapple_num = mul_apple_layer.backward(dapple_price) #(1) print(price) # 715 print(dapple_num, dapple, dorange, dorange_num, dtax) # 110 2.2 3.3 165 650
矩阵点乘节点
前面涉及的反向传播均为标量 运算,然而在实际的神经网络是通过矩阵形式 进行运算,而矩阵点乘 dotdotdot 运算是仿射变换层的重点,因此有必要明白其反向传播的过程。
Y=X⋅W+B Y=X \cdot W+B Y=X⋅W+B
-
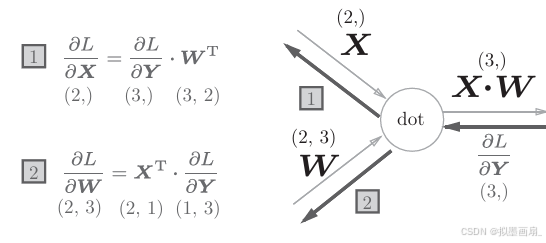
理论 ------ 以 Y=X⋅WY=X \cdot WY=X⋅W 为例,其中各变量的形状设置如下:
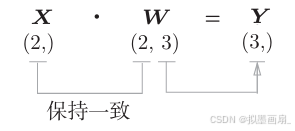
注意 :(2,)(2,)(2,) 是
NumPy中一维数组的shape写法,不要与数学的矩阵写法混淆。它既不是行向量,也不是列向量,就是一条扁平数组,没有行列之分假设损失函数为 LLL,反向传播时上游传来的梯度为 ∂L∂Y\frac{\partial L}{\partial Y}∂Y∂L(形状与 YYY 相同,为 (3,)(3,)(3,)),则其前向传播的计算图,可以表述如下。
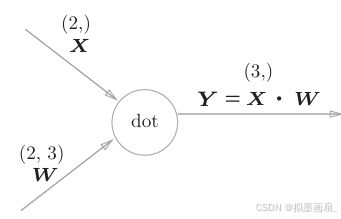
-
正向传播逐元素展开 : Y=X⋅WY=X \cdot WY=X⋅W 的逐元素形式为:yj=∑i=12xi⋅wij(j=1,2,3)y_j = \sum_{i=1}^{2} x_i \cdot w_{ij} \quad (j = 1, 2, 3)yj=∑i=12xi⋅wij(j=1,2,3),写成方程组形式为:
{y1=x1⋅w11+x2⋅w21y2=x1⋅w12+x2⋅w22y3=x1⋅w13+x2⋅w23 \begin{cases} y_1 = x_1 \cdot w_{11} + x_2 \cdot w_{21} \\ y_2 = x_1 \cdot w_{12} + x_2 \cdot w_{22} \\ y_3 = x_1 \cdot w_{13} + x_2 \cdot w_{23} \end{cases} ⎩ ⎨ ⎧y1=x1⋅w11+x2⋅w21y2=x1⋅w12+x2⋅w22y3=x1⋅w13+x2⋅w23
-
推导 ∂L∂xi\frac{\partial L}{\partial x_i}∂xi∂L :根据链式法则,LLL 对 xix_ixi 的梯度等于 LLL 对每个 yjy_jyj 的梯度乘以 yjy_jyj 对 xix_ixi 的偏导,再求和:
∂L∂xi=∑j=13∂L∂yj⋅∂yj∂xi \frac{\partial L}{\partial x_i} = \sum_{j=1}^{3} \frac{\partial L}{\partial y_j} \cdot \frac{\partial y_j}{\partial x_i} ∂xi∂L=j=1∑3∂yj∂L⋅∂xi∂yj
由 yj=∑kxk⋅wkjy_j = \sum_{k} x_k \cdot w_{kj}yj=∑kxk⋅wkj,对固定的 iii 和 jjj,有:
∂yj∂xi=wij \frac{\partial y_j}{\partial x_i} = w_{ij} ∂xi∂yj=wij
代入得:
∂L∂xi=∑j=13∂L∂yj⋅wij \frac{\partial L}{\partial x_i} = \sum_{j=1}^{3} \frac{\partial L}{\partial y_j} \cdot w_{ij} ∂xi∂L=j=1∑3∂yj∂L⋅wij
将三个分量写成向量形式,其中 WTW^TWT 是 WWW 的转置
∂L∂X=∂L∂Y⋅WT \frac{\partial L}{\partial X} = \frac{\partial L}{\partial Y} \cdot W^T ∂X∂L=∂Y∂L⋅WT
形状验证 :∂L∂O\frac{\partial L}{\partial O}∂O∂L 的形状为 (3,)(3,)(3,),WTW^TWT 的形状为 (3,2)(3, 2)(3,2),乘积结果为 (2,)(2,)(2,),与 XXX 的形状一致 ✅
-
推导 ∂L∂wij\frac{\partial L}{\partial w_{ij}}∂wij∂L :根据链式法则,LLL 对 wijw_{ij}wij 的梯度为:
∂L∂wij=∂L∂oj⋅∂oj∂wij \frac{\partial L}{\partial w_{ij}} = \frac{\partial L}{\partial o_j} \cdot \frac{\partial o_j}{\partial w_{ij}} ∂wij∂L=∂oj∂L⋅∂wij∂oj
由 yj=∑kxk⋅wkjy_j = \sum_{k} x_k \cdot w_{kj}yj=∑kxk⋅wkj,对固定的 iii 和 jjj,有:
∂yj∂wij=xi \frac{\partial y_j}{\partial w_{ij}} = x_i ∂wij∂yj=xi
代入得:
∂L∂wij=∂L∂yj⋅xi \frac{\partial L}{\partial w_{ij}} = \frac{\partial L}{\partial y_j} \cdot x_i ∂wij∂L=∂yj∂L⋅xi
将所有 i,ji, ji,j 组合写成矩阵形式:
∂L∂W=XT⋅∂L∂Y \frac{\partial L}{\partial W} = X^T \cdot \frac{\partial L}{\partial Y} ∂W∂L=XT⋅∂Y∂L
形状验证 :XXX 视为列向量时形状为 (2,1)(2, 1)(2,1),其转置 XTX^TXT 为 (1,2)(1, 2)(1,2)。∂L∂O\frac{\partial L}{\partial O}∂O∂L 视为行向量时形状为 (1,3)(1, 3)(1,3)。乘积 (1,2)⋅(1,3)(1, 2) \cdot (1, 3)(1,2)⋅(1,3) 需调整为 (2,1)⋅(1,3)=(2,3)(2, 1) \cdot (1, 3) = (2, 3)(2,1)⋅(1,3)=(2,3),与 WWW 的形状一致 ✅
-
综上,可以看出, dotdotdot 函数的反向传播计算图为:
-
-
代码实现
pythonclass DotLayer: def __init__(self): self.x = None self.W = None def forward(self, x, W): self.x = x self.W = W out = np.dot(x, W) return out def backward(self, dout): dx = np.dot(dout, self.W.T) dW = np.dot(self.x.T, dout) return dx, dW
Affine 层
-
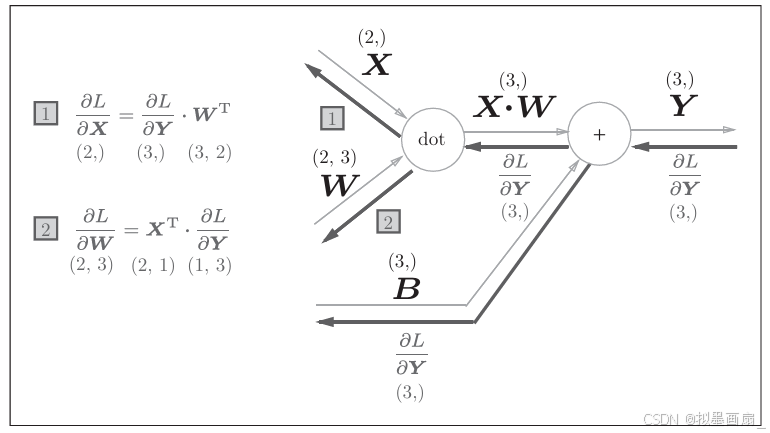
理论 ------ 通过上面 dotdotdot 节点的分析,不难得:仿射变换 Y=X⋅W+BY=X \cdot W+BY=X⋅W+B 实际上是在 dotdotdot 节点上叠加一个加法节点,而加法节点是原样输出 ,故出偏导数和计算图如下:
∂L∂X=∂L∂Y⋅WT∂L∂W=XT⋅∂L∂Y∂L∂B=∂L∂Y \frac{\partial L}{\partial X} = \frac{\partial L}{\partial Y} \cdot W^T\\ \frac{\partial L}{\partial W} = X^T \cdot \frac{\partial L}{\partial Y}\\ \frac{\partial L}{\partial B} = \frac{\partial L}{\partial Y} ∂X∂L=∂Y∂L⋅WT∂W∂L=XT⋅∂Y∂L∂B∂L=∂Y∂L
-
代码实现
pythonclass Affine: def __init__(self, W, b): self.W = W self.b = b self.x = None self.dW = None self.db = None def forward(self, x): self.x = x out = np.dot(x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.reshape(-1, 1), dout.reshape(1, -1)) self.db = dout return dx
批版本的 Affine 层
理解区分
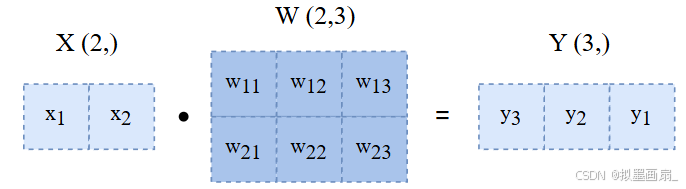
前面
Affine层的矩阵 XXX 的形状是 (2,)(2,)(2,),即 X=x1x2X=\begin{bmatrix} x_1&x_2 \end{bmatrix}X=x1x2,代表的是一个样本的在 222 个输入神经元上的取值,通过与权重矩阵 WWW 、偏置矩阵 BBB 运算,得到输出矩阵 YYY
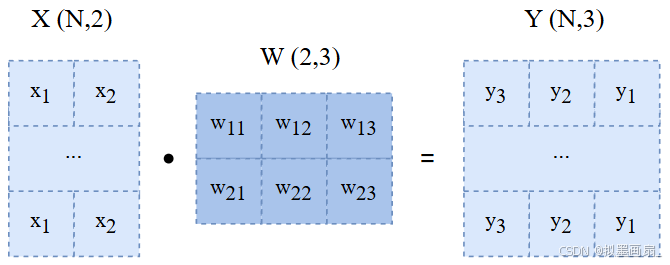
在批版本的Affine层,矩阵 XXX 的形状变为 (N,2)(N,2)(N,2),即 X=x11x12x21x22...xn1xn2X=\begin{bmatrix}x_{11}&x_{12}\\x_{21}&x_{22}\\...\\x_{n1}&x_{n2}\\\end{bmatrix}X= x11x21...xn1x12x22xn2 ,代表的是 NNN 个样本的 222 个输入运算。故称为批,这是与之前的不同之处。
注意:(N,2)(N,2)(N,2) 是NumPy中二维数组的shape,它有明确的行列,其中
第 0 维(
N)------ 行数,即样本数量第 1 维(
2)------ 列数,即每个样本的特征数
-
理论 ------ 前面的 AffineAffineAffine 层的输入 XXX 是以单个样本为对象的,现在考虑NNN个样本一起传播的情况,即批版本 AffineAffineAffine 层,计算图如下:
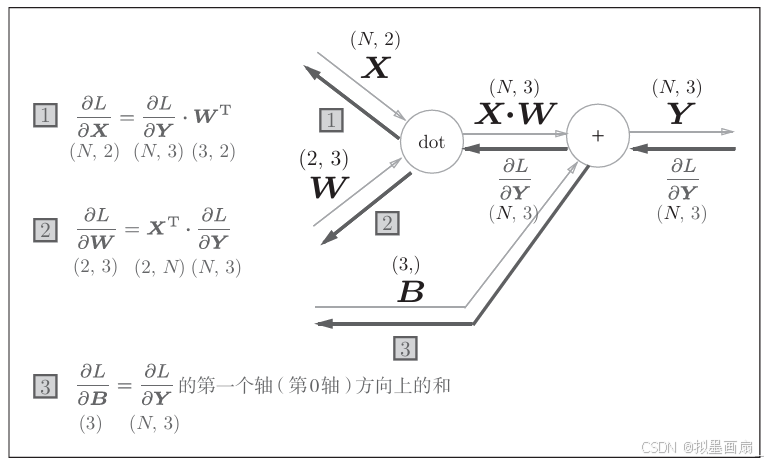
这里,∂L∂X\frac{\partial L}{\partial X}∂X∂L 和 ∂L∂W\frac{\partial L}{\partial W}∂W∂L 与 前面介绍的公式是一致的,而 ∂L∂B\frac{\partial L}{\partial B}∂B∂L 有所区别,具体来分析:
-
正向传播时,代码是
out = np.dot(x, self.W) + self.b,各变量形状:变量 形状 含义 x(N, D)N个样本,每个D维self.W(D, H)权重矩阵 np.dot(x, self.W)(N, H)每个样本得到一个 H维输出self.b(H,)偏置向量,只有 H个值out(N, H)最终输出 在
(N, H) + (H,)这一步,NumPy的广播机制 会自动把(H,)扩展成(N, H)------ 相当于把同一个偏置b复制N份,分别加到每个样本上:pythonX_dot_W = np.array([[0, 0, 0], [10, 10, 10]]) # (2, 3) B = np.array([1, 2, 3]) # (3,) result = X_dot_W + B # 正向传播时,B 广播为[[1, 2, 3], [1, 2, 3]],然后逐元素相加,得到 [[ 1, 2, 3],[11, 12, 13]] -
反向传播时,上游传来的梯度
dout形状是(N, H)------ 每个样本对自己那行输出的梯度。而偏置b只有(H,)个值,它在正向时被广播到N个样本。根据链式法则,
b对最终损失的梯度 = 各样本梯度之和,故各样本的反向传播的值需要重新汇总 为偏置的元素∂L∂bj=∑i=1N∂L∂outij \frac{\partial L}{\partial b_j} = \sum_{i=1}^{N} \frac{\partial L}{\partial out_{ij}} ∂bj∂L=i=1∑N∂outij∂L
从代码上看,就是使用
np.sum()对第 000 轴(以样本为单位的轴,axis=0)方向上的元素进行求和pythondY = np.array([[1, 2, 3,], [4, 5, 6]]) # [[1, 2, 3], [4, 5, 6]] dB = np.sum(dY, axis=0) # [5, 7, 9]
-
-
代码实现
pythonclass Affine: def __init__(self, W, b): self.W = W self.b = b self.x = None self.dW = None self.db = None def forward(self, x): self.x = x out = np.dot(x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.T, dout) self.db = np.sum(dout, axis=0) # 把正向传播的偏置重新"汇总" return dx
激活函数层
ReLU 层
-
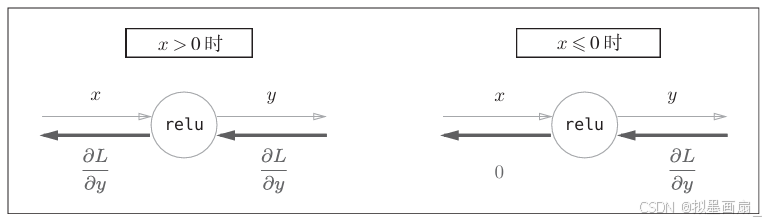
理论 ------ 激活函数 ReLUReLUReLU 函数,其偏导数可由下式解析性地计算出来:
y={x,x>00,x≤0,∂y∂x={1,x>00,x≤0 y=\begin{cases} x, & x > 0 \\ 0, & x ≤ 0 \end{cases}, \\ \frac{\partial y}{\partial x}=\begin{cases} 1, & x > 0 \\ 0, & x ≤ 0 \end{cases} y={x,0,x>0x≤0,∂x∂y={1,0,x>0x≤0
由计算图,可以表述如下:
-
代码实现 ------ 由上面的分析可知:
- 对正向传播时的输入值 ≤0≤0≤0 的,反向传播为 000
- 对正向传播时的输入值 >0>0>0 的,反向传播则原样输出
pythonclass Relu: def __init__(self): self.mask = None def forward(self, x): self.mask = (x <= 0) out = x.copy() out[self.mask] = 0 return out def backward(self, dout): dout[self.mask] = 0 dx = dout return dx在
backward的参数中,dout表示该节点反向传播的输入值 ∂L∂y\frac{\partial L}{\partial y}∂y∂L
ReluReluRelu 类的 maskmaskmask 是由 TrueTrueTrue/FalseFalseFalse 构成的 NumPyNumPyNumPy 数组,它把正向传播时的输入 xxx 的元素中, ≤0≤0≤0 的地方保存为 TrueTrueTrue,>0>0>0 的地方保存为 FalseFalseFalsepythonx = np.array([[1.0, -0.5], [-2.0, 3.0]]) # [[ 1. -0.5] [-2. 3. ]] mask = (x <= 0) # [[False True] [ True False]]
sigmoid 层
-
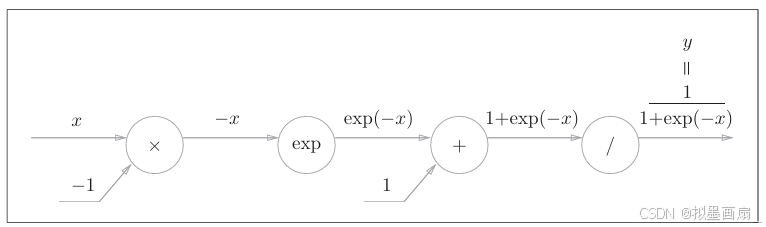
理论 ------ 激活函数 sigmoidsigmoidsigmoid 的表达式如下:
y=11+exp(−x) y=\frac{1}{1+exp(-x)} y=1+exp(−x)1
其前向传播的计算图,可以表述如下。可以发现,除了 "×××" 和 "+++" 节点外,还出现了 "expexpexp" (进行 y=exp(x)y=exp(x)y=exp(x) 计算)和 "///" 节点(进行 y=1xy=\frac{1}{x}y=x1 计算)。下面从反向传播的方向,一步步进行拆解:
-
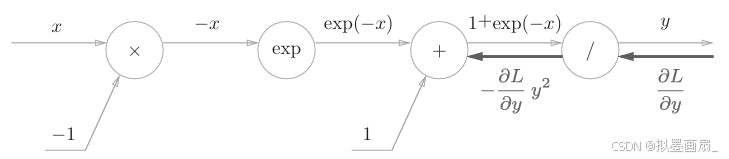
步骤1 :对 "///" 节点,其运算 y=1xy=\frac{1}{x}y=x1 的导数可解析性计算为:
∂y∂x=−1x2=−y2 \frac{\partial y}{\partial x}=-\frac{1}{x^2}=-y^2 ∂x∂y=−x21=−y2
故反向传播的计算图中,该节点将乘以 −y2-y^2−y2,传给下游,计算图如下:
乘以 −y2-y^2−y2 即 正向传播的输出的平方乘以 −1−1−1 后的值
-
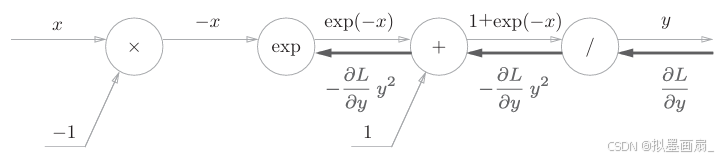
步骤2 :对 "+++" 节点,其将上游的值原封不动地传给下游,故反向传播的计算图如下
-
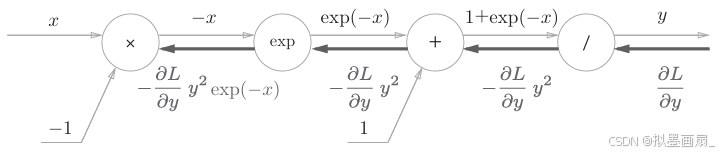
步骤3 :对 "expexpexp" 节点,其运算 y=exp(x)y=exp(x)y=exp(x) 的导数可解析性计算为:
∂y∂x=exp(x)=y \frac{\partial y}{\partial x}=exp(x)=y ∂x∂y=exp(x)=y
故反向传播的计算图中,该节点将乘以 yyy,传给下游,计算图如下:
乘以 −y-y−y 即 正向传播的输出的值
-
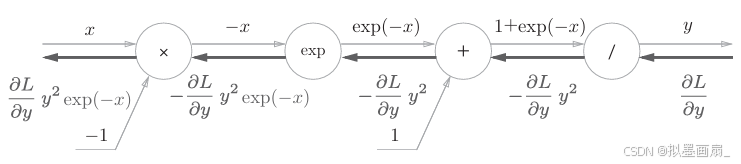
步骤4 :对 "×××" 节点,其将正向传播的值翻转再做乘法运算,因此乘以 −1−1−1,反向传播的计算图如下:
-
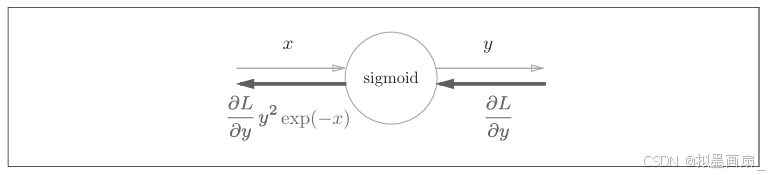
综上,可以看出, sigmoidsigmoidsigmoid 函数的反向传播输出为 ∂L∂yy2exp(−x)\frac{\partial L}{\partial y}y^2exp(-x)∂y∂Ly2exp(−x),节点简化如下:
-
进一步的,对 ∂L∂yy2exp(−x)\frac{\partial L}{\partial y}y^2exp(-x)∂y∂Ly2exp(−x) 进行整理,可以得到如下计算图:
∂L∂yy2exp(−x)=∂L∂y1(1+exp(−x))2exp(−x)=∂L∂y11+exp(−x)exp(−x)1+exp(−x)=∂L∂yy(1−y) \frac{\partial L}{\partial y} y^2 \exp(-x) = \frac{\partial L}{\partial y} \frac{1}{(1 + \exp(-x))^2} \exp(-x) = \frac{\partial L}{\partial y} \frac{1}{1 + \exp(-x)} \frac{\exp(-x)}{1 + \exp(-x)} = \frac{\partial L}{\partial y} y(1 - y) ∂y∂Ly2exp(−x)=∂y∂L(1+exp(−x))21exp(−x)=∂y∂L1+exp(−x)11+exp(−x)exp(−x)=∂y∂Ly(1−y)
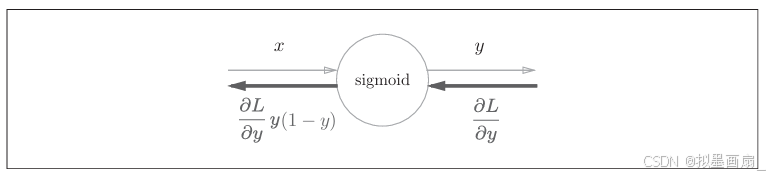
-
-
代码实现 ------ 由上面的分析可知:
pythonclass Sigmoid: def __init__(self): self.out = None def forward(self, x): out = 1 / (1 + np.exp(-x)) self.out = out return out def backward(self, dout): dx = dout * (1.0 - self.out) * self.out return dx
输出层的反向传播实现
Softmax-with-Loss 层
一般的,可以认为神经网络的分为推理 和学习两个阶段:
阶段 任务 包含步骤 推理 用训练好的模型对新数据做预测 前向传播 学习 从训练数据中调整网络参数 前向传播 → 计算损失 → 反向传播 → 更新参数 在介绍输出层的激活函数时提到,一般在推理阶段,可以忽略
Softmax函数,因为可以直接选择输出值最大的标签作为结果,不需要再压缩为概率值,减少不必要的计算。同时也提到,在学习阶段必须使用
Softmax函数,因为它与交叉熵损失函数 配合,能产生优美的梯度形式,这也是为什么该层叫Softmax-with-Loss层而不是单纯的Softmax层。
-
理论
-
激活函数 SoftmaxSoftmaxSoftmax 的表达式如下:
yk=eak∑i=1neai y_k = \frac{e^{a_k}}{\sum_{i=1}^n e^{a_i}} yk=∑i=1neaieak
-
交叉熵损失函数 CrossEntropyErrorCross Entropy ErrorCrossEntropyError 的表达式如下:
L=−∑i=1myilog(yi^) \mathcal{L} = -\sum_{i=1}^{m} y_i \log(\hat{y_i}) L=−i=1∑myilog(yi^)
-
假设神经网络要进行 333 类分类(即输出 333 个节点,表示三个标签的概率值),结合二者的前向、反向传播的计算图,可以表述如下,其中
-
SoftmaxSoftmaxSoftmax 层将输入(a1a_1a1, a2a_2a2, a3a_3a3)正规化,输出(y1y_1y1, y2y_2y2, y3y_3y3)
-
CrossCrossCross EntropyEntropyEntropy ErrorErrorError 层接收 SoftmaxSoftmaxSoftmax 的输出(y1y_1y1, y2y_2y2, y3y_3y3)和教师标签(t1t_1t1, t2t_2t2, t3t_3t3),从这些数据中输出损失 LLL
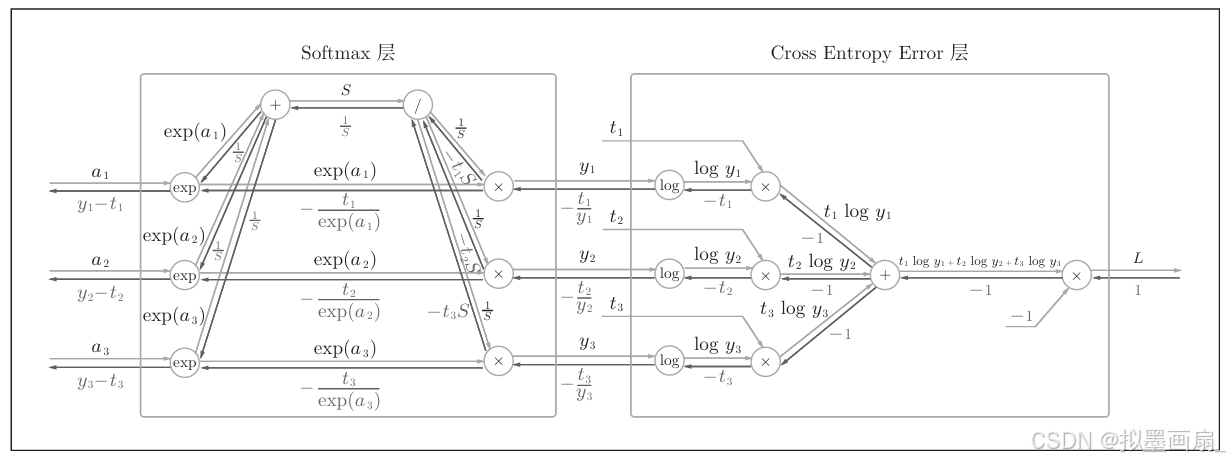
-
-
可以看到,Softmax−with−LossSoftmax-with-LossSoftmax−with−Loss 层的推导过程相对复杂,这里只给出最终的简化计算图结果,感兴趣的可以参考书籍《深度学习入门:基于Python的理论与实现》附录
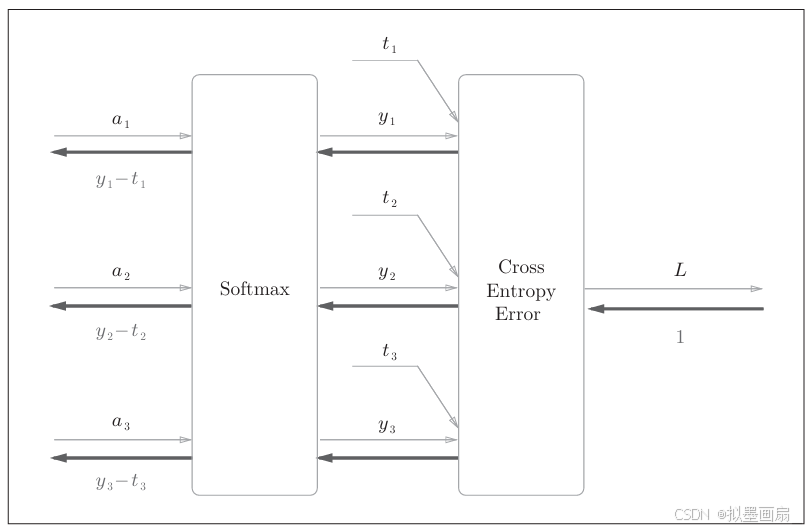
-
重点关注反向传播的结果,即计算图的左侧箭头。SoftmaxSoftmaxSoftmax 层的反向传播得到了( y1y_1y1 −-− t1t_1t1 , y2y_2y2 −-− t2t_2t2 , y3y_3y3 −-− t3t_3t3 )这样漂亮 的结果。由于( y1y_1y1 , y2y_2y2 , y3y_3y3 )是 SoftmaxSoftmaxSoftmax 层的输出,( t1t_1t1 , t2t_2t2 , t3t_3t3 )是真实数据,所以( y1y_1y1 −-− t1t_1t1 , y2y_2y2 −-− t2t_2t2 , y3y_3y3 −-− t3t_3t3 )是 SoftmaxSoftmaxSoftmax 层的输出和教师标签的差分
这里的教师标签就是"正确答案 ",也叫监督标签、真实标签,就人工标注的用来"教"神经网络的数据
-
-
实例
- 当教师标签为( 000 , 111 , 000 ), SoftmaxSoftmaxSoftmax 层输出为( 0.30.30.3 , 0.20.20.2 , 0.50.50.5 )时,正确类别的概率仅 0.20.20.2 ,识别错误。此时反向传播传递的误差为( 0.30.30.3 , −-− 0.80.80.8 , 0.50.50.5 )------ 它告诉前面的层:"你严重低估了这个类别,需要大幅调整权重"
- 当教师标签为( 000 , 111 , 000 ), SoftmaxSoftmaxSoftmax 层输出为( 0.010.010.01 , 0.990.990.99 , 000 )时,识别相当准确。此时反向传播传递的误差为( 0.010.010.01 , −-− 0.010.010.01 , 000 )------ 它告诉前面的层:"你做得很好,只需微调即可"
-
代码实现
pythonclass SoftmaxWithLoss: def __init__(self): self.loss = None # 损失 self.y = None # softmax的输出 self.t = None # 监督数据(one-hot vector) def forward(self, x, t): self.t = t self.y = softmax(x) self.loss = cross_entropy_error(self.y, self.t) return self.loss def backward(self, dout=1): batch_size = self.t.shape[0] dx = (self.y - self.t) / batch_size return dx此处的 softmaxsoftmaxsoftmax() 和 cross_entropy_errorcross\_entropy\_errorcross_entropy_error() 正向传播的函数在前面已经实现
pythondef softmax(a): exp_a = np.exp(a - np.max(a)) # 溢出对策 sum_exp_a = np.sum(exp_a) y = exp_a / sum_exp_a return ypythondef cross_entropy_error(y, t): delta = 1e-7 return -np.sum(t * np.log(y + delta))
参考文献:
1 斋藤康毅. 深度学习入门:基于Python的理论与实现M. 陆宇杰, 译. 北京: 人民邮电出版社, 2018.