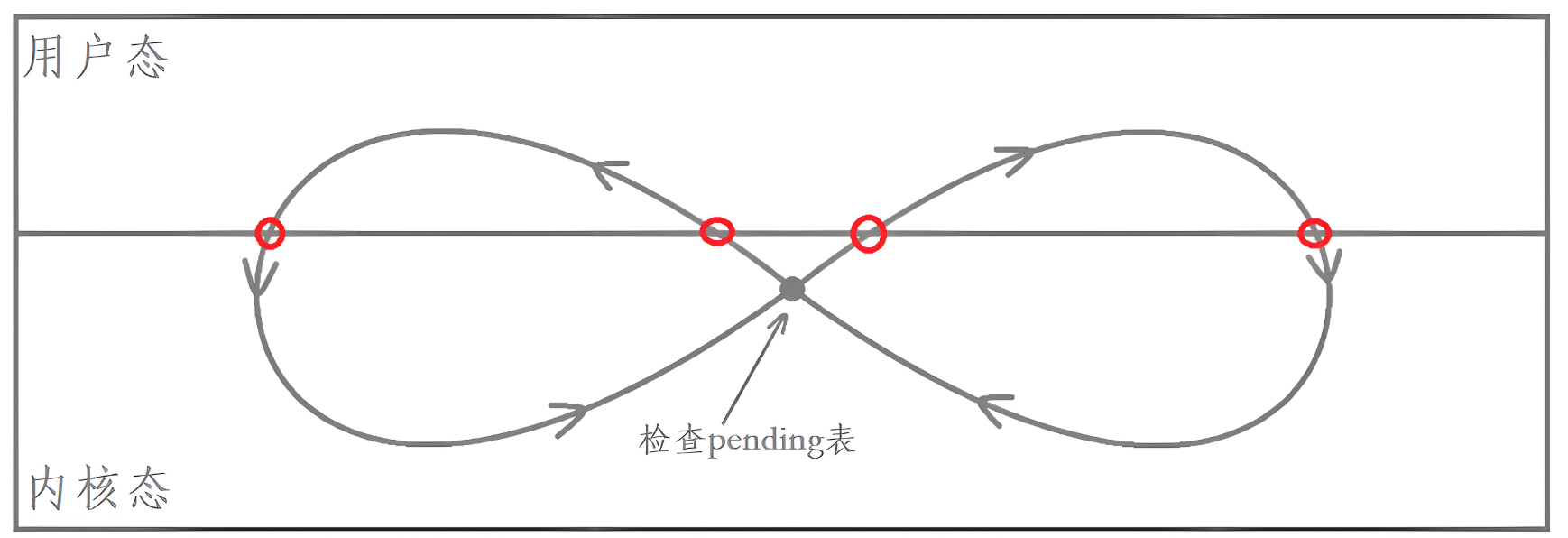
信号捕捉的流程
两张表:
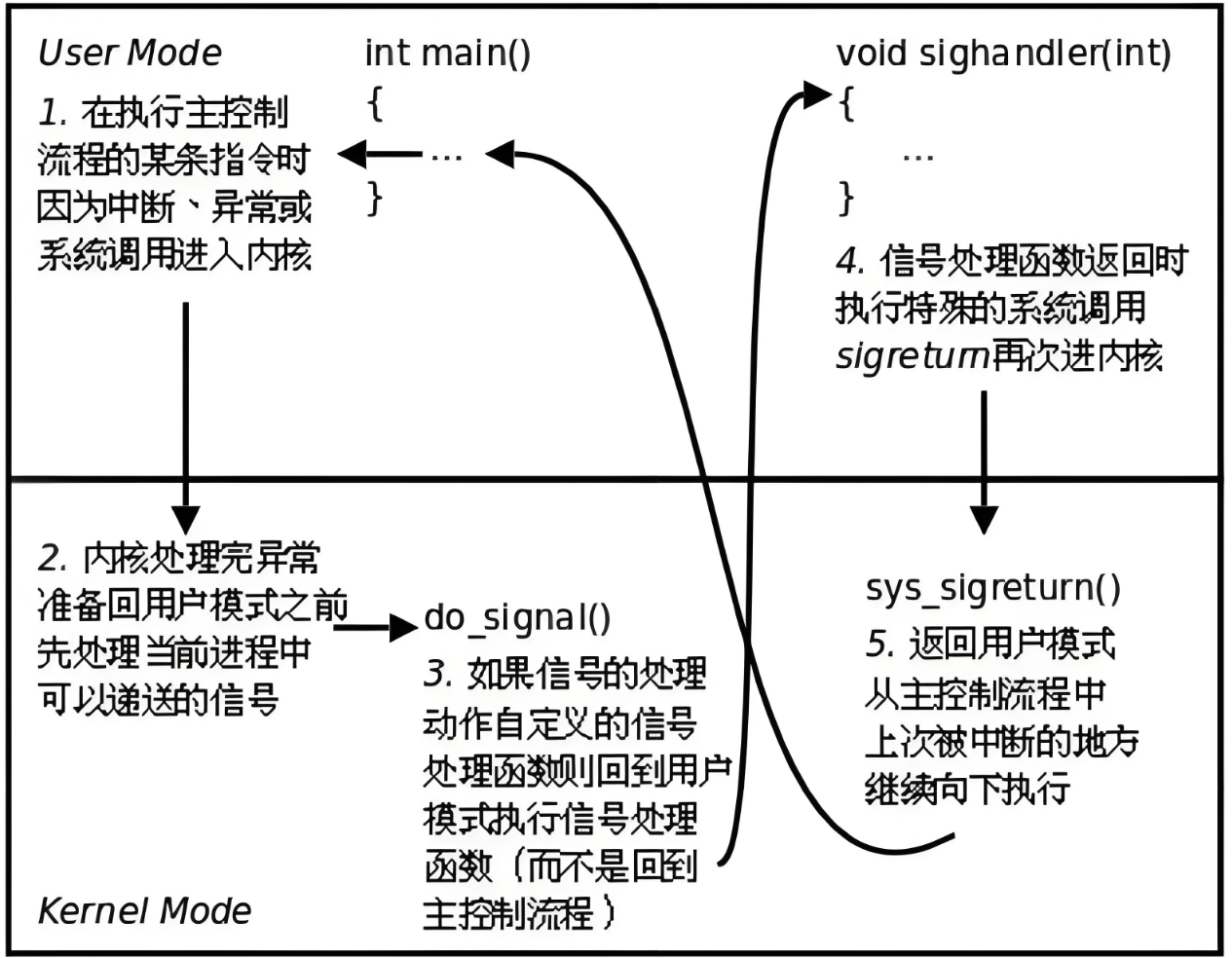
以Ctrl+C 自定义捕获 SIGINT 为例展示一下:
1. 进入内核(对应图第 1 步)
main 函数在用户态正常运行,按下 Ctrl+C 触发键盘硬件中断,CPU 从用户态切换到内核态,内核处理键盘中断,把 SIGINT 写入当前前台进程 PCB 的 pending 未决信号集。
2. 内核收尾前执行 do_signal(对应图第 2 步)
中断处理完毕,内核准备用iret切回用户态 main 函数之前,固定执行**do_signal()函数**:检查进程 pending 信号集、阻塞 mask,发现未屏蔽的 SIGINT。
3. 修改用户栈上下文,跳转执行 handler(对应图第 3 步)
信号是自定义捕获的,内核改写用户栈:压入原 main 断点地址、sigreturn 函数地址、handler 函数地址; 执行iret切回用户态,取栈顶得到handler地址,就去执行handler(如果是SIGINT默认动作直接释放进程资源、关闭文件、回收内存。不往后走了)
4. handler 结束触发 sigreturn 系统调用,二进内核(对应图第 4 步)
handler结束后再取栈顶得到sigreturn地址,从而再进内核,执行sigreturn
5. sigreturn 内核恢复现场,iret回到 main 断点(对应图第 5 步)
关键细节:
为什么不能 handler 直接跳回 main 断点?而要再进一次内核执行sigreturn?
handler 运行在用户态,拿不到内核数据,进程被 Ctrl+C 打断时,CPU保存现场,把用户态运行时所有寄存器数据等,压入内核栈(内核内存区域)保存。,用户态代码完全读不到。 handler 只是普通用户函数,它没有权限访问内核内存,没法自己复原所有运行环境。必须通过 sigreturn 系统调用再次进入内核,由内核统一复原现场。
sigreturn 到底是干什么的?
(1)恢复完整 CPU 上下文
(2)撤销信号临时屏蔽掩码(sa_mask)sigaction加入到sa_mask
(3)清除递送上下文标记,代表本次信号递达流程结束了
iret(x86)
CPU 执行 iret 时,自动从内核栈顶部依次取出 3 组数据,恢复寄存器:
- 弹出
EIP:下一条要执行的代码地址(程序断点) - 弹出
CS:代码段寄存器,顺带修改 CPL 特权级(cs由0->1) - 弹出
EFLAGS:标志寄存器(含中断开关、状态标记)
**作用:**从内核态安全切回用户态,一次性恢复全部 CPU 运行环境
和ret区别:
ret:普通函数返回,只弹 EIP,不切换特权级,用户 / 内核都能用iret:中断专用返回,弹 EIP+CS+EFLAGS,自动切换用户 / 内核态,仅内核可执行
中断类型(按 CPU 触发来源(硬件标准分类))
硬件中断(包含时钟中断)
(键盘、磁盘、网卡、时钟源)外设硬件发起,经中断控制器转发 CPU;
CPU内部异常 Exception(内部中断共3点)
- Fault 故障(能修好,重新执行出错指令) 缺页异常(虚拟内存按需分配内存)
- Trap 陷阱(主动找内核帮忙,处理完走下一行代码) int 0x80 /syscall 系统调用(也俗称 "软中断")
- Abort 终止(修不好,直接发信号杀进程) 除零、野指针段错误、非法指令
硬件中断
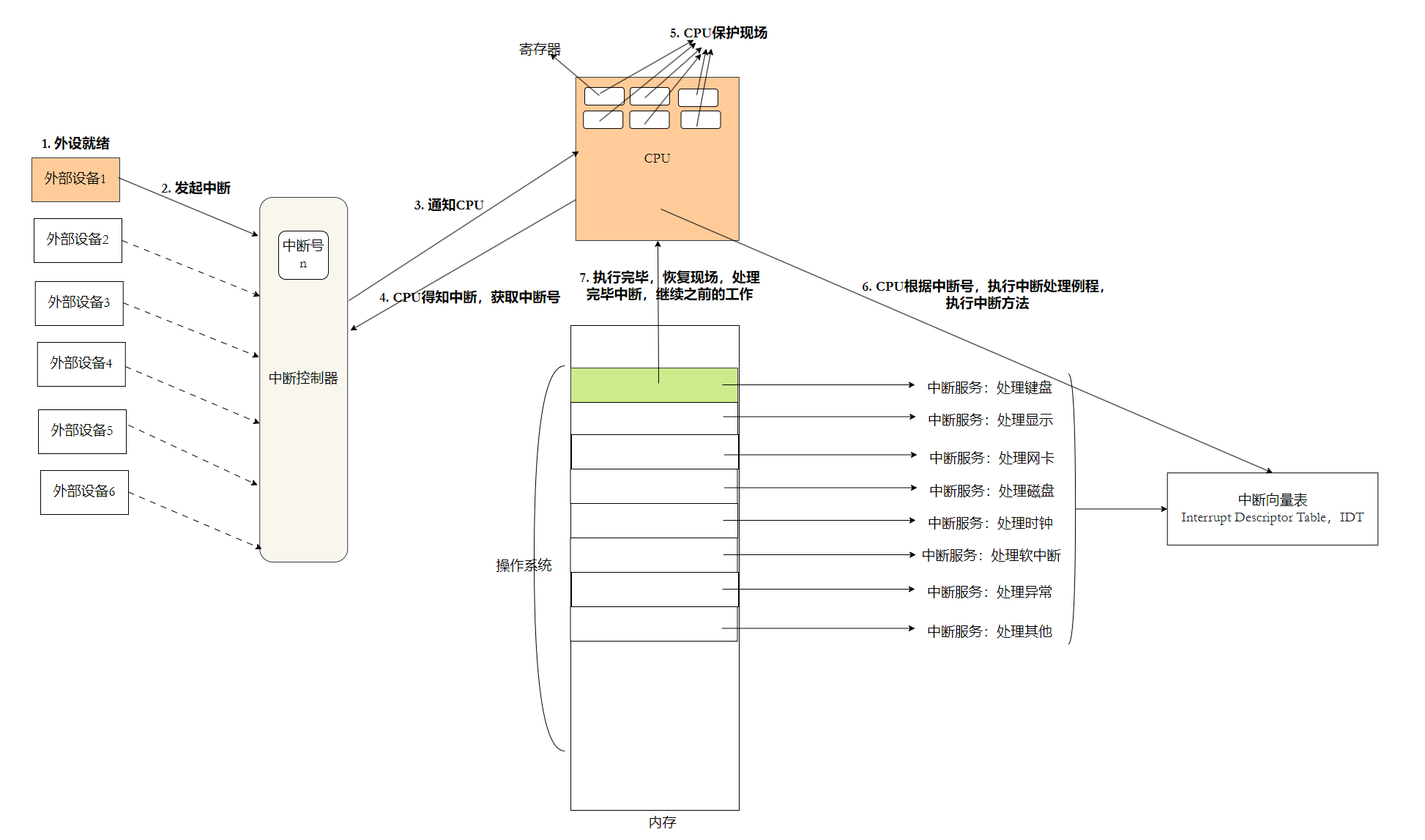
0.小知识
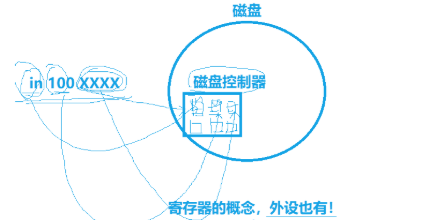
in 100 XXXX,CPU 通过这条指令访问磁盘外设寄存器
- 磁盘:外部存储外设
- 磁盘控制器:磁盘的控制芯片,负责磁盘和 CPU 的数据中转
- 方框内:外设寄存器组(状态寄存器、控制寄存器、数据寄存器)
寄存器不只 CPU 内部有,所有外设(磁盘、网卡、键盘等)控制器都自带硬件寄存器。
os怎么知道外设就绪了?
传统轮询:OS 主动循环检查外设是否就绪;
硬件中断:外设准备好数据后主动向 CPU 发信号通知,CPU 无需空等,大幅提升效率。
完整步骤:
- 外设就绪(外设 1~6):磁盘、网卡等硬件完成读写,产生就绪信号
- 发送中断请求 :外设向中断控制器(8259) 提交中断信号
- 中断控制器通知 CPU :把中断号发给 CPU 的
reg寄存器 - CPU 响应中断:暂停当前正在执行的程序,保存现场(寄存器、指令地址)
- CPU 保护现场:把当前运行进程上下文压栈保存,避免程序数据丢失
- 查询中断向量表 IDT(OS的一部分,OS启动时其会自动加载) :中断向量表可以理解成函数指针数组,下标 = 中断号,存储每个中断对应的处理函数地址
- 执行中断服务程序 :根据中断号找到处理函数,例如处理磁盘函数,完成数据读取(如
in 100 0XXX读取磁盘数据);处理完毕后恢复现场,回到之前被打断的程序继续运行
硬件中断和信号对比
| 硬件中断(硬件层面) | 信号(软件层面,Linux 信号) |
|---|---|
| 发中断(硬件向 CPU 发请求) | 发信号(kill/raise 等给进程发送信号) |
| 保存中断号(CPU 记录硬件中断编号) | 记录信号(进程 PCB 里标记收到的信号编号) |
| 中断号(区分不同硬件事件) | 信号编号(SIGINT=2、SIGKILL=9 等区分软件事件) |
| 处理中断(执行内核预设中断服务函数) | 处理信号(执行信号处理函数,支持自定义捕捉) |
本质上硬件中断是硬件通知 CPU 的异步机制,信号是操作系统用软件模仿这套逻辑,用来通知进程异步事件。
时钟中断(属于硬件中断)
没有中断到来时,OS 执行空闲死循环 + pause 休眠 ,让 CPU 暂停工作、低功耗等待中断触发 ,OS自身处于暂停待机状态,不做额外运算,不会空跑浪费 CPU 资源;
for(;;) {
pause();
}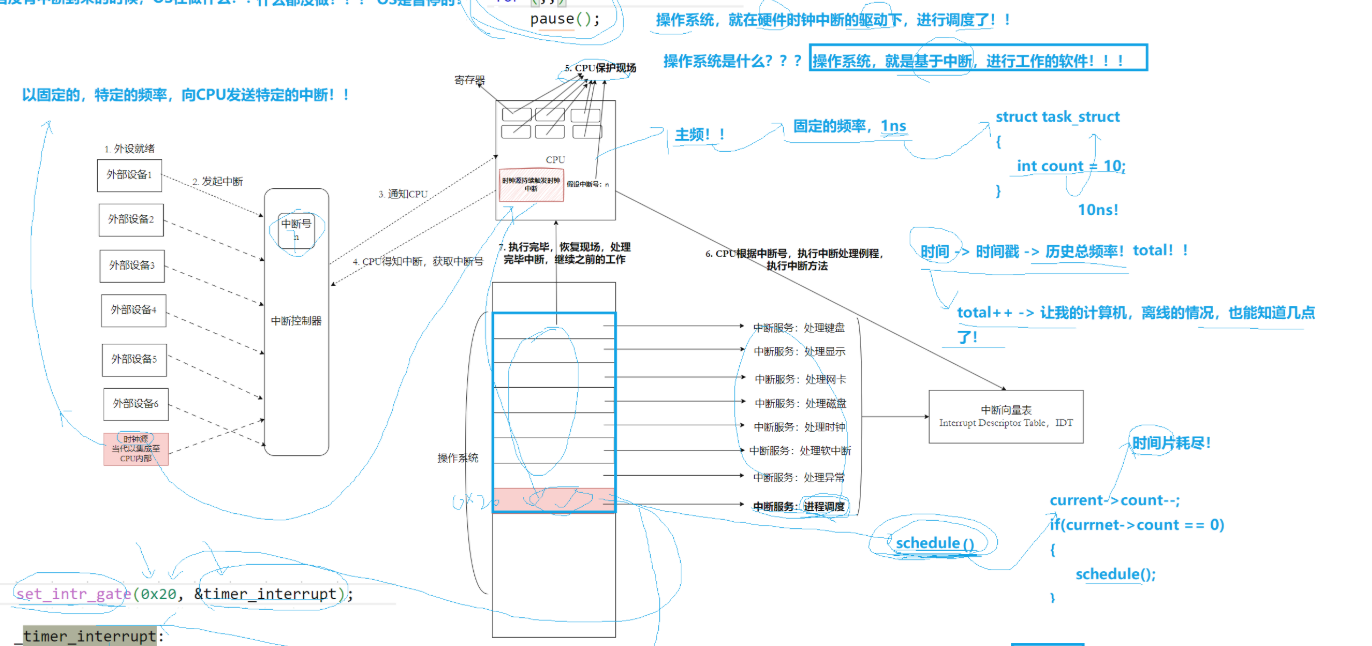
时钟源(CPU 内置硬件) 以固定频率周期性发硬件中断,是多任务分时调度的核心驱动力。
放 CPU 里面:计时更准、响应更快、不受其他外设设备干扰,保证进程调度和系统时间稳定可靠。
每次时钟中断主要做2件事
- 全局计时;
- 进程时间片调度;
进程时间片调度(最核心):
- 每个进程 PCB
struct task_struct里有count,代表剩余时间片; - 每一次时钟中断触发:
current->count--,消耗当前进程 1 单位时间片; - 时间片耗尽判断:
if(current->count == 0),调用schedule()触发进程切换;
全局计时
每次时钟中断 触发,内核就执行 total++。
total 是全局计数器,记录系统开机以来,一共触发了多少次中断,假设时钟频率 100Hz(10ms 一次中断):每 + 1 = 过去了 10 毫秒。用 total × 单次中断时长,就能算出开机过了多久,再结合硬件 RTC 时间,换算成当前年月日时分秒。
RTC 时间是硬件自带、断电不停走的底层时钟时间,是设备时间的基准。
设备开机时,操作系统从 RTC 读取时间,初始化系统时间(是内存临时时钟);关机前系统会把当前时间写回 RTC 保存。
eg:主板 RTC 记录开机基准时间:2026-06-22 10:00:00开机后 total 累计 6000,6000 × 10 = 60000 ms = 60 秒 = 1 分钟,当前系统时间戳 = 10:00:00 + 1 分钟 = 2026-06-22 10:01:00
结论:
操作系统本质:基于硬件中断工作的软件,没有中断 OS 无法感知外设、无法切换进程;
多任务实现依靠时钟中断:时钟源每隔一小会儿就打断 CPU,消耗当前进程 1 单位时间片,时间片用完就换别的程序跑,轮流分配 CPU 时间。
时钟中断和硬件中断区别:
时钟中断是硬件中断的子集,普通硬件中断用来处理外设 IO,时钟中断专门负责分时调度、维护系统时间。
查看源码实现:

set_intr_gate(0x20, &timer_interrupt);把0x20号中断绑定处理函数timer_interrupt,而_timer_interrupt中封装有call _do_timer,而do timer函数就主要判断当前进程时间片耗尽没有,耗尽了就执行schedule()切换进程(其中封装的switch_to(next)主要完成进程上下文切换),反正schedule()函数就是完成进程切换
CPU 内部异常中断--Fault 故障和Abort 终止
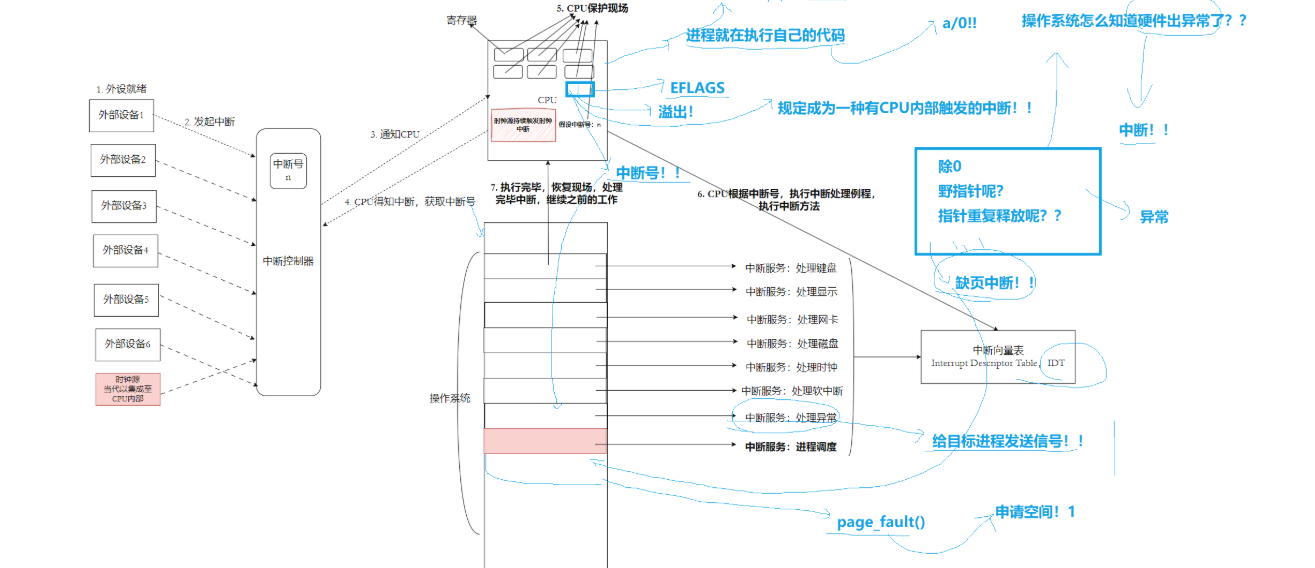
Fault故障(比如缺页异常 page_fault)
- 进程访问一段只有虚拟地址、没有分配物理内存的空间,CPU 触发缺页异常中断;
- CPU 保护现场,查 IDT 执行
page_fault()缺页处理函数; - 内核补齐虚拟内存与物理内存映射;
- 恢复现场,重新执行刚才报错的那条指令(这次有内存,不会再报错);
Abort 终止(除 0、野指针、溢出、重复释放指针)
- CPU 执行到非法指令,内部自动生成异常中断号;
- CPU 同样保护现场,查 IDT 进入「处理异常」的中断服务;
- 内核判断错误类型,给当前进程发送对应信号 :
- 除零 → SIGFPE 浮点错误信号
- 野指针非法访问内存 → SIGSEGV 段错误信号
- 恢复现场,执行自定义捕获函数方法,或者默认处理动作或者忽略
操作系统怎么知道硬件出异常?
硬件 / 代码异常都会被 CPU 硬件实时捕获,生成唯一中断号;CPU 依靠中断号查询操作系统提前注册的 IDT 中断表,然后自动跳转内核预设的异常处理函数,操作系统由此感知到异常并处理。
CPU 内部异常中断--Trap 陷阱("软中断")
用户主动找内核帮忙
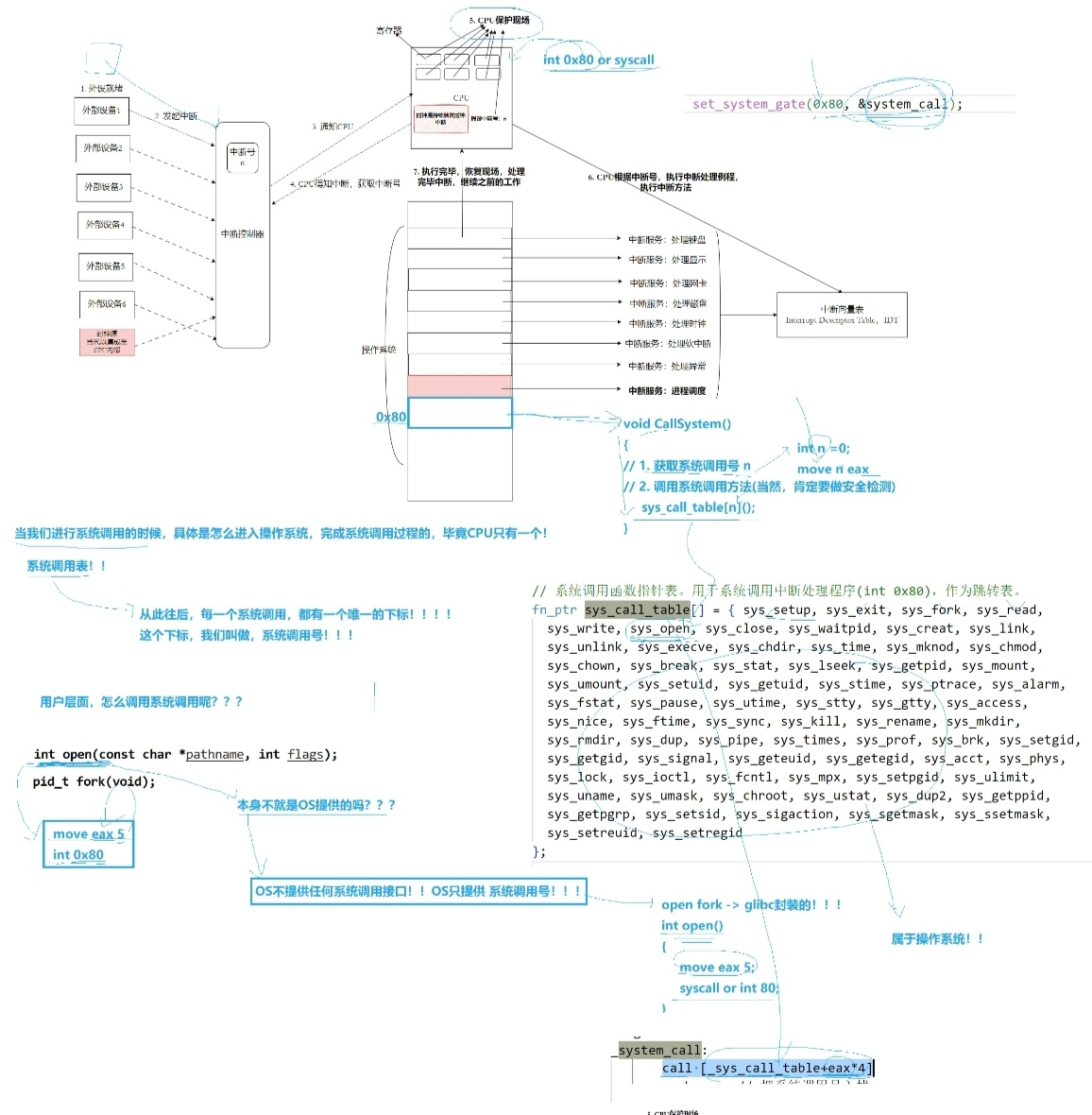
触发条件:
x86 32 位:int 0x80 ,慢
x86_64位:syscall,快
在这里要分清楚的一点:syscall不走标准中断流程(不依赖IDT),有独立快速通道(entry_SYSCALL_64),int 0x80走完整 IDT 中断流程
两者最后都会进入内核的system_call分发逻辑,只是从用户态进内核的 CPU 路径不一样。


系统调用号 :每个操作分配唯一数字(__NR_open/__NR_read等),存入寄存器
- x86 32 位:
eax存调用号,参数依次 ebx/ecx/edx... - x86_64:
rax存调用号,参数 rdi/rsi/rdx...
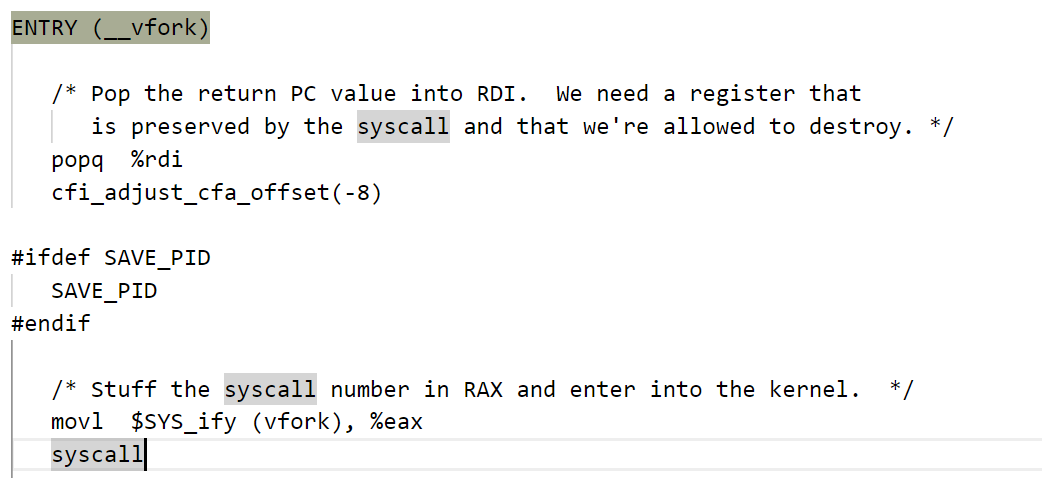
宏SYS_ify(函数名),自动展开为__NR_xxx系统调用号
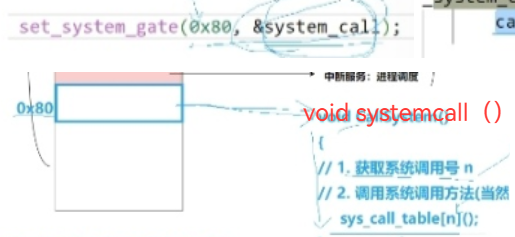
系统调用表 sys_call_table 内核全局函数指针数组,下标 = 系统调用号,例如system_call 通过 call [sys_call_table + eax*4(64位指针大小8)] 跳转对应内核函数(sys_open/sys_fork)
OS不提供任何系统调用接口,只提供系统调用号,open(),fork()系统调用都是glibc做了分装
- 应用层(用户写的 C 代码) 直接调用
open()/fork()/read()等标准函数,看不到底层汇编。 - glibc 标准库(中间封装层) 对所有系统调用做封装:① 将系统调用号存入
eax/rax② 把函数参数放入对应寄存器③ 嵌入int 0x80/syscall汇编指令触发内核切换(就去内核了)
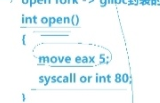
- 内核层 提供调用号 + 系统调用表
sys_call_table
完整执行流程(以open()为例)
用户调用 open() → glibc 填入 __NR_open 到 rax、参数入寄存器、执行syscall → CPU 切内核态进入system_call → 内核查sys_call_table调用sys_open
小知识点:
Trap其实可以分为系统调用 Trap(int 0x80、syscall),调试陷阱 Trap(int3),溢出陷阱 Trap(into)
所以 所有系统调用都是通过 Trap 陷进内核
内核态和用户态
在说完了常见的中断后,从内核态到用户态就可以通过我们上面所说的方式
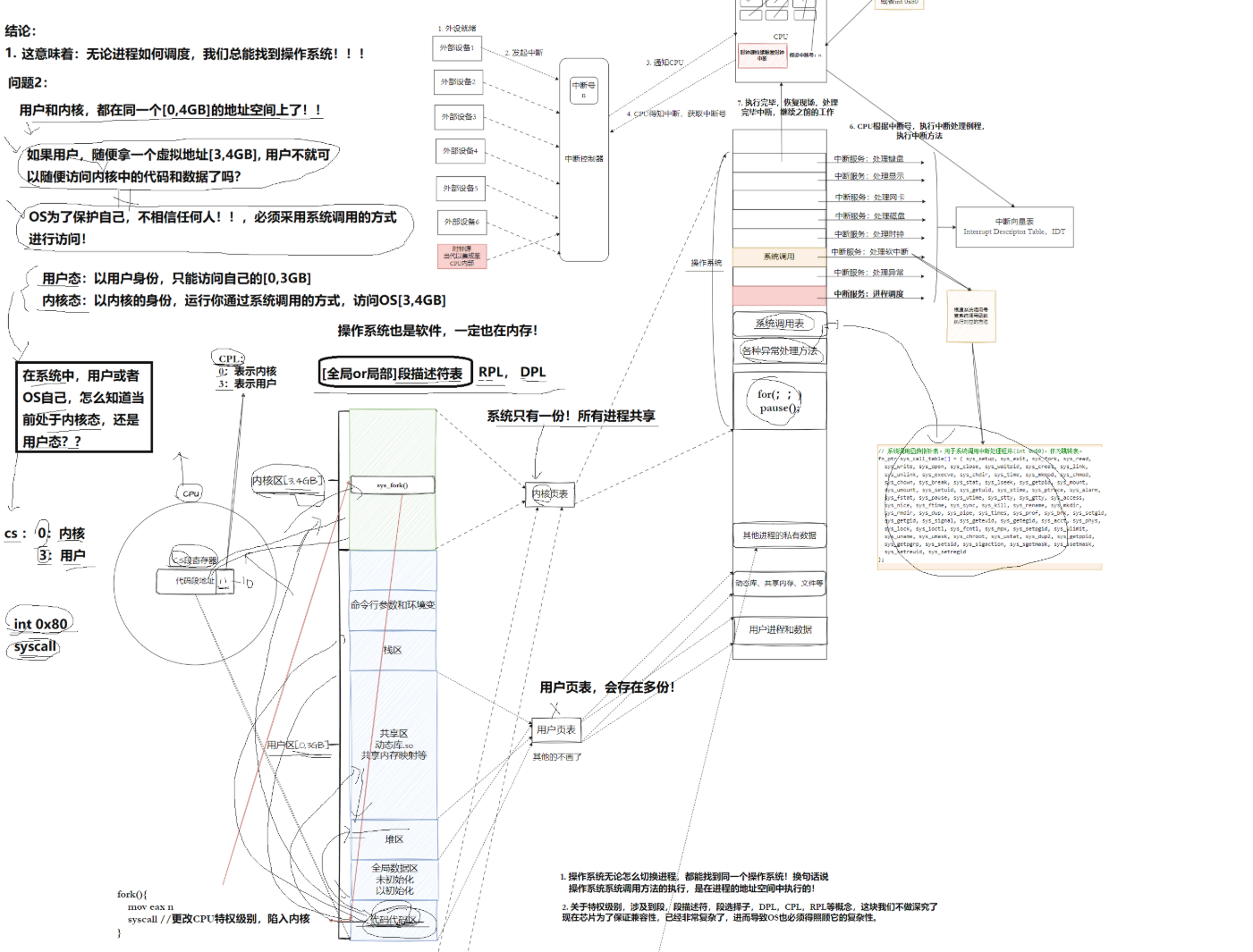
虚拟地址空间划分(32 位)
用户区 0~3GB
- 每个进程独有,进程间相互隔离
- 存放:代码段、全局数据、堆、栈、动态共享库
- 用户态仅能访问这片区域
内核区 3~4GB
- 全系统所有进程共享同一份
- 存放:内核代码、中断处理、GDT 全局段表、页表、进程 PCB、硬件驱动
- 用户态无法直接读写,必须通过系统调用访问
所有进程共享 3~4GB 内核地址空间,无论进程如何调度切换,操作系统内核始终可以被找到;
用户态:以用户的身份只能访问自己的0~3GB
内核态:以内核的身份允许通过系统调用的方式访问3~4GB
页表(用户和内核)
- 用户页表:每个进程独立一份,映射 0~3GB 用户虚拟地址
- 内核页表:全局共享只有1个,3~4GB 内核地址映射统一物理内存
怎么做到用户态 / 内核态保护。?
CPL(当前正在运行代码的权限,即判断在用户态还是内核态)
. 区分标记:CS 寄存器最低位
- CS=0(0b00):内核态,可访问完整 0~4GB 地址
- CS=3(0b11):用户态,仅能访问 0~3GB 用户区
除了CPL外还有DPL和RPL,三者都是实现用户态 / 内核态保护。
但之间的关系比较复杂,这里就以表格简单说明一下
| 缩写 | 全称 | 存放在哪 | 核心作用 |
|---|---|---|---|
| CPL | 当前特权级 | CS 寄存器 | CPU 现在是什么身份 |
| DPL | 描述符特权级 | GDT/LDT 段描述符 | 一段代码 / 一扇门的最低访问权限门槛 |
| RPL | 请求特权级 | 段选择子 | 访问时声明的身份做安全校验,防止用户骗内核越权 |
sigaction(signal的升级版)
#include <signal.h>
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);参数说明
signum:要捕获的信号act:新的信号处理配置,NULL则不修改oldact:输出参数,保存原来的信号处理配置,NULL不需要备份
返回值:成功则返回0,出错则返回-1
struct sigaction
struct sigaction {
// 信号处理函数二选一
void (*sa_handler)(int); // 简单版本,同signal的回调
void (*sa_sigaction)(int, siginfo_t *, void *); // 高级版本,带详细信号信息(不管)
sigset_t sa_mask; // 信号屏蔽集:处理当前信号时,阻塞哪些信号
int sa_flags; // 行为控制标志(不管)
void (*sa_restorer)(void); // 废弃,不用管(不管)
};sa_mask(信号屏蔽集):
当某个信号的处理函数被调用时,内核自动将当前信号加入进程的信号屏蔽(block表置为1),这样就保证了在处理某个信号时,如果这种信号再次产生,那么它会被阻塞到当前处理结束为止。如果在调用信号处理函数时,除了当前信号被⾃动屏蔽之外,还希望自动屏蔽另外⼀ 些信号,则加入sa_mask即可
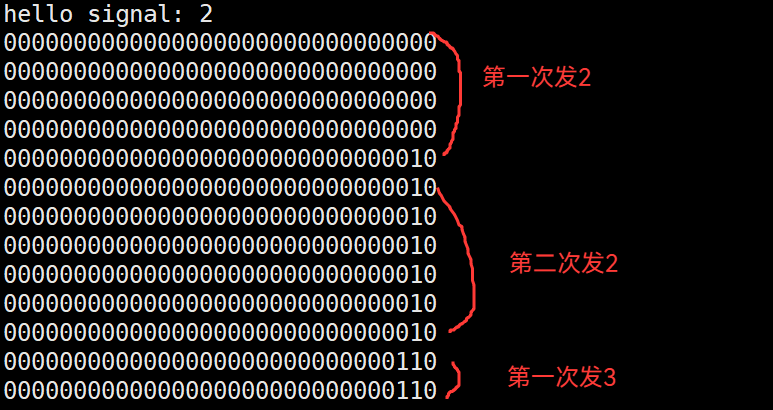
验证:
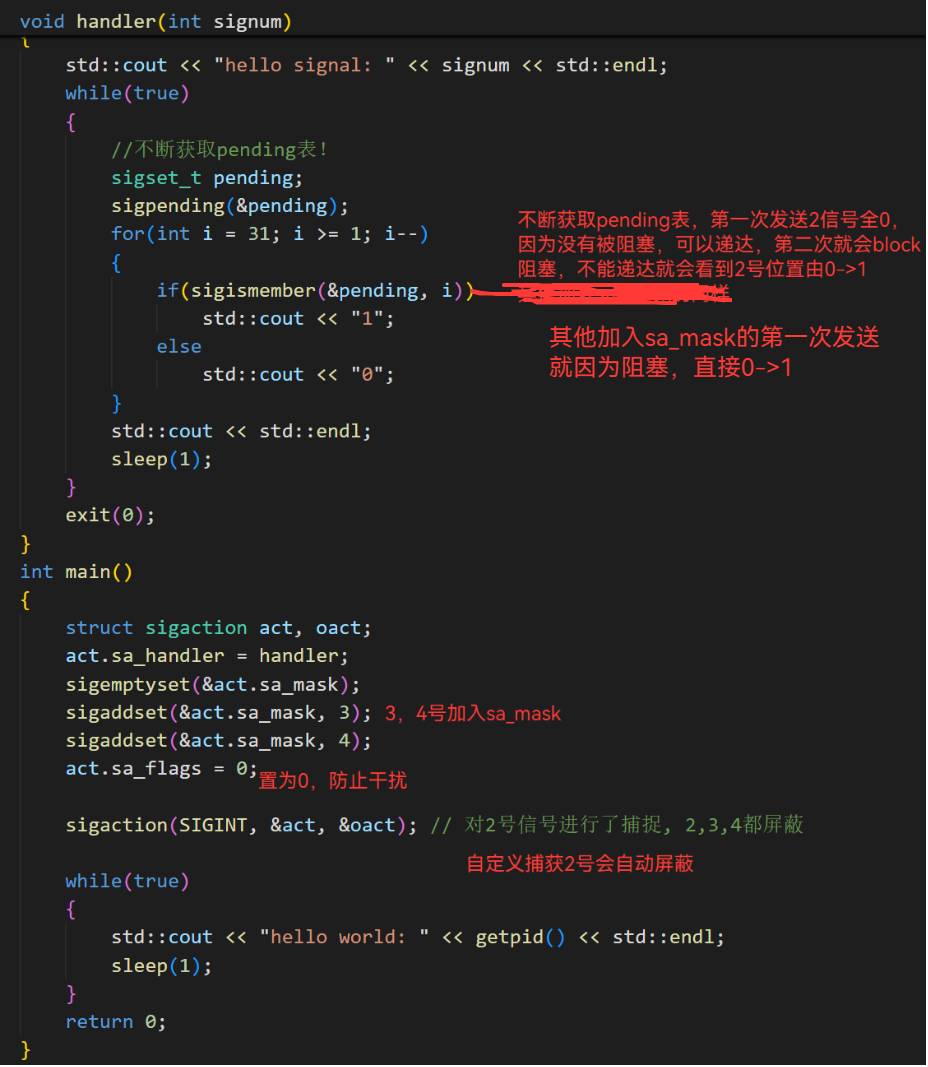
运行结果:
可重入函数
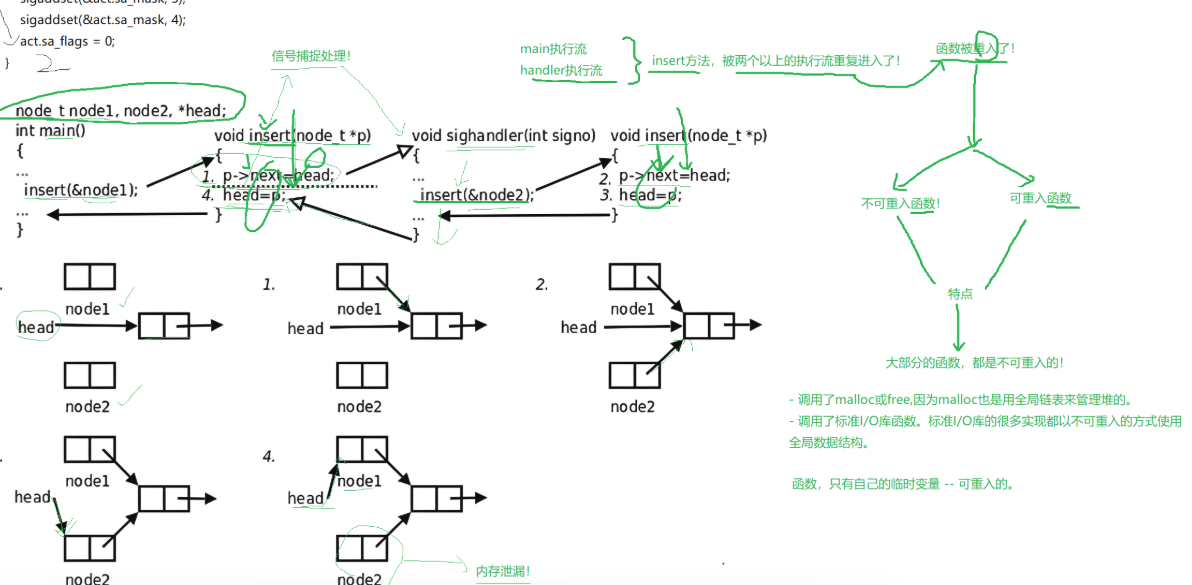
上表最终结果:
node2 从链表中彻底丢失,无法访问 → 内存泄漏,链表数据完全错乱
什么是重入
同一个函数同时被多条执行流并发进入执行,比如:
- 主线程正常调用
insert(main 执行流) - 执行到一半时,硬件触发信号,handler 又调用了同一个
insert此时insert函数被重入。
可重入 / 不可重入区分
- 可重入函数:重入后不会产生逻辑错误、数据错乱、内存泄漏,多条执行流并发调用结果正确。
- 不可重入函数:重入后全局 / 静态共享数据被篡改,出现逻辑 bug(比如图中链表丢失节点、内存泄漏)。
不可重入函数典型特征:
操作全局 / 静态变量
调用了malloc或free,因为malloc也是用全局链表来管理堆的。
调用了标准I/O库函数(printf/fopen等)
相反可重入函数必备条件,函数仅使用函数内部局部栈变量,完全不触碰任何共享资源
volatile
编译器优化的底层动机
CPU 访问速度对比(数量级差距极大):
- 寄存器:1~3 个时钟周期(最快)
- 物理内存:几百个时钟周期(最慢)
所以编译器核心优化目标:尽量减少慢的内存访问,把反复读取的变量丢进寄存器,大幅提速。
编译器优化级别
-o0,-o1,-o2,-o3
优化级别依次增加
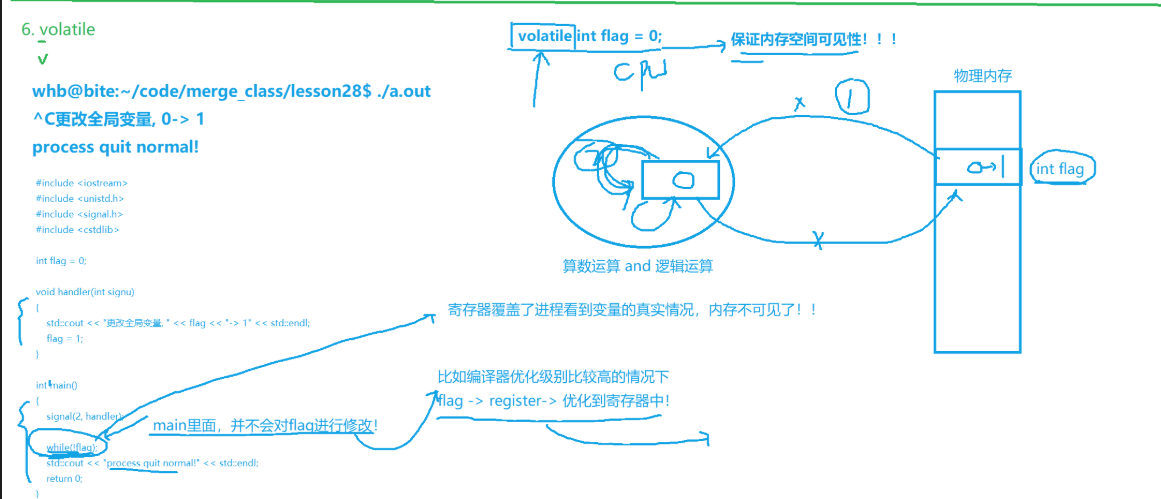
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <cstdlib>
int flag = 0; // 未加volatile
void handler(int signo)
{
std::cout << "更改全局变量, " << flag << " -> 1" << std::endl;
flag = 1; // 信号处理函数修改flag
}
int main()
{
signal(2, handler); // 绑定Ctrl+C信号
while(!flag) // 主线程循环判断flag
{
// 循环内无修改flag的逻辑
}
std::cout << "process quit normal!" << std::endl;
return 0;
}编译器只做单执行流静态分析 ,它分析 main 时完全感知不到存在另一条独立执行流:信号中断 handler;
所以编译器静态扫描整个 main 函数,得出结论:
在主线程这条执行流里,
flag自始至终只有初始值 0,没有任何代码修改它。
在优化级别高的编译器看来 :既然值永远不变,没必要每次循环都慢吞吞读内存,只在循环前读一次放到寄存器,之后循环就只读取寄存器里的了。(优化级别低的还会读内存再更新)
所以当handler修改flag为1时,CPU 寄存器里还是旧值 0
下面让我们来看一下不同优化级别下的运行情况:


按理说O2和O3应该和O1结果一样,但在测试的时候发现结却是:


直接打印while循环后面的语句,就是说直接就把while()循环给优化了(因为while循环什么都没有,优化了不影响)这不是这里主要说明的地方,知道就行,下面就以O0和O1来验证volatile的作用
volatile作用:保持内存的可见性,告知编译器,被该关键字修饰的变量,不允许被优化,对该变量的任何操作,都必须在真实的内存中进行操作
int flag=0-->volatile int flag=0;后

SIGCHLD
子进程终止 / 暂停 / 恢复运行时,内核给父进程发送 SIGCHLD
默认动作:忽略,所以父进程要调用 wait/waitpid回收子进程

Ign = SIG_IGN
waitpid(-1,nullptr,0)阻塞等待,如果此时有子进程不退出那么,父进程就不能做自己的事,只会浪费时间一直等子进程退出
void WaitAll(int num)
{
while (true)
{
pid_t n = waitpid(-1, nullptr, 0); //
if (n == 0)
{
break;
}
else if (n < 0)
{
std::cout << "waitpid error " << std::endl;
break;
}
}
std::cout << "father get a signal: " << num << std::endl;
}
int main()
{
// 父进程
signal(SIGCHLD, WaitAll); // 父进程
for (int i = 0; i < 10; i++)
{
pid_t id = fork(); // 如果我们有10个子进程呢??6退出了,4个没退
if (id == 0)
{
sleep(3);
std::cout << "I am child, exit" << std::endl;
//做实验,只让6个进程退出,另外4个先不退
if(i <= 6) exit(3);
else pause();
}
}
while (true)
{
std::cout << "I am fater, exit" << std::endl;
sleep(1);
}
return 0;
}运行结果:
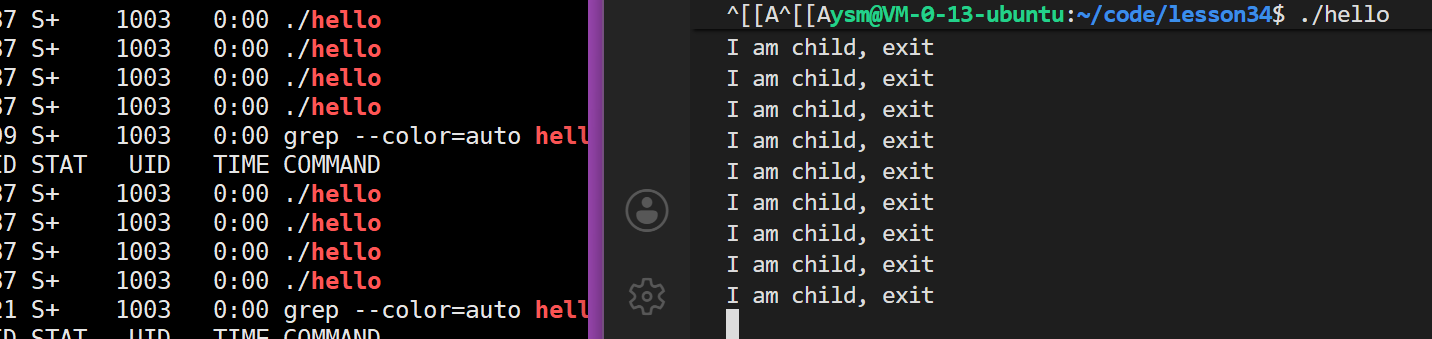
父进程就阻塞在这,不能正常打印
waitpid(-1,nullptr,WNOHANG)
运行结果:
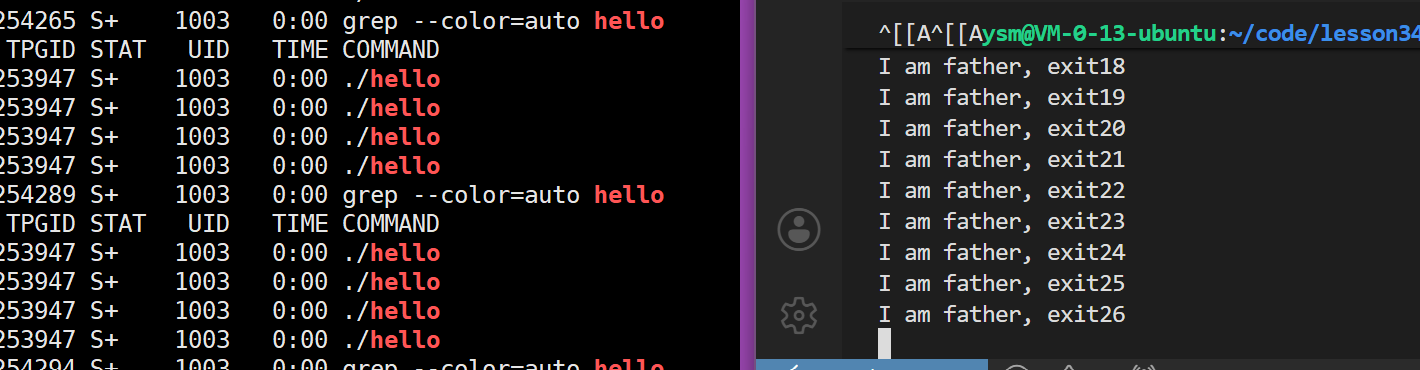
父进程还可以正常运行之间的代码,不会阻塞
**signal(SIGCHLD, SIG_IGN); (**父进程完全不关心子进程退出状态,简单省心。)
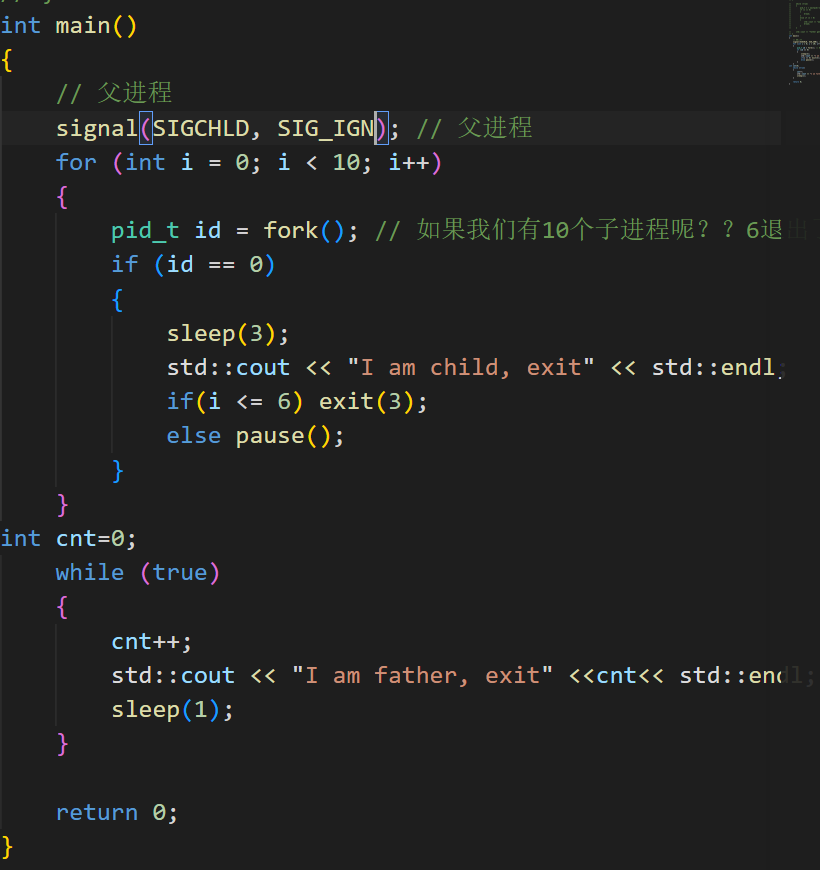
将 SIGCHLD 设置为忽略
子进程终止时不会产生僵尸进程,父进程不会收到 SIGCHLD 信号,无需手动 wait/waitpid,内核自动回收子进程资源
其实这和sigaction 标志 SA_NOCLDWAIT: 子进程结束后内核自动释放资源,**不会产生僵尸进程,也不会发送 SIGCHLD相似(**act.sa_flags = SA_NOCLDWAIT;)