三层路由基础
静态→OSPF→重分发
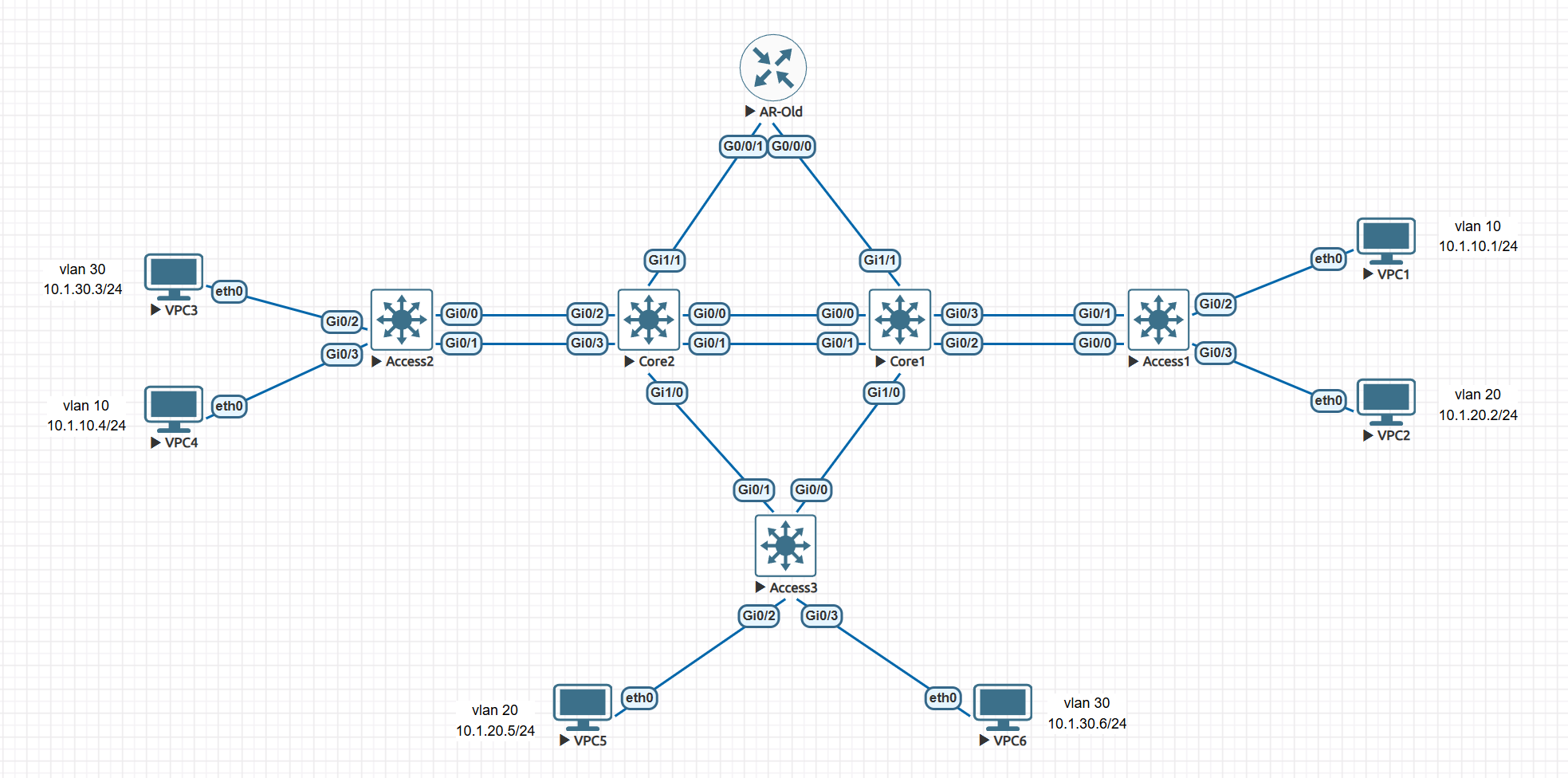
拓扑
模块 1 基础上添加 1 台 Huawei AR1000v(模拟老旧厂区 RIP 网络)
可以先看一下配置结构图,我不太想把它放前面。
练习内容
- SVI 三层接口:核心交换机配置各 VLAN 的 SVI,实现跨 VLAN 互通
- OSPF 完整配置:
- 所有核心/接入交换机加入 OSPF Area 0 骨干区域
- 配置被动接口(Passive-interface)
- DR/BDR 选举
- 配置 OSPF 默认路由下发(default-information originate)
- 配置路由汇总与 NULL0 黑洞路由防环
- RIP/OSPF 双向重分发与调优:
- 老旧厂区(AR-Old)部署 RIP v2;双核心配置 RIP 与 OSPF 双向重分发。
- AD 值调优:核心侧修改 RIP 管理距离(
distance 100),避免次优路径。 - 防环策略:使用 Route-Map 过滤重分发路由,防止路由反馈环路。
- 双活负载均衡(ECMP):验证接入层与边缘层的双下一跳等价路由,实现端到端双活。
验证:
- 跨 VLAN 互通:总部各业务 VLAN PC 之间可正常 Ping 通
- 端到端双活负载均衡 :Access1 上
show ip route ospf显示 10.2.0.0/24 存在双下一跳(Core1/Core2);AR-Old 上回程路由同样存在双下一跳 - 链路故障自动收敛:关闭 Core1 互联接口后,PC1 长 ping 仅丢 1~3 个包即自动恢复,Access1 路由表自动撤销失效下一跳,流量无缝切换至 Core2
- 链路恢复自动回切 :重新开启接口并执行
clear ip route *后,双活 ECMP 状态在 20 秒内自动恢复 - 老旧厂区全可达:AR-Old 下挂 PC 可正常访问总部所有业务网段(10.1.10.0/24、10.1.20.0/24、10.1.30.0/24)及互联网
- 防环验证:手动断开一侧 RIP 链路,确认不会出现路由震荡或环路计数递增现象
实现
一、实验拓扑与设备连接
1. 设备清单与命名
所有交换机均为同型号 Cisco vIOS L2 镜像,通过 SVI 实现三层路由能力;新增 1 台 Huawei AR1000v 模拟老旧厂区 RIP 网络。
| 设备类型 | 数量 | EVE-NG 命名 | 角色 |
|---|---|---|---|
| Cisco vIOS L2 交换机 | 2 | Core1、Core2 | 双核心(通过 SVI 提供三层网关、运行 OSPF 与路由重分发) |
| Cisco vIOS L2 交换机 | 3 | Access1、Access2、Access3 | 接入层(二层转发,配置管理 SVI 加入 OSPF) |
| Huawei AR1000v | 1 | AR-Old | 老旧厂区出口路由器(运行 RIP v2) |
| VPCS | 6 | PC1~PC6 | 终端测试设备 |
2. 详细物理连接表
原有二层链路(核心间 LACP 聚合、核心与接入 Trunk / 聚合、终端接入端口)完全保持不变,新增三层互联链路如下:
| 设备 A | 端口 | 设备 B | 端口 | 互联 VLAN | 互联网段 | 链路角色 |
|---|---|---|---|---|---|---|
| Core1 | GigabitEthernet1/1 | AR-Old | GigabitEthernet0/0/0 | VLAN 200 | 10.0.0.0/30 | 总部 - 老旧厂区主链路 |
| Core2 | GigabitEthernet1/1 | AR-Old | GigabitEthernet0/0/1 | VLAN 201 | 10.0.0.4/30 | 总部 - 老旧厂区备链路 |
网段规划:从三层互联地址池 10.0.0.0/24 中按 / 30 掩码划分子网;老旧厂区内网以 10.2.0.0/24 模拟。
3. 拓扑图
二、基础配置准备
1. 核心交换机互联 VLAN 与 SVI 配置(Core1 / Core2)
创建专用互联 VLAN,将对接 vSR 的物理接口设为 access 模式划入对应 VLAN,通过 SVI 配置三层互联 IP。
Core1
bash
# 创建 vlan 200
Core1(config)#vlan 200
# 为 vlan 200 设置描述性名称
Core1(config-vlan)#name To_AR-Old_Main
Core1(config-vlan)#exit
# 进入接口 g1/1 的配置模式
Core1(config)#int g1/1
# 设置接口描述,便于识别连接对象
Core1(config-if)#description To_AR-Old_Main
# 将接口设为 access 模式
Core1(config-if)#switchport mode access
# 将接口加入 vlan 200
Core1(config-if)#switchport access vlan 200
Core1(config-if)#no shutdown
Core1(config-if)#exit
# 进入 vlan 200 的三层虚拟接口
Core1(config)#int vlan 200
# 为 SVI 接口配置 IP 地址(用于三层路由)
Core1(config-if)#ip address 10.0.0.1 255.255.255.252
Core1(config-if)#no shutdown分析
10.0.0.1/30 子网掩码分析:
- 可用 IP 地址:
10.0.0.1~10.0.0.2(共 2 个可用地址) - 网络地址:
10.0.0.0 - 广播地址:
10.0.0.3
典型的 点到点链路 配置,用于连接两个三层设备
plaintext
Core1 (三层交换机)
│
├── g1/1 (Access模式, VLAN 200) ──── 连接 AR-Old_Main
│
└── SVI VLAN 200 (IP: 10.0.0.1/30) ──── 提供三层路由能力Core2
bash
Core2(config)#vlan 201
Core2(config-vlan)#name To_AR-Old_Backup
Core2(config-vlan)#int g1/1
Core2(config-if)#description To_AR-Old_G2/0_Backup
Core2(config-if)#switchport mode access
Core2(config-if)#switchport access vlan 201
Core2(config-if)#no shutdown
Core2(config-if)#exit
Core2(config)#int vlan 201
Core2(config-if)#ip address 10.0.0.5 255.255.255.252
Core2(config-if)#no shutdown分析
10.0.0.5/30 子网掩码分析:
- 可用 IP 地址:
10.0.0.5~10.0.0.6(共 2 个可用地址) - 网络地址:
10.0.0.4 - 广播地址:
10.0.0.7
plaintext
Core2 (三层交换机)
│
├── g1/1 (Access模式, VLAN 201) ──── 连接 AR-Old 的 G2/0(备份链路)
│
└── SVI VLAN 201 (IP: 10.0.0.5/30) ──── 提供三层路由能力2. Huawei AR1000 基础配置(AR-Old)
vSR1000 接口默认为三层路由模式,直接配置 IP 即可,并用 Loopback 接口模拟老旧厂区内网网段。
bash
# 进入系统视图并修改设备名
<Huawei>system-view
[Huawei]sysname AR-Old
# 主链路互联接口(对接Core1)
# 进入接口 g1/0 的配置模式
[AR-Old]interface GigabitEthernet 0/0/0
# 设置接口描述,标识为主链路(连接 Core1 的 G0/0/0)
[AR-Old-GigabitEthernet0/0/0]description To_Core1_G0/0/0_Main
# 配置接口 IP 地址
[AR-Old-GigabitEthernet0/0/0]ip address 10.0.0.2 255.255.255.252
[AR-Old-GigabitEthernet0/0/0]undo shutdown
[AR-Old-GigabitEthernet0/0/0]quit
# 备链路互联接口(对接Core2)
[AR-Old]interface GigabitEthernet 0/0/1
[AR-Old-GigabitEthernet0/0/1]description To_Core2_G0/0/1_Backup
[AR-Old-GigabitEthernet0/0/1]ip address 10.0.0.6 255.255.255.252
[AR-Old-GigabitEthernet0/0/1]undo shutdown
[AR-Old-GigabitEthernet0/0/1]quit
# Loopback0 模拟老旧厂区内网网段
# 创建并进入 Loopback0 接口配置模式
# int + LoopBack(虚拟环回接口类型)+ 0(接口编号)
[AR-Old]int LoopBack 0
# 配置环回接口 IP 地址(模拟内网网段)
[AR-Old-LoopBack0]ip address 10.2.0.254 255.255.255.0
[AR-Old-LoopBack0]quit分析
| 接口 | IP 地址 | 子网掩码 | 用途 |
|---|---|---|---|
| g1/0 | 10.0.0.2 | 255.255.255.252 (/30) | 主链路(与 Core1 的 10.0.0.1 通信) |
| g2/0 | 10.0.0.6 | 255.255.255.252 (/30) | 备份链路(与 Core2 的 10.0.0.5 通信) |
| LoopBack0 | 10.2.0.254 | 255.255.255.0 (/24) | 模拟老旧厂区内网网关 |
plaintext
AR-Old (Huawei 路由器)
│
├── g1/0 (主链路) ──── IP: 10.0.0.2/30 ──── 连接 Core1 的 g1/1
│
├── g2/0 (备份链路) ──── IP: 10.0.0.6/30 ──── 连接 Core2 的 g1/1
│
└── LoopBack0 ──── IP: 10.2.0.254/24 ──── 模拟老旧厂区内网网段设计意图:AR-Old 作为老旧厂区的核心路由器,通过主备两条链路分别连接到 Core1 和 Core2,实现链路冗余;LoopBack0 接口模拟了老旧厂区的内网网段(10.2.0.0/24)。
3. 接入交换机管理 SVI 配置(Access1/2/3)
配置 VLAN100 管理 SVI,用于设备管理与 OSPF 纳入:
Access2 为 10.1.100.2/24
Access3 为 10.1.100.3/24
bash
# Access1 示例,
Access1#conf t
# 创建并进入 VLAN 100 的三层虚拟接口(SVI)配置模式
Access1(config)#int vlan 100
# 为 SVI 接口配置 IP 地址(作为 VLAN 100 的网关)
# ip address <IP地址> <子网掩码>
Access1(config-if)#ip address 10.1.100.1 255.255.255.0
Access1(config-if)#no shutdown分析
VLAN 100 管理网段分析
| 参数 | 说明 |
|---|---|
| 网络地址 | 10.1.100.0/24 |
| 可用 IP 地址范围 | 10.1.100.1 ~ 10.1.100.254(共 254 个可用地址) |
| 子网掩码 | 255.255.255.0 |
| 设备 IP | Access1: 10.1.100.1 Access2: 10.1.100.2 Access3: 10.1.100.3 |
| 用途 | 接入交换机管理 + OSPF 路由协议 |
plaintext
Access1 (接入层交换机)
│
├── Trunk端口 ──── 连接 Core1/Core2(承载多个 VLAN)
│
├── Access端口 ──── 连接终端设备(划入各业务 VLAN)
│
└── SVI VLAN 100 (IP: 10.1.100.1/24)
│
├── 功能:设备管理 + OSPF 邻居建立
└── 默认路由:指向核心交换机
plaintext
Access2 (接入层交换机)
│
├── Trunk端口 ──── 连接 Core1/Core2(承载多个 VLAN)
│
├── Access端口 ──── 连接终端设备(划入各业务 VLAN)
│
└── SVI VLAN 100 (IP: 10.1.100.2/24)
│
├── 功能:设备管理 + OSPF 邻居建立
└── 默认路由:指向核心交换机
plaintext
Access3 (接入层交换机)
│
├── Trunk端口 ──── 连接 Core1/Core2(承载多个 VLAN)
│
├── Access端口 ──── 连接终端设备(划入各业务 VLAN)
│
└── SVI VLAN 100 (IP: 10.1.100.3/24)
│
├── 功能:设备管理 + OSPF 邻居建立
└── 默认路由:指向核心交换机总结:Access1/2/3 是三个独立的接入层交换机,通过 Trunk 链路分别连接到双核心(Core1/Core2),它们之间没有直接物理连接。VLAN 100 的 SVI 作为管理接口用于 OSPF 协议和设备管理,业务流量通过核心交换机的 SVI 实现三层互通。
三、分步配置实现
(一)配置业务 SVI 三层接口,实现跨 VLAN 互通
在双核心上配置各业务 VLAN 的 SVI 作为三层网关,IP 规划匹配 MSTP 实例拓扑,保证二三层转发路径一致。
双核心网关冗余对比
| VLAN | Core1 IP | Core2 IP | 主网关 | 备份网关 |
|---|---|---|---|---|
| 10 | 10.1.10.254 | 10.1.10.253 | Core1 | Core2 |
| 20 | 10.1.20.253 | 10.1.20.254 | Core2 | Core1 |
| 30 | 10.1.30.253 | 10.1.30.254 | Core2 | Core1 |
| 100 | 10.1.100.254 | 10.1.100.253 | Core1 | Core2 |
Core1 配置(MSTP 实例 1 根桥,VLAN10 主网关)
bash
Core1#conf t
# 创建并进入 VLAN 10 的 SVI 配置模式
Core1(config)#int vlan 10
# 为 VLAN 10 SVI 配置 IP 地址
Core1(config-if)#ip address 10.1.10.254 255.255.255.0
Core1(config-if)#no shutdown
Core1(config-if)#exit
Core1(config)#int vlan 20
Core1(config-if)#ip address 10.1.20.253 255.255.255.0
Core1(config-if)#no shutdown
Core1(config-if)#exit
Core1(config)#int vlan 30
Core1(config-if)#ip address 10.1.30.253 255.255.255.0
Core1(config-if)#no shutdown
Core1(config-if)#exit
Core1(config)#int vlan 100
Core1(config-if)#ip address 10.1.100.254 255.255.255.0
Core1(config-if)#no shutdown
Core1(config-if)#exit分析
IP 地址规划分析
| VLAN | SVI IP | 子网掩码 | 网关角色 | 设计说明 |
|---|---|---|---|---|
| VLAN 10 | 10.1.10.254/24 | 255.255.255.0 | 主网关 | .254 表示此 VLAN 的主网关 |
| VLAN 20 | 10.1.20.253/24 | 255.255.255.0 | 备份网关 | .253 表示此 VLAN 的备份网关 |
| VLAN 30 | 10.1.30.253/24 | 255.255.255.0 | 备份网关 | .253 表示此 VLAN 的备份网关 |
| VLAN 100 | 10.1.100.254/24 | 255.255.255.0 | 主网关 | .254 表示此 VLAN 的主网关 |
设计规律:根据 MSTP 实例规划,Core1 作为 VLAN 10 和 VLAN 100 的根桥(主设备),所以使用 .254;作为 VLAN 20 和 VLAN 30 的备份设备,使用 .253。
网络架构说明
plaintext
Core1 (核心交换机)
│
├── SVI VLAN 10 (IP: 10.1.10.254/24) ◄─── VLAN 10 主网关
│
├── SVI VLAN 20 (IP: 10.1.20.253/24) ◄─── VLAN 20 备份网关
│
├── SVI VLAN 30 (IP: 10.1.30.253/24) ◄─── VLAN 30 备份网关
│
├── SVI VLAN 100 (IP: 10.1.100.254/24) ◄─── 管理 VLAN 主网关
│
├── SVI VLAN 200 (IP: 10.0.0.1/30) ◄─── 对接 AR-Old 主链路
│
└── Trunk端口 ──── 连接 Access1/2/3(承载所有业务 VLAN)Core2 配置(MSTP 实例 2 根桥,VLAN20/30 主网关)
bash
Core2#conf t
Core2(config)#int vlan 10
Core2(config-if)#ip address 10.1.10.253 255.255.255.0
Core2(config-if)#no shutdown
Core2(config-if)#exit
Core2(config)#int vlan 20
Core2(config-if)#ip address 10.1.20.254 255.255.255.0
Core2(config-if)#no shutdown
Core2(config-if)#exit
Core2(config)#int vlan 30
Core2(config-if)#ip address 10.1.30.254 255.255.255.0
Core2(config-if)#no shutdown
Core2(config-if)#exit
Core2(config)#int vlan 100
Core2(config-if)#ip address 10.1.100.253 255.255.255.0
Core2(config-if)#no shutdown
Core2(config-if)#exit分析
IP 地址规划分析
| VLAN | SVI IP | 子网掩码 | 网关角色 | 设计说明 |
|---|---|---|---|---|
| VLAN 10 | 10.1.10.253/24 | 255.255.255.0 | 备份网关 | .253 表示此 VLAN 的备份网关 |
| VLAN 20 | 10.1.20.254/24 | 255.255.255.0 | 主网关 | .254 表示此 VLAN 的主网关 |
| VLAN 30 | 10.1.30.254/24 | 255.255.255.0 | 主网关 | .254 表示此 VLAN 的主网关 |
| VLAN 100 | 10.1.100.253/24 | 255.255.255.0 | 备份网关 | .253 表示此 VLAN 的备份网关 |
网络架构说明
plaintext
Core2 (核心交换机)
│
├── SVI VLAN 10 (IP: 10.1.10.253/24) ◄─── VLAN 10 备份网关
│
├── SVI VLAN 20 (IP: 10.1.20.254/24) ◄─── VLAN 20 主网关
│
├── SVI VLAN 30 (IP: 10.1.30.254/24) ◄─── VLAN 30 主网关
│
├── SVI VLAN 100 (IP: 10.1.100.253/24) ◄─── 管理 VLAN 备份网关
│
├── SVI VLAN 201 (IP: 10.0.0.5/30) ◄─── 对接 AR-Old 备份链路
│
└── Trunk端口 ──── 连接 Access1/2/3(承载所有业务 VLAN)总结:这段配置在 Core2 上为 VLAN 10、20、30、100 创建了 SVI 接口,与 Core1 形成完整的双核心网关冗余设计。Core2 作为 VLAN 20 和 VLAN 30 的主网关,以及 VLAN 10 和 VLAN 100 的备份网关,实现了流量负载均衡和故障冗余。
(二)OSPF 完整配置
将所有交换机内网网段纳入 OSPF Area 0,实现内网路由动态学习、链路冗余与路由汇总。
1. 核心交换机 OSPF 配置
Core1 示例,Core2 仅修改 Router-ID 为 10.1.100.253
bash
# 启用 OSPF 路由进程,进程ID为1
# OSPF 进程 ID(本地有效,范围 1-65535)
Core1(config)#router ospf 1
# 设置 Router-ID
# router-id: 命令关键字,设置 OSPF 路由器标识
# 10.1.100.254: Router-ID 值,使用管理 VLAN 的 SVI IP 作为标识(Core2 使用 10.1.100.253)
Core1(config-router)#router-id 10.1.100.254
# 发布网络到 OSPF Area 0
# network <网络地址> <反掩码(wildcard mask)> <区域号>
# network: 命令关键字,将指定网段发布到 OSPF
# 网络地址: 要发布的网段
# 反掩码(wildcard mask): 匹配该网段内所有 IP(/24)
# 区域号: 发布到骨干区域(Area 0)
Core1(config-router)#network 10.1.10.0 0.0.0.255 area 0
Core1(config-router)#network 10.1.20.0 0.0.0.255 area 0
Core1(config-router)#network 10.1.30.0 0.0.0.255 area 0
Core1(config-router)#network 10.1.100.0 0.0.0.255 area 0
# 终端侧SVI设为被动接口,不发送OSPF Hello
# passive-interface <接口名称>
# passive-interface: 命令关键字,设置被动接口
# 接口名称: 指定要设为被动的 SVI 接口
# 作用:被动接口只接收路由更新,不发送 OSPF Hello 包,防止在终端侧建立 OSPF 邻居。
Core1(config-router)#passive-interface vlan 10
Core1(config-router)#passive-interface vlan 20
Core1(config-router)#passive-interface vlan 30
# 向OSPF域下发默认路由
# default-information originate: 命令关键字,向 OSPF 域下发默认路由
# always: 参数,强制下发,即使本地没有默认路由也下发
# 作用:让 OSPF 域内的其他路由器(如 Access1/2/3)获得默认路由。
Core1(config-router)#default-information originate always
# 路由汇总:业务网段汇总为10.1.0.0/16
# summary-address <汇总网络地址> <汇总掩码>
# summary-address: 命令关键字,配置 OSPF 路由汇总
# 汇总网络地址: 将多个子网汇总为一个大网段
# 汇总掩码: 汇总网络地址的掩码,用于确定汇总范围
# 汇总效果:将 10.1.10.0/24、10.1.20.0/24、10.1.30.0/24 汇总为 10.1.0.0/16。
Core1(config-router)#summary-address 10.1.0.0 255.255.0.0分析
设计意图分析
| 设计特点 | 说明 |
|---|---|
| 骨干区域 | 所有设备加入 Area 0,简化网络拓扑 |
| 被动接口 | 终端侧接口设为被动,减少不必要的 Hello 报文 |
| 默认路由下发 | 接入层交换机自动获得默认路由 |
| 路由汇总 | 减少路由表条目,提高收敛速度,防止环路 |
总结:这段配置完整实现了核心交换机的 OSPF 部署。通过
router ospf 1启用进程,router-id设置唯一标识,network命令发布业务和管理网段到骨干区域,passive-interface优化 Hello 报文发送,default-information originate always向下游下发默认路由,summary-address实现路由汇总。Core2 只需修改 Router-ID 为 10.1.100.253 即可完成配置。
2. 配置 NULL0 黑洞路由(防汇总环路)
Core1、Core2 均配置,使用默认管理距离 1,仅明细路由失效时生效:
bash
# Core1 配置
# ip route: 命令关键字,配置静态路由
# 10.1.0.0: 目标网络地址,汇总后的网络地址
# 255.255.0.0: 子网掩码,/16汇总掩码
# Null0: 下一跳接口,NULL0接口(黑洞接口)
# 省略管理距离参数,使用默认值 1;直连SVI路由管理距离为0,优先级更高
Core1(config)#ip route 10.1.0.0 255.255.0.0 Null0
# Core2 配置
Core2(config)#ip route 10.1.0.0 255.255.0.0 Null0总结:这段配置在 Core1 和 Core2 上配置了 NULL0 黑洞路由,核心作用有两点:
- 防路由环路:直连 SVI 网段的管理距离为 0,优先级高于该静态路由(管理距离 1),正常业务流量始终匹配明细路由转发;当数据包发往汇总范围内但实际不存在的子网、且无更优明细路由时,会被 NULL0 接口吸收丢弃,避免路由环路。
- 重分发载体:该路由会进入活跃路由表,可在后续 RIP 双向重分发配置中,作为总部汇总网段的源路由注入 RIP 进程,实现老旧厂区访问总部所有网段。
3. 接入交换机的 OSPF 配置
Access1 示例
Router-ID:Access2 改为10.1.100.2,Access3 改为10.1.100.3
bash
# 启用 OSPF 路由进程 1
# router ospf(命令关键字)+ 1(进程号)
Access1(config)#router ospf 1
# 设置 OSPF 路由器标识
# router-id(命令关键字)+ 10.1.100.1(Router-ID 值)
# Access2 改为 10.1.100.2,Access3 改为 10.1.100.3
Access1(config-router)#router-id 10.1.100.1
# 将管理网段发布到 OSPF 骨干区域
# network(命令关键字)+ 10.1.100.0(网络地址)+ 0.0.0.255(反掩码)+ area 0(区域号)
Access1(config-router)#network 10.1.100.0 0.0.0.255 area 0分析
各接入交换机 Router-ID 配置
| 设备 | Router-ID | 说明 |
|---|---|---|
| Access1 | 10.1.100.1 | 使用管理 VLAN SVI IP |
| Access2 | 10.1.100.2 | 使用管理 VLAN SVI IP |
| Access3 | 10.1.100.3 | 使用管理 VLAN SVI IP |
OSPF 邻居关系建立
plaintext
Access1/2/3 通过管理 VLAN 100 的 SVI 接口与核心交换机建立 OSPF 邻居:
邻居关系:
Access1 ↔ Core1 (通过 VLAN 100)
Access1 ↔ Core2 (通过 VLAN 100)
Access2 ↔ Core1 (通过 VLAN 100)
Access2 ↔ Core2 (通过 VLAN 100)
Access3 ↔ Core1 (通过 VLAN 100)
Access3 ↔ Core2 (通过 VLAN 100)
路由学习:
- 接入交换机通过 OSPF 学习到核心交换机发布的业务路由
- 接入交换机获得默认路由(由核心交换机下发)设计意图分析
| 设计特点 | 说明 |
|---|---|
| 简化配置 | 接入交换机只发布管理网段,不发布业务网段 |
| 统一管理 | 使用 VLAN 100 作为 OSPF 通信的管理网段 |
| 默认路由 | 接入交换机通过 OSPF 获得默认路由,无需手动配置 |
| 冗余邻居 | 每个接入交换机 与双核心都建立邻居关系 |
与核心交换机配置对比
| 配置项 | 核心交换机(Core1/Core2) | 接入交换机(Access1/2/3) |
|---|---|---|
| OSPF 进程号 | 1 | 1(需与核心一致) |
| Router-ID | 10.1.100.254/253 | 10.1.100.1/2/3 |
| 发布网段 | VLAN 10/20/30/100 | 仅 VLAN 100 |
| 被动接口 | VLAN 10/20/30 | 无(仅管理 VLAN 参与 OSPF) |
| 默认路由下发 | default-information originate always | 无需配置(接收) |
| 路由汇总 | summary-address 10.1.0.0 255.255.0.0 | 无需配置(接收汇总) |
总结:这段配置为接入层交换机配置了 OSPF 协议,使其加入骨干区域。通过发布管理 VLAN 100 网段,接入交换机与核心交换机建立 OSPF 邻居关系,从而学习到业务路由和默认路由。接入交换机的配置相对简化,仅需启用 OSPF、设置 Router-ID 和发布管理网段即可。
4. DR/BDR 选举优化
调整 VLAN100 接口 OSPF 优先级,确保核心为 DR/BDR:
Core1 配置,优先级150
bash
# 进入 VLAN100 接口配置模式
interface Vlan100
# ip ospf priority: 命令关键字,设置接口的 OSPF 优先级
# 150: 优先级值,数值范围 0-255,值越大优先级越高
ip ospf priority 150Core2 配置,优先级100
bash
interface Vlan100
ip ospf priority 100分析
优先级配置对比
| 设备 | OSPF 优先级 | 角色 |
|---|---|---|
| Core1 | 150 | DR(优先级最高) |
| Core2 | 100 | BDR(优先级次高) |
| Access1/2/3 | 默认(1) | DROther(优先级最低) |
总结:这段配置通过调整 VLAN100 接口的 OSPF 优先级,确保 Core1(优先级150)成为 DR,Core2(优先级100)成为 BDR,接入交换机保持默认优先级(1)成为 DROther。这样的设计保证了 OSPF 网络的稳定性和可靠性,让性能更强的核心交换机承担 DR/BDR 的职责。
(三)RIP 配置与双向路由重分发
老旧厂区运行 RIP v2,核心交换机实现 OSPF 与 RIP 双向重分发,通过路由策略防止路由回灌与环路。
1. AR-Old 侧 RIP 配置
bash
# 创建并进入 RIP 进程 1 配置视图
# rip(命令关键字)+ 1(进程号)
[AR-Old]rip 1
# 指定 RIP 版本为 v2
# version(命令关键字)+ 2(版本号)
[AR-Old-rip-1]version 2
# 关闭 RIP 自动汇总功能
# undo(否定命令)+ summary(自动汇总)
[AR-Old-rip-1]undo summary
# 在 10.0.0.0 网段的接口上启用 RIP
# network(命令关键字)+ 10.0.0.0(网络地址)
[AR-Old-rip-1]network 10.0.0.0
[AR-Old-rip-1]quit说明:RIP v2 默认开启自动汇总,必须通过 undo summary 关闭,才能传递精确子网路由。
分析
关闭自动汇总的原因
plaintext
RIP 默认会在主网边界自动汇总路由。
例如:10.2.0.0/24 会被汇总为 10.0.0.0/8。
关闭自动汇总后:
- 可以精确传递子网路由(如 10.2.0.0/24)
- 避免路由汇总导致的路由不精确问题
- 便于路由策略的精确控制总结:这段配置为 AR-Old 路由器配置了 RIP v2 协议,通过 network 10.0.0.0 在所有 10.x.x.x 接口上启用 RIP,关闭自动汇总确保子网路由精确传递。这样老旧厂区的 10.2.0.0/24 网段可以通过 RIP 协议发布到核心交换机,再通过路由重分发进入 OSPF 域。
2. 核心交换机侧 RIP 配置(Core1、Core2 均配置)
互联 SVI 会自动纳入 RIP 进程,内网业务 SVI 设为被动接口:
bash
# 启用 RIP 路由进程
# router rip(命令关键字)
Core1(config)#router rip
# 指定 RIP 版本为 v2
# version(命令关键字)+ 2(版本号)
Core1(config-router)#version 2
# 关闭 RIP 自动汇总功能
# no(否定命令)+ auto-summary(自动汇总)
Core1(config-router)#no auto-summary
# 在 10.0.0.0 网段的接口上启用 RIP
# network(命令关键字)+ 10.0.0.0(网络地址)
Core1(config-router)#network 10.0.0.0
# 修改 RIP 协议的管理距离(AD值)
# distance(命令关键字)+ 100(管理距离数值)
# 默认情况下 RIP 的 AD 值为 120,OSPF 的 AD 值为 110。
# 在双向重分发环境中,如果不修改此值,核心交换机会优先选择从另一台核心学来的 OSPF 路由(110),
# 而不是本地直连的 RIP 路由(120),导致次优路径和"非对称重分发"引发的路由丢失。
# 将 RIP 的 AD 值降为 100(优于 OSPF 的 110),强制核心交换机优先使用本地 RIP 链路,实现本地流量本地转发。
Core1(config-router)#distance 100
# 将指定接口设为被动接口
# passive-interface(命令关键字)+ vlan x(接口名称)
Core1(config-router)#passive-interface vlan 10
Core1(config-router)#passive-interface vlan 20
Core1(config-router)#passive-interface vlan 30
Core1(config-router)#passive-interface vlan 100
Core1(config-router)#exit分析
RIP 网络发布分析
plaintext
network 10.0.0.0 命令的作用:
- 匹配所有 IP 地址以 10.x.x.x 开头的接口
- 在这些接口上启用 RIP 协议
在 Core1 上:
- SVI VLAN 200: 10.0.0.1/30 → 匹配并启用 RIP(与 AR-Old 通信)
- SVI VLAN 10: 10.1.10.254/24 → 匹配但设为被动接口
- SVI VLAN 20: 10.1.20.253/24 → 匹配但设为被动接口
- SVI VLAN 30: 10.1.30.253/24 → 匹配但设为被动接口
- SVI VLAN 100: 10.1.100.254/24 → 匹配但设为被动接口RIP 与 OSPF 共存设计
plaintext
Core1/2 同时运行 RIP 和 OSPF:
┌──────────────────────────────────────────┐
│ Core1/2 route protocol │
│ │
│ RIP process │
│ ├── network 10.0.0.0 │
│ └── passive-interface VLAN 10/20/30/100 │
│ │
│ OSPF process │
│ ├── network 10.1.10.0/24 area 0 │
│ ├── network 10.1.20.0/24 area 0 │
│ ├── network 10.1.30.0/24 area 0 │
│ ├── network 10.1.100.0/24 area 0 │
│ └── passive-interface VLAN 10/20/30 │
│ │
└──────────────────────────────────────────┘总结:这段配置在核心交换机上启用了 RIP v2 协议,通过 network 10.0.0.0 在互联接口上启用 RIP,同时将业务和管理 VLAN 设为被动接口,确保 RIP 仅在与 AR-Old 的互联链路上运行。这样设计为后续的 RIP ↔ OSPF 路由重分发奠定了基础。
3. OSPF ↔ RIP 双向重分发
需在 Core1、Core2 两台核心交换机上分别执行以下命令:
方向一:RIP 路由重分发进 OSPF
将老旧厂区的 RIP 网段注入 OSPF 域,实现总部访问老旧厂区:
bash
# 进入 OSPF 进程 1,指定要配置重分发的 OSPF 进程
Core1(config)#router ospf 1
# redistribute: 命令关键字,配置路由重分发
# rip: 源路由协议,从 RIP 协议重分发路由
# subnets: 参数,重分发子网路由(否则只重分发主网路由)
# metric-type 1: 参数,设置外部路由类型为 E1(Type 1)
# metric 10: 参数,设置度量值(cost)为 10
# route-map RIP-to-OSPF: 参数,应用名为 RIP-to-OSPF 的路由策略
Core1(config-router)#redistribute rip subnets metric-type 1 metric 10 route-map RIP-to-OSPF
# redistribute: 命令关键字,配置路由重分发
# static: 源路由类型,以静态路由(NULL0汇总路由)为源注入OSPF
# metric-type 1: 参数,设置外部路由类型为 E1(Type 1)
# metric 10: 参数,设置度量值(cost)为 10
# route-map RIP-to-OSPF: 参数,应用名为 RIP-to-OSPF 的路由策略
Core1(config-router)#redistribute static subnets metric-type 1 metric 10 route-map RIP-to-OSPF
Core1(config-router)#exit方向二:总部网段重分发进 RIP
由于总部业务网段为核心本地直连 SVI,不会以 OSPF 路由条目出现在路由表中,因此借助已配置的 NULL0 静态汇总路由作为源,将总部汇总网段注入 RIP,同时保留防环路能力:
bash
# OSPF路由重分发进RIP,指定跳数
# 进入 RIP 进程,指定要配置重分发的 RIP 进程
Core1(config)#router rip
# redistribute: 命令关键字,配置路由重分发
# ospf 1: 源路由协议,从 OSPF 进程 1 重分发路由
# metric 5: 参数,设置 RIP 跳数为 5
# route-map OSPF-to-RIP: 参数,应用名为 OSPF-to-RIP 的路由策略
Core1(config-router)#redistribute ospf 1 metric 5 route-map OSPF-to-RIP
# redistribute: 命令关键字,配置路由重分发
# static: 源路由类型,以静态路由(NULL0汇总路由)为源注入RIP
# metric 5: 参数,设置 RIP 跳数为 5
# route-map OSPF-to-RIP: 参数,应用名为 OSPF-to-RIP 的路由策略
Core1(config-router)#redistribute static metric 5 route-map OSPF-to-RIP
# 出方向过滤:仅允许汇总路由发布,拦截所有直连明细网段
Core1(config-router)#distribute-list prefix OSPF-Routes out
Core1(config-router)#exit总结:这段配置实现了 OSPF 和 RIP 之间的双向路由重分发。RIP 路由通过
redistribute rip subnets metric-type 1 metric 10进入 OSPF 域,设置为 E1 类型;OSPF 路由通过redistribute ospf 1 metric 5进入 RIP 域,设置跳数为 5。路由策略(route-map)用于精确控制路由过滤,防止路由环路和次优路径。
分析
路由重分发原理
E1 vs E2 外部路由类型
plaintext
OSPF 外部路由分为两种类型:
- E1 (Type 1):外部度量值 + 内部开销,适合域间路由
- E2 (Type 2):仅外部度量值,默认类型
配置 metric-type 1 的原因:
- 当存在多条路径时,E1 类型会考虑内部开销
- 更准确地反映到达目标网络的真实代价RIP 度量值(跳数)
plaintext
RIP 使用跳数作为度量值,最大跳数为 15。
配置 metric 5 的原因:
- 预留一定的跳数余量(5 < 15)
- 避免路由被标记为不可达路由策略(Route-Map)作用
plaintext
route-map 用于过滤和修改路由:
- RIP-to-OSPF:控制哪些 RIP 路由可以进入 OSPF 域
- OSPF-to-RIP:控制哪些 OSPF 路由可以进入 RIP 域
典型应用:
1. 过滤掉不需要的路由
2. 修改路由属性(如度量值、标签)
3. 防止路由环路
4. 实现路由策略控制双向重分发网络架构
plaintext
RIP 域 OSPF 域
┌──────────────┐ ┌──────────────┐
│ AR-Old │ │ Core1 │
│ RIP v2 │──────────│ RIP + OSPF │
│ 10.2.0.0/24 │ │ 重分发点 │
└──────────────┘ └───────┬──────┘
│
┌───────┴───────┐
▼ ▼
Access1/2/3 Core2
(OSPF客户端) (重分发点)路由学习方向
方向一:RIP → OSPF(老旧厂区 → 总部)
plaintext
AR-Old 发布 10.2.0.0/24
│
▼
Core1/Core2 通过 RIP 学习
│
▼
重分发进 OSPF(metric-type 1, metric 10)
│
▼
Access1/2/3 通过 OSPF 学习到 10.2.0.0/24方向二:OSPF → RIP(总部 → 老旧厂区)
plaintext
Core1/Core2 汇总发布 10.1.0.0/16
│
▼
重分发进 RIP(metric 5)
│
▼
AR-Old 通过 RIP 学习到 10.1.0.0/164. 路由策略配置(防路由回灌)
需在 Core1、Core2 两台核心交换机上分别配置
通过前缀列表精确匹配双方原生网段,仅允许原生网段跨协议重分发:
bash
# 前缀列表配置
# ip prefix-list: 命令关键字,创建前缀列表
# RIP-Routes / OSPF-Routes: 前缀列表名称,标识前缀列表的用途
# seq 5: 序列号,匹配顺序(数值越小越优先)
# permit: 动作,允许匹配的路由
# 10.2.0.0/24 / 10.1.0.0/16: 前缀,要匹配的网络地址和掩码
ip prefix-list RIP-Routes seq 5 permit 10.2.0.0/24
ip prefix-list OSPF-Routes seq 5 permit 10.1.0.0/16
# 路由策略配置
# route-map: 命令关键字,创建路由策略
# RIP-to-OSPF / OSPF-to-RIP: 路由策略名称,标识策略的用途方向
# permit 10: 动作和序列号,permit 表示允许,10 是序列号
# match ip address prefix-list 根据前缀列表匹配路由
# RIP-Routes / OSPF-Routes: 前缀列表名称,指定要使用的前缀列表
route-map RIP-to-OSPF permit 10
match ip address prefix-list RIP-Routes
route-map OSPF-to-RIP permit 10
match ip address prefix-list OSPF-Routes RIP-Routes分析
路由策略工作流程
方向一:RIP → OSPF
plaintext
路由进入重分发:
│
▼
检查 route-map RIP-to-OSPF:
│
├─ seq 10: match ip address prefix-list RIP-Routes
│ ├─ 10.2.0.0/24 → permit(允许通过)
│ └─ 其他路由 → deny(默认拒绝)
│
▼
允许 10.2.0.0/24 进入 OSPF 域方向二:OSPF → RIP
plaintext
路由进入重分发:
│
▼
检查 route-map OSPF-to-RIP:
│
├─ seq 10: match ip address prefix-list OSPF-Routes RIP-Routes
│ ├─ 10.1.0.0/16 → permit(允许通过)
│ ├─ 10.2.0.0/24 → permit(允许通过)
│ └─ 其他路由 → deny(默认拒绝)
│
▼
允许 10.1.0.0/16 和 10.2.0.0/24 进入 RIP 域设计意图分析
| 设计特点 | 说明 |
|---|---|
| 精确匹配 | 使用前缀列表精确控制允许重分发的网段 |
| 防止回灌 | 只允许原生网段跨协议传递,防止路由环路 |
| 默认拒绝 | route-map 默认拒绝所有未匹配的路由 |
| 扩展性 | 可以方便地添加更多前缀列表条目 |
总结:这段配置通过前缀列表和路由策略实现了精确的路由过滤。
RIP-Routes前缀列表匹配老旧厂区的 10.2.0.0/24 网段,OSPF-Routes前缀列表匹配总部的 10.1.0.0/16 网段。路由策略RIP-to-OSPF和OSPF-to-RIP分别控制两个方向的重分发,确保只有原生网段才能跨协议传递,从而有效防止路由回灌和环路。
四、功能验证步骤
各VPC的ip配置
bash
# VPC1(VLAN10 办公)
VPC1> ip 10.1.10.1/24 10.1.10.254
# VPC2(VLAN20 财务)
VPC2> ip 10.1.20.2/24 10.1.20.254
# VPC3(VLAN30 生产)
VPC3> ip 10.1.30.3/24 10.1.30.254
# VPC4(VLAN10 办公)
VPC4> ip 10.1.10.4/24 10.1.10.254
# VPC5(VLAN20 财务)
VPC5> ip 10.1.20.5/24 10.1.20.254
# VPC6(VLAN30 生产)
VPC6> ip 10.1.30.6/24 10.1.30.254(一)跨 VLAN 互通验证
- 核心交换机 执行
show ip interface brief,确认所有 VLAN 接口协议与状态均为 up - 测试不同 VLAN 终端互访:
- PC1(VLAN10)ping PC2(VLAN20)、PC3(VLAN30)
- PC5(VLAN20)ping PC4(VLAN10)、PC6(VLAN30)
- 预期结果 :不同 VLAN 终端均可正常互通,证明核心 SVI 接口、
ip routing三层转发功能工作正常。
(二)动态路由双活负载均衡与高可用(HA)破坏性测试
本环节旨在验证 OSPF 与 RIP 双向重分发架构下的端到端双活(ECMP)能力,以及单点链路故障时的动态路由自动收敛与自愈能力。
1. 双活状态(ECMP)基线验证
在故障注入前,确认全网处于完美的双活负载均衡状态:
- 接入层(上行流量)验证 :在 Access1 上执行
show ip route ospf,确认去往老旧厂区10.2.0.0/24的 O E1 外部路由存在双下一跳 (分别指向 Core1 的10.1.100.254和 Core2 的10.1.100.253)。 - 边缘层(回程流量)验证 :在 AR-Old 上执行
display ip routing-table 10.1.0.0 16,确认去往总部汇总网段的 RIP 路由存在双下一跳 (分别指向 Core1 的10.0.0.1和 Core2 的10.0.0.5)。
2. 故障注入与毫秒级收敛测试
- 开启长 Ping:在总部 PC1 上持续 Ping 老旧厂区网关,观察业务中断情况:
bash
ping 10.2.0.254 -t- 模拟主链路物理故障:在 Core1 上关闭连接 AR-Old 的互联接口:
bash
Core1(config)# interface vlan 200
Core1(config-if)# shutdown- 观察业务与路由收敛 :
- 业务层表现:PC1 的长 Ping 测试仅丢失 1~3 个 ICMP 报文(收敛耗时约 1~3 秒)即自动恢复连通。
- 接入层验证 :再次在 Access1 上执行
show ip route ospf,确认10.2.0.0/24的路由自动撤销了经由 Core1 的下一跳 ,上行流量无缝、精准地切换至 Core2(单臂支撑)。同时,总部内网路由依然保持双活,证明故障被完美隔离。若没有自动切换,可执行clear ip route *清一下路由。 - 边缘层验证:在 AR-Old 上查看路由表,确认回程双活路由瞬间收敛为单一备用路由(仅指向 Core2)。
3. 链路恢复与双活自动回切验证
- 恢复主链路:在 Core1 上重新开启接口:
bash
Core1(config-if)# no shutdown- 控制平面重置(关键排错步骤) :
由于 Cisco IOS 在双向重分发环境中存在"仅重分发活跃路由"的底层机制,链路恢复后,旧的路由依赖可能导致双活无法自动恢复。需在 Core1 和 Core2 上执行强制刷新:
bash
Core1# clear ip route *
Core2# clear ip route *- 验证满血复活 :等待约 10~20 秒后,再次在 Access1 和 AR-Old 上查看路由表,确认双下一跳(ECMP)状态自动恢复,网络再次回到无死角的双活负载均衡状态。
实验总结 :
采用 OSPF + RIP 动态路由双向重分发设计。结合核心层 AD 值调优(
distance 100消除次优路径)与 Route-Map 防环策略。
(三)OSPF 功能验证
- 邻居验证:
核心执行show ip ospf neighbor,确认邻居状态为 Full - 路由学习:
接入交换机执行show ip route ospf,确认学习到业务网段与默认路由 - DR/BDR 验证:执行
show ip ospf interface Vlan100,确认 Core1 为 DR、Core2 为 BDR - 汇总路由验证:执行
display rip 1 route和display ip routing-table 10.1.0.0 16,能看到协议标记为R(RIP),Cost=1,双下一跳 10.0.0.1/10.0.5,就是正常的总部汇总路由。
(四)路由重分发与端到端验证
- OSPF 侧路由验证(外部路由注入检查):
- 在 接入交换机(Access) 上验证:执行
show ip route ospf,确认 10.2.0.0/24 已成功学习为 OSPF 外部路由(路由表中标记为 O E1 或 O E2),且下一跳正确指向核心交换机。 - 在 核心交换机(Core) 上验证:作为重分发边界(ASBR),核心交换机本地的
show ip route ospf输出为空是正常现象。应执行全局路由表命令show ip route,确认10.2.0.0/24显示为原始协议路由(如静态路由 S 或直连路由 C)。 - 核心交换机(Core) 进阶 LSA 验证:在核心交换机上执行
show ip ospf database external 10.2.0.0,确认该网段已成功生成 Type-5 LSA 并注入 OSPF 域。
- 在 接入交换机(Access) 上验证:执行
- RIP 侧验证:vSR 执行
display rip 1 route,确认学习到总部 10.1.0.0/16 网段 - 端到端连通:所有 PC 执行
ping 10.2.0.254,验证总部与老旧厂区端到端可达 - 防环路验证:
核心执行show ip route rip,确认无 10.1.0.0/16 的 RIP 路由,无路由回灌
(五)老旧厂区能访问总部所有网段验证
- 路由表预校验(先确认路由存在)
在 AR-Old 上执行命令,确认已获取总部网段路由:
bash
# 查看 RIP 学习到的总部路由
<AR-Old> display rip 1 route
# 查看全局路由表中的总部网段
<AR-Old> display ip routing-table 10.1.0.0 16预期结果:能看到 10.1.0.0/16 的 RIP 路由,下一跳分别指向 Core1(主)和 Core2(备)。
- 端到端流量验证(厂区侧主动发起)
以 AR-Old 的 LoopBack0 地址作为源地址,模拟老旧厂区内网访问总部各个业务网段,覆盖所有 VLAN:
bash
# 测试访问总部 VLAN10 网段(指定源IP为厂区网段地址)
<AR-Old> ping -a 10.2.0.254 10.1.10.254
# 测试访问总部 VLAN20 网段
<AR-Old> ping -a 10.2.0.254 10.1.20.254
# 测试访问总部 VLAN30 网段
<AR-Old> ping -a 10.2.0.254 10.1.30.254
# 测试访问总部管理 VLAN100 网段
<AR-Old> ping -a 10.2.0.254 10.1.100.254预期结果:所有 ping 均能通,证明老旧厂区可以访问总部所有业务网段和管理网段。
配置结构图
#mermaid-svg-g2GyuNzOp7HuKpbZ{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-g2GyuNzOp7HuKpbZ .error-icon{fill:#552222;}#mermaid-svg-g2GyuNzOp7HuKpbZ .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-g2GyuNzOp7HuKpbZ .marker{fill:#333333;stroke:#333333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .marker.cross{stroke:#333333;}#mermaid-svg-g2GyuNzOp7HuKpbZ svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-g2GyuNzOp7HuKpbZ p{margin:0;}#mermaid-svg-g2GyuNzOp7HuKpbZ .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster-label text{fill:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster-label span{color:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster-label span p{background-color:transparent;}#mermaid-svg-g2GyuNzOp7HuKpbZ .label text,#mermaid-svg-g2GyuNzOp7HuKpbZ span{fill:#333;color:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .node rect,#mermaid-svg-g2GyuNzOp7HuKpbZ .node circle,#mermaid-svg-g2GyuNzOp7HuKpbZ .node ellipse,#mermaid-svg-g2GyuNzOp7HuKpbZ .node polygon,#mermaid-svg-g2GyuNzOp7HuKpbZ .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .rough-node .label text,#mermaid-svg-g2GyuNzOp7HuKpbZ .node .label text,#mermaid-svg-g2GyuNzOp7HuKpbZ .image-shape .label,#mermaid-svg-g2GyuNzOp7HuKpbZ .icon-shape .label{text-anchor:middle;}#mermaid-svg-g2GyuNzOp7HuKpbZ .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .rough-node .label,#mermaid-svg-g2GyuNzOp7HuKpbZ .node .label,#mermaid-svg-g2GyuNzOp7HuKpbZ .image-shape .label,#mermaid-svg-g2GyuNzOp7HuKpbZ .icon-shape .label{text-align:center;}#mermaid-svg-g2GyuNzOp7HuKpbZ .node.clickable{cursor:pointer;}#mermaid-svg-g2GyuNzOp7HuKpbZ .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .arrowheadPath{fill:#333333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-g2GyuNzOp7HuKpbZ .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-g2GyuNzOp7HuKpbZ .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-g2GyuNzOp7HuKpbZ .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster text{fill:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ .cluster span{color:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-g2GyuNzOp7HuKpbZ .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-g2GyuNzOp7HuKpbZ rect.text{fill:none;stroke-width:0;}#mermaid-svg-g2GyuNzOp7HuKpbZ .icon-shape,#mermaid-svg-g2GyuNzOp7HuKpbZ .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-g2GyuNzOp7HuKpbZ .icon-shape p,#mermaid-svg-g2GyuNzOp7HuKpbZ .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-g2GyuNzOp7HuKpbZ .icon-shape .label rect,#mermaid-svg-g2GyuNzOp7HuKpbZ .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-g2GyuNzOp7HuKpbZ .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-g2GyuNzOp7HuKpbZ .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-g2GyuNzOp7HuKpbZ :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-g2GyuNzOp7HuKpbZ .no-wrap>*{white-space:pre!important;text-align:left!important;}#mermaid-svg-g2GyuNzOp7HuKpbZ .no-wrap span{white-space:pre!important;text-align:left!important;}#mermaid-svg-g2GyuNzOp7HuKpbZ .sg-title>*{font-size:30px!important;font-weight:700!important;}#mermaid-svg-g2GyuNzOp7HuKpbZ .sg-title span{font-size:30px!important;font-weight:700!important;} 终端业务区
接入层(二层转发 + 管理网段 OSPF)
总部核心层(OSPF Area 0 + RIP 双向重分发)
老旧厂区网络(RIP v2 域)
LACP 链路聚合 Trunk
允许所有 VLAN
备链路
VLAN201: 10.0.0.4/30
GE2/0 ↔ G1/1
主链路
VLAN200: 10.0.0.0/30
GE1/0 ↔ G1/1
Trunk
VLAN 10/20/30/100
Trunk
VLAN 10/20/30/100
Trunk
VLAN 10/20/30/100
Trunk
VLAN 10/20/30/100
Trunk
VLAN 10/20/30/100
Trunk
VLAN 10/20/30/100
Access VLAN 10
Access VLAN 20
Access VLAN 10
Access VLAN 20
Access VLAN 30
Access VLAN 30
AR-Old
RIP 进程 1
LoopBack0: 10.2.0.254/24
GE1/0: 10.0.0.2/30 | GE2/0: 10.0.0.6/30
Core1
Router-ID: 10.1.100.254
OSPF 优先级 150(DR)
SVI: Vlan10/20/30/100/200
Core2
Router-ID: 10.1.100.253
OSPF 优先级 100(BDR)
SVI: Vlan10/20/30/100/201
Access1
管理 SVI: Vlan100
10.1.100.1/24
Access2
管理 SVI: Vlan100
10.1.100.2/24
Access3
管理 SVI: Vlan100
10.1.100.3/24
PC1
VLAN10
10.1.10.1/24
PC2
VLAN20
10.1.20.2/24
PC3
VLAN30
10.1.30.3/24
PC4
VLAN10
10.1.10.4/24
PC5
VLAN20
10.1.20.5/24
PC6
VLAN30
10.1.30.6/24
相关知识
SVI
SVI = Switched Virtual Interface,交换虚拟接口
属于三层逻辑接口 ,仅存在于支持三层交换的设备(三层交换机、核心交换机、汇聚交换机),没有对应的物理端口,是绑定某个 VLAN 的虚拟三层网关接口。
简单一句话:给 VLAN 分配 IP 地址、实现 VLAN 之间互通的虚拟三层接口。
核心功能
- 充当对应 VLAN 内终端的默认网关
同一 VLAN 下 PC、服务器把 SVI 地址设为网关,跨 VLAN 访问流量交给 SVI 三层转发。 - 实现 VLAN 间路由(三层交换)
二层交换机只能同 VLAN 互通;不同 VLAN 天然隔离,必须靠 SVI 做三层转发。 - 设备自身管理地址
给交换机配置管理 IP,远程 SSH/Telnet 管理交换机,就是创建对应 VLAN 的 SVI 配 IP。 - 对接上行路由、静态路由、OSPF/IS-IS 等动态路由协议
SVI 可以参与路由协议,和防火墙、路由器、其他三层交换机交换路由条目。 - 支持 ACL、QoS、HA 冗余(HSRP/VRRP)
所有三层接口特性都能在 SVI 上配置,做流量控制、冗余网关。
为什么必须要有 SVI(底层原理)
1. 二层 VLAN 天然隔离
VLAN 是二层隔离技术,不同 VLAN 属于不同广播域、不同子网 。
PC1:VLAN10,192.168.10.0/24
PC2:VLAN20,192.168.20.0/24
仅二层转发时,两者无法通信,二层设备不会转发跨 VLAN 流量。
2. 两种跨 VLAN 方案对比,凸显 SVI 价值
方案 A:单臂路由(路由器 + 二层交换机)
交换机所有 VLAN trunk 上联路由器单物理口,路由器子接口做单臂。
缺点:性能瓶颈,所有跨 VLAN 流量挤一条物理链路,吞吐低,大型园区不用。
方案 B:三层交换机 SVI(主流)
三层交换机内置硬件三层转发芯片,SVI 是板载虚拟接口,跨 VLAN 转发走硬件 ASIC,线速转发,无性能瓶颈 。
这就是大型局域网、园区网、数据中心全部用 SVI 的根本原因。
3. 管理设备刚需
二层交换机只能在一个 VLAN配管理 IP;三层交换机可创建多个 SVI,每个 VLAN 都能有三层地址,运维更灵活。
4. 网关冗余需求
双核心三层交换机,同 VLAN 创建 SVI,部署 VRRP/HSRP 生成虚拟网关,一台故障另一台接管,保障业务不中断,SVI 是冗余网关的载体。
实际设备中 SVI 如何存在、配置形态
1. 设备前提
只有三层交换机 支持 SVI
纯二层交换机(傻瓜交换机、二层接入交换机)没有 SVI 功能。
2. SVI 的本质存在形式
- 逻辑对象,无物理硬件端口;
- 一一绑定 VLAN:interface Vlanif 10(华为)= interface Vlan 10(思科),一个 VLAN 最多一个 SVI;
- 存在于设备的三层转发表、VLAN 数据库、接口表中;
- 状态依赖 VLAN:
- 对应 VLAN 不存在 → SVI down;
- VLAN 存在,但无任何 access/trunk 端口属于该 VLAN → SVI 协议 down;
- VLAN 内有至少一个 UP 的端口,SVI 才 UP。
SVI vs 物理三层接口
- SVI:虚拟、绑定 VLAN、用于终端网关、大量部署;
- 三层物理口(interface GigabitEthernet 0/0/1):真实网口,取消 switchport,直接配 IP,用于设备间互联(交换机 - 防火墙、交换机 - 路由器),不绑定 VLAN。
浮动静态路由
1. 浮动静态路由是什么
浮动静态路由(Floating Static Route)本质是经过优先级调整的特殊静态路由,是基于设备路由选路规则实现的主备静态路由机制。
网络设备会为不同来源的路由(直连、静态、动态协议)分配一个可信度评分:华为称为路由优先级(Preference) ,思科称为管理距离(AD, Administrative Distance) ,核心规则一致:数值越小,路由优先级越高、可信度越高。
针对同一个目标网段,手动配置一条比主路由优先级数值更大(实际优先级更低) 的静态路由:正常情况下它不会被加入IP路由表,也不参与数据转发;只有当主路由失效(主链路中断、下一跳不可达)时,这条低优先级静态路由才会"浮上来",被加载到路由表中承担转发任务,"浮动" 正是对这种 "平时潜伏、故障上浮" 工作状态的形象描述。
2. 为什么会有浮动静态路由
它的出现是为了填补普通静态路由无自动冗余 和动态路由协议成本高之间的空白:
- 普通静态路由的天然缺陷:静态路由配置简单、转发稳定、不消耗设备CPU,但没有链路探测和自动切换能力。主链路故障后,失效路由不会自动消失,备用路径也不会自动启用,必须人工修改配置才能恢复,业务中断时间长。
- 动态路由的场景不匹配:部署OSPF、BGP等动态路由协议可以实现自动故障切换,但对于小型分支、门店、末梢监控点等简单网络,动态协议配置复杂、维护成本高,属于过度设计。
- 低成本冗余需求:企业大量场景只需要"主链路+备份链路"的简单冗余(如专线+4G/5G备份),浮动静态路由仅通过修改一个优先级参数,就能利用设备原生的路由选路逻辑实现自动主备切换,几乎零额外成本。
3. 浮动静态路由的作用
- 链路冗余与高可用(核心作用):为同一目标网段提供主备两条转发路径,主链路故障时备用路径自动接管业务,无需人工干预,大幅缩短中断时间,提升网络可靠性。
- 流量路径精细化管控:日常业务流量仅走高带宽、低延迟的主链路(如专线、光纤),低优先级的备用链路(如4G/5G、低速互联网)仅在故障时启用,既保证日常业务质量,又避免备用链路的无效占用。
- 末梢网络低成本部署:适用于企业分支、门店、户外点位等末梢节点,无需部署复杂的动态路由协议,仅两条静态路由即可实现双链路备份,配置和维护门槛极低。
- 动态路由兜底备份:在大中型网络中,可将浮动静态路由作为OSPF、BGP等动态路由的兜底备用路径;当动态路由学习异常、邻居中断时,由静态备份路径保底,避免业务完全中断。
4. 浮动静态路由与普通静态路由有区别吗
浮动静态路由本质上仍属于静态路由,不是独立的路由类型,二者核心差异在于优先级、生效逻辑和定位,具体对比如下:
| 对比维度 | 普通静态路由 | 浮动静态路由 |
|---|---|---|
| 优先级/管理距离 | 使用厂商默认值(华为60、思科1) | 手动设置为更大的数值(如华为100、思科200),优先级低于主路由 |
| 路由表状态 | 只要下一跳可达、出接口正常,就常驻IP路由表 | 正常状态下仅存在于配置中,不进入路由表;主路由失效后才加载 |
| 核心角色 | 业务流量的主用转发路径 | 主路由的备份路径,平时不承担转发 |
| 配置方式 | 标准静态路由命令,无需指定优先级 | 静态路由命令末尾额外指定优先级/管理距离参数 |
| 适用场景 | 指定固定转发路径 | 链路冗余、故障备份场景 |
补充说明:如果两条同目的静态路由优先级完全相同,设备会执行等价负载分担,两条路由同时出现在路由表中;而浮动静态路由优先级不同,永远是主备模式,不会同时生效。
5. 浮动静态路由在设备中的实际呈现形式
设备本身没有"浮动路由"这个独立协议分类,它在设备中分为配置层面 和路由表层面两种呈现:
(1)配置形式
核心是在静态路由命令后追加优先级/管理距离参数,主流厂商配置示例如下:
-
华为设备(路由优先级 Preference,数值越小越优先)
- 主静态路由(使用默认优先级60)
- 浮动静态路由(手动设置优先级100,优先级低于主路由)
-
思科 IOS 设备(管理距离 AD,数值越小越优先)
- 主静态路由(使用默认管理距离1)
- 浮动静态路由(手动设置管理距离200)
(2)路由表呈现
-
正常状态(主链路正常) :
查看IP路由表时,只能看到主静态路由,浮动路由不会出现在转发表中,仅存在于配置文件里。
-
故障状态(主链路中断) :
设备检测到主路由下一跳不可达、出接口Down后,会自动移除主路由,将浮动静态路由加载进路由表,协议类型仍标记为
Static,仅优先级数值变化
补充:原生浮动静态路由仅依赖接口状态、下一跳直连可达性检测故障,切换精度有限;实际项目中通常会搭配 BFD(双向转发检测) 或 NQA(网络质量分析) 联动,实现毫秒级的链路故障检测与切换。
OSPF
OSPF = Open Shortest Path First,开放式最短路径优先
是目前业界应用最广泛的链路状态型内部网关协议(IGP) ,主要用于单个自治系统(AS)内部的路由计算与分发。
对应 IPv4 网络的主流版本为 OSPFv2,对应 IPv6 网络的主流版本为 OSPFv3。
- OSPF 属于网络层路由协议 ,不经过 TCP/UDP,直接使用 IP 协议承载,IP 协议号为 89,封装结构:
以太网帧头 → IP 头 → OSPF 报文 - 协议全程围绕 IP 体系设计:
- 路由器的 OSPF Router-ID 采用 IP 地址格式;
- 邻居发现、LSA 泛洪、最短路径计算全部基于 IP 网段进行;
- OSPFv2 对应 IPv4,OSPFv3 对应 IPv6,都运行在对应版本的 IP 网络层之上。
核心特征
- 基于 Dijkstra(最短路径优先 SPF)算法计算路由,从机制上避免路由环路
- 属于无类路由协议,原生支持 VLSM(可变长子网掩码)与 CIDR(无类域间路由)
- 采用区域化分层架构,强制以 Area 0(骨干区域)为核心,所有非骨干区域必须挂靠骨干区域,实现故障隔离与网络横向扩展
- 路由度量值为 Cost(开销),默认基于链路带宽计算,带宽越高开销越小,路径优先级越高
- 通过组播地址传递开销报文(224.0.0.5 所有 OSPF 路由器、224.0.0.6 DR/BDR 路由器),减少对无关设备的干扰
- 采用触发更新 + 周期刷新机制:拓扑变化时立即泛洪更新,正常状态下30分钟周期刷新 LSA,保证全网链路状态一致
核心工作逻辑:网络中所有 OSPF 路由器都会生成描述自身直连链路、网段、开销的 LSA(链路状态通告),通过泛洪机制同步到整个区域内的所有路由器;每台路由器都会拥有一份完全一致的链路状态数据库(LSDB),再基于 LSDB 独立运行 SPF 算法,计算出到各个目标网段的最短路径。
为什么会有 OSPF?
OSPF 的诞生,核心是解决早期路由方案在中大型网络中的固有缺陷:
- 静态路由的能力天花板:静态路由手动配置,在节点数量少的网络中简单高效,但随着网络规模扩大,配置量呈指数级增长;拓扑变化(链路中断、新增网段)必须人工修改,无法自动适配,维护成本极高,完全不适合中大型网络。
- 距离矢量协议的先天短板:在 OSPF 之前主流的 RIP 协议,以跳数为度量值(最大15跳),无法适配大型网络;路由逐跳传递易产生环路,收敛速度慢,且不支持分层设计,网络规模越大性能越差,无法满足企业级网络的可靠性与扩展需求。
- 开放标准与厂商互通需求:早期部分路由协议为厂商私有,不同品牌设备无法互通;OSPF 为 IETF 制定的开放标准协议,所有主流网络厂商(华为、思科、锐捷等)均原生支持,跨厂商组网兼容性强。
- 企业网络分层设计的刚需:大中型企业网络普遍采用核心-汇聚-接入的分层架构,OSPF 的区域化设计天然适配这种架构,可将故障、LSA 泛洪范围限制在单个区域,大幅提升网络稳定性与可维护性。
OSPF 的作用
- 自动路由学习与动态收敛(核心作用):自动发现网络中的所有网段,计算最优转发路径;当链路故障、拓扑变更时,自动重新计算路由并同步全网,无需人工干预,大幅缩短业务中断事件。
- 提供无环路的最优转发路径:基于 SPF 算法从全局拓扑计算最短路径,结合区域间防环规则,从机制上避免路由环路;以链路带宽为核心的开销度量,比跳数更贴合实际网络质量,保证流量走最优链路。
- 支持大规模网络的可扩展部署:通过骨干区域 + 非骨干区域的分层架构,隔离 LSA 泛洪范围,降低单台设备的数据库大小与计算压力,支持从几十台到上千台节点的企业级网络。
- 精细化流量与路由管控:支持路由汇总、开销调度、路由过滤、路由策略、接口认证等丰富功能,可根据业务需求规划流量路径,限制路由传播范围,保障网络安全与可控性。
- 提升网络冗余与可靠性:天然支持等价多路径(ECMP),同开销的多条链路同时承载流量,实现负载分担;结合 BFD 等技术可实现毫秒级故障切换,满足高可用业务需求。
- 作为内部路由基础承载上层业务:是企业内网、数据中心、城域网最主流的 IGP 协议,同时可作为 BGP、MPLS VPN等上层协议到的底层路由承载。
OSPF 在设备中的实际呈现形式
OSPF 在设备中以 协议进程 + 多维表项 + 路由条目 的形式存在,分为配置层面 和运行状态层面两部分:
- 配置形式
OSPF 需要先创建进程,再宣告网段并绑定区域 - 运行状态与路由表呈现
OSPF 运行后会维护三张核心表:邻居表、链路状态数据库(LSDB)、路由表- 邻居表:确认 OSPF 邻居关系
- 链路状态数据库(LSDB):全网拓扑的统一视图
- IP 路由表中的 OSPF 条目:正常状态下,OSPF 计算出的最优路由会加载到 IP 路由表,协议类型标记为 OSPF,同时区分内部路由、外部路由。
RIP
RIP = Routing Information Protocol(路由信息协议)
是网络发展史上最早普及的距离矢量型内部网关协议(IGP),工作在应用层,基于 UDP 520 端口传输,用于小型自治系统(AS)内部的路由自动学习与分发。
- RIP 属于应用层路由协议 ,报文通过 UDP 封装,使用 UDP 520 端口,最终承载在 IP 报文中传输,完整封装结构:
以太网帧头 → IP 头 → UDP 头 → RIP 路由报文 - 它的核心功能就是交换 IP 网段的路由信息:RIPv1 支持有类 IPv4,RIPv2 支持无类 IPv4(CIDR),RIPng 对应 IPv6,全程围绕对应版本的 IP 地址、IP 子网设计。
- 没有接口 IP 地址、没有 IP 连通性,RIP 邻居无法建立,路由条目也无法传递。
核心版本与特性
- RIPv1 :初代有类路由协议,以广播(255.255.255.255)发送更新,不支持 VLSM(可变长子网掩码),无认证机制,现已基本淘汰。
- RIPv2 :主流实用版本,无类路由协议,以组播(224.0.0.9)发送更新,原生支持 VLSM/CIDR,支持明文 / MD5 接口认证。
- RIPng:适配 IPv6 网络的版本,继承 RIPv2 的核心机制。
| 特性 | RIP v1 | RIP v2 |
|---|---|---|
| 路由更新方式 | 广播 | 组播(224.0.0.9) |
| 子网掩码支持 | 不支持(有类路由) | 支持(无类路由) |
| 认证功能 | 不支持 | 支持 |
| 自动汇总 | 默认开启 | 默认开启(可关闭) |
核心运行机制
- 度量值为跳数(Hop Count),即到达目标网段需要经过的路由器数量;最大有效跳数为 15,跳数 16 被定义为 "不可达"。
- 采用周期性更新 + 触发更新:默认每 30 秒向直连邻居发送完整路由表;拓扑变化时立即触发增量更新。
- 配套水平分割、毒性逆转、抑制时间、最大跳数等防环机制,弥补距离矢量协议易产生路由环路的先天缺陷。
工作逻辑:路由器逐跳向邻居传递自身路由表,邻居接收后更新本地路由表再向下游传递,最终完成全网路由的分布式学习。
为什么会有 RIP?
RIP 诞生于网络发展早期,核心是填补静态路由在小型多节点网络中的能力空白:
- 解决静态路由的运维瓶颈:早期网络从单节点向多节点扩展,静态路由需要手动逐条配置,拓扑变更必须人工修改,效率极低;RIP 实现了路由的自动发现与更新,大幅降低小型网络的部署维护成本。
- 适配早期设备性能:早期路由器算力、内存非常有限,RIP 逻辑简单、实现复杂度极低、资源消耗极小,能在低性能硬件上稳定运行。
- 标准化与低门槛需求 :RIP 脱胎于 UNIX 系统的
routed程序,后由 IETF 标准化,配置门槛极低,仅需宣告网段即可完成部署,无需复杂的网络规划,适合小型场景快速组网。 - 距离矢量思想的落地:它是距离矢量路由理论首个大规模商业化落地的协议,为早期多节点网络提供了标准化的动态路由解决方案。
RIP 的作用
- 小型网络自动路由学习与维护(核心作用):在 15 跳以内的小型网络中,自动发现网段、生成路由,无需管理员逐台配置静态路由,降低初始部署成本。
- 基础故障自愈:链路或节点故障时,通过触发更新逐跳同步路由变化,自动切换到备用路径,无需人工干预,提供基础的网络冗余能力。
- 降低小型网络运维门槛:配置逻辑极简,无需复杂的协议规划和参数调优,普通运维人员即可快速部署和维护,适合无专业网络团队的小型场景。
- 异构设备互联互通:作为 IETF 标准协议,所有主流网络厂商、嵌入式设备、工业设备均原生支持,可实现不同品牌设备的小型网络路由互通。
- 遗留网络兼容过渡:在包含老旧设备的网络改造中,可通过 RIP 对接遗留系统,配合路由重分发实现新旧网络的路由平滑过渡。
RIP 在设备中实际呈现形式
RIP 在设备中以 协议进程 + 路由条目 的形式存在,分为配置层面和运行状态层面两部分
补充:RIP 没有 OSPF 那样严格的邻居建立流程和完整邻居表,仅维护路由条目与接口状态,可通过命令查看 RIP 接口信息、报文收发统计。
现在还用 RIP 吗?
新建中大型企业网络基本不再使用 RIP,它已全面被 OSPF 取代,但在特定场景下仍有应用。
仍在使用的场景
- 老旧遗留网络改造:很多早期部署的工厂、楼宇、小型园区网络仍在运行 RIP,出于业务稳定考虑不会轻易替换,改造时通常保留 RIP 并通过路由重分发对接新的 OSPF 网络。
- 低端嵌入式/工业物联网设备:部分工业交换机、物联网网关、嵌入式路由器性能极低,仅能支持 RIP 这种资源消耗极小的简单动态协议,这类场景下 RIP 仍有生存空间。
- 教学与认证考试:RIP 是距离矢量协议的典型代表,是学习路由原理、理解防环机制的基础案例,也是 HCIA、CCNA 等入门级网络认证的必考内容。
- 极小型简单组网:部分微型网点、双设备简单组网,偶尔会用 RIP 替代静态路由,减少配置工作量。
主流场景不再使用的核心原因
- 规模硬上限:15 跳的最大跳数限制,完全无法适配中大型网络的扩展需求。
- 收敛速度慢:依赖周期更新逐跳传递,故障收敛时间长达分钟级,且存在 "计数到无穷大" 的问题,无法满足高可用业务需求。
- 选路逻辑粗糙:仅以跳数作为选路依据,不考虑链路带宽、延迟、拥塞情况,经常会选出带宽更低但跳数更少的次优路径。
- 环路风险高:尽管有多重防环机制,拓扑变更过程中仍可能出现临时路由环路,稳定性远不如链路状态型的 OSPF。
- 功能特性匮乏:相比 OSPF 的区域划分、路由汇总、精细化策略等能力,RIP 的管控能力极弱,无法满足复杂网络的运维需求。
静态路由 vs 浮动静态路由 vs RIP vs OSPF
| 对比维度 | 普通静态路由 | 浮动静态路由 | RIP(距离矢量动态路由) | OSPF(链路状态动态路由) |
|---|---|---|---|---|
| 核心本质 | 手动配置的固定路由条目,无协议运行 | 调整了优先级的静态路由,静态路由的主备应用形态 | 距离矢量型内部网关动态协议 | 链路状态型内部网关动态协议 |
| 路由生成方式 | 管理员手动逐条配置下一跳 / 出接口 | 管理员手动配置,额外指定更高的优先级数值 | 邻居间周期性传递完整路由表,逐跳学习路由 | 泛洪链路状态 LSA 同步全网拓扑,每台设备独立运行 SPF 算法计算路由 |
| 核心选路依据 | 人工指定路径,无动态度量,仅靠优先级区分可信度 | 人工指定路径,通过优先级区分主备,本身无动态度量 | 跳数(经过路由器数量),最大 15 跳,16 跳视为不可达 | Cost(开销),默认与链路带宽成反比,带宽越高开销越小 |
| 路由表生效逻辑 | 下一跳可达、出接口正常时,常驻 IP 路由表 | 正常状态仅存在于配置文件中,不进入路由表;主路由失效后才加载进路由表 | 学习到的有效路由直接进入路由表,支持等价路由负载分担 | SPF 计算出的最优路径进入路由表,原生支持 ECMP 等价多路径负载分担 |
| 切换 / 收敛机制 | 无自动收敛能力,故障后必须人工修改或删除配置 | 依赖设备原生路由选路逻辑,主路由失效(接口 Down / 下一跳不可达)时自动上浮;主路由恢复后自动回切 | 周期更新 + 触发更新,收敛速度慢(分钟级),存在 "计数到无穷大" 问题 | 拓扑变化触发增量 LSA 泛洪,秒级收敛;结合 BFD 可实现毫秒级故障切换 |
| 支持网络规模 | 极小规模,单设备末梢接入场景 | 仅用于点到点双链路备份,不具备网络扩展能力 | 小型网络,15 跳以内,实际建议不超过 10 台设备 | 中大型网络,区域化分层架构可承载上千台节点 |
| 防环能力 | 无原生防环机制,配置不当极易产生路由环路 | 同静态路由,无原生防环;主备切换过程无环路风险 | 依靠水平分割、毒性逆转、最大跳数防环,仍可能出现临时环路 | 区域内 SPF 算法天然无环路;区域间强制骨干区域架构防环;外部路由带防环标记,机制完善 |
| 设备资源消耗 | 几乎为 0,不占用 CPU、内存 | 几乎为 0,仅多一条配置条目,无额外计算开销 | 极低,仅需维护路由表,计算量极小 | 较高,需维护邻居表、链路状态数据库(LSDB),周期性运行 SPF 计算 |
| 配置与维护成本 | 极简,小型网络零维护;网络越大、拓扑越多变,维护成本指数级上升 | 简单,仅比普通静态多一个优先级参数;仅适用于固定双链路场景 | 配置极简单,仅需宣告网段;大规模网络故障排查难度极高 | 初始配置稍复杂,需规划区域、Router ID;网络扩容时自动同步,长期维护成本低 |
| 网络扩展性 | 极差,新增网段、节点需逐台设备修改配置 | 无扩展性,仅用于固定点到点的备份场景 | 差,15 跳硬上限,规模扩大后收敛变慢、环路风险陡增 | 优秀,通过区域化分层隔离故障域,支持平滑横向扩容 |
| VLSM/CIDR 支持 | 原生完全支持,完全由管理员控制 | 原生完全支持 | RIPv1 不支持(有类路由);RIPv2 支持(无类路由) | 原生支持(无类路由协议) |
| 路由更新机制 | 无自动更新,永久生效直到手动删除 | 无自动更新,永久生效,仅随主路由状态切换是否进表 | 默认 30 秒周期向邻居发送完整路由表 | 拓扑变化时触发增量泛洪;稳态下 30 分钟周期刷新 LSA,不传递完整路由表 |
| 华为默认路由优先级 | 60 | 手动设置(通常≥100,数值大于主路由) | 100 | 内部路由:10;外部路由:150 |
| 思科默认管理距离(AD) | 1 | 手动设置(通常≥200,数值大于主路由) | 120 | 110 |
| 故障自愈能力 | 无,必须人工介入处理 | 有,仅支持固定主备链路自动切换,依赖主路由失效检测 | 有,但速度慢,故障扩散过程可能出现临时环路 | 有,收敛速度快,拓扑变更全程无临时环路 |
| 路由策略灵活度 | 极低,仅能调整优先级、修改下一跳 | 极低,仅通过调整优先级实现主备备份 | 一般,支持基础的路由过滤、度量值调整 | 极强,支持开销调整、路由汇总、过滤、策略路由、接口认证等丰富功能 |
| 典型适用场景 | 末梢节点、出口网关、固定单链路接入 | 双链路主备冗余、动态路由兜底备份路径 | 老旧小型网络、教学实验、仅支持 RIP 的低端物联网设备 | 企业园区网、数据中心、城域网等中大型网络的标准 IGP 方案 |
关系差异
- 层级差异:浮动静态路由不是新的路由类型,它和普通静态路由是 "同根同源" 的静态路由范畴;RIP 和 OSPF 是完整的动态路由协议,具备自主学习、计算、更新路由的能力。
- 切换逻辑差异:浮动静态的 "自动切换" 仅依赖设备路由优先级的原生规则,只能在两条固定路径间主备切换,无法感知复杂拓扑变化;动态路由可以适配全网任意拓扑变更,自动重算全量路由。
- 优先级搭配逻辑:实际组网中常将浮动静态作为动态路由的备份,例如华为设备中 OSPF 内部路由优先级为 10,将浮动静态优先级设为 100,正常情况下 OSPF 路由优先级更高而被选用,当 OSPF 邻居中断、路由消失时,浮动静态自动上浮兜底。
现网典型组合部署方案四者并非互斥关系,实际企业网络中通常分层搭配使用:
- 核心/汇聚层:运行 OSPF 作为主干动态路由,实现全网路由自动学习、负载分担与故障自愈
- 分支出口:主链路走 OSPF 专线,备份链路配置浮动静态路由走 4G / 互联网,以最低成本实现双链路自动备份
- 服务器网关、末梢监控网段:配置普通静态路由,再通过路由重分发注入 OSPF 全域同步
- RIP:新建网络基本不再部署,仅在老旧设备改造、兼容遗留网络时作为过渡协议使用
NULL0 黑洞路由
什么是 NULL0 接口?
NULL0 接口是一个虚拟接口,任何发往该接口的数据包都会被丢弃(吸收)。
它类似于一个 "数据黑洞",因此称为黑洞路由。
为什么需要黑洞路由?
路由汇总可能导致的环路问题:
plaintext
场景:Core1 将 10.1.0.0/16 汇总后发布到 OSPF
│
▼
Core1 ────── 10.1.0.0/16 ──────► Core2
│ │
◄────────────────────────────┘
如果 Core2 收到一个目标为 10.1.50.0/24 的数据包
(该网段实际上不存在),Core2 会将其转发给 Core1
Core1 收到后又转发给 Core2,形成环路!黑洞路由的作用:
plaintext
配置黑洞路由后:
│
▼
Core1 ───────── 10.1.0.0/16 ────────► Core2
│ │
└── NULL0 (drop unknown subnet) ◄─┘
如果 Core2 转发一个不存在的子网数据包给 Core1
Core1 会根据黑洞路由将其丢弃,而不是继续转发DR/BDR 选举机制
OSPF 网络类型与 DR/BDR
OSPF 在广播型网络(如以太网)中会选举 DR 和 BDR:
- DR(Designated Router):指定路由器,负责发送链路状态更新
- BDR(Backup Designated Router):备份指定路由器,DR 失效时接替
- DROther:非指定路由器,只与 DR/BDR 交换路由信息
选举规则:
- 优先级最高的路由器成为 DR
- 优先级次高的路由器成为 BDR
- 优先级相同则比较 Router-ID,Router-ID 大的获胜
- 优先级为 0 的路由器不参与选举
DR/BDR 选举流程
- 所有路由器启动时,认为自己是 DR 和 BDR
- 交换 Hello 报文,比较优先级
- Core1(优先级150)胜出,成为 DR
- Core2(优先级100)成为 BDR
- Access1/2/3(优先级1)成为 DROther
- DROther 只与 DR/BDR 建立邻接关系
优先级值说明
| 优先级值 | 含义 |
|---|---|
| 0 | 不参与 DR/BDR 选举,始终为 DROther |
| 1 | 默认值 |
| 1-254 | 参与选举,值越大优先级越高 |
| 255 | 最高优先级 |
对比默认配置
| 场景 | DR/BDR 选举结果 | 问题 |
|---|---|---|
| 默认配置(所有优先级=1) | 可能由任意路由器担任 DR/BDR | 接入交换机可能成为 DR,影响网络稳定性 |
| 优化配置 | Core1=DR, Core2=BDR | 确保核心设备承担关键角色 |