1. 引言:机器人智能的新范式
在人工智能领域,大语言模型(LLM)和视觉语言模型(VLM)通过大规模预训练展现了惊人的泛化能力。机器人领域也在探索类似路径,但面临独特挑战:现有机器人基础模型多采用行为克隆(Behavior Cloning, BC)范式,只能从高质量专家演示中学习。这导致一个严重问题------大量包含丰富物理交互动力学的异构具身数据(低质量轨迹、失败尝试、人类视频)被浪费。如何让机器人像人类一样从各种经验中学习,包括失败和次优行为?这正是LDA-1B要解决的核心问题。
想象一下,如果我们能让机器人不仅学习"做什么",还能理解"为什么这样做会产生这样的结果",那么机器人的智能水平将会有质的飞跃。这正是LDA-1B(Latent Dynamics Action Model)所要解决的核心问题。LDA-1B是一款参数量达10亿 的机器人基础模型,它通过创新的 "通用具身数据摄入"机制 ,能够从超过3万小时的混合质量人机交互数据中学习,不仅掌握操作策略,还深刻理解物理世界的动力学规律。
统一世界模型(Unified World Model, UWM)框架为解决这些问题提供了新思路。UWM在单一模型内联合优化动力学、策略和视频生成 ,理论上可以利用各种质量的数据。但现有的UWM实现仍然存在明显不足:数据使用方式粗糙、缺乏大规模标准化数据集、在像素空间中表征导致训练效率低下 。对应的代码可以参考Github,文章参考LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
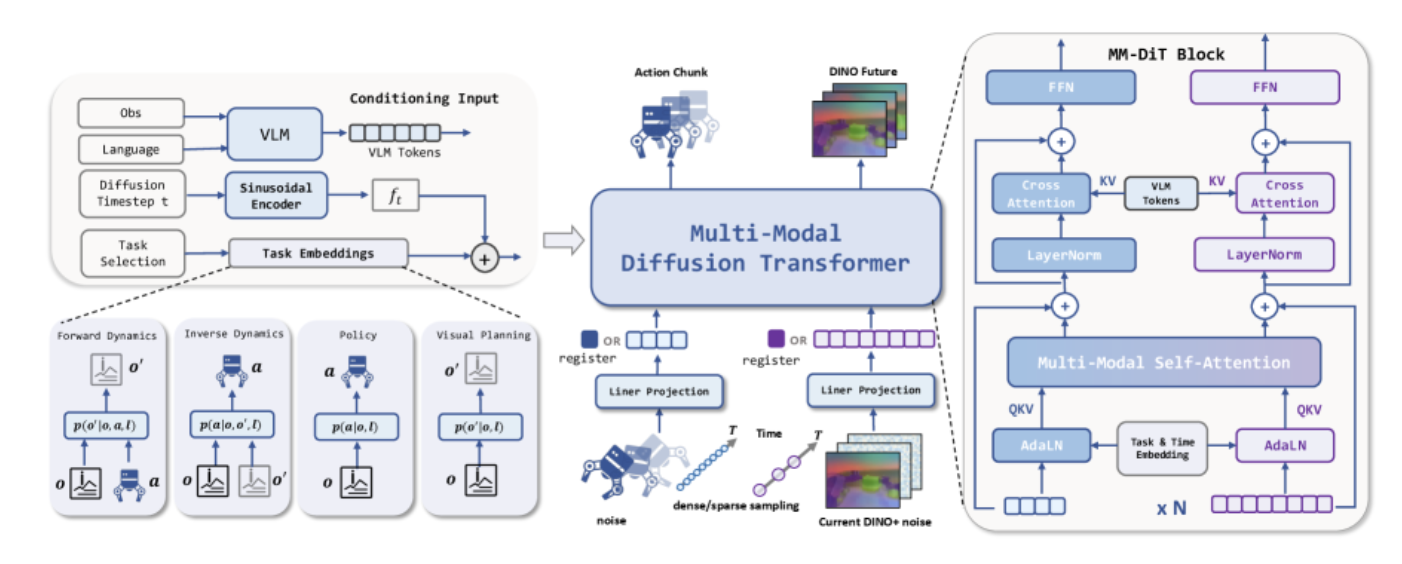
2. 核心技术原理:潜态动力学动作模型
LDA-1B通过四大核心创新,突破了现有方法的瓶颈:
1. 通用具身数据摄入机制
LDA-1B为不同质量的数据分配差异化角色 :无动作标注的人类视频用于视觉预测 ,低质量轨迹主要用于动力学学习 ,高质量轨迹同时支撑策略和动力学学习。这种设计使得模型能够充分挖掘每一份数据的价值。
2. EI-30k大规模数据集
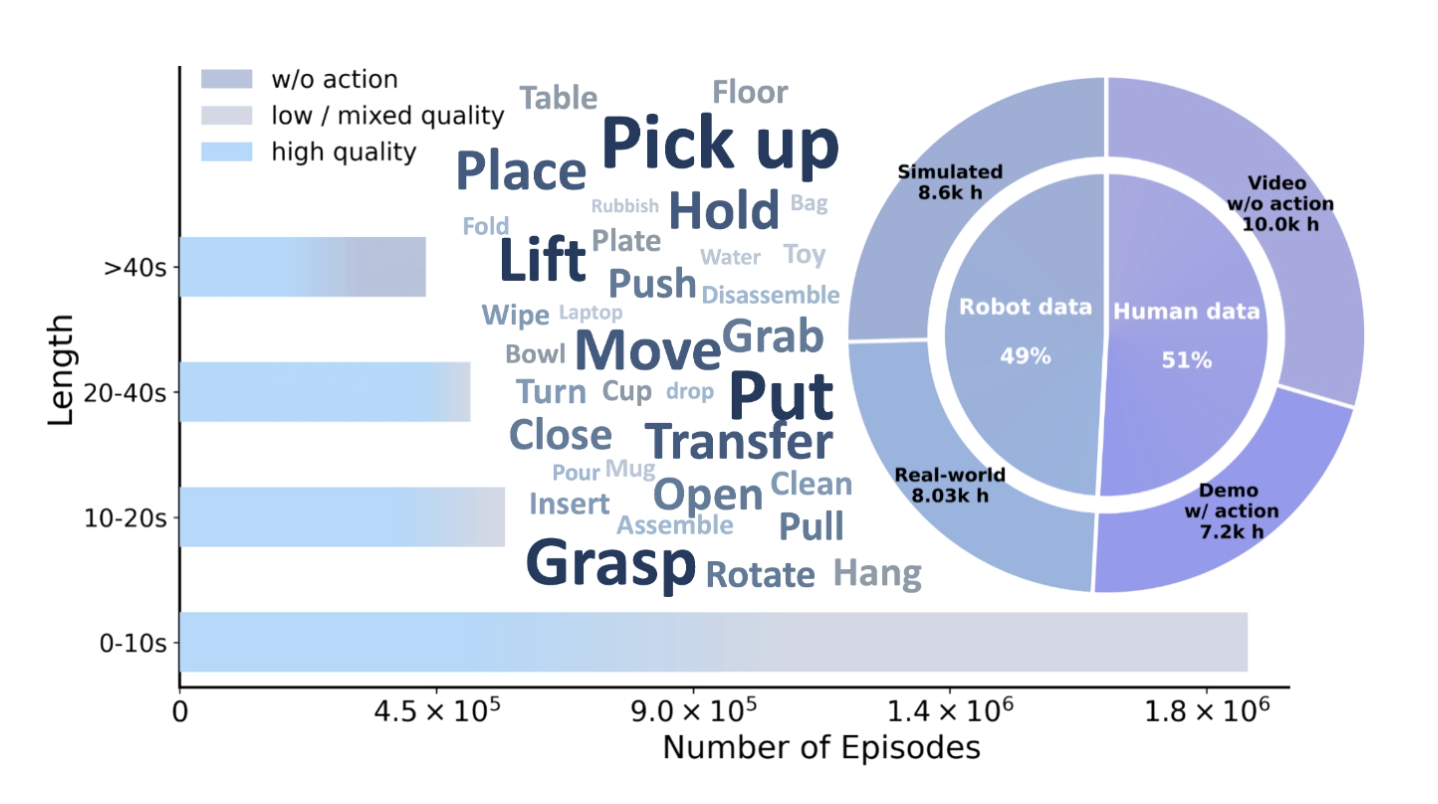
研究团队构建了包含超3万小时 人机轨迹的EI-30k数据集,涵盖8030小时真实世界机器人数据、8600小时仿真数据、7200小时带动作标注的人类演示和10000小时无动作人类视频。所有数据采用统一格式,实现了末端执行器坐标系的对齐。
3. 结构化DINO潜空间
不同于传统方法在像素空间中进行预测,LDA-1B在预训练的DINO编码器 提取的潜特征空间 中进行动力学学习。这种表征对高层语义和空间结构 进行编码,同时抑制背景噪声和低层视觉变化,大幅提升了训练效率和泛化能力。
4. 多模态扩散Transformer(MM-DiT)
LDA-1B采用创新的MM-DiT架构 ,能够处理异步的视觉和动作流 。视觉观测以3Hz采样 ,动作以10Hz采样,这种设计在保留细粒度动作动力学的同时,减少了冗余计算。
2.1 统一世界模型(UWM)基础
LDA-1B的核心思想建立在 统一世界模型(Unified World Model, UWM) 框架之上。传统的机器人学习方法往往将策略学习和动力学建模分离,而UWM则提出了一个革命性的想法:在单一模型内联合学习四个关键能力。
给定当前观测 o t o_t ot (通常为RGB图像),UWM联合建模未来观测和动作分块的多个条件分布:
- 策略学习 : p ( a t + 1 : t + k ∣ o t ) p(a_{t+1:t+k} | o_t) p(at+1:t+k∣ot) - 根据当前观测预测未来动作序列
- 前向动力学 : p ( o t + 1 : t + k ∣ o t , a t + 1 : t + k ) p(o_{t+1:t+k} | o_t, a_{t+1:t+k}) p(ot+1:t+k∣ot,at+1:t+k) - 预测执行动作后的未来状态
- 逆向动力学 : p ( a t + 1 : t + k ∣ o t : t + k ) p(a_{t+1:t+k} | o_t:t+k) p(at+1:t+k∣ot:t+k) - 从状态变化推断所需动作
- 视觉规划 : p ( o t + 1 : t + k ∣ o t ) p(o_{t+1:t+k} | o_t) p(ot+1:t+k∣ot) - 预测未来可能的状态演化
这种统一框架的优势在于,不同的学习目标可以相互促进。例如,学习前向动力学可以帮助模型更好地理解动作的物理后果,从而改进策略学习;而逆向动力学则能帮助模型理解如何通过动作达到期望状态。
技术实现 :UWM采用联合扩散模型来实例化这一框架。扩散模型是一类强大的生成模型,通过逐步去噪的过程生成数据。在UWM中,模型同时为动作和未来观测预测噪声:
python
def unified_world_model(current_obs, language_instruction, t_action, t_obs):
"""
current_obs: 当前观测(RGB图像)
language_instruction: 语言指令
t_action: 动作的扩散时间步
t_obs: 观测的扩散时间步
"""
# 编码当前观测和语言指令
obs_embedding = vlm_encoder(current_obs, language_instruction)
# 为动作和观测独立采样噪声
noisy_action = add_noise(action, t_action)
noisy_future_obs = add_noise(future_obs, t_obs)
# 联合预测去噪后的动作和观测
denoised_action, denoised_obs = diffusion_model(
obs_embedding,
noisy_action,
noisy_future_obs,
t_action,
t_obs
)
return denoised_action, denoised_obs这里的关键创新在于,动作和观测使用独立采样的扩散时间步(t_a和t_o),这使得模型能够灵活地处理不同模态的噪声水平,提高了训练的稳定性和效率。
2.2 通用数据摄入:让每一份数据发挥价值
LDA-1B最重要的创新之一是"通用数据摄入"机制。这一机制的核心思想是:不同质量的数据应该在训练中扮演不同但互补的角色,而不是简单地被接受或拒绝。
数据分类与角色分配
高质量机器人和人类演示数据作为最可靠的监督信号,用于所有四个训练目标的联合训练,同时支撑动作策略学习和动力学建模。这些数据代表了专家级的操作水平,为模型提供了最优行为的范例。
低质量轨迹数据虽然动作可能不完美,但仍然包含有价值的物理交互过程。这些数据仅用于动力学和视觉预测任务,因为这些任务对动作最优性的要求较低。即使是失败的尝试,也能帮助模型理解"什么样的动作会导致什么样的结果"。
无动作标注的人类操作视频专门用于视觉预测目标,提供大规模的视觉动力学监督。这些视频帮助模型学习物体运动和场景变化规律,即使没有精确的动作标签,也能从中提取丰富的视觉先验知识。
这种设计避免了模型过拟合到仅含专家的行为,同时实现了可扩展的可迁移动力学和动作表征学习。
技术实现:任务嵌入和寄存器标记
为了在单一扩散模型中实现差异化目标,LDA-1B引入了创新的设计:
python
# 多任务数据加载器实现
class MultiTaskDiffusionModel:
def __init__(self):
# 4个可学习的任务嵌入(对应4种训练目标)
self.task_embeddings = nn.ModuleDict({
'policy': nn.Embedding(1, dim), # 策略学习
'forward_dynamics': nn.Embedding(1, dim), # 前向动力学
'inverse_dynamics': nn.Embedding(1, dim), # 逆向动力学
'visual_forecasting': nn.Embedding(1, dim) # 视觉预测
})
# 2个可学习的寄存器标记(处理缺失模态)
self.action_register = nn.Parameter(torch.randn(1, 1, dim))
self.visual_register = nn.Parameter(torch.randn(1, 1, dim))
def forward(self, obs, task_type, noisy_action=None, noisy_visual=None):
# 获取任务嵌入
task_emb = self.task_embeddings[task_type](torch.zeros(1, dtype=torch.long))
# 根据任务类型使用实际数据或寄存器
if task_type == 'policy':
# 策略学习: 有动作,无未来视觉
action_tokens = noisy_action
visual_tokens = self.visual_register.expand(batch_size, -1, -1)
elif task_type == 'visual_forecasting':
# 视觉预测: 无动作,有未来视觉
action_tokens = self.action_register.expand(batch_size, -1, -1)
visual_tokens = noisy_visual
else:
# 动力学学习: 两者都有
action_tokens = noisy_action
visual_tokens = noisy_visual
# 联合处理
return self.mm_dit(obs, task_emb, action_tokens, visual_tokens)这种设计的巧妙之处在于,它使统一架构能够灵活支持不同的输入输出结构,无需修改网络拓扑。模型通过任务嵌入知道当前要执行什么任务,通过寄存器标记处理缺失的模态信息。
流匹配目标:
模型采用流匹配(Flow Matching)目标进行训练,这是一种比传统DDPM更高效的训练方法:
L a c t i o n = E ( v a θ − ( ϵ a − a t + 1 : t + k ) ) 2 L_{action} = \mathbb{E}(v_a\^\\theta - (\\epsilon_a - a_{t+1:t+k}))\^2 Laction=E(vaθ−(ϵa−at+1:t+k))2
L o b s = E ( v o θ − ( ϵ o − o t + 1 : t + k ) ) 2 L_{obs} = \mathbb{E}(v_o\^\\theta - (\\epsilon_o - o_{t+1:t+k}))\^2 Lobs=E(voθ−(ϵo−ot+1:t+k))2
L t o t a l = L a c t i o n + L o b s L_{total} = L_{action} + L_{obs} Ltotal=Laction+Lobs
在训练过程中,动作和视觉损失会根据任务要求选择性激活。例如,对于无动作标注的人类视频,只计算 L o b s L_{obs} Lobs;对于低质量轨迹,计算 L o b s L_{obs} Lobs和动力学相关的损失,但不计算策略损失。
这种灵活的训练机制使得LDA-1B能够从3万小时的混合质量数据中学习,而不是像传统方法那样只能使用其中的一小部分高质量数据。
2.3 预测目标的表征:从像素到语义
LDA-1B的另一个关键创新是预测目标的表征方式。传统的世界模型通常在像素空间中进行预测,这带来了严重的问题:光照变化、纹理细节、背景杂乱等与任务无关的因素会主导训练目标,导致模型难以学习真正重要的物理交互动力学。
DINO潜空间:语义结构化的表征
LDA-1B采用预训练的DINO(Self-Distillation with No Labels)编码器提取的潜特征,而非基于VAE的像素空间表征。DINO是一种自监督学习方法,能够学习到高质量的视觉表征。
DINO潜特征具有三大核心优势:语义编码 能力使其对高层语义和空间结构进行编码,关注物体的功能属性而非表面外观;噪声抑制 特性可以自动抑制背景噪声和低层视觉变化,如光照、阴影等干扰因素;强大的泛化能力使其在不同环境和物体配置下保持一致性,有助于跨场景泛化。
python
# DINO潜特征提取
class LatentRepresentation:
def __init__(self):
# 使用预训练的DINOv2-ViT-small(冻结参数)
self.dino_encoder = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14')
self.dino_encoder.eval()
for param in self.dino_encoder.parameters():
param.requires_grad = False
def encode_observation(self, rgb_image):
"""
将RGB图像编码为DINO潜特征
输入: (B, 3, 224, 224) RGB图像
输出: (B, 196, 384) 潜特征序列 (14x14 patches)
"""
with torch.no_grad():
# 提取patch级别的特征(不包含CLS token)
features = self.dino_encoder.forward_features(rgb_image)
patch_features = features['x_norm_patchtokens'] # (B, 196, 384)
return patch_features
def predict_future_latent(self, current_latent, action):
"""
在潜空间中预测未来状态(核心优势)
- 不需要重建像素级纹理和光照
- 专注于物体运动、接触和状态变化
"""
future_latent = self.mm_dit(current_latent, action)
return future_latent这种设计的关键优势在于,模型不需要学习如何重建像素级的纹理和光照,而是专注于学习物体的运动、接触和状态变化等与任务相关的动力学知识。
统一的动作空间:以手部为中心
为了实现不同具身形式(机器人、人类、不同类型的机械手)之间的知识共享,LDA-1B定义了统一的以手部为中心的动作空间。该空间包含两个核心组件:腕部位姿增量 表示6自由度的位置和姿态变化,手指构型则根据具身形式不同而有所区别------对于平行爪夹持器使用单自由度的夹持器宽度,对于多指灵巧手则使用腕部坐标系中的关键点位置。
python
# 统一动作表征(跨具身形式)
class UnifiedActionSpace:
def __init__(self, embodiment_type):
self.embodiment_type = embodiment_type
def encode_action(self, raw_action):
"""将不同具身形式的动作编码为统一格式"""
if self.embodiment_type == 'parallel_gripper':
# 机器人平行爪: 6D位姿增量 + 夹持器宽度
wrist_delta = raw_action[:6] # (x,y,z, roll,pitch,yaw)
gripper = raw_action[6:7]
return torch.cat([wrist_delta, gripper])
elif self.embodiment_type == 'dexterous_hand':
# 灵巧手(Sharpa 22-DoF): 6D位姿 + 手指关节
wrist_delta = raw_action[:6]
finger_joints = raw_action[6:] # 22个关节角度
return torch.cat([wrist_delta, finger_joints])
elif self.embodiment_type == 'human_hand':
# 人类手部: 6D位姿 + MANO关键点
wrist_pose = raw_action[:6]
mano_keypoints = raw_action[6:] # 21个3D关键点
return torch.cat([wrist_pose, mano_keypoints])这种统一表征使得模型能够从人类演示中学习灵巧操作的先验知识,然后迁移到机器人上,大大提高了数据利用效率。
混合频率的时间建模
LDA-1B采用创新的混合频率设计来建模时间动力学:视觉观测以3Hz采样 ,动作以10Hz采样。这种设计基于一个重要观察------视觉场景的变化通常比动作控制信号慢。高频采样视觉会产生大量高度相关的连续帧造成计算浪费,而动作需要更高的采样频率来捕捉细粒度的控制动力学。这种设计在保留细粒度动作动力学的同时减少了冗余计算,使模型能够在快速变化的控制信号和慢速演化的视觉状态之间维持连贯的时间对齐。
python
# 混合频率时间建模(3Hz视觉 + 10Hz动作)
class MixedFrequencyStream:
def __init__(self):
self.visual_freq = 3 # Hz (每333ms一帧)
self.action_freq = 10 # Hz (每100ms一个动作)
def organize_temporal_data(self, trajectory):
"""将轨迹组织为异步的视觉和动作流"""
# 视觉流: 降采样到3Hz
visual_indices = torch.arange(0, len(trajectory), step=10//3)
visual_stream = trajectory.observations[visual_indices]
# 动作流: 保持10Hz
action_stream = trajectory.actions
# 时间对齐: 为每个动作关联最近的视觉观测
aligned_data = self.temporal_alignment(visual_stream, action_stream)
return aligned_data这种设计在保留细粒度动作动力学的同时,减少了冗余计算,使模型能够在快速变化的控制信号和慢速演化的视觉状态之间维持连贯的时间对齐。
2.4 多模态扩散Transformer(MM-DiT):统一架构的核心
LDA-1B的模型架构采用多模态扩散Transformer(MM-DiT),这是一个能够在统一扩散框架中联合处理动作和视觉两种模态的创新架构。
架构设计原理
MM-DiT的核心思想是:虽然动作和视觉是两种截然不同的模态,但它们在物理交互中是紧密耦合的。因此,模型需要能够同时处理这两种模态,并让它们相互交互。
python
class MMDiTBlock(nn.Module):
"""多模态扩散Transformer块 - 核心创新"""
def __init__(self, dim, num_attention_heads, attention_head_dim):
super().__init__()
# 双时间步编码器(动作+视觉)
self.dual_timestep_encoder = DualTimestepEncoder(dim)
# 条件注入层(AdaLN-Zero初始化)
self.to_cond = nn.Sequential(
nn.SiLU(),
nn.Linear(dim * 3, dim * 12) # gamma和beta参数
)
nn.init.zeros_(self.to_cond[-1].weight)
nn.init.constant_(self.to_cond[-1].bias[:dim*8], 1.0) # gamma初始化为1
# 模态特定的归一化
self.image_norm1 = RMSNorm(dim)
self.action_norm1 = RMSNorm(dim)
# 联合自注意力(关键创新:动作和视觉共享注意力)
self.joint_attn = JointAttention(
dim=dim,
num_heads=num_attention_heads,
qk_rmsnorm=True, # 稳定训练
flash_attn=True # 加速计算
)
# 语言交叉注意力
self.cross_attn_image = Attention(dim, cross_attention_dim=dim)
self.cross_attn_action = Attention(dim, cross_attention_dim=dim)
# 模态特定的前馈网络
self.image_ff = FeedForward(dim, activation_fn="geglu")
self.action_ff = FeedForward(dim, activation_fn="geglu")
def forward(self, image_tokens, action_tokens, language_context,
t_action, t_visual, task_emb):
"""
image_tokens: (B, N_img, D) 视觉标记
action_tokens: (B, N_act, D) 动作标记
language_context: (B, L, D) 语言上下文
t_action, t_visual: 扩散时间步
"""
# 1. 双时间步编码
timestep_emb = self.dual_timestep_encoder(t_action, t_visual)
cond = torch.cat([timestep_emb, task_emb, language_context.mean(1)], -1)
# 2. 提取AdaLN参数(gamma和beta)
gammas_betas = self.to_cond(cond).chunk(12, dim=-1)
(img_gamma1, img_gamma2, img_gamma3, img_gamma4,
act_gamma1, act_gamma2, act_gamma3, act_gamma4,
img_beta1, img_beta2, act_beta1, act_beta2) = gammas_betas
# 3. 自注意力(联合处理两个模态)
img_norm = self.image_norm1(image_tokens) * img_gamma1 + img_beta1
act_norm = self.action_norm1(action_tokens) * act_gamma1 + act_beta1
img_attn, act_attn = self.joint_attn(img_norm, act_norm)
image_tokens = image_tokens + img_attn * img_gamma2
action_tokens = action_tokens + act_attn * act_gamma2
# 4. 交叉注意力(语言条件)
image_tokens = image_tokens + self.cross_attn_image(
image_tokens, language_context
) * img_gamma3
action_tokens = action_tokens + self.cross_attn_action(
action_tokens, language_context
) * act_gamma3
# 5. 前馈网络
image_tokens = image_tokens + self.image_ff(image_tokens) * img_gamma4
action_tokens = action_tokens + self.action_ff(action_tokens) * act_gamma4
return image_tokens, action_tokensMM-DiT Block的设计
每个MM-DiT块包含三个关键组件:
python
class MMDiTBlock(nn.Module):
def __init__(self, hidden_size, num_heads):
super().__init__()
# 自适应层归一化(AdaLN)
self.adaln = AdaptiveLayerNorm(hidden_size)
# 模态特定的QKV投影
self.action_qkv = nn.Linear(hidden_size, 3 * hidden_size)
self.visual_qkv = nn.Linear(hidden_size, 3 * hidden_size)
# 共享的多头注意力
self.attention = MultiHeadAttention(num_heads, hidden_size)
# 语言交叉注意力
self.cross_attention = CrossAttention(hidden_size)
# 模态特定的FFN
self.action_ffn = FeedForward(hidden_size)
self.visual_ffn = FeedForward(hidden_size)
def forward(self, tokens, condition):
# 1. AdaLN调节
tokens_norm = self.adaln(tokens, condition)
# 2. 分离动作和视觉标记
action_tokens = tokens_norm[:, :action_len]
visual_tokens = tokens_norm[:, action_len:]
# 3. 模态特定的QKV投影
action_qkv = self.action_qkv(action_tokens)
visual_qkv = self.visual_qkv(visual_tokens)
# 4. 拼接后进行共享注意力(关键创新!)
all_qkv = torch.cat([action_qkv, visual_qkv], dim=1)
attended = self.attention(all_qkv)
# 5. 语言交叉注意力
attended = self.cross_attention(attended, language_tokens)
# 6. 分离并通过模态特定的FFN
action_out = self.action_ffn(attended[:, :action_len])
visual_out = self.visual_ffn(attended[:, action_len:])
# 7. 残差连接
return tokens + torch.cat([action_out, visual_out], dim=1)关键设计特点
MM-DiT的设计体现了四个核心创新。模态特定的QKV投影 保留每个模态的归纳偏置,使模型能够学习模态特定的特征。共享的注意力机制 允许动作和视觉标记相互交互,学习跨模态的依赖关系。AdaLN条件注入 通过自适应层归一化将时间步和任务信息注入每一层。语言交叉注意力提供高层语义指导,使模型理解任务目标。
这种设计使得MM-DiT能够同时处理异步的视觉(3Hz)和动作(10Hz)流,在10亿参数规模下实现稳定训练,并灵活支持不同的训练目标(策略、动力学、视觉预测)。
python
# 基于实际实现的训练循环
def train_step(batch, model, optimizer):
"""LDA-1B训练步骤 - 流匹配目标"""
# 1. 随机采样扩散时间步 [0, 1]
t_action = torch.rand(batch_size, device=device)
t_visual = torch.rand(batch_size, device=device)
# 2. 添加噪声(线性插值)
eps_action = torch.randn_like(batch.action)
eps_visual = torch.randn_like(batch.future_visual)
action_noisy = t_action * batch.action + (1 - t_action) * eps_action
visual_noisy = t_visual * batch.future_visual + (1 - t_visual) * eps_visual
# 3. 模型预测速度场(flow matching)
v_action, v_visual = model(
obs=batch.obs,
language=batch.language,
action_noisy=action_noisy,
visual_noisy=visual_noisy,
t_action=t_action,
t_visual=t_visual,
task_emb=batch.task_embedding
)
# 4. 流匹配损失(预测目标 - 噪声)
target_action = batch.action - eps_action
target_visual = batch.future_visual - eps_visual
loss_action = F.mse_loss(v_action, target_action)
loss_visual = F.mse_loss(v_visual, target_visual)
# 5. 根据任务类型选择性激活损失
if batch.task == 'policy':
loss = loss_action # 仅策略学习
elif batch.task == 'visual_forecasting':
loss = loss_visual # 仅视觉预测
elif batch.task == 'forward_dynamics':
loss = loss_action + loss_visual # 前向动力学
elif batch.task == 'inverse_dynamics':
loss = loss_action + 0.5 * loss_visual # 逆向动力学
# 6. 反向传播(带梯度裁剪)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
return loss.item()通过这些精心设计的架构和训练技术,LDA-1B实现了在10亿参数规模下的稳定训练,同时保持了对异构数据的高效利用能力。
3. EI-30k数据集:规模化的基石
3.1 数据集概览
EI-30k(Embodied Interaction 30k)是LDA-1B能够实现规模化学习的关键基础设施。这是一个包含超过3万小时 具身交互轨迹的大规模数据集,是目前机器人领域最大的统一格式数据集之一。