前言
在复习的时候可以拿笔或者新建个文档,将知识点的重点内容记下来,像以下这样

我已经整理好了详细的复习资料,本文配套资料自取


简单理论
大体框架(先梳理整体逻辑)
我们可以按照计算机的经典五大部件(运算器、控制器、存储器、输入/输出设备)加上系统总线这个框架来复习。
1. 计算机系统概述 (基础中的基础)
这部分是送分题,但概念必须清晰。
- 冯·诺依曼体系结构 :这是核心。记住它的核心思想是**"存储程序"**,即程序和数据都以二进制形式存放在存储器中。
- 五大部件:运算器、控制器、存储器、输入设备、输出设备。
- 层次结构:从底层到高层依次是:微程序机器级 -> 机器语言级 -> 操作系统级 -> 汇编语言级 -> 高级语言级。
- 性能指标 :
- 字长:决定运算精度。
- MIPS:每秒执行多少百万条指令。
- CPI:执行一条指令所需的时钟周期数。
2. 数据的表示与运算 (计算题高发区)
这部分主要考查数制转换和加减法运算,特别是补码运算。
- 数制转换 :二进制、十进制、十六进制互转(如模拟卷中的
30D = 1EH)。 - 定点数表示 :
- 原码:最高位符号位,0正1负。
- 反码:正数同原码,负数符号位不变,数值位取反。
- 补码 (重点):正数同原码,负数反码+1。补码中0的表示是唯一的。
- 移码:通常用于表示浮点数的阶码。
- 溢出判断 :
- 双符号位法(变形补码) :
00表示正,11表示负。若结果符号位为01(正溢)或10(负溢),则发生溢出。 - 单符号位法:最高有效位进位 ⊕ 符号位进位 = 1,则溢出。
- 双符号位法(变形补码) :
- 浮点数 :
N = M * R^E。注意规格化的概念,即尾数的最高有效位必须为1(对于原码)。
3. 存储系统 (难点与重点)
这部分涉及层次结构和地址映射计算,是考试的重头戏。
- 三级存储体系:Cache - 主存 - 辅存。目的是解决速度、容量和成本的矛盾。
- 局部性原理 :
- 时间局部性:刚被访问的很可能再次被访问(如循环)。
- 空间局部性:访问了当前地址,其附近的地址也很可能被访问(如数组)。
- Cache 映射方式 (必考计算):
- 直接映射 :主存块只能放到 Cache 的固定位置。公式:
Cache行号 = 主存块号 % Cache总行数。 - 全相联映射:主存块可以放到 Cache 的任意位置。
- 组相联映射:折中方案。先分组,组内全相联。
- 直接映射 :主存块只能放到 Cache 的固定位置。公式:
- 存储器扩展 :
- 位扩展:增加数据位宽(如 4位 -> 8位),地址线并联。
- 字扩展:增加存储单元数量,地址线串联(需要译码器)。
4. 指令系统
- 指令格式:操作码 + 地址码。
- 寻址方式 :
- 立即寻址:操作数就在指令里(速度快,但范围小)。
- 直接寻址:指令给出的是内存地址。
- 间接寻址:指令给出的是地址的地址(需要多次访存)。
- 寄存器寻址:操作数在寄存器中(最快)。
5. CPU 结构与功能
- 核心寄存器 :
- PC (程序计数器) :存放下一条要执行指令的地址。
- IR (指令寄存器) :存放当前正在执行的指令。
- MAR (存储器地址寄存器):存放要访问的内存单元地址。
- MDR (存储器数据寄存器):存放读出或写入的数据。
- 控制器 :
- 硬布线控制器:速度快,但设计复杂,修改困难(适合 RISC)。
- 微程序控制器:灵活性高,设计规整,但速度稍慢(适合 CISC)。
- 指令流水线 :
- 将指令执行分为取指(IF)、译码(ID)、执行(EX)、访存(MEM)、写回(WB)等阶段。
- 流水线周期 = 执行时间最长的那个阶段的时间。
- 执行n条指令的时间 =
(k + n - 1) * 周期(k为流水线段数)。
6. 总线与 I/O 系统
- 总线仲裁 :
- 链式查询:对电路故障最敏感,离控制器越近优先级越高。
- 计数器定时查询:优先级可动态改变。
- 独立请求:响应速度快,但控制线多。
- I/O 控制方式 (按效率从低到高):
- 程序查询:CPU 轮询,效率最低,CPU 利用率低。
- 程序中断:外设就绪后发信号,CPU 暂停当前工作去处理。适合键盘等低速设备。
- DMA (直接存储器访问):硬件控制,直接在内存和外设间传数据,仅在开始和结束时打扰 CPU。适合硬盘等高速设备。
- 通道/IOP:更高级的独立处理器,进一步解放 CPU。
💡 复习建议与易错点提示
- 区分概念:一定要分清 MAR 和 MDR,PC 和 IR 的功能,这是选择题常设陷阱的地方。
- 计算题专项突破 :
- 补码加减法:一定要练习双符号位判断溢出的方法。
- Cache 映射:特别是组相联映射的地址结构划分(标记位、组号、块内地址)。
- 存储器扩展:搞清楚什么时候需要位扩展,什么时候需要字扩展,以及芯片数量的计算。
- 简答题背诵 :
- 冯·诺依曼结构的特点。
- 程序访问的局部性原理及其在存储系统中的应用。
- 中断处理的过程(请求 -> 判优 -> 响应 -> 服务 -> 返回)。
- 三种 I/O 方式的优缺点比较。
一部分一部分带你复习
我们先从最基础、也是所有后续内容基石的第一部分开始。
🧱 第一块:计算机系统概述
这部分是整个计算机组成原理的"世界观",理解它,你就明白了计算机到底是个什么东西,以及它是如何工作的。
1. 冯·诺依曼结构 (Von Neumann Architecture)
这是现代计算机的"祖宗之法",几乎所有考题都会围绕它展开。你必须记住它的核心思想:
- 存储程序 (Stored Program) :这是最核心的一点。程序(指令)和数据都以二进制的形式,不加区别地存放在同一个存储器中。
- 五大部件 :计算机硬件由 运算器、控制器、存储器、输入设备、输出设备 这五大部件组成。
- 指令驱动:计算机的工作过程,就是自动地、连续地从存储器中取出指令、分析指令、执行指令的过程。
- 以运算器为中心:在早期的冯·诺依曼机中,数据流都经过运算器。现代计算机已演变为以存储器为中心。
一句话总结:冯·诺依曼结构定义了计算机"存什么"(二进制)、"怎么存"(程序和数据放一起)、"由谁组成"(五大部件)和"怎么工作"(自动取指执行)。
2. 计算机的层次结构
计算机不是一个单一的个体,而是一个复杂的系统。我们可以从不同层面来理解它,就像一个公司有不同的管理层级一样。
从最底层的硬件到最顶层的应用,通常分为以下几个层次:
- 微程序机器级 (Microprogram Level):最底层,由硬件直接执行微指令。
- 传统机器语言级 (Machine Language Level):CPU 能直接识别和执行机器指令(二进制代码)。
- 操作系统级 (Operating System Level):管理硬件资源,为上层提供接口。
- 汇编语言级 (Assembly Language Level) :用助记符(如
ADD,MOV)代替二进制指令,需要通过汇编器翻译成机器语言。 - 高级语言级 (High-Level Language Level):如 C, Java, Python,更接近人类语言,需要通过编译器或解释器翻译。
一句话总结:下层为上层提供服务,上层是下层的抽象。我们写的代码最终要一层层"翻译"下去,变成硬件能听懂的"0"和"1"。
3. 核心硬件部件功能
这是选择题和填空题的常客,一定要分清楚每个部件是干什么的。
| 部件 | 核心功能 | 易混淆点辨析 |
|---|---|---|
| 运算器 (ALU) | 执行所有的算术运算 (加减乘除)和逻辑运算(与或非)。 | 它只负责"算",不负责"指挥"。 |
| 控制器 (CU) | 计算机的"大脑",负责取指令、分析指令、执行指令,并向其他部件发出控制信号。 | 它只负责"指挥",不负责"计算"。 |
| CPU | 运算器 + 控制器。是计算机的核心。 | CPU 不包含存储器! |
| 存储器 | 存放程序 和数据。 | 分为主存(内存)和辅存(硬盘)。 |
4. 关键寄存器
寄存器是 CPU 内部的高速存储单元,有几个特别重要,必须分清:
- PC (程序计数器) :存放下一条将要执行的指令的地址。取走当前指令后,PC 会自动加 1,指向下一条。
- IR (指令寄存器) :存放当前正在执行的那条指令。
- MAR (存储器地址寄存器) :存放 CPU 想要访问的内存单元的地址。
- MDR (存储器数据寄存器) :存放从内存读出 或准备写入 内存的数据。
一句话总结:PC 指路,IR 拿活,MAR 找地,MDR 搬货。
📝 自测一下
看完上面的内容,试着回答这几个问题,检验一下掌握程度:
- 冯·诺依曼计算机最核心的思想是什么?
- CPU 是由哪两个主要部件组成的?
- 哪个寄存器负责存放下一条指令的地址?
- 计算机硬件能直接执行的语言是汇编语言还是机器语言?
你可以把你的答案写下来,答案在下面,不要偷看哦。没问题了,我们就进入下一块:数据的表示与运算。
第一部分答案:
1.存储程序;程序与数据以二进制的形式存放,以运算器为中心,由操作码和地址码组成,五大核心部件:运算器,控制器,存储器,输入系统,输出系统
2.运算器,控制器
3.程序计数器
4.机器语言
做的怎么样,相信你对第一部分的掌握非常扎实,概念清晰,没有混淆点了。
🧮 第二块:数据的表示与运算
这部分是计算题的"重灾区",也是理解计算机如何"思考"的关键。核心就是搞清楚计算机如何用"0"和"1"来表示正数、负数、小数,以及如何进行加减乘除。
1. 进位计数制
这个相对简单,但必须熟练。
- 二进制 (B):计算机的母语,只有 0 和 1。
- 十进制 (D):我们人类的母语。
- 十六进制 (H) :二进制的"简写",因为
4位二进制刚好对应1位十六进制,写起来更简洁。比如1111 B=F H。
核心技能:必须熟练掌握它们之间的相互转换,尤其是二进制和十进制。
十六进制:二进制的"速记本"
十六进制其实一点都不难,你只需要记住一件事:它是二进制的"压缩包"。
因为二进制太长了(比如 1111 1111),人类看着眼晕。而 4位二进制 刚好能表示 1位十六进制。
你只需要背下这组"暗号":
0000= 00001= 10010= 20011= 30100= 40101= 50110= 60111= 71000= 81001= 91010= A (10)1011= B (11)1100= C (12)1101= D (13)1110= E (14)1111= F (15)
转换技巧(每4位一劈):
比如二进制 1011 0101,从右往左每4位分开,1011 是 B,0101 是 5。所以就是 B5。就这么简单!
十进制怎么转化为十六进制?
其实非常简单,核心就是**"除以16取余数,倒序排列"**。
具体步骤:
- 把十进制数不断除以 16。
- 记下每次的余数。
- 直到商为 0 为止。
- 把得到的余数**从下往上(倒序)**连起来,就是十六进制。
举个通俗的例子:
把十进制的 30 转成十六进制:
- 第一步:30 ÷ 16 = 1 ...... 余 14 (14在十六进制里是 E)
- 第二步:1 ÷ 16 = 0 ...... 余 1 (1在十六进制里还是 1)
- 倒序排列余数:所以
30的十六进制就是1E。
(注:在考试中,更常见的做法是先把十进制转成二进制,然后"每4位一劈"直接转成十六进制,这样更不容易出错。)
2. 定点数的表示 (原码、反码、补码)
这是本章节的绝对重点!计算机用这些编码来表示有符号的整数或小数。
| 编码方式 | 正数 | 负数 | 特点 |
|---|---|---|---|
| 原码 | 符号位为0,数值位不变 | 符号位为1,数值位不变 | 最直观,但 0 有两种表示 (+0 和 -0),加减法复杂。 |
| 反码 | 同原码 | 符号位为1,数值位按位取反 | 0 也有两种表示,是求补码的中间步骤。 |
| 补码 | 同原码 | 反码 + 1 | 计算机中实际使用的编码! 0 的表示唯一,能将减法变为加法,简化硬件设计。 |
一句话口诀:正数三码合一;负数原码取反得反码,反码加一得补码。
3. 溢出判断
当运算结果超出了机器能表示的范围时,就会发生溢出。这是计算题的另一个高频考点。
- 双符号位法 (变形补码) :这是最可靠的判断方法。
- 用两个比特位表示符号:
00代表正,11代表负。 - 运算后,看结果的两个符号位:
00或11:无溢出。01:正溢出 (两个正数相加,结果太大变成了负数)。10:负溢出 (两个负数相加,结果太小变成了正数)。
- 用两个比特位表示符号:
4. 浮点数表示
用来表示带小数点的数,类似于科学计数法。格式为 N = M × R^E。
- M (尾数):表示数的精度,是一个定点小数。
- E (阶码):表示数的范围,是一个定点整数。
- R (基数):通常是 2,是隐含的,不存储在机器数中。
规格化 :为了保证精度,要求尾数的最高有效位必须是 1(例如 0.1xxxx 的形式)。如果不是,就需要通过移动小数点(调整阶码)来使其满足要求。计数法"
浮点数听起来吓人,其实就是我们初中学过的科学计数法(比如 3.14×1023.14×102 ),只不过计算机里把底数换成了2。
公式是:N=尾数(M)×2阶码(E)N=尾数(M)×2阶码(E)
你可以把它想象成手电筒:
- 尾数 (M) :决定了手电筒照得多清楚(精度)。
- 阶码 (E) :决定了手电筒照得多远(范围)。
举个通俗的例子:
假设我们要表示十进制的 12.0,二进制是 1100.0。
- 移动小数点 :把它变成
0.1100,小数点向左移了4位。 - 确定阶码:因为左移了4位,所以阶码 E=4E=4 。
- 确定尾数 :尾数 M=0.1100M=0.1100 。
所以,12.0在计算机里就被拆解成了"尾数"和"阶码"两部分分开存。
补码:为什么计算机非要用它?
你刚才问"为什么用补码不用原码",这是极其经典的考点!记住两个核心理由:
- 把减法变成加法 :计算机硬件造一个"加法器"很容易,造一个"减法器"很复杂。用补码,
A - B可以直接变成A + (-B的补码),这样CPU里只需要加法器就能搞定一切! - 0的表示唯一 :原码里有
+0和-0两个零,浪费了一个编码,还容易引起逻辑混乱。补码里0只有一种表示。
📝 自测一下
来,试试这几道题,看看概念是否真的吃透了:
- 为什么计算机内部普遍采用补码进行运算,而不是原码?
- 写出十进制数
-5的 8 位二进制原码、反码和补码。 - 在双符号位法中,如果两个负数相加,结果的符号位是
01,这表示发生了什么? - 浮点数的阶码 和尾数分别决定了这个数的什么特性?
第二部分答案:
1.因为补码可以直接进行加法运算,计算机做减法很复杂,而且补码的0只有一种表示
2.原码:10000101 反码:11111010 补码:11111011
3.负溢出
4.尾数M是决定精度,阶码E决定范围
到这里,第二块:数据的表示与运算,你已经完全拿下了!
🧱 第三块:存储系统
这块是整门课的重中之重,也是考试里最容易出大题、拉开分差的地方。别怕,我们依然把它拆成几个小点,一步步来。
1. 为什么需要三级存储体系?
你可以把计算机的存储想象成你的书桌和图书馆:
- Cache(高速缓存) :就像你手边的草稿纸。速度极快,但容量很小。用来放你当前正在疯狂计算的数据。
- 主存(内存) :就像你的书桌。速度较快,容量适中。用来放你当前正在看的书(正在运行的程序)。
- 辅存(硬盘) :就像图书馆。速度极慢,但容量巨大,断电也不丢数据。用来放你暂时不用的书。
核心目的:用尽可能低的成本,实现"速度快、容量大"的效果。
2. 局部性原理(为什么 Cache 能起作用?)
计算机之所以能用 Cache 提速,全靠这个原理:
- 时间局部性 :刚被访问过的东西,大概率马上还会被访问。(比如:
for循环里的变量) - 空间局部性:访问了某个地址,大概率马上会访问它旁边的地址。(比如:读取数组里的第一个元素,接着就会读第二个)
3. Cache 映射方式(必考计算题!)
这是这块最难、也最常考的地方。主存那么大,Cache那么小,数据该怎么放?有三种方式:
- 直接映射 :
- 规则 :一个萝卜一个坑。主存的第 ii 块,只能放在 Cache 的第 ii 行(取余数)。
- 优点:硬件最简单,速度最快。
- 缺点:冲突率高(两个常用数据刚好要抢同一个坑,只能互相挤掉)。
- 全相联映射 :
- 规则 :随便放。主存的任何一块,可以放在 Cache 的任意一行。
- 优点:冲突率极低,空间利用率高。
- 缺点:硬件太复杂,找数据时得挨个比对,速度最慢。
- 组相联映射 :
- 规则:折中方案。把 Cache 分成若干"组",先按组找(直接映射),组内随便放(全相联映射)。
4. 存储器扩展(字扩展 vs 位扩展)
当单个存储芯片不够用时,需要把多个芯片拼起来:
- 位扩展 :增加数据位宽。比如芯片是 4位的,要拼成 8位。就像把4根细水管并排绑在一起,变成一根粗水管。地址线并联,数据线串联。
- 字扩展 :增加存储容量。比如芯片容量不够,需要多买几块。数据线并联,地址线串联(需要用到译码器来选通不同的芯片)。
📝 自测一下
来检验一下这块的理解,题目都不难:
- 计算机系统中,Cache 主要是为了解决 CPU 和 主存 之间的什么矛盾?
- 在 Cache 的三种映射方式中,哪一种的硬件实现最简单、速度最快?
- 如果我想把 4 片容量为
1K × 4位的存储芯片,扩展成1K × 8位的存储器,这属于什么扩展?(字扩展还是位扩展?)
第三部分答案:
1.cpu速度快但是容量小,主存速度慢但是容量大,根据局部性原理,就能用低成本实现,速度快容量大的效果
2.直接映射
3.位拓展
看来第三块:存储系统的基础概念你已经稳稳拿下了。
🧱 第四块:指令系统
这块主要讲计算机的"语言"------指令是怎么设计的,以及它是怎么找到数据的。
1. 指令格式
一条指令通常由两部分组成:操作码 + 地址码。
- 操作码:告诉 CPU "做什么"(比如加法、减法、跳转)。
- 地址码:告诉 CPU "对谁做"(比如操作数在哪里,或者下一条指令去哪)。
2. 寻址方式(重点!)
这是指令系统里最常考的概念。通俗来说,就是**"找操作数(数据)的方法"**。
- 立即寻址 :指令里直接给出了数据本身。
- 比喻:就像外卖单上直接写着"送一个汉堡",数据就在指令里。速度最快,但数据大小受指令长度限制。
- 直接寻址 :指令里给出的是数据在内存中的真实地址 。
- 比喻:外卖单上写着"送到XX路XX号",CPU 直接去这个地址拿数据。
- 间接寻址 :指令里给出的地址,里面存的还是地址(地址的地址)。
- 比喻:外卖单上写着"去XX路XX号拿一张纸条,纸条上写着真正的送货地址"。需要访问两次内存,速度慢,但非常灵活。
- 寄存器寻址 :数据直接放在 CPU 内部的寄存器里。
- 比喻:数据就在你手里拿着。速度极快,因为不需要访问内存。
📝 自测一下
- 一条指令通常由哪两个部分组成?
- 如果指令的地址码字段直接给出了操作数在内存中的真实地址,这叫什么寻址方式?
- 在立即寻址、直接寻址、间接寻址、寄存器寻址这四种方式中,哪一种执行速度最快?为什么?
第四部分答案:
1.操作码和地址码
2.直接寻址
3.寄存器寻址,因为数据直接存在cpu内部寄存器了,不用输入指令才能获得地址
看来第四块:指令系统对你来说已经毫无难度了。我们继续推进!
🧱 第五块:CPU 结构与功能
这块是计算机的"指挥中心",主要考查CPU内部是怎么运转的,以及它如何高效地执行指令。
1. 核心寄存器(必考选择题)
这几个寄存器是CPU的"贴身小秘书",必须分清它们的职责:
- PC (程序计数器) :永远指向下一条要执行的指令的地址。
- IR (指令寄存器) :存放当前正在执行的那条指令。
- MAR (存储器地址寄存器) :存放CPU准备去内存找的地址。
- MDR (存储器数据寄存器) :存放刚从内存读出来,或者准备写进内存的数据。
2. 指令流水线(必考计算题)
这是提高CPU效率的绝招。你可以把它想象成工厂的流水线:
- 把一条指令的执行过程拆分成几个阶段:取指 -> 译码 -> 执行 -> 访存 -> 写回。
- 当第一条指令在"执行"时,第二条指令可以同时在"译码",第三条指令可以同时在"取指"。大家同时干活,效率大幅提升!
- 核心考点 :流水线的执行时间取决于最慢的那一段(木桶效应)。
- 计算公式:执行 nn 条指令的时间 = (流水线段数+n−1)×周期(流水线段数+n−1)×周期 。
3. 控制器的两种方式
控制器负责发出控制信号,有两种实现方式:
- 硬布线控制器 :用纯硬件电路(逻辑门)搭出来的。优点 是速度极快;缺点是设计复杂,一旦造好就很难修改。
- 微程序控制器 :把控制信号写成一段段"微代码"(软件思想),存在专门的存储器里。优点 是规整、容易修改;缺点是速度相对较慢。
📝 自测一下
来检验一下这块的掌握情况:
- 在CPU中,哪个寄存器负责存放下一条将要执行的指令的地址?
- 假设一条指令的执行过程分为 4 个阶段,每个阶段耗时都是 2ns。那么流水线的周期是多少?如果连续执行 10 条指令,总共需要多少时间?
- 硬布线控制器和微程序控制器相比,谁的执行速度更快?
第五部分答案:
1.PC(程序计数器)
2.8ns;104ns
3.硬布线控制器
🧱 最后一块:第六块 总线与 I/O 系统
这块相对轻松,主要讲计算机的各个部件是怎么"连"在一起,以及怎么和外部世界"沟通"的。
1. 总线 (Bus)
总线就是计算机内部的"高速公路"。所有部件(CPU、内存、外设)都挂在总线上。
- 总线仲裁 :当多个设备同时想用总线时,谁先谁后?
- 链式查询:排队,离得近的优先。缺点是容易坏(一个坏了后面全断)。
- 计数器定时查询:可以动态改变优先级。
- 独立请求:每个设备都有专属的"呼叫按钮"。速度最快,但线太多。
2. I/O 控制方式(重点!)
CPU 和外设(比如键盘、硬盘)交换数据,有四种方式,效率从低到高:
- 程序查询方式:CPU 像个傻子一样,不停地问外设:"好了没?好了没?"(CPU 被严重浪费,效率最低)。
- 程序中断方式 :外设准备好了,主动给 CPU 发个信号(打个响指),CPU 停下手里的工作去处理。适合键盘、鼠标这种低速、随机的设备。
- DMA(直接存储器访问) :请了一个"搬运工"(DMA控制器)。数据直接在内存和外设之间搬,不需要经过CPU 。只有在搬完一批数据后,才通知一下CPU。适合硬盘这种高速、大批量传输。
- 通道方式:更高级的搬运工,相当于一个小型的专用CPU,能自己执行简单的指令来管理I/O。
有些教材会说是5种控制方式:按效率从低到高排列如下:
- 程序直接控制方式(程序查询方式):CPU 不断循环测试外设状态,效率最低,浪费大量 CPU 时间。
- 程序中断方式:外设准备好后主动打断 CPU 请求服务,适合低速设备,但每次传数据都要经过 CPU,仍消耗较多 CPU 时间。
- DMA(直接内存存取)方式:由专门的 DMA 控制器接管,数据直接在内存和外设间批量传输,只在开始和结束时才需要 CPU 干预。
- 通道控制方式:通道相当于一个功能简单的专用处理机,能独立执行通道程序来统一管理 I/O 操作,使 I/O 操作与 CPU 完全并行工作。
- 外围处理机(I/O处理机)方式:这是最高级的控制方式。外围处理机的结构更接近于一般的通用处理机,它不仅具有通道的所有功能,还能完成码制变换、差错检验与纠正、文件记录格式变换等更复杂的操作。
I/O是什么
I/O 是英文 Input/Output 的缩写,中文就是**"输入/输出"**。
通俗地说,I/O 就是计算机与外界(比如人类用户、其他计算机系统或网络)进行数据通信的过程。计算机的处理操作通常是:先从外部读取数据(输入),在内部处理数据,再向外部输出结果(输出)。
- 输入 (Input):比如你用键盘打字、用鼠标点击、用麦克风说话,这些设备把数据"送进"计算机。
- 输出 (Output):比如显示器显示画面、音响播放声音、打印机打印文件,这些设备把计算机处理好的结果"展示"给你。
所以,I/O 系统就是负责管理这些"进进出出"的数据的。
📝 最后的自测
- 在 I/O 控制方式中,数据直接在内存和外设之间传送,不经过 CPU 的是哪种方式?
- 在总线仲裁中,哪种方式响应速度最快,但需要的控制线最多?
- 程序中断方式通常适合连接什么类型的外设?(高速还是低速?)
第六部分答案:
1.DMA(直接存储器访问)
2.独立请求
3.适合低速随机的设备,比如鼠标和键盘i/o控制方式不是有五种吗,我课本上说的,还有一个I/O处理机方式,而且我不知道I/O是什么
计算题
- 存储系统扩展与映射 (分值高,步骤多,最容易丢分)
- 指令流水线 (公式固定,但陷阱多)
- 数据的表示与运算 (原码一位乘、补码加减、浮点数)
🧮 模块一:存储系统计算题 (重中之重)
这类题通常有两种考法:
- 存储器扩展:用小的RAM芯片拼成大的存储器,问需要多少芯片,怎么连线。
- Cache映射:计算主存地址如何划分(标记、组号、块内地址),以及Cache命中率。
考点 1:存储器扩展 (芯片数量计算)
核心逻辑:
- 位扩展 (增加数据位宽):芯片并联。所需芯片数 = 目标位宽 / 芯片位宽。
- 字扩展 (增加地址容量):芯片串联。所需组数 = 目标容量 / 芯片容量。
- 总芯片数 = 位扩展数 × 字扩展数。
真题演练 (来自你的模拟卷):
题目 :某机地址码20位,按字节寻址。使用
4K × 4位的RAM芯片,组成32K × 8位的模块板。问每个模块板需要多少片RAM芯片?
解题四步法:
- 看目标 :我们要造一个
32K × 8位的存储器。 - 看原料 :手里只有
4K × 4位的芯片。 - 算位扩展 :目标是8位,原料是4位。
8 ÷ 4 = 2。说明每次读写需要 2片 芯片并联,才能凑够8位数据。 - 算字扩展 :目标是32K容量,原料是4K容量。
32K ÷ 4K = 8。说明需要 8组 这样的并联结构。 - 算总数 :
2 (位扩展) × 8 (字扩展) = 16片。
答案:16片。
考点 2:Cache 映射与地址划分 (难点)
这是最绕的地方,但只要记住**"切蛋糕"** 原理就不怕。
一个主存地址(比如32位)会被切成三段:[ 标记(Tag) | 组号/行号(Index) | 块内地址(Offset) ]
解题口诀:
- 先切右边(块内地址) :看块大小。如果是32字节,
2^5 = 32,所以右边切 5位。 - 再切中间(组号) :看Cache有多少组。如果是128组,
2^7 = 128,所以中间切 7位。 - 剩下左边(标记):总位数 - 组号位 - 块内位 = 标记位。
真题演练 (来自模拟卷):
题目 :主存容量 256K字,Cache容量 2K字,块大小 16字。采用直接映射 。问主存地址多少位?Cache地址多少位?主存第
i块映射到Cache哪一块?
解题步骤:
- 算主存地址位数 :
- 主存容量
256K = 2^8 × 2^10 = 2^18。 - 所以主存地址需要 18位。
- 主存容量
- 算Cache地址位数 :
- Cache容量
2K = 2^11。 - 所以Cache地址需要 11位。
- Cache容量
- 算映射关系 :
- 直接映射公式:
Cache行号 = 主存块号 % Cache总行数。 - 先算Cache有多少行(块):
Cache容量 ÷ 块大小 = 2K ÷ 16 = 2048 ÷ 16 = 128行。 - 所以映射公式为:
i mod 128(或i % 128)。
- 直接映射公式:
📝 现在轮到你了 (实战演练)
请根据你上传的文档中 卷2 的计算题第21题 ,尝试解答下面这个问题。这道题考了组相联映射,比直接映射稍微复杂一点点,是考试的拉分项。
【题目】
某计算机的 Cache 共有 16块 ,采用 2路组相联映射 方式(即每组2块)。每个主存块大小为 32字节 ,按字节编址。
问题 :主存 129号单元 所在的主存块,应装入到的 Cache组号 是多少?
提示步骤:
- 算出主存129号单元属于主存的第几块?(
129 ÷ 32取整) - 算出Cache一共有多少组?(总块数16 ÷ 路数2)
- 套用组相联映射公式:
组号 = 主存块号 % Cache组数。
"映射关系"这个概念确实很抽象,它是整个存储系统里最难"开窍"的地方。别担心,我们不讲公式,用一个生活中的例子来类比,保证你一听就懂。
🏠 把 Cache 想象成一个"快递柜"
你可以把 Cache 想象成一个小区的 快递柜 ,它有固定数量的格子,用来临时存放你的快递(数据)。
而 主存 就像是整个城市的 所有地址,范围非常大。
现在,快递员(CPU)要从城市里取一个快递,放到快递柜里,方便你随时来取。他该怎么决定把这个快递放进哪个格子呢?这就是"映射"要解决的问题。
1. 直接映射:按"门牌号"取余数
规则 :快递柜有 128 个格子(编号 0-127)。规则很简单:用你的"门牌号"除以 128,余数是几,就放进几号格子。
- 主存块号 = 你的"门牌号"
- Cache总行数 = 快递柜的"总格子数" (128个)
- Cache行号 = 快递要放的"格子号"
举个例子:
- 如果你住在 130号 门牌。
130 ÷ 128 = 1 ... 余 2。所以你的快递必须放进 2号 格子。 - 如果你住在 258号 门牌。
258 ÷ 128 = 2 ... 余 2。你的快递也必须放进 2号 格子。
你看懂了吗?
这个规则 (主存块号 % Cache总行数) 的本质就是:不管你的门牌号多大,我都通过"取余数"这个动作,把它强行对应到快递柜里一个固定的、有限的格子上。
所以,i mod 128 的意思就是:主存里的第 i 块数据,必须被放到 Cache 的第 (i除以128的余数) 行里。 这是一个硬性规定。
2. 组相联映射:先选"区",再选"格"
规则:现在快递柜升级了。它有 16 个格子,但被分成了 8 个"区",每个区有 2 个格子(这就是"2路",1路=1格)。
规则变成了两步走:
- 第一步(选区):还是用你的"门牌号"除以"总区数"(8),余数是几,就去几号区。
- 第二步(选格):进了指定的区之后,2个格子你随便挑一个放。
对应到你的题目:
- Cache总块数 = 16个格子
- 路数 = 2路 (每组2块)
- Cache组数 =
16 ÷ 2 = 8个区
所以,映射规则是:组号 = 主存块号 % Cache组数 。
先算出应该去哪个"区"(组),进了区之后,随便放。
📝 现在,我们用这个思路来做那道题
【题目回顾】
Cache共16块,2路组相联(每组2块)。主存块大小32字节。问:主存129号单元所在的主存块,应装入到的Cache组号是多少?
解题三步走:
-
第一步:找到"门牌号"(主存块号)
- 我们要找的是"129号单元"。一个块能装32个单元(字节)。
129 ÷ 32 = 4.03125。- 这说明129号单元在第4块和第5块之间。在计算机里,我们从0开始数,所以它属于 第4号主存块。(0号块是0-31,1号块是32-63... 4号块是128-159)。
- 所以,主存块号 = 4。这就是我们的"门牌号"。
-
第二步:算出有多少个"区"(Cache组数)
- 快递柜总共16个格子,每2个格子为1个区。
16 ÷ 2 = 8。- 所以,Cache总共有 8 个组。
-
第三步:套用规则,找到"区号"(Cache组号)
- 规则是:
组号 = 主存块号 % Cache组数 - 代入数字:
组号 = 4 % 8 4 ÷ 8 = 0 ... 余 4- 所以,Cache组号 = 4。
- 规则是:
最终答案:应装入到的 Cache 组号是 4。
现在是不是清晰多了?核心就是理解"取余数"这个动作,它就像一个哈希函数,把一个很大的地址空间(城市)压缩映射到一个很小的Cache空间(快递柜)里。
按照"存储器扩展"和"Cache映射"两大类,帮你彻底梳理一遍。
🧱 存储器扩展类 (芯片数量计算)
这类题的核心就是算清楚需要多少个小芯片才能拼成一个大存储器。
题目 1:模拟卷 1 - 五、计算题
这道题是最完整、最复杂的存储器扩展题,它把"字扩展"、"位扩展"和"模块板"的概念全结合在了一起。
- 已知条件 :
- 地址码:20位
- 寻址方式:按字节寻址
- RAM芯片规格:
4K × 4位 - 模块板规格:
32K × 8位
- 问题 :
- 该机所允许的最大主存空间是多少?
- 若每个模块板为
32K × 8位,共需几个模块板? - 每个模块板内共有几片 RAM 芯片?
- 共有多少片 RAM?
解题思路提示:
- 最大主存空间 :20位地址线能寻址
2^20个单元,按字节寻址,所以是2^20字节,即 1MB。 - 模块板数量:总容量(1MB) ÷ 单板容量(32KB)。注意单位换算,1MB = 1024KB。
- 单板芯片数 :这是核心!用目标规格(
32K × 8位)除以原料规格(4K × 4位)。- 位扩展:
8位 ÷ 4位 = 2(需要2片并联) - 字扩展:
32K ÷ 4K = 8(需要8组串联) - 总数:
2 × 8 = 16片。
- 位扩展:
- 总芯片数:模块板数量 × 单板芯片数。
题目 2:复习汇总- 四、计算题 20
这道题更贴近实际设计,要求你根据CPU的引脚和给定的芯片,设计一个存储系统。
- 已知条件 :
- CPU:16根地址线,8根数据线
- 目标:设计一个
8KB的 RAM 和4KB的 ROM 系统 - 可选芯片:
RAM: 1K×4位, 4K×8位, 8K×8位;ROM: 2K×8位, 4K×8位, 8K×8位
- 问题 :
- 选择合适的芯片,并画出逻辑框图(考试时画出连接示意图即可)。
解题思路提示:
- 选RAM芯片 :目标是
8KB(即8K × 8位)。直接选用8K × 8位的芯片(如6264)最省事,只需要 1片。 - 选ROM芯片 :目标是
4KB(即4K × 8位)。直接选用4K × 8位的芯片(如2732)最省事,只需要 1片。 - 地址分配 :这是难点。你需要为RAM和ROM分配不重叠的地址空间。例如,ROM放在
0000H开始,RAM放在ROM后面。 - 逻辑框图:画出CPU的地址线、数据线、读写控制线如何连接到RAM和ROM芯片上,并说明如何用地址线的高位通过译码器来选择是访问RAM还是ROM。
🗺️ Cache 映射类 (地址划分与命中率)
这类题的核心是理解主存地址是如何被"切分"的,以及如何计算Cache的性能。
题目 3:模拟卷 2 - 五、计算题
这道题是直接映射的教科书级范例,步骤非常清晰。
- 已知条件 :
- Cache容量:
2K 字 - 块大小:
16 字 - 主存容量:
256K 字
- Cache容量:
- 问题 :
- Cache可容纳的块数?
- 主存的块数?
- 主存地址与Cache地址的位数?
- 直接映射下,主存第
i块映射到Cache的块号?
解题思路提示:
- Cache块数 :
Cache容量 ÷ 块大小=2K ÷ 16= 128块。 - 主存块数 :
主存容量 ÷ 块大小=256K ÷ 16= 16K块。 - 地址位数 :
- 主存地址:
256K = 2^18,所以需要 18位。 - Cache地址:
2K = 2^11,所以需要 11位。
- 主存地址:
- 映射关系 :直接映射公式
i % Cache总块数,即i % 128。
题目 4:复习汇总 - 四、计算题 21
这道题是组相联映射的经典考法,和你刚才搞懂的那道题几乎一模一样,是绝佳的巩固练习!
- 已知条件 :
- Cache:共16块,2路组相联
- 主存块大小:32字节
- 按字节编址
- 问题 :
- 主存 129号单元 所在的主存块,应装入到的 Cache组号 是多少?
解题思路提示:
- 找主存块号 :
129 ÷ 32(块大小) = 4...余1。所以是 第4号主存块。 - 找Cache组数 :
16块 (总块数) ÷ 2 (路数)= 8组。 - 算组号 :
主存块号 % Cache组数=4 % 8= 4。
题目 5:复习汇总 - 四、计算题 22
这道题是组相联映射 + 命中率计算的综合题,难度升级,是拉分的关键!
- 已知条件 :
- 主存容量:
16MB - Cache容量:
16KB - 块大小:8个字,每字32位 (即
8 × 4 = 32字节) - 映射方式:四路组相联
- 访问序列:CPU依次读
0, 1, ..., 99号单元,重复8次。
- 主存容量:
- 问题 :
- 画出主存地址字段中各段的位数(标记、组号、块内地址)。
- 命中率是多少?
解题思路提示:
- 地址划分 :
- 块内地址 :块大小32字节 =
2^5,所以是 5位。 - 组号 :Cache总块数 =
16KB ÷ 32B = 512块。四路组相联,所以组数 =512 ÷ 4 = 128组 = 2^7。所以组号是 7位。 - 标记(Tag) :主存
16MB = 2^24字节,地址共24位。标记位 =24 - 7 - 5= 12位。
- 块内地址 :块大小32字节 =
- 命中率计算 :
- 总访问次数 :
100个单元 × 8次= 800次。 - 不命中次数 :第一次循环时,Cache是空的,访问的每个新块都会不命中。100个单元,每块32字节(32个单元),需要
100 ÷ 32向上取整 = 13个主存块。所以第一次循环不命中13次。 - 后续访问:从第2次到第8次循环,数据都在Cache里,全部命中。
- 命中率 :
(总次数 - 不命中次数) ÷ 总次数=(800 - 13) ÷ 800= 98.375%。
- 总访问次数 :
把这5道题的思路都理清楚,存储系统的计算题你就可以高枕无忧了!
🧮 模块二:指令流水线 (公式固定,陷阱极多)
这类题的公式很简单(比如 T=(k+n−1)×Δt,但考试最喜欢在**"执行时间怎么算"** 和**"是否有停顿"**上挖坑。
📍 题库定位:
-
《复习汇总》 - 四、计算题 23
- 考点:流水线执行时间的计算。
- 陷阱预警 :注意看题目是否说明了"取指、译码、执行"各阶段的时间是否相等。如果不等,流水线的周期 Δt必须取最长的那一段的时间。另外,要看有没有"数据相关"或"控制相关"导致的流水线停顿(气泡)。
-
《模拟卷》- 五、计算题 (流水线相关)
- 考点:吞吐率 (Throughput) 和 加速比 (Speedup) 的计算。
- 陷阱预警:吞吐率的公式是 n/T总 ,加速比是 T串行/T流水线 。计算时一定要看清题目问的是"理论最大吞吐率"还是"实际吞吐率"。
这部分内容在考试中属于"公式简单、陷阱极多"的类型。很多同学习惯背公式 。
T=(k+n−1)×Δt
当流水线各阶段时间不相等时,绝对不能直接用 T=(k+n−1)×Δt 这个公式。
必须使用分步法:T总=T第一条完整指令+(n−1)×Δt
但题目稍微变个花样(比如各阶段时间不等、或者问的是吞吐率),就容易丢分。
为了帮你彻底搞懂,我将从核心概念与公式 、三大常见陷阱 以及经典例题实战三个方面进行拆解。
核心概念与公式
做流水线题,必须分清两个状态:串行执行 和流水线执行。
基础参数定义
- n:指令条数。
- k:流水线的级数(段数),例如取指、译码、执行、访存、写回共5级。
- Δt :流水线周期。注意:这是所有阶段中耗时最长的那个阶段的时间。
关键公式
-
一条指令的执行时间
- 如果各级时间相等: T1=k×Δt
- 如果各级时间不等: T1=∑(各阶段时间) (即所有阶段时间之和)
-
nn 条指令的流水线总时间 ( TpipeTpipe )
这是考试最常考的公式:
Tpipe=T第一条+(n−1)×Δt
> 通俗理解:第一条指令需要把整个管道填满(耗时最长),之后每过一个周期 ΔtΔt ,就会有一条新指令完成。
- 加速比 ( SpSp )
Sp=TserialTpipe=n×T1Tpipe
- 吞吐率 ( TPTP )
TP=nTpipe
三大常见陷阱
请务必警惕以下三种情况,它们是出题人最爱挖坑的地方:
陷阱一:各阶段时间不相等
错误做法 :直接把所有时间加起来除以级数求平均值。
正确做法 :木桶效应 。流水线的周期 ΔtΔt 取决于最慢的那个阶段。
例子:取指 2ns,译码 1ns,执行 3ns。
- 此时 Δt=3ns (不是 2ns,也不是 (2+1+3)/3。
- 计算总时间时,第一条指令依然耗时 2+1+3=6ns,但后续每条指令只间隔 3ns3ns 。
陷阱二:理论 vs 实际
- 理论公式假设流水线是完美流动的,没有停顿。
- 实际情况 中,如果遇到数据相关 (下一条指令要用上一条的结果)或控制相关 (遇到跳转指令),流水线会发生阻塞(Stall) 或气泡(Bubble)。
- 应对策略 :如果题目给出了时空图(甘特图),不要盲目套公式,要老老实实地数格子的总数。
陷阱三:单位换算
- 题目给出的时间可能是 ns(纳秒),而问题可能问的是 MHz(兆赫兹)。
- 换算关系: f=1Tf=T1 。若 Δt=2ns,则频率 f=12×10−9=500MHz
经典例题实战
我们来看一道典型的计算题,涵盖上述考点。
【题目】
某计算机指令流水线分为 4 段:取指 (IF)、译码 (ID)、执行 (EX)、写回 (WB)。
各段所需时间分别为:IF=3ns, ID=2ns, EX=4ns, WB=1ns。
现有 100 条指令连续输入该流水线。
请计算:
- 该流水线的时钟周期 ΔtΔt 是多少?
- 执行这 100 条指令所需的总时间是多少?
- 该流水线的实际吞吐率是多少?
- 相比于非流水线(串行)方式,加速比是多少?
【解析】
第一步:确定周期
观察各段时间:3, 2, 4, 1。
最大值是 4ns。
所以,Δt=4ns
第二步:计算总时间
- 第一条指令完整执行时间(建立时间): Tfirst=3+2+4+1=10ns
- 剩余 99 条指令,每隔一个周期产出一条。
- 总时间 Ttotal=Tfirst+(n−1)×Δt
Ttotal=10+(100−1)×4=10+396=406ns
第三步:计算吞吐率
TP=n➗Ttotal=100➗406ns≈0.246 条/ns
(注:也可以写成 2.46×108 条/s)
第四步:计算加速比
- 串行执行时间 Tserial=n×Tfirst=100×10=1000ns
- 加速比 Sp=Tserial➗Ttotal=1000➗406≈2.46
💡 总结建议
针对你手头的题库,做题时请按以下步骤检查:
- 找最大值:先圈出各阶段时间,确定 ΔtΔt 。
- 算首条:算出第一条指令的绝对耗时(所有阶段相加)。
- 套公式:使用 T=T首条+(n−1)Δt
- 看图表:如果题目给了具体的时空图,优先数格子,因为图中可能隐含了"停顿"。
🧮 模块三:数据的表示与运算 (步骤繁琐,极易粗心)
这部分是真正的"体力活",需要一步步画图或列表,原码一位乘的加法、移位,以及浮点数的对阶、尾数求和、规格化,每一步都容易算错。
📍 题库定位:
-
《复习汇总》- 四、计算题 19
- 考点 :原码一位乘法。
- 陷阱预警 :这是最容易算错的题!一定要画好表格,注意符号位单独处理 (异或),数值位相乘时,部分积的右移操作不能漏掉,且移位时最高位补0。
-
《复习汇总》- 四、计算题 18
- 考点 :补码加减法 与 溢出判断。
- 陷阱预警:注意题目给的是原码还是补码,如果是原码,第一步必须先转成补码!减法要变加法( X−Y补=X补+−Y补X−Y补=X补+−Y补 )。最后一定要判断是否溢出(双符号位法:01为正溢,10为负溢)。
-
《复习汇总》 - 四、计算题 24 (重点拉分题)
- 考点 :浮点数加减运算。
- 陷阱预警:步骤最多,分为五步:① 对阶(小阶向大阶看齐,尾数右移);② 尾数求和;③ 规格化(左规或右规);④ 舍入(0舍1入法);⑤ 判溢出。只要中间一步算错,后面全完。
具体看本文配套的文档:(以下是部分文档内容)


🧮 模块四(补充):关于串行通信接口的计算
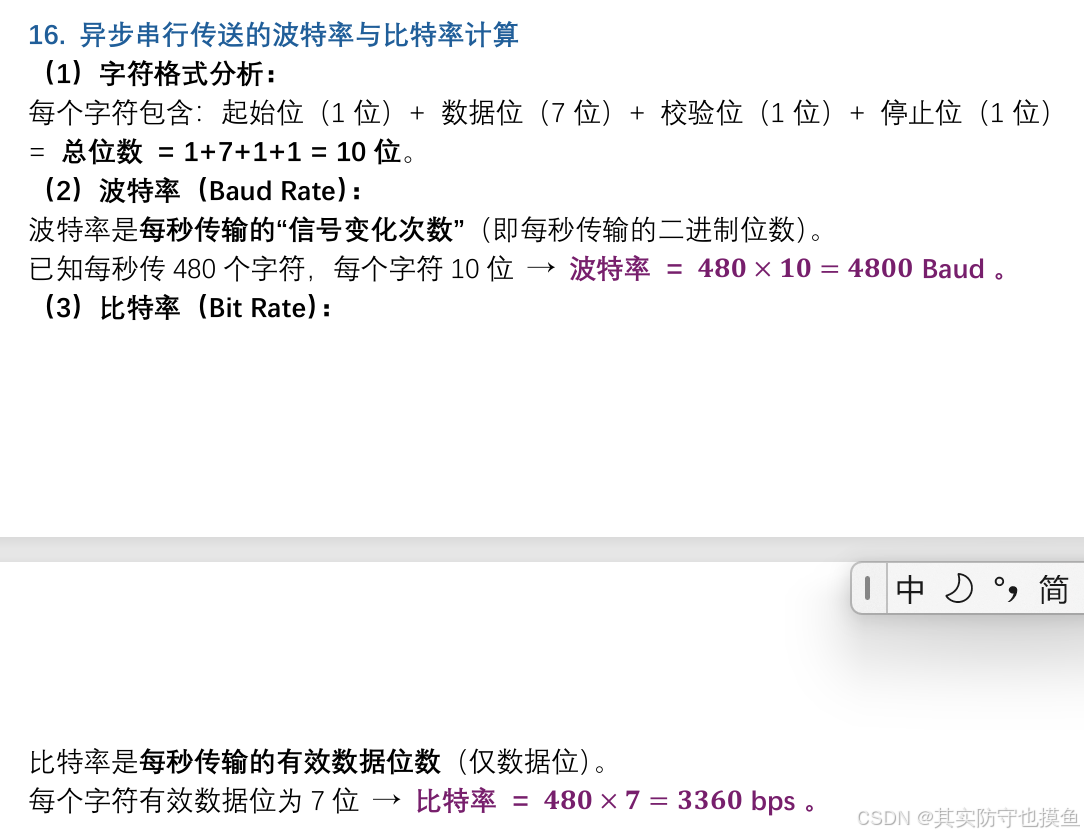
为了让你复习更有条理,我把这个知识点的核心逻辑给你拆解一下,防止混淆:
1. 为什么是"总线与I/O"?
- 指令流水线是在CPU内部算时间的。
- 数据表示是在ALU里算数值的。
- 而这张图 讲的是CPU怎么通过一根线(串口)跟外面的设备(比如鼠标、老式调制解调器)说话。这是典型的I/O接口技术。
2. 这个题型的"坑"在哪里?
这类题通常就考两个概念的区别,一定要分清题目问的是哪个:
波特率 (Baud Rate) ------ 也就是"线路传输速度"
- 定义:每秒在物理线路上实际传输了多少个二进制位(0或1)。
- 计算 :要把所有"废话"都算进去。
- 公式 :
波特率 = 每秒字符数 × (起始位 + 数据位 + 校验位 + 停止位) - 对应图中:480×(1+7+1+1)=4800 Baud480×(1+7+1+1)=4800 Baud 。
- 理解:不管这10位里有没有用,只要在线上跑了,就算波特率。
- 公式 :
比特率 (Bit Rate) / 有效数据传输率 ------ 也就是"干货传输速度"
- 定义 :每秒真正传输了多少个有效数据位。
- 计算 :只算数据位,把起始位、停止位这些"包装纸"扔掉。
- 公式 :
比特率 = 每秒字符数 × 数据位 - 对应图中:480×7=3360 bps480×7=3360 bps 。
- 理解:这就是你实际能拿到的有用信息量。
- 公式 :
总结建议
既然你正在刷题库,看到这个知识点时,只需要记住一个原则:
- 看到 "波特率" →→ 全加(起+数+校+停)。
- 看到 "有效数据率" 或 "比特率" →→ 只乘数据位。
波特率比特率,前者整体除,后者有效除

期末好运!