0. 摘要
本文深入剖析深度估计领域的核心挑战与前沿解决方案。以蚂蚁灵波科技开源的LingBot-Depth为例,详细阐述掩码深度建模(Masked Depth Modeling, MDM)这一创新范式如何将深度传感器的固有缺陷转化为学习信号,实现对透明、反光等困难场景的鲁棒深度感知。文章涵盖理论基础、技术架构、数据工程及代码实践,旨在为读者提供从原理到实现的完整技术图景。
1. 引言
精确感知三维世界是任何在物理环境中运行的智能体的基础能力。无论是生物有机体、自动驾驶汽车还是通用机器人,3D感知都为定位("我在哪里?")和场景理解("周围有什么?")提供了必要的上下文信息。缺乏鲁棒的3D感知能力,现实世界中的动作规划、执行和验证都将无从谈起。
当前实现3D感知的技术路线主要分为三类:
| 技术范式 | 代表方法 | 优势 | 局限性 |
|---|---|---|---|
| 多视图几何 | 立体匹配、SfM、SLAM | 理论成熟,无需额外硬件 | 计算开销大,依赖纹理 |
| 单目深度估计 | 深度学习方法 | 仅需单张图像 | 缺乏绝对尺度 |
| 主动传感器 | LiDAR、ToF、结构光 | 直接测量,精度高 | 成本高,受材质影响 |
有效的3D感知需要同时满足三个关键条件:绝对度量尺度 、像素级稠密几何 以及实时获取能力。RGB-D相机是目前唯一能够在实时条件下同时满足这三项要求的传感模态。然而,其实用性常常受到固有硬件限制的制约,尤其是立体匹配算法对外观歧义的敏感性。
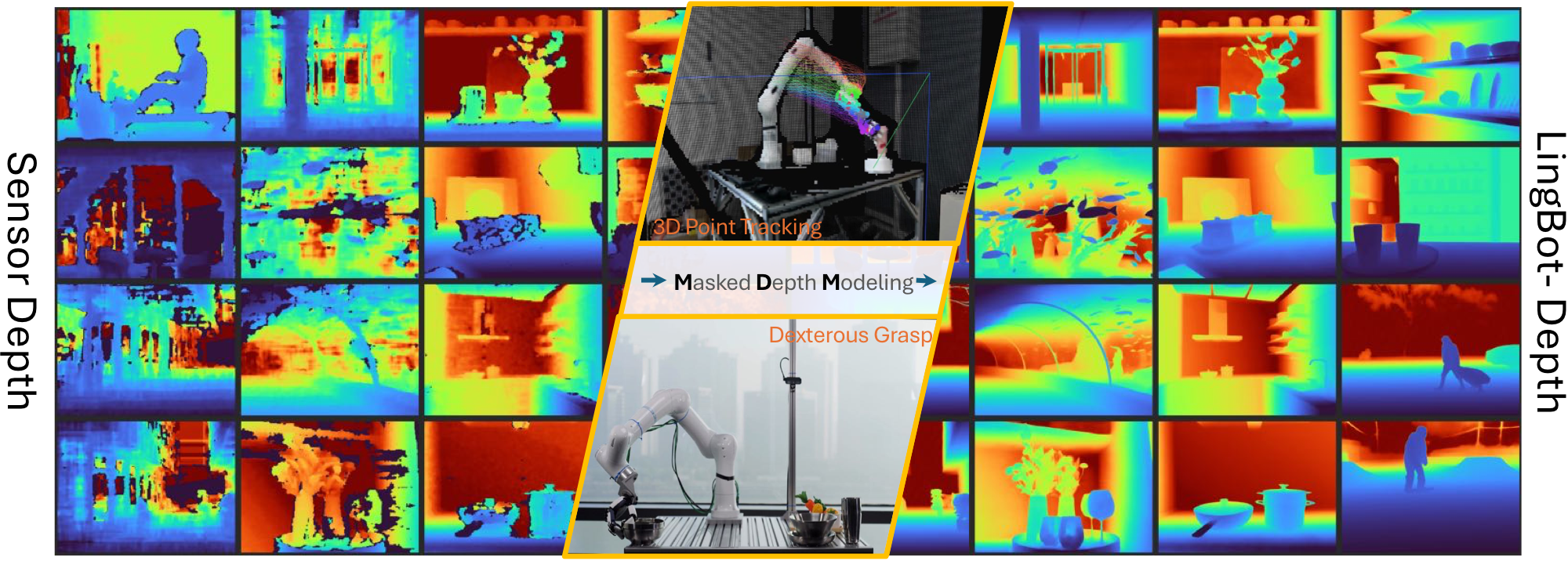
图1:LingBot-Depth将不完整的传感器深度数据转化为高质量、度量准确的3D测量结果
如上图所示,即便是商用级深度相机,在面对低纹理表面、镜面反射和复杂光照条件等挑战性场景时也会出现严重的数据损坏和缺失。这些失效直接违背了稠密、像素对齐几何的基本要求,成为制约机器人在家庭、商场、医院等真实场景中部署的关键瓶颈。
2. 问题剖析:透明与反光的本质差异
在非专业讨论中,透明物体和反光物体常被笼统地归类为"视觉难点"。但从算法层面审视,二者实际上是两类截然不同、甚至相反的问题。
2.1 透明物体:信息缺失问题
透明材质(如玻璃、塑料容器)的核心挑战在于信息缺失 。光线几乎可以无阻碍地穿透这类材质,导致深度传感器无法接收到有效的回波信号。从成像角度看,相机捕获的更多是背景的延续,而非物体本身的几何特征。
对于深度估计模型而言,这意味着:
- 无法确定透明物体的边界位置
- 难以推断物体的真实厚度和形态
- 背景深度信息会"穿透"到前景区域
2.2 反光物体:信息过载问题
与透明物体相反,高反射率表面(如不锈钢、镜面)的问题在于信息过载。这类表面会将环境、光源甚至相机本身映射到画面中,导致同一物体在不同视角、不同时刻呈现完全不同的外观特征。
这种现象给深度估计带来的困难包括:
- 难以区分物体本身的像素与环境倒影
- 立体匹配算法因外观不一致而失效
- 结构光图案被反射到错误位置
2.3 统一处理的困境
正是由于透明和反光问题的物理成因截然不同,采用单一假设去处理这两类问题往往两头都做不好。传统方法要么将这些区域的深度值简单丢弃,要么尝试用启发式规则进行填充,但都无法从根本上解决问题。
LingBot-Depth的核心洞察在于:传感器的失效模式本身就是一种有价值的信息。那些深度缺失的区域恰恰标记出了场景中最具挑战性的部分,这为设计针对性的学习策略提供了天然的监督信号。
3. 核心创新:掩码深度建模范式
3.1 从MAE到MDM的思想演进
掩码自编码器(Masked Autoencoders, MAE)是近年来自监督学习领域的重要突破。其核心思想是随机遮挡输入图像的部分区域,然后训练模型重建被遮挡的内容。通过这种方式,模型被迫学习图像的深层语义结构,而非简单记忆像素模式。
LingBot-Depth提出的掩码深度建模(Masked Depth Modeling, MDM)继承了MAE的核心理念,但做出了关键性的改进:
传统MAE :随机掩码 → 重建RGB像素
MDM:自然掩码(传感器缺失)+ 随机掩码 → 重建深度值
这一改进的精妙之处在于:深度传感器产生的缺失区域并非随机分布,而是集中在几何和外观歧义最严重的位置(如镜面反射、透明表面)。这些"自然掩码"比随机掩码提出了更具挑战性的重建任务,迫使模型学习更深层次的几何-外观关联。
3.2 MDM的核心设计理念
MDM框架的设计遵循以下原则:
- 缺陷即信号:将传感器失效区域视为学习目标,而非需要丢弃的噪声
- 跨模态推理:利用完整的RGB图像作为条件,推断缺失的深度信息
- 任务统一:通过调整掩码策略,在同一框架下实现单目深度估计和深度补全
当所有深度token都被掩码时,模型退化为纯单目深度估计器,完全依赖RGB上下文推断几何;当仅掩码无效区域时,模型执行深度补全任务,融合稀疏的有效深度读数与视觉线索。
4,技术架构详解
4.1 整体架构概览
MDM采用编码器-解码器架构,整体数据流如下:
输入RGB图像 ──┐
├──→ ViT编码器 ──→ 联合特征表示 ──→ ConvStack解码器 ──→ 稠密深度图
输入深度图 ──┘ (掩码处理)编码器基于Vision Transformer (ViT-Large),负责学习RGB与深度的联合表示;解码器采用卷积金字塔结构(ConvStack),专门针对稠密几何预测任务优化。
4.2 分离式Patch嵌入
对于RGB-D输入,MDM采用分离的Patch嵌入层分别处理两种模态:
python
# RGB图像: 3通道 → N个patch tokens
# 深度图: 1通道 → N个patch tokens
# patch_size = 14 (遵循DINOv2设定)
# 假设输入分辨率为 (H, W),则token数量为:
N = (H * W) / (14 * 14)
# RGB token: c_i ∈ R^n
# Depth token: d_i ∈ R^n
# 其中 n 为token嵌入维度这种分离设计使得自注意力层能够学习整合RGB图像的外观上下文与深度测量的几何线索。模型可以利用丰富的视觉上下文和基本的几何先验(如远近关系、共面性、空间连续性)进行互补推理。
4.3 位置编码设计
RGB-D token序列需要编码两类位置信息:
- 空间位置编码:标识每个token在2D图像平面上的位置
- 模态编码:区分同一空间位置的RGB token和深度token
python
# 位置编码计算
position_embedding = spatial_embedding + modality_embedding
# 模态编码设定
modality_embedding_rgb = 1 # RGB tokens
modality_embedding_depth = 2 # Depth tokens
# 最终token表示
token_final = token_raw + position_embedding这种双重编码机制确保模型能够准确理解每个token的空间位置及其所属模态,为跨模态注意力计算奠定基础。
4.4 智能掩码策略
MDM的掩码策略是其核心创新之一,与传统MAE的随机掩码有本质区别:
python
import torch
def depth_masking(
x,
patch_num_h,
patch_num_w,
depth_values,
depth_mask_threshold_ratio=None,
depth_mask_threshold_num=None,
valid_depth_range=(0.1, 10.0),
):
"""
Perform patch masking based on depth validity
Args:
x: [B, N, D] input features (after patch embedding)
patch_num_h: int, height of the patch grid
patch_num_w: int, width of the patch grid
depth_values: [B, 1, H_img, W_img], raw depth map
depth_mask_threshold_ratio: float or list, valid depth ratio threshold (0-1)
depth_mask_threshold_num: int or list, valid depth pixel count threshold
valid_depth_range: tuple, valid depth range (min, max)
Returns:
visible_list: list of [N_visible_i, D], visible patches for each sample
mask_info: dict, containing masking information
"""
B, N, D = x.shape
device = x.device
assert N == patch_num_h * patch_num_w, \
f"N={N} must equal patch_num_h * patch_num_w = {patch_num_h * patch_num_w}"
# Compute depth invalid mask
depth_invalid_mask = _compute_depth_invalid_mask(
depth_values,
patch_num_h,
patch_num_w,
depth_mask_threshold_ratio,
depth_mask_threshold_num,
valid_depth_range
) # [B, N], True indicates this patch is invalid
# Process each sample separately
visible_list = []
mask_info = {
'visible_indices': [],
'mask_indices': [],
'num_visible': [],
}
for i in range(B):
# Get valid patch indices
valid_mask = ~depth_invalid_mask[i] # [N]
visible_indices = torch.where(valid_mask)[0]
masked_indices = torch.where(depth_invalid_mask[i])[0]
# Extract visible patches
visible = x[i, visible_indices] # [N_visible, D]
visible_list.append(visible)
# Record information
mask_info['visible_indices'].append(visible_indices)
mask_info['mask_indices'].append(masked_indices)
mask_info['num_visible'].append(len(visible_indices))
return visible_list, mask_info
def _compute_depth_invalid_mask(
depth_values,
H_patch,
W_patch,
threshold_ratio,
threshold_num,
valid_range
):
"""
Compute depth validity for each patch
Args:
depth_values: [B, 1, H_img, W_img] raw depth map
H_patch, W_patch: patch grid dimensions
threshold_ratio: float or list, valid depth ratio threshold
threshold_num: int or list, valid depth pixel count threshold
valid_range: tuple, (min_depth, max_depth)
Returns:
invalid_mask: [B, N] bool tensor, True indicates this patch is invalid
"""
B, _, H_img, W_img = depth_values.shape
N = H_patch * W_patch
device = depth_values.device
min_depth, max_depth = valid_range
# Calculate pixel size for each patch
patch_h = H_img // H_patch
patch_w = W_img // W_patch
# Reshape depth map into patches: [B, 1, H_img, W_img] -> [B, H_patch, patch_h, W_patch, patch_w]
depth_reshaped = depth_values.view(B, 1, H_patch, patch_h, W_patch, patch_w)
# Transpose and flatten: [B, H_patch, W_patch, patch_h, patch_w] -> [B, N, patch_h*patch_w]
depth_reshaped = depth_reshaped.permute(0, 2, 4, 1, 3, 5).reshape(B, N, -1)
# Calculate valid depth
valid_depth = (depth_reshaped >= min_depth) & (depth_reshaped <= max_depth)
valid_depth_ratio = valid_depth.float().mean(dim=-1) # [B, N]
valid_depth_num = valid_depth.float().sum(dim=-1) # [B, N]
# Handle list-form thresholds (different thresholds for each sample in batch)
if isinstance(threshold_ratio, list) or isinstance(threshold_num, list):
invalid_mask = torch.zeros(B, N, dtype=torch.bool, device=device)
for i in range(B):
tr = threshold_ratio[i] if isinstance(threshold_ratio, list) else threshold_ratio
tn = threshold_num[i] if isinstance(threshold_num, list) else threshold_num
sample_mask = torch.zeros(N, dtype=torch.bool, device=device)
if tr is not None:
sample_mask |= (valid_depth_ratio[i] < tr)
if tn is not None:
sample_mask |= (valid_depth_num[i] < tn)
invalid_mask[i] = sample_mask
else:
# Uniform threshold
invalid_mask = torch.zeros(B, N, dtype=torch.bool, device=device)
if threshold_ratio is not None:
invalid_mask |= (valid_depth_ratio < threshold_ratio)
if threshold_num is not None:
invalid_mask |= (valid_depth_num < threshold_num)
return invalid_mask这种策略的优势在于:
- 基于深度有效性阈值(
threshold_ratio)判断每个patch是否需要掩码 - 支持批量处理,每个样本可以有不同的掩码阈值
- 通过
valid_depth_range参数灵活定义有效深度范围
4.5 ViT编码器:联合表示学习
编码器采用ViT-Large架构,包含24个自注意力块:
python
class DINOv2_RGBD_Encoder(nn.Module):
backbone: DinoVisionTransformer
image_mean: torch.Tensor
image_std: torch.Tensor
dim_features: int
def __init__(self, backbone: str, intermediate_layers: Union[int, List[int]], dim_out: int,
ignore_layers: Union[str, List[str]]=[], in_chans: int=3, strict: bool=True,
img_depth_fuse_mode='', depth_emb_mode='', depth_mask_ratio=0.6,
img_mask_ratio=0.0, **deprecated_kwargs):
super(DINOv2_RGBD_Encoder, self).__init__()
self.intermediate_layers = intermediate_layers
self.strict = strict
self.ignore_layers = ignore_layers
self.img_mask_ratio = img_mask_ratio
# 动态加载DINOv2骨干网络
self.hub_loader = getattr(importlib.import_module(".dinov2_rgbd.hub.backbones", __package__), backbone)
self.backbone_name = backbone
self.backbone = self.hub_loader(pretrained=False,
in_chans=in_chans,
img_depth_fuse_mode=img_depth_fuse_mode,
depth_emb_mode=depth_emb_mode,
depth_mask_ratio=depth_mask_ratio,
img_mask_ratio=img_mask_ratio)
# 获取特征维度(ViT-Large为1024)
self.dim_features = self.backbone.blocks[0].attn.qkv.in_features
self.num_features = intermediate_layers if isinstance(intermediate_layers, int) else len(intermediate_layers)
# 特征投影层
self.output_projections = nn.ModuleList([
nn.Conv2d(in_channels=self.dim_features, out_channels=dim_out, kernel_size=1, stride=1, padding=0)
for _ in range(self.num_features)
])
# ImageNet标准化参数
self.register_buffer("image_mean", torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
self.register_buffer("image_std", torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))编码器的关键设计包括:
- DINOv2初始化:利用DINOv2的预训练权重初始化,继承其强大的视觉表示能力
- 动态模块加载 :通过
importlib实现配置驱动的骨干网络选择 - 深度掩码比例 :
depth_mask_ratio参数控制深度token的掩码比例
4.6 ConvStack解码器:稠密几何重建
与传统MAE使用浅层Transformer解码器不同,MDM采用卷积金字塔解码器(ConvStack)进行深度重建:
python
class ConvStack(nn.Module):
def __init__(self,
dim_in: List[Optional[int]],
dim_res_blocks: List[int],
dim_out: List[Optional[int]],
resamplers: Union[Literal['pixel_shuffle', 'nearest', 'bilinear', 'conv_transpose',
'pixel_unshuffle', 'avg_pool', 'max_pool'], List],
dim_times_res_block_hidden: int = 1,
num_res_blocks: int = 1,
res_block_in_norm: Literal['layer_norm', 'group_norm', 'instance_norm', 'none'] = 'layer_norm',
res_block_hidden_norm: Literal['layer_norm', 'group_norm', 'instance_norm', 'none'] = 'group_norm',
activation: Literal['relu', 'leaky_relu', 'silu', 'elu'] = 'relu',
):
super().__init__()
self.input_blocks = nn.ModuleList([
nn.Conv2d(dim_in_, dim_res_block_, kernel_size=1, stride=1, padding=0)
if dim_in_ is not None else nn.Identity()
for dim_in_, dim_res_block_ in zip(
dim_in if isinstance(dim_in, Sequence) else itertools.repeat(dim_in),
dim_res_blocks)
])
self.resamplers = nn.ModuleList([
Resampler(dim_prev, dim_succ, scale_factor=2, type_=resampler)
for i, (dim_prev, dim_succ, resampler) in enumerate(zip(
dim_res_blocks[:-1],
dim_res_blocks[1:],
resamplers if isinstance(resamplers, Sequence) else itertools.repeat(resamplers)
))
])
self.res_blocks = nn.ModuleList([
nn.Sequential(*(
ResidualConvBlock(
dim_res_block_, dim_res_block_, dim_times_res_block_hidden * dim_res_block_,
activation=activation, in_norm=res_block_in_norm, hidden_norm=res_block_hidden_norm
) for _ in range(num_res_blocks[i] if isinstance(num_res_blocks, list) else num_res_blocks)
)) for i, dim_res_block_ in enumerate(dim_res_blocks)
])
self.output_blocks = nn.ModuleList([
nn.Conv2d(dim_res_block_, dim_out_, kernel_size=1, stride=1, padding=0)
if dim_out_ is not None else nn.Identity()
for dim_out_, dim_res_block_ in zip(
dim_out if isinstance(dim_out, Sequence) else itertools.repeat(dim_out),
dim_res_blocks)
])
def forward(self, in_features: List[torch.Tensor]):
out_features = []
for i in range(len(self.res_blocks)):
feature = self.input_blocks[i](in_features[i])
if i == 0:
x = feature
elif feature is not None:
x = x + feature
x = self.res_blocks[i](x)
out_features.append(self.output_blocks[i](x))
if i < len(self.res_blocks) - 1:
x = self.resamplers[i](x)
return out_features解码器从低分辨率特征图开始,通过堆叠的残差块和转置卷积逐步上采样,最终恢复到原始输入分辨率。在每个尺度上,UV位置编码被注入以保持空间布局和宽高比信息。
4.7 跨模态注意力可视化
为验证联合嵌入是否有效捕获了跨模态关联,研究团队对编码器最后一层的深度-RGB注意力图进行了可视化分析。
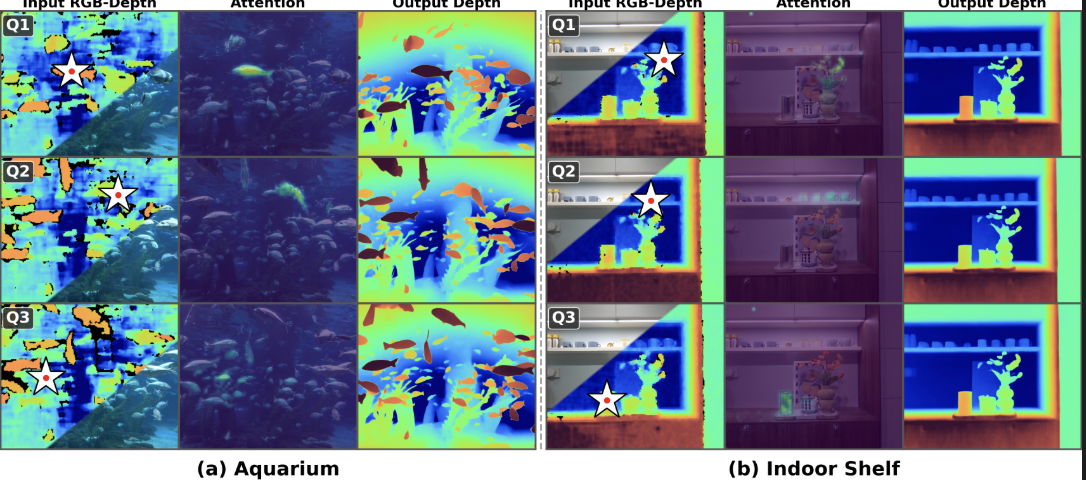
图2:多查询深度-RGB注意力可视化。对于两个场景(水族馆和室内货架),选取三个深度查询patch(Q1-Q3),可视化其对RGB tokens的注意力分布。不同查询关注空间上对应的不同区域,证实联合嵌入捕获了细粒度的跨模态几何-外观关联。
从可视化结果可以观察到:
- 不同位置的深度token关注RGB图像中空间对应的局部区域
- 注意力模式具有明确的空间选择性,而非退化为全局或平凡模式
- 即使在物体密集堆叠或材质异质的复杂场景中,模型仍能建立准确的对应关系
这一结果表明,通过掩码深度建模目标,编码器学习到了位置感知的几何-外观对应关系。
5. 数据工程:大规模RGB-D数据采集
5.1 数据稀缺性挑战
RGB-D数据的获取远比纯RGB数据困难,主要原因包括:
- 依赖专用深度传感器
- 现有数据集多回避挑战性场景以减少深度缺失
- 高质量3D资产渲染的深度图过于"完美",缺乏真实传感器的失效模式
为支持大规模MDM训练,研究团队构建了一套可扩展的数据采集与合成流水线,最终形成约1000万样本的训练集。

图3:训练数据集构成。上排展示200万真实采集和100万仿真样本覆盖的多样化室内环境;下排展示RGB-D输入与对应的真值深度图。
5.2 合成数据管线
与现有方法仅渲染理想深度图不同,MDM的合成管线显式模拟真实主动式RGB-D相机的成像过程,生成带有自然缺陷的深度观测。
渲染流程:
- 使用自建高质量3D场景资产
- 在Blender中同时渲染:RGB图像、完美深度图、带散斑图案的灰度立体图像对
- RGB图像从立体对的左相机视角渲染,确保与深度测量像素对齐
- 使用半全局匹配(SGM)算法处理立体图像,生成模拟传感器深度
相机参数采样:
python
# 立体基线:均匀采样
baseline = np.random.uniform(0.05, 0.2) # 5-20厘米
# 焦距:均匀采样
focal_length = np.random.uniform(16, 28) # 16-28毫米单个样本包含:
| 数据项 | 分辨率 | 说明 |
|---|---|---|
| RGB图像 | 960×1280 | 左相机视角 |
| 完美深度图 | 960×1280 | 渲染真值 |
| 立体图像对 | 720×960 | 带散斑图案 |
| 真值视差图 | 960×1280 | 渲染真值 |
| 传感器深度 | 960×1280 | SGM计算结果 |
通过这种方式,合成管线从442个室内场景生成了100万样本,数据规模比此前工作(如HSSD-IsaacSIM-STD的1万样本、DREDS的13万样本)高出一个数量级。
5.3 可扩展RGB-D采集系统
为收集大规模真实世界RGB-D数据,研究团队设计了一套模块化采集原型系统。

图4:可扩展RGB-D采集系统。多传感器配置包括Intel RealSense、Orbbec Gemini和Azure Kinect,支持大规模真实世界数据采集。
6. 核心代码深度解析
本章节对LingBot-Depth的核心代码进行逐行解析,帮助读者深入理解每个模块的设计意图和实现细节。
6.1 模型主类MDMModel解析
MDMModel是整个深度估计系统的核心入口类,负责协调编码器和解码器的工作流程。以下是其关键组件的详细分析:
python
class MDMModel(nn.Module):
"""
掩码深度建模主模型类
该类整合了RGB-D编码器和ConvStack解码器,
实现从输入RGB-D数据到精炼深度图的端到端推理。
"""
# 类型注解:声明模型的核心组件
encoder: Union[DINOv2_RGBD_Encoder] # RGB-D联合编码器
neck: ConvStack # 共享特征颈部网络
points_head: ConvStack # 点云预测头(可选)
mask_head: ConvStack # 掩码预测头(可选)
scale_head: MLP # 尺度预测头(可选)设计解析 :模型采用模块化设计,将编码器、颈部网络和多个任务头分离。这种设计允许在同一骨干网络上灵活添加不同的下游任务头,实现多任务学习。Union类型注解表明编码器可以支持多种实现,提高了代码的扩展性。
6.2 模型初始化流程解析
python
def __init__(self,
encoder: Dict[str, Any], # 编码器配置字典
neck: Dict[str, Any], # 颈部网络配置
depth_head: Dict[str, Any] = None, # 深度预测头配置
mask_head: Dict[str, Any] = None, # 掩码预测头配置
remap_output: Literal['linear', 'sinh', 'exp', 'sinh_exp'] = 'linear',
remap_depth_in: Literal['linear', 'log'] = 'log',
remap_depth_out: Literal['linear', 'exp'] = 'exp',
num_tokens_range: List[int] = [1200, 3600],
):
super(MDMModel, self).__init__()
# 深度值映射策略配置
self.remap_output = remap_output
self.remap_depth_in = remap_depth_in # 输入深度映射:log变换
self.remap_depth_out = remap_depth_out # 输出深度映射:exp还原
self.num_tokens_range = num_tokens_range # token数量范围
# 实例化核心组件
self.encoder = DINOv2_RGBD_Encoder(**encoder)
self.neck = ConvStack(**neck)
# 条件性创建任务头
if depth_head is not None:
self.depth_head = ConvStack(**depth_head)
if mask_head is not None:
self.mask_head = ConvStack(**mask_head)深度映射策略解析 :remap_depth_in='log'表示输入深度值会经过对数变换。这一设计基于深度值的分布特性------室内场景的深度值通常在0.5米到10米之间,直接使用原始值会导致近处和远处的梯度差异过大。对数变换将深度值压缩到更均匀的范围,有利于网络学习。remap_depth_out='exp'则在输出时通过指数函数还原到真实深度尺度。