目录
- 前言
- [一、初识两种 Worker:界面直观区分](#一、初识两种 Worker:界面直观区分)
- [二、两种 Worker 核心原理与优缺点详解](#二、两种 Worker 核心原理与优缺点详解)
- [1. Code Worker(HTTP/协议模式)](#1. Code Worker(HTTP/协议模式))
- [2. Browser Worker(浏览器模式)](#2. Browser Worker(浏览器模式))
- 三、核心选型标准:场景对应最优方案
- [四、分段 Worker 配置(Worker per stage)](#四、分段 Worker 配置(Worker per stage))
- [1. 什么场景需要分段配置?](#1. 什么场景需要分段配置?)
- [2. 分段 Worker 开启步骤](#2. 分段 Worker 开启步骤)
- 五、运行效果实测对比
- 六、最终选型总结
- 七、总结
前言
在使用 Bright Data Scraper Studio 搭建爬虫任务时,Worker 工作类型的选择是决定爬虫成功率、运行速度、抓取成本的核心关键。很多新手爬虫报错、抓取数据不全、运行耗时过长、扣费过高的问题,本质都是 Worker 类型选错、配置不匹配导致。
Scraper Studio 核心提供两种 Worker 工作模式:Code Worker(代码/HTTP 模式)和 Browser Worker(浏览器模式)。本文将带大家一起来看一下具体的操作,并且讲解进阶分段配置技巧,兼顾爬虫稳定性与性价比。
bash
试用链接:https://www.bright.cn/products/web-scraper/custom?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_hjs202606&promo=brd06一、初识两种 Worker:界面直观区分
首先我们需要明确两种 Worker 的官方定义与界面展示,这是后续选型的基础。在 Scraper Studio 自定义爬虫 IDE 界面中,可直接看到两种 Worker 的切换选项。
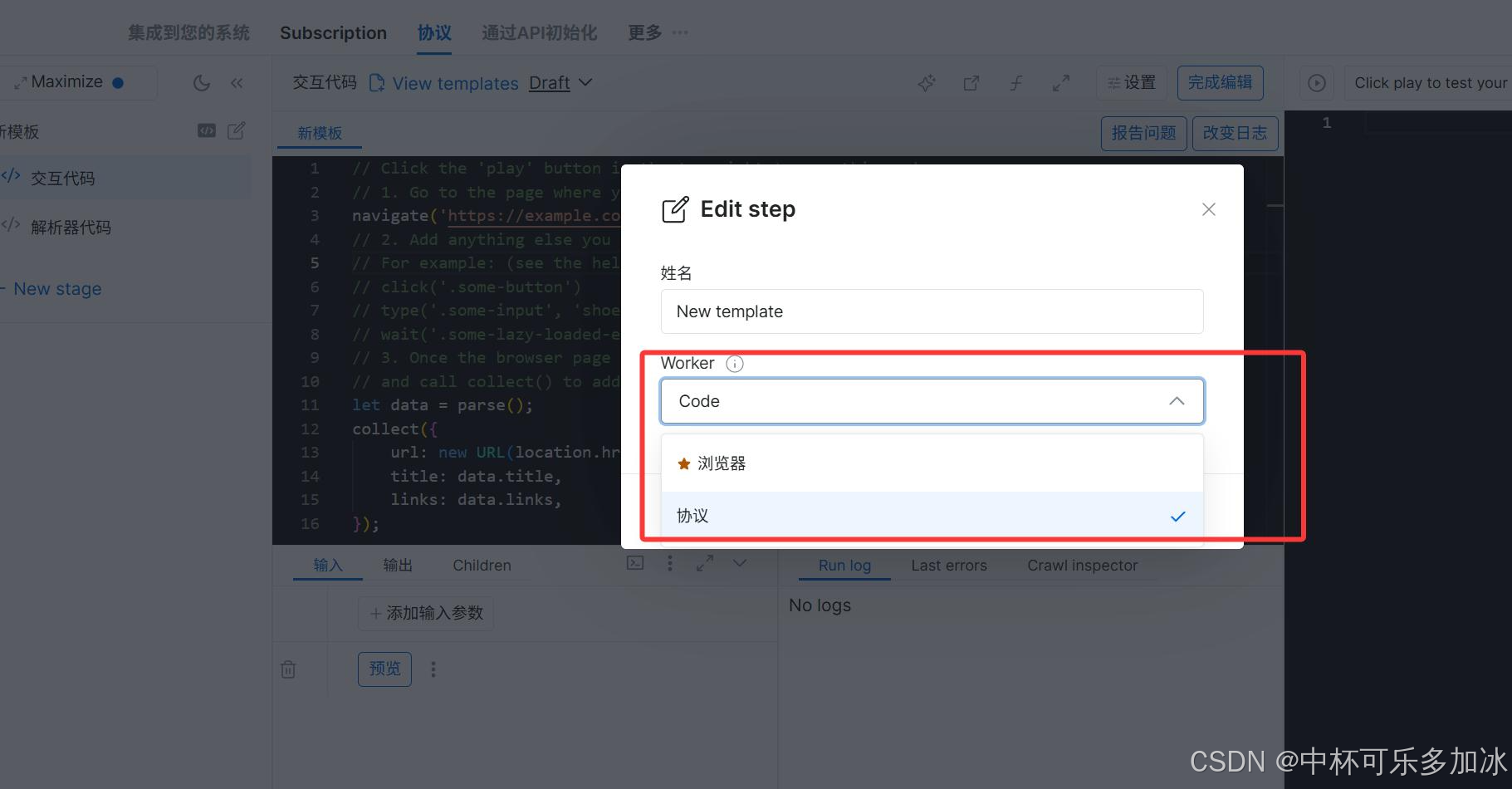
该界面为 Scraper Studio 爬虫阶段编辑页面,下拉菜单中可直接选择Code(协议模式) 和 Browser(浏览器模式) 两种工作类型,也是我们日常选型的核心操作入口。
二、两种 Worker 核心原理与优缺点详解
两种 Worker 的底层运行逻辑完全不同,适配的网站场景、支持的功能、运行性能天差地别,下面做精细化拆解。
1. Code Worker(HTTP/协议模式)
Code Worker 是轻量化请求模式,底层基于原生 HTTP/HTTPS 协议发送请求,类似于 Python 的 requests、curl 工具,不会启动浏览器、不加载前端渲染引擎。
核心优势:运行速度极快、资源消耗低、抓取成本最低,适合大批量批量采集任务,几乎无冗余资源消耗。
功能限制:不支持 JavaScript 渲染、不支持任何人工交互操作,无法执行点击、滚动、等待加载、表单输入、破解验证等操作。
适用场景:纯静态 HTML 页面、公开 API 接口、网站列表页、分页数据、无需动态加载的公开文本数据。
2. Browser Worker(浏览器模式)
Browser Worker 是全真模拟浏览模式,会启动无头浏览器内核,完整模拟真人打开网页的全过程,自动加载页面资源、执行 JS 代码、渲染动态数据。
核心优势:功能全覆盖,支持所有浏览器交互操作,适配 99% 的复杂动态网站,可解决动态渲染、无限下拉、登录鉴权、人机验证、GraphQL 接口捕获等难题。
功能短板:需要初始化浏览器内核、加载页面全部资源,运行速度慢,资源开销大,单次抓取成本远高于 Code Worker。
适用场景:SPA 单页应用网站、JS 动态渲染数据、无限滚动页面、需要点击交互、登录授权、存在验证码防护的站点。
三、核心选型标准:场景对应最优方案
结合实操经验,总结出最简单、零出错的选型规则,新手可直接套用。
优先原则:能选 Code Worker 绝不选 Browser Worker,仅在 Code Worker 抓取数据不全、失效时,切换 Browser Worker。
精准选型对照表

截图说明:通过图文对比直观区分两种 Worker 的速度、成本、功能、适配场景,快速匹配自身爬虫任务需求。
四、分段 Worker 配置(Worker per stage)
大部分多阶段爬虫(列表页+详情页)不适合全局统一 Worker,全局选型会造成严重的资源浪费或数据抓取失败,此时必须使用 Scraper Studio 核心进阶功能------分阶段 Worker 配置。
1. 什么场景需要分段配置?
爬虫分为多个执行阶段,不同阶段的页面特性不同:
举例:列表页为静态数据(可用 Code Worker 极速抓取),详情页为 JS 动态渲染(必须 Browser Worker),全局单一模式无法兼顾速度与成功率。
2. 分段 Worker 开启步骤
1.进入 Scraper Studio 自定义 IDE 编辑页面;
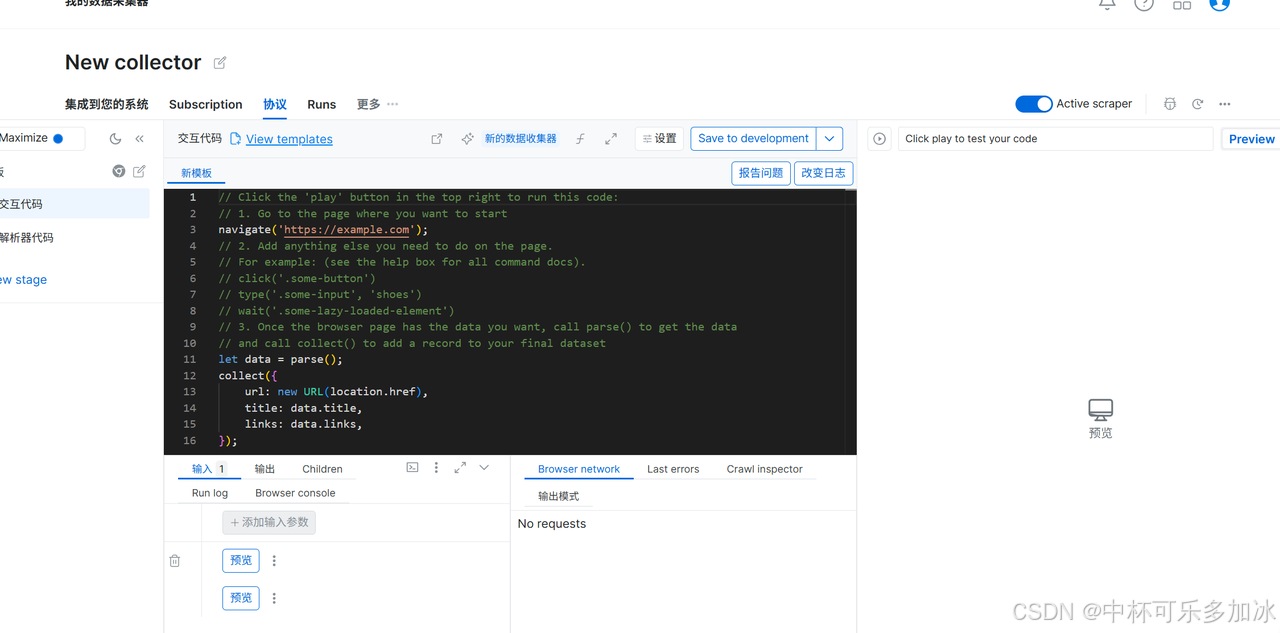
2.点击顶部设置菜单栏,勾选开启 Worker per stage 分段模式;
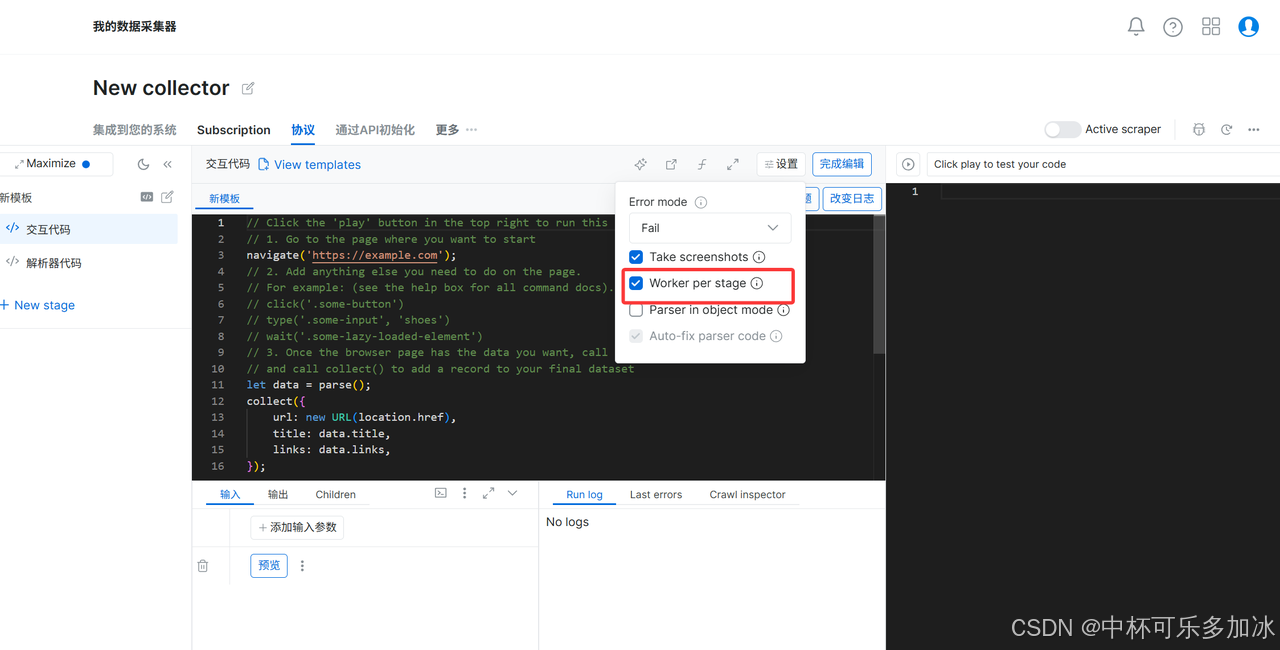
3.单独编辑每一个爬虫阶段,分别为列表页、详情页、采集页配置对应的 Code / Browser Worker;
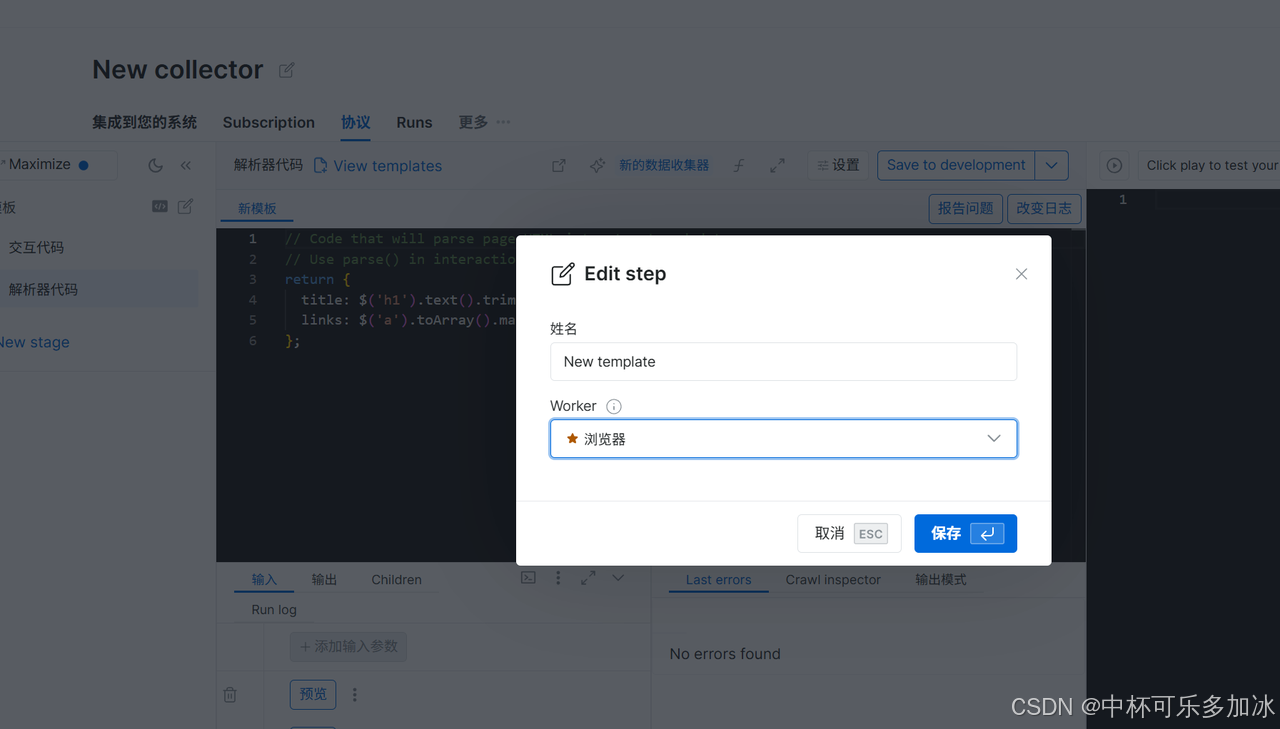
4.保存配置并运行,实现不同阶段差异化抓取。
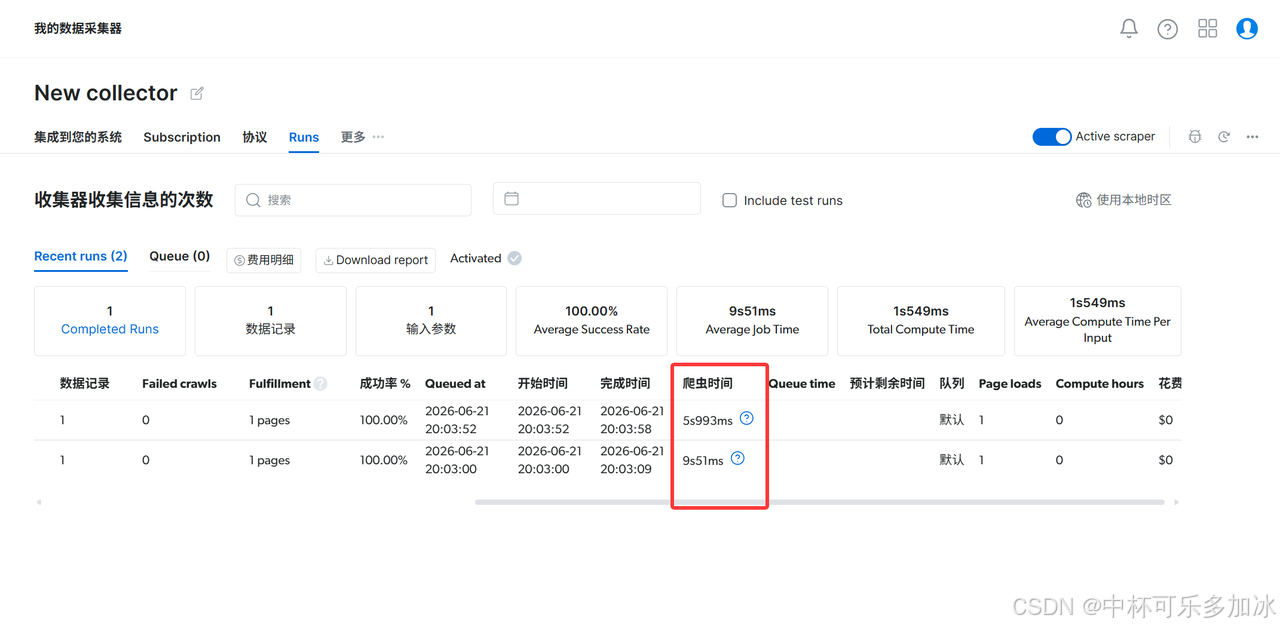
五、运行效果实测对比
为了直观体现差异,我们用同一组采集任务实测对比:
1、Code Worker:无浏览器加载过程,单次任务耗时 5-6 秒,成本极低;
2、Browser Worker:需加载浏览器与页面资源,单次任务耗时 9-12 秒,成本更高;
大批量抓取场景下,两者的时间成本、计费成本差距会成倍放大,合理选型可直接优化 50% 以上的爬虫效率与开销。
六、最终选型总结
1、静态页面、API 接口、纯列表分页 → 首选 Code Worker,高速省钱;
2、动态渲染、交互操作、验证防护、登录站点 → 必选 Browser Worker,保证数据完整;
3、多阶段复合爬虫 → 开启 Worker per stage 分段配置,兼顾效率与稳定性;
4、所有爬虫优先测试 Code Worker,抓取异常再升级 Browser Worker,拒绝过度资源消耗。
七、总结
Worker 类型选择是 Scraper Studio 爬虫搭建的基石,选对类型可以规避 80% 的爬虫报错、数据缺失、效率低下问题。新手无需盲目全程使用浏览器模式,合理搭配两种 Worker,结合分段配置功能,既能保障爬虫稳定抓取,又能最大程度节约成本、提升采集效率。