有需要本项目的代码、文档、完整资源,或者需要部署调试的朋友,可以私信博主。
项目从一个现实问题开始
空气质量数据每天都在更新,但真正把这些数据整理成一个能查、能看、能对比、能展示的系统,并不是简单画几张图就能完成。这个项目最初想解决的就是两个问题:一是把全国范围内分散的历史天气与 AQI 数据稳定采集下来,二是把枯燥的表格数据转成更容易理解的动态图表和大屏页面。
我没有把它做成单纯的课程作业式页面,而是按完整数据项目的思路来推进:先做数据源分析,再做采集脚本和异常处理,然后进入清洗、入库、统计、可视化和 Web 集成。项目的主题围绕空气质量指数展开,同时保留了温度、风向、风力、降雨、降雪、污染等级等指标,这些字段组合起来,可以支撑趋势分析、空间对比、极值发现和综合画像。
数据时间跨度覆盖 2020 年 1 月到 2025 年 8 月,规模超过七万条。这样的数据量不算特别大,但已经足够暴露真实项目中常见的问题:网页字段不稳定、部分日期缺失、编码异常、请求失败、数据入库格式不统一、图表交互体验不够好等。把这些问题逐一处理完,系统才具备比较完整的展示价值。
整个开发流程可以理解为一条数据流水线:采集端负责把原始网页数据转为结构化记录,清洗端负责把字段和口径统一,数据库负责保存可复用数据,分析脚本负责沉淀指标,前端页面负责把结果展示出来。这样划分以后,每一层都能独立调试,出问题时也更容易定位,而不是把所有逻辑堆在一个脚本里。
一、数据采集:先把全国城市数据稳定拿下来
采集环节是整个项目的起点。我先从目标天气网站的城市脚本入手,提取城市名称和 areaid 的对应关系,再按照年份和月份构造历史数据地址。这样做的好处是不用手工维护大量 URL,只要城市编码关系稳定,后续就可以批量生成采集任务。
脚本基于 Requests 完成请求,并加入了请求头、随机等待、失败重试和编码识别。实际爬取过程中,网络波动和源站限制很常见,所以我没有追求"跑得越快越好",而是更重视稳定性。每次请求之间都会保留一定间隔,失败后按递增时间重试,避免短时间内连续访问造成封禁。
字段抽取部分主要围绕日期、最高温、最低温、天气、风向、风力、AQI、空气质量说明和等级进行。部分月份存在单日字段缺失的问题,因此脚本里设计了简单补全策略,通过月度聚合信息给缺失项兜底,保证时间序列尽量连续。
为了便于排查,我在采集脚本中保留了进度输出和异常提示。哪个城市、哪一年、哪一月正在运行,是否请求失败,缺失字段是否被补全,都会在控制台留下记录。这个细节在长时间采集时很重要,因为采集任务一旦覆盖多个城市和多个年份,仅靠最终文件很难判断中途哪里出了问题。
图 1 数据来源、城市编码与采集机制展示
图 2 爬虫运行、数据预览与入库过程展示
二、清洗与入库:让数据真正能被系统调用
爬下来的数据如果直接拿来画图,很容易出现各种小问题:日期格式有差异、字段类型不一致、空值混在字符串里、天气文本不适合直接统计。为此,我在预处理阶段先做字段检查,再统一日期、温度、AQI 等关键字段格式,并增加自增 id,方便后续排查和定位。
天气字段经过了进一步标签化处理。例如,把"小雨、中雨、大雨、暴雨"等描述转成降雨等级,把晴、多云、雪、雾、高温日、寒冷日等状态转成可计算的特征变量。这样一来,页面展示时不再只依赖原始文本,而是可以直接做分组统计、地图映射和占比分析。
存储方面采用 CSV 与 MySQL 双路径。CSV 用于快速回放和人工核验,MySQL 用于系统查询和大屏调用。后端通过 SQLAlchemy、PyMySQL 或连接器完成批量写入与读取,字段顺序和类型在入库前保持一致。为了适合公开展示,文档中的数据库名称、路径、账号类信息都做了脱敏处理,只保留功能效果。
清洗后的数据还会再次进行抽样检查,包括行数是否变化、日期是否能够正常排序、省份城市字段是否为空、AQI 等级是否能对应到数值范围。很多可视化页面看起来只是前端效果,但底层数据一旦有重复、空值或类型错误,图表就会出现比例异常、坐标错位或页面报错。因此我把清洗过程当成系统质量控制的一部分,而不是简单的格式转换。
图 3 数据标准化与特征工程流程展示
三、分析主线:不只看 AQI ,还要看时间、空间和天气条件
空气质量分析的核心指标是 AQI,但只盯着一个数字很难讲清楚问题。我把分析拆成几个层次:先看全年空气质量等级占比,再看每日平均 AQI 曲线、月度变化、省份均值排名和空间地图分布。这样的组合能同时回答"全年整体情况如何""什么时候波动最大""哪些地区差异明显"这几类问题。
从 2024 年的展示结果看,优和良的天数占据绝大多数,整体空气质量状态较好,但冬季 AQI 明显抬升,年初和年末波动更突出。把每日曲线切换为月度柱状图后,季节性会更清楚:冬季偏高,夏季相对较低。再配合省份对比和地图,就能看到不同区域之间的结构差异。
这里没有把所有年份简单混在一起展示,而是把年份作为可配置参数。因为不同年份的极端天气、数据覆盖和治理背景可能不同,直接混合会削弱解释力。独立年份分析更适合做项目展示,也方便后续扩展成多年份对比模式。
图表设计时,我尽量让每张图承担一个明确问题:饼图负责看结构,折线图负责看波动,柱状图负责看排名,地图负责看空间差异,雷达图负责看多指标轮廓。这样组织之后,页面不会变成图表堆叠,而是围绕数据问题逐层展开,展示时也更容易讲清楚。
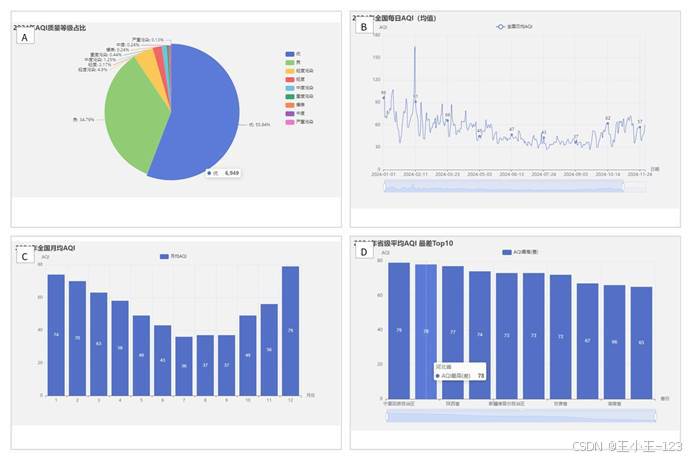
图 4 AQI 等级分布、趋势与省份对比展示
四、空间分布:用地图看清区域差异
地图模块是这个项目里最直观的部分。普通折线图适合看趋势,地图更适合表达地区差异。我分别做了平均 AQI、晴天占比、降雨占比、降雪占比、优良天比例等空间分布图。每个省份通过颜色深浅呈现指标大小,用户不用看复杂表格,也能快速判断哪些区域更突出。
例如,降雨日比例在四川、重庆、贵州、广西、广东等南方地区更高,降雪日则集中在东北、西北和高海拔地区;优良天比例的地图可以呈现全国空气质量的整体改善情况,也能看到少数地区仍存在一定压力。通过这些地图,空气质量不再只是一个单点数值,而是被放进了更完整的自然地理背景中。
地图展示还特别适合和交互提示结合。鼠标悬停时可以显示省份名称、指标数值和排名信息,用户无需翻表格就能看到细节。对于环境类数据而言,这种交互方式比静态截图更有价值,因为它允许用户按自己的关注点去探索不同地区,而不是只能接受固定结论。
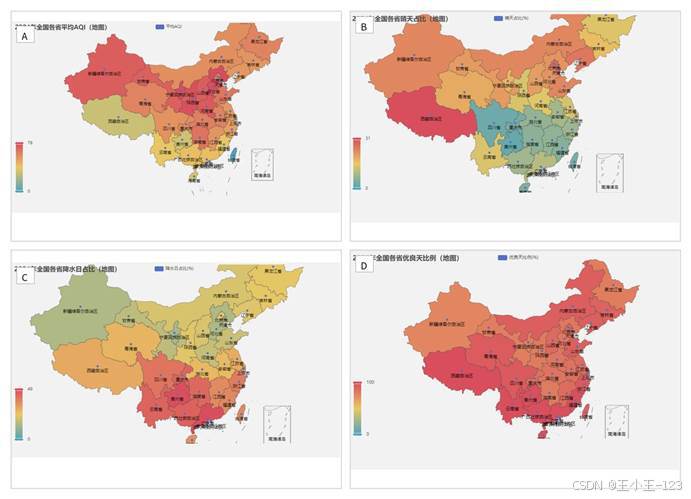
图 5 空气质量与典型天气指标空间分布展示
五、温度与天气特征:把气象背景补充进去
空气质量变化往往和气象条件有关,所以我在系统中保留了温度、降水、降雪、风力和风向等指标。温度模块主要看月度平均最高温、最低温、省份温度排名、极端高温和极端低温。这样可以把空气质量和季节变化放在同一套页面中观察。
天气类型模块则关注晴、多云、雨、雪、雾等出现频率,并通过饼图和地图表达结构特征。比如晴天占比、降雨占比、高温日数、寒冷日数等指标,既适合做环境科普,也适合做城市气候差异展示。对于一个可视化项目来说,这些指标能让页面内容更丰富,不会停留在单一 AQI 曲线。
这些分析并不是为了直接证明某个天气因素一定导致空气质量变化,而是为后续建模提供线索。比如冬季 AQI 升高、高温日分布、降水日比例和风向风力特征,都可以作为后续预测模型或关联分析的候选变量。先用可视化发现现象,再考虑更严谨的统计模型,这是我在项目里采用的推进思路。
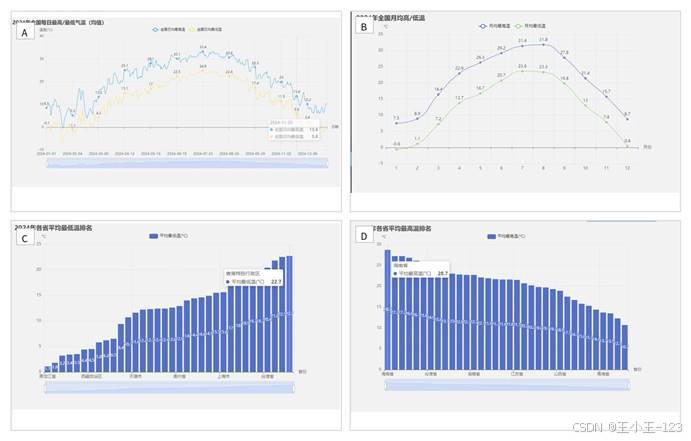
图 6 温度趋势与省份温度排名展示
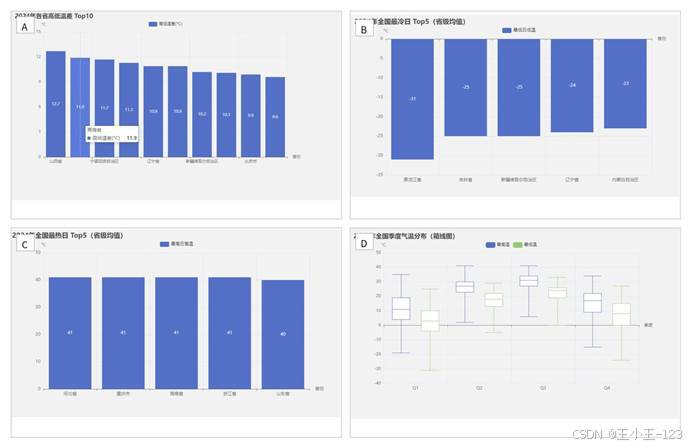
图 7 温差、极端高温与极端低温分析展示
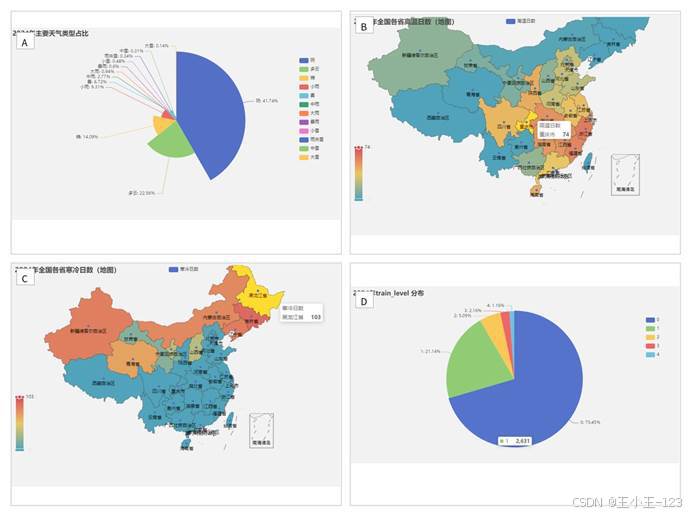
图 8 天气类型、高温寒冷日与降雨等级展示
六、风向风力与综合画像:增加一点多维分析味道
风力和风向模块主要做交叉统计。系统把风向划分为多个方向,把风力划分为不同等级,再用热力图展示组合频次。热力图能直观看到哪些风向和风力等级出现更频繁,比单纯列表更适合浏览。
综合画像部分用雷达图展示多个城市或地区在晴天比例、雨日比例、雪日比例、高温日比例、优良天气比例等维度上的差异。这个设计比较适合做项目亮点展示,因为它把多个指标压缩到一张图里,既能看单项差异,也能看整体轮廓。后续如果接入更多指标,还可以扩展成城市气候画像或环境质量画像。
从开发体验看,雷达图和热力图比普通柱状图更考验数据组织方式。前者需要先做多指标标准化,后者需要构建二维交叉矩阵。如果前期字段没有整理好,后面会非常麻烦。这个部分也说明,数据可视化项目并不只是页面好看,更关键的是把指标口径提前设计清楚。
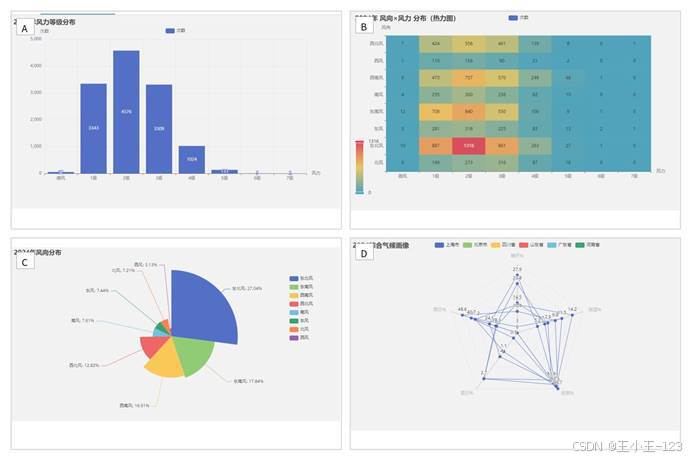
图 9 风向风力热力图与综合气候画像展示
七、可视化大屏:从单张图表走向整页展示
完成单个图表后,我继续把图表按主题组合成大屏页面。Pyecharts 版本更偏静态交互展示,适合快速生成 HTML 页面;Flask + ECharts 版本则更接近真实 Web 系统,大屏每次刷新时可以重新读取数据库或接口数据,页面动态性更强。
大屏布局上采用指标卡片、折线图、柱状图、饼图、地图和表格组合。顶部卡片负责展示总记录数、平均 AQI、优良天数、污染天数等关键指标,中间区域放趋势和地图,左右两侧放排名、占比和明细模块。这样设计后,用户进入页面就能先看到全局情况,再通过具体图表继续查看细节。
为了让视觉效果更接近数据驾驶舱,ECharts 版本采用了深色背景和高亮数字卡片,适合项目答辩、课程展示、系统宣传和成果演示。Pyecharts 版本则更适合保存为独立页面,方便打包和迁移。两套展示方式可以同时保留,使用场景不同。
后端接口在设计时尽量保持简洁,每个页面只请求自己需要的数据。比如趋势图返回时间序列,地图返回省份指标,排名模块返回排序后的列表。前端拿到 JSON 后再交给 ECharts 渲染,这样页面逻辑比较清晰,也方便以后把数据源从本地数据库换成在线接口。
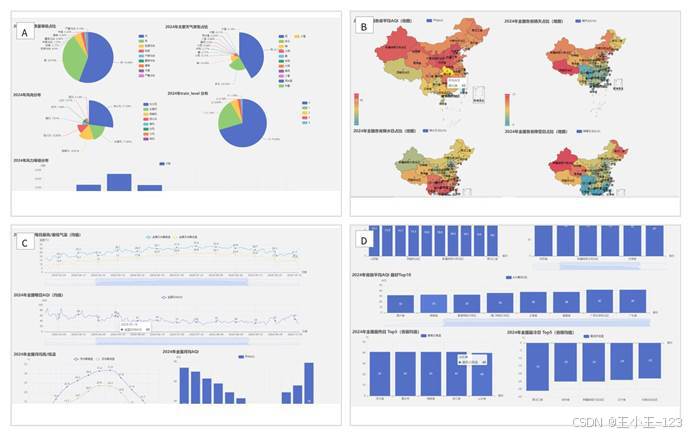
图 10 Pyecharts 多页面组合大屏展示
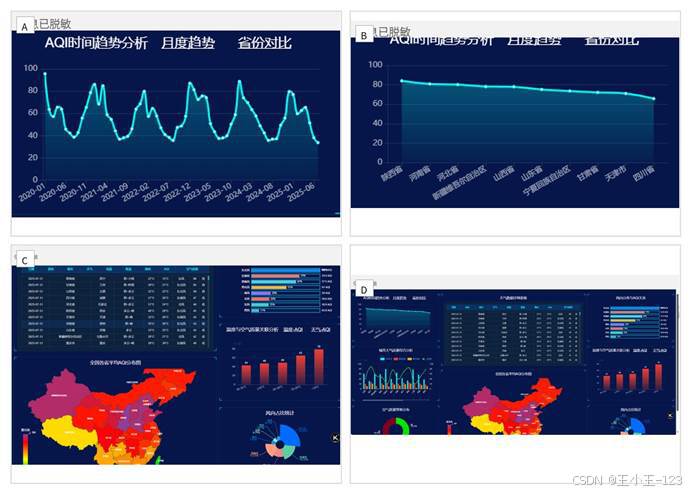
图 11 Flask 与 ECharts 动态大屏展示
八、系统集成:让所有页面有统一入口
单独的 HTML 页面虽然能展示结果,但管理起来并不方便。所以我又增加了一个可视化系统入口,把不同主题的大屏统一放到侧边栏中。用户登录后可以通过导航切换空气质量、气象分布、省际对比、风向风力、综合画像等页面。
系统前端采用 Layui 风格的管理界面,后端用 Flask 提供数据接口,数据库负责持久化存储。这样的结构比较清晰:采集脚本负责拿数据,清洗程序负责规范数据,数据库负责管理数据,接口负责输出数据,前端负责展示数据。后续如果要增加预测模型、实时数据、用户权限或导出报告,都可以在现有结构上继续扩展。
我比较满意的是,这个项目最终不是停留在"图表截图",而是形成了可运行、可访问、可扩展的一套小型平台。对于学习 Python 数据分析、Flask Web 开发、ECharts 大屏和环境数据可视化的朋友来说,这类项目非常适合作为综合练手案例。
部署时只需要保证 Python 环境、数据库连接和静态资源路径配置正确,就可以在浏览器中访问。对于初学者来说,最容易出错的地方通常不是算法,而是依赖包版本、数据库编码、前后端路径和端口占用。因此完整资源里我会把运行步骤、依赖说明和常见问题单独整理出来,方便按步骤复现。
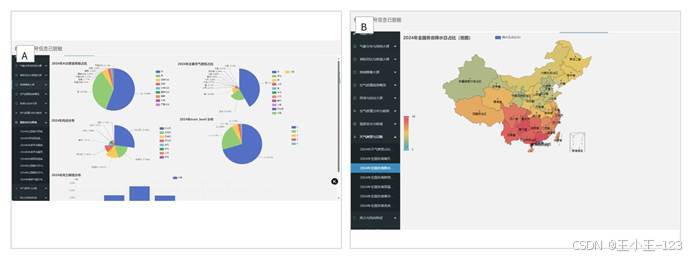
图 12 可视化系统集成界面展示
九、项目资源可以怎么用
这套资源适合做数据分析课程设计、毕业设计、环境数据可视化展示、Python 爬虫练习、Flask 系统开发练习,也可以作为大屏项目的二次开发模板。完整资源中可以包含采集脚本、清洗脚本、数据库建表说明、可视化页面、系统运行说明和展示文档。
如果想继续升级,可以从三个方向动手:第一,接入实时空气质量接口,让系统从历史分析走向实时监测;第二,加入机器学习预测模块,对未来 AQI 或污染等级做短期预测;第三,完善用户权限、报告导出和移动端适配,让它更像一个完整应用。
我在整理公开展示内容时,只保留了技术路线、功能模块和运行效果,涉及账号、路径、数据库连接、接口地址和原始代码细节的部分已经做了处理。完整代码、部署步骤和详细说明,适合通过私信单独获取。
如果用于发布平台展示,建议把文章配图控制在功能截图和结果图为主,代码截图只放少量流程片段即可。这样既能体现项目完整度,也不会把核心实现全部公开。真正需要复现或二次开发的朋友,可以再根据完整资源进行部署、调试和修改。
每文一语
真正有价值的项目,不是把数据堆在一起,而是把问题拆清楚、把流程跑通、把结果讲明白。