目录
介绍
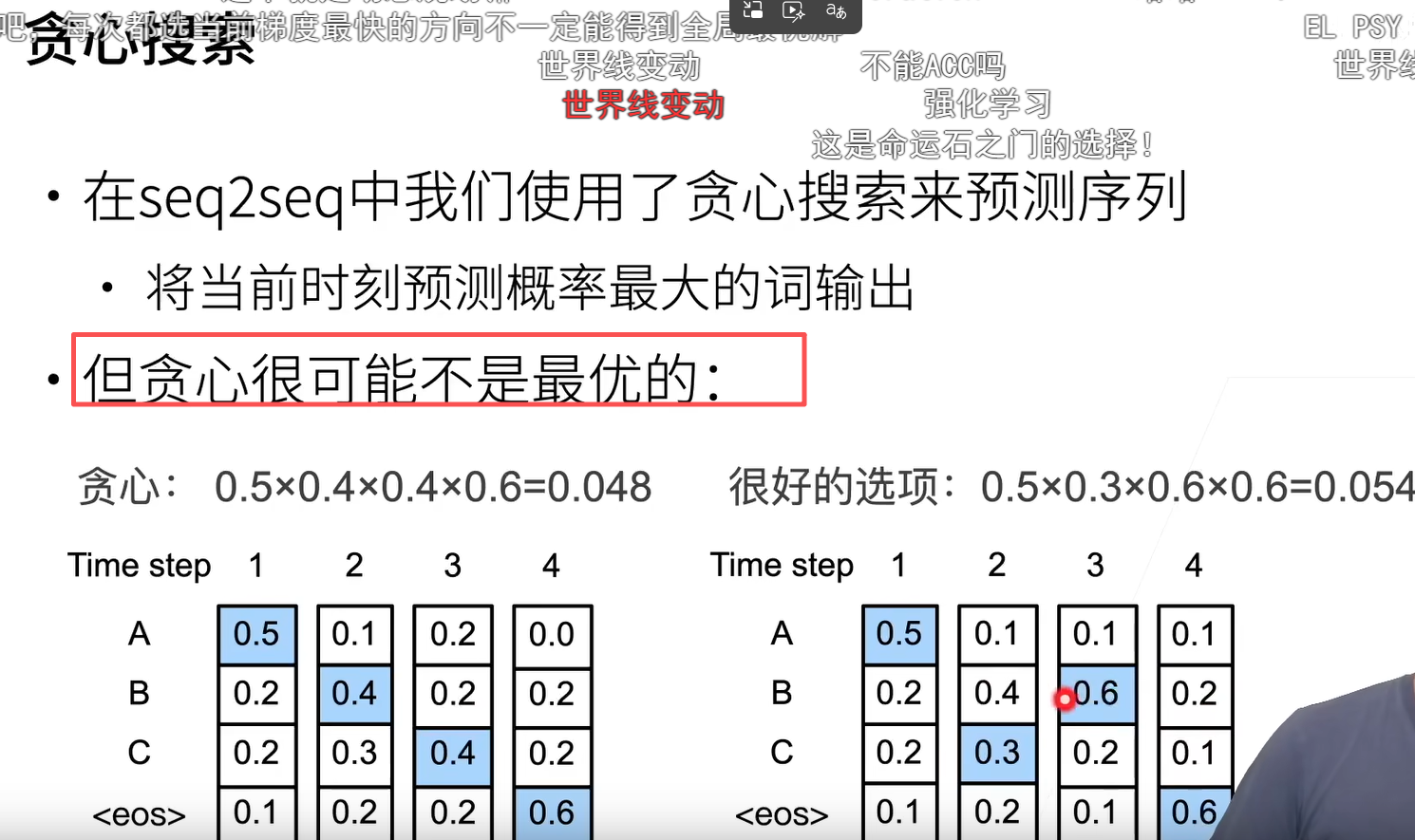
这是最优化里面的局部最优解吧,每次都选当前梯度最快的方向不一定能得到全局最优解
穷举搜索:
-
对所有可能的序列,计算它的概率,然后选取最好的那个
-
如果输出字典大小为 n,序列最长为 T,那么我们需要考察 nT个序列
-
n=10000, T=10: nT=1040
-
计算上不可行
-

启发式搜索: (贪心和穷举折中)
束搜索
-
保存最好的 k个候选
-
在每个时刻,对每个候选新加一项(n种可能),在 kn个选项中选出最好的 k个
步骤演示 (k=2)
-
Time step 1 Candidates
-
起始节点 分出 A, B, C, D, E
-
保留最优的 2 个候选:A , C
-
-
Time step 2 Candidates
-
候选 A 扩展出 A, B, C, D, E → 形成路径 AB, AC, AD, AE
-
候选 C 扩展出 A, B, C, D, E → 形成路径 CA, CB, CC, CD, CE
-
在所有扩展路径中选出最优的 2 个:AB , CE
-
-
Time step 3 Candidates
-
候选 AB 扩展出 A, B, C, D, E → 形成路径 ABA, ABB, ABC, ABD, ABE
-
候选 CE 扩展出 A, B, C, D, E → 形成路径 CEA, CEB, CEC, CED, CEE
-
在所有扩展路径中选出最优的 2 个:ABD , CED
-

每一个时间步都做kn次选择
公式的计算逻辑可以分为三个部分来理解:
- 核心逻辑:为什么要求"对数"和"求和"?
机器翻译模型通常会计算一个序列出现的概率 P(y1,...,yL)。根据概率链式法则,这等于每一步条件概率的乘积:
P(序列)=p(y1)×p(y2∣y1)×p(y3∣y1,y2)×...
-
取对数的作用(log) :直接连乘很多小于1的小数(概率值)容易导致计算机浮点数下溢(变成极小的科学计数法,精度丢失)。数学上,log(A×B)=logA+logB,将乘法转换为加法,既解决了数值精度问题,又符合神经网络计算习惯。
-
求和的作用:∑t′=1Llogp(yt′∣...)就是把每一步的对数概率加起来,得到整个序列的总对数概率。
- 归一化:除以 Lα
这是公式中最关键的一步。如果不做处理,模型会有一个严重偏向:它总是喜欢生成短句子。
因为概率都是小于1的正数,乘的次数越多(句子越长),整体概率值就越小。为了公平比较不同长度的句子,需要进行归一化。
-
L:代表当前候选序列的长度(单词个数)。
-
α:长度惩罚系数。除以 Lα就是为了让分数"平均"到每个词上。
-
α=0.75 :这是一个经验值。如果 α=1,就是纯粹的平均;设为 0.75 是为了稍微降低惩罚力度。这意味着模型并不完全排斥长句子,如果长句子带来的额外信息增益足够大,它依然会被保留。
- 计算示例
假设有两个候选句子:
-
候选 A(短句):长度为 2,原始概率是 0.1×0.1=0.01。
- 分数 = log(0.01)/20.75=−4.6/1.68≈−2.7
-
候选 B(长句):长度为 4,原始概率是 0.3×0.3×0.3×0.3=0.0081。虽然绝对值小,但相对表现不错。
- 分数 = log(0.0081)/40.75=−4.8/2.82≈−1.7
虽然候选 B 的原始概率更低,但经过归一化后,-1.7 > -2.7,长句 B 获得了更高的分数并被保留。
这个公式的本质就是:在保证精度的前提下,综合考虑序列的整体置信度,并消除句子长短带来的偏见。

每个step会从kn个结果里面选出最好的k个
穷举是对所有可能的序列中选出最好的一个,是指数级的