1. 引言
在具身智能领域,视觉-语言-行动(Vision-Language-Action, VLA)模型 正在成为机器人操作任务的主流范式。这类模型通过统一的框架将视觉感知、语言理解和动作生成整合在一起,展现出强大的跨模态泛化能力。然而,当我们将目光从实验室的简单任务转向真实世界的复杂场景时,现有VLA模型开始暴露出三个根本性的局限。
第一个挑战是长程任务的规划能力不足 。真实世界的机器人任务往往需要完成多个连续的子任务,例如"准备早餐"需要依次完成打开冰箱、取出食材、关闭冰箱、打开微波炉、放入食物、设置时间等一系列操作。现有的VLA模型大多采用单一的动作解码器,缺乏有效的层次化规划机制,难以在这种长序列任务中保持稳定的执行表现。这种缺陷在LIBERO-LONG等长程任务基准测试中表现得尤为明显,成功率往往显著低于短程任务。
第二个挑战是技能干扰问题。当前的VLA模型通常将所有技能的训练数据混合在一起,使用同一组参数来学习不同的操作技能。这种做法导致不同技能之间共享相同的参数空间,容易产生相互干扰。例如,在学习"抓取"和"旋转"两种技能时,模型可能会在执行抓取动作时错误地激活旋转相关的参数,导致动作执行不精确。这种干扰在多任务混合训练场景中尤为严重,直接影响模型在各个任务上的整体性能表现。
第三个挑战是持续学习中的灾难性遗忘 。在实际应用中,机器人需要不断学习新的操作技能来适应新的任务需求。然而,现有的VLA模型在学习新技能时往往需要对整个模型进行重新训练,这不仅计算成本高昂,而且容易导致模型遗忘之前已经掌握的技能。这种现象在神经网络领域被称为 "灾难性遗忘"(Catastrophic Forgetting)。例如,当模型学习"拧瓶盖"这个新技能时,可能会显著降低在"抓取物体"这个旧技能上的表现。这种问题严重制约了VLA模型在真实世界中的可扩展性和实用性。
针对这些挑战,来自中山大学、鹏城实验室和引望智能 的研究团队提出了AtomicVLA框架 。这个框架的核心思想是将复杂的机器人任务分解为可复用的 "原子技能" ,并通过 **技能引导的混合专家架构(Skill-Guided Mixture-of-Experts, SG-MoE)**来构建一个可扩展的技能库。这种设计不仅能够有效解决长程任务规划问题,还能显著减少技能间的干扰,并支持高效的持续学习。对应的文章为《AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots》,然后对应代码在Github上
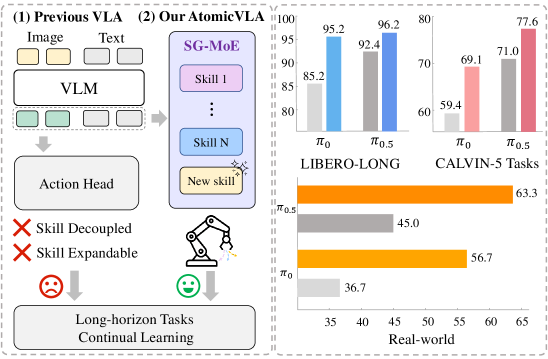
图1: AtomicVLA框架概览。与传统VLA模型使用单一动作头不同,AtomicVLA采用SG-MoE架构构建可扩展的技能专家库,统一任务规划和动作执行。
2. 统一规划与执行的架构设计
AtomicVLA的第一个核心创新在于提出了一个统一的规划与执行框架 。传统的机器人系统通常采用两阶段架构:首先使用高层规划器(如预训练的视觉-语言模型)生成子任务指令,然后使用低层控制器将这些指令转换为具体的动作序列。这种模块化的设计虽然在概念上清晰,但存在一个根本性的问题------规划器和控制器之间缺乏相互感知,导致决策不一致。
具体而言,规划器在生成子任务指令时无法感知控制器的实际执行能力,可能会生成控制器难以完成的指令 。同时,控制器在执行动作时也无法理解规划器的整体意图,可能会做出与长期目标不一致的局部决策。更严重的是,在实际应用中,系统延迟可能导致规划器生成的指令与当前环境状态不匹配,从而产生过时或不相关的指令。
AtomicVLA通过引入自适应的 "思考-行动"(Think-Act)机制来解决这个问题。模型在每个时间步都会自主决定当前应该进入"思考模式"还是"行动模式"。这种决策通过预测特殊的输出标记来实现:
python
# AtomicVLA 的自适应 Think-Act 推理流程(基于 pi0_atomic.py 实现)
import jax
import jax.numpy as jnp
from openpi.models import tokenizer as _tokenizer
def inference_pipeline(model, rng, observation, temperature=0.0, num_steps=10):
"""
统一的推理流程:prefill → 模式判断 → reason/act
Args:
model: Pi0Atomic 模型实例
rng: JAX 随机数生成器
observation: AtomicObservation 包含图像、状态、指令等
temperature: 解码温度(0.0 表示贪婪解码)
num_steps: 动作去噪步数
Returns:
dict: 包含模式、推理文本或动作的结果
"""
# 第一步:Prefill - 处理图像和文本前缀
observation, kv_cache, token, eop_logit, prefix_mask, prefix_positions, has_boa = \
model.prefill(rng, observation, temprature=temperature)
# 第二步:模式判断 - 检查是否为 BEGIN_OF_ACTION 标记
if jnp.any(has_boa):
# 行动模式:基于原子技能生成具体动作
rng, act_rng = jax.random.split(rng)
actions = model.act(
act_rng,
observation,
kv_cache,
prefix_mask,
prefix_positions,
num_steps=num_steps
)
return {"mode": "act", "actions": actions}
else:
# 思考模式:生成推理文本(任务链规划和原子技能抽象)
rng, reason_rng = jax.random.split(rng)
reasoning_tokens = model.reason(
reason_rng,
eop_logit,
kv_cache,
prefix_mask,
prefix_positions,
temprature=temperature,
max_decoding_steps=256
)
return {"mode": "think", "reasoning_tokens": reasoning_tokens}在思考模式下,模型会生成三个关键输出:任务链规划(Task-chain Plans) 、当前执行进度(Current Progress)和原子技能抽象(Atomic Skill Abstraction)。任务链规划描述了完成整个任务需要执行的子任务序列,例如"打开抽屉→抓取物体→关闭抽屉"。当前执行进度用于追踪任务的完成状态,帮助模型判断何时应该切换到下一个子任务。原子技能抽象则是对当前需要执行的具体操作的高层描述,例如"grasp"(抓取)、"rotate"(旋转)或"push"(推动)。
在行动模式下,模型会基于最近一次思考得到的原子技能抽象来生成具体的动作序列。这种设计确保了高层规划和低层执行之间的紧密耦合,避免了传统两阶段架构中的信息断层问题。更重要的是,模型可以根据环境的实时反馈动态调整模式切换的时机,在任务初始化或子任务切换时进入思考模式,在稳定执行阶段保持行动模式,从而实现高效的计算资源利用。
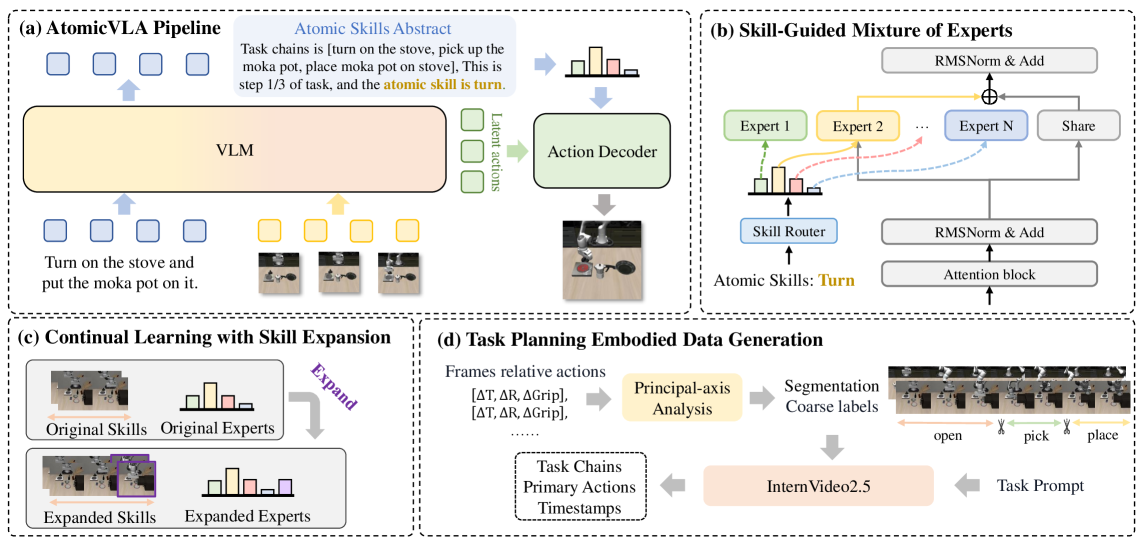
图2: AtomicVLA的完整架构。(a)统一的规划与执行流程;(b)技能引导的混合专家架构;©通过技能扩展实现持续学习;(d)基于主轴分析的任务规划数据生成。
3.技能引导的混合专家架构(SG-MoE)
AtomicVLA的第二个核心创新是提出了技能引导的混合专家架构(Skill-Guided Mixture-of-Experts, SG-MoE)。这个架构的设计灵感来源于一个简单但深刻的观察:人类在学习复杂技能时,往往会将其分解为多个基础的"原子技能",然后通过组合这些原子技能来完成复杂任务。例如,学习弹钢琴时,我们首先掌握单个音符的弹奏,然后学习音阶,最后才能演奏完整的乐曲。
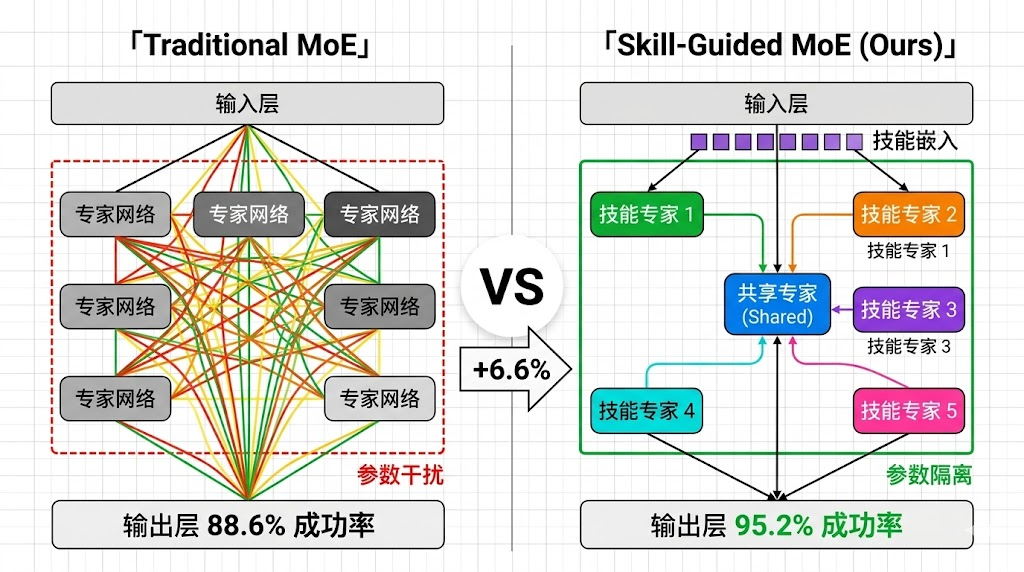
SG-MoE架构包含三个核心组件:技能路由器(Skill Router) 、共享专家(Shared Expert)和多个原子技能专家(Atomic Skill Experts)。每个原子技能专家专注于掌握一种特定的基础操作技能,例如"抓取"、"旋转"、"推动"等。共享专家则保留了预训练VLA模型的通用动作生成能力,确保模型在面对新场景时仍具有基本的泛化能力。
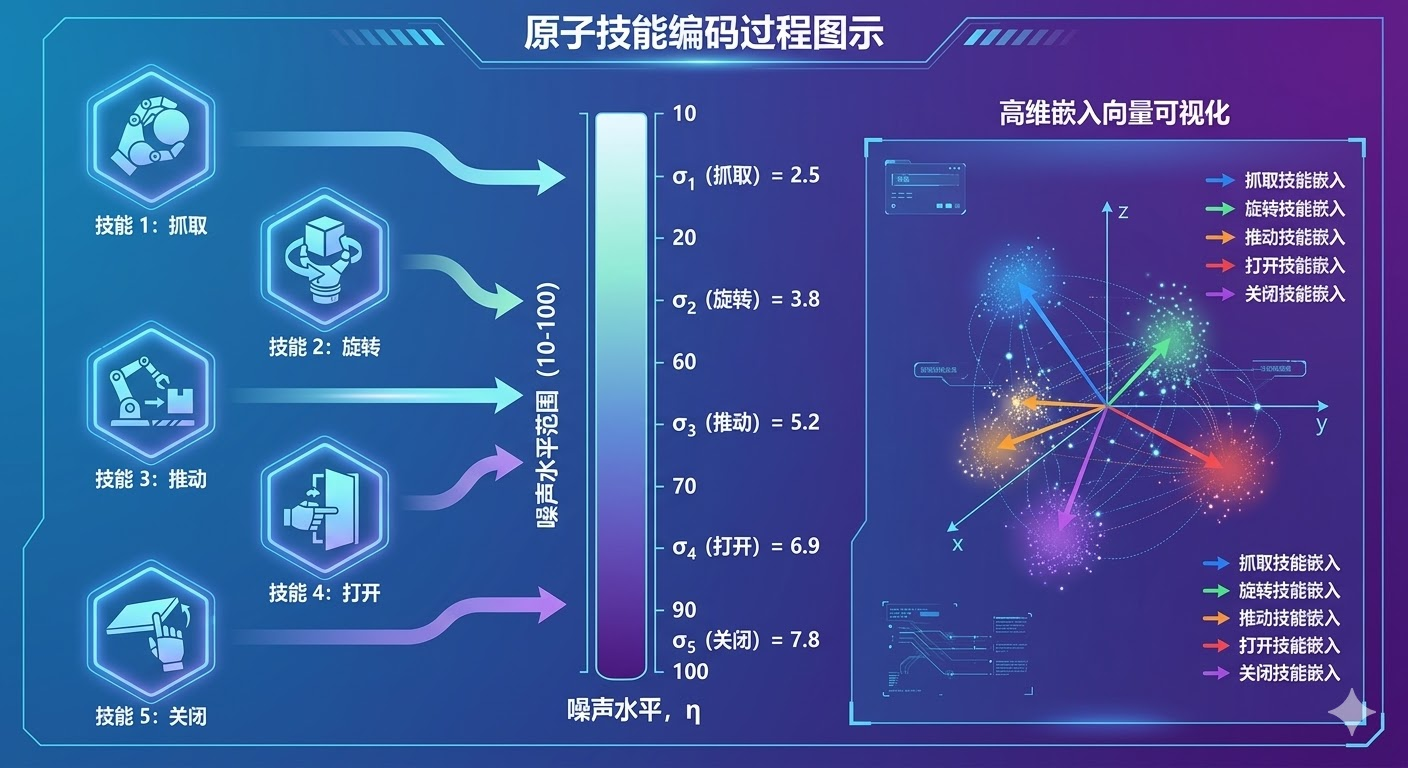
原子技能的编码方式借鉴了扩散模型中的噪声调度机制。每个原子技能被映射到一个标量噪声水平σ∈0,100,然后通过嵌入函数转换为高维向量:
python
# AtomicVLA 原子技能编码器(基于 pi0_atomic.py 实现)
import jax.numpy as jnp
import einops
import flax.nnx as nnx
class Pi0Atomic:
"""Pi0Atomic 模型中的原子技能编码实现"""
def __init__(self, config, rngs):
# 初始化技能嵌入矩阵:每个专家对应一个噪声水平 σ ∈ [10, 100]
action_expert_config = config.action_expert_variant
self.num_local_experts = action_expert_config.num_local_experts
self.action_horizon = config.action_horizon
# 创建线性映射的噪声水平:从 10.0 到 100.0
scales = jnp.linspace(10.0, 100.0, self.num_local_experts)
# 构建对角矩阵作为技能嵌入基础
base = jnp.eye(self.num_local_experts) * scales[:, None]
# 如果嵌入维度大于专家数量,进行零填充
if action_expert_config.width > self.num_local_experts:
base = jnp.pad(
base,
((0, 0), (0, action_expert_config.width - self.num_local_experts))
)
# 存储为不可训练的参数
self.sigma_emb = nnx.Variable(base, trainable=False)
def embed_atomic_skill(self, obs):
"""
将原子技能索引映射为高维嵌入向量
Args:
obs: AtomicObservation,包含 atomic_token (batch,) 技能索引
Returns:
atomic_embed: (batch, action_horizon, embedding_dim) 技能嵌入
"""
# 根据技能索引选择对应的嵌入向量
atomic_embed_mid = self.sigma_emb[obs.atomic_token.astype(jnp.int32)]
# 在时间维度上重复,匹配动作序列长度
atomic_embed = einops.repeat(
atomic_embed_mid,
f"b emb -> b {self.action_horizon} emb"
)
return atomic_embed这种编码方式的优势在于为不同的原子技能提供了结构化的表示空间。相似的技能会被映射到相近的嵌入向量,这有助于模型学习技能之间的语义关系。同时,这种连续的嵌入空间也为未来扩展新技能提供了灵活性。
技能路由器的核心功能是根据原子技能嵌入动态选择合适的专家网络。与传统的MoE架构不同,SG-MoE采用稀疏激活策略,每次只激活得分最高的一个技能专家。这种设计确保了每个原子技能都由专门的专家网络处理,避免了不同技能之间的参数干扰:
python
# AtomicVLA 技能引导路由器和 SG-MoE(基于 gemmoe.py 实现)
import jax
import jax.numpy as jnp
import flax.linen as nn
class Router(nn.Module):
"""原子技能路由器,使用缩放单位矩阵初始化"""
hidden_dim: int
num_experts: int
kernel_scale: float = 1.0
def setup(self):
scale = self.kernel_scale
def kernel_init(key, shape, dtype=jnp.float32):
"""使用缩放的单位矩阵初始化路由权重"""
if shape[0] < self.num_experts:
raise ValueError("hidden_dim must be >= num_experts")
# 创建对角矩阵并缩放
eye = jnp.eye(self.num_experts, dtype=dtype) * scale
# 如果维度更大,进行零填充
if shape[0] > self.num_experts:
eye = jnp.pad(eye, ((0, shape[0] - self.num_experts), (0, 0)))
return eye
self.route = nn.Dense(
features=self.num_experts,
use_bias=False,
kernel_init=kernel_init,
)
@nn.compact
def __call__(self, x):
return self.route(x)
def top1_routing(router_logits):
"""
Top-1 路由:每个 token 只选择一个专家
Args:
router_logits: (batch, time, num_experts) 路由得分
Returns:
combine_weights: (batch, time, num_experts) 稀疏权重矩阵
top_idx: (batch, time, 1) 选中的专家索引
"""
probs = jax.nn.softmax(router_logits, axis=-1)
top_vals, top_idx = jax.lax.top_k(probs, k=1)
B, T, E = router_logits.shape
one_hot = jax.nn.one_hot(top_idx[..., 0], E, dtype=router_logits.dtype)
combine = one_hot * top_vals
return combine, top_idx
class GemmoeSparseMoeBlock(nn.Module):
"""稀疏 MoE 块:1 个共享专家 + N 个原子技能专家"""
config: Config
def setup(self):
self.num_extra_experts = getattr(self.config, "num_local_experts", 1)
self.num_experts = 1 + self.num_extra_experts
# Expert 0: 共享专家(保留预训练能力)
experts = [
FeedForward(
features=1024,
hidden_dim=4096,
name="expert_0",
)
]
# Expert 1-N: 原子技能专家
for e in range(1, self.num_experts):
experts.append(
GemmoeBlockSparseTop2MLP(
features=self.config.width,
hidden_dim=self.config.mlp_dim,
name=f"expert_{e}",
)
)
self.experts = experts
def __call__(self, x, combine_weights, deterministic=True):
"""
Args:
x: (batch, time, dim) 输入特征
combine_weights: (batch, time, num_experts) 路由权重
Returns:
y: (batch, time, dim) 专家输出的加权组合
"""
# 每个专家独立处理输入
expert_outs = [expert(x) for expert in self.experts]
expert_outs = jnp.stack(expert_outs, axis=2) # (B, T, E, D)
# 根据路由权重加权组合
y = jnp.einsum("bte,bted->btd", combine_weights, expert_outs)
return y.astype(x.dtype)这种架构设计带来了两个关键优势。首先,每个技能专家只需要学习一种特定的操作模式,大大降低了学习难度。其次,不同技能的参数被显式地分离到不同的专家网络中 ,有效避免了技能间的相互干扰。实验结果表明,这种设计在LIBERO-LONG基准测试中相比标准MoE架构提升了6.6%的成功率。
4. 持续学习:可扩展的技能库设计
在真实世界的应用场景中,机器人不可避免地会遇到需要学习新技能的情况。传统的VLA模型在面对这种需求时通常采用两种策略:要么对整个模型进行重新训练,这会导致巨大的计算开销;要么在现有模型基础上进行微调,这往往会导致灾难性遗忘------新技能的学习会显著降低旧技能的表现。
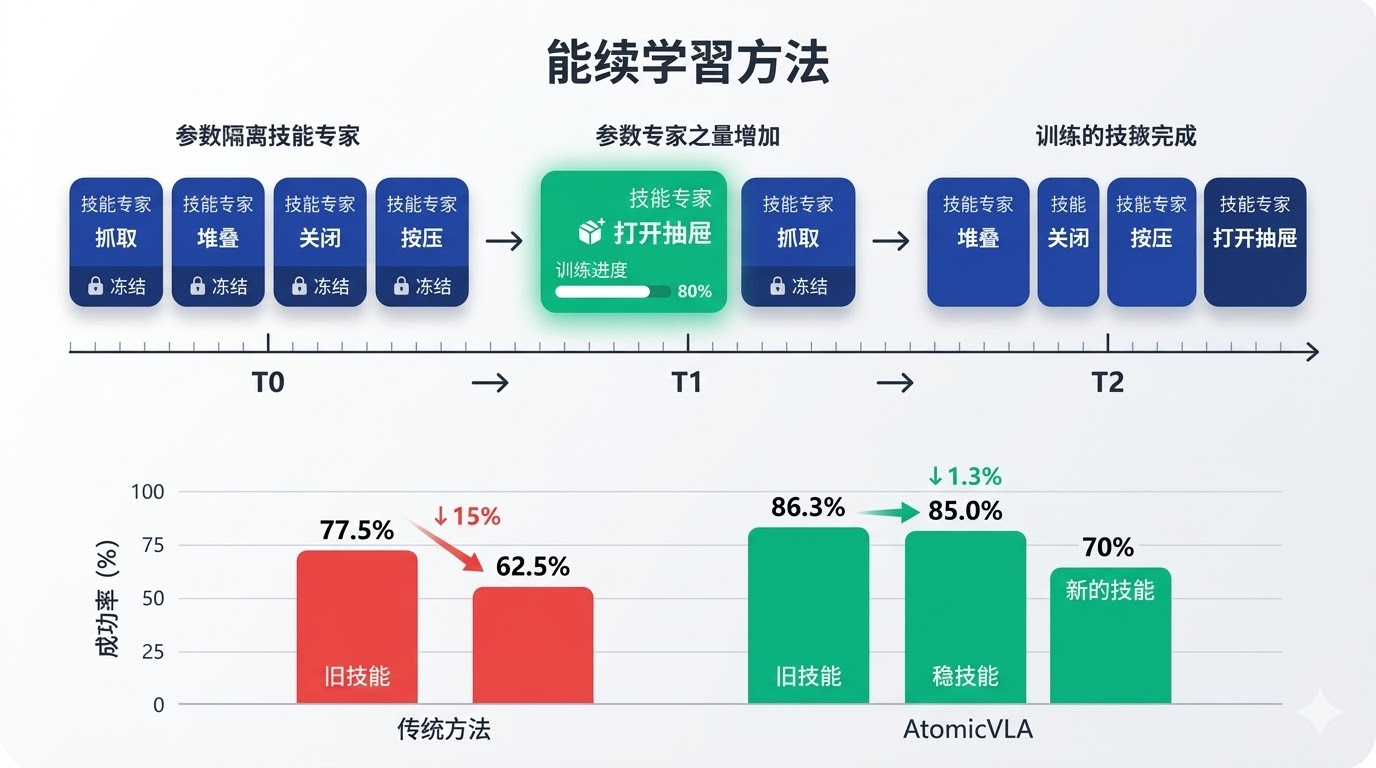
AtomicVLA通过模块化的技能专家机制 优雅地解决了这个问题。当需要学习新的原子技能时,系统只需要执行两个简单的操作:添加一个新的技能专家网络 ,并扩展路由器以支持新技能的选择 。关键的是,已有的技能专家参数保持冻结,不会在新技能的学习过程中被修改。
python
# AtomicVLA 持续学习机制(基于 train_atomic.py 实现)
import jax
import jax.numpy as jnp
import flax.traverse_util as traverse_util
def update_params(orig_params, partial_params):
"""
递归更新参数:仅更新 partial_params 中存在的部分,保留其他参数不变
Args:
orig_params: 原始参数字典
partial_params: 部分更新的参数字典
Returns:
更新后的参数字典
"""
for k, v in partial_params.items():
if isinstance(v, dict):
if k not in orig_params:
orig_params[k] = {}
orig_params[k] = update_params(orig_params.get(k, {}), v)
else:
orig_params[k] = v
return orig_params
def load_and_filter_weights(loader, params_shape):
"""
加载预训练权重并适配 MoE 架构
将单个 MLP 层的权重复制到 MoE 的 expert_0(共享专家)
Args:
loader: 权重加载器
params_shape: 目标参数形状
Returns:
过滤和映射后的参数字典
"""
loaded_params = loader.load(params_shape)
flat_loaded = traverse_util.flatten_dict(loaded_params)
# MLP → MoE 映射:将原始 MLP 权重复制到 expert_0
mlp_to_moe_mapping = {
("PaliGemma", "llm", "layers", "moe_1", "expert_0", "gating_einsum"):
("PaliGemma", "llm", "layers", "mlp_1", "gating_einsum"),
("PaliGemma", "llm", "layers", "moe_1", "expert_0", "linear"):
("PaliGemma", "llm", "layers", "mlp_1", "linear"),
}
for moe_key, mlp_key in mlp_to_moe_mapping.items():
if mlp_key in flat_loaded:
flat_loaded[moe_key] = flat_loaded[mlp_key] # 复制到 expert_0
# 移除原始 MLP 权重(已被 MoE 替代)
keys_to_remove = [k for k in flat_loaded if "mlp_1" in k]
for k in keys_to_remove:
flat_loaded.pop(k)
return traverse_util.unflatten_dict(flat_loaded)
def add_new_skill_expert(model, new_expert_config):
"""
添加新的技能专家到现有模型
关键特性:
1. 冻结所有旧专家参数
2. 只训练新专家和路由器的新分支
3. 参数隔离确保不会遗忘旧技能
Args:
model: 现有的 Pi0Atomic 模型
new_expert_config: 新专家的配置
Returns:
扩展后的模型
"""
# 1. 冻结所有现有专家的参数
for expert in model.PaliGemma.llm.experts:
for param in expert.parameters():
param.trainable = False
# 2. 添加新的技能专家
new_expert = GemmoeBlockSparseTop2MLP(
features=new_expert_config.width,
hidden_dim=new_expert_config.mlp_dim,
name=f"expert_{len(model.PaliGemma.llm.experts)}",
)
model.PaliGemma.llm.experts.append(new_expert)
# 3. 扩展路由器输出维度
old_num_experts = model.num_local_experts
model.num_local_experts = old_num_experts + 1
# 4. 更新技能嵌入矩阵
old_scales = jnp.linspace(10.0, 100.0, old_num_experts)
new_scale = 10.0 + (100.0 - 10.0) * (old_num_experts / model.num_local_experts)
new_scales = jnp.append(old_scales, new_scale)
new_base = jnp.eye(model.num_local_experts) * new_scales[:, None]
if new_expert_config.width > model.num_local_experts:
new_base = jnp.pad(
new_base,
((0, 0), (0, new_expert_config.width - model.num_local_experts))
)
model.sigma_emb.value = new_base
return model这种设计的核心优势在于参数隔离 。由于每个技能专家的参数是独立的,新技能的学习不会影响旧技能的参数。实验数据验证了这一点:在真实机器人实验中,AtomicVLA在学习"打开抽屉"这个新技能后,在四个旧技能上的平均性能仅下降了1.3%,而基线模型π0.5的性能下降了15%。这种显著的差异充分证明了模块化设计在持续学习中的有效性。