2026年开始,央国企也逐步开始尝试AI规模化落地,早期更多是在验证模型效果,看看知识问答准不准,材料生成能不能减轻一点办公负担,随着Harness工程的晚上,很多单位开始把Agent放到生产管理、安全审查、采购供应链、经营分析和研发设计这些更接近主业的位置,项目的复杂度也随之提高。

这种变化其实很现实。一个办公助手做得好,通常只影响一类人员的工作体验;一个生产管理类Agent要进入系统,就会牵涉权限、流程、接口、审计和运行环境。前者可以快速试,后者要经得起集团范围内的复用和安全审查。央国企真正要处理的,是AI能力如何在集团范围内被统一建设、分级使用、持续运营,并能通过信创、安全和审计要求。
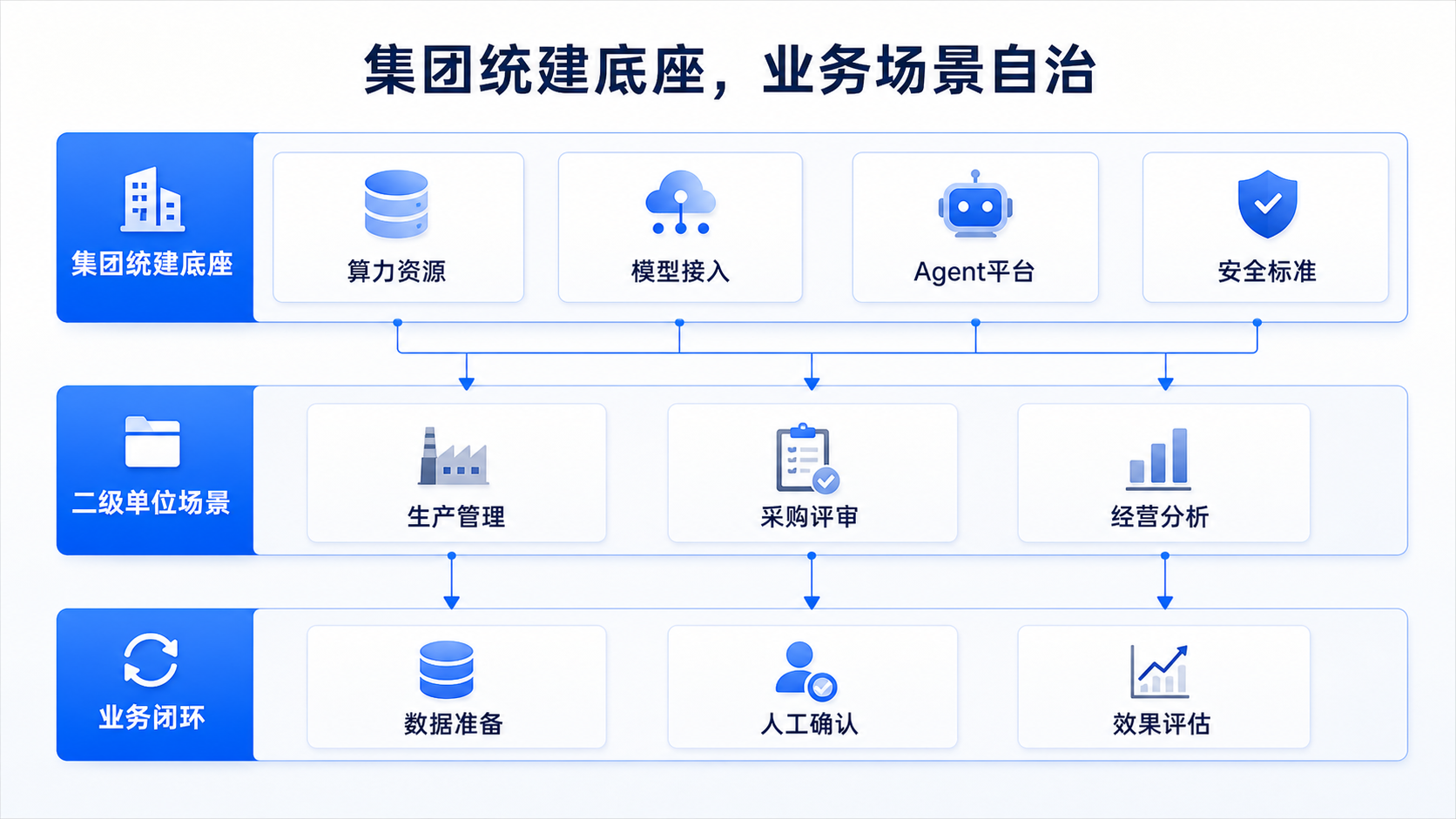
集团做底座,业务单位做场景
央国企的业务线长,组织层级多,系统边界也复杂。AI能力如果都由各单位单独建设,短期内看起来推进快,后面会出现一批相似问题:模型接入方式不同,知识库重复维护,接口标准不一致,权限和审计口径也很难统一。到了集团推广阶段,这些差异都会变成迁移成本。
更稳妥的分工,是集团层面建设公共底座,业务单位负责场景设计和效果验证。集团统一算力、模型接入、智能体平台、安全策略和技术标准,二级、三级单位负责把AI放进真实业务任务里,业务团队再根据使用效果不断调整流程和知识内容。
| 建设层级 | 适合承担的工作 | 作用 |
|---|---|---|
| 集团总部 | 算力、模型、平台、安全、标准 | 降低重复建设,统一治理口径 |
| 二级单位 | 场景规划、数据准备、流程改造 | 让AI贴近业务现场 |
| 业务团队 | 任务验证、反馈收集、效果评估 | 判断AI是否真的可用 |
| 安全与审计团队 | 权限边界、操作留痕、风险复核 | 控制生产环境风险 |
上面的分工重点不在名义,而在能力复用。一个场景已经验证过,如果底层接口、权限模型和审计规则一致,迁移到相邻单位时成本会低很多;如果每个单位都从头接系统、配权限、做安全评审,规模化会被工程细节拖慢。很多集团项目推进到生产阶段才卡住,常见原因是这些工程化问题没有提前收口。
信创适配要放在选型前面
央国企、政务和金融机构在AI平台选型时,通常会先看一个基础问题:系统能不能运行在信创环境里。操作系统、数据库、中间件、浏览器和终端环境都会影响上线评审,尤其是进入集团级项目后,兼容性验证和安全测评会直接影响项目周期。
试点阶段可以先看模型效果和业务可用性,进入生产阶段后,系统运行环境是否符合信创要求,数据能否本地化管理,操作过程是否具备审计能力,都会进入验收范围。很多AI应用前期演示效果不错,后面卡在环境适配和安全评审上,原因就在这里。
以凡泰AI的数字员工中台为例,其FinClaw企业级智能体中台已完成与统信软件产品的互认认证。这类认证对央国企客户的意义,不只是产品能安装运行,也包括国产化环境下的兼容风险更低,后续运维责任更清楚,平台更容易纳入既有信创基础设施管理。
央国企规模化引入AI时,信创适配不宜放到项目后段补。平台选型阶段就要关注国产化操作系统适配、私有化部署、本地数据管理、统一身份接入、日志留痕和安全策略配置。否则应用层已经做出效果,底层环境过不了评审,项目仍然会停在试点里。对很多单位来说,这关系到项目能不能进入正式采购和生产验收。
场景选择要少一些贪多
知识问答、办公生成和数据查询适合作为AI入口。这些场景覆盖人群广,风险边界相对清楚,也能让员工先形成使用习惯。集团建设统一AI入口时,从这类场景切入比较顺。
但通用入口不能代表业务价值已经释放。央国企后续要看的,是AI能不能进入生产调度、安全合规、采购评审、科研设计和经营分析这些流程里。这类场景对专业知识、系统连接和人工确认要求更高,跑通以后才更接近真实经营价值。
场景筛选时,单看"能不能做"意义不大,更应该看任务能不能形成闭环。比如招采审核Agent,如果只生成风险提示,价值有限;如果能够读取制度和历史评审记录,结合供应商信息给出审查建议,并把人工复核结果沉淀回知识库,后续复用价值会高得多。
| 筛选维度 | 判断方式 |
|---|---|
| 任务频率 | 是否经常发生,是否长期占用人力 |
| 数据基础 | 是否有可用文档、系统数据和历史案例 |
| 流程闭环 | AI结果是否能进入后续业务动作 |
| 风险边界 | 哪些动作要人工确认,哪些内容不能访问 |
| 评价指标 | 是否能用周期、准确率、返工率或成本衡量 |
央国企不缺试点方向,真正稀缺的是能够长期运行、持续复用的场景。前期选一个边界清楚的小流程跑透,比铺开很多只有演示效果的应用更有价值。一个流程跑透以后,身份、数据、权限、审计这些底层能力都能复用,后续扩展才会更顺。
数据和知识工程要早做
央国企往往有大量制度文件、图纸资料、历史报告、合同文本和专家经验。表面上看,这些都是AI可用的资产;实际接入时会发现,资料分散、版本混乱、权限不清、语义标签不足,是很多Agent无法进入生产的原因。
知识库能存储文档,不代表Agent能可靠使用。企业要把原始资料处理成可检索、可引用、可追溯的知识单元,还要让知识和组织权限绑定。安全生产、科研设计、财务采购等专业场景里,知识的准确性会直接影响业务判断,简单切片后丢进向量库,后续误召回和过期知识都会变成风险。
这部分工作通常不显眼,但很耗时间。数据来源要盘清楚,文档版本要整理,专家经验要转成标准化案例,Agent使用反馈也要进入知识库更新流程。没有这一步,AI很容易停在"能回答问题",很难进入"能参与业务"。不少项目在演示阶段表现不错,到了真实业务里回答不稳定,原因往往在知识源、权限和业务语境没有处理干净。
运行治理要和任务链路放在一起
Agent进入业务流程后,会开始代表某个用户读取数据、调用工具、生成材料或触发后续动作。管理要求和普通聊天助手不同。企业要知道它以谁的身份执行,能访问哪些系统,调用了什么工具,哪些结果经过人工确认,失败后由谁接管。
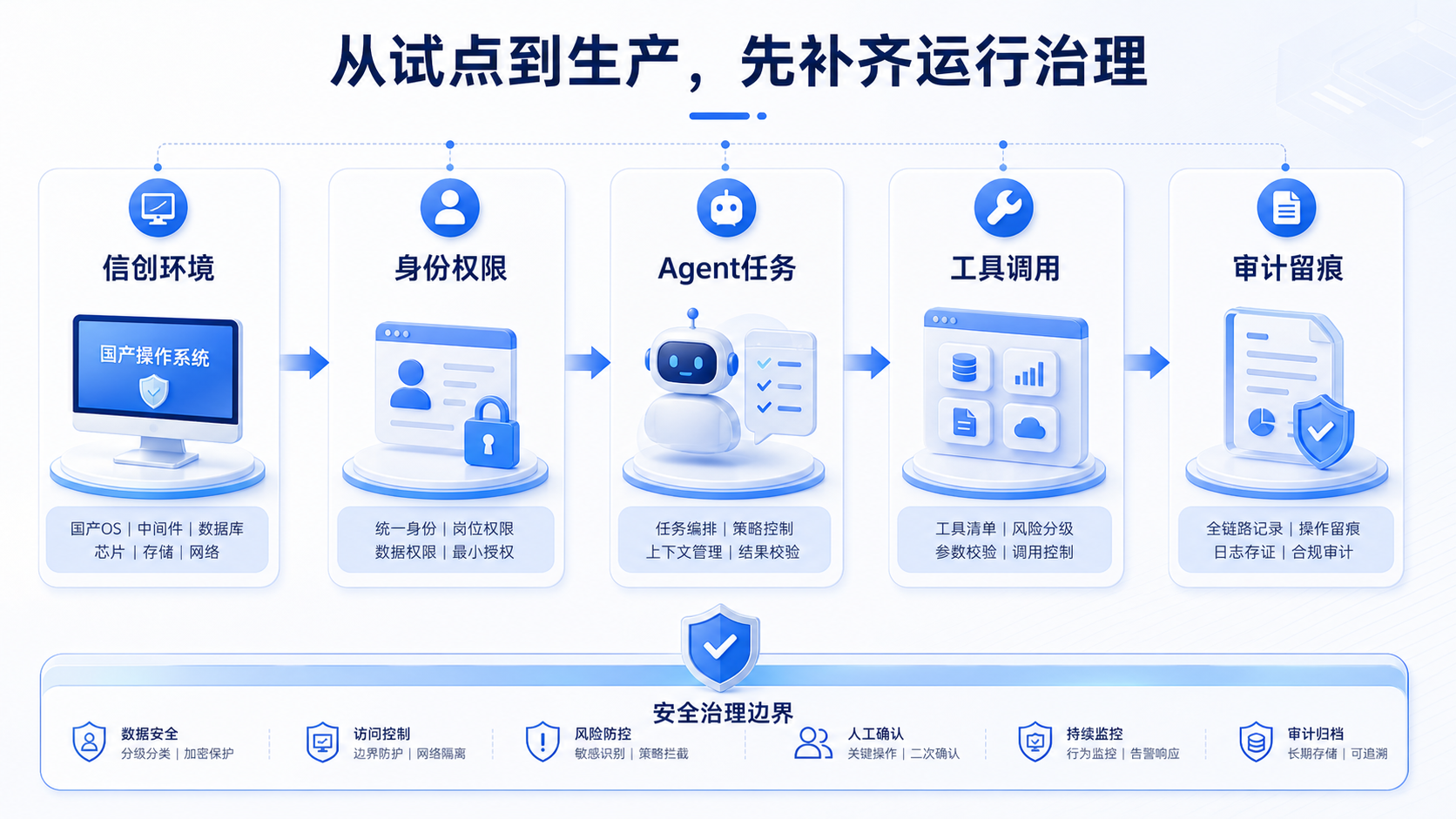
很多项目从试点走向生产时,会卡在这条链路上。模型效果过关,只是其中一环。没有统一身份和权限,Agent进不了核心系统;没有任务状态管理,长程任务中断后很难恢复;没有日志和审计,安全部门无法判断一次操作是否合规;没有运营机制,知识和规则更新以后,旧Agent还可能继续按照旧逻辑工作。
生产级AI平台要把模型调用、工具执行、业务审批、人工确认和日志留痕串起来。业务部门关心效率,安全部门关心边界,审计部门关心证据链,平台设计时要把这些需求放到同一条任务链路里。高风险动作也不适合只靠提示词约束,最好进入可控执行环境,由策略决定能不能执行。这样做会让前期建设更重一些,但对央国企来说,后面推广时会少很多解释成本。
规模化靠运营,不靠一次上线
AI系统上线后不会自动稳定。制度会调整,业务流程会变化,模型能力会更新,用户提问也会暴露新的知识缺口。没有运营机制,很多应用上线几个月后就会变成"能用但不好用"的系统。
央国企做规模化AI,可以先选一段任务量稳定、边界清楚、评价指标明确的流程,把数据接入、权限控制、任务流转和效果评估跑通。跑通以后,再把底座能力复用到相邻场景。这样推进速度未必最快,但失败成本更低,也更容易形成集团范围内的复制经验。
后续评价AI项目,不宜只看上线了多少应用、覆盖了多少员工。更有价值的指标包括任务周期是否缩短、人工复核压力是否下降、结果一次通过率是否提升、风险识别是否更稳定、知识复用是否更充分。只要这些指标能持续改善,AI才算真正进入组织运行。
央国企引入AI能力,早期可以从通用场景建立入口,进入生产阶段后要补齐信创适配、统一底座、数据知识工程、运行治理和持续运营。这个过程更像一次组织能力建设。做得稳,AI才能从单点工具变成集团可复用的基础能力。