这段Python代码实现了一个基于Tesseract OCR引擎的图片文字识别工具。主要功能包括:自动检测Tesseract安装路径,支持多语言识别(默认中英文混合),检查语言包可用性,并提供友好的错误提示。使用时需通过命令行传入图片路径,程序会输出识别结果。依赖pytesseract和Pillow库,需要预先安装Tesseract OCR引擎(Windows版建议从指定链接下载并安装中文语言包)。代码还包含路径自动查找、语言包验证等实用功能,是一个完整的OCR解决方案。
识别效果
html
® ocrrecognizepy X
® ocr recognize.py >...
418 def ocr_image(image_pat!
: str, lang: str = "chi_simteng") -> str:
" amg"= atiege-open(amage pain)
29 text = pytesseract.image_to_string(img, lang-lang)
30 return text
31
32
33 if _name_ == "_main_":
34 if len(sys.argv) <
35 print "用法: python ocr_recognize.py "图片路径>)
36 print "示例: python ocr_recognize.py test.png")
37 sys-exit(1)
38
39 image_path = sys.argv[1]
40 if not Path(image_path).exists():
41 print (f"错误: 文件不存在 - {image_path}")
42 sys-exit(1)
43
44 print("正在识别. - ...)
45 result = ocr_image(image_path)
46 print( "识别结果:")
47 print(result)
48
PROBLEMS OUTPUT DEBUG CONSOLE TERMINAL PORTS1、Tesseract OCR 引擎下载: https://github.com/UB-Mannheim/tesseract/wiki
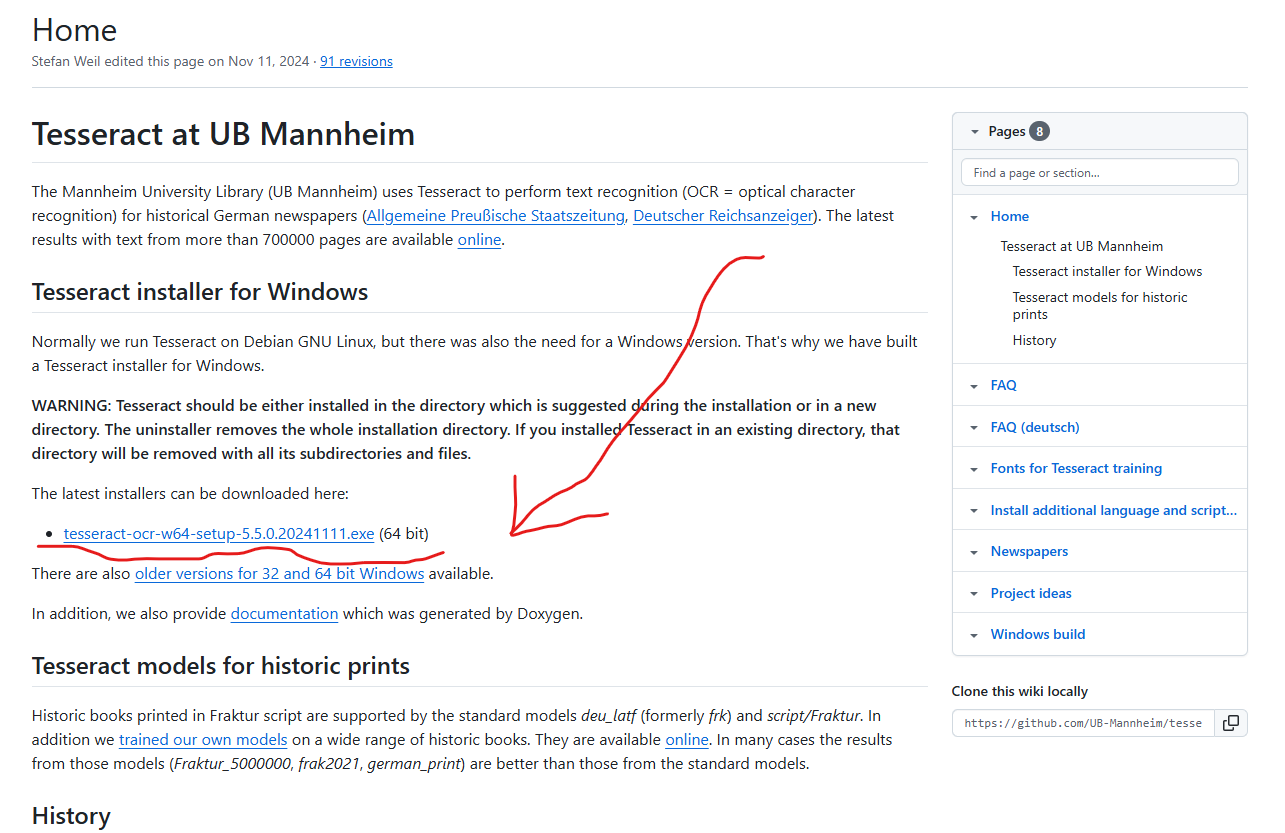
2、安装好后直接加入tesseract.exe路径即可
Python代码
python
"""
图片文字识别 (OCR) - Tesseract 版本
依赖: pip install pytesseract Pillow
Tesseract OCR 引擎下载: https://github.com/UB-Mannheim/tesseract/wiki
"""
import sys
import os
from pathlib import Path
from PIL import Image
try:
import pytesseract
except ImportError:
print("请先安装依赖: pip install pytesseract Pillow")
sys.exit(1)
TESSERACT_COMMON_PATHS = [
r"C:\Program Files\Tesseract-OCR\tesseract.exe",
r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe",
r"C:\Users\Administrator\AppData\Local\Programs\Tesseract-OCR\tesseract.exe",
os.path.expandvars(r"%LOCALAPPDATA%\Programs\Tesseract-OCR\tesseract.exe"),
os.path.expandvars(r"%USERPROFILE%\AppData\Local\Tesseract-OCR\tesseract.exe"),
]
def find_tesseract() -> str:
for path in TESSERACT_COMMON_PATHS:
if os.path.isfile(path):
return path
return ""
def init_tesseract() -> bool:
tesseract_path = find_tesseract()
if tesseract_path:
pytesseract.pytesseract.tesseract_cmd = tesseract_path
return True
try:
pytesseract.get_tesseract_version()
return True
except pytesseract.TesseractNotFoundError:
return False
def check_language(lang: str) -> str:
try:
available = pytesseract.get_languages(config='')
except Exception:
return lang
requested = lang.split('+')
available_langs = [l for l in requested if l in available]
missing_langs = [l for l in requested if l not in available]
if missing_langs:
print(f"警告: 缺少语言包: {', '.join(missing_langs)}")
print(f"可用语言: {', '.join(available)}")
if not available_langs:
if 'eng' in available:
print("自动降级为英文识别 (eng)")
return 'eng'
return available[0] if available else 'eng'
return '+'.join(available_langs)
def ocr_image(image_path: str, lang: str = "chi_sim+eng") -> str:
"""
识别图片中的文字
Args:
image_path: 图片路径
lang: 识别语言,默认为简体中文+英文
Returns:
识别出的文字
"""
img = Image.open(image_path)
actual_lang = check_language(lang)
text = pytesseract.image_to_string(img, lang=actual_lang)
return text
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法: python ocr_recognize.py <图片路径>")
print("示例: python ocr_recognize.py test.png")
sys.exit(1)
if not init_tesseract():
print("错误: 未找到 Tesseract OCR 引擎")
print()
print("请按以下步骤安装:")
print("1. 下载 Tesseract-OCR for Windows:")
print(" https://github.com/UB-Mannheim/tesseract/wiki")
print("2. 安装时勾选 Chinese (Simplified) 语言包")
print("3. 默认安装路径: C:\\Program Files\\Tesseract-OCR\\")
print("4. 或将 tesseract.exe 所在目录加入系统 PATH")
sys.exit(1)
image_path = sys.argv[1]
if not Path(image_path).exists():
print(f"错误: 文件不存在 - {image_path}")
sys.exit(1)
print("正在识别...")
result = ocr_image(image_path)
print("识别结果:")
print(result)