《The Illustrated GPT-2》中文原理精讲
本文根据 Jay Alammar 的 The Illustrated GPT-2 整理。图片来自原文,文字部分改写为中文教程,目标是接着 《The Illustrated Transformer》中文原理精讲 往下走,把 GPT-2 为什么是现代 LLM 的重要基石讲清楚。
上一篇 Transformer 主要解释的是机器翻译模型:左边有编码器读原文,右边有解码器写译文。GPT-2 做的事情更像"超级输入法":给它一段前文,它不断预测下一个 token。它没有原始 Transformer 里的编码器,也没有翻译模型中解码器用来读取编码器结果的交叉注意力层,而是把"带遮罩的自注意力解码器块"一层一层堆高。
先约定几个符号。假设输入 token 序列是:
x 1 , x 2 , ... , x t x_1,x_2,\dots,x_t x1,x2,...,xt
语言模型要学习的是下一个 token 的概率:
P ( x t + 1 ∣ x 1 , x 2 , ... , x t ) P(x_{t+1}\mid x_1,x_2,\dots,x_t) P(xt+1∣x1,x2,...,xt)
如果把"已经写出来的上文"看成题目,那么 GPT-2 每一步都在做一道选择题:词表里有很多候选 token,哪个最适合接在后面?
GPT-2 的核心流程可以概括为:
token编号 → 词向量 + 位置向量 → 多层 masked Transformer block → 词表分数 → 下一个 token \text{token编号} \rightarrow \text{词向量 + 位置向量} \rightarrow \text{多层 masked Transformer block} \rightarrow \text{词表分数} \rightarrow \text{下一个 token} token编号→词向量 + 位置向量→多层 masked Transformer block→词表分数→下一个 token
这里的 masked 很关键,意思是模型在预测当前位置时只能看左边已经出现的内容,不能偷看右边未来答案。
0. 先把 GPT-2 和上一篇 Transformer 对上
上一篇原始 Transformer 的结构是:
Encoder + Decoder \text{Encoder} + \text{Decoder} Encoder+Decoder
它适合翻译,因为翻译时有一整句源语言输入,也有一串目标语言输出。编码器先读完整源句,解码器再一边看源句信息,一边生成目标句。
GPT-2 的结构更像:
Decoder-only Transformer \text{Decoder-only Transformer} Decoder-only Transformer
它只保留"能从左往右生成文本"的那部分。可以把原始 Transformer 和 GPT-2 的差异记成下面这张表:
| 问题 | 原始 Transformer | GPT-2 |
|---|---|---|
| 典型任务 | 翻译 | 续写、生成、问答的基础 |
| 是否有编码器 | 有 | 没有 |
| 是否有解码器 | 有 | 有,但改造成 decoder-only |
| 自注意力能不能看未来 | 目标端不能看未来 | 不能看未来 |
| 是否有交叉注意力 | 有,解码器看编码器输出 | 没有 |
| 核心训练目标 | 给源句预测目标句 | 给前文预测下一个 token |
所以 GPT-2 不是"另一个完全陌生的模型"。它更像把上一篇的 Transformer 拆开后,拿出其中最适合生成的部件,做大、堆深、喂更多文本。
1. GPT-2:一个大号的下一个词预测器

GPT-2 展示出来的能力是:给它一个开头,它可以继续写出看起来连贯的文章。它之所以能做到这件事,不是因为它真的像人一样拥有经历,而是因为它在大量文本中学会了"什么样的上文后面常常接什么样的下文"。
从最朴素的角度看,GPT-2 每一步只做一件事:
根据前面的 token,预测下一个 token 的概率分布 \text{根据前面的 token,预测下一个 token 的概率分布} 根据前面的 token,预测下一个 token 的概率分布
"概率分布"不是只给一个答案,而是给所有候选 token 一个分数。例如上文是:
text
The robot must obey模型可能给出:
text
orders: 0.42
the: 0.16
humans: 0.07
law: 0.04
...如果每次都选概率最高的 token,生成会比较确定,但也容易重复。如果按概率抽样,生成会更有变化,但也更容易跑偏。GPT-2 这类语言模型的生成艺术,很多都在"怎么从概率里挑 token"这里。
2. 语言模型:手机输入法的超级放大版
语言模型最容易理解的类比就是手机输入法。你输入 我今天想吃,输入法可能提示 火锅、饭、点、什么。这就是一个简化版语言模型:看前面已经输入的内容,猜后面最可能出现什么。
GPT-2 和手机输入法的区别不是方向不同,而是规模和能力不同。手机输入法通常只需要给你几个短建议,GPT-2 则用更大的参数量、更长的上下文、更复杂的 Transformer 结构,从大量互联网文本中学习语言规律。
数学上,语言模型要最大化训练文本中真实下一个 token 的概率。对于一句话:
text
I love machine learning训练时可以拆成多道题:
text
I -> love
I love -> machine
I love machine -> learning每道题都让模型给正确答案更高概率。如果模型把 learning 的概率给得太低,损失就会大;梯度下降会调整模型里的权重,让下一次类似上下文中 learning 的概率上升。
常用的损失可以写成:
L o s s = − log P ( 正确的下一个 token ∣ 前文 ) \mathrm{Loss}=-\log P(\text{正确的下一个 token}\mid \text{前文}) Loss=−logP(正确的下一个 token∣前文)
这个公式的意思很直接:正确答案概率越高,损失越小;正确答案概率越低,损失越大。
3. 模型大小:参数就是模型学到的"旋钮"

原文提到 GPT-2 有不同大小的版本。所谓"大小",主要指参数数量、层数、隐藏维度、注意力头数这些配置。参数可以理解成模型内部可以被训练修改的数字旋钮。
如果一个模型只有几个参数,它能表达的规律很少;如果有上亿参数,它就有更多空间记录复杂的语言规律。这里要注意,参数不是逐条存储句子的数据库,而是神经网络中的权重矩阵。训练过程会把大量文本中的统计规律压进这些矩阵里。
例如一个最简单的线性函数:
y = a x + b y=ax+b y=ax+b
这里的 a a a 和 b b b 就是参数。训练就是不断调整 a a a 和 b b b,让预测值更接近真实值。GPT-2 里的参数也是类似思想,只不过不再是两个数字,而是很多巨大的矩阵,比如词向量矩阵、注意力权重矩阵、前馈网络权重矩阵。
4. 从编码器-解码器到只堆一种 Transformer 块
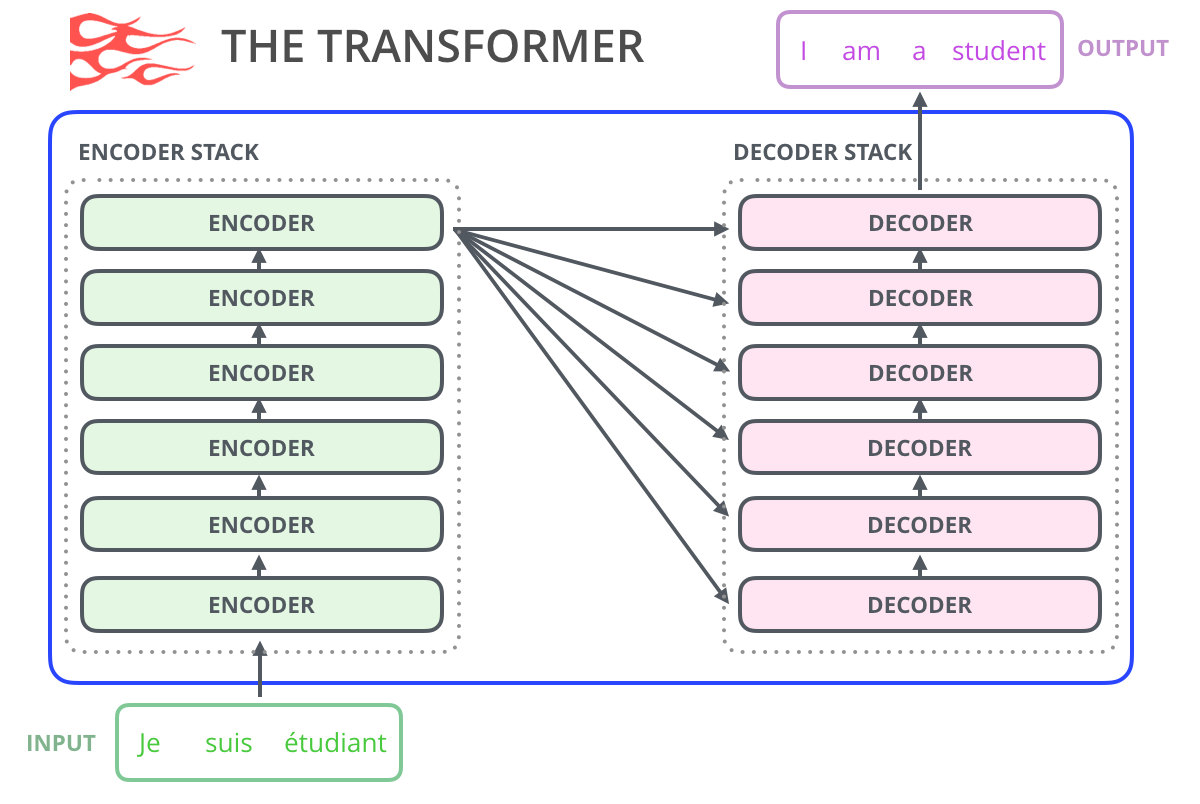
原始 Transformer 由编码器和解码器组成。编码器适合"理解完整输入",解码器适合"从左到右生成输出"。在翻译任务里,这个分工非常自然:先读完整法语句子,再写英语句子。
GPT-2 的任务不是"读一段源语言再翻译",而是"根据已有上文继续写"。这时模型并不需要另一个编码器给它源句表示,它只需要在当前前文内部做推理。因此后续很多语言模型都开始尝试只保留一类 Transformer block。
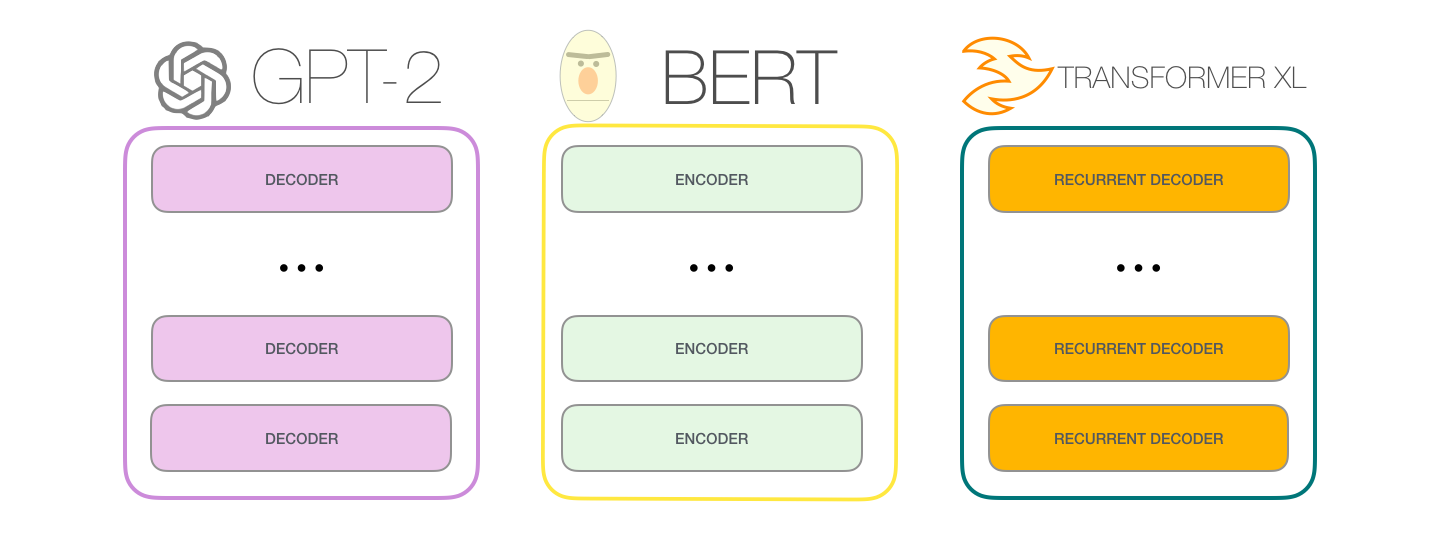
这张图展示了后续模型对原始 Transformer 的不同取舍。BERT 更偏向编码器,它擅长双向理解;GPT-2 更偏向解码器,它擅长从左往右生成。
这也是为什么 BERT 和 GPT-2 的气质不同:
text
BERT:看完整句子,适合理解、分类、抽取。
GPT-2:只看左边上文,适合续写、生成。两者都来自 Transformer,但遮罩方式和训练目标不同,最后擅长的事情也不同。
5. GPT-2 的尺寸差异:层数、宽度和注意力头
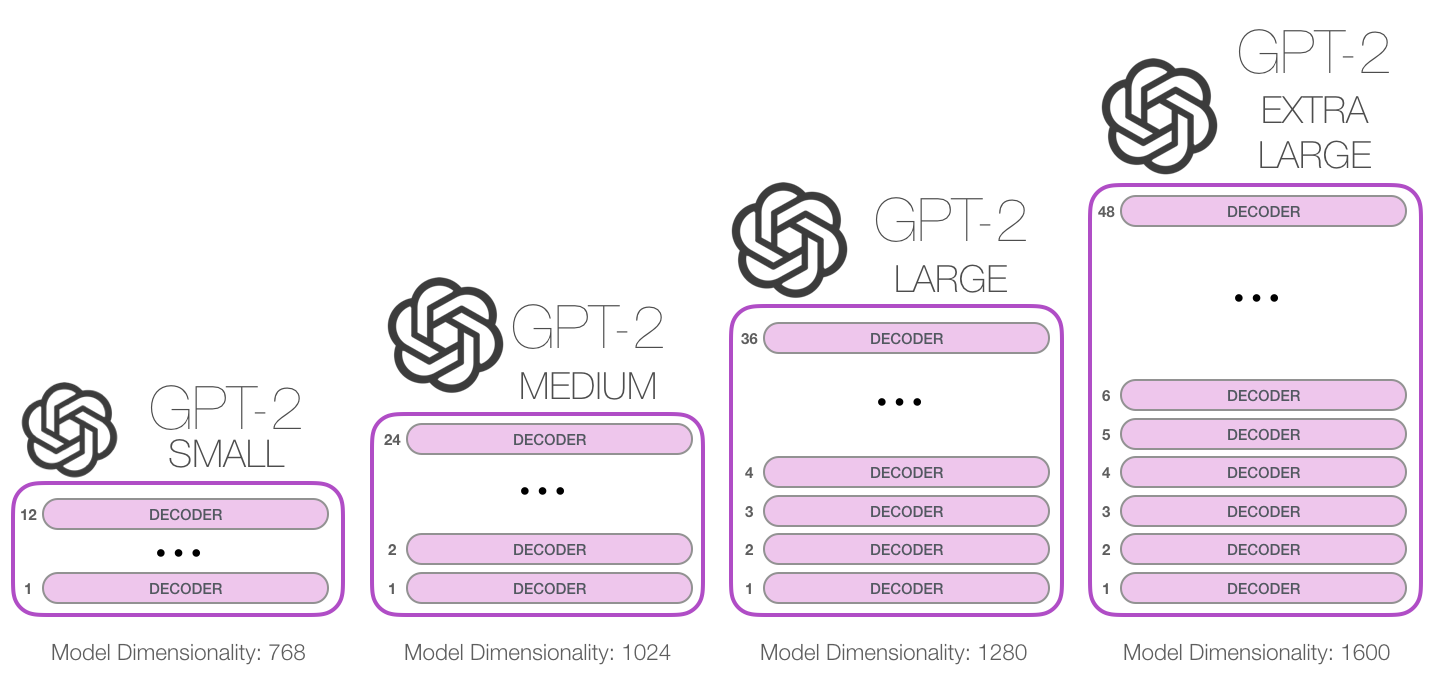
这张图里常见几个词:
layers 表示 Transformer block 堆了多少层。层数越多,模型可以做越多轮加工。第一层可能处理比较浅的搭配,高层可能形成更抽象的上下文表示。
d_model 或 hidden size 表示每个 token 的向量长度。GPT-2 small 是 768,也就是每个 token 在模型内部用 768 个数字表示。
heads 表示多头注意力的头数。GPT-2 small 有 12 个头,可以理解成每层里有 12 个"观察角度"并行工作。
context size 表示模型一次最多能看多长的前文。GPT-2 的常见上下文长度是 1024 token。这里的 token 不一定等于一个完整单词,有时是单词片段。
这些数字变大,模型表达能力通常更强,但训练和推理成本也更高。
6. GPT-2 和 BERT 的关键区别:自回归
GPT-2 是自回归模型。自回归的意思是:模型先生成一个 token,再把这个 token 接回输入序列,继续预测下一个 token。
用流程写出来就是:
text
输入:<s>
输出:the
输入:<s> the
输出:robot
输入:<s> the robot
输出:must每一步的新输出,都会成为下一步的新输入。这就像写文章时,每写一个字,后面要写什么都会受到刚写下的内容影响。
自回归模型天然适合生成,因为它的运行方式和"从左到右写句子"一致。但是它也有代价:生成时必须一步一步来,不能像阅读理解那样一次性同时得到所有位置的答案。
训练时会更高效一些。虽然目标仍然是"每个位置预测下一个 token",但整段文本可以并行送进模型,因为 causal mask 会保证每个位置只看到自己左边的内容。
7. Transformer block 的三种形态
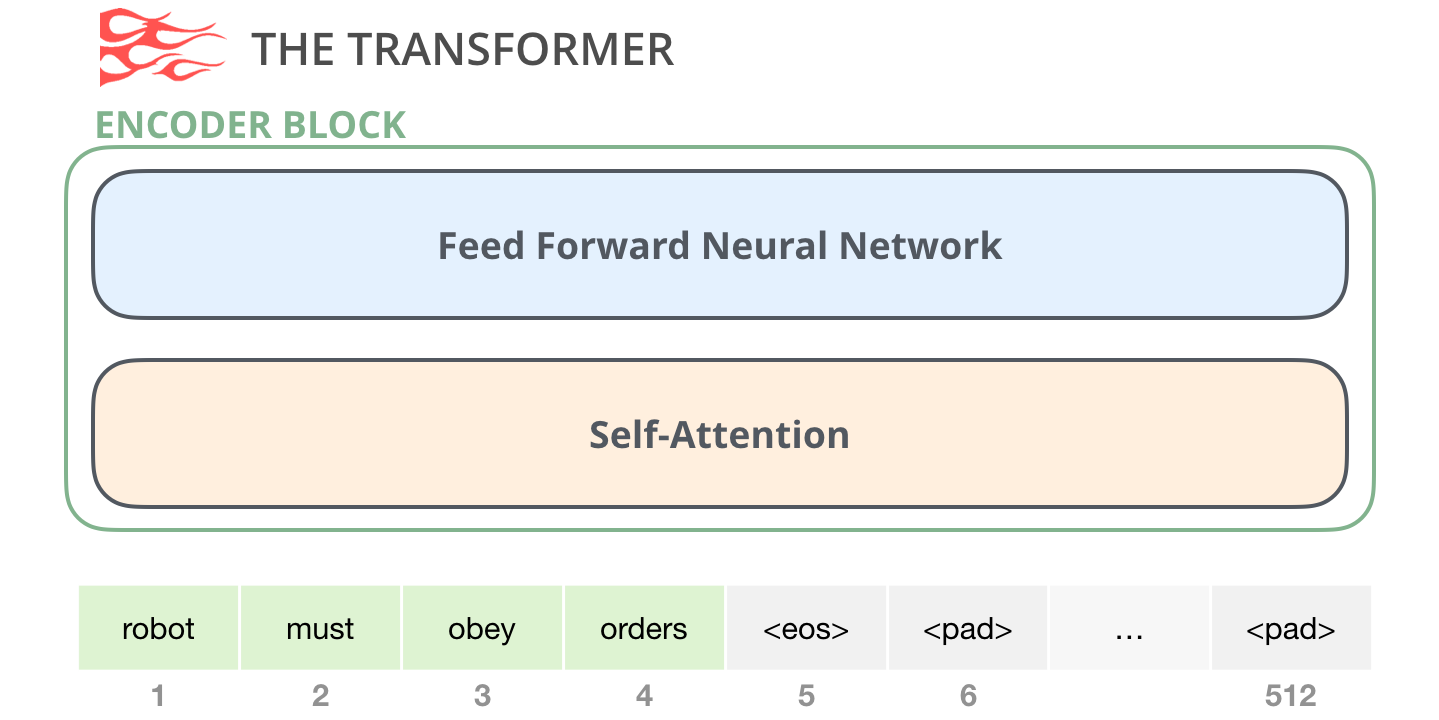
编码器块的自注意力可以看完整句子。比如处理第 3 个词时,它可以看第 1、2、4、5 个词。因为编码器通常用于理解完整输入,不需要假装未来不存在。
编码器块的主要结构是:
Self-Attention + Feed-Forward \text{Self-Attention} + \text{Feed-Forward} Self-Attention+Feed-Forward
每个 token 先通过自注意力和其他 token 交换信息,再通过前馈网络做非线性加工。
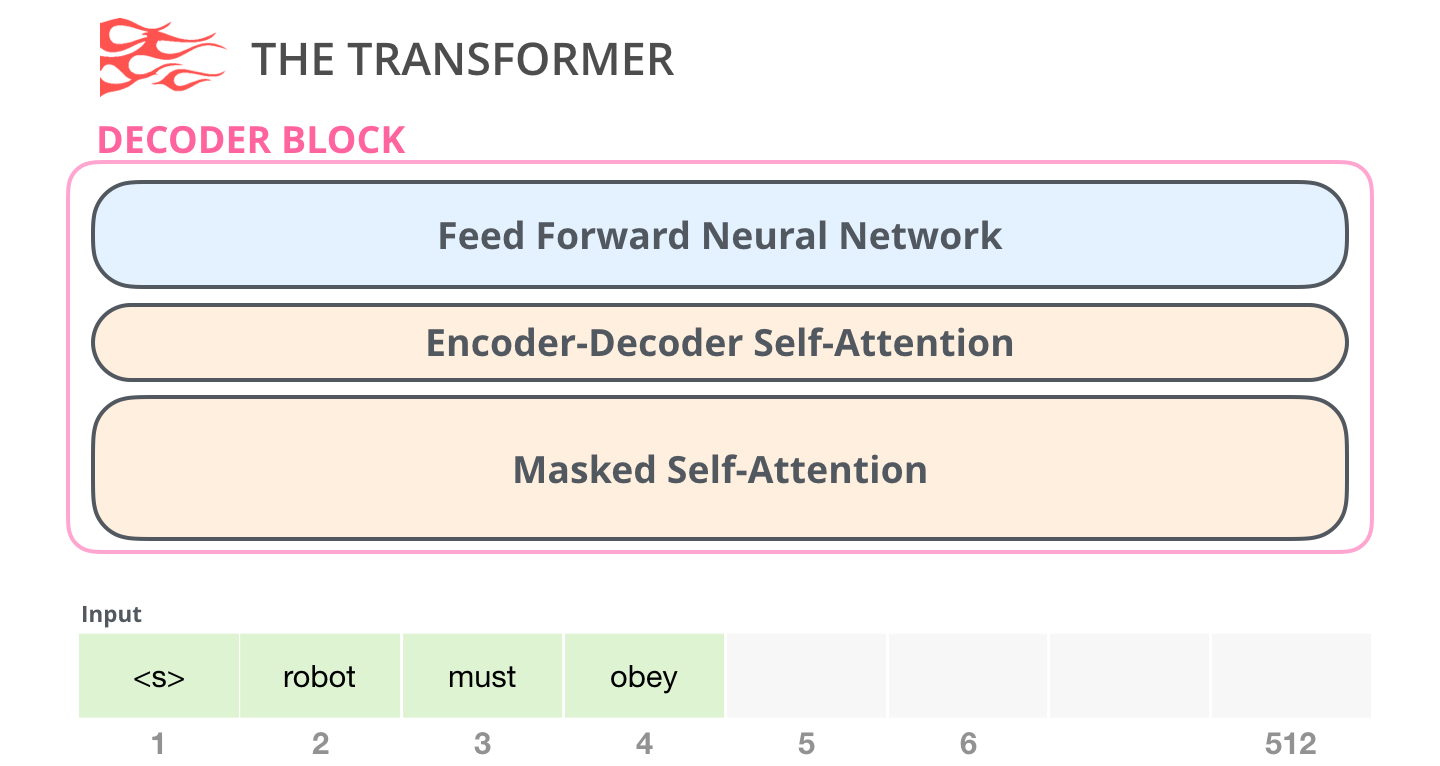
原始 Transformer 的解码器块更复杂。它有三块:
text
masked self-attention
cross-attention
feed-forward第一块让目标句内部从左到右生成,不能看未来。第二块让目标句每个位置去看编码器输出,也就是读取源句信息。第三块再对每个位置做非线性加工。
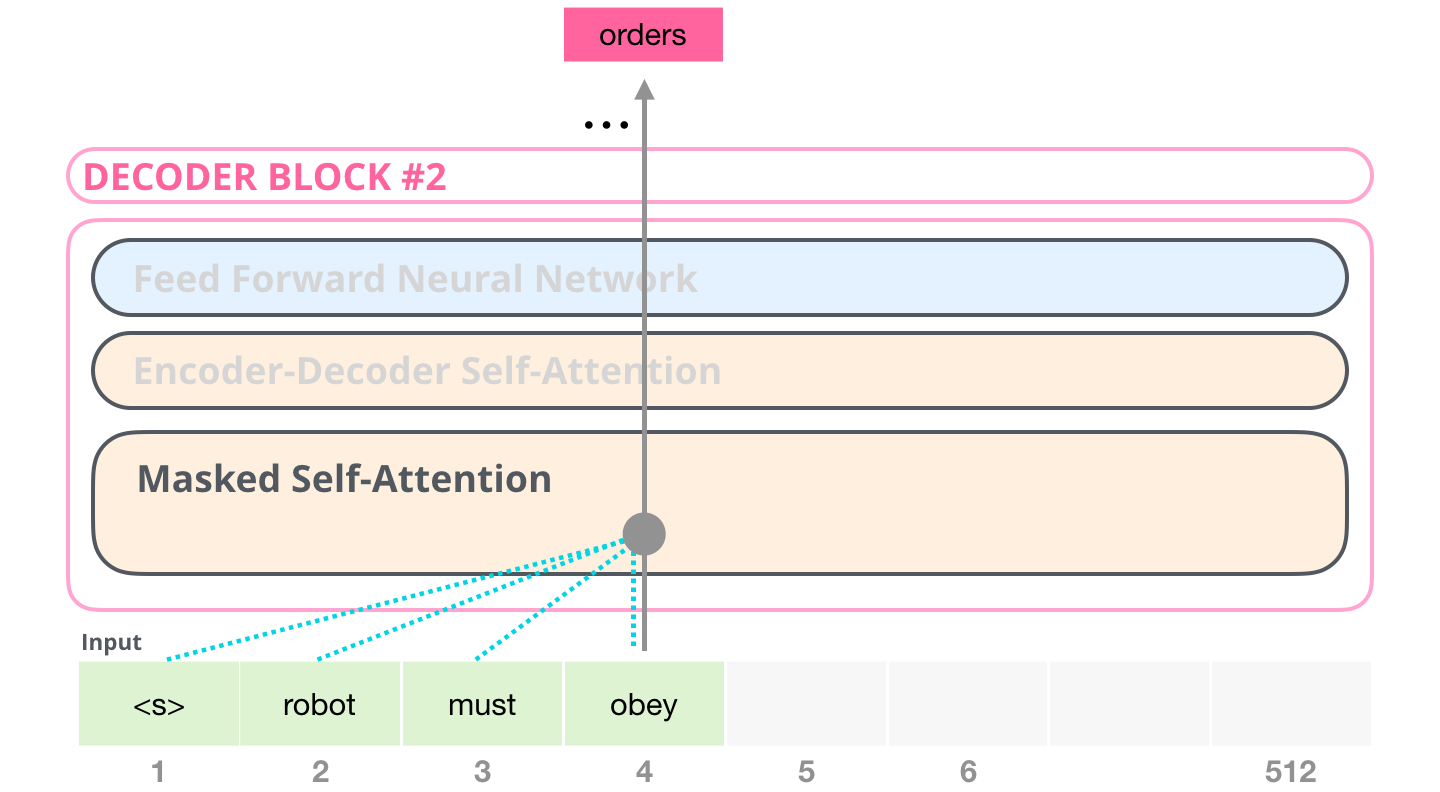
遮罩自注意力的作用是防止作弊。假设训练句子是:
text
The robot must obey orders当模型在 must 这个位置预测下一个 token 时,它不能提前看到后面的 obey orders。否则训练时答案泄露,生成时又没有未来答案可看,训练和使用就不一致。
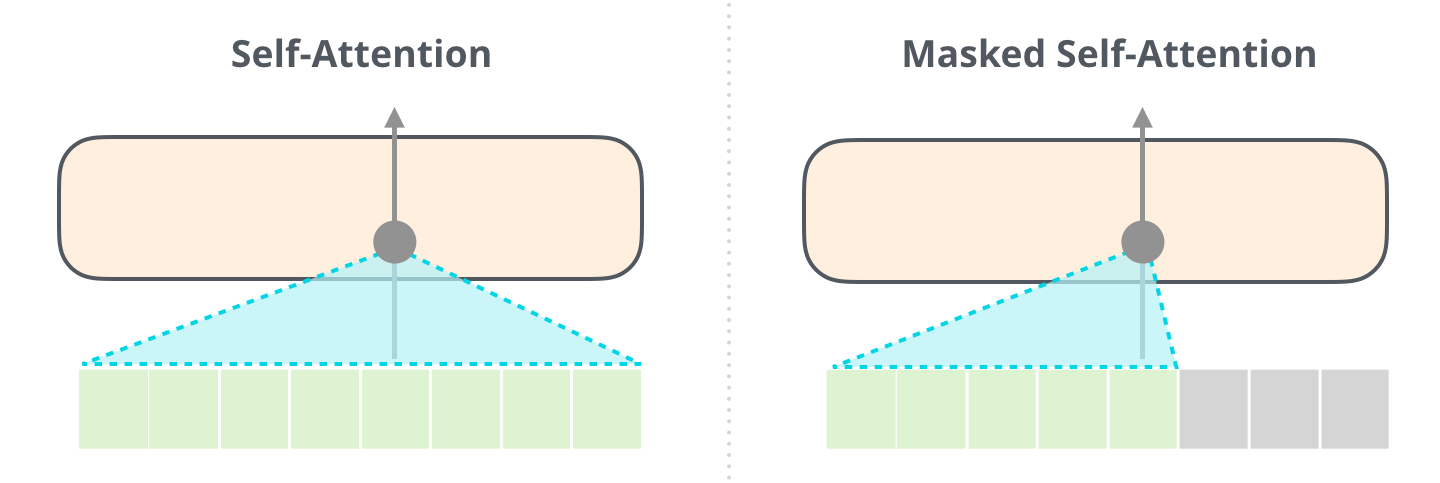
普通自注意力像一场全班讨论,每个词都能听到所有词。遮罩自注意力像按时间顺序写日记:今天写到这里,只能参考今天之前的内容,明天发生的事情不能提前拿来用。
8. Decoder-only:GPT-2 只留下生成需要的部分
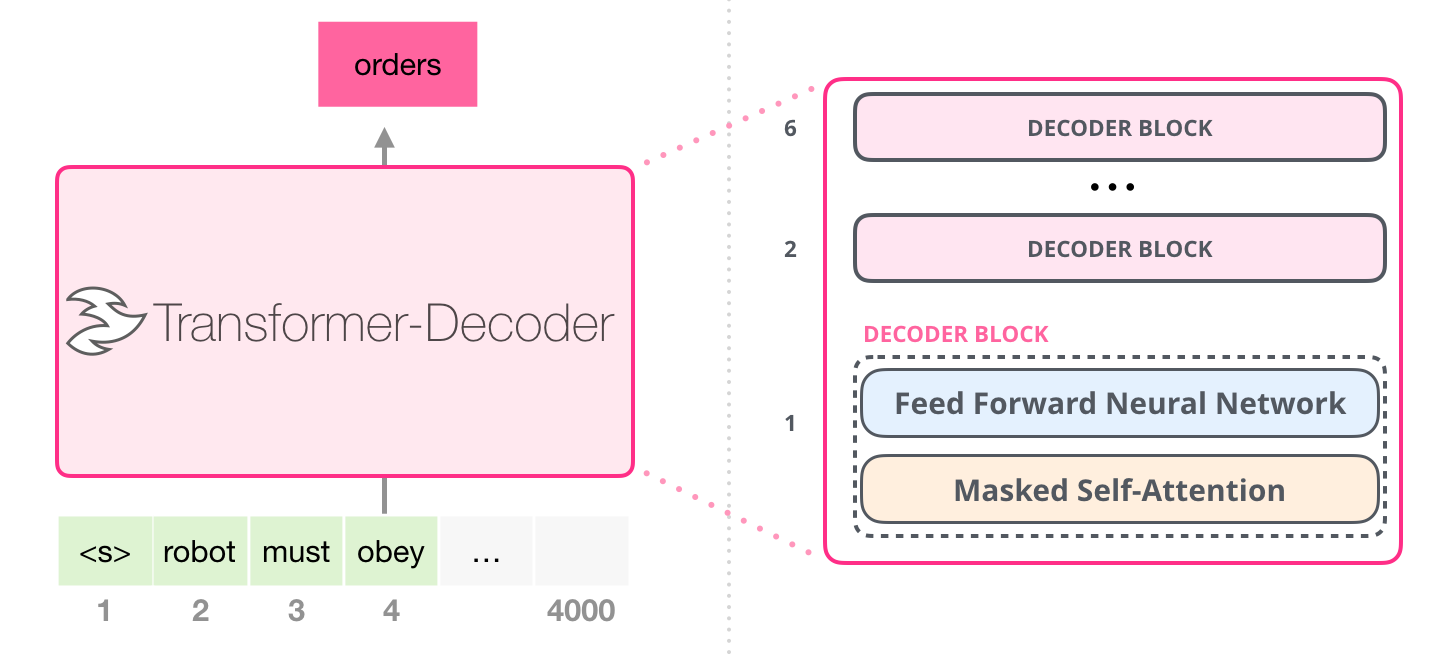
Decoder-only block 可以理解成把原始解码器里的 cross-attention 拿掉,只保留:
text
masked self-attention
feed-forward为什么可以去掉 cross-attention?因为 GPT-2 的输入和输出不是"源句"和"译文"两条不同序列,而是一条连续文本。它只需要根据前面的 token 预测后面的 token,不需要额外读取编码器给的源语言表示。
这就是 GPT 系列的基本骨架。现代很多 LLM 仍然沿用这个方向:大量 decoder-only Transformer block 堆叠起来,训练目标仍然是预测下一个 token。
9. 打开 GPT-2:1024 条位置轨道
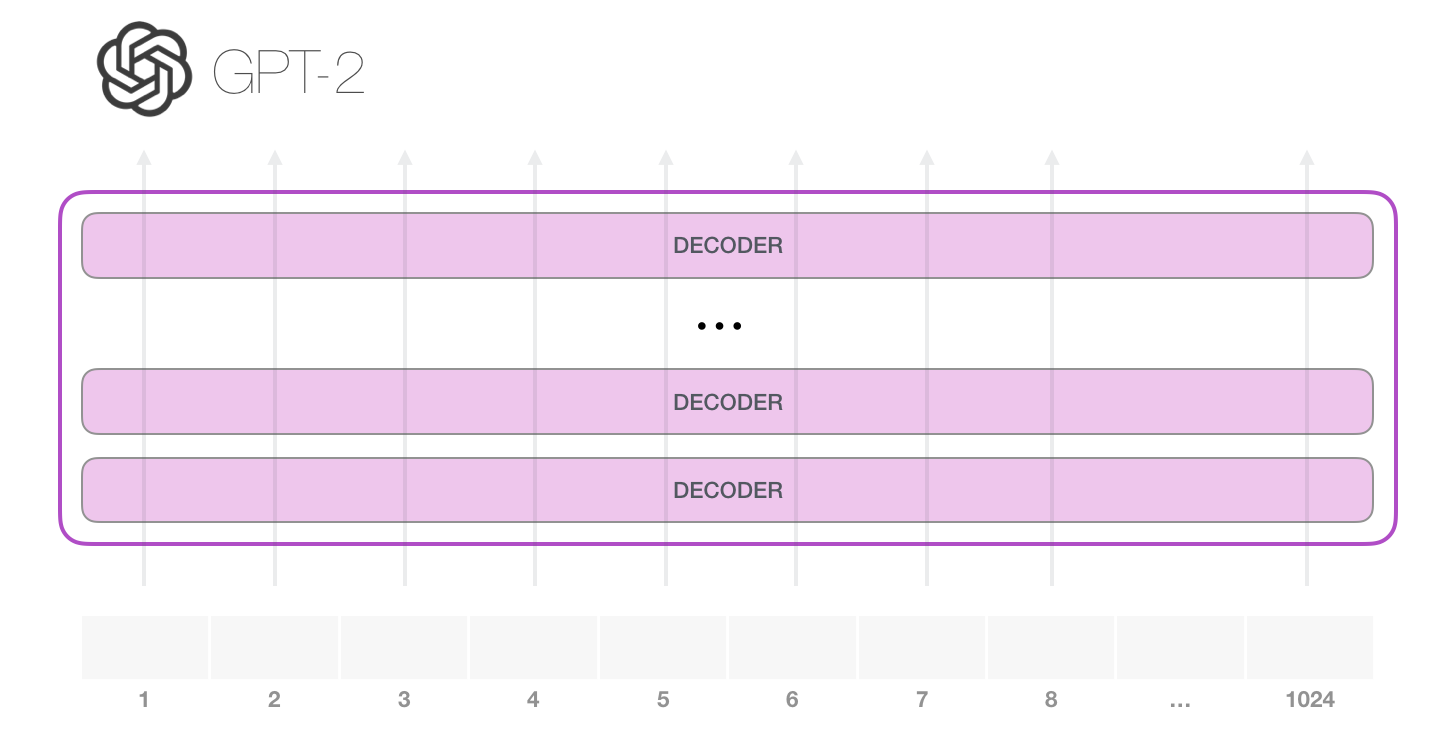
GPT-2 可以处理一段最多 1024 个 token 的上下文。每个 token 都会沿着自己的位置轨道穿过一层层 Transformer block。
如果把每个 token 想成一名学生,Transformer block 就像一间间教室。每进一间教室,学生先通过注意力和前面学生交流,再通过前馈网络整理自己的理解。走完所有教室后,每个位置都会得到一个更成熟的向量表示。
设第 l l l 层输入是:
X ( l ) ∈ R T × d m o d e l X^{(l)}\in \mathbb{R}^{T\times d_{model}} X(l)∈RT×dmodel
其中 T T T 是当前序列长度, d m o d e l d_{model} dmodel 是每个 token 的向量长度。第 l l l 层输出可以写成:
X ( l + 1 ) = B l o c k ( l ) ( X ( l ) ) X^{(l+1)}=\mathrm{Block}^{(l)}(X^{(l)}) X(l+1)=Block(l)(X(l))
最后一层的最后一个位置向量,就会被用来预测下一个 token。
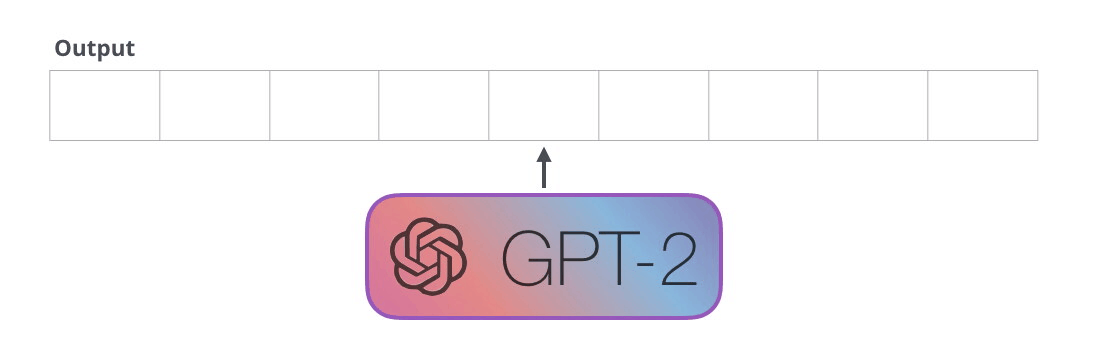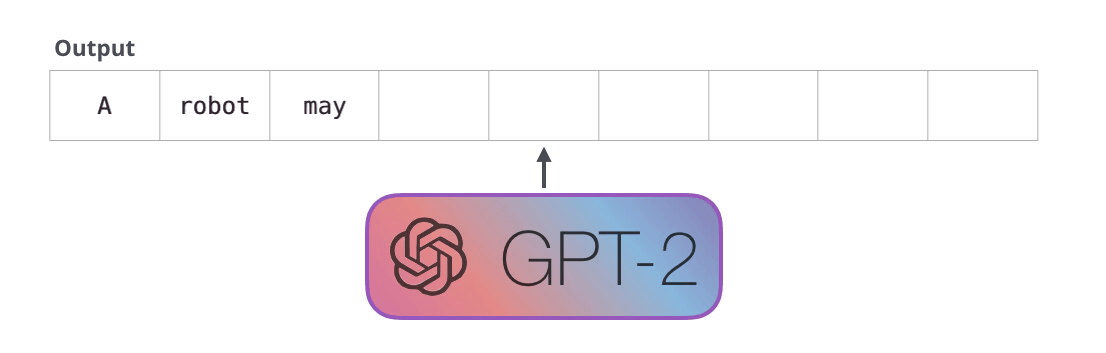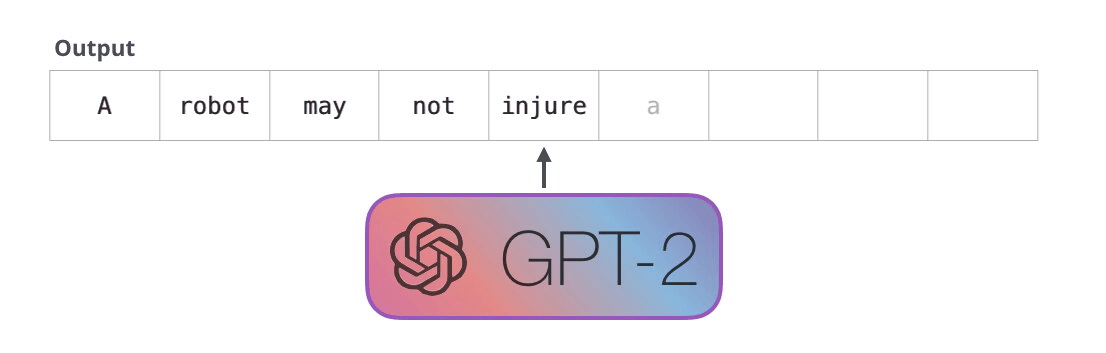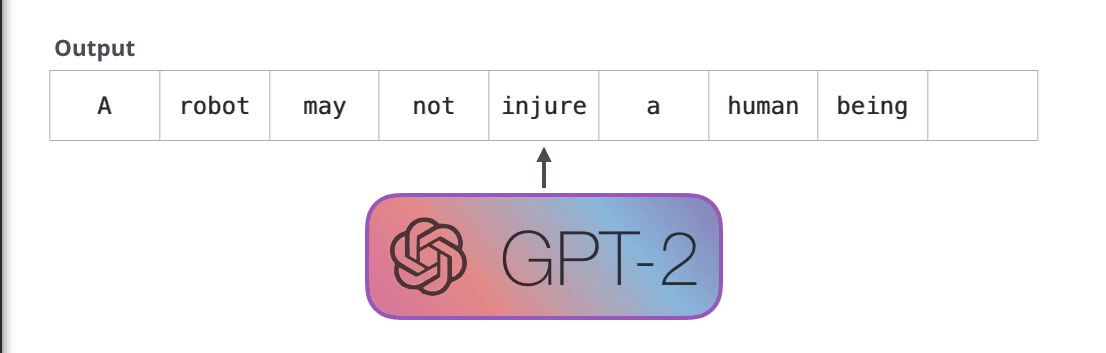
10. 从一个起始 token 开始生成
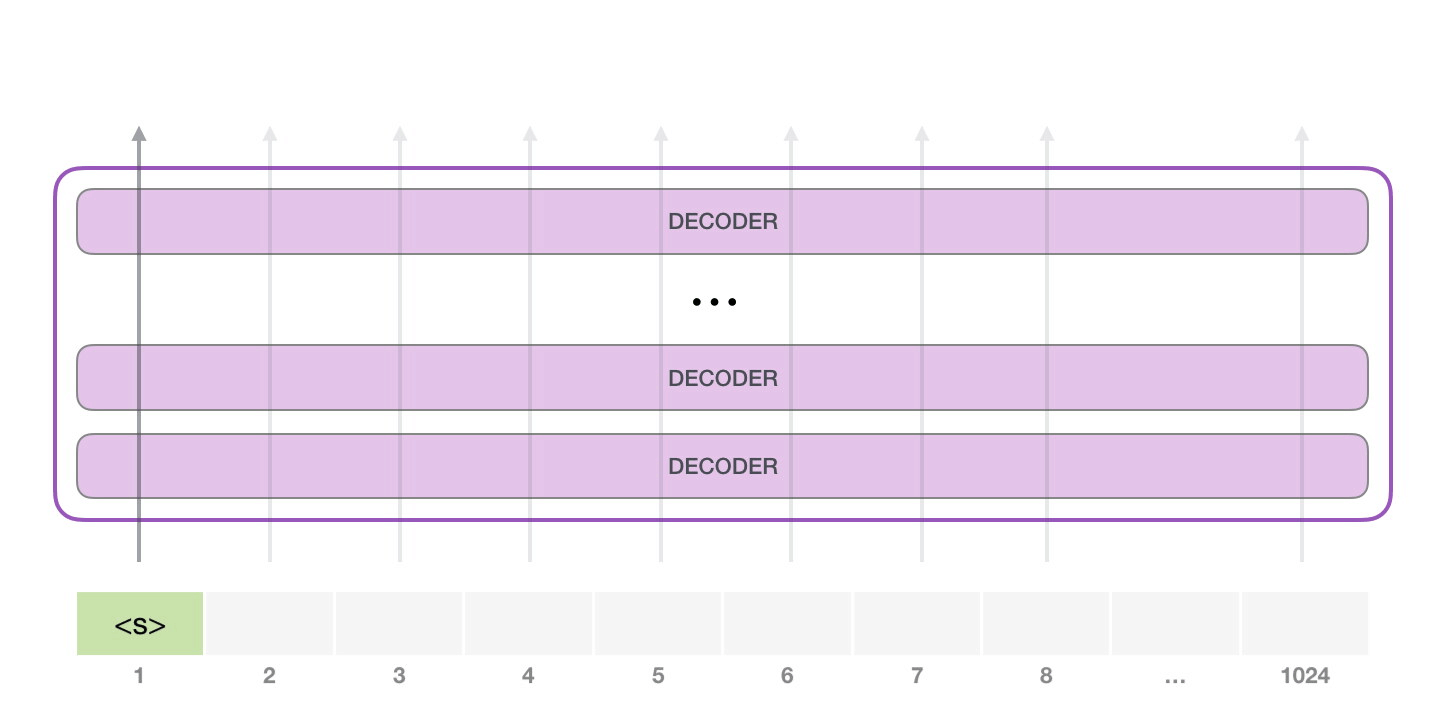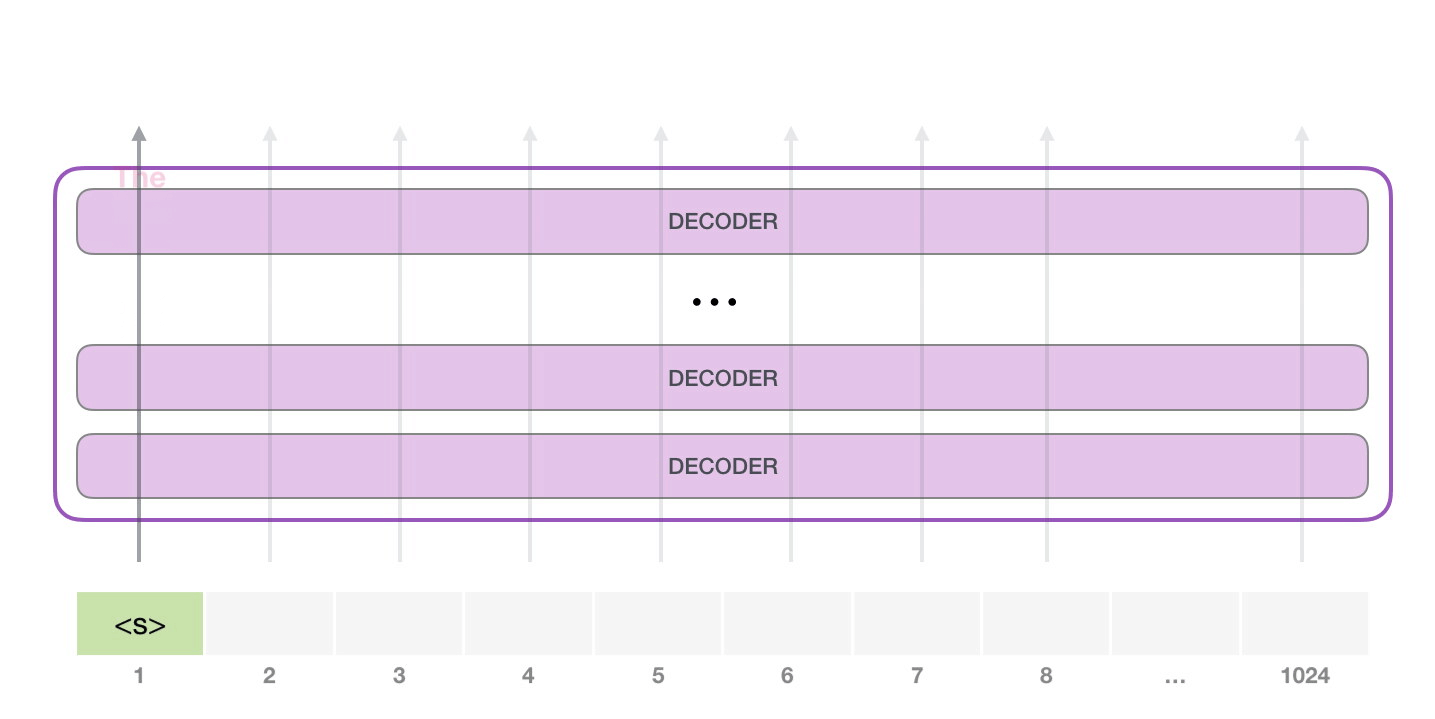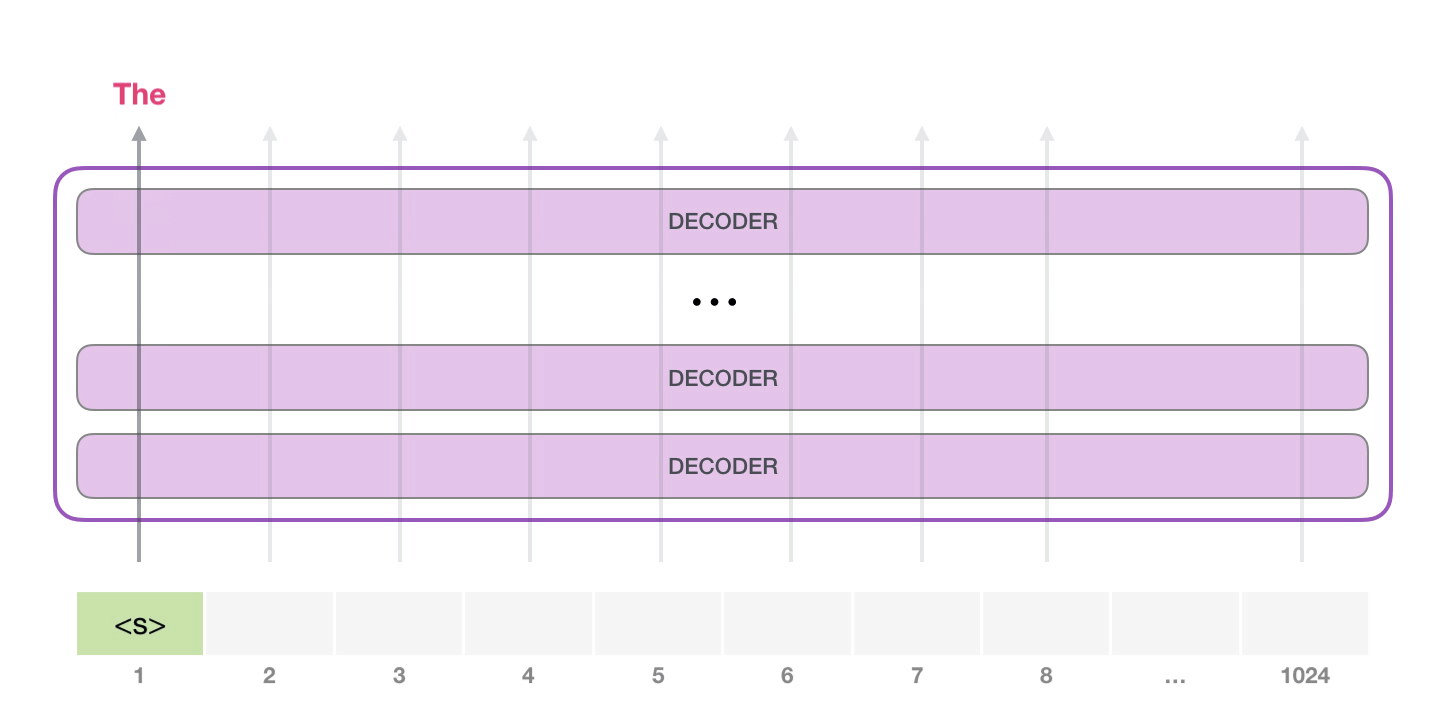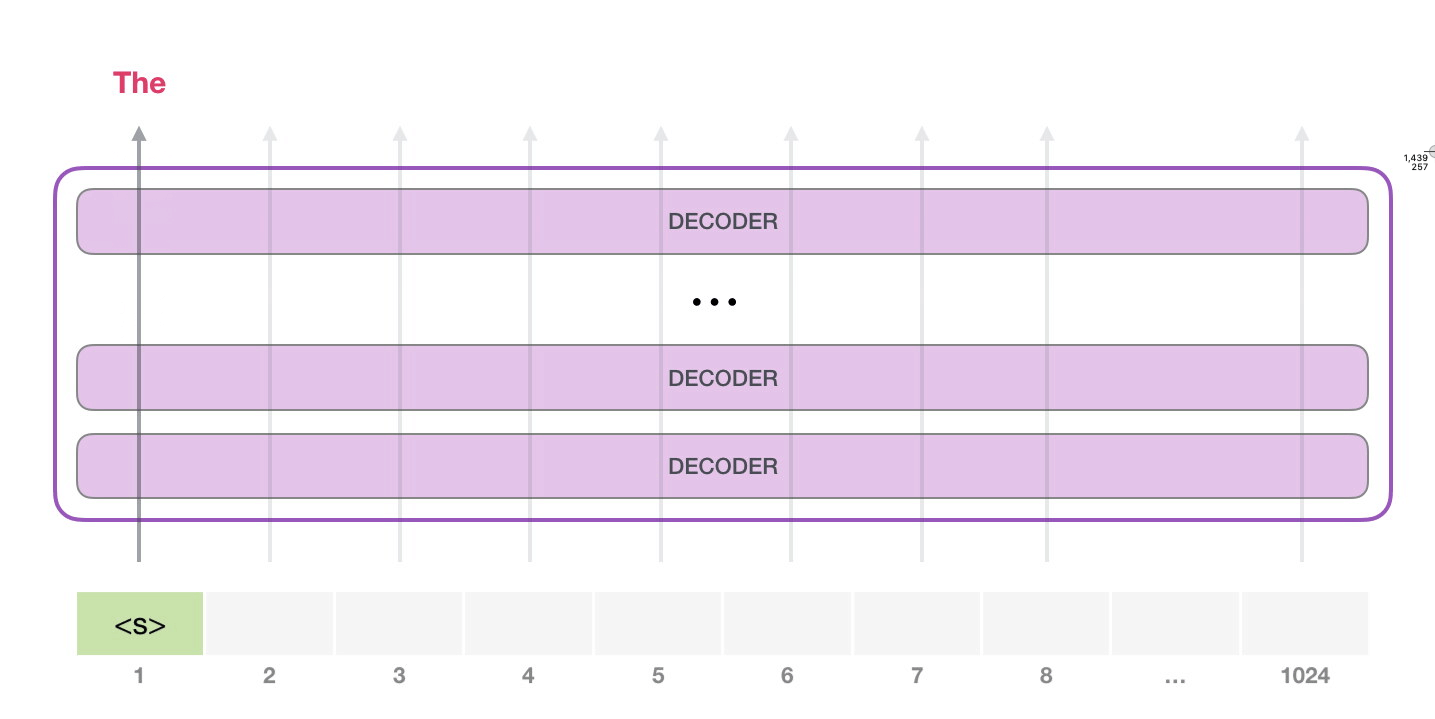
GPT-2 可以在没有具体提示词时,从特殊 token <|endoftext|> 开始生成。原文为了简单,把它叫作 <s>。这个 token 不是自然语言里的普通单词,而是词表中的一个特殊符号,表示文本边界或起始。
第一步只有一个输入 token,模型会把它变成向量,穿过所有层,得到一个输出向量。这个输出向量会和词表里的每个 token 做匹配,得到所有候选 token 的分数。分数最高的可能是 the,于是模型输出 the。
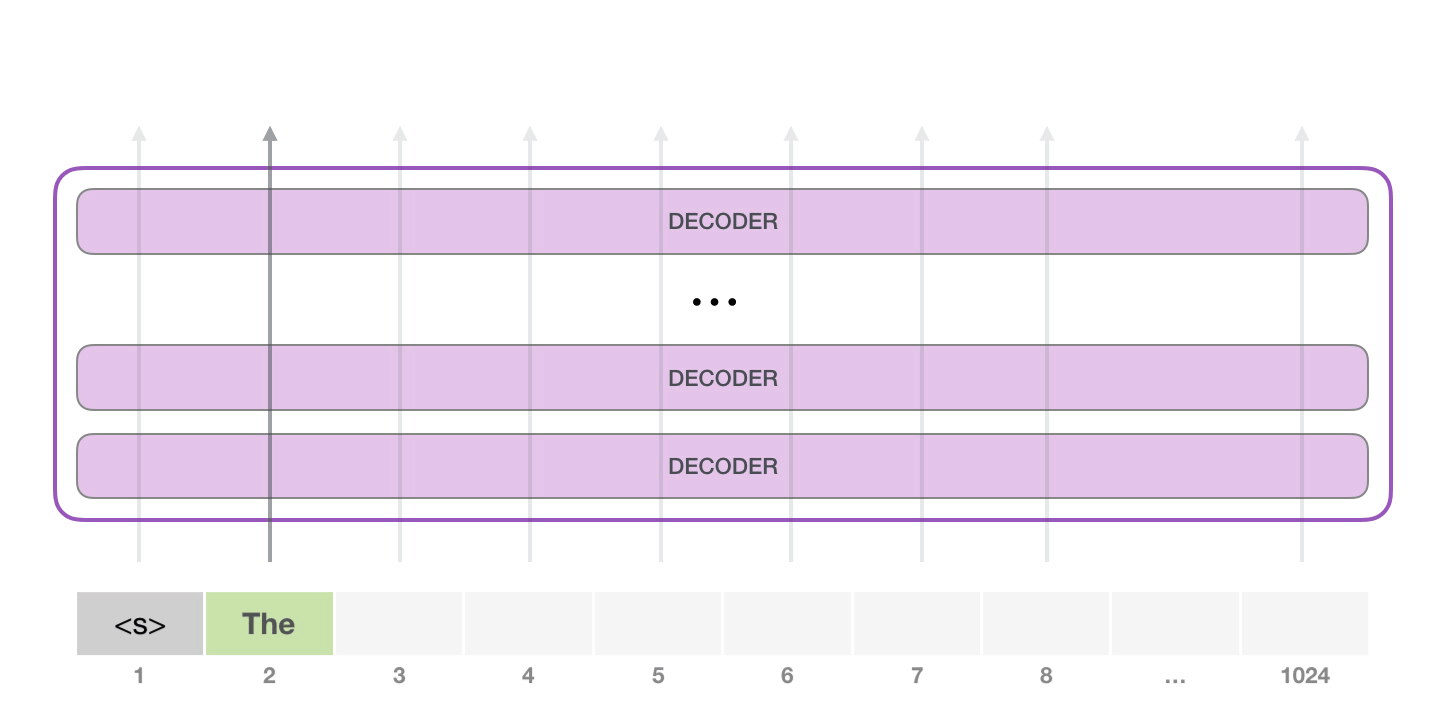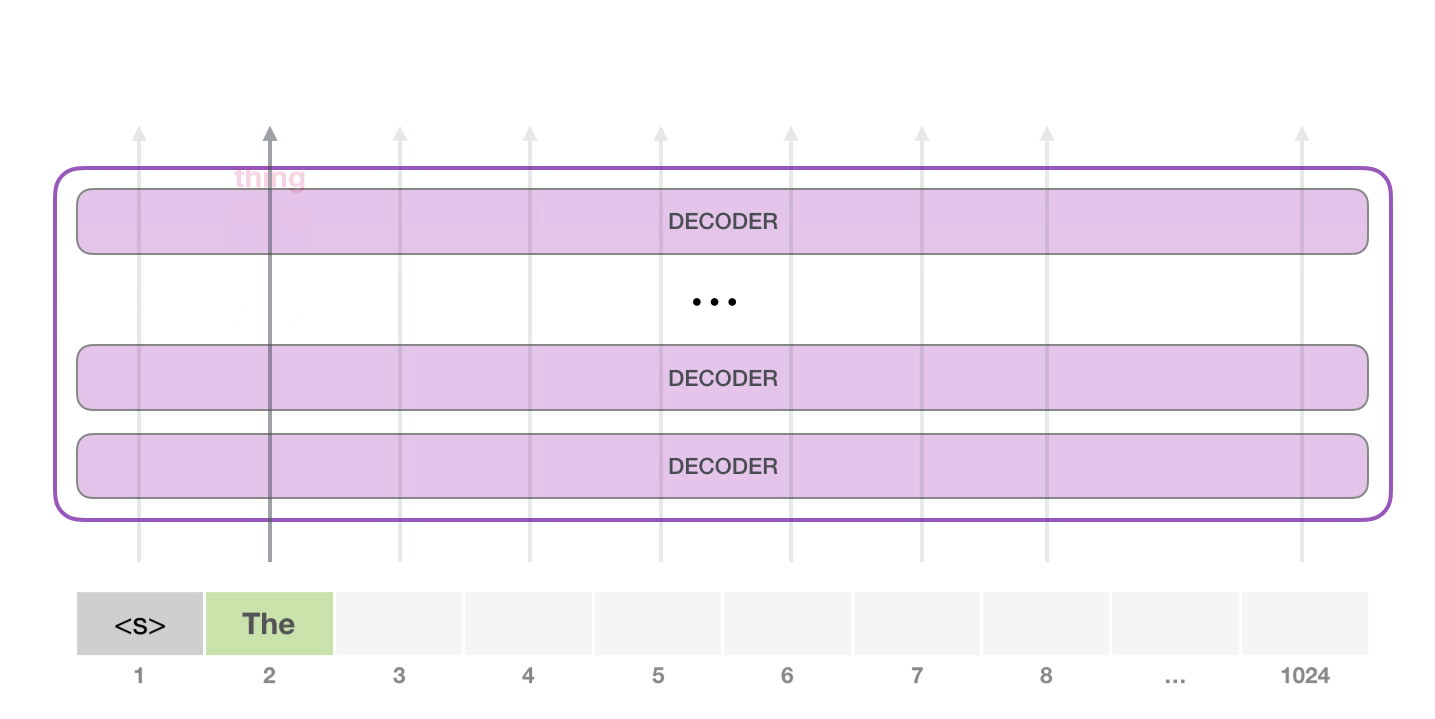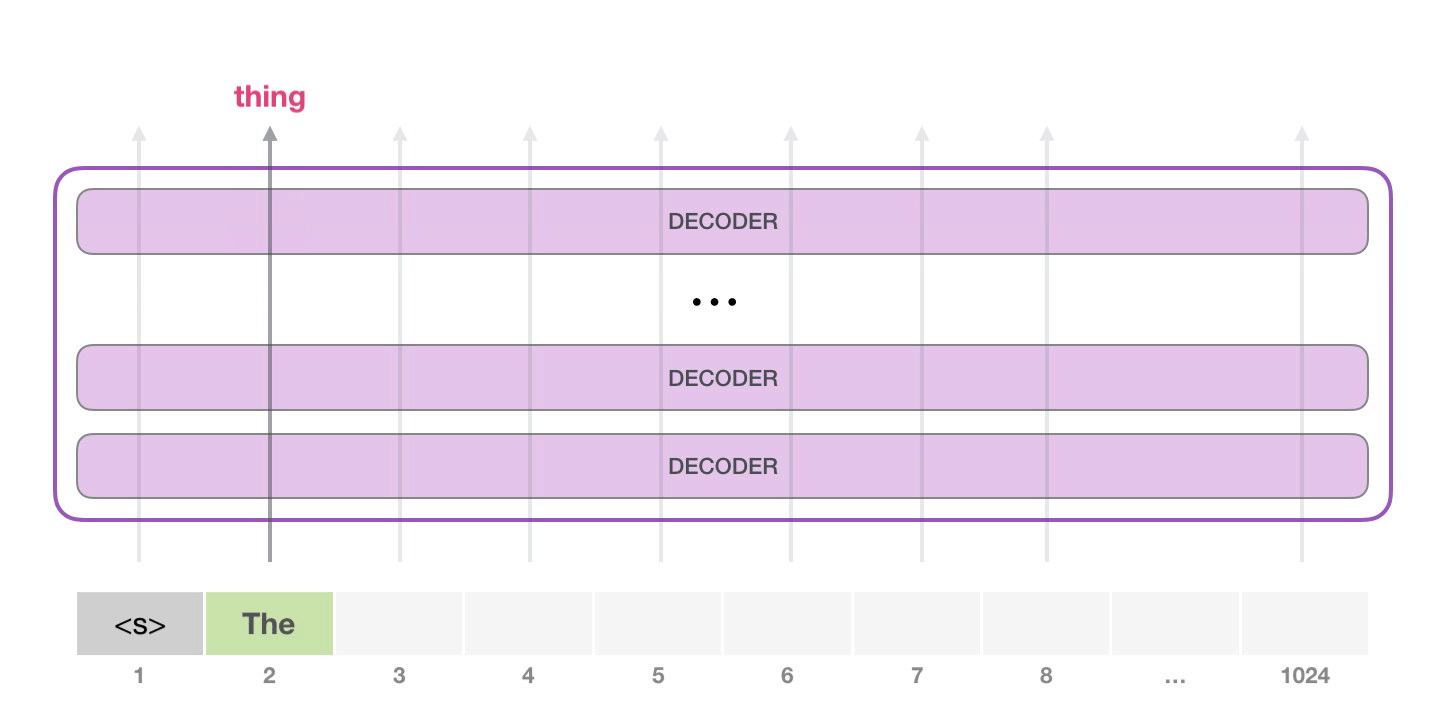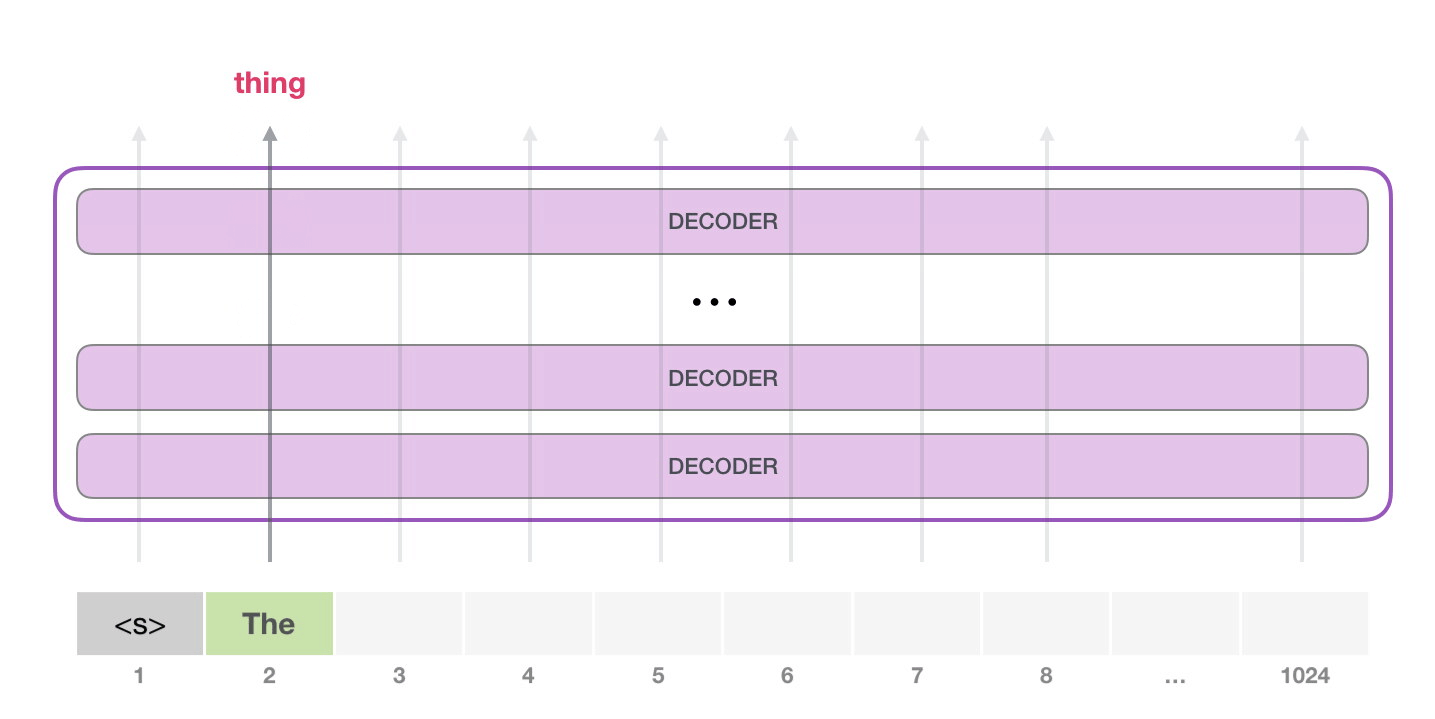
第二步输入变成:
text
<s> the模型再预测下一个 token。这个过程不断重复,就形成了长文本。
这里有一个容易误解的地方:GPT-2 不是一次性在脑子里写完整篇文章。它每一步只决定下一个 token。长文章的连贯性来自很多步局部预测叠加,以及模型在训练中学到的长程依赖。
11. token embedding:把 token 编号变成向量
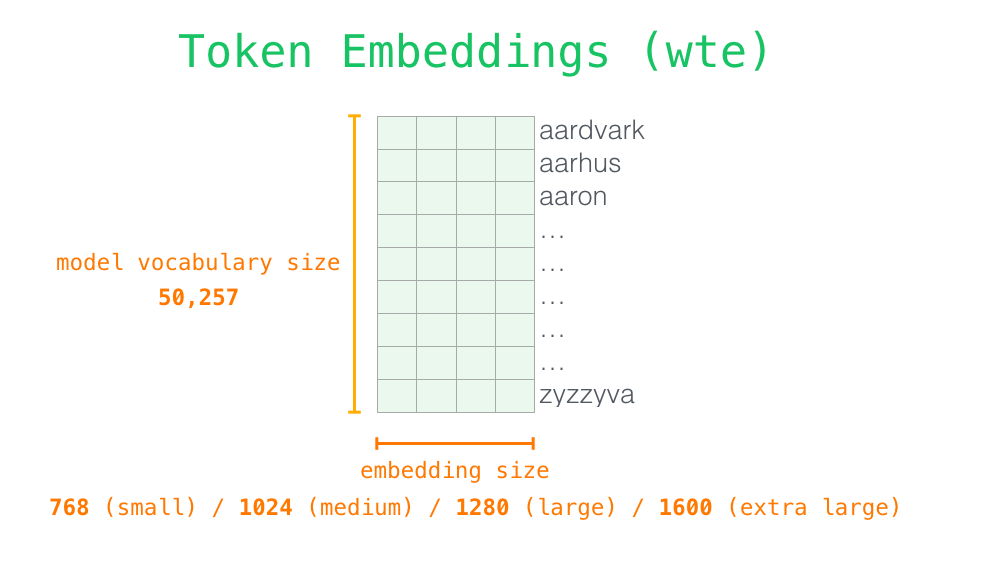
模型不能直接理解文字。无论输入是 robot、must,还是一个子词片段,都要先变成编号,再通过 embedding 矩阵查成向量。
假设词表里有 5 个 token:
text
0: <s>
1: the
2: robot
3: must
4: obeyembedding 矩阵可以想成一张表:
E = 0.10 − 0.20 0.30 0.40 0.05 − 0.10 − 0.30 0.80 0.20 0.70 − 0.60 0.10 0.25 0.15 0.90 E= \begin{bmatrix} 0.10 & -0.20 & 0.30\\ 0.40 & 0.05 & -0.10\\ -0.30 & 0.80 & 0.20\\ 0.70 & -0.60 & 0.10\\ 0.25 & 0.15 & 0.90 \end{bmatrix} E= 0.100.40−0.300.700.25−0.200.050.80−0.600.150.30−0.100.200.100.90
如果输入 token 编号是 2,模型就取第 2 行:
E 2 = − 0.30 , 0.80 , 0.20 E2=-0.30,\\ 0.80,\\ 0.20 E2=−0.30, 0.80, 0.20
这行数字就是 robot 的向量表示。真实 GPT-2 small 不是 3 维,而是 768 维。维度越高,每个 token 可以携带的特征越丰富,比如词性、语义、常见搭配、语气、领域等信息都会混在这些数字里。
12. 位置编码:告诉模型顺序
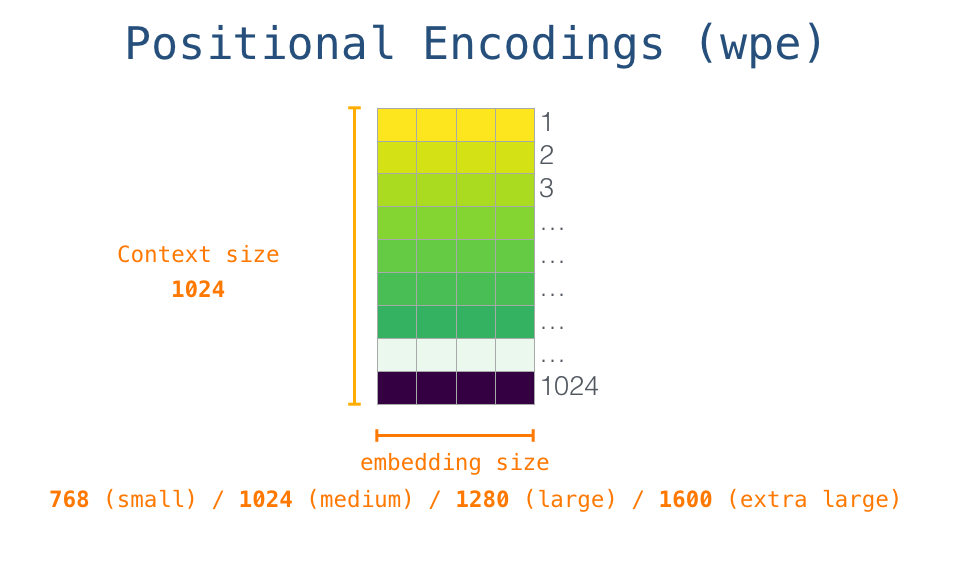
自注意力本身很像"看一堆 token 的集合"。如果不额外告诉它顺序,dog bites man 和 man bites dog 里的 token 集合一样,但意思完全不同。
GPT-2 使用可学习的位置向量。它有一张位置表,位置 0 有一个向量,位置 1 有一个向量,一直到最大上下文长度。输入第 t t t 个 token 时,模型会把 token 向量和位置向量相加:
x t = E token i d t + E pos t x_t=E_{\text{token}}id_t+E_{\text{pos}}t xt=Etokenidt+Epost
这就像给每个词贴两张标签:一张写"我是谁",另一张写"我站在第几个位置"。

上一篇原始 Transformer 使用的是正弦余弦位置编码,而 GPT-2 使用可学习位置编码。两者目的相同,都是补充顺序信息;不同点是正弦余弦位置编码是固定公式生成的,GPT-2 的位置向量是训练中学出来的。
13. 向上穿过所有 Transformer block
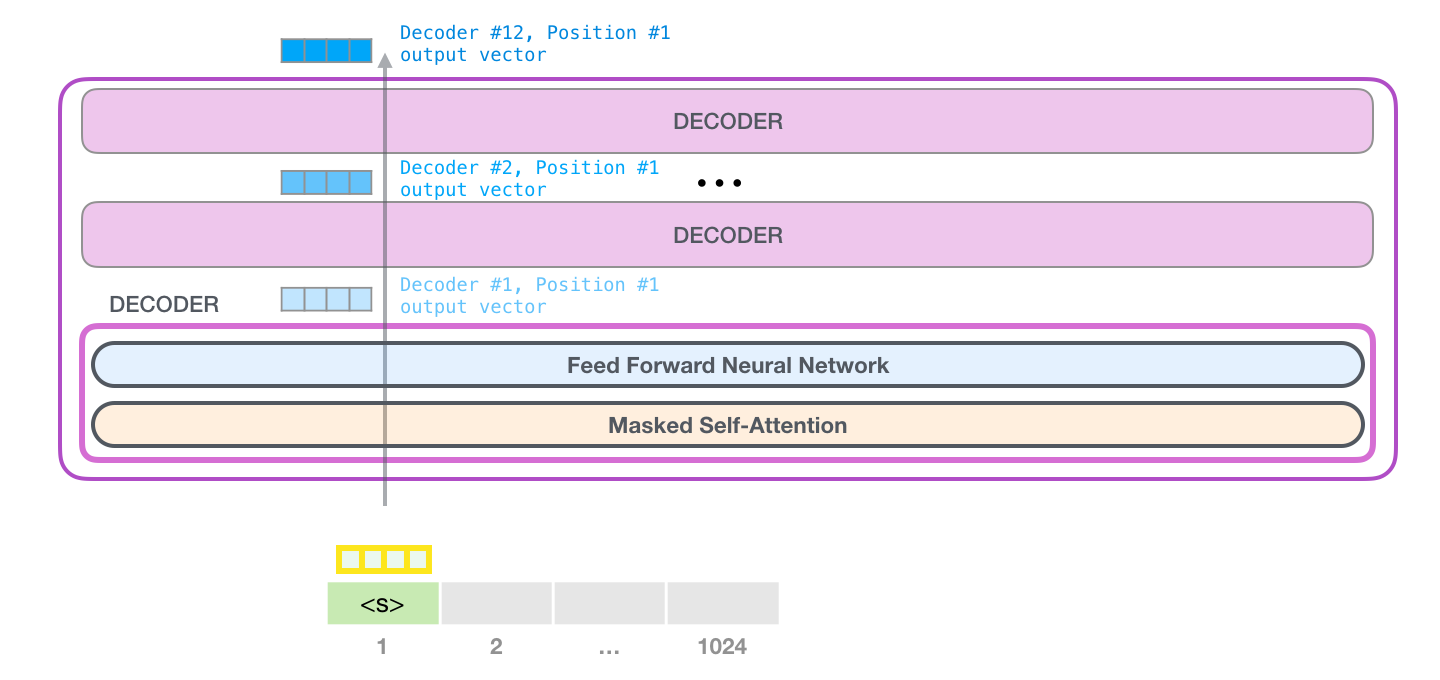
进入第一层 block 后,token 向量会先经过 masked self-attention,再经过前馈网络。然后输出向量进入下一层,重复同样流程。
每一层结构看起来相似,但每一层有自己的权重。也就是说,第 1 层和第 10 层不是同一套参数反复使用,而是不同层各自学习不同加工方式。
可以写成:
h t ( 0 ) = E token i d t + E pos t h_t^{(0)}=E_{\text{token}}id_t+E_{\text{pos}}t ht(0)=Etokenidt+Epost
h t ( l + 1 ) = T r a n s f o r m e r B l o c k ( l ) ( h ≤ t ( l ) ) h_t^{(l+1)}=\mathrm{TransformerBlock}^{(l)}(h_{\le t}^{(l)}) ht(l+1)=TransformerBlock(l)(h≤t(l))
注意 h ≤ t h_{\le t} h≤t 表示当前位置只能利用自己和左边位置的信息。这个限制就是 masked self-attention 保证的。
14. 自注意力为什么能处理上下文
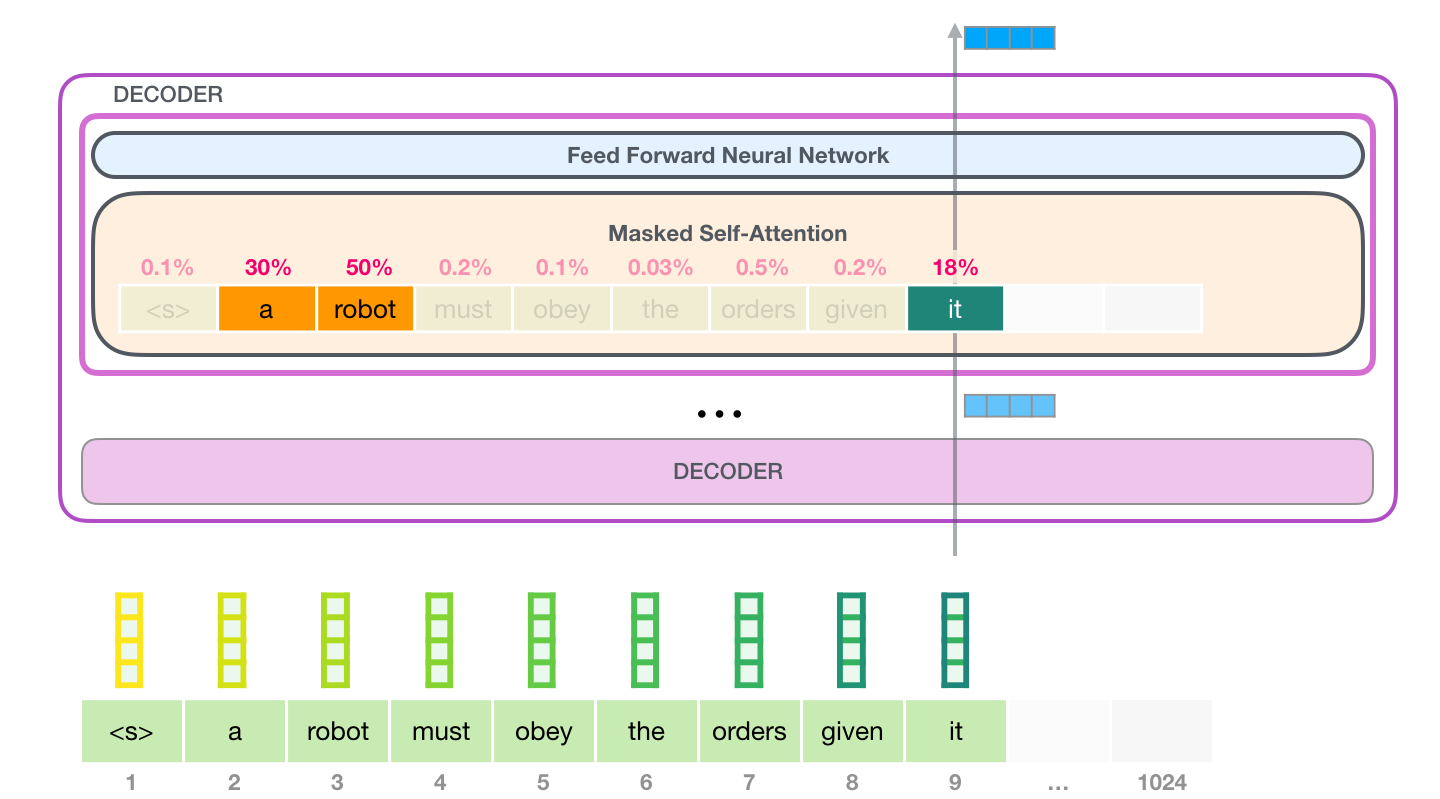
语言里很多词必须靠上下文才能理解。例如 it 指谁?such orders 指什么?the First Law 指哪段内容?人读句子时会自动回看前文,模型也需要类似能力。
自注意力做的事情就是:当处理某个 token 时,给前面每个 token 分配一个相关性权重,再把这些 token 的信息按权重混合进来。
假设处理 it 时,模型学到:
text
a 0.30
robot 0.50
it 0.20那么 it 的新表示就会更偏向 robot 的信息。用公式写就是:
z it = 0.30 v a + 0.50 v robot + 0.20 v it z_{\text{it}}=0.30v_{\text{a}}+0.50v_{\text{robot}}+0.20v_{\text{it}} zit=0.30va+0.50vrobot+0.20vit
这里的 v v v 是 value 向量。注意力权重决定"参考谁更多",value 向量提供"真正带过来的内容"。
15. Q、K、V:查询、标签和内容
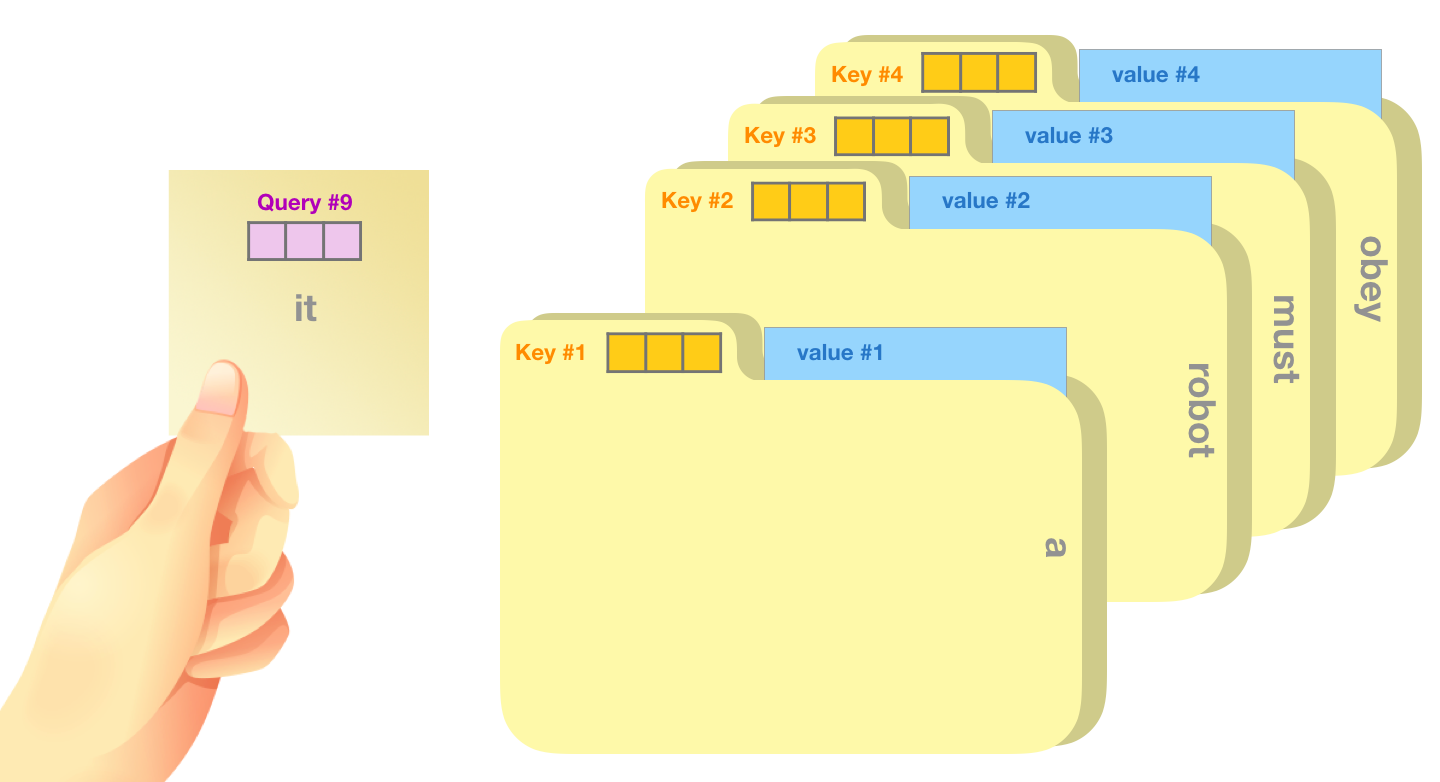
Q、K、V 可以用文件柜来理解。Query 像你手里的问题纸条:我现在想找什么信息?Key 像文件夹标签:这个文件夹大概是什么主题?Value 像文件夹里的真实内容:如果决定参考这个文件夹,真正拿走的资料是什么?
对于每个 token,模型会从同一个输入向量生成三种向量:
q = x W Q q=xW_Q q=xWQ
k = x W K k=xW_K k=xWK
v = x W V v=xW_V v=xWV
为什么不直接用原始词向量互相匹配?因为"用来判断关系的特征"和"要传递的信息"不一定一样。判断 it 指谁时,Query 和 Key 可能更关注指代线索;真正传递给 it 的 Value 可能包括名词语义、单复数、角色、状态等信息。把 Q、K、V 分开,模型就能学出更灵活的表示。
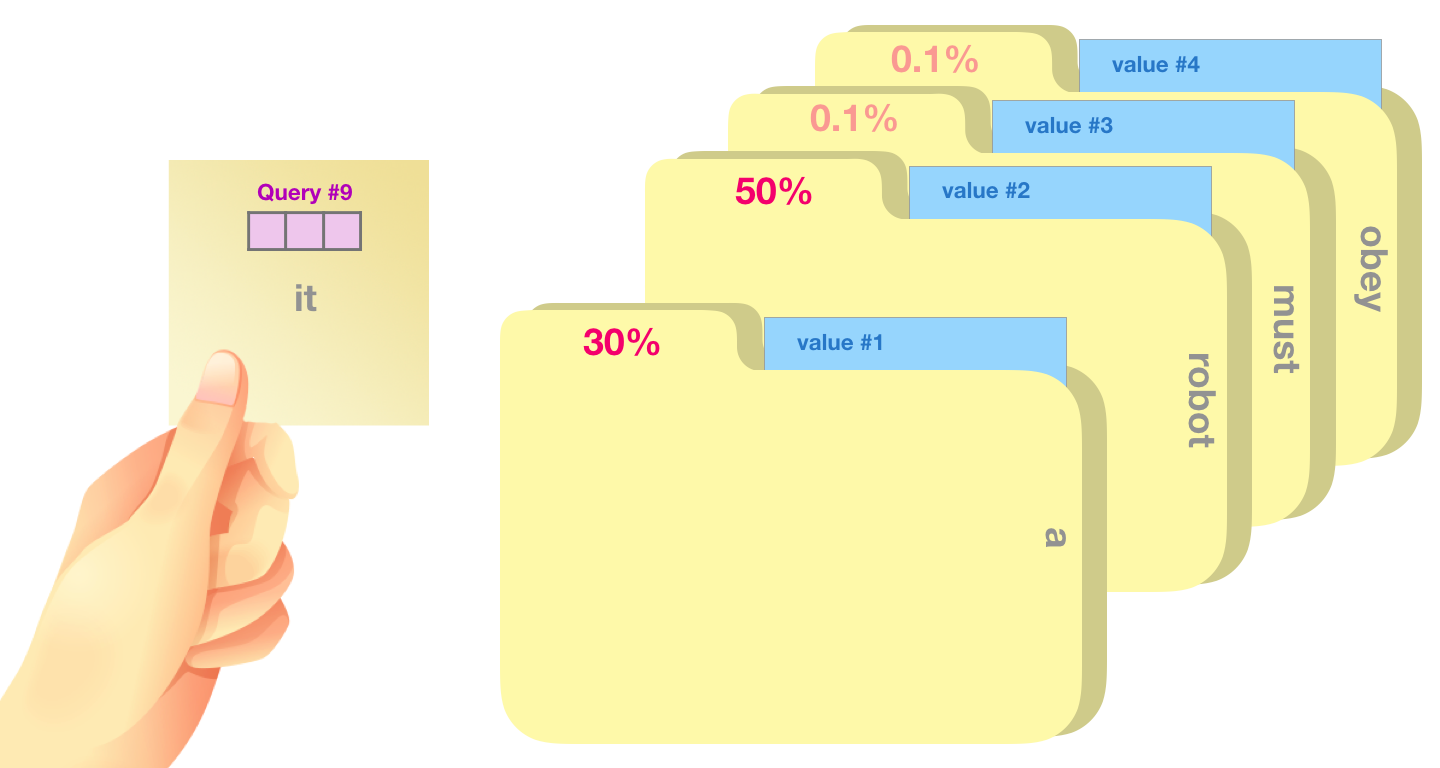
Query 和 Key 的点积会产生相关性分数。两个向量方向越接近,点积越大,说明当前 token 更应该关注那个 token。
一个小例子:
q it = 1 , 2 q_{\text{it}}=1,\\ 2 qit=1, 2
k robot = 2 , 1 k_{\text{robot}}=2,\\ 1 krobot=2, 1
点积是:
q it ⋅ k robot = 1 × 2 + 2 × 1 = 4 q_{\text{it}}\cdot k_{\text{robot}}=1\times 2+2\times 1=4 qit⋅krobot=1×2+2×1=4
如果另一个 key 是:
k law = − 1 , 0 k_{\text{law}}=-1,\\ 0 klaw=−1, 0
那么:
q it ⋅ k law = 1 × ( − 1 ) + 2 × 0 = − 1 q_{\text{it}}\cdot k_{\text{law}}=1\times (-1)+2\times 0=-1 qit⋅klaw=1×(−1)+2×0=−1
经过 softmax 后,robot 会得到更高注意力权重。
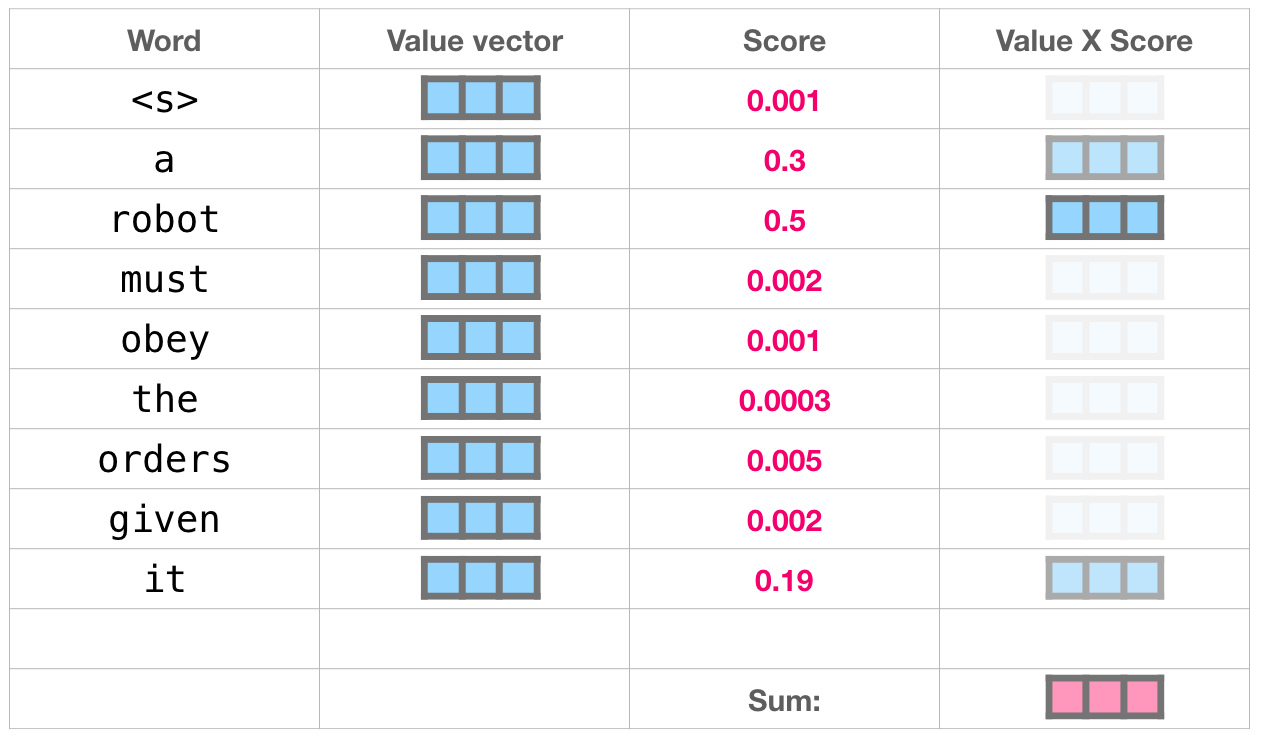
打分不是终点。真正输出的是 Value 的加权和:
A t t e n t i o n ( q , K , V ) = ∑ i α i v i \mathrm{Attention}(q,K,V)=\sum_i \alpha_i v_i Attention(q,K,V)=i∑αivi
其中 α i \alpha_i αi 是 softmax 后的注意力权重。权重大,那个 token 的 value 就贡献多;权重小,贡献就少。
16. 从隐藏向量到词表分数
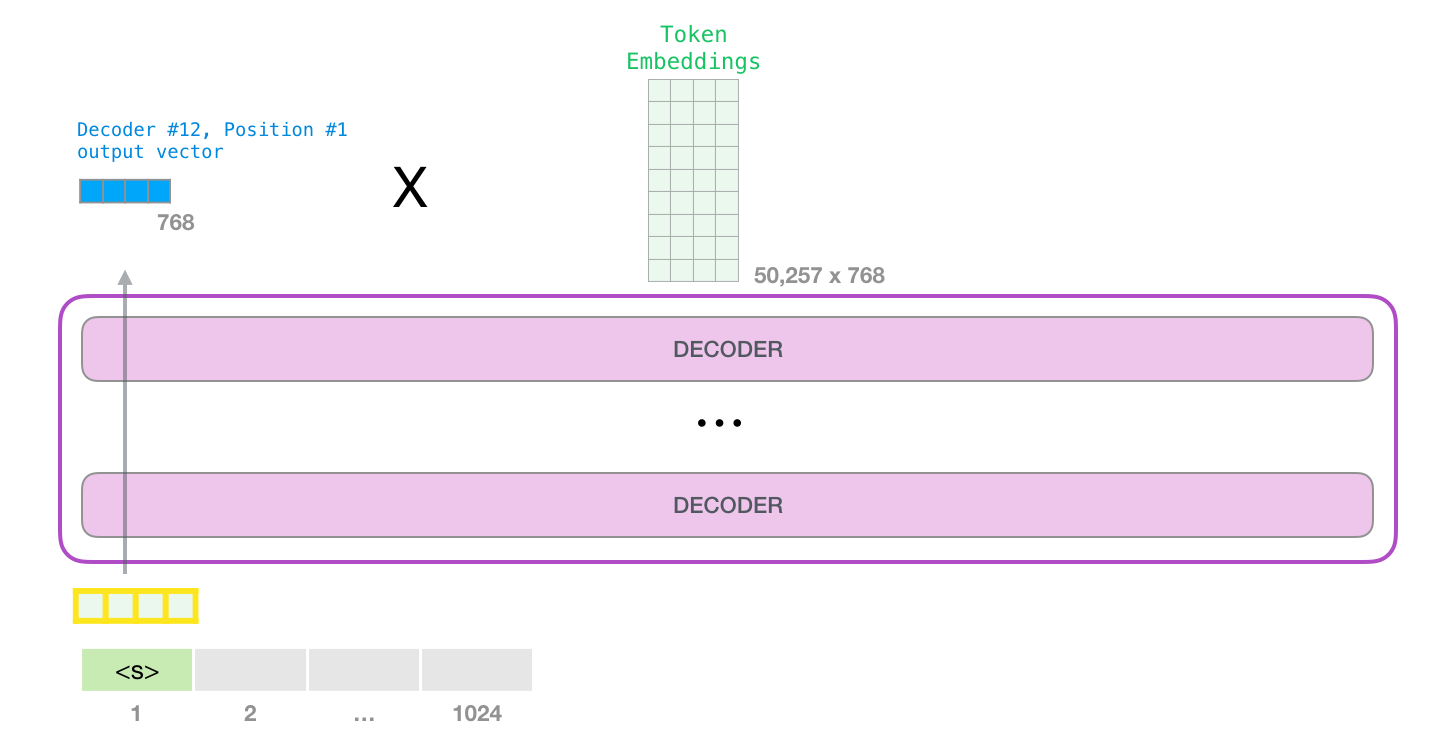
最顶层 block 输出一个隐藏向量后,模型还不能直接把它当成文字。它要把这个向量映射到整个词表,每个 token 得到一个分数。
如果隐藏向量长度是 768,词表大小是 50257,那么输出分数就是 50257 个数字。每个数字对应一个 token。这个分数通常叫 logits。
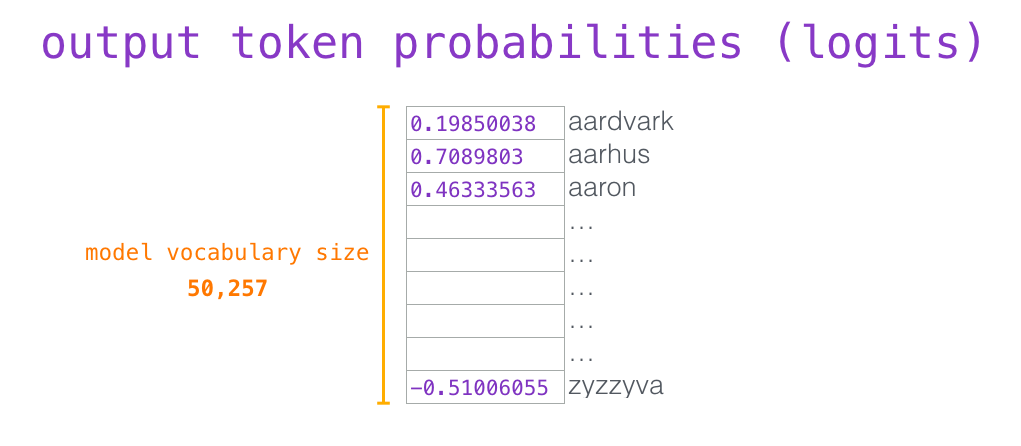
logits 还不是概率。它们可以是任意实数,比如:
text
the: 5.1
robot: 3.8
apple: -1.2
...softmax 会把这些分数转成概率:
P i = e z i ∑ j e z j P_i=\frac{e^{z_i}}{\sum_j e^{z_j}} Pi=∑jezjezi
分数越高,概率越高。所有 token 的概率加起来等于 1。
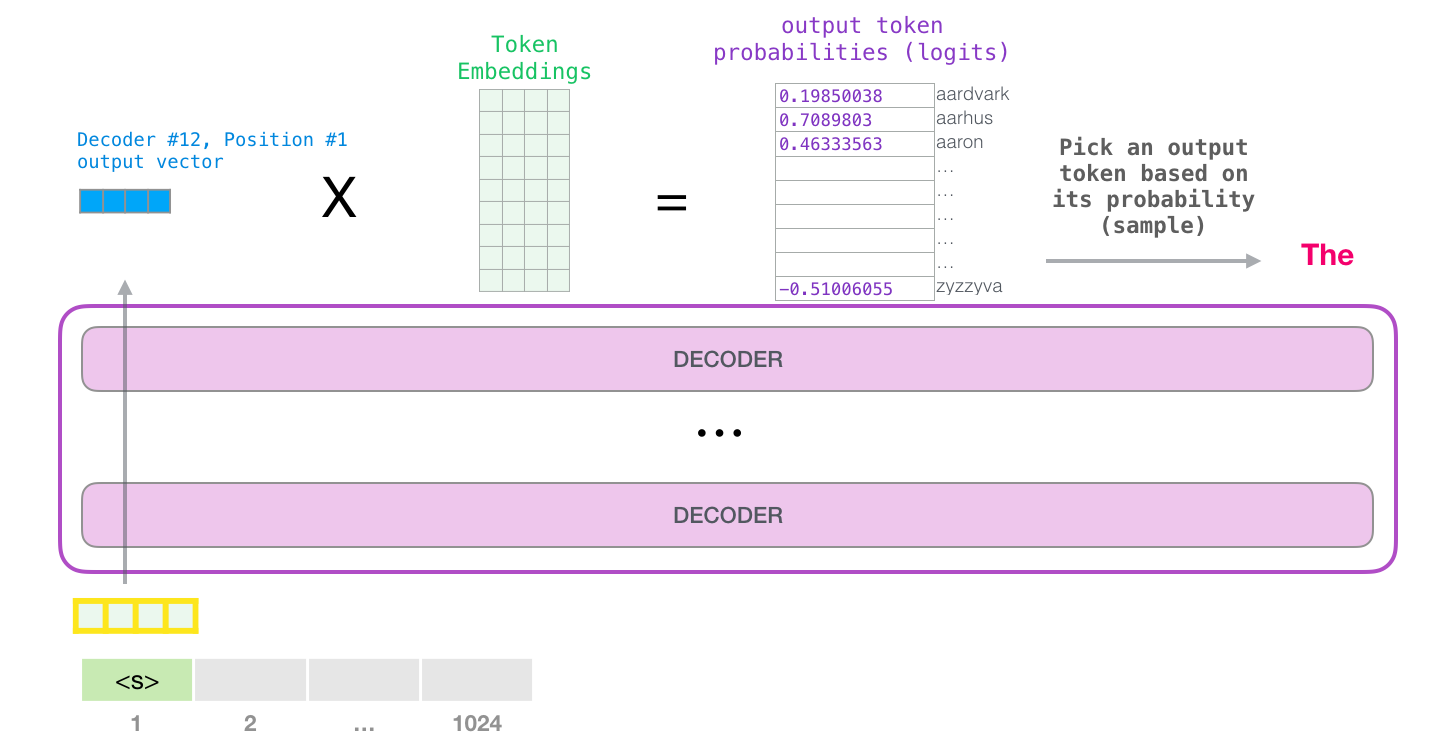
选择下一个 token 有多种方式。最简单的是贪心选择:
arg max i P i \arg\max_i P_i argimaxPi
也就是选概率最大的 token。原文还提到 top-k,例如 top-k=40 表示只从概率最高的 40 个候选里抽样。这样既不会完全死板,也不会从几乎不可能的词里乱选。
17. 原文的几个简化点
原文为了讲清直觉,做了一些简化。阅读时要记住这些简化,不然容易把图当成真实代码形状。
第一,原文常把 word 和 token 混着说,但 GPT-2 真正处理的是 token,不是人眼看到的"单词"。token 可以是一个完整单词,也可以是单词片段、标点、空格加单词、甚至某些字节片段。
比如一句话:
text
I love machine learning.人会觉得它有 5 个词加 1 个句号,但 tokenizer 可能把它变成类似这样的 token:
text
I
love
machine
learning
.注意有些 token 前面带空格,比如 love。这是因为 GPT-2 的分词方式会把空格也纳入 token 的模式里。再比如一个长词:
text
unbelievable它不一定作为一个完整 token 存在,可能被拆成:
text
un
believable也可能拆成别的片段,具体取决于 GPT-2 的 BPE 词表。真正进入模型的不是字符串本身,而是一串 token 编号:
text
[40, 1842, 4572, 4673, 13]这些数字只是示意,不是上面句子的真实 GPT-2 编号。关键是理解:模型看到的是编号,再通过 embedding 表把编号查成向量。
第二,原文为了展示生成,会把 GPT-2 画成"一次处理一个 token"。这个画法适合解释推理,也就是模型真的在写文章时的过程;但训练时通常不是这样慢慢一个 token 一个 token 喂进去。
推理时像这样:
text
输入:The
预测: robot
输入:The robot
预测: must
输入:The robot must
预测: obey训练时更像一次把整段切片送进去:
text
输入 token: [The, robot, must, obey]
目标 token: [robot, must, obey, orders]模型会同时在多个位置做预测:
text
位置 1:看到 The -> 预测 robot
位置 2:看到 The robot -> 预测 must
位置 3:看到 The robot must -> 预测 obey
位置 4:看到 The robot must obey -> 预测 orders为什么能同时算?因为 masked self-attention 会遮住未来。第 2 个位置虽然和第 3、4 个位置一起被放进模型,但 mask 会让第 2 个位置看不到后面的 must 和 obey。这就是"训练并行,生成串行"。
第三,图里的向量经常被画成小方块、小条形或箭头,但真实代码里要严格区分维度。比如 GPT-2 small 常见配置是:
text
batch size B = 2
序列长度 T = 5
隐藏维度 C = 768
注意力头数 H = 12
每个头维度 D = 64那么输入到某一层 Transformer block 的张量形状通常是:
X ∈ R B × T × C X\in \mathbb{R}^{B\times T\times C} X∈RB×T×C
代入数字就是:
X ∈ R 2 × 5 × 768 X\in \mathbb{R}^{2\times 5\times 768} X∈R2×5×768
这里的含义是:一次喂 2 句,每句 5 个 token,每个 token 用 768 个数字表示。图里画一个 token 向量时,通常只是在画其中一小段,真实向量可能有 768 个数字。
第四,原文常把 Q、K、V 画成"分别生成三个向量",这在概念上完全正确,但代码实现里经常会一次性生成。也就是说,代码不会总是写成:
Q = X W Q , K = X W K , V = X W V Q=XW_Q,\quad K=XW_K,\quad V=XW_V Q=XWQ,K=XWK,V=XWV
而可能写成:
Q , K , V = X W Q K V Q,K,V=XW_{QKV} Q,K,V=XWQKV
这个 W Q K V W_{QKV} WQKV 是一个更宽的大矩阵。算完之后再把结果切成三份。概念上仍然是 Q、K、V 三套东西,只是实现时为了效率合并计算。
继续用形状看会更清楚。假设:
X ∈ R B × T × 768 X\in \mathbb{R}^{B\times T\times 768} X∈RB×T×768
一次性线性变换后得到:
X W Q K V ∈ R B × T × 2304 XW_{QKV}\in \mathbb{R}^{B\times T\times 2304} XWQKV∈RB×T×2304
因为:
2304 = 3 × 768 2304=3\times 768 2304=3×768
再切成:
Q , K , V ∈ R B × T × 768 Q,K,V\in \mathbb{R}^{B\times T\times 768} Q,K,V∈RB×T×768
然后再按 12 个头拆开:
Q , K , V ∈ R B × H × T × D Q,K,V\in \mathbb{R}^{B\times H\times T\times D} Q,K,V∈RB×H×T×D
代入数字:
Q , K , V ∈ R 2 × 12 × 5 × 64 Q,K,V\in \mathbb{R}^{2\times 12\times 5\times 64} Q,K,V∈R2×12×5×64
这就是为什么看图时觉得"一个 token 一根向量",看代码时却看到一堆 view、reshape、transpose。它们不是在改变模型思想,只是在把同一批数字整理成适合矩阵乘法的形状。
第五,原文为了好懂,会把最后输出画成"模型选中一个词"。真实流程更细:模型先输出整个词表的 logits,再经过 softmax 或采样策略选 token。
假设词表只有 5 个 token,模型输出 logits:
text
the: 4.2
robot: 2.1
must: 1.7
apple: -0.8
.: -1.5softmax 后可能变成:
text
the: 0.82
robot: 0.10
must: 0.07
apple: 0.01
.: 0.00如果用贪心解码,就选 the。如果用采样,就可能按概率从候选里抽一个。为了避免抽到特别离谱的低概率 token,常见方法有 top-k 和 top-p。
top-k=3 的意思是:只保留概率最高的 3 个候选:
text
the
robot
must再在这 3 个里面抽样。这样生成不会完全死板,也不会从很低概率的垃圾候选里乱跳。
第六,原文会说 GPT-2 能看 1024 个 token,但这不等于 1024 个中文词或英文单词。因为 token 和 word 不是一回事,1024 token 可能对应更少的英文单词,也可能对应更多的字符片段。
比如:
text
I like cats.可能只需要很少几个 token。但如果文本里有生僻词、代码、URL、混合语言,token 数会涨得很快:
text
https://example.com/some/very/long/path?id=123这种字符串可能被切成很多 token。对 GPT-2 来说,超过上下文窗口的内容不能无限保留。如果前文太长,最老的 token 通常会被截掉,只保留最近的一段上下文。
第七,原文重点画注意力,所以经常省略残差连接、LayerNorm 和 Dropout。真实 GPT-2 block 不是只有:
text
Attention -> MLP更接近:
x = x + A t t e n t i o n ( L a y e r N o r m ( x ) ) x=x+\mathrm{Attention}(\mathrm{LayerNorm}(x)) x=x+Attention(LayerNorm(x))
x = x + M L P ( L a y e r N o r m ( x ) ) x=x+\mathrm{MLP}(\mathrm{LayerNorm}(x)) x=x+MLP(LayerNorm(x))
残差连接的意思是:不要把旧信息直接覆盖掉,而是在原来的 x x x 上加一个新变化量。就像改作文,不是把整篇撕掉重写,而是在原文基础上修改润色。
LayerNorm 的意思是:先把一组数字整理到比较稳定的范围,再送去注意力或 MLP。训练深层网络时,如果每层输出的数值忽大忽小,后面层会很难学。归一化像是在每个环节前先把音量调到合适范围。
Dropout 主要用于训练阶段。它会随机让一部分神经元输出暂时失效,逼模型不要过度依赖某几个固定通道。比如一个学生做题时不能只背一道模板题,Dropout 像是故意把某些提示遮住,让模型学得更稳。推理生成时通常会关闭 Dropout。
第八,原文为了直观,经常把推理画成"把所有历史 token 重新送进模型"。概念上可以这么理解,但高效实现会用 KV cache。因为历史 token 的 Key 和 Value 一旦算好,后续步骤可以复用。
假设已经生成:
text
The robot must下一步要预测 obey。如果没有 cache,模型可能重新为 The、robot、must 全部计算 Q、K、V。有了 KV cache 后,历史的 K 和 V 已经存着,只需要为最新 token 计算新的 K、V,并把它们追加到缓存。
要注意,cache 缓存的不是最终生成文字,也不是"模型记忆了一整篇文章的意思",而是每一层、每一个头里的 Key 和 Value 张量。它是一种计算加速技巧,不会改变 GPT-2 的数学目标。
把这些简化点放在一起看,原文的图解决的是"先理解模型在做什么",真实代码解决的是"怎样高效、稳定地把这件事算出来"。读图时先抓住直觉,读源码时再把 token、张量形状、mask、残差、归一化、采样和 cache 一层层补回来。
18. 自注意力完整流程总览

自注意力可以分成三大步:
- 为每个 token 生成 Q、K、V。
- 用当前 token 的 Q 和所有可见 token 的 K 打分。
- 用分数加权求和所有可见 token 的 V。
用矩阵公式写就是:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QK⊤)V
GPT-2 需要加上遮罩:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ + M d k ) V \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top+M}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QK⊤+M)V
M M M 是 mask 矩阵。允许看的地方加 0,不允许看的未来位置加一个很大的负数,softmax 后概率接近 0。
19. 不加遮罩的普通自注意力
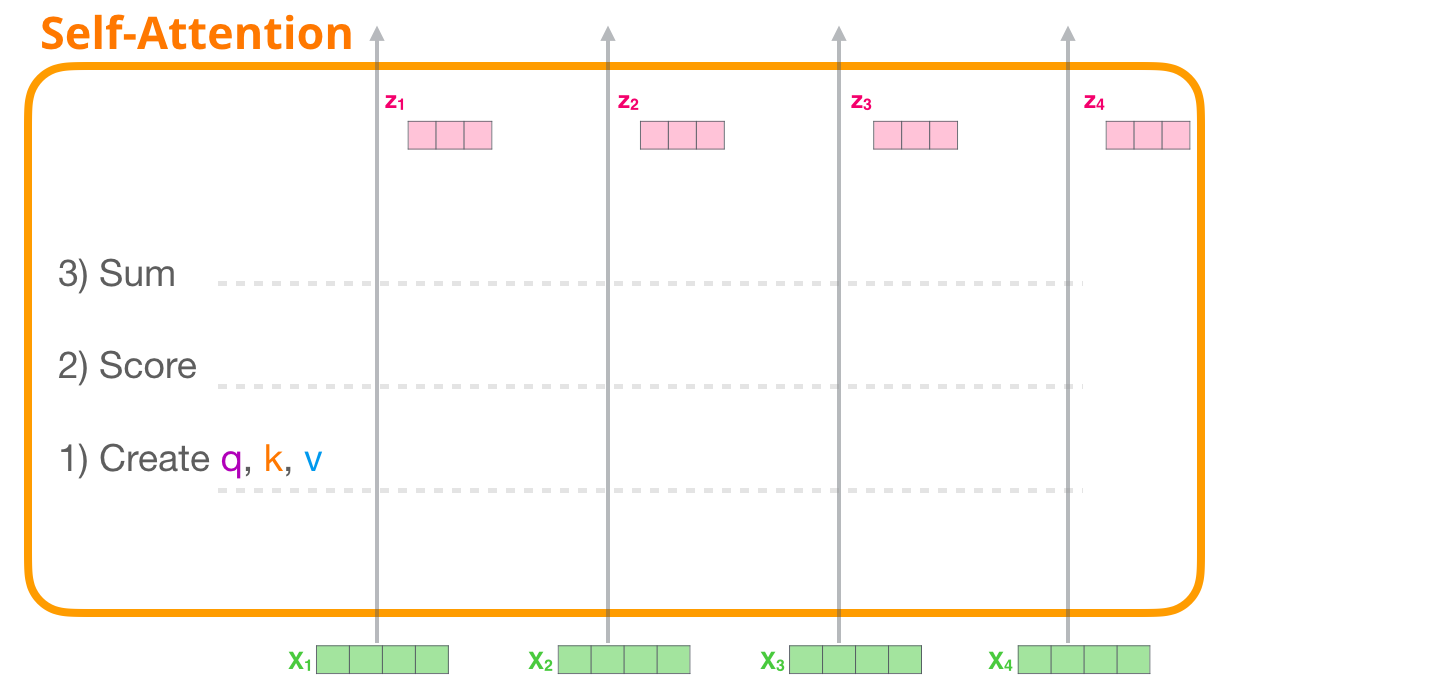
这张图是在概括普通自注意力的三步:先给每个词准备 Q、K、V,再用 Q 和 K 计算"谁该关注谁",最后按关注程度把 V 混合起来。图里没有遮罩,所以每个位置都能看所有位置,包括左边和右边。
普通自注意力常见于编码器。它适合"理解完整输入"的场景,因为完整句子已经摆在模型面前,不需要假装未来不存在。比如处理一句:
text
The animal didn't cross the street because it was too tired如果模型正在理解 it,它可以同时看左边的 animal,也可以看右边的 tired。右边的信息能帮助它判断 it 的语法角色和语义关系。编码器的目标是读懂完整句子,所以这种双向查看是合理的。
把图里的三步用更白话的方式说:
text
Q:我现在想找什么信息?
K:我这里有什么线索,别人要不要关注我?
V:如果别人关注我,我真正提供什么内容?注意力不是简单地"某个词找某个词",而是每个词都对句子里的所有词做一次打分,然后把有用信息混合回来。
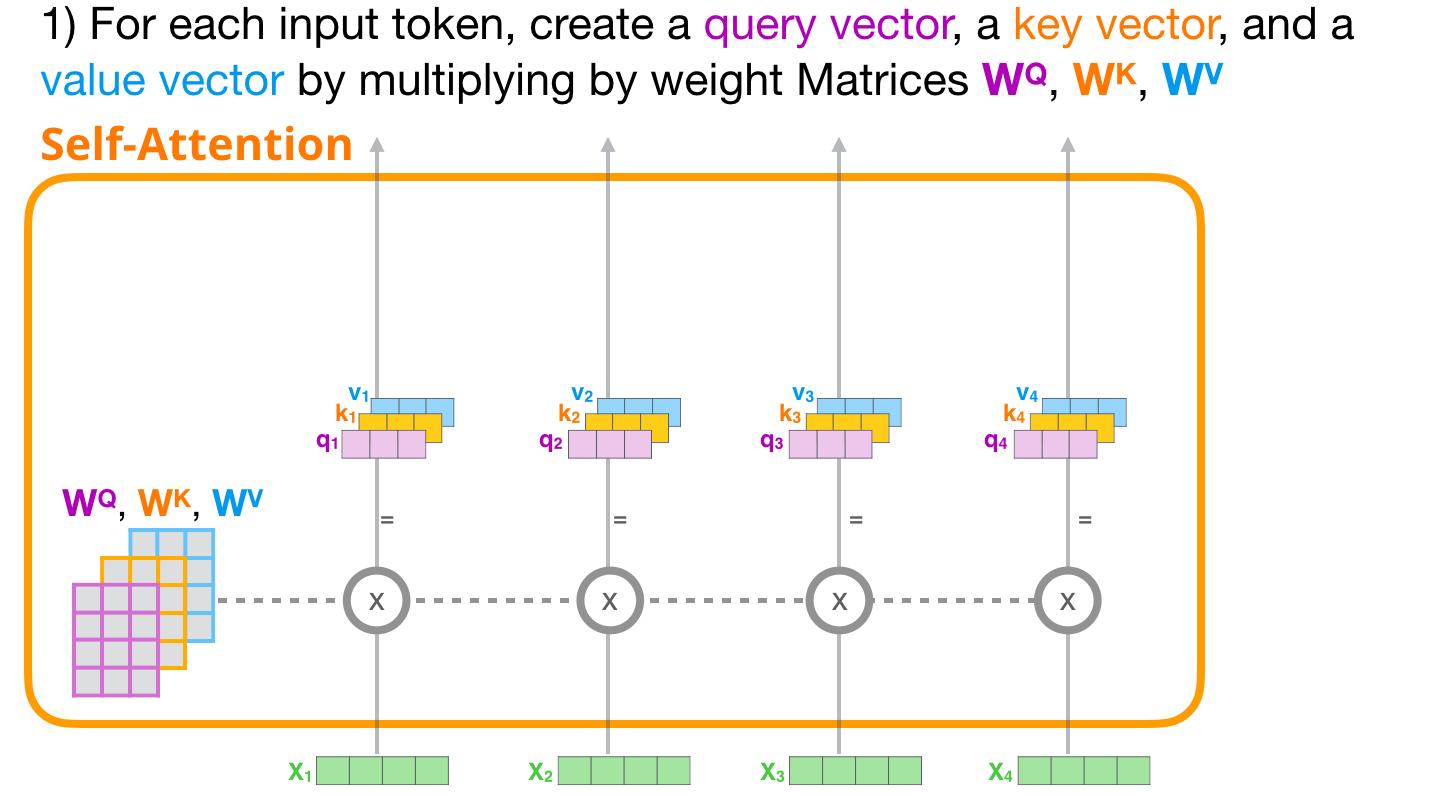
这张图展示第一步:同一个 token 向量会被投影成 Query、Key、Value 三个向量。图里看起来像一个词突然分裂成三份,其实是同一串数字分别乘上三组不同的权重矩阵。
假设 robot 的输入向量是:
x robot = 0.2 , − 0.4 , 0.7 x_{\text{robot}}=0.2,\\ -0.4,\\ 0.7 xrobot=0.2, −0.4, 0.7
模型会用三组训练出来的矩阵把它变成:
q robot = x robot W Q q_{\text{robot}}=x_{\text{robot}}W_Q qrobot=xrobotWQ
k robot = x robot W K k_{\text{robot}}=x_{\text{robot}}W_K krobot=xrobotWK
v robot = x robot W V v_{\text{robot}}=x_{\text{robot}}W_V vrobot=xrobotWV
这三个向量来自同一个词,但用途不同。Query 用来主动寻找信息,Key 用来被别人匹配,Value 用来真正贡献内容。
一个生活类比:同一个人参加会议时,可以有三种身份。
text
Query:我现在有一个问题,想找谁回答?
Key:我的名牌写着我的专长,别人可以根据名牌找我。
Value:如果别人真的来问我,我能提供的实际答案。如果输入矩阵是:
X ∈ R T × d m o d e l X\in \mathbb{R}^{T\times d_{model}} X∈RT×dmodel
那么:
Q = X W Q , K = X W K , V = X W V Q=XW_Q,\quad K=XW_K,\quad V=XW_V Q=XWQ,K=XWK,V=XWV
其中 T T T 是 token 个数, d m o d e l d_{model} dmodel 是每个 token 的隐藏维度。
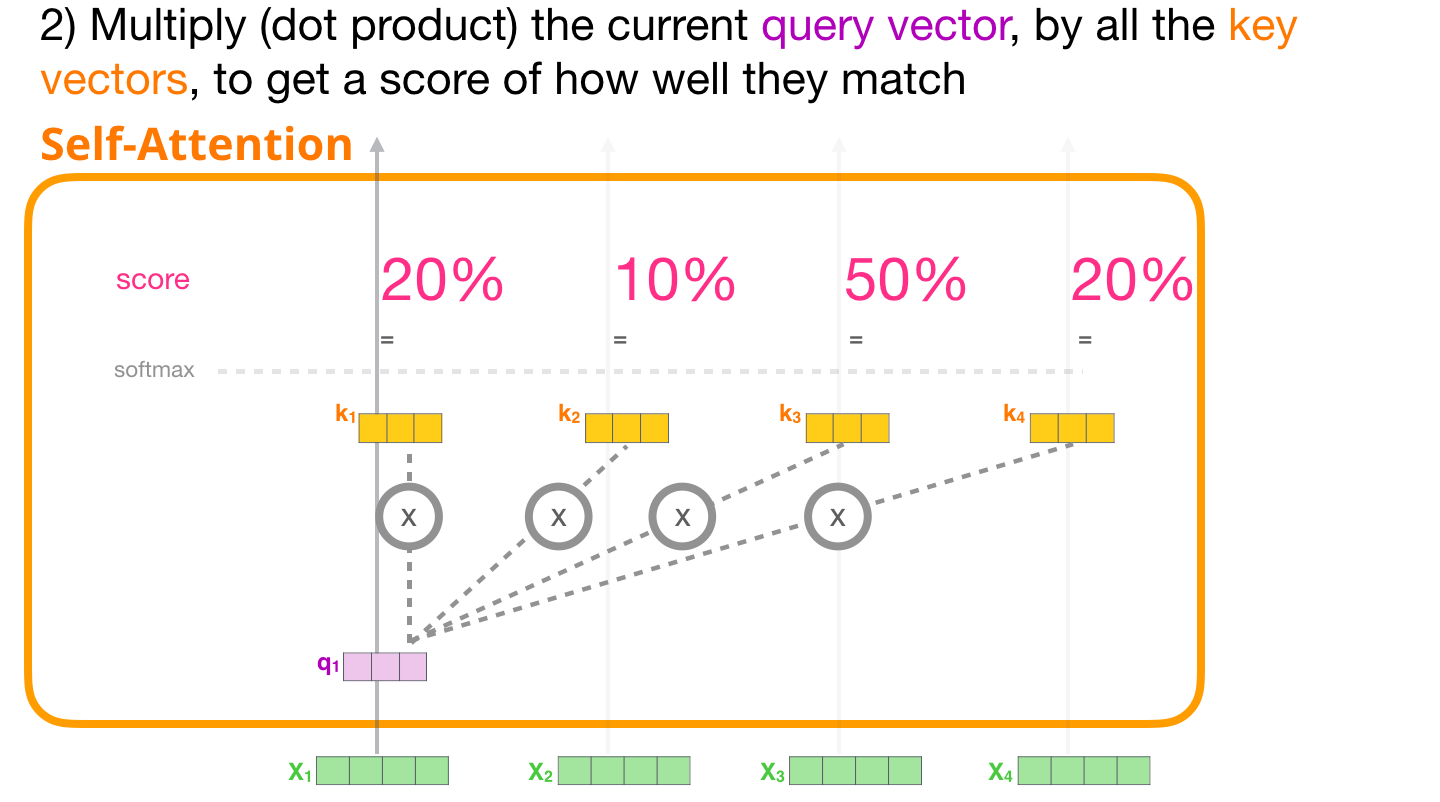
这张图展示第二步:拿当前 token 的 Query,去和所有 token 的 Key 逐个打分。图里箭头从一个 Query 指向很多 Key,意思是"当前这个位置正在问:句子里哪些位置对我最有用?"
比如处理 it 时,它的 Query 可能在找"我指代谁"。句子里的 animal、street、tired 都有自己的 Key。训练之后,如果 animal 的 Key 和 it 的 Query 更匹配,那么 it 就会更关注 animal。
对于第 i i i 个 token,它的 Query 会和每个 token 的 Key 做点积:
s i j = q i ⋅ k j s_{ij}=q_i\cdot k_j sij=qi⋅kj
s i j s_{ij} sij 越大,表示第 i i i 个 token 越应该关注第 j j j 个 token。
点积可以理解为两个向量方向是否相近。方向相近,结果大;方向相反,结果小。举一个二维例子:
q it = 1 , 2 q_{\text{it}}=1,\\ 2 qit=1, 2
k animal = 2 , 1 k_{\text{animal}}=2,\\ 1 kanimal=2, 1
点积是:
1 × 2 + 2 × 1 = 4 1\times 2+2\times 1=4 1×2+2×1=4
如果另一个词的 Key 是:
k street = − 1 , 0 k_{\text{street}}=-1,\\ 0 kstreet=−1, 0
点积是:
1 × ( − 1 ) + 2 × 0 = − 1 1\times (-1)+2\times 0=-1 1×(−1)+2×0=−1
那么在这个简单例子里,it 更应该关注 animal,不太应该关注 street。真实模型里的向量维度更高,比如 64 维、768 维,但思想一样。
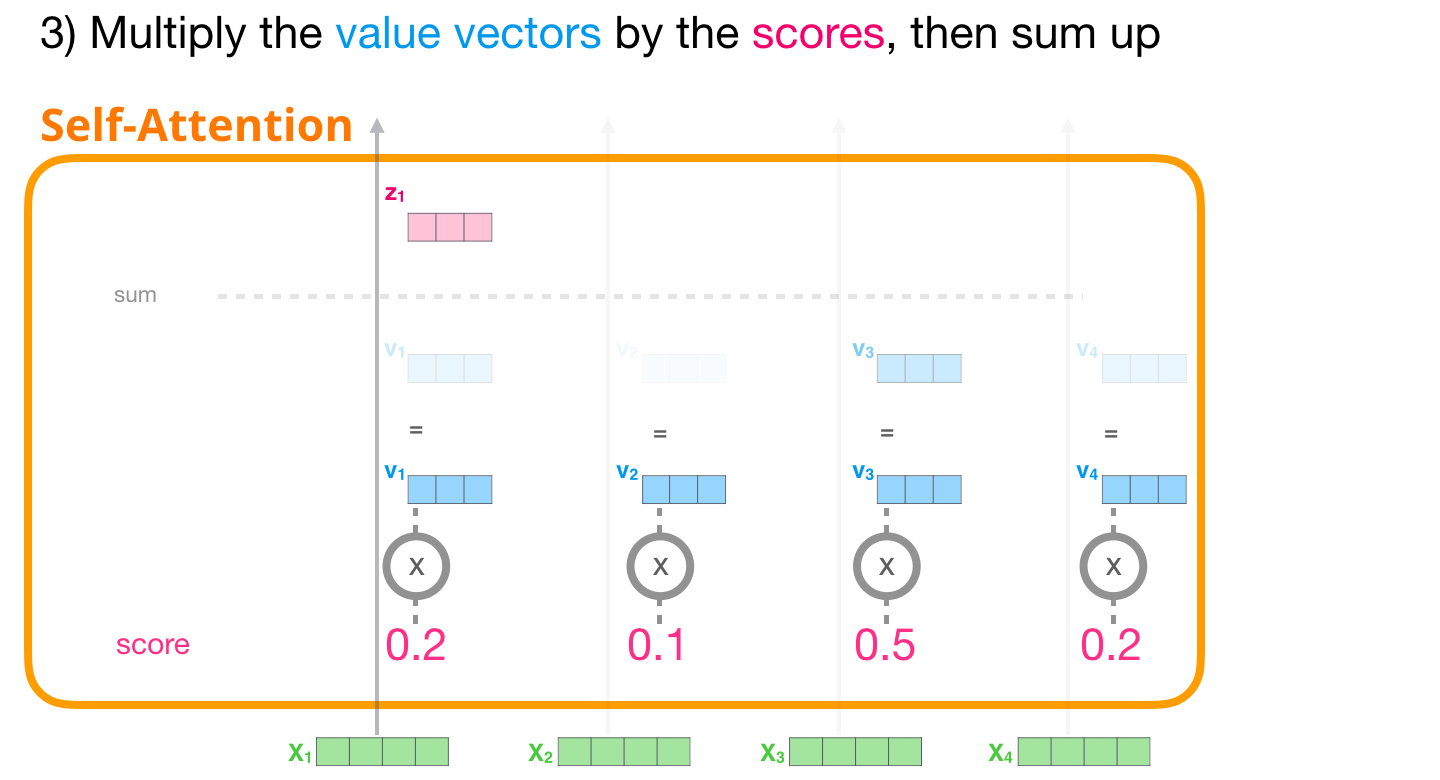
这张图展示第三步:分数经过 softmax 变成权重,然后用这些权重去混合 Value。图里不是把某一个 Value 原封不动拿走,而是把多个 Value 按比例加起来。
假设 it 对三个词的注意力权重是:
text
animal: 0.70
street: 0.10
it: 0.20那么 it 的新向量就是:
z it = 0.70 v animal + 0.10 v street + 0.20 v it z_{\text{it}}=0.70v_{\text{animal}}+0.10v_{\text{street}}+0.20v_{\text{it}} zit=0.70vanimal+0.10vstreet+0.20vit
这样一来,it 自己的位置向量里就混入了 animal 的信息。模型后面的层再看到 it 时,就不只是看到一个孤零零的代词,而是看到一个已经带着上下文线索的表示。
数学上,第三步是把分数变成权重,再对 Value 求加权和:
α i j = e s i j ∑ m e s i m \alpha_{ij}=\frac{e^{s_{ij}}}{\sum_m e^{s_{im}}} αij=∑mesimesij
z i = ∑ j α i j v j z_i=\sum_j \alpha_{ij}v_j zi=j∑αijvj
这就是自注意力输出。它不是复制某个词,而是把多个相关词的信息按比例混合。普通自注意力的"普通"主要指没有未来遮罩,所以它更适合完整理解,不适合从左到右生成。
20. 遮罩自注意力:不能偷看未来
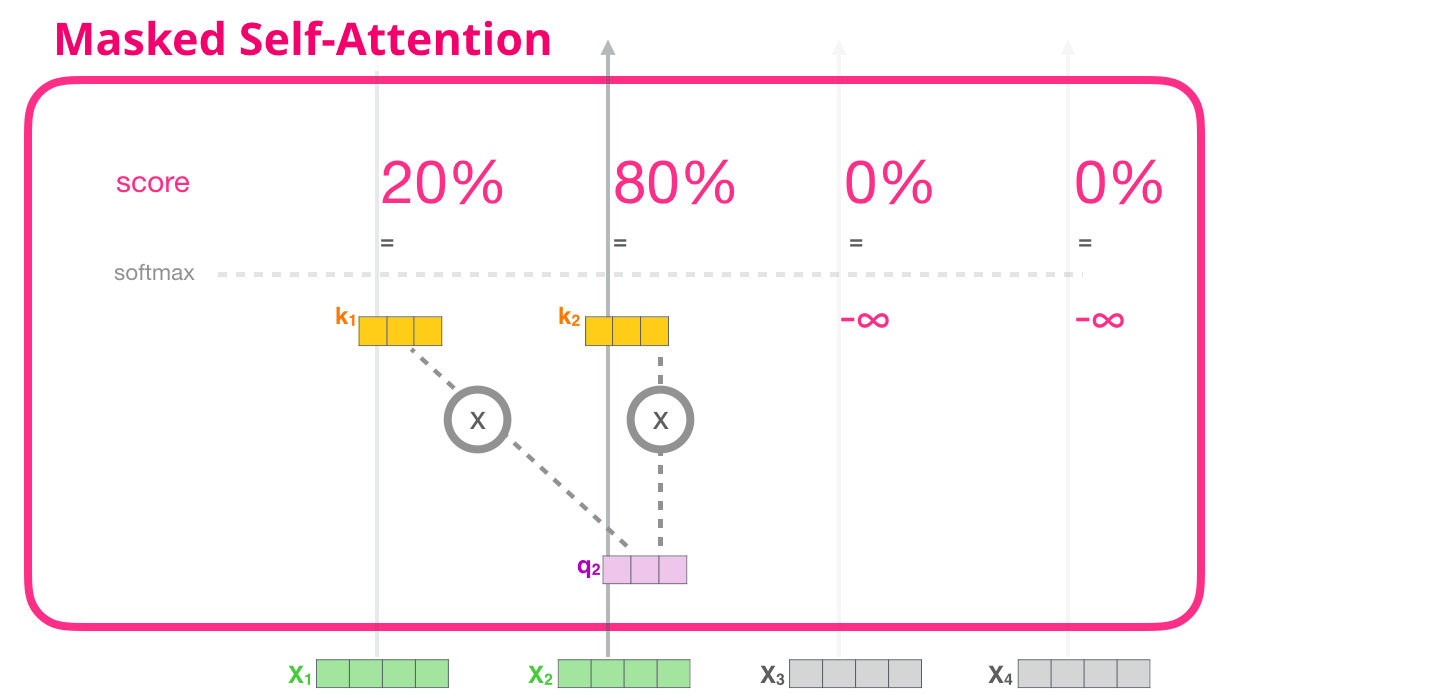
这张图的重点是:右上角那些未来位置被挡住了。普通自注意力像全员互相交流,遮罩自注意力像排队写答案,每个人只能看自己和前面的人,不能看后面人的答案。
GPT-2 的核心是 masked self-attention。假设序列是:
text
robot must obey orders处理 must 时只能看:
text
robot must不能看:
text
obey orders因为生成时未来 token 还不存在。训练时如果让它看到未来,就相当于考试时把答案写在题目后面,模型学到的是作弊方式,不是真正根据前文预测。
这张图可以按行来读:
text
第 1 个位置:只能看第 1 个 token
第 2 个位置:能看第 1、2 个 token
第 3 个位置:能看第 1、2、3 个 token
第 4 个位置:能看第 1、2、3、4 个 token越往后的 token,能看的历史越长;但任何位置都不能看自己右边的未来 token。

这张图是在解释训练时为什么可以并行。它把一整段文本变成很多道"根据前文预测下一个 token"的题。每个位置都在做自己的预测任务,但 mask 保证它只能用允许看的前文。
例如训练序列是:
text
The robot must obey orders模型输入可以是:
text
The robot must obey目标答案是整体左移一位后的:
text
robot must obey orders于是同一批计算里同时包含多道题:
text
看到 The -> 预测 robot
看到 The robot -> 预测 must
看到 The robot must -> 预测 obey
看到 The robot must obey -> 预测 orders这就是语言模型训练的核心。它没有单独标注"主语""宾语""语法规则",训练信号只是不断告诉模型:在这个上下文后面,真实文本的下一个 token 是什么。
这个并行训练非常重要。虽然生成时要一步一步来,但训练时可以把很多位置一起算,大幅提升效率。mask 的作用就是让并行训练看起来像严格的从左到右预测。
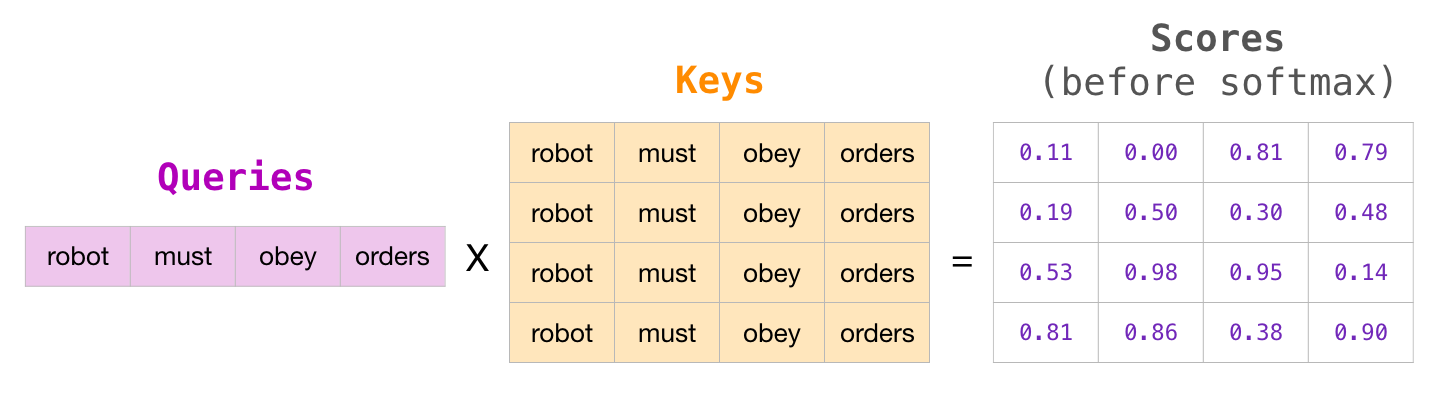
这张图把"不能看未来"落到了矩阵上。矩阵形式下, Q K ⊤ QK^\top QK⊤ 会得到一个 T × T T\times T T×T 的分数表。第 i i i 行表示第 i i i 个位置看所有位置的分数,第 j j j 列表示它正在看第 j j j 个位置。
例如 T = 4 T=4 T=4:
Q K ⊤ = s 11 s 12 s 13 s 14 s 21 s 22 s 23 s 24 s 31 s 32 s 33 s 34 s 41 s 42 s 43 s 44 QK^\top= \begin{bmatrix} s_{11} & s_{12} & s_{13} & s_{14}\\ s_{21} & s_{22} & s_{23} & s_{24}\\ s_{31} & s_{32} & s_{33} & s_{34}\\ s_{41} & s_{42} & s_{43} & s_{44} \end{bmatrix} QK⊤= s11s21s31s41s12s22s32s42s13s23s33s43s14s24s34s44
对于 GPT-2,第 2 行不能看第 3、4 列,第 3 行不能看第 4 列。所以未来位置会被 mask 掉。
用更具体的表格看:
text
看1 看2 看3 看4
位置1 可以 禁止 禁止 禁止
位置2 可以 可以 禁止 禁止
位置3 可以 可以 可以 禁止
位置4 可以 可以 可以 可以所以图里被遮掉的区域不是随便遮,而是严格对应"不能看右边未来 token"。

这张图展示的就是 causal mask 的形状。它通常是一个上三角结构。允许看的地方保留,不允许看的地方加上一个极大的负数,比如 − 10 9 -10^9 −109:
M i j = { 0 , j ≤ i − 10 9 , j > i M_{ij}= \begin{cases} 0, & j\le i\\ -10^9, & j>i \end{cases} Mij={0,−109,j≤ij>i
加到分数上以后,未来位置经过 softmax 几乎变成 0。
为什么要加一个很大的负数,而不是直接把那个位置删掉?因为矩阵计算更喜欢保持形状不变。原来是 T × T T\times T T×T,mask 后仍然是 T × T T\times T T×T,只是禁止位置的分数被压到极低。
比如某一行原始分数是:
text
[3.0, 2.0, 5.0, 1.0]如果当前位置只能看前两个位置,mask 后变成:
text
[3.0, 2.0, -1000000000, -1000000000]softmax 后未来两个位置的概率几乎就是 0。这样它们不会参与 Value 加权求和。

这张图展示 mask 之后再做 softmax 的结果。softmax 是按行做的,每一行都会变成一组加起来等于 1 的注意力权重。
第 1 行只能看第 1 个 token,所以权重是 100% 给自己。第 2 行可以看第 1、2 个 token,权重分配在这两个位置之间。越靠后的位置,能看的历史越多。
看一个简化例子。假设第 3 个位置原始分数是:
text
[1.0, 3.0, 2.0, 9.0]第 4 个位置是未来,所以要遮掉:
text
[1.0, 3.0, 2.0, -1000000000]softmax 后可能近似是:
text
[0.09, 0.67, 0.24, 0.00]这说明第 3 个位置最关注第 2 个 token,其次关注自己,第 4 个 token 完全不参与。
这就是 causal language model 的"因果"含义:当前位置的输出只能由过去和现在决定,不能由未来决定。
21. 推理时的 KV cache:别重复算旧内容
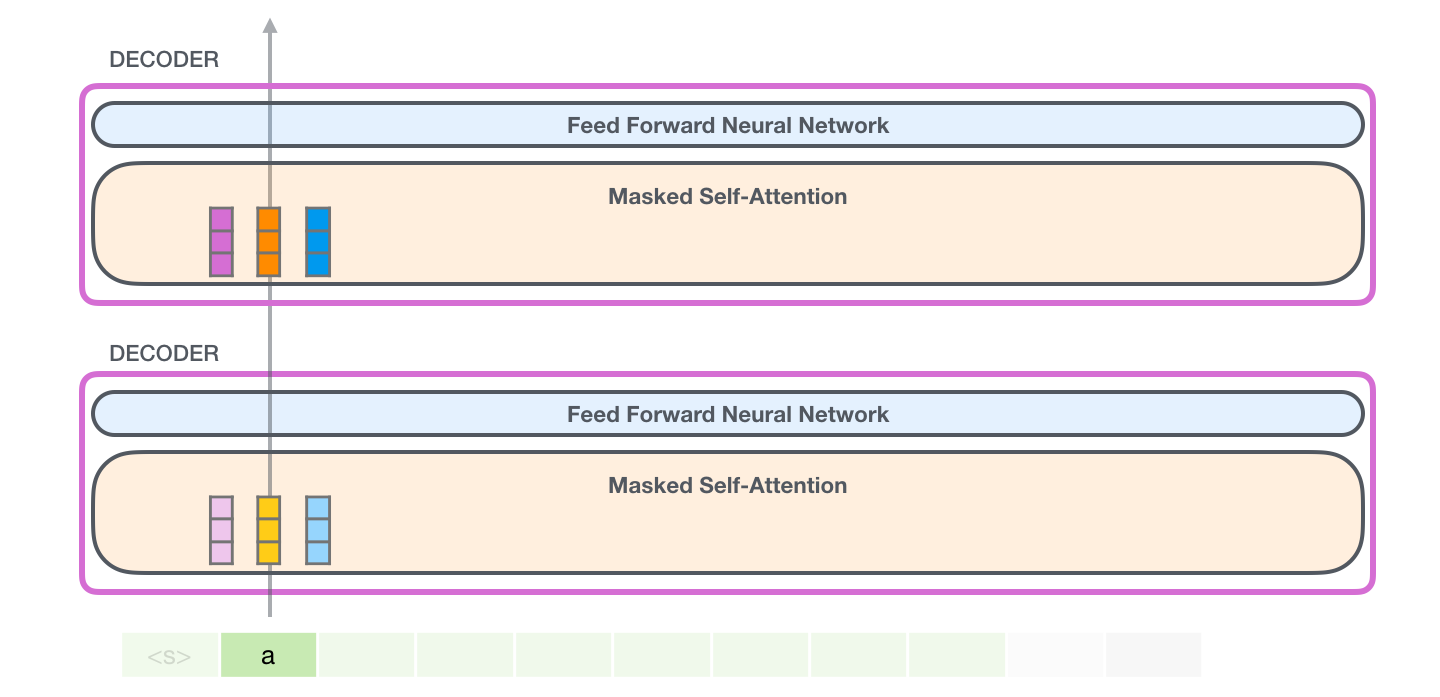
这张图开始讲一个上一篇 Transformer 图文里没有重点展开的工程机制:KV cache。它不是 Transformer block 的新层,也不是改变模型能力的新公式,而是让自回归生成变快的推理技巧。现代 LLM 推理几乎都离不开它。
严格说,原始 Transformer 的解码器在推理生成译文时也可以使用类似缓存;只是上一篇主要讲模型结构,没有把它作为核心机制展开。到了 GPT-2 这种 decoder-only 语言模型里,模型的主要工作就是不断生成下一个 token,KV cache 的价值就变得非常突出。
先看图里的第一步:生成时,GPT-2 一次只新增一个 token。假设当前只有一个 token:
text
a模型会为它计算:
text
q_a, k_a, v_a如果只有一个 token,那么它只能关注自己:
A t t e n t i o n ( q a , k a , v a ) = v a \mathrm{Attention}(q_a,k_a,v_a)=v_a Attention(qa,ka,va)=va
这里方括号表示当前可见的 Key 和 Value 列表。第一步很简单,因为历史里只有它自己。
但重点来了:生成第一个 token 后,a 的 Key 和 Value 已经算出来了。后面再生成新 token 时,a 仍然是同一个历史 token,它的 Key 和 Value 不会改变。
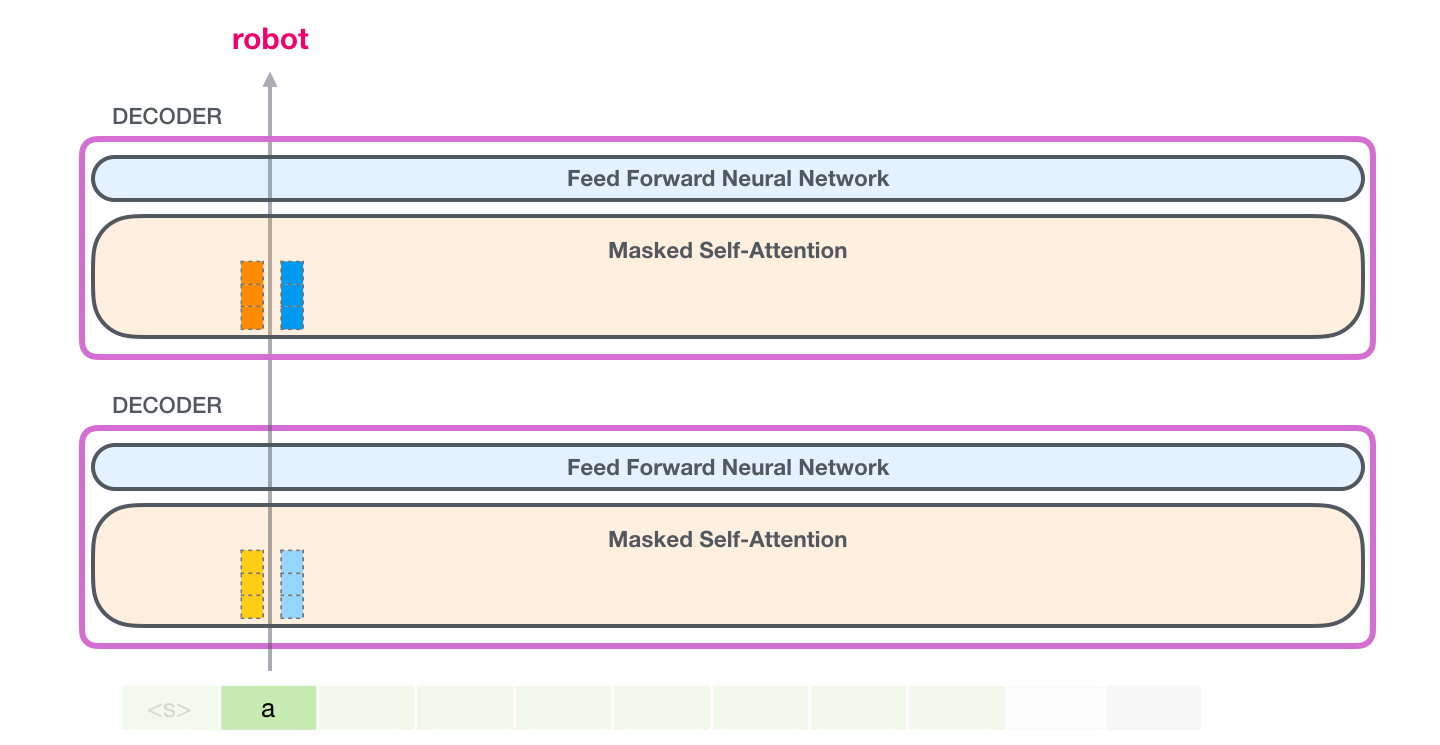
这张图展示的就是"把历史 token 的 K 和 V 存起来"。保存的不是文字 a,也不是最终输出概率,而是每一层 Transformer block、每一个注意力头里的 Key 张量和 Value 张量。
为什么只缓存 K 和 V,不缓存 Q?因为未来的新 token 需要拿自己的 Query 去查询历史信息。历史 token 的 Query 是它当时作为"提问者"用的,未来 token 不需要再用历史 Query。未来 token 真正需要的是历史 token 的:
text
Key:我能不能被你关注?
Value:如果你关注我,我给你什么内容?所以缓存 K 和 V 就够了。
用两步生成看得更清楚。假设模型已经有:
text
a缓存是:
K cache = k a K_{\text{cache}}=k_a Kcache=ka
V cache = v a V_{\text{cache}}=v_a Vcache=va
下一步生成了 robot,模型只需要新算:
text
q_robot, k_robot, v_robot然后把新的 k robot k_{\text{robot}} krobot 和 v robot v_{\text{robot}} vrobot 追加到缓存:
K cache = k a , k robot K_{\text{cache}}=k_a,\\ k_{\\text{robot}} Kcache=ka, krobot
V cache = v a , v robot V_{\text{cache}}=v_a,\\ v_{\\text{robot}} Vcache=va, vrobot
a 的 k a k_a ka 和 v a v_a va 不用重算。
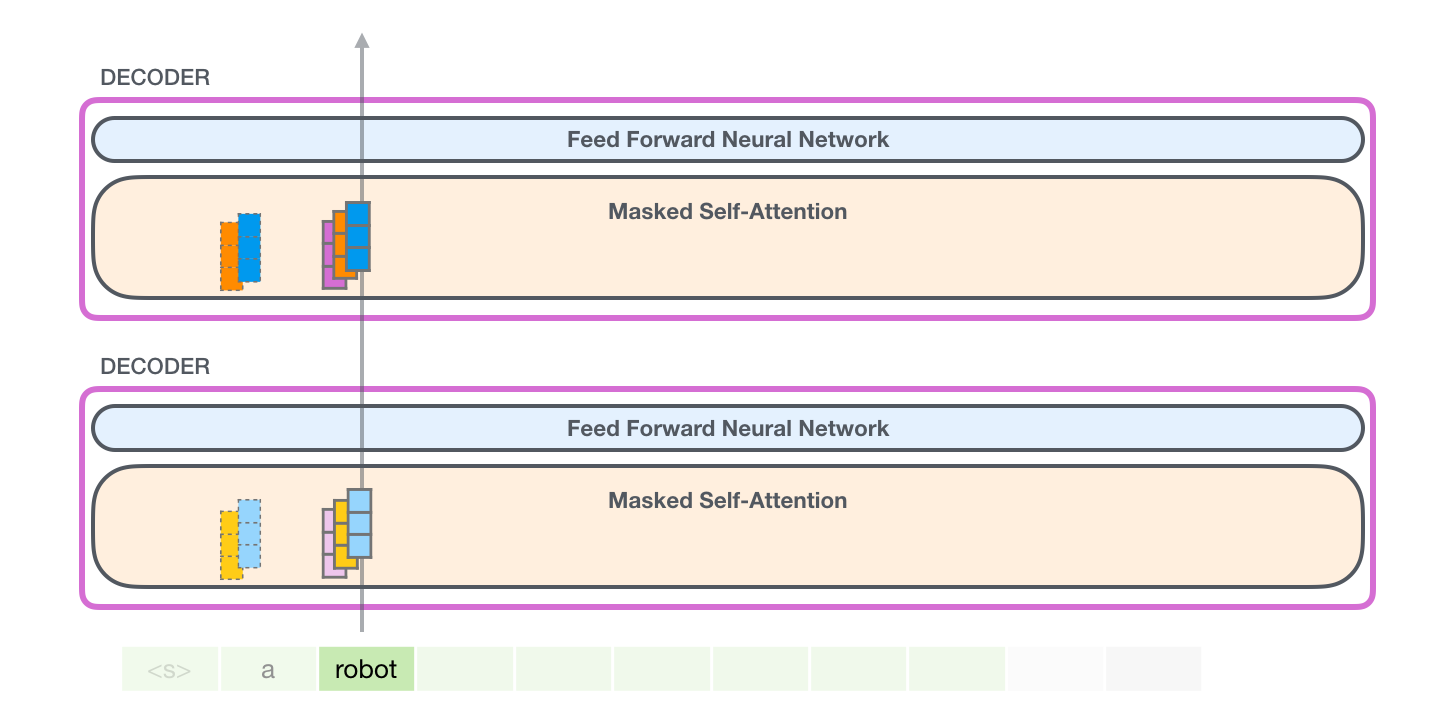
这张图展示第三步:处理新 token 时,模型把新 Query 拿去和缓存里的所有 Key 打分,再用缓存里的所有 Value 做加权求和。
假设当前已经有:
text
a robot处理 robot 时,注意力不是只看 robot 自己,而是:
A t t e n t i o n ( q robot , k a , k robot , v a , v robot ) \mathrm{Attention}(q_{\text{robot}},k_a,k_{\\text{robot}},v_a,v_{\\text{robot}}) Attention(qrobot,ka,krobot,va,vrobot)
如果模型发现 robot 需要参考前面的 a,那么 q robot q_{\text{robot}} qrobot 和 k a k_a ka 的打分会比较高,最后输出里就会混入更多 v a v_a va 的信息。
再往后生成:
text
a robot must处理 must 时,只新算:
text
q_must, k_must, v_must注意力计算变成:
A t t e n t i o n ( q must , k a , k robot , k must , v a , v robot , v must ) \mathrm{Attention}(q_{\text{must}},k_a,k_{\\text{robot}},k_{\\text{must}},v_a,v_{\\text{robot}},v_{\\text{must}}) Attention(qmust,ka,krobot,kmust,va,vrobot,vmust)
这就是 KV cache 的核心:每一步只为"新来的 token"计算新的 Q、K、V,历史 token 的 K、V 从缓存里拿。
如果不用 KV cache,生成过程会很浪费。比如已经有 4 个 token:
text
The robot must obey要生成第 5 个 token 时,模型会重新处理:
text
The
The robot
The robot must
The robot must obey更准确地说,它会把整个前文再次送进所有 Transformer 层,重新算历史 token 的 Q、K、V 和中间结果。历史越长,重复计算越多。
有 KV cache 后,流程分成两个阶段。
第一阶段叫 prefill,也就是先处理用户给的整段提示词:
text
提示词:The robot must模型一次性算出每一层的历史 K/V 缓存:
text
第1层 cache: K,V for [The, robot, must]
第2层 cache: K,V for [The, robot, must]
...
第12层 cache: K,V for [The, robot, must]第二阶段叫 decode,也就是每次只生成一个新 token:
text
新 token: obey这时每一层只需要处理这个新 token,并让它查询本层已有的历史 K/V。然后把 obey 在每一层产生的新 K/V 追加到对应层的 cache 里。
注意,KV cache 是"每层都有一份"。因为第 1 层的 Key/Value 来自第 1 层的隐藏状态,第 12 层的 Key/Value 来自第 12 层的隐藏状态,它们不是同一套东西。
从形状上看,某一层的 cache 通常类似:
K cache ∈ R B × H × T × D K_{\text{cache}}\in \mathbb{R}^{B\times H\times T\times D} Kcache∈RB×H×T×D
V cache ∈ R B × H × T × D V_{\text{cache}}\in \mathbb{R}^{B\times H\times T\times D} Vcache∈RB×H×T×D
其中 B B B 是 batch size, H H H 是注意力头数, T T T 是已经缓存的历史长度, D D D 是每个头的维度。GPT-2 small 里常见:
text
H = 12
D = 64如果历史越来越长, T T T 会越来越大,cache 占用的显存也会越来越多。所以 KV cache 让计算更快,但会消耗更多显存。这也是长上下文推理很吃显存的重要原因之一。
KV cache 和 mask 的关系也要分清。用了 KV cache 后,生成阶段每次只处理最新 token,而最新 token 的历史缓存天然都是它左边的内容,所以它本来就看不到未来。训练阶段没有逐步生成,仍然需要 causal mask 来防止每个位置偷看右边。
最后用一句话总结这张图的意思:新 token 带着自己的 Query 来问问题,历史 token 把早就算好的 Key 和 Value 摆在缓存里供它查询,模型不必每次把整段历史重新算一遍。
用符号表示,第 t t t 步会保存:
K ≤ t = K ≤ t − 1 ; k t K_{\le t}=K_{\\le t-1}; k_t K≤t=K≤t−1;kt
V ≤ t = V ≤ t − 1 ; v t V_{\le t}=V_{\\le t-1}; v_t V≤t=V≤t−1;vt
下一步只追加新的 k t + 1 k_{t+1} kt+1 和 v t + 1 v_{t+1} vt+1。
这也是为什么 KV cache 是 GPT-2 走向实际可用生成系统的关键机制之一。论文结构图里不一定把它画成一个模块,但真实 LLM 服务如果没有 KV cache,长文本生成会慢得多。
22. GPT-2 里 QKV 是一次性算出来的
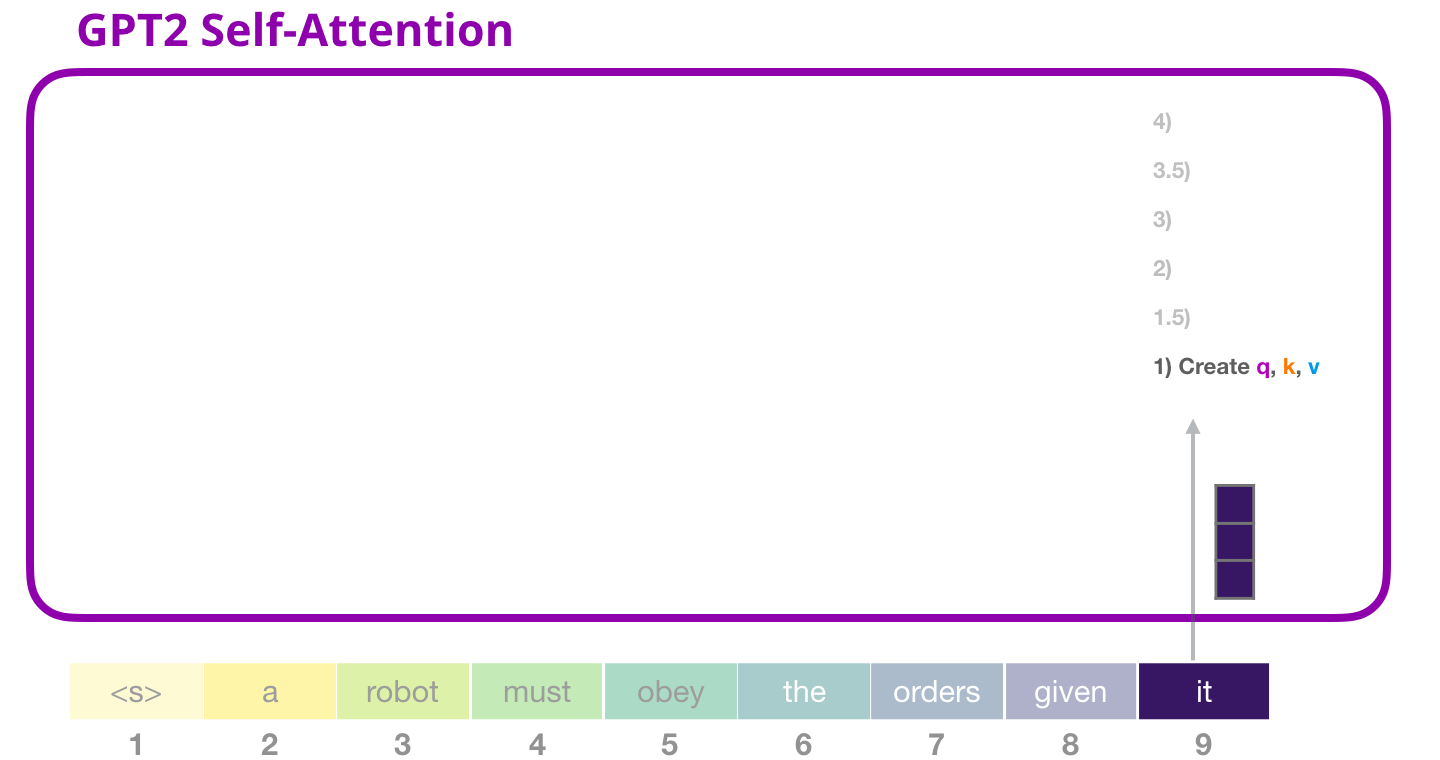
这张图要表达的是:一个 token 进入注意力层后,不是只变成一个东西,而是会被加工成 Query、Key、Value 三种表示。图里从输入向量连到一大块权重,再得到 Q、K、V,意思是"同一个 token 向量经过线性变换,被切出三种用途"。
这里有一个很重要的点:Q、K、V 分开是注意力机制的核心思想;把 Q、K、V 一次性算出来,是 GPT-2 这类实现里的高效工程设计。它不是把数学公式改了,而是把原来三次类似的计算合并成一次更大的矩阵计算。
先按概念写,应该是三次投影:
q = x W Q q=xW_Q q=xWQ
k = x W K k=xW_K k=xWK
v = x W V v=xW_V v=xWV
这里的 x x x 是某个 token 当前的隐藏向量。 W Q W_Q WQ、 W K W_K WK、 W V W_V WV 是三组可训练权重。训练开始时它们是随机数,训练过程中通过反向传播不断调整,最后学会把同一个输入拆成三种不同角色。
为什么要三种角色?继续用会议类比:
text
Query:我现在要找什么信息?
Key:我能被什么问题匹配上?
Value:如果别人关注我,我真正贡献什么内容?比如处理 it 时,it 的 Query 可能在找"我指代谁";robot 的 Key 可能带着"我是一个实体名词,可以被代词指代"的线索;robot 的 Value 则带着更丰富的信息,比如它是机器人、单数、前文主角等。
如果直接用同一个原始向量同时做这三件事,模型会被迫用一套特征既负责"找关系",又负责"提供内容"。Q、K、V 分开后,模型可以让不同权重矩阵学习不同侧面。
但在真实代码里,为了效率,GPT-2 往往不真的做三次独立矩阵乘法,而是把三个矩阵横向拼成一个大矩阵:
设输入向量是 x x x,单个 Q、K、V 的维度都是 d d d。可以把三个权重矩阵拼成一个大矩阵:
W Q K V = W Q W K W V W_{QKV}=W_Q\\ W_K\\ W_V WQKV=WQ WK WV
于是:
q k v = x W Q K V q\\ k\\ v=xW_{QKV} q k v=xWQKV
这就像去窗口办三项业务。低效做法是排三次队:先办 Query,再办 Key,再办 Value。合并做法是到一个综合窗口,一次提交材料,窗口内部同时给你办出三份结果。三份结果的用途仍然不同,只是办理过程更快。
用一个很小的数字例子看。假设输入向量是 2 维:
x = 1 , 2 x=1,\\ 2 x=1, 2
我们希望 Q、K、V 也都是 2 维。概念上需要三个 2 × 2 2\times 2 2×2 矩阵:
W Q = 1 0 0 1 , W K = 2 0 0 2 , W V = 1 1 1 − 1 W_Q= \begin{bmatrix} 1 & 0\\ 0 & 1 \end{bmatrix} ,\quad W_K= \begin{bmatrix} 2 & 0\\ 0 & 2 \end{bmatrix} ,\quad W_V= \begin{bmatrix} 1 & 1\\ 1 & -1 \end{bmatrix} WQ=1001,WK=2002,WV=111−1
如果分开算:
q = x W Q = 1 , 2 q=xW_Q=1,\\ 2 q=xWQ=1, 2
k = x W K = 2 , 4 k=xW_K=2,\\ 4 k=xWK=2, 4
v = x W V = 3 , − 1 v=xW_V=3,\\ -1 v=xWV=3, −1
合并算就是把三个矩阵横向拼起来:
W Q K V = 1 0 2 0 1 1 0 1 0 2 1 − 1 W_{QKV}= \begin{bmatrix} 1 & 0 & 2 & 0 & 1 & 1\\ 0 & 1 & 0 & 2 & 1 & -1 \end{bmatrix} WQKV=10012002111−1
一次乘法得到:
x W Q K V = 1 , 2 , 2 , 4 , 3 , − 1 xW_{QKV}=1,\\ 2,\\ 2,\\ 4,\\ 3,\\ -1 xWQKV=1, 2, 2, 4, 3, −1
然后把这个长向量切成三段:
1 , 2 \] ∣ \[ 2 , 4 \] ∣ \[ 3 , − 1 \] \[1,\\ 2\]\\ \|\\ \[2,\\ 4\]\\ \|\\ \[3,\\ -1\] \[1, 2\] ∣ \[2, 4\] ∣ \[3, −1
这三段正好就是 q q q、 k k k、 v v v。所以合并计算没有改变结果,只是把"三次小计算"变成"一次大计算"。
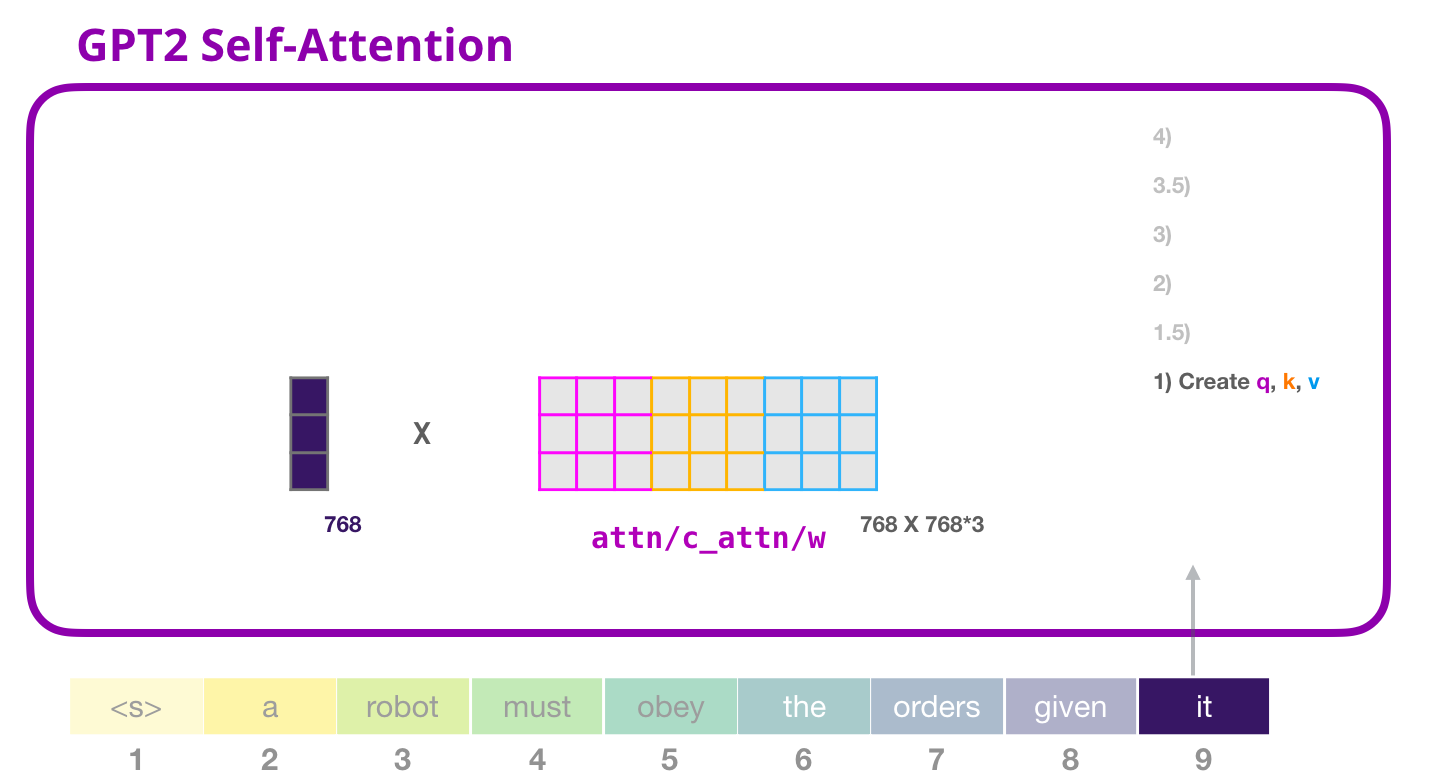
这张图里的大矩阵就是 W Q K V W_{QKV} WQKV。可以把它看成三块并排放在一起:
text
[ 生成 Query 的权重 | 生成 Key 的权重 | 生成 Value 的权重 ]如果 GPT-2 small 的隐藏维度是 768,那么单独看每一块:
W Q ∈ R 768 × 768 W_Q\in \mathbb{R}^{768\times 768} WQ∈R768×768
W K ∈ R 768 × 768 W_K\in \mathbb{R}^{768\times 768} WK∈R768×768
W V ∈ R 768 × 768 W_V\in \mathbb{R}^{768\times 768} WV∈R768×768
三块拼在一起后:
W Q K V ∈ R 768 × 2304 W_{QKV}\in \mathbb{R}^{768\times 2304} WQKV∈R768×2304
因为:
2304 = 3 × 768 2304=3\times 768 2304=3×768
如果输入是一整段序列,而不是一个 token,形状就更明显。假设 batch size 是 B B B,序列长度是 T T T:
X ∈ R B × T × 768 X\in \mathbb{R}^{B\times T\times 768} X∈RB×T×768
经过这一个大矩阵后:
X W Q K V ∈ R B × T × 2304 XW_{QKV}\in \mathbb{R}^{B\times T\times 2304} XWQKV∈RB×T×2304
这张图里大矩阵的意义就是:每个 token 的 768 维向量,一次性被投影成 2304 维,然后后面再拆成 3 个 768 维。
为什么这算重要设计?因为深度学习硬件很擅长做大矩阵乘法。一次大矩阵乘法通常比三次小矩阵乘法更容易被 GPU 高效执行,也更少产生中间调度开销。模型越大、层数越多、生成越频繁,这种工程优化越重要。
但要小心一个误解:大矩阵不是让 Q、K、V 变成同一套东西。它只是把三套权重装进同一个矩阵里。训练时,左边那一块仍然主要负责学 Query,中间那一块负责学 Key,右边那一块负责学 Value。
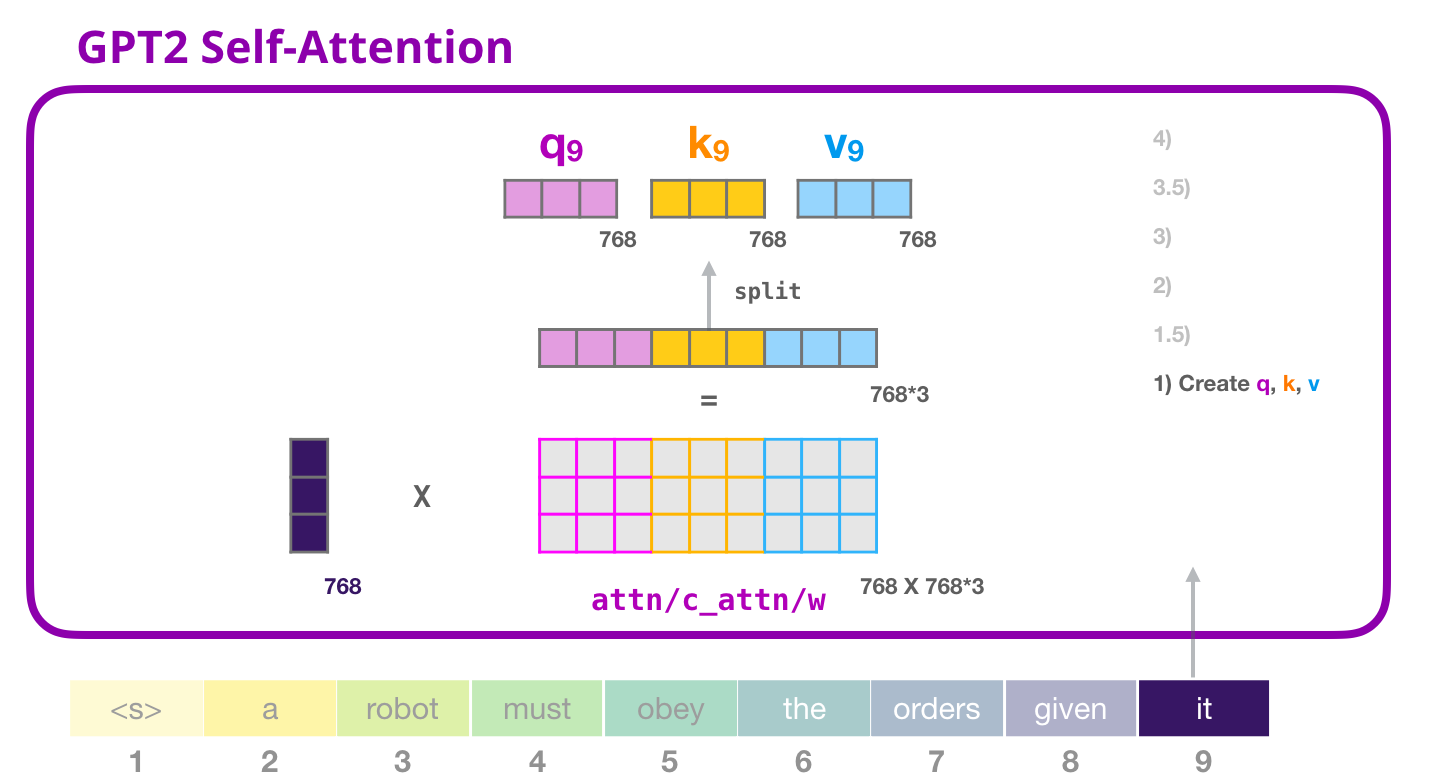
这张图展示合并计算后的下一步:把长向量拆回 Q、K、V。上一张图得到的是一个拼接结果,这一张图把它按维度切开。
计算结果是一个长向量,然后再切成三段:
text
[Query | Key | Value]如果是 GPT-2 small,这个长向量长度是 2304:
text
[前 768 维 | 中间 768 维 | 后 768 维]切开后得到:
text
Query: 768 维
Key: 768 维
Value: 768 维然后它们还会继续被拆成多个注意力头。GPT-2 small 有 12 个头,所以每个 768 维会变成:
12 × 64 12\times 64 12×64
也就是:
text
Query -> 12 个头,每个头 64 维
Key -> 12 个头,每个头 64 维
Value -> 12 个头,每个头 64 维这张图如果和下一章的多头注意力连起来看,流程就是:
text
输入隐藏向量 768 维
↓
一次线性层得到 2304 维
↓
切成 Q、K、V 三份,每份 768 维
↓
每份再切成 12 个头,每个头 64 维
↓
每个头独立做注意力这和快递分拣有点像:先用一条流水线统一处理所有包裹,到了后面再按 Query、Key、Value 三个区域分开,然后每个区域再分给 12 个小组处理。
把这一节放回 GPT-2 的创新脉络里看,真正关键的是两层含义:
第一,理论上,Q、K、V 的分工让注意力能够同时解决"找谁"和"拿什么信息"两个问题。
第二,工程上,一次性 QKV 投影让这种机制在大模型里更高效。GPT-2 之后的很多 LLM 实现也沿用类似写法,例如常见代码里会看到 c_attn、qkv_proj、in_proj 这样的名字,它们往往就是这个合并投影层。
所以这三张图不是在讲一个额外的小技巧,而是在讲自注意力真正进入可训练、可加速实现时的关键入口:先把 token 的隐藏向量一次性变成 Q、K、V,再交给后面的多头注意力去打分、加权和融合。
23. 多头注意力:把一个大视角拆成多个小视角
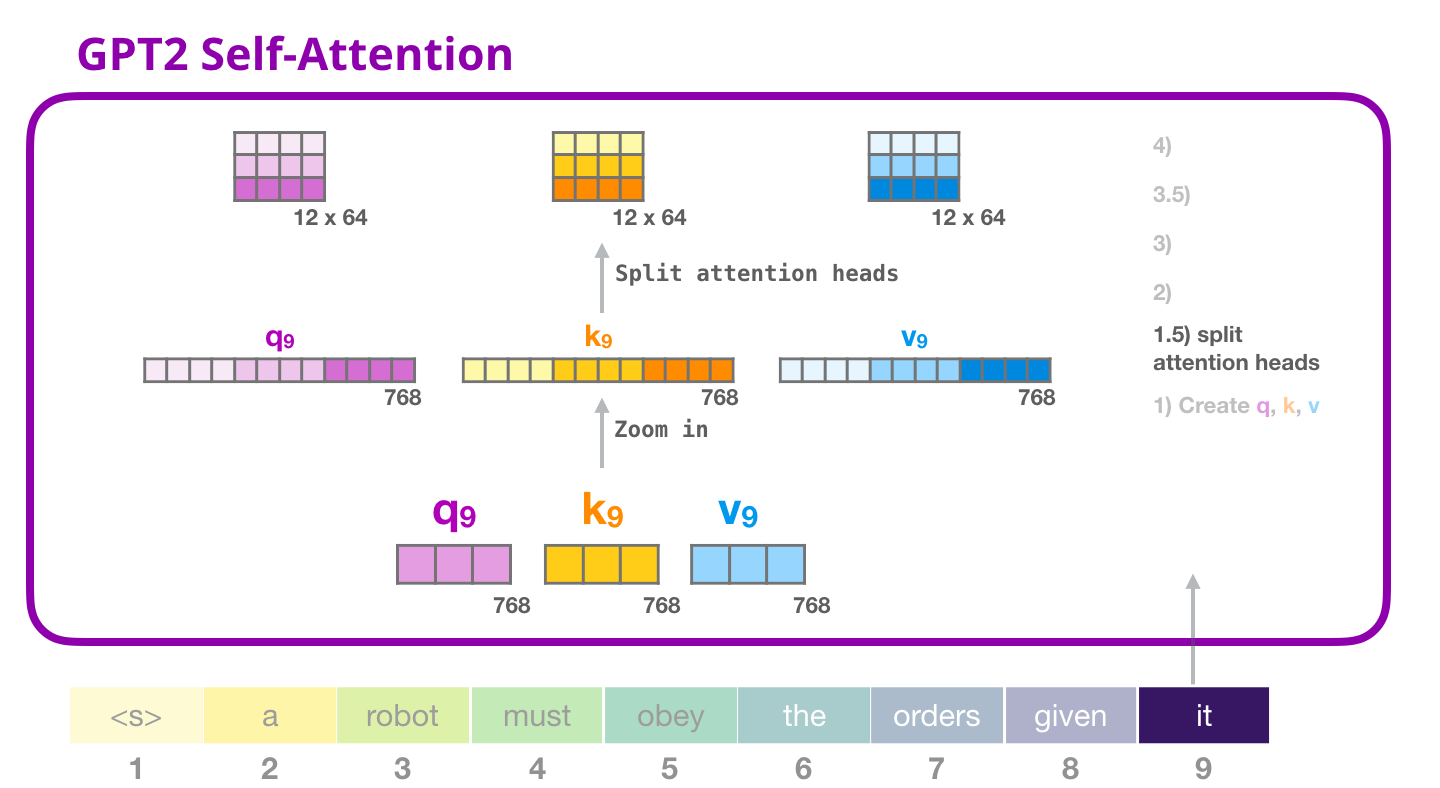
这张图接着上一章的 QKV 拆分继续往下讲。上一章说每个 token 会得到一份 768 维的 Query、Key、Value。这里的图要表达的是:这 768 维不会作为一个整体直接去做注意力,而是会再切成多个小块,每个小块交给一个 attention head。
GPT-2 small 的隐藏维度是 768,注意力头数是 12。每个头拿到的维度是:
d h e a d = 768 12 = 64 d_{head}=\frac{768}{12}=64 dhead=12768=64
所以一份 Query 会从:
text
768 维变成:
text
12 份,每份 64 维Key 和 Value 也一样。注意,这不是把句子切成 12 段,也不是把 12 个 token 分给 12 个头。每个头都能看整段上下文,只是每个头看的"特征维度"不同。
可以把一个 token 的 Query 想成 768 个数字排成一长条:
text
[数字1, 数字2, ..., 数字768]切成 12 个头后变成:
text
head 1: [数字1 到 数字64]
head 2: [数字65 到 数字128]
...
head 12: [数字705 到 数字768]真实实现里通常不是手工切列表,而是通过 reshape 或 view 改变张量形状:
B × T × 768 B\times T\times 768 B×T×768
变成:
B × T × 12 × 64 B\times T\times 12\times 64 B×T×12×64
然后为了方便矩阵乘法,常会再调整维度顺序:
B × 12 × T × 64 B\times 12\times T\times 64 B×12×T×64
其中 B B B 是一次处理多少条样本, T T T 是序列长度,12 是注意力头数,64 是每个头的维度。
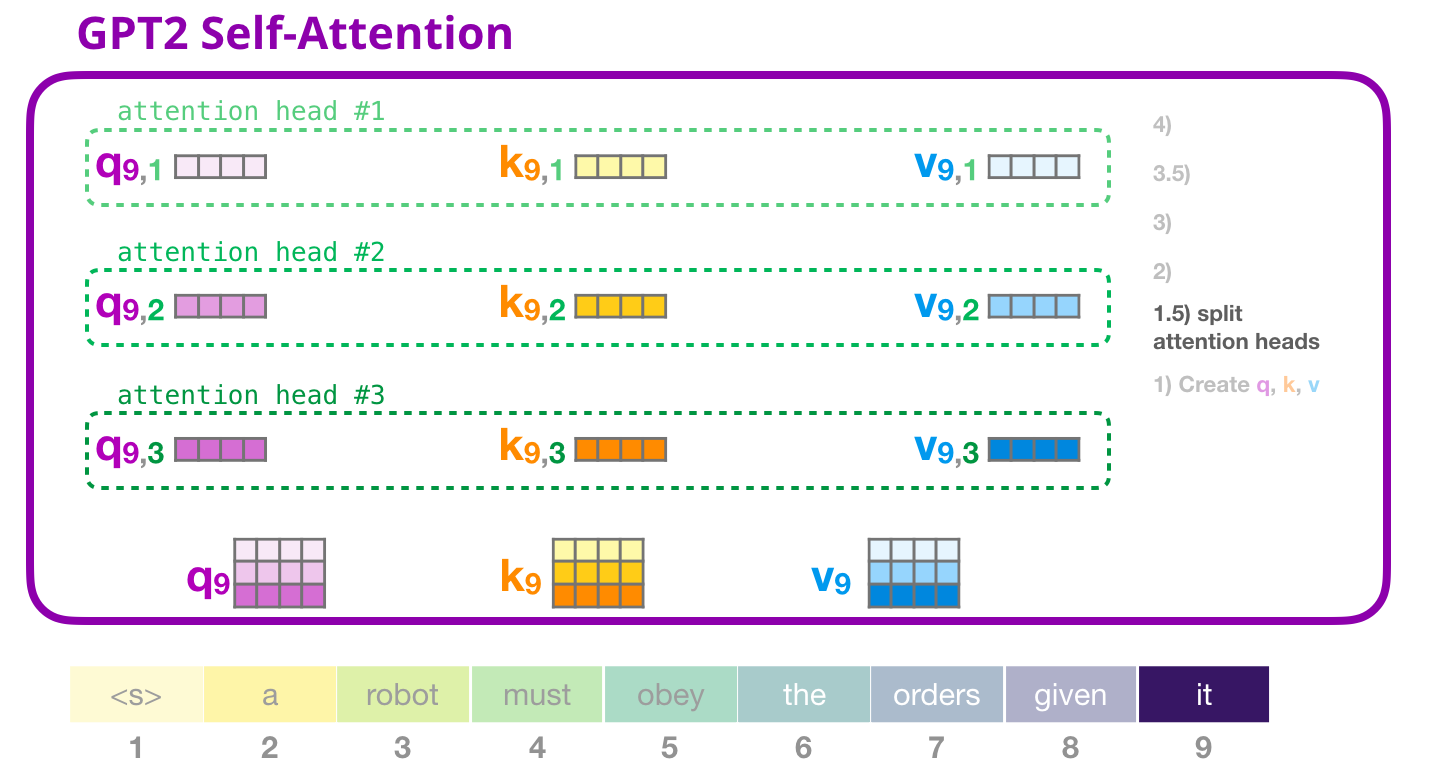
这张图展示多个头并行工作。每个头都有自己的 Q、K、V 子向量,它会独立完成一遍注意力计算:打分、softmax、对 Value 加权求和。也就是说,12 个头不是排队一个接一个算,而是可以并行算。
为什么要有多个头?因为语言关系不止一种。看一句话:
text
The robot said it must obey the law.处理 it 时,模型可能需要不同类型的信息:
text
一个头关注 it 指代 robot。
一个头关注 must obey 这种动作结构。
一个头关注 the law 这个宾语。
一个头关注 said 后面的从句范围。当然,真实模型里的头不会被人工指定成这些功能,而是在训练中自己学出来。我们只能事后通过可视化大概观察某些头的倾向。
多个头的结构一样,但权重不一样。即使结构都是:
s o f t m a x ( Q K ⊤ d h e a d ) V \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_{head}}}\right)V softmax(dhead QK⊤)V
它们拿到的 Q、K、V 子空间不同,训练中收到的梯度也不同,所以会逐渐学出不同的关注模式。
多头注意力的意义不是"重复做同一件事",而是让模型从多个表示子空间并行看上下文。一个头只有 64 维,表达能力有限;12 个头合起来,既保留了总的 768 维容量,又让模型能同时从多个角度理解一句话。
这一点和人读句子很像。我们理解一句话时,不会只看一种关系。我们会同时注意代词指代、语法结构、时间顺序、情绪色彩、前后呼应。多头注意力就是让模型拥有多个并行的"观察通道"。
不过也要注意,多头注意力不是 GPT-2 独创的,它来自原始 Transformer。GPT-2 继承了这个结构,并把它用在 decoder-only 的生成模型里。
24. 注意力打分:为什么 Key 要被转置
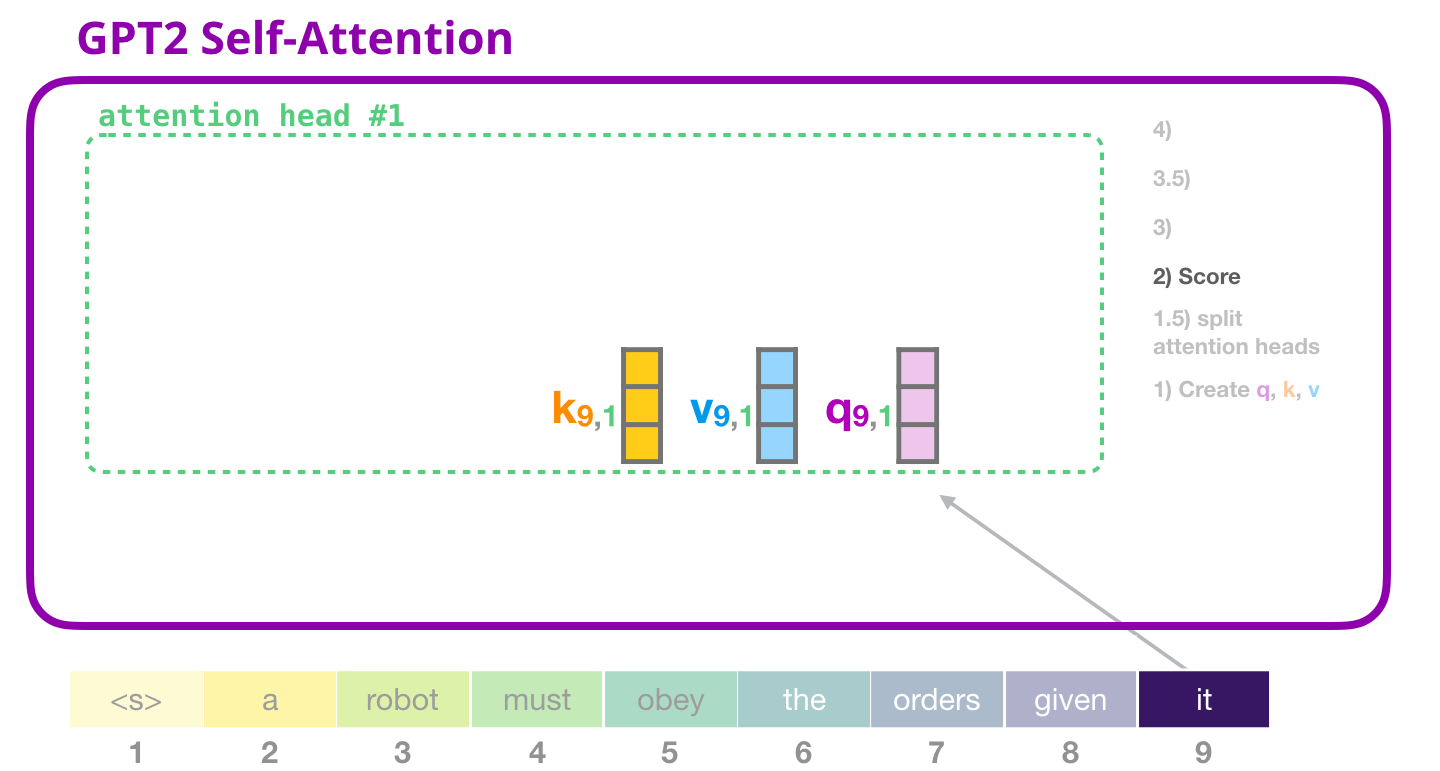
这张图把视角缩小到一个注意力头。前面说 12 个头并行,这里先只看其中一个头。每个头里都有一组 Query 和 Key。打分时,当前 token 的 Query 要和可见历史 token 的 Key 做匹配,得到"我应该关注谁"的分数。
如果处理的是第 4 个 token,它在 GPT-2 里只能看第 1 到第 4 个 token。它的 Query 会分别和这 4 个 token 的 Key 做点积:
text
q_4 · k_1
q_4 · k_2
q_4 · k_3
q_4 · k_4这些点积就是注意力分数。分数越大,表示第 4 个 token 越应该参考那个位置。
矩阵形式下,我们不想一个一个手动点积,而是用一次矩阵乘法同时算出所有位置之间的分数。如果有 T T T 个 token,每个 head 的维度是 d h e a d d_{head} dhead:
Q ∈ R T × d h e a d Q\in \mathbb{R}^{T\times d_{head}} Q∈RT×dhead
K ∈ R T × d h e a d K\in \mathbb{R}^{T\times d_{head}} K∈RT×dhead
要得到 T × T T\times T T×T 的分数表,就需要:
Q K ⊤ QK^\top QK⊤
因为 K ⊤ K^\top K⊤ 的形状是:
K ⊤ ∈ R d h e a d × T K^\top\in \mathbb{R}^{d_{head}\times T} K⊤∈Rdhead×T
矩阵乘法后:
( T × d h e a d ) ( d h e a d × T ) = T × T (T\times d_{head})(d_{head}\times T)=T\times T (T×dhead)(dhead×T)=T×T
为什么要转置 K K K?因为矩阵乘法要求中间维度对齐。 Q Q Q 的每一行是一个 Query, K K K 的每一行是一个 Key。我们想让"每一行 Query"和"每一行 Key"都做点积,就要把 Key 的行转成列。这样 Q Q Q 的行乘 K ⊤ K^\top K⊤ 的列,刚好得到两个向量的点积。
图中这些分数还不是最终权重。之后还会经过三步:
text
除以 sqrt(d_head)
加 causal mask
做 softmax为什么要除以 d h e a d \sqrt{d_{head}} dhead ?因为维度越高,点积数值通常越大。如果分数过大,softmax 会变得特别尖锐,几乎只给一个位置权重,训练会不稳定。缩放能让分数保持在更合适的范围。
GPT-2 small 里:
d h e a d = 64 d_{head}=64 dhead=64
所以缩放因子是:
64 = 8 \sqrt{64}=8 64 =8
也就是注意力分数通常会除以 8。
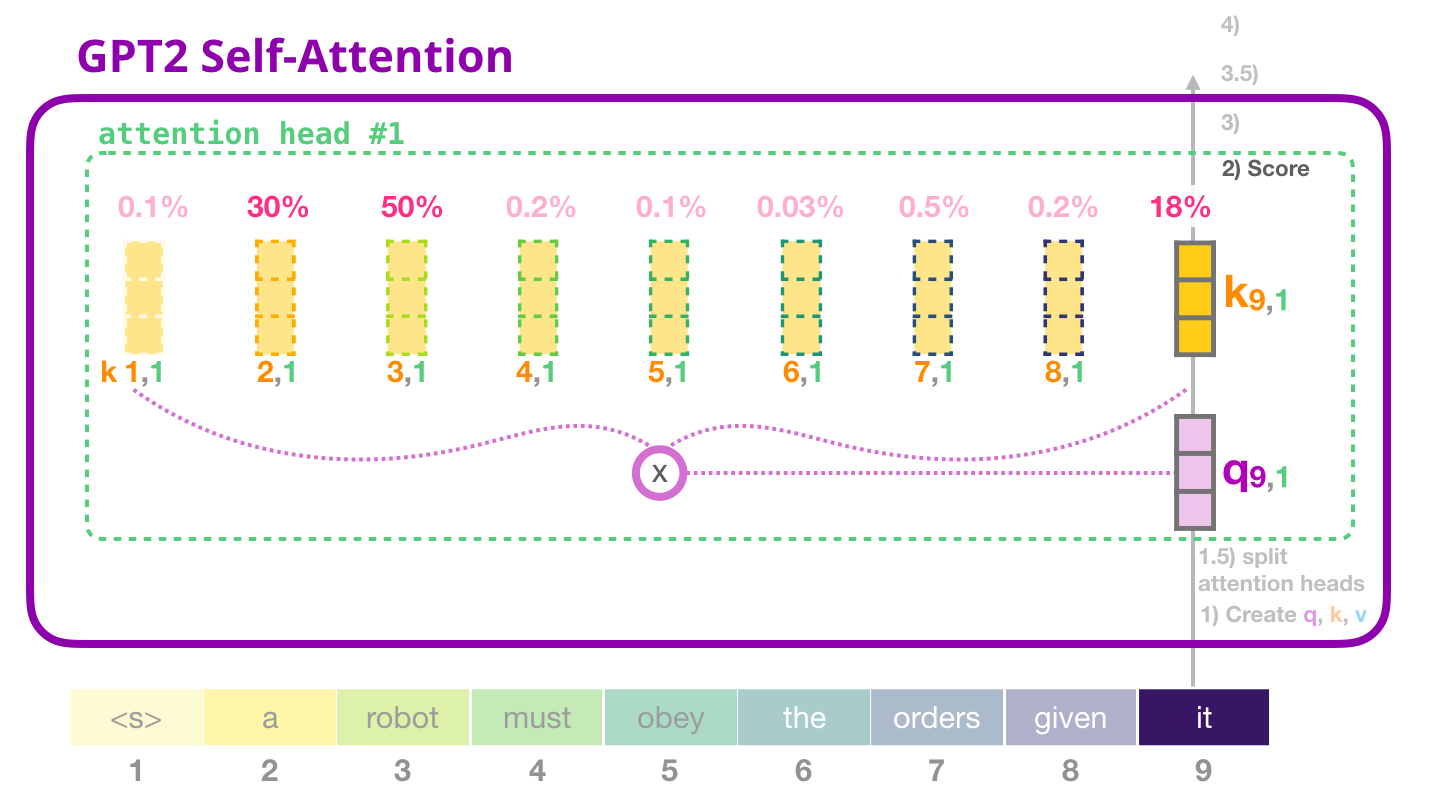
这张图展示"当前 Query 和所有 Key 打分"的展开效果。可以把它理解成当前 token 拿着一张问题卡,到历史 token 的标签前逐个比对,看哪个标签最匹配。
一个小矩阵例子。假设有 3 个 token,head 维度是 2:
Q = 1 0 0 1 1 1 , K = 1 1 2 0 0 2 Q= \begin{bmatrix} 1 & 0\\ 0 & 1\\ 1 & 1 \end{bmatrix} ,\quad K= \begin{bmatrix} 1 & 1\\ 2 & 0\\ 0 & 2 \end{bmatrix} Q= 101011 ,K= 120102
那么:
K ⊤ = 1 2 0 1 0 2 K^\top= \begin{bmatrix} 1 & 2 & 0\\ 1 & 0 & 2 \end{bmatrix} K⊤=112002
相乘得到:
Q K ⊤ = 1 2 0 1 0 2 2 2 2 QK^\top= \begin{bmatrix} 1 & 2 & 0\\ 1 & 0 & 2\\ 2 & 2 & 2 \end{bmatrix} QK⊤= 112202022
第 2 行第 3 列的 2 表示:第 2 个 token 的 Query 和第 3 个 token 的 Key 的匹配分数是 2。GPT-2 再对未来位置加 mask,然后 softmax,得到真正的注意力权重。
如果这是 GPT-2 的遮罩注意力,第 2 行第 3 列虽然算出来了,也不能使用,因为第 3 个 token 对第 2 个 token 来说是未来。mask 会把它压掉。所以完整流程更像:
S = Q K ⊤ d h e a d S=\frac{QK^\top}{\sqrt{d_{head}}} S=dhead QK⊤
S m a s k e d = S + M S_{masked}=S+M Smasked=S+M
A = s o f t m a x ( S m a s k e d ) A=\mathrm{softmax}(S_{masked}) A=softmax(Smasked)
这里 A A A 才是注意力权重矩阵。图里画的打分,是注意力权重出现之前的关键一步。
25. 每个头得到自己的上下文向量
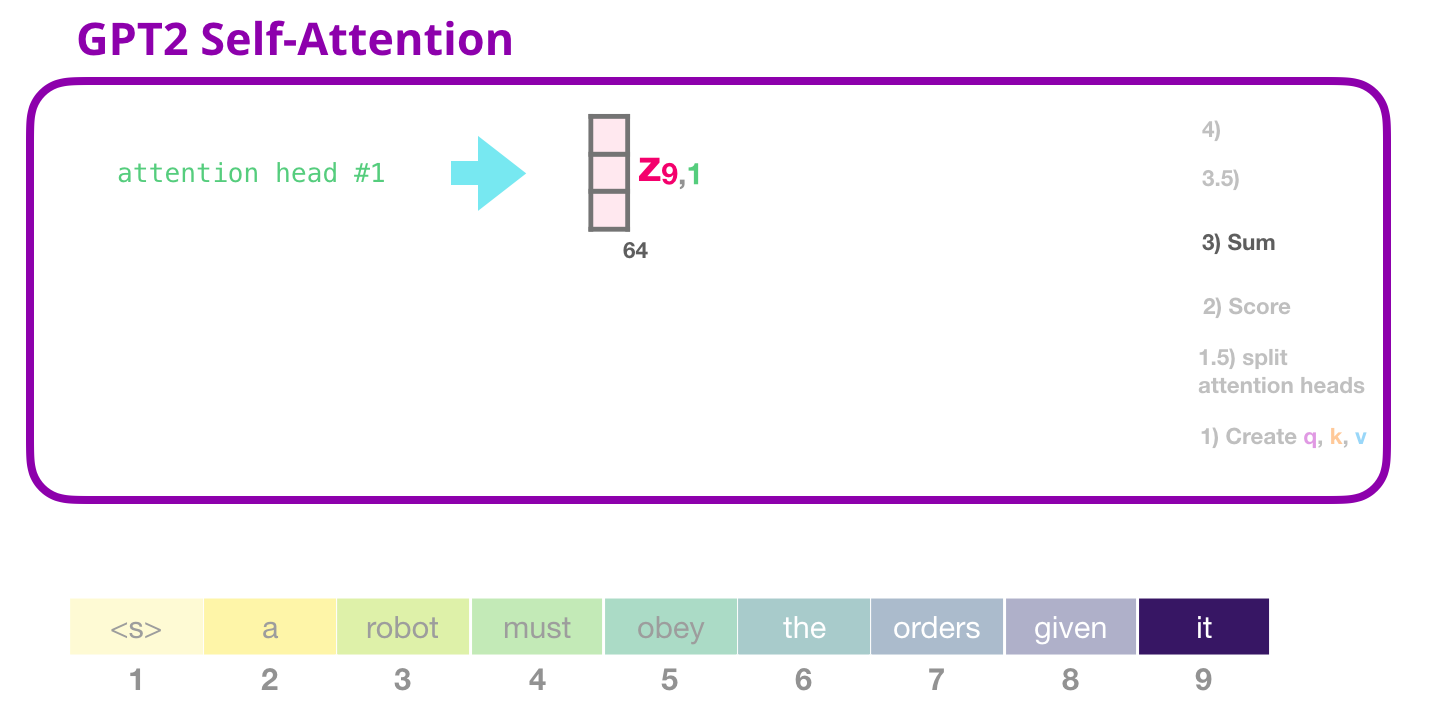
这张图展示的是打分之后真正"拿信息"的阶段。前面 Query 和 Key 的点积只是决定关注比例,最后真正被混合进输出的是 Value。
每个注意力头都会得到一个输出向量。这个向量是该头视角下的上下文总结。假设某个头正在处理第 4 个 token,它对前 4 个位置的权重是:
text
token1: 0.10
token2: 0.60
token3: 0.20
token4: 0.10那么这个头的输出就是:
z 4 = 0.10 v 1 + 0.60 v 2 + 0.20 v 3 + 0.10 v 4 z_4=0.10v_1+0.60v_2+0.20v_3+0.10v_4 z4=0.10v1+0.60v2+0.20v3+0.10v4
如果每个 Value 是 64 维,那么 z 4 z_4 z4 也是 64 维。也就是说,一个注意力头对每个 token 都会产出一个 64 维上下文向量。
如果某个头在处理 it 时给 robot 很高权重,那么这个头输出的向量就会强烈混入 robot 的 value 信息。另一个头可能关注 must obey 这种动作关系,它的输出又会混入另一类信息。
这张图只画了一个头的一次求和,但实际 GPT-2 small 同一层里有 12 个头同时做类似事情。对于同一个 token,会得到 12 个不同的上下文向量:
text
head 1 输出 64 维
head 2 输出 64 维
...
head 12 输出 64 维所以同一个 token 经过多头注意力后,不是只有一种理解,而是同时拥有多个角度的上下文理解。
这里有个很关键的因果关系:
text
Q/K 决定权重
V 提供内容
权重乘 V 得到上下文向量如果只记一句话,就记这个:注意力分数不是最终答案,它只是决定 Value 信息怎么混合。
26. 合并注意力头:拼接后还要投影
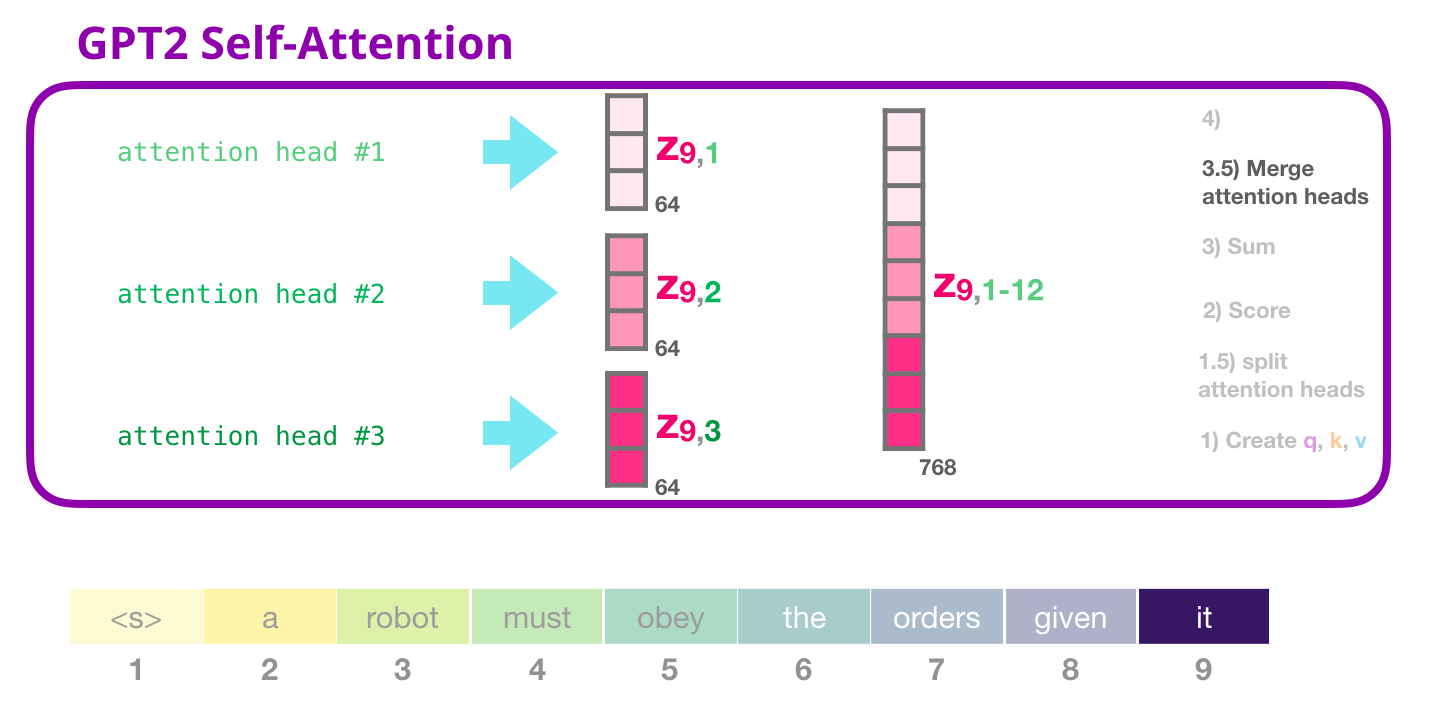
这张图展示多个注意力头算完之后的第一步:拼接。前面每个头都输出一个 64 维向量,现在要把 12 个头的结果重新放回一个大向量里。
如果有 12 个头,每个头 64 维,拼起来又回到 768 维:
12 × 64 = 768 12\times 64=768 12×64=768
所以对每个 token 来说,多头注意力的输出可以从:
text
12 个 64 维向量拼成:
text
1 个 768 维向量这一步叫 concat,也就是拼接。它只是把各个头的输出首尾接起来:
text
[head1输出 | head2输出 | ... | head12输出]拼接后虽然维度回到了 768,但这只是把报告堆在一起,还没有让不同头之间充分交流。
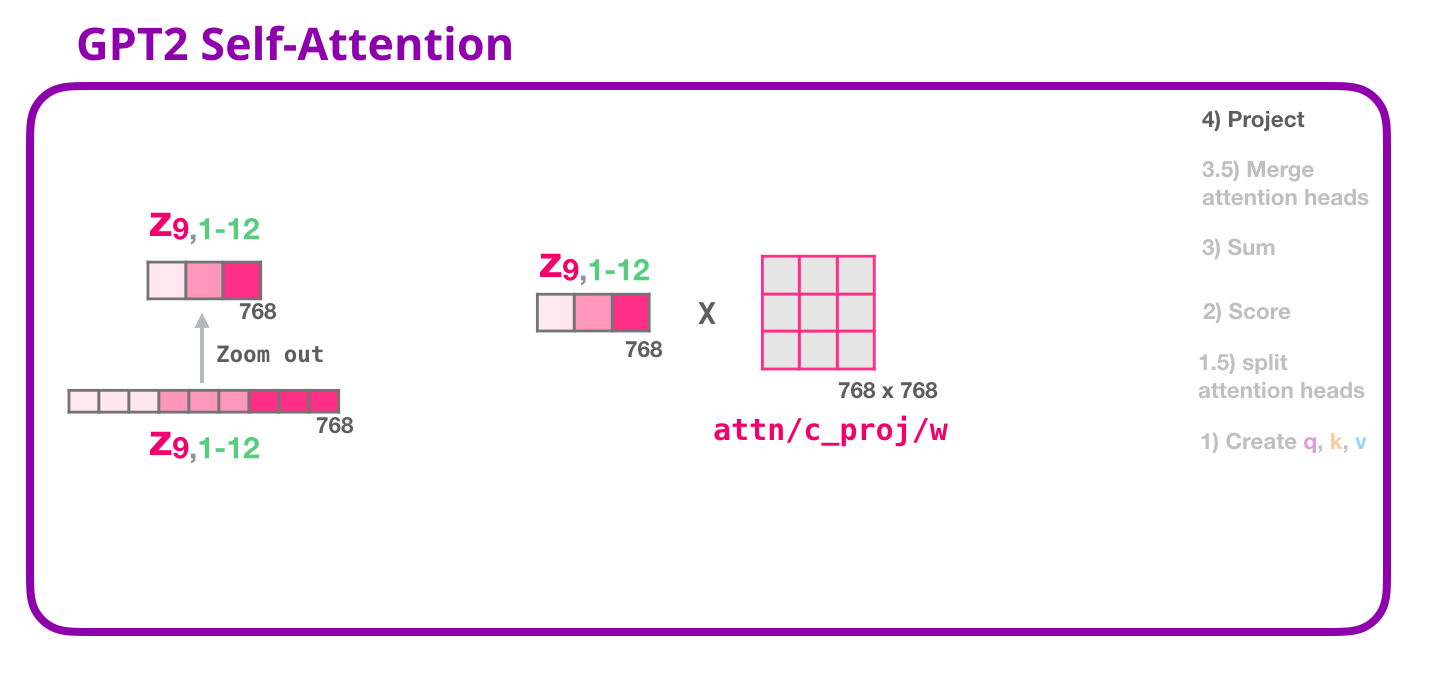
这张图展示拼接之后还要经过一个输出投影矩阵。这个矩阵通常记作 W O W_O WO。它的作用是把多个头的结果重新混合成统一表示。
O = C o n c a t ( h e a d 1 , ... , h e a d h ) W O O=\mathrm{Concat}(head_1,\dots,head_h)W_O O=Concat(head1,...,headh)WO
如果 GPT-2 small 的维度是 768,那么:
W O ∈ R 768 × 768 W_O\in \mathbb{R}^{768\times 768} WO∈R768×768
它输入 768 维,输出还是 768 维。为什么维度没变还要乘一个矩阵?因为拼接只是"摆在一起",投影才是"重新组合"。
一个类比:12 个注意力头像 12 位分析员,各自写了一段观察报告。concat 是把 12 段报告贴在同一个文档里。 W O W_O WO 则像总编辑,它会重新组织这些报告,决定哪些观点保留、哪些观点组合、哪些观点弱化。
没有 W O W_O WO,每个头的输出只是机械拼接,后面的层很难灵活地融合不同头的信息。有了 W O W_O WO,模型可以学习"第 3 个头和第 8 个头的信息应该怎样组合"。
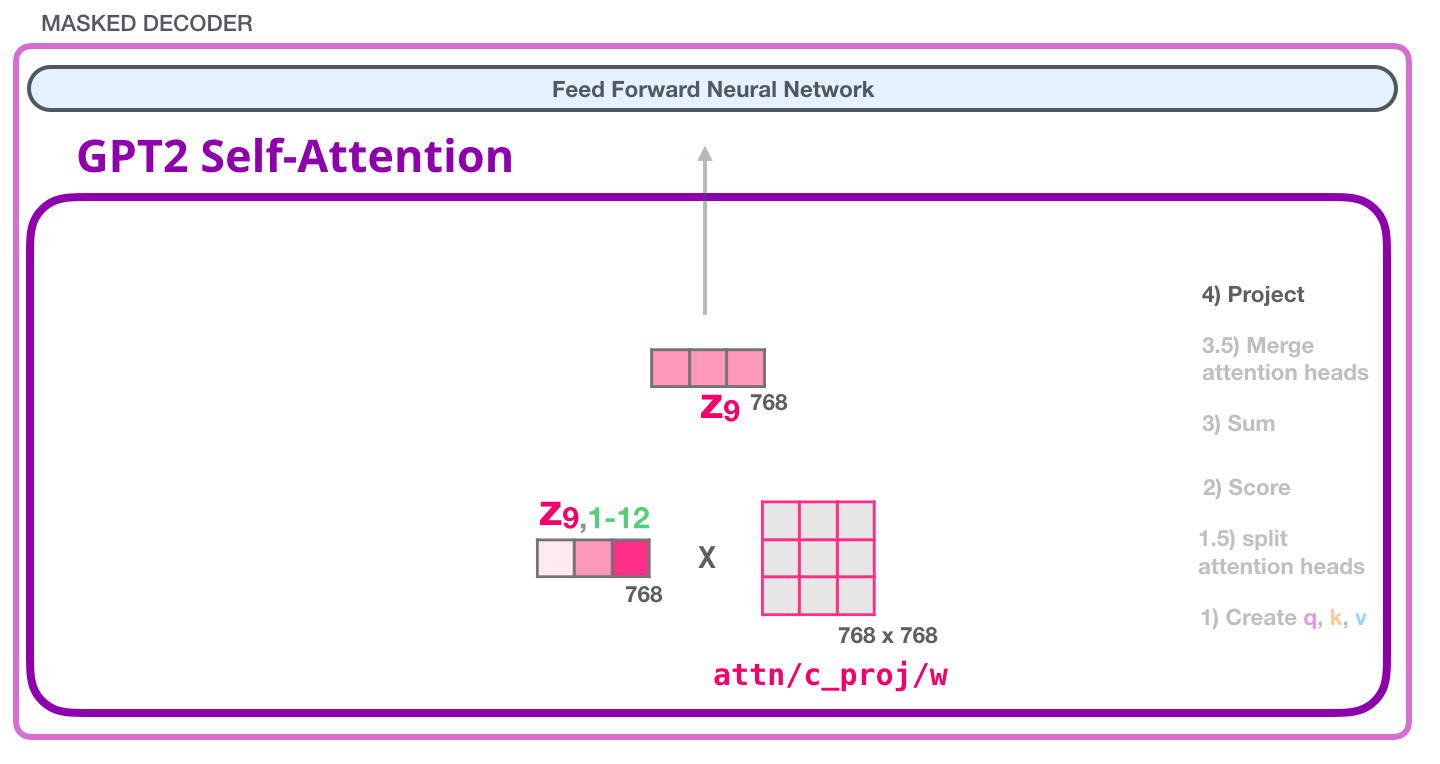
这张图展示输出投影之后得到的最终 attention 输出向量。这个向量仍然是 768 维,可以和进入注意力层之前的向量相加,也就是残差连接:
x after attention = x before attention + A t t e n t i o n O u t p u t x_{\text{after attention}}=x_{\text{before attention}}+\mathrm{AttentionOutput} xafter attention=xbefore attention+AttentionOutput
真实 GPT-2 里还会配合 LayerNorm。前面已经讲过,残差连接的作用是保留旧信息,在旧表示上增加注意力带来的新信息。
到这里,一个 self-attention 子层才算完成。它完成的事情可以总结为:
text
把每个 token 的向量拆成多个头
每个头独立查看上下文
每个头输出自己的上下文总结
把所有头拼接回来
用输出投影融合成统一向量这个统一向量接下来会进入前馈网络,也就是下一章的 MLP。
27. 前馈网络:对每个位置做更深的非线性加工
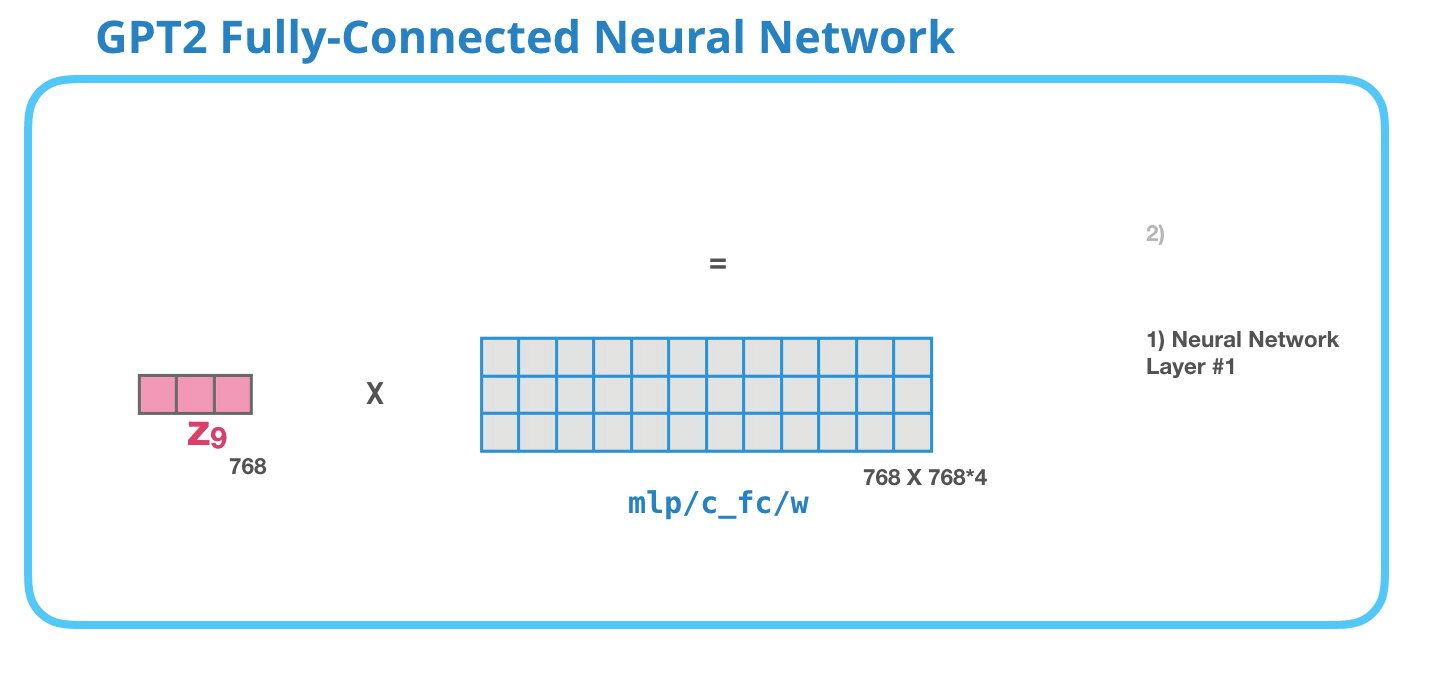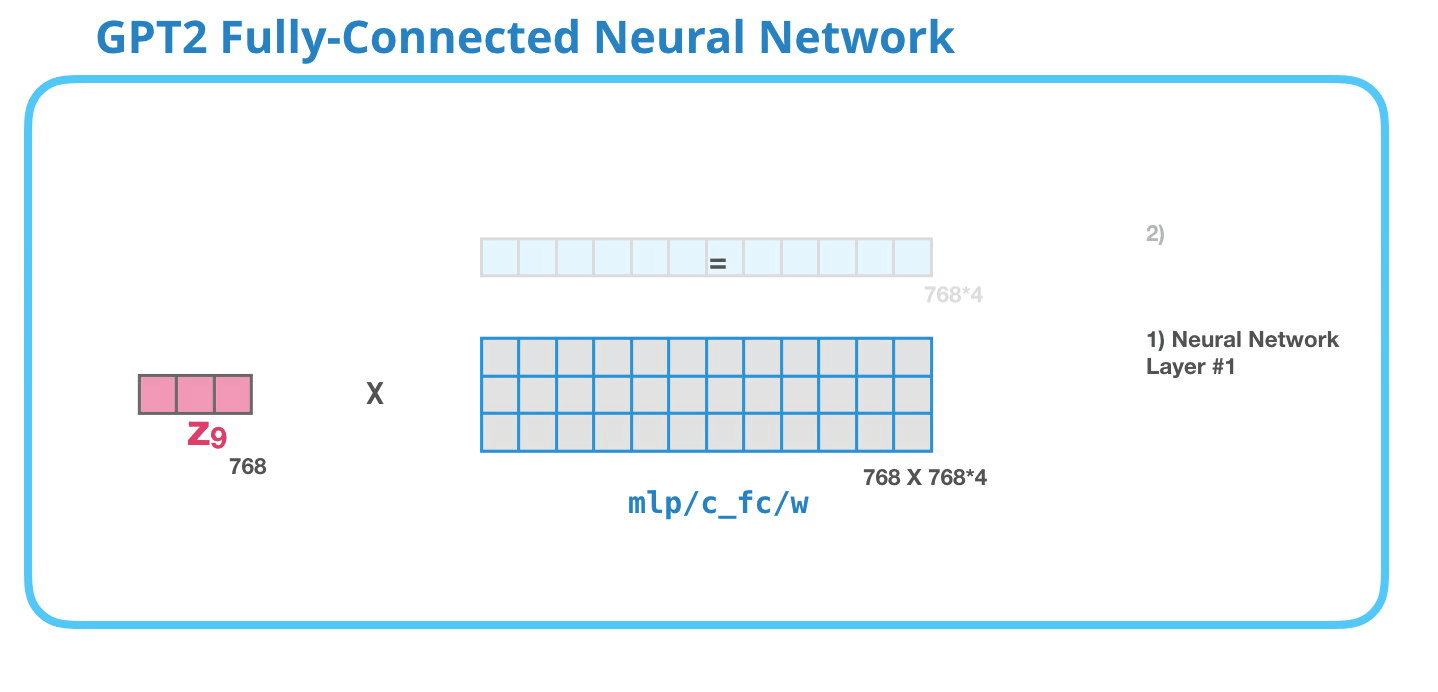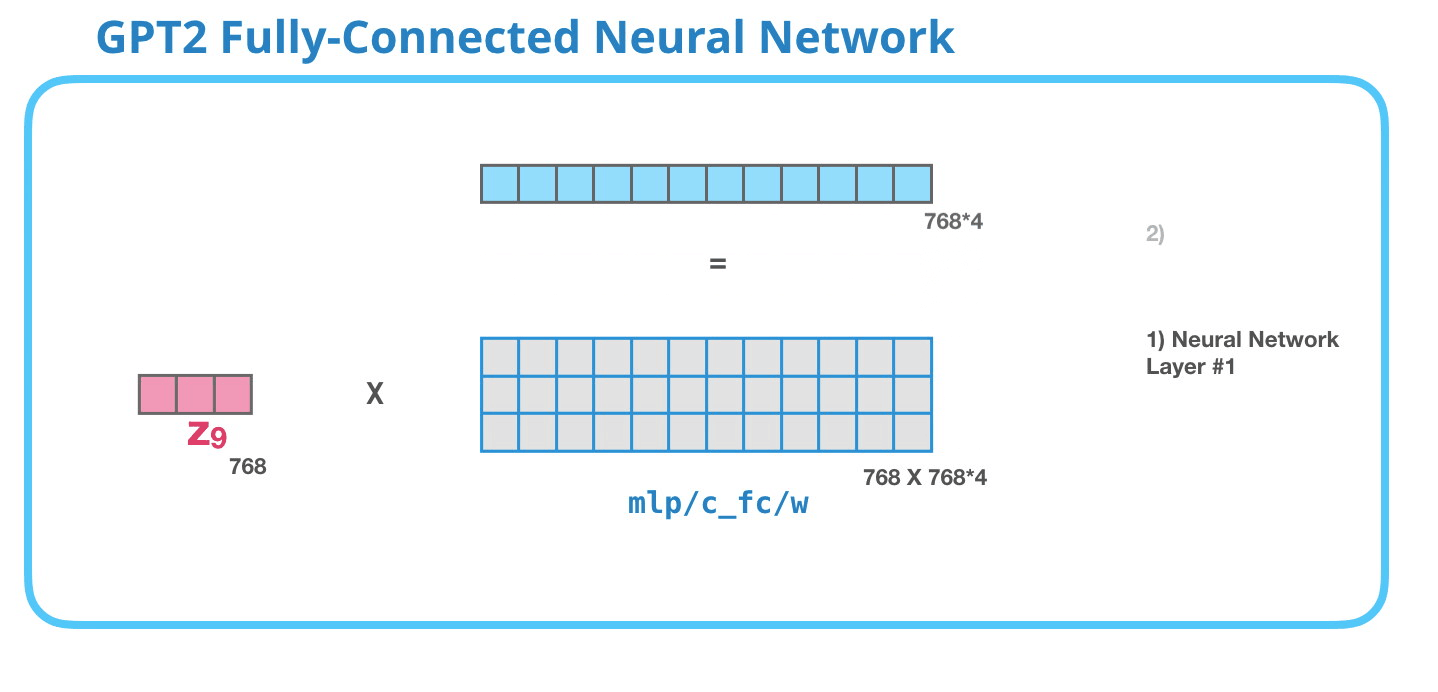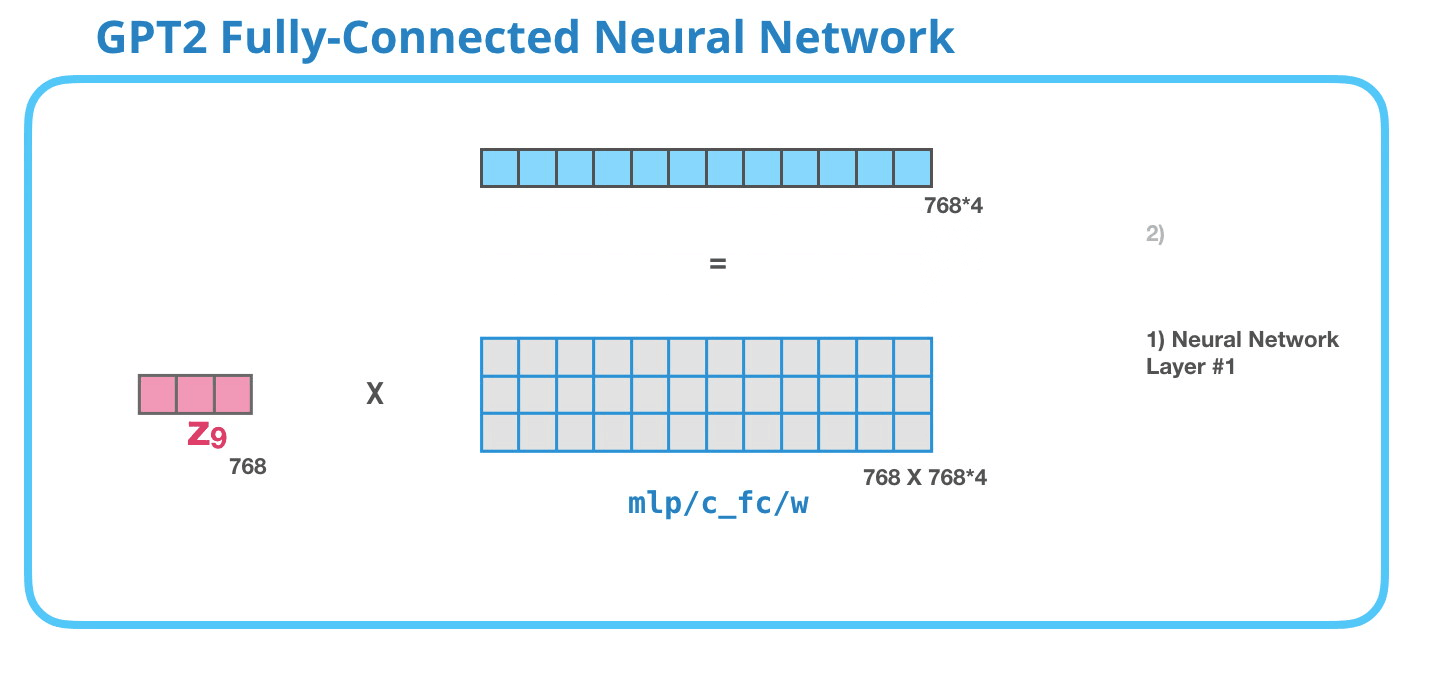
这张动图展示 attention 子层之后的下一块:前馈网络。GPT-2 block 里的前馈网络常被叫作 MLP。它通常由两层线性层组成,中间加非线性激活函数。第一层会把维度扩大到 4 倍。GPT-2 small 的 hidden size 是 768,所以中间维度是:
4 × 768 = 3072 4\times 768=3072 4×768=3072
这张图里的"第一层"就是把每个 token 的 768 维向量映射到 3072 维。注意,它是对每个位置单独做的,不会在不同 token 之间交换信息。不同 token 之间的信息交换已经由注意力层完成了。
可以这样分工:
text
注意力层:让 token 之间交流。
前馈网络:每个 token 拿着交流后的结果,自己内部继续加工。为什么要先变宽?可以把它想成把一句压缩笔记展开成更大的草稿纸。768 维像是压缩后的摘要,3072 维给模型更大的临时空间,让它能组合出更多中间特征。
比如一个 token 的向量里已经混入了上下文信息:它可能同时包含"这是代词""指向 robot""处在 must obey 的语境里"这些线索。MLP 的第一层可以把这些线索展开成更多组合特征,例如:
text
是否像主语
是否和前文实体有关
是否处在规则/命令语境中
是否应该影响下一个动词选择这些特征不是人工标注出来的,而是训练过程中通过权重自动学出来的。
常见形式是:
M L P ( x ) = W 2 σ ( W 1 x + b 1 ) + b 2 \mathrm{MLP}(x)=W_2\ \sigma(W_1x+b_1)+b_2 MLP(x)=W2 σ(W1x+b1)+b2
其中 σ \sigma σ 是激活函数。GPT-2 使用 GELU,而上一篇 Transformer 里常讲的是 ReLU。它们的作用都是引入非线性。
如果没有激活函数,两层线性变换:
W 2 ( W 1 x ) W_2(W_1x) W2(W1x)
可以合并成一个新的线性变换:
W ′ x W'x W′x
这样堆很多层也只是更大的线性变换,表达能力会弱很多。GELU 像一道"软门",它会根据数值大小决定哪些特征更该通过,哪些特征该弱化。
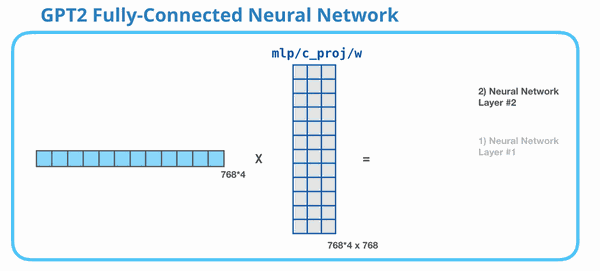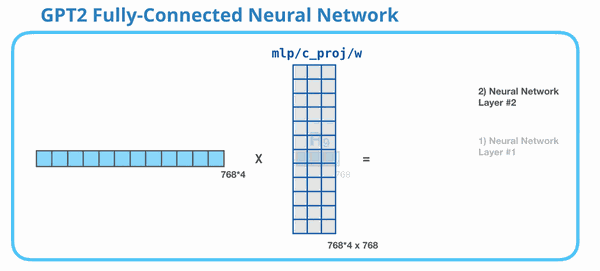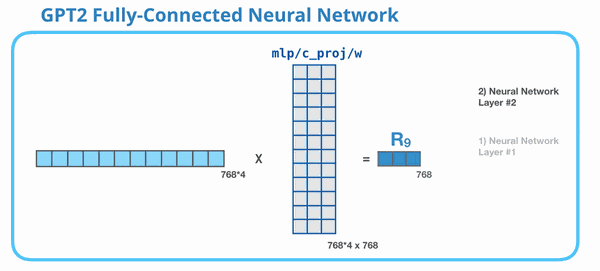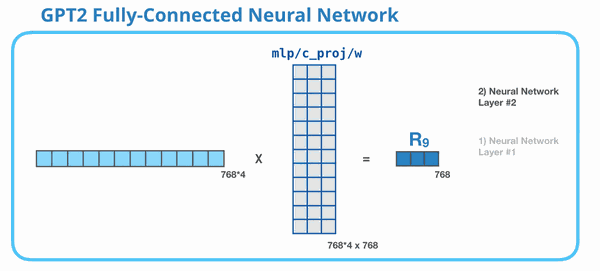
这张动图展示 MLP 的第二层:把 3072 维再压回 768 维。为什么必须压回 768?因为整个 GPT-2 block 的输入输出维度要保持一致。下一层 Transformer block 仍然期待每个 token 是 768 维。
所以 MLP 的完整形状是:
768 → 3072 → 768 768\rightarrow 3072\rightarrow 768 768→3072→768
第一步扩展,第二步压回。扩展提供更大的计算空间,压回保证和模型主干维度对齐。
如果用代码风格描述,就是:
text
x: B x T x 768
Linear: B x T x 3072
GELU: B x T x 3072
Linear: B x T x 768注意这里一直是 B × T B\times T B×T 个位置分别处理。MLP 不会让第 3 个 token 直接看第 1 个 token,它只加工自己位置上的向量。这个向量之所以已经有上下文,是因为前面的注意力层已经把上下文混进来了。
前馈网络和注意力的分工可以这样记:
text
注意力:让不同 token 之间交换信息。
前馈网络:在每个 token 自己的位置上加工已经混合好的信息。所以一个 GPT-2 block 的内部节奏可以理解为:
text
先交流,再思考。注意力负责交流,MLP 负责把交流后的信息进一步消化。
28. 一个 GPT-2 block 里有哪些权重
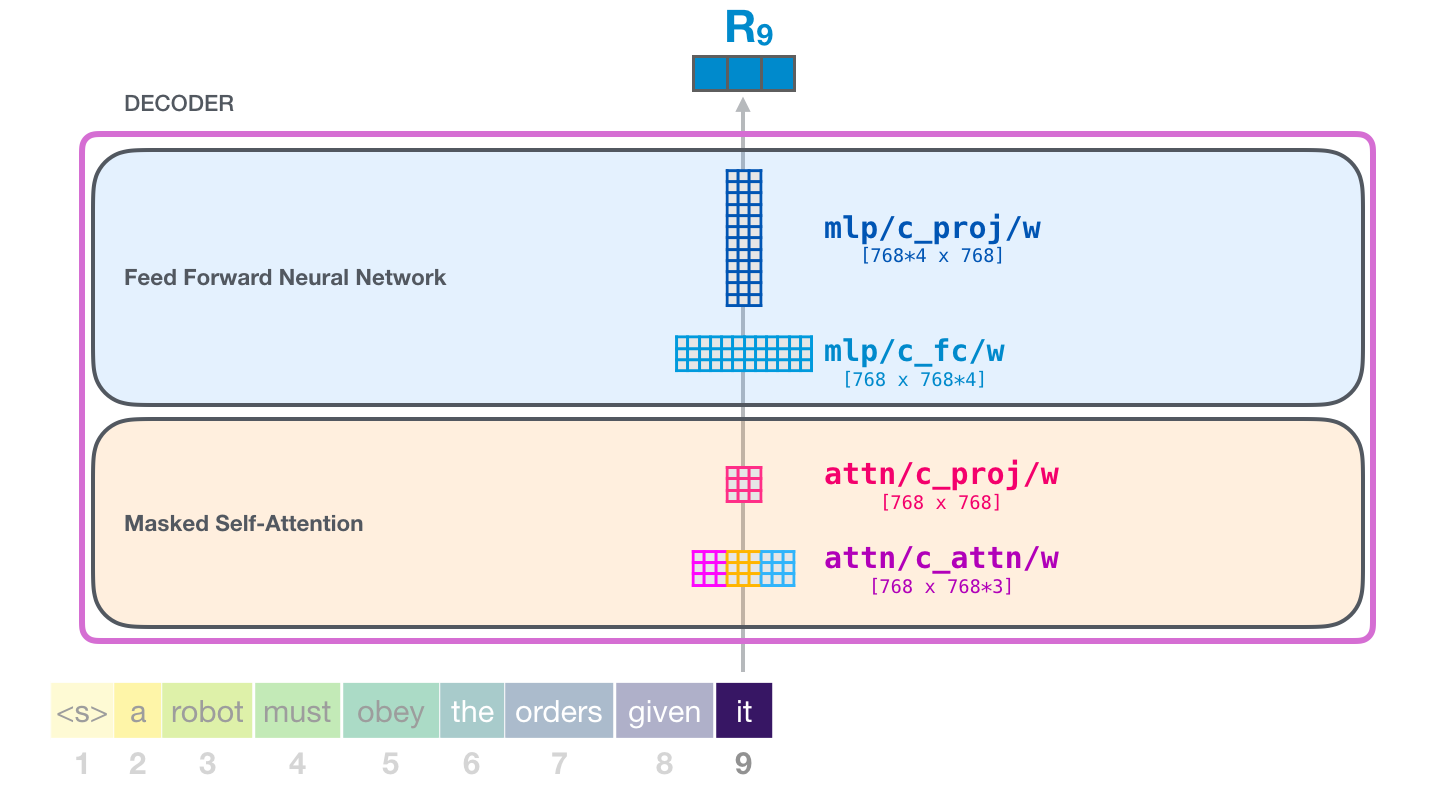
这张图是在把一个 GPT-2 block 里真正需要训练的权重摊开给你看。前面几章讲的 QKV、输出投影、MLP,都不是临时计算出来的魔法,而是由这些权重矩阵控制的。
每个 GPT-2 block 里都有几组重要权重:
text
QKV 投影权重
注意力输出投影权重
MLP 第一层权重
MLP 第二层权重
LayerNorm 相关参数把它们和前面章节对应起来:
text
QKV 投影权重:第 22 章,一次性生成 Q、K、V。
注意力输出投影权重:第 26 章,把多个头的结果融合回 768 维。
MLP 第一层权重:第 27 章,把 768 维扩展到 3072 维。
MLP 第二层权重:第 27 章,把 3072 维压回 768 维。
LayerNorm 参数:稳定每个子层输入的数值范围。这些权重每一层都有一套。第 1 层的 QKV 矩阵和第 10 层的 QKV 矩阵不是同一个。层数越多,重复这样的 block 越多,参数量也越大。
为什么每层不共享同一套权重?因为不同层可以承担不同加工阶段。低层可能更关注局部词形、短距离搭配,高层可能更关注长距离依赖、语义结构、生成风格。虽然不能机械地说"第几层一定学什么",但每层有自己的权重,给了模型分阶段处理语言的能力。
以 GPT-2 small 为例,一个 block 里主要矩阵的大致规模是:
text
QKV 投影:768 x 2304
输出投影:768 x 768
MLP 第一层:768 x 3072
MLP 第二层:3072 x 768这还没算 bias 和 LayerNorm。单个 block 就已经有很多参数,而 GPT-2 small 有 12 个 block,所以参数量会迅速累积。
这张图还帮助我们理解"训练到底在训练什么"。训练不是把一句句文本存进模型,而是在不断调整这些矩阵里的数字。每次预测下一个 token 错了,loss 变大,反向传播就会给这些权重一个修改方向。
29. 全模型共享的词向量和位置向量
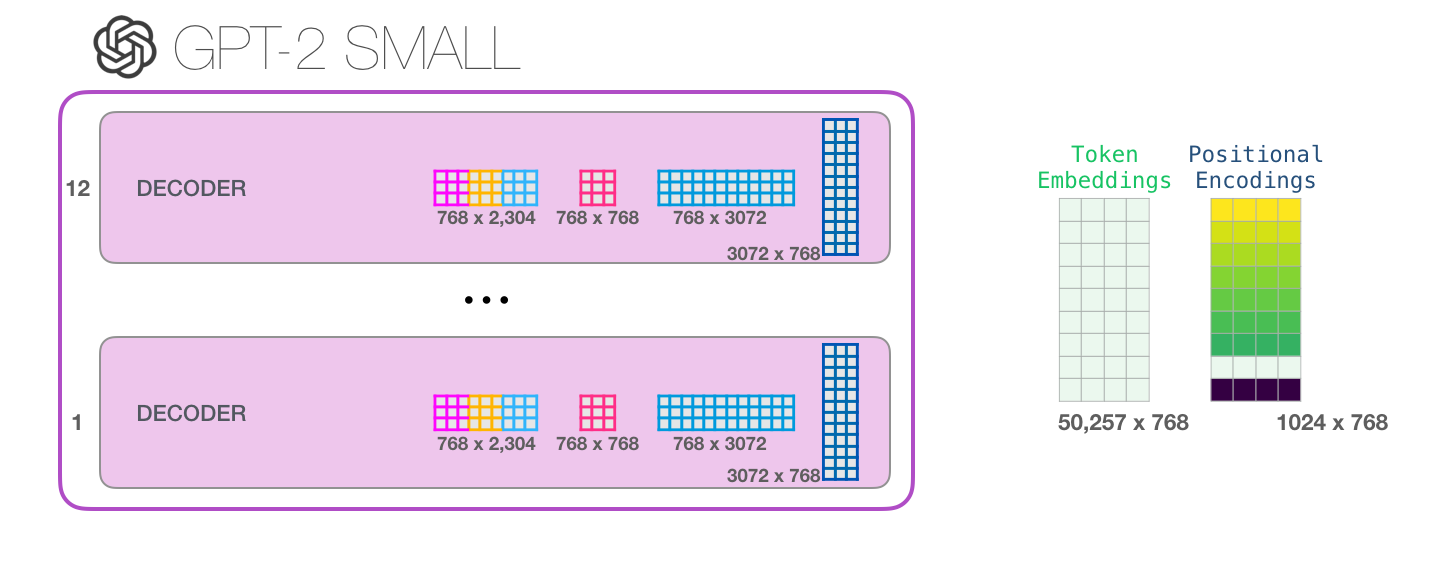
这张图把视角从"一个 block"拉回"整个 GPT-2 模型"。除了每个 block 自己的权重,模型整体还有两张非常基础的表:
text
token embedding 矩阵
positional embedding 矩阵token embedding 负责"这个 token 是谁",positional embedding 负责"它在第几个位置"。输入时两者相加:
x t = E token i d t + E pos t x_t=E_{\text{token}}id_t+E_{\text{pos}}t xt=Etokenidt+Epost
比如输入序列是:
text
The robot must模型会做三件事:
text
The -> 查 token embedding -> 加位置0 embedding
robot -> 查 token embedding -> 加位置1 embedding
must -> 查 token embedding -> 加位置2 embedding这样每个 token 既有"身份信息",也有"位置信息"。如果没有位置向量,模型很难区分:
text
robot must obey和:
text
obey must robot因为它们包含的 token 类似,但顺序不同。
这张图还在表达一个重要事实:embedding 矩阵本身也有大量参数。GPT-2 的词表大约是 50257,GPT-2 small 的隐藏维度是 768,所以 token embedding 大小约为:
50257 × 768 50257\times 768 50257×768
这已经是几千万个参数。也就是说,模型一开始把 token 变成向量的那张表,本身就是训练中非常重要的一部分。
输出时 GPT-2 还会使用词向量矩阵把隐藏向量映射回词表分数,这叫权重共享或权重绑定。直观理解是:
text
输入时:用词向量表把 token 编号变成语义坐标。
输出时:用同一张语义坐标表判断当前隐藏向量最像哪个 token。权重绑定的直觉是:既然词向量矩阵学会了每个 token 在语义空间中的坐标,那么输出时也可以用同一套坐标去判断"当前隐藏向量最像哪个 token"。
例如最后一层得到一个隐藏向量 h t h_t ht。模型要判断下一个 token 是谁,就把它和词表里每个 token 的向量做匹配,得到 logits:
l o g i t s = h t E token ⊤ logits=h_tE_{\text{token}}^\top logits=htEtoken⊤
如果 h t h_t ht 和 robot 的词向量方向更接近,robot 的 logit 就会更高;如果和 the 更接近,the 的 logit 就会更高。最后再经过 softmax 或采样策略,选出下一个 token。
把第 28 章和第 29 章合起来看,GPT-2 的可训练权重主要分成两类:
text
全局表:token embedding、position embedding。
每层 block 权重:QKV、输出投影、MLP、LayerNorm。文本进入模型时先查全局表,之后一层层通过 block 权重加工,最后再回到词表空间预测下一个 token。这就是 GPT-2 从文字到概率分布的主干路径。
30. 参数量为什么这么大
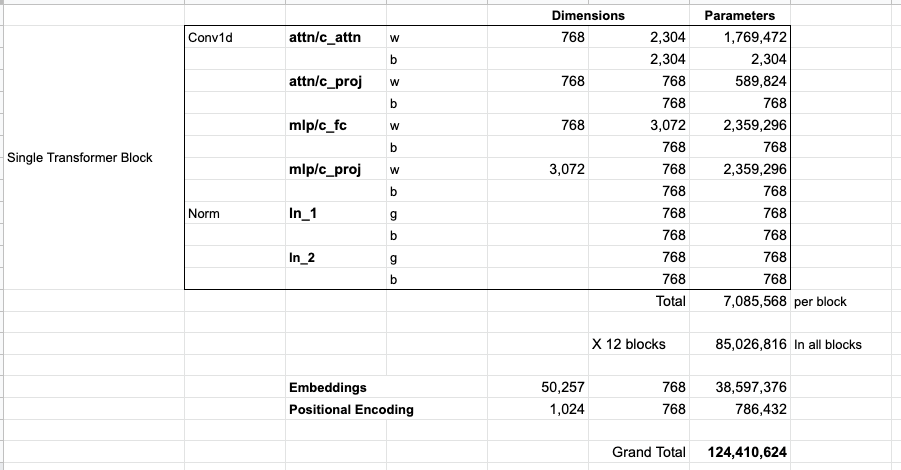
这张图是一张参数量统计表。普通读者第一次看会觉得全是缩写:attn/c_attn、mlp/c_fc、ln_1、w、b、g。其实它只是在回答一个问题:GPT-2 small 里面到底有多少个可以训练的数字?
先把表格的列名翻译一下。
text
Dimensions:这个权重矩阵的形状。
Parameters:这一项有多少个可训练数字。
w:weight,权重矩阵。
b:bias,偏置。
g:gamma,LayerNorm 里的缩放参数。图里第一列写 Conv1d,这个名字很容易误导。这里不是图像卷积里的那种卷积。在 OpenAI GPT-2 早期代码里,Conv1D 基本可以当成线性层理解,也就是:
y = x W + b y=xW+b y=xW+b
所以看到 Conv1d 时,可以先把它理解成"一个线性变换层"。
表格分两大块:
text
Single Transformer Block:一个 Transformer block 里面的参数。
Embeddings / Positional Encoding:整个模型共享的词向量表和位置向量表。GPT-2 small 有 12 个 Transformer block,所以表格先算一个 block 有多少参数,再乘以 12。
30.1 attn/c_attn:一次性生成 Q、K、V
表格第一行是:
text
attn/c_attn w 768 x 2304 = 1,769,472
attn/c_attn b 2304 = 2,304attn 表示 attention,c_attn 可以理解成"注意力里的 QKV 合并投影层"。第 22 章已经讲过,GPT-2 不是分别用三层生成 Q、K、V,而是一次性从 768 维投影到 2304 维:
2304 = 3 × 768 2304=3\times 768 2304=3×768
其中:
text
前 768 维:Query
中 768 维:Key
后 768 维:Value权重矩阵形状是:
768 × 2304 768\times 2304 768×2304
所以参数量是:
768 × 2304 = 1 , 769 , 472 768\times 2304=1,769,472 768×2304=1,769,472
偏置 b 是每个输出维度一个偏置。输出有 2304 维,所以偏置有:
2304 2304 2304
这一项就是表格里的 2,304。
30.2 attn/c_proj:把多头注意力结果投影回模型维度
接下来是:
text
attn/c_proj w 768 x 768 = 589,824
attn/c_proj b 768 = 768c_proj 里的 proj 是 projection,投影。第 26 章讲过,12 个头每个输出 64 维,拼接后回到:
12 × 64 = 768 12\times 64=768 12×64=768
但拼接只是把 12 份结果放在一起,还需要一个输出投影矩阵把它们融合。这个矩阵输入 768 维,输出还是 768 维:
768 × 768 = 589 , 824 768\times 768=589,824 768×768=589,824
偏置是 768 个,因为输出是 768 维。
30.3 mlp/c_fc:前馈网络第一层,把 768 维扩展到 3072 维
下一项是:
text
mlp/c_fc w 768 x 3072 = 2,359,296
mlp/c_fc b 表中按 768 计mlp 就是第 27 章的前馈网络。c_fc 可以理解成 MLP 的第一层。它把每个 token 的 768 维向量扩展到 3072 维:
3072 = 4 × 768 3072=4\times 768 3072=4×768
权重参数量是:
768 × 3072 = 2 , 359 , 296 768\times 3072=2,359,296 768×3072=2,359,296
为什么要扩展到 3072?因为注意力层已经把上下文信息混进每个 token 的向量里,MLP 接着需要更大的临时空间做非线性加工。可以把它理解成"先把压缩笔记展开到大草稿纸上"。
这里有一个小提醒:常见 GPT-2 实现里,mlp/c_fc 的 bias 通常对应输出维度 3072;这张图的表格按 768 计入,所以如果你以后用代码打印参数量,可能会看到和图中总数略有差异。这个差异不影响理解主线:这一层的大头参数来自 768 x 3072 这个权重矩阵。
30.4 mlp/c_proj:前馈网络第二层,把 3072 维压回 768 维
再下一项是:
text
mlp/c_proj w 3072 x 768 = 2,359,296
mlp/c_proj b 768 = 768这就是 MLP 的第二层。第 27 章讲过,MLP 的形状是:
768 → 3072 → 768 768\rightarrow 3072\rightarrow 768 768→3072→768
第一层展开,第二层压回。第二层权重参数量是:
3072 × 768 = 2 , 359 , 296 3072\times 768=2,359,296 3072×768=2,359,296
可以看到,MLP 两个大矩阵加起来已经非常大:
2 , 359 , 296 + 2 , 359 , 296 = 4 , 718 , 592 2,359,296+2,359,296=4,718,592 2,359,296+2,359,296=4,718,592
这说明 GPT-2 block 里不只是注意力层有很多参数,MLP 也占了很大一部分。
30.5 ln_1 和 ln_2:LayerNorm 的缩放和偏移
表格里的:
text
Norm ln_1 g 768
Norm ln_1 b 768
Norm ln_2 g 768
Norm ln_2 b 768ln 是 LayerNorm。一个 GPT-2 block 里通常有两个 LayerNorm:一个在 attention 前后相关位置,一个在 MLP 前后相关位置。
LayerNorm 不像大矩阵那样有几十万、几百万参数。它主要有两组长度为 768 的可训练参数:
text
g:缩放参数,控制每个维度放大或缩小。
b:偏移参数,控制每个维度整体平移。每个 LayerNorm 有:
768 + 768 = 1536 768+768=1536 768+768=1536
两个 LayerNorm 合起来:
1536 × 2 = 3072 1536\times 2=3072 1536×2=3072
和百万级的大矩阵相比,LayerNorm 参数很少,但它对训练稳定性很重要。它像是在每个关键步骤前后把数值整理到更合适的范围。
30.6 一个 block 总共有多少参数
按照图中表格的统计方式,一个 block 总数是:
text
7,085,568 parameters per block也就是一个 Transformer block 里大约 708 万个可训练数字。GPT-2 small 有 12 个 block,所以:
7 , 085 , 568 × 12 = 85 , 026 , 816 7,085,568\times 12=85,026,816 7,085,568×12=85,026,816
这就是表格里的:
text
X 12 blocks = 85,026,816这还没有算词向量表和位置向量表。
30.7 Embeddings:词表里的每个 token 都有一个 768 维向量
表格下面写:
text
Embeddings 50,257 x 768 = 38,597,376这里的 50,257 是 GPT-2 的词表大小,也就是 tokenizer 里大约有 50,257 个 token。每个 token 都有一个 768 维向量,所以 token embedding 矩阵是:
50257 × 768 50257\times 768 50257×768
参数量就是:
50257 × 768 ≈ 38 , 600 , 000 50257\times 768\approx 38,600,000 50257×768≈38,600,000
更精确地算:
50257 × 768 = 38 , 597 , 376 50257\times 768=38,597,376 50257×768=38,597,376
这说明 embedding 本身就占了相当多参数。模型要知道每个 token 的语义坐标,这张大表就是基础。
30.8 Positional Encoding:1024 个位置也各有一个 768 维向量
表格最后还有:
text
Positional Encoding 1024 x 768 = 786,432GPT-2 的上下文长度是 1024 token。它给每个位置也准备一个 768 维的位置向量:
text
位置 0:768 维
位置 1:768 维
...
位置 1023:768 维所以参数量是:
1024 × 768 = 786 , 432 1024\times 768=786,432 1024×768=786,432
这就是位置编码表。它告诉模型每个 token 在序列里的位置。
30.9 Grand Total:为什么最后是 124,410,624
最后把三部分加起来:
text
12 个 Transformer block:85,026,816
token embedding: 38,597,376
position embedding: 786,432总数是:
85 , 026 , 816 + 38 , 597 , 376 + 786 , 432 = 124 , 410 , 624 85,026,816+38,597,376+786,432=124,410,624 85,026,816+38,597,376+786,432=124,410,624
所以表格最后写:
text
Grand Total = 124,410,624也就是大约 1.24 亿个参数。GPT-2 small 有时也被叫作 117M 或 124M 级别模型,具体数字会因为统计口径和实现细节略有差异。理解时不必纠结最后几百万的差别,关键是看出参数主要来自哪里:
text
第一大块:12 个 Transformer block,约 8500 万。
第二大块:token embedding,约 3860 万。
第三小块:position embedding,约 79 万。如果用一句话理解这张表:GPT-2 的"大"不是因为它藏了很多人工规则,而是因为它有很多巨大的矩阵;训练就是不断调整这些矩阵里的数字,让模型更会根据前文预测下一个 token。
31. GPT-2 的完整预测路径
把上面的所有步骤串起来,一次预测可以写成:
x t = E token i d t + E pos t x_t=E_{\text{token}}id_t+E_{\text{pos}}t xt=Etokenidt+Epost
H = G P T 2 B l o c k s ( X ) H=\mathrm{GPT2Blocks}(X) H=GPT2Blocks(X)
l o g i t s t = h t E token ⊤ + b logits_t=h_tE_{\text{token}}^\top+b logitst=htEtoken⊤+b
P ( x t + 1 ∣ x ≤ t ) = s o f t m a x ( l o g i t s t ) P(x_{t+1}\mid x_{\le t})=\mathrm{softmax}(logits_t) P(xt+1∣x≤t)=softmax(logitst)
这里 h t h_t ht 是最后一层第 t t t 个位置的隐藏向量。模型用它预测第 t + 1 t+1 t+1 个 token。
训练时,所有位置都可以同时计算 loss:
L o s s = − ∑ t log P ( x t + 1 ∣ x ≤ t ) \mathrm{Loss}=-\sum_t \log P(x_{t+1}\mid x_{\le t}) Loss=−t∑logP(xt+1∣x≤t)
梯度下降会沿着这个 loss 反向传播,更新 embedding、QKV、MLP、LayerNorm 等所有可训练参数。
32. GPT-2 可以做翻译吗
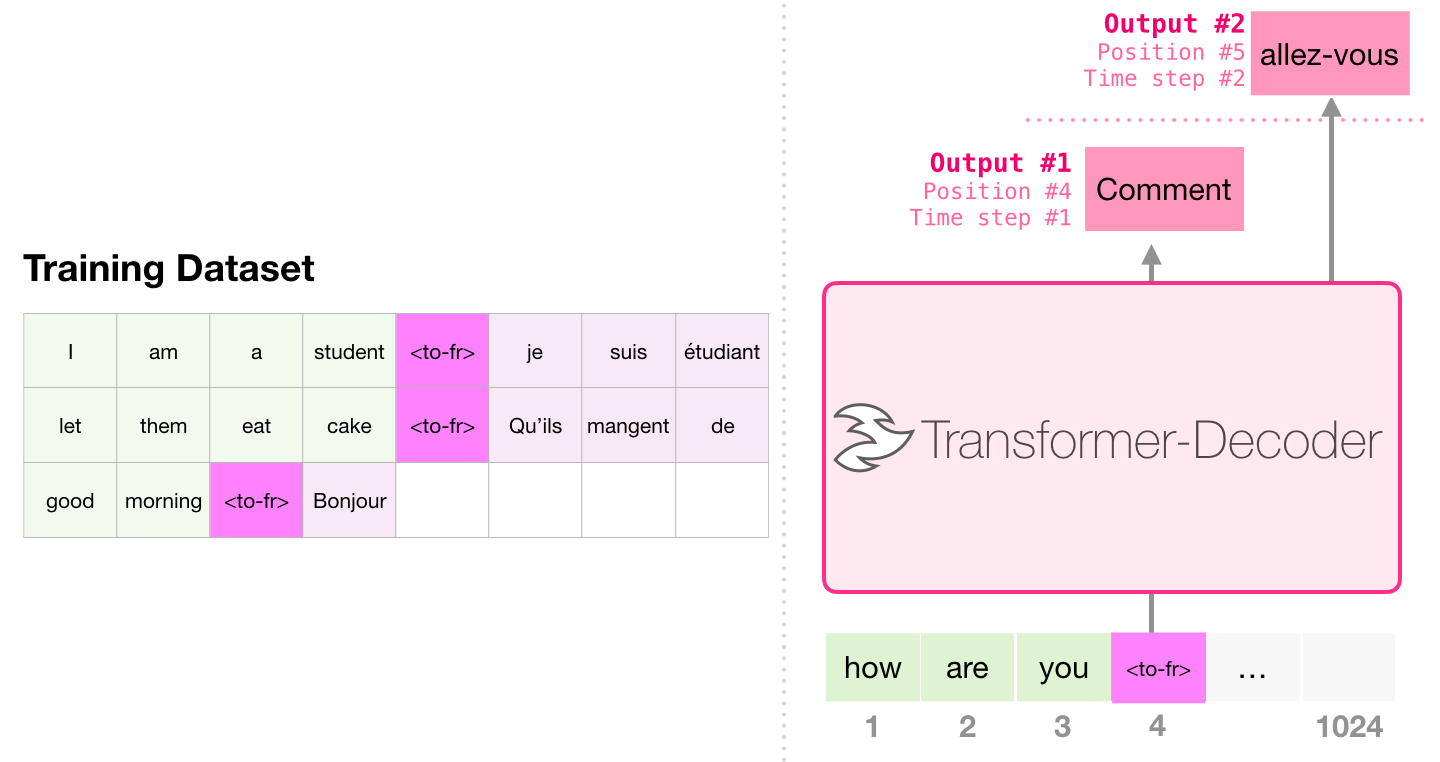
原始 Transformer 翻译模型用了编码器和解码器,但 decoder-only 模型也可以做翻译。方法是把任务写成一段连续文本,例如:
text
Translate French to English:
French: Je suis etudiant.
English:模型继续生成英文部分。它本质上还是做下一个 token 预测,只是提示词把任务描述清楚了。
这就是后来很多 LLM 的统一范式:把各种任务都包装成文本输入,再让模型续写答案。
33. 摘要任务:读文章后生成摘要
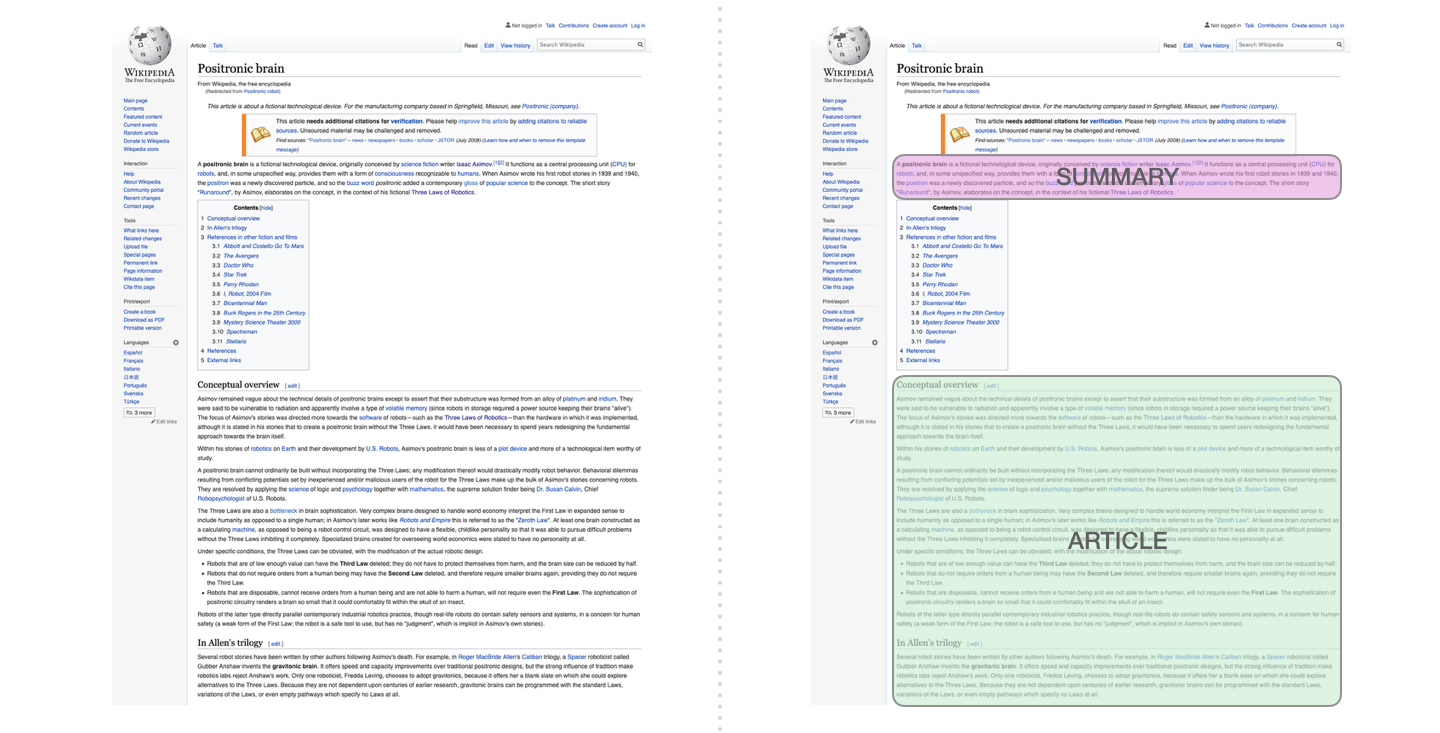
摘要也可以看成生成任务。输入是一篇文章,输出是摘要。decoder-only 模型可以把它们拼成一个序列:
text
Article: ...
Summary: ...训练时模型学习在 Summary: 后面生成正确摘要。推理时给它文章和 Summary:,让它继续写。
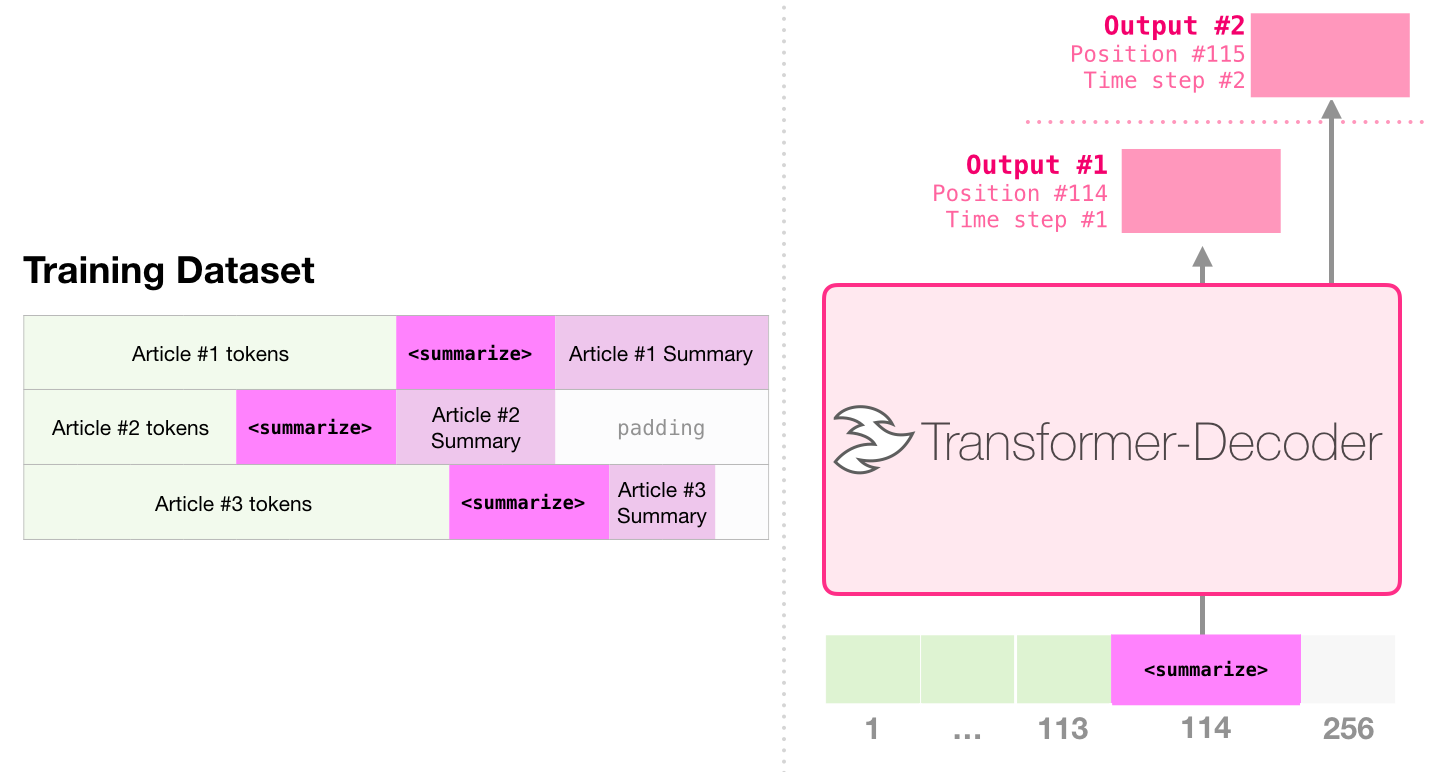
这和翻译的逻辑一样:模型没有单独的"摘要按钮",它仍然只是在预测下一个 token。区别在于提示词和训练数据让它学会了某种输出格式。
这种思想后来发展成 instruction tuning,也就是用很多"指令 -> 回答"的数据训练模型,让模型更会听任务要求。
34. 迁移学习:先学语言,再学任务
原文提到 decoder-only Transformer 也可以先做语言建模预训练,再针对摘要等任务微调。这个思想非常重要。
预训练阶段像广泛读书:模型从海量文本里学习语法、事实、风格、常识和模式。微调阶段像专项训练:给它某一类任务样例,让它把通用语言能力转成具体任务能力。
用公式看,预训练目标是:
max ∑ t log P ( x t ∣ x < t ) \max \sum_t \log P(x_t\mid x_{<t}) maxt∑logP(xt∣x<t)
微调仍然可以是同一种下一个 token 预测,只是训练文本换成了任务格式:
text
Question: ...
Answer: ...这就是 GPT 系列能从"语言模型"走向"通用助手"的关键路线之一。
35. 音乐生成:把音符也当成 token
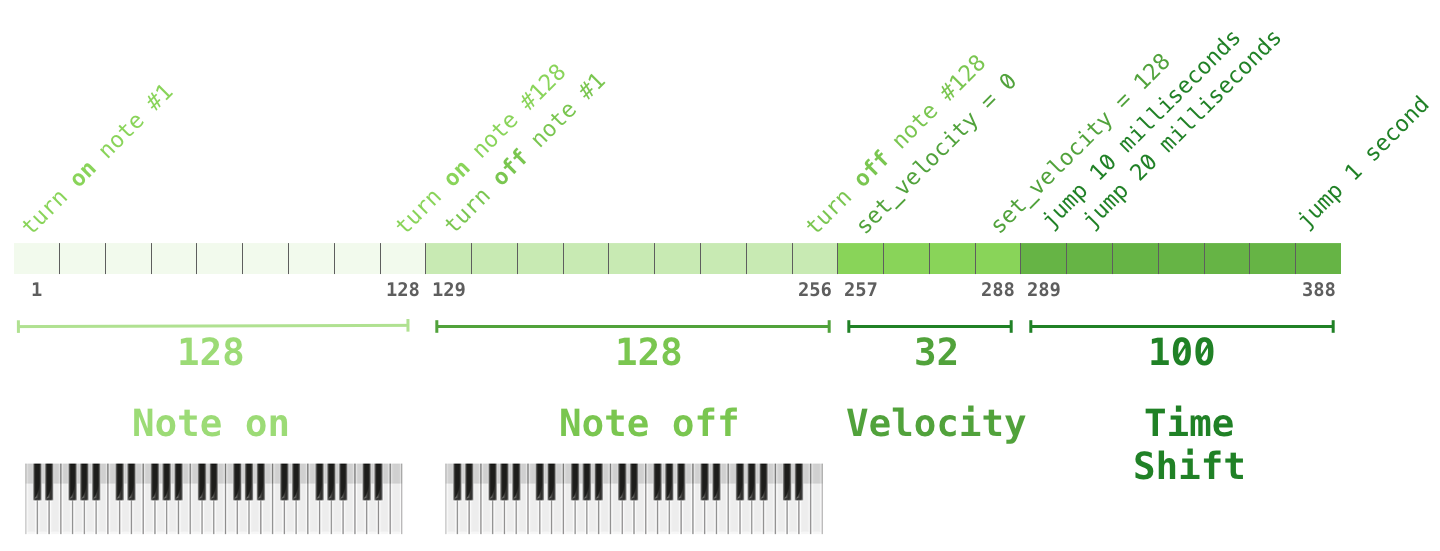
语言模型不一定只能处理自然语言。只要能把对象表示成离散序列,就可以尝试用类似方法建模。音乐里可以把音符、力度、时间等事件编码成 token。

例如钢琴演奏不只有"按了哪个键",还包括"什么时候按""按得多重""什么时候松开"。这些事件可以转成序列:
text
NOTE_ON_C4
VELOCITY_80
TIME_SHIFT_10
NOTE_OFF_C4模型看到前面的音乐事件,就预测下一个音乐事件。
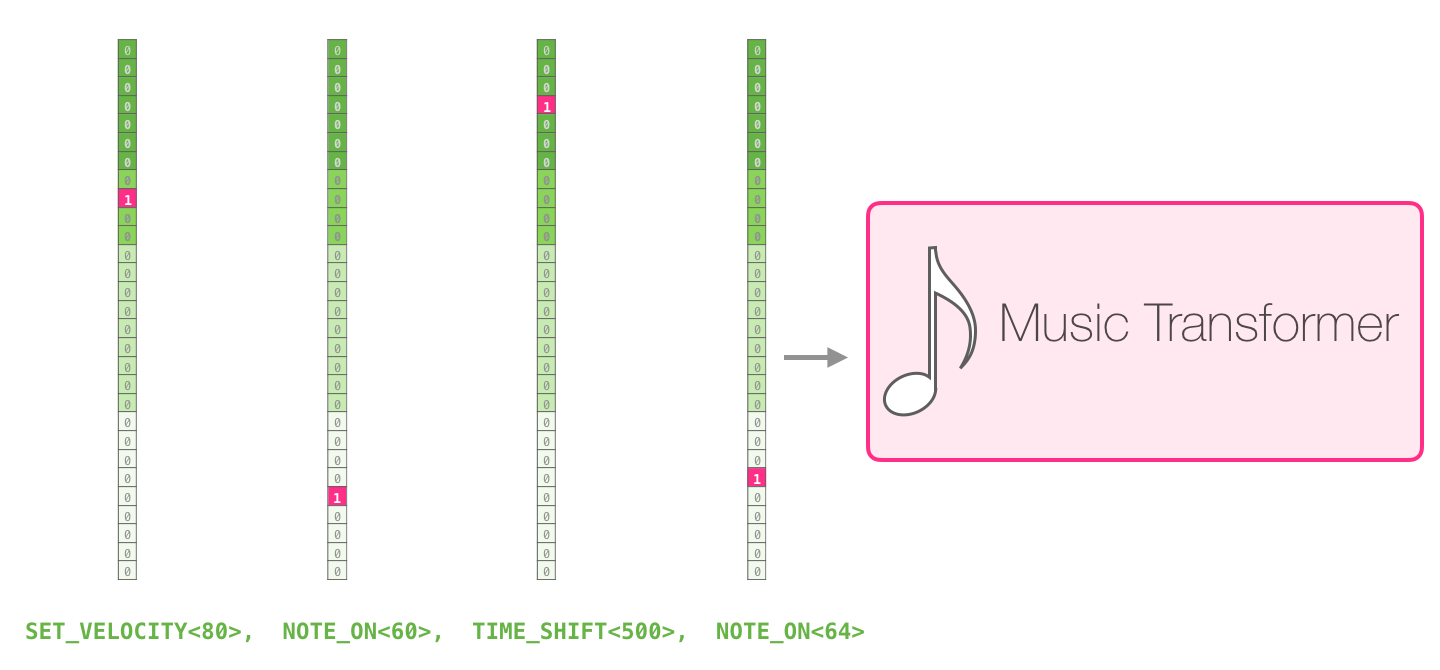
这和文本里的 token 序列非常像。区别只是词表不再是文字片段,而是音乐事件。
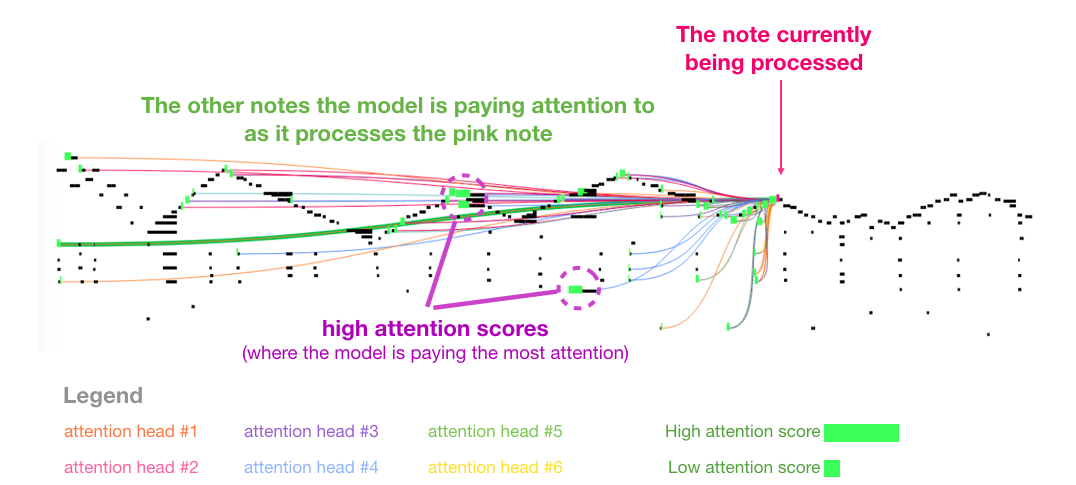
自注意力在音乐里也有用,因为音乐有重复主题、节奏呼应、旋律回归。模型可以在后面的音符处关注前面相似的旋律片段,从而生成更有结构的音乐。
36. GPT-2 和现代 LLM 的关系
GPT-2 不是今天最强的 LLM,但它把一条非常重要的路线讲清楚了:
text
decoder-only Transformer
+ causal masked self-attention
+ 大规模文本预训练
+ 下一个 token 预测后来的 GPT-3、LLaMA、Mistral 等模型,在大方向上仍然是 decoder-only Transformer。它们会加入很多工程改进,比如更好的归一化、RoPE 位置编码、更高效注意力、更大的训练数据、更稳定的优化方法、更长上下文、更强指令微调和人类反馈训练。
但如果从原理链条看,GPT-2 已经包含现代 LLM 的主干:
文本 → token → 向量 → masked attention → 下一个 token 概率 \text{文本} \rightarrow \text{token} \rightarrow \text{向量} \rightarrow \text{masked attention} \rightarrow \text{下一个 token 概率} 文本→token→向量→masked attention→下一个 token 概率
理解 GPT-2,就等于真正跨过了"Transformer 翻译模型"到"现代生成式语言模型"的门槛。
37. 和上一篇 Illustrated Transformer 的逐项对照
| 知识点 | Illustrated Transformer | Illustrated GPT-2 |
|---|---|---|
| 主要任务 | 机器翻译 | 语言建模和生成 |
| 输入输出 | 源句 -> 目标句 | 前文 -> 下一个 token |
| 结构 | Encoder + Decoder | Decoder-only |
| 自注意力 | 编码器可双向看,解码器目标端遮罩 | 全部使用 causal mask |
| 交叉注意力 | 解码器读取编码器输出 | 去掉 |
| 位置编码 | 原文重点讲正弦余弦 | GPT-2 用可学习位置向量 |
| 输出层 | 线性层 + softmax 得到目标词概率 | 隐藏向量映射到词表 logits,再采样 |
| 生成方式 | 解码器逐步生成译文 | 每次生成一个 token 接回输入 |
| 现代延伸 | Transformer 基础结构 | LLM 主流骨架 |
可以把两篇连起来这样理解:
text
第一篇:Transformer 如何通过注意力读写句子。
这一篇:只保留适合生成的解码器部分,并把它训练成下一个 token 预测器。38. 最容易混淆的几个点
word 和 token 不是一回事。为了直观,很多图会写 word,但 GPT-2 实际处理的是 BPE token。一个英文单词可能是一个 token,也可能被拆成多个 token。
logits 和 probability 不是一回事。logits 是 softmax 前的原始分数,probability 是 softmax 后的概率。
attention score 和 attention output 不是一回事。score 决定关注比例,output 是 value 向量按比例混合后的结果。
multi-head 不是多层。多头是在同一层里并行的多个注意力视角;多层是 block 一层层堆叠。
decoder-only 不是原始 Transformer 解码器原封不动拿来用。它去掉了 cross-attention,只保留 masked self-attention 和前馈网络等核心部件。
生成一步 不等于 训练一步。生成时通常一步新增一个 token;训练时可以把一段文本并行处理,只用 mask 控制可见范围。
39. 用一句话复盘 GPT-2
GPT-2 把文本切成 token,把 token 查成向量,加上位置向量后送入一层层只看左边的 Transformer block,最后把当前位置隐藏向量映射成整个词表的概率分布,再选择或抽样下一个 token,把它接回输入,循环往复生成文本。
如果你已经理解上一篇里的 Q、K、V、softmax、多头注意力、残差连接和前馈网络,那么 GPT-2 的关键变化只有三点:
text
只用 decoder-only block
用 causal mask 保证不能看未来
训练目标改成预测下一个 token这三点一连起来,就是现代大语言模型的主线。
来源与许可
本文参考并改写自 Jay Alammar 的 The Illustrated GPT-2。图片来自原文页面,仅用于学习笔记说明。
原文许可为 Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License,即署名、非商业使用、相同方式共享。
相关前置阅读:The Illustrated Transformer。