本文提出了 UnWeaver,一种不构建知识图谱却能逼近 GraphRAG 效果的轻量 RAG 框架。核心思路是用 LLM 从每个文档块中提取实体,将跨块的等价实体描述拼接后做向量索引,检索时通过实体投票回溯原始文档块。实验表明,纯 VectorRAG 在多数场景下优于标准 GraphRAG,而 UnWeaver 以极低成本达到与 SOTA 图方法(HippoRAG2)相当的水平。
| 项目 | 内容 |
|---|---|
| 📄 论文标题 | UnWeaving the knots of GraphRAG -- turns out VectorRAG is almost enough |
| 👥 作者 | Ryszard Tuora, Mateusz Galiński 等(共同一作) |
| 🏛️ 机构 | Samsung AI Warsaw |
| 📅 发表 | arXiv Preprint, June 2026 |
| 🔗 链接 | 代码已在 GitHub 开源 |
🔍 研究背景与痛点
RAG(Retrieval-Augmented Generation,检索增强生成)已经成为大模型落地的事实标配:先从外部知识库检索相关文档片段,再喂给 LLM 生成回答。主流的 VectorRAG 方案把文档切成固定长度的块(chunk),每块编码成一个向量,检索时做 k-NN 相似度搜索。
这个方案有一个根本问题:每个文档块被当作原子对象处理。一个块里可能包含多个实体和多条事实,但它们的向量表示被压缩成了一个"混合信号"。更关键的是,块与块之间没有任何关联建模,面对需要跨块推理的多跳问题(multi-hop question),这种方案缺乏专门的应对机制。
GraphRAG 试图解决这个问题。它将文档建模为知识图谱:实体作为节点,关系作为边,再通过层次化社区检测(Hierarchical Community Detection)组织全局结构。理论上,这种图结构能更精细地表达信息、支持多跳推理。
但 GraphRAG 的代价很大。构建图谱索引需要多个复杂步骤------命名实体识别(NER)、关系三元组抽取、社区聚类、层级摘要生成------每一步都依赖 LLM 调用。以微软 MSGraphRAG 为例,整个索引流程的 Token 开销可以达到 VectorRAG 的数十倍。检索阶段也无法简单做向量搜索,需要启发式算法遍历图结构或生成结构化查询(SPARQL / Cypher),工程复杂度显著上升。
这就引出了一个核心问题:能不能在不用建图的前提下,获得 GraphRAG 的好处?
🛠️ UnWeaver 核心方法
UnWeaver 的回答是:用实体解耦 + 向量检索替代知识图谱。它的灵感来自一个直觉------GraphRAG 真正有价值的不是图结构本身,而是"把混在文档块里的信息拆解成独立的语义单元"。UnWeaver 用一种更轻量的方式实现了这一点。
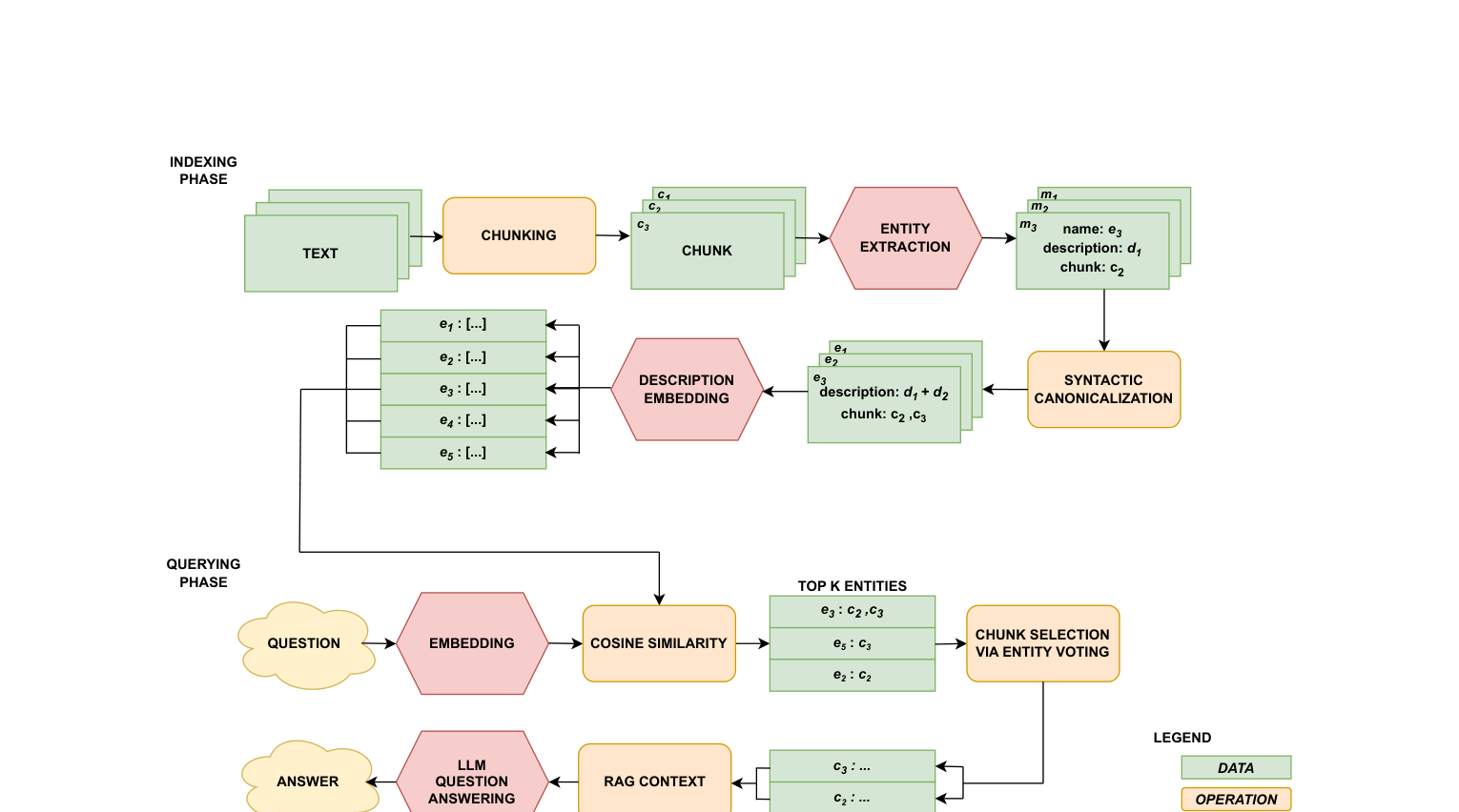
Figure 1:UnWeaver 整体架构。上半部分为索引阶段(Indexing Phase):文本分块 → 实体提取 → 语法规范化 → 描述拼接 → 向量索引。下半部分为检索阶段(Querying Phase):查询嵌入 → 余弦相似度 → Top-K 实体 → 实体投票选块 → LLM 回答。红色操作依赖 LLM,橙色为纯算法步骤。
整个系统分为两个阶段。
索引阶段:从文档块到实体向量
第一步:文本分块。 将原始文档 TTT 切分为 nnn 个固定长度的块 CT=(c1,c2,...,cn)C_T = (c_1, c_2, \ldots, c_n)CT=(c1,c2,...,cn),这一步和标准 VectorRAG 完全一样。
第二步:实体提取。 对每个块 cic_ici,调用 LLM 提取其中出现的实体及其描述。输出是一个列表 Li=(e1,...,eki)L_i = (e_1, \ldots, e_{k_i})Li=(e1,...,eki),每个实体 ej=(nji,dji)e_j = (n_j^i, d_j^i)ej=(nji,dji) 包含名称和描述。注意,描述仅基于当前块的内容生成,不看其他块。
打个比方:如果一篇文档有 10 个段落,每个段落都会被 LLM "过一遍",输出"这个段落提到了谁、在什么语境下提到的"。
第三步:语法规范化(Syntactic Canonicalization)。 不同块可能提到同一个实体,只是写法略有差异(比如 "J.K. Rowling" 和 "Rowling")。UnWeaver 通过语法等价关系将同名实体归入等价类。如果实体 ea=(na,da)e_a = (n_a, d_a)ea=(na,da) 和 eb=(nb,db)e_b = (n_b, d_b)eb=(nb,db) 的名称语法等价(na≈namenbn_a \approx_{name} n_bna≈namenb),它们就被归为同一类。
第四步:描述拼接。 对每个等价类的代表 e~a\tilde{e}_ae~a,将它来自不同块的描述拼接起来:
d~a=da1⌢da2⌢...⌢dak\tilde{d}a = d{a_1} \frown d_{a_2} \frown \ldots \frown d_{a_k}d~a=da1⌢da2⌢...⌢dak
这是 UnWeaver 的核心创新点。拼接后的描述聚合了该实体在整个文档库中被提及时的所有上下文信息,比任何单个块中的局部描述都更完整。
直觉理解:如果"爱因斯坦"在文档的 3 个不同段落被提到,每段各给出一部分信息(物理学家、相对论、诺贝尔奖),拼接后就得到一份综合画像。这和知识图谱中"合并一个实体的所有属性"是等价的,但不需要显式建图。
第五步:向量索引。 将每个等价类的拼接描述通过 Embedder EEE 编码为 lll 维向量 vi=E(e~i)v_i = E(\tilde{e}i)vi=E(e~i),存入向量数据库。同时维护一个 m×nm \times nm×n 的二元矩阵 MCM_CMC(实体-块关联矩阵,chunk-entity matrix),其中 tij=1t{ij} = 1tij=1 当且仅当实体 e~i\tilde{e}_ie~i 的名称出现在块 cjc_jcj 中。这个矩阵记录了"哪些实体来自哪些块",是后续回溯的关键。
检索阶段:从查询到文档块
第一步:查询嵌入。 将用户查询 qqq 编码为向量 E(q)E(q)E(q)。
第二步:实体相似度排序。 用余弦相似度 σ(vi,E(q))\sigma(v_i, E(q))σ(vi,E(q)) 计算查询与每个实体向量的相似度,选出相似度最高的 k0k_0k0 个实体。定义一个二元过滤向量 MqM_qMq:qi=1q_i = 1qi=1 如果 viv_ivi 在 Top-k0k_0k0 中,否则 qi=0q_i = 0qi=0。
第三步:实体投票选块。 将 MCM_CMC 的第 iii 行乘以 MqM_qMq 的第 iii 个分量,过滤掉未被选中的实体行,然后按列求和。得分越高的块,说明它包含越多与查询语义相关的实体。选取得分最高的若干块作为检索上下文。
直觉上,这个过程类似"选举":每个被查询激活的实体为自己所在的文档块"投一票",得票最多的块就是最相关的上下文。
第四步:LLM 生成回答。 将选中的块拼接成上下文,连同原始查询一起喂给 LLM。
数学框架
论文用矩阵语言形式化了上述过程,核心思路可以用三个矩阵概括:
- 实体描述矩阵 AAA:每列是一个实体在某个块中的描述向量
- 实体-块关联矩阵 W∈{0,1}K×nW \in \{0,1\}^{K \times n}W∈{0,1}K×n:记录实体出现在哪些块中
- 等价类置换子矩阵 Ps=In(:,σ(s))P_s = I_n(:, \sigma(s))Ps=In(:,σ(s)):选出属于同一等价类的实体
对每个等价类 sss,拼接描述为 Ds=APsD_s = A P_sDs=APs,关联块向量为 cs=sign(WPs1)c_s = \text{sign}(W P_s \mathbf{1})cs=sign(WPs1)。最终构建向量数据库 V=E(D1)∣⋯∣E(DS)V = E(D_1) \| \\cdots \| E(D_S)V=E(D1)∣⋯∣E(DS) 和块-类矩阵 C=c1∣⋯∣cSC = c_1 \| \\cdots \| c_SC=c1∣⋯∣cS。
检索时,对查询 qqq 计算相关性得分 γ=VTq\gamma = V^T qγ=VTq,然后从 CCC 中选出 Top-K 实体对应的列,得到检索矩阵 R=C(:,σ^)R = C(:, \hat{\sigma})R=C(:,σ^)。RRR 的每一列告诉你"哪些块与这个查询相关的实体有关"。

Algorithm 1:UnWeaver 对齐检索完整伪代码。涵盖预处理(分块、实体提取、等价类识别)、查询处理(嵌入与相关性评分)、检索对齐(Utility-Based 效用最大化或 CLS 约束最小二乘)和上下文检索四个阶段。
进阶:检索对齐(Retrieval Alignment)
论文还提出了一个更优雅的理论框架。把矩阵 CCC 看作网络路由中的"路由矩阵",将检索问题转化为经典的聚合效用最大化问题(Aggregate Utility Maximization):
maxx≥0∑s=1SUs(xs)s.t.Cx≤f\max_{x \geq 0} \sum_{s=1}^{S} U_s(x_s) \quad \text{s.t.} \quad Cx \leq fx≥0maxs=1∑SUs(xs)s.t.Cx≤f
其中 xsx_sxs 表示第 sss 个等价类(即某个"概念")在检索上下文中的"权重",fff 控制每个块的容量上限。选择对数效用函数 Us(xs)=γslog(xs)U_s(x_s) = \gamma_s \log(x_s)Us(xs)=γslog(xs) 时,最优解有闭式表达:
xˉs=γs∑i=1Krisλˉi\bar{x}s = \frac{\gamma_s}{\sum{i=1}^{K} r_{is} \bar{\lambda}_i}xˉs=∑i=1Krisλˉiγs
其中 λˉi\bar{\lambda}_iλˉi 是约束对应的 Lagrange 乘子,可以通过迭代拍卖过程(iterative auction)求解。
这个框架的实际意义在于:它不只是"选块",而是给每个块分配一个连续权重,控制不同实体在不同块中的"影响力"。论文还给出了基于约束最小二乘(Constrained Least Squares)的替代方案,通过求解 KKT 线性方程组得到闭式解。不过实验中使用的是基础的实体投票方案,对齐方法更多是理论探索。
🏆 实验结果与分析
实验设置
论文在 4 个数据集上评估了端到端 QA 性能:
COVID-QA(1234 个问题):新冠疫情相关的单跳问答eManual(522 个问题):电子设备手册问答Tech-QA(596 个问题):技术领域单跳问答MuSiQue(2417 个问题):多跳推理问答
基线方法包括:GraphRAG(微软)、HippoRAG2(当前 SOTA 图方法之一)、RAPTOR(树结构检索)、VectorRAG(纯向量检索)、ClosedBook(纯 LLM 无检索)、Oracle(上界参考)。评价指标是 Factual Correctness(FC),即回答的事实正确性。
主实验结果
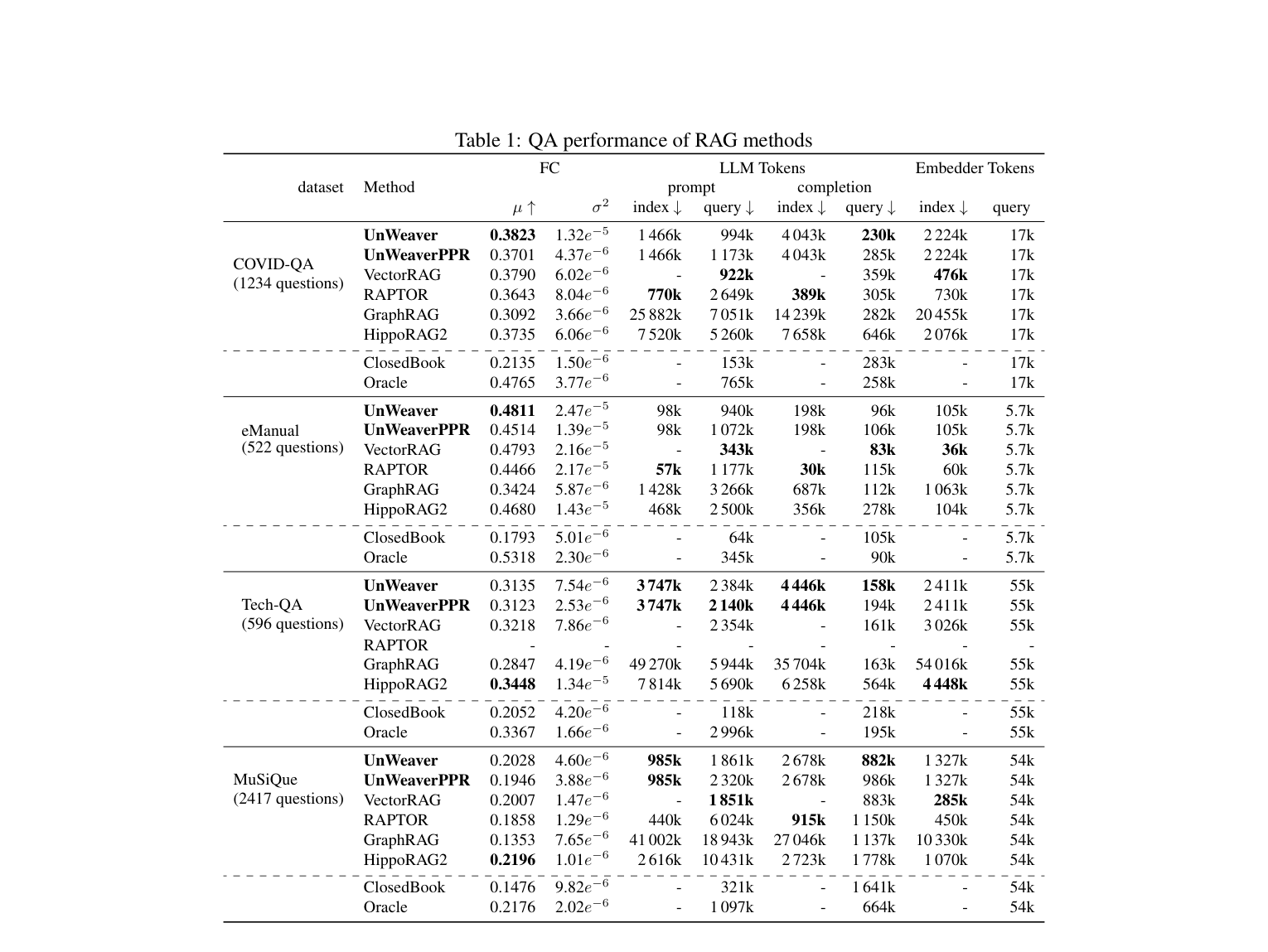
Table 1:各 RAG 方法在 4 个数据集(COVID-QA、eManual、Tech-QA、MuSiQue)上的 Factual Correctness 对比,以及索引/查询阶段的 LLM Token 和 Embedder Token 开销统计。
| 方法 | COVID-QA | eManual | Tech-QA | MuSiQue |
|---|---|---|---|---|
| UnWeaver | 0.3823 | 0.4811 | 0.3135 | 0.2028 |
| UnWeaver_PPR | 0.3701 | 0.4514 | 0.3123 | 0.1946 |
| VectorRAG | 0.3790 | 0.4793 | 0.3218 | 0.2007 |
| RAPTOR | 0.3643 | 0.4466 | - | 0.1858 |
| GraphRAG | 0.3092 | 0.3424 | 0.2847 | 0.1353 |
| HippoRAG2 | 0.3735 | 0.4680 | 0.3448 | 0.2196 |
| ClosedBook | 0.2135 | 0.1793 | 0.2052 | 0.1476 |
| Oracle | 0.4765 | 0.5318 | 0.3367 | 0.2176 |
几个关键发现:
发现一:VectorRAG 是隐藏赢家。 在 4 个数据集中,VectorRAG 有 3 个进入了 Top-3。这个结果相当出人意料------最简单的向量检索方案,不做任何图结构或实体分解,表现就已经超过 GraphRAG 和 RAPTOR。
发现二:GraphRAG 全程垫底。 微软的 GraphRAG 在所有数据集上都是最差的方法(不算 ClosedBook)。在 COVID-QA 上 FC 仅为 0.3092 ,仅比纯 LLM 无检索的 ClosedBook(0.2135 )高出不到 0.1 分------也就是说费了很大力气建图谱,带来的提升非常有限。而 VectorRAG 在同一数据集上拿到 0.3790,差距明显。论文推测这是因为 GraphRAG 过度依赖转换后的摘要输出,丢失了原始文档的保真度。
发现三:UnWeaver 和 VectorRAG 非常接近。 在 COVID-QA 和 eManual 上 UnWeaver 略优于 VectorRAG(0.3823 vs 0.3790 、0.4811 vs 0.4793 ),在 Tech-QA 和 MuSiQue 上略低于 VectorRAG。总体差距很小。
发现四:HippoRAG2 在困难场景下更强。 在 MuSiQue(多跳问题)和 Tech-QA 上,HippoRAG2 分别取得 0.2196 和 0.3448 的最高分。多跳推理场景下,图结构的优势确实更明显。
Token 开销对比
性能是一方面,成本是另一面。论文统计了各方法的 Token 消耗:
以 COVID-QA 为例,索引阶段的 LLM prompt token:VectorRAG 为 0 (无需 LLM 调用),UnWeaver 为 1,466k ,HippoRAG2 为 7,520k ,GraphRAG 为 25,882k。
也就是说,UnWeaver 的索引成本约为 HippoRAG2 的 1/5 ,GraphRAG 的 1/18。而在查询阶段,UnWeaver 的 Token 消耗与 VectorRAG 几乎相同,意味着检索延迟不会增加。
结论:UnWeaver 在"差不多好用"的前提下,把 GraphRAG 的复杂度砍掉了一个数量级。如果不需要处理大量多跳问题,它的性价比非常高。
💡 主要创新点总结
- 实体解耦代替知识图谱:不需要建图、不需要社区检测、不需要图数据库,只靠"实体提取 + 描述拼接 + 向量索引"就能获得接近图方法的检索精度。这是对"GraphRAG 是否真的需要图"这个问题的一次有力回应。
- 跨块实体聚合:将分散在不同文档块中的同一实体信息拼接到一起,本质上做了知识图谱的"实体融合",但实现方式极其轻量。
- 实验发现 VectorRAG 被低估:系统性的对比实验揭示了一个反直觉的事实------在很多场景下,简单的向量检索就够用,复杂的图结构反而是过度工程。
- 检索对齐的理论框架:将检索问题映射到效用最大化问题,给出了闭式解和迭代算法,为后续研究提供了一个优雅的理论起点。
⚠️ 局限性与思考
实体提取依赖 LLM 质量。 实体的提取和描述生成都由 LLM 完成,如果 LLM 对特定领域的实体识别能力不足(比如医学、法律),索引质量会直接受影响。论文没有对不同类型的 LLM 做消融分析。
语法规范化的局限。 当前的等价类判定仅基于语法(名称字符串)等价,无法处理同义不同名的情况(比如 "AI" 和 "Artificial Intelligence")。论文在附录中提到可以推广到语义等价,但实验中没有实际验证。
多跳场景仍有差距。 在 MuSiQue 多跳数据集上,UnWeaver(0.2028 )与 HippoRAG2(0.2196)的差距比单跳场景更大。实体投票机制天然更适合"找到包含相关实体的块",而不太擅长处理"A 和 B 通过 C 间接关联"这类链式推理。
对齐方法未在实验中验证。 Retrieval Alignment 是一个漂亮的理论贡献,但论文没有在端到端实验中评估它的实际效果。从理论到落地还有一段距离。
数据集覆盖面有限。 4 个数据集都是英文的,没有跨语言验证。此外 Tech-QA 上 RAPTOR 因数值不稳定未能跑出结果,对比的完整性受到一定影响。
📝 总结
UnWeaver 解决了一个很实际的问题:GraphRAG 的理念是好的(解耦文档中的结构化信息),但实现路径太重了。UnWeaver 用"实体提取 + 描述拼接"这条更简单的路达到了类似的效果。
从工程角度看,这篇论文最大的启示不是 UnWeaver 本身,而是实验中的那个反直觉发现------VectorRAG 在多数场景下已经够用了。很多团队花大力气上 GraphRAG,结果可能还不如好好优化 chunk 策略和 embedding 模型。
如果你的 RAG 应用主要处理单跳问答,优先考虑把 VectorRAG 做精做细。如果确实有大量多跳推理需求,再考虑 GraphRAG 或 HippoRAG2 这类图方案。UnWeaver 则是一个不错的折中选择------比 VectorRAG 多一些语义精细度,比 GraphRAG 少一个数量级的复杂度。
📚 参考文献
1 Ryszard Tuora, Mateusz Galiński, et al. UnWeaving the knots of GraphRAG -- turns out VectorRAG is almost enough. arXiv Preprint, 2026.
2 Edge, D., Trinh, H., Cheng, N., et al. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. Microsoft Research, 2024.
3 Gutierrez, B. J., et al. HippoRAG2: Hippocampal Subnetworks for Retrieval-Augmented Generation. 2024.
4 Lewis, P., Perez, E., Piktus, A., et al. Retrieval-augmented generation for Knowledge-intensive NLP tasks. NeurIPS, 2020.
5 Sarthi, P., Abdullah, S., Tuli, A., et al. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. 2024.
6 Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A. MuSiQue: Multihop Questions via Single-hop Question Composition. TACL, 2022.
cessing for Tree-Organized Retrieval. 2024.
6 Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A. MuSiQue: Multihop Questions via Single-hop Question Composition. TACL, 2022.