模糊测试(Fuzz Testing)作为软件安全领域的"重武器",其核心逻辑朴素而有力:通过向目标程序投喂海量随机数据,观察其是否崩溃,从而暴露潜在的漏洞。然而,这种"大力出奇迹"的传统模式正面临前所未有的挑战------投入产出比急剧下降,大量测试资源被消耗在无效路径上。人工智能的介入,正在从**"提高测试深度"与"降低测试噪音"**两个看似矛盾的方向,重塑模糊测试的价值链。
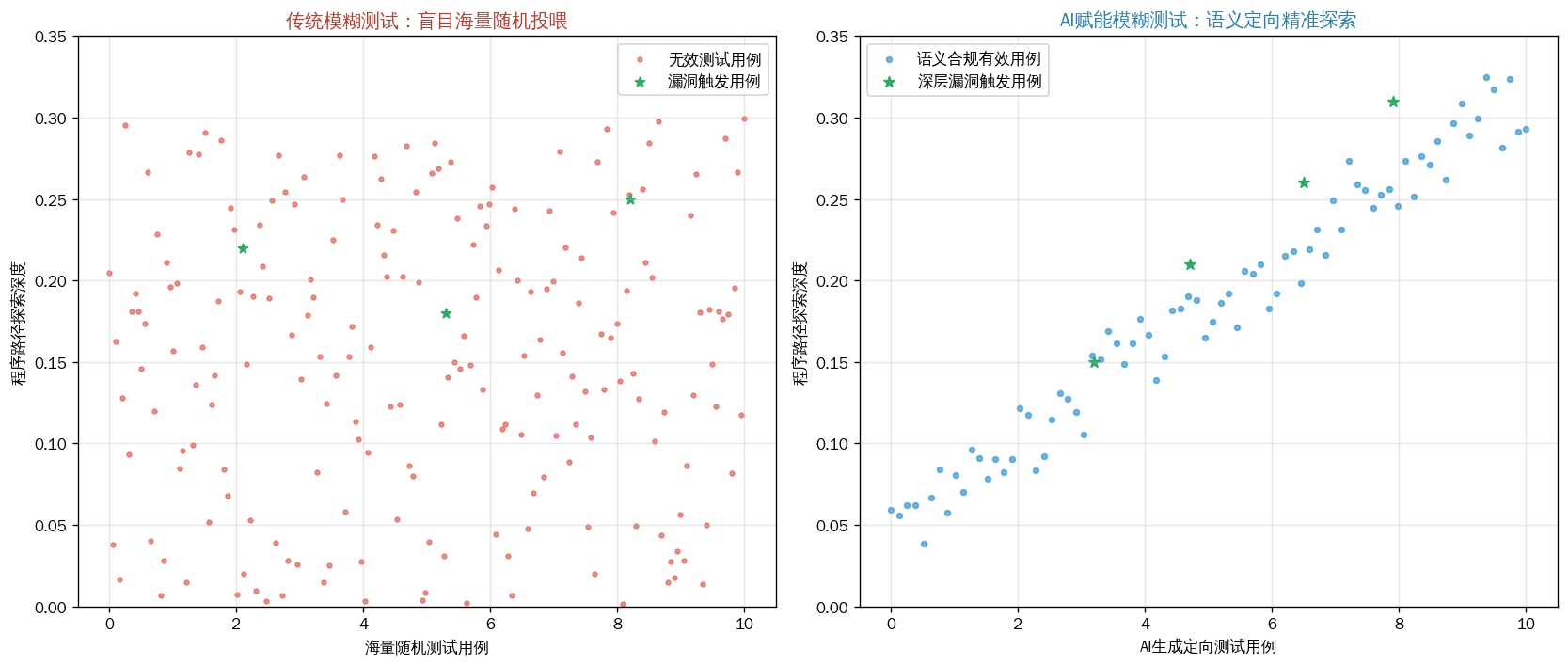
从"跑接口"到"懂业务":AI如何提高模糊测试的深度
传统的自动化模糊测试,尤其是早期的AI辅助测试,大多停留在"接口级"的覆盖。测试工具像一名不知疲倦但缺乏思考的士兵,对着API接口狂轰滥炸,却往往忽略了方法(Method)、头部(Header)、参数(Param)等精细化场景。这些细节场景的组合空间呈指数级增长,人工编写测试用例覆盖所有组合几乎是不可能的任务,导致测试存在大量盲区。
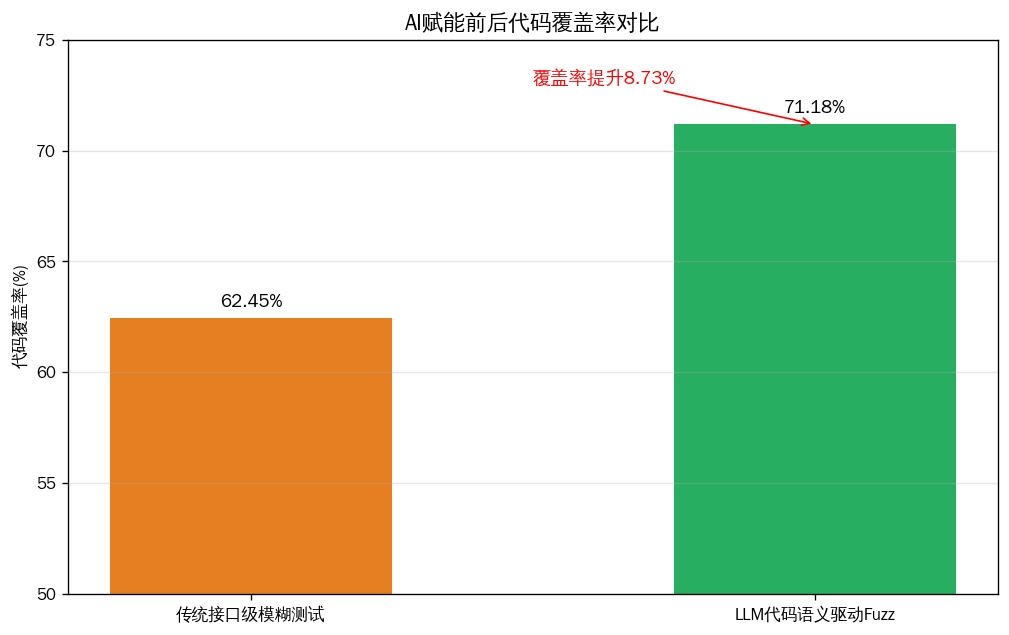
大语言模型(LLM)的代码理解能力正在打破这一僵局。以谷歌的OSS-Fuzz为例,其引入AI后,成功发现了OpenSSL库中一个存在长达20年 的越界内存写入漏洞(CVE-2024-9143)。该漏洞之所以长期潜伏,正是因为其触发条件极为隐蔽,人类编写的现有Fuzz目标根本无法触及。AI通过分析代码仓库中函数间的调用关系、数据流和控制流,能够生成符合特定API使用场景的Fuzz驱动(Harness) 。例如,CodeGraphGPT等系统通过构建代码知识图谱,让AI理解"这些API通常怎么配合使用",从而生成能够覆盖多API交互 场景的测试用例,将代码覆盖率平均提升了8.73%。这意味着,模糊测试不再仅仅是在门口徘徊,而是被AI引导着"登堂入室",深入到业务逻辑的细枝末节中去。
从"大杂烩"到"狙击枪":AI如何降低模糊测试的噪音
传统模糊测试的另一个痛点在于"字典"质量。由于缺乏对输入结构的语义理解,传统字典往往是一个包罗万象的"大杂烩"。测试工具跑了一万条用例,可能只有几条能通过语法校验,其余全是无效输入,不仅浪费算力,还掩盖了真正有价值的异常信号。
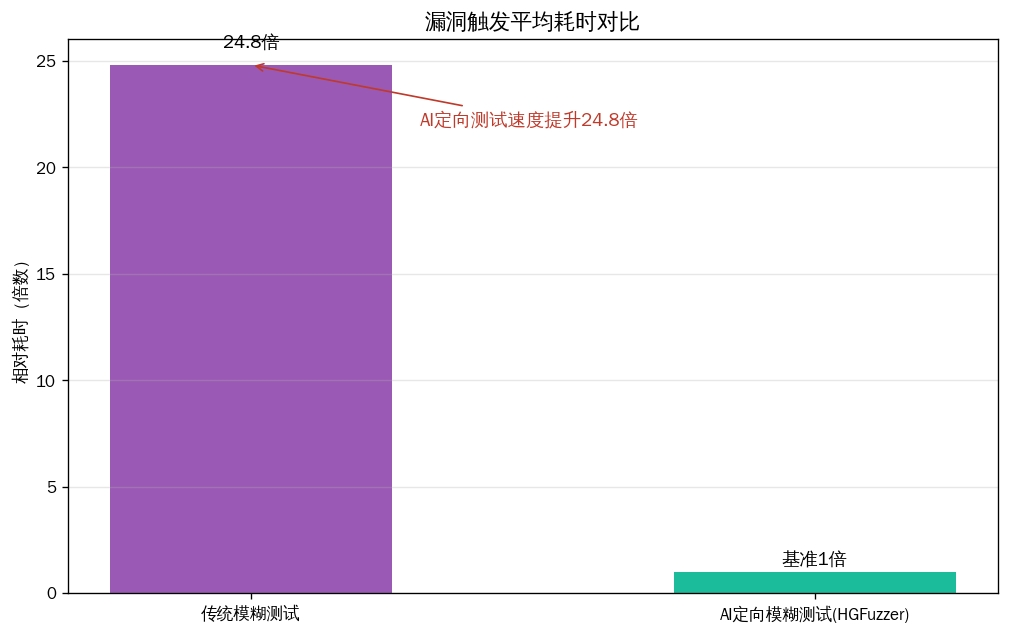
AI的介入,相当于为模糊测试装上了一个"语义过滤器"。通过分析API文档、源代码注释及实际调用示例,AI能够推导出参数的有效取值范围、依赖关系和约束条件,生成极其精准的种子(Seed)和变异策略 。PromeFuzz框架就专注于从代码元数据和文档中提取结构化知识,增强API的语义约束与依赖关系 ,确保生成的Fuzz驱动严格符合语法、遵守API语义规则,并能有效探索程序状态空间。这种转变,使得测试用例的命中率大幅提升。研究表明,基于AI的定向模糊测试(如HGFuzzer)通过生成可达种子和定制变异器,在触发已知漏洞时实现了至少24.8倍 的速度提升,并在实验中成功发现了9个此前未知的CVE漏洞。
结语
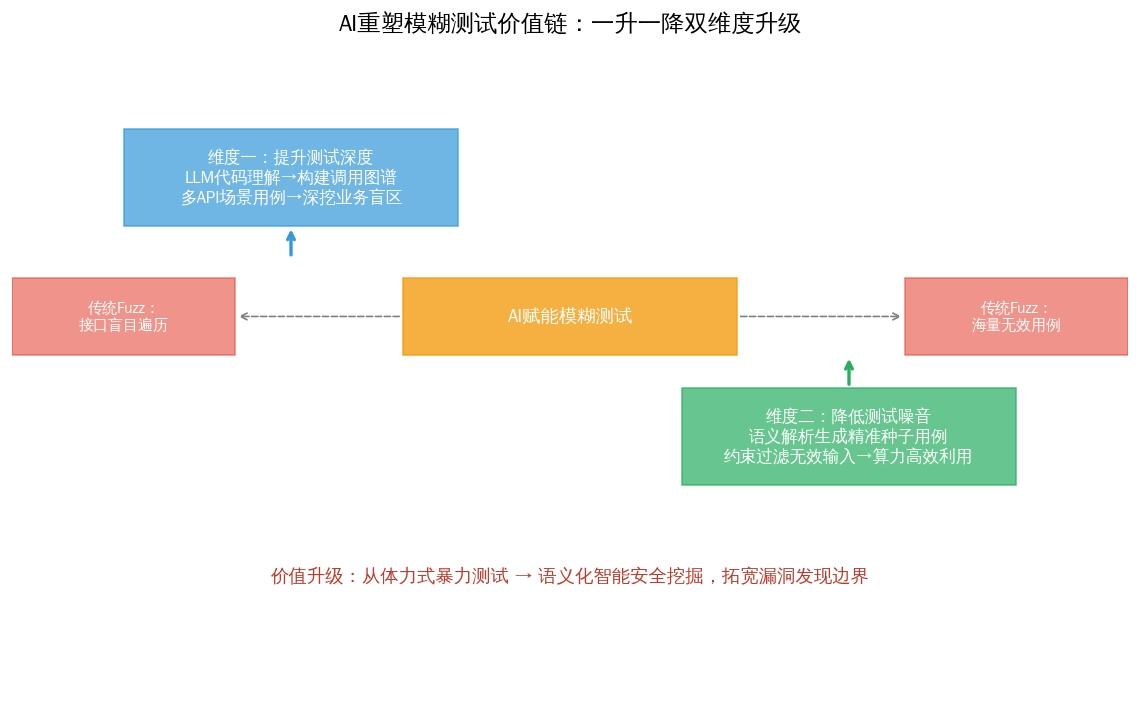
AI赋能下的SRC模糊测试,正在经历一场从"体力活"到"脑力活"的进化。它一方面利用代码语义理解提高 了测试的覆盖深度,挖掘出人类因"太费事"而遗漏的深层漏洞;另一方面又利用知识推理降低了测试的无效噪音,让每一次Fuzz都更具目的性。这种"一升一降"之间,AI不仅让模糊测试变得更聪明、更高效,更重要的是,它重新定义了安全测试的边界------从"能发现什么",进化为"还能发现什么不可能"。