1. 为什么机器人训练需要仿真环境
在真实世界中训练一台机器人学会走路,代价是极其高昂的。硬件磨损、安全风险、数据采集效率低下,这些问题使得直接在物理机器人上进行强化学习几乎不可行。2019 年 OpenAI 用强化学习训练机械手解魔方的工作中,仿真环境中的训练量相当于真实世界中约一万年的操作经验。这个数字直观地说明了一件事:没有高效的仿真器,现代机器人强化学习根本无从谈起。
仿真环境的核心价值在于三点。第一,它可以同时运行成百上千个并行环境,将数据采集效率提升几个数量级。第二,仿真中的失败没有任何物理代价------机器人摔倒了,重置状态即可。第三,仿真器可以精确控制物理参数,比如地面摩擦系数、关节阻尼、重力大小,这为 domain randomization 等 sim-to-real 技术提供了基础。
目前主流的机器人仿真平台包括 MuJoCo、Isaac Gym、Brax 等。MuJoCo 以物理精度著称,Isaac Gym 依托 NVIDIA GPU 实现了大规模并行仿真,Brax 则基于 JAX 实现了可微分的物理仿真。MotrixLab 选择了另一条路径:它基于 Motphys 公司自研的 MotrixSim 物理引擎构建,目标是提供一个结构清晰、易于扩展的强化学习开发平台。项目地址:https://github.com/Motphys/MotrixLab,文档地址:https://motrixlab.readthedocs.io

2. MotrixLab 的整体架构
MotrixLab 的设计哲学可以用一句话概括:将仿真环境的定义与训练框架的实现彻底解耦。整个项目被划分为两个独立的 Python 包,通过 UV workspace 进行管理:
MotrixLab/
├── motrix_envs/ # 仿真环境定义(与 RL 框架无关)
│ └── src/motrix_envs/
│ ├── base.py # 抽象基类:EnvCfg、ABEnv
│ ├── registry.py # 环境注册系统
│ ├── np/ # NumPy 后端实现
│ ├── basic/ # 基础控制任务(倒立摆、摆锤等)
│ ├── locomotion/ # 四足运动任务(Go1、Go2、ANYmal-C)
│ └── manipulation/ # 操作任务(Franka 机械臂、Shadow Hand)
│
├── motrix_rl/ # 强化学习训练框架
│ └── src/motrix_rl/
│ ├── cfgs.py # 各环境的 PPO 训练配置
│ ├── registry.py # RL 配置注册系统
│ └── skrl/ # SKRL 框架集成
│ ├── jax/ # JAX 后端
│ └── torch/ # PyTorch 后端
│
└── scripts/ # 入口脚本
├── train.py # 训练
├── play.py # 推理
└── view.py # 环境可视化
这种分层设计带来的直接好处是:如果你只想定义一个新的仿真环境,完全不需要关心 SKRL 或 PPO 的实现细节;反过来,如果你想替换训练算法(比如从 PPO 换成 SAC),也不需要修改任何环境代码。这种关注点分离在工程实践中非常重要,尤其是当团队中有人专注物理建模、有人专注算法调优的时候。
3.环境注册系统:装饰器驱动的工厂模式
MotrixLab 的环境管理采用了一套两级注册机制。第一级注册环境配置(EnvCfg),第二级注册环境实现(ABEnv)。两者通过装饰器完成,代码非常简洁:
python
# 第一级:注册环境配置
@registry.envcfg("cartpole")
@dataclass
class CartPoleEnvCfg(EnvCfg):
model_file: str = "cartpole.xml"
reset_noise_scale: float = 0.01
max_episode_seconds: float = 10
# 第二级:注册环境实现(绑定到 "np" 后端)
@registry.env("cartpole", "np")
class CartPoleEnv(NpEnv):
...注册完成后,创建环境只需要一行调用:
python
env = registry.make("cartpole", sim_backend="np", num_envs=2048)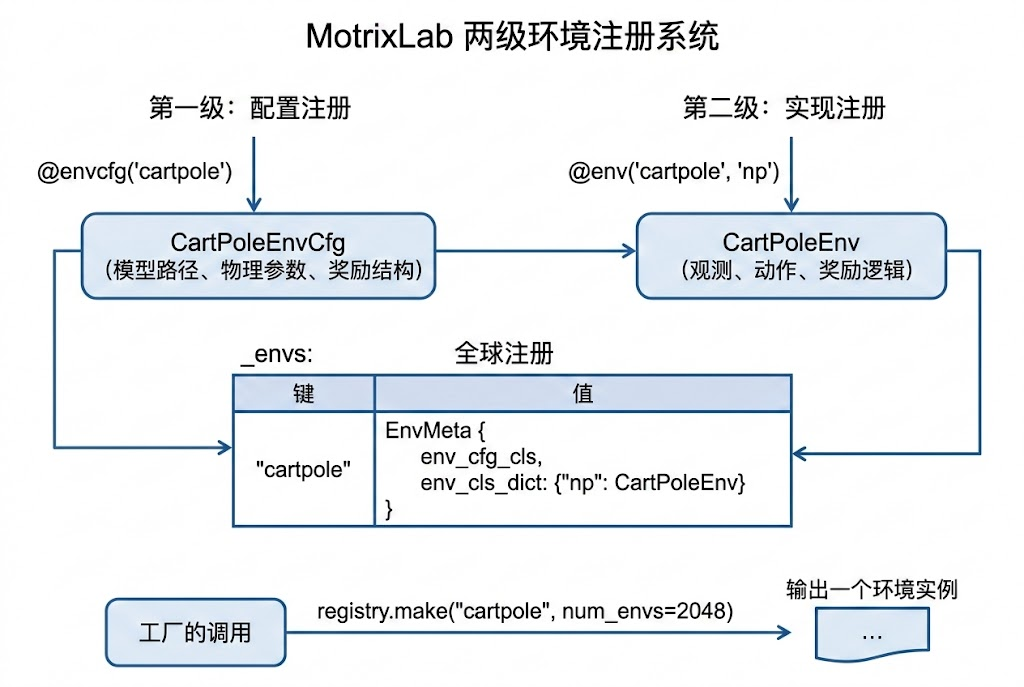
这套机制的内部实现并不复杂。registry.py 维护了一个全局字典 _envs,键是环境名称,值是一个 EnvMeta 数据结构,其中包含配置类和各后端的实现类映射:
python
@dataclass
class EnvMeta:
env_cfg_cls: Type[EnvCfg]
env_cls_dict: Dict[str, Type[ABEnv]] = field(default_factory=dict)make 函数的工作流程是:根据名称查找 EnvMeta,实例化配置对象,应用用户传入的覆盖参数,校验配置合法性,最后用对应后端的环境类创建实例。这是一个典型的工厂模式实现,但通过装饰器语法将注册过程内联到了类定义中,避免了集中式的注册表文件。
这种设计的一个值得注意的细节是:配置和实现的注册是分开的。这意味着你可以先定义一个环境的配置(物理参数、奖励结构等),然后为同一个环境提供多种后端实现。目前 MotrixLab 只支持 NumPy 后端("np"),但架构上已经为 GPU 后端预留了扩展空间。
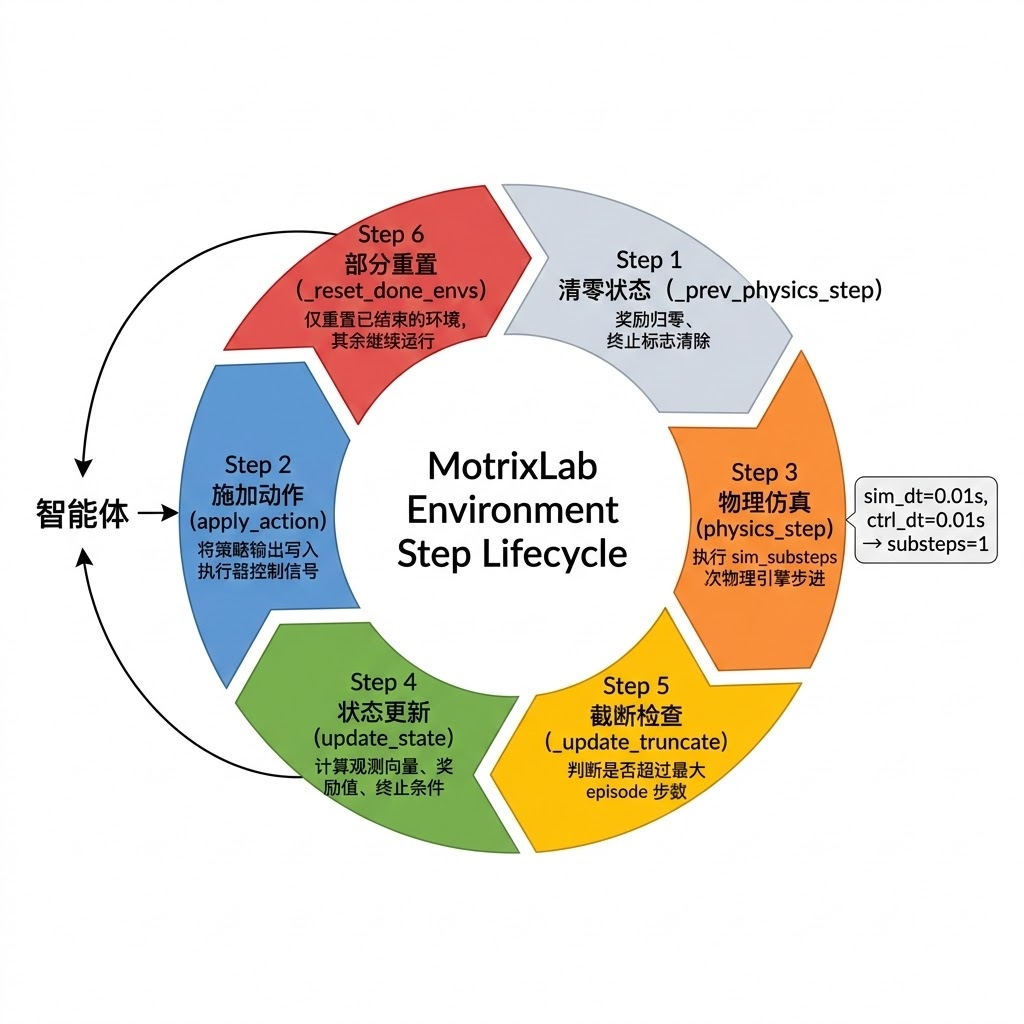
4. 环境的生命周期:从物理仿真到观测-奖励计算
理解一个强化学习环境的运行机制,关键在于理解它的 step 循环。在 MotrixLab 中,所有基于 NumPy 后端的环境都继承自 NpEnv 基类,这个基类定义了一套严格的执行顺序:
python
def step(self, actions: np.ndarray) -> NpEnvState:
self._prev_physics_step() # 1. 清零奖励和终止标志
self.apply_action(actions) # 2. 将动作施加到执行器
self.physics_step() # 3. 运行物理仿真(可能多个子步)
self.update_state() # 4. 计算观测值和奖励
self._update_truncate() # 5. 检查是否超过最大步数
self._reset_done_envs() # 6. 自动重置已结束的环境
return self._state这六个步骤构成了环境与智能体交互的一个完整周期。其中第 3 步的物理仿真值得特别说明。MotrixLab 区分了两个时间尺度:sim_dt(物理仿真步长)和 ctrl_dt(控制步长)。控制步长通常等于或大于仿真步长,两者的比值决定了每次 step 调用中物理引擎实际执行的子步数:
python
@property
def sim_substeps(self) -> int:
return int(round(self.ctrl_dt / self.sim_dt))
def physics_step(self):
for _ in range(self._cfg.sim_substeps):
self._model.step(self._state.data)这种双时间尺度设计在机器人仿真中非常常见。物理引擎需要较小的时间步长来保证数值稳定性(通常 0.001s 到 0.01s),而控制器的决策频率不需要那么高(通常 0.01s 到 0.05s)。通过 sim_substeps 机制,MotrixLab 在一次控制决策之间可以执行多步物理仿真,既保证了物理精度,又降低了策略网络的推理频率。
环境的状态被封装在 NpEnvState 数据类中,它包含了仿真数据、观测值、奖励、终止标志等所有信息:
python
@dataclass
class NpEnvState:
data: mtx.SceneData # MotrixSim 的场景数据(关节位置、速度等)
obs: np.ndarray # 观测向量
reward: np.ndarray # 即时奖励
terminated: np.ndarray # 是否因失败终止
truncated: np.ndarray # 是否因超时截断
info: dict # 附加信息(步数计数等)terminated 和 truncated 的区分遵循了 Gymnasium 的最新规范。前者表示环境因为达到某个失败条件而结束(比如倒立摆倾倒),后者表示因为达到最大步数限制而截断。这个区分对于价值函数的 bootstrap 计算有实际影响:截断的 episode 末尾状态仍然有价值,而终止的末尾状态价值为零。
5. 以 CartPole 为例:一个完整环境的实现
CartPole(倒立摆)是强化学习领域最经典的入门环境。一辆小车在一维轨道上左右移动,车上铰接着一根杆,目标是通过控制小车的水平力让杆保持竖直。这个问题看似简单,但它包含了强化学习环境设计的所有核心要素:状态空间定义、动作空间定义、奖励函数设计、终止条件判断。
在 MotrixLab 中,CartPole 环境的实现分为两个文件。配置文件定义了物理模型路径和环境参数:
python
@registry.envcfg("cartpole")
@dataclass
class CartPoleEnvCfg(EnvCfg):
model_file: str = os.path.dirname(__file__) + "/cartpole.xml"
reset_noise_scale: float = 0.01
max_episode_seconds: float = 10环境实现文件则定义了具体的观测、动作、奖励和重置逻辑。观测空间是一个 4 维向量(小车位置、杆角度、小车速度、杆角速度),动作空间是一个连续的标量(施加在小车上的力):
python
@registry.env("cartpole", "np")
class CartPoleEnv(NpEnv):
def __init__(self, cfg, num_envs=1):
super().__init__(cfg, num_envs=num_envs)
self._action_space = gym.spaces.Box(-3.0, 3.0, (1,), dtype=np.float32)
self._observation_space = gym.spaces.Box(-np.inf, np.inf, (4,), dtype=np.float32)奖励函数的设计极为简洁------只要杆没倒,每一步都给 1.0 的奖励。终止条件是杆的角度超过 0.2 弧度(约 11.5 度)或小车偏离中心超过 0.8 个单位:
python
def update_state(self, state):
dof_pos = state.data.dof_pos
dof_vel = state.data.dof_vel
obs = np.concatenate([dof_pos, dof_vel], axis=-1)
reward = np.ones((self._num_envs,), dtype=np.float32)
cart_pos = dof_pos[:, 0]
angle = dof_pos[:, 1]
terminated = np.logical_or(np.abs(angle) > 0.2, np.abs(cart_pos) > 0.8)
state.obs = obs
state.reward = reward
state.terminated = terminated
return state这段代码有一个值得注意的工程细节:所有计算都是向量化的。dof_pos 的形状是 (num_envs, 2),reward 的形状是 (num_envs,)。这意味着 2048 个并行环境的观测、奖励、终止判断在一次 NumPy 运算中同时完成,没有任何 Python 层面的循环。这种向量化设计是大规模并行仿真的基础。
重置逻辑同样值得关注。当某些环境达到终止或截断条件时,_reset_done_envs 方法会自动识别这些环境并重置它们,同时在初始状态上添加微小的随机噪声,防止策略过拟合到固定的初始条件:
python
def reset(self, data):
noise_pos = np.random.uniform(-cfg.reset_noise_scale, cfg.reset_noise_scale, ...)
dof_pos = np.tile(self._init_dof_pos, (*data.shape, 1)) + noise_pos
data.reset(self._model)
data.set_dof_pos(dof_pos, self._model)
obs = np.concatenate([dof_pos, dof_vel], axis=-1)
return obs, {}这种"部分重置"机制是向量化环境的标准做法。与逐个重置不同,它只重置已经结束的环境,其余环境继续运行,最大限度地利用了并行计算的优势。
6. PPO 训练管线:从环境到策略网络
PPO(Proximal Policy Optimization)是目前机器人强化学习中使用最广泛的算法之一。它由 OpenAI 在 2017 年提出,核心思想是在策略更新时通过裁剪比率来限制每次更新的幅度,从而在样本效率和训练稳定性之间取得平衡。相比更早的 TRPO 算法,PPO 的实现更简单,计算开销更低,但在大多数任务上能达到相当甚至更好的效果。这也是为什么从 OpenAI Five 到 Tesla Optimus,PPO 几乎成了机器人控制领域的默认选择。
MotrixLab 通过 SKRL 框架来实现 PPO 训练。SKRL 是一个模块化的强化学习库,同时支持 JAX 和 PyTorch 后端。MotrixLab 在 SKRL 之上构建了自己的配置系统和训练管线,使得启动一次训练只需要指定环境名称:
bash
uv run scripts/train.py --env cartpole这条命令背后的执行流程可以分解为以下几个阶段。首先,train.py 检测当前设备的计算能力,按照 JAX GPU > PyTorch GPU > JAX CPU > PyTorch CPU 的优先级自动选择训练后端:
python
def get_train_backend(supports):
if supports.jax and supports.jax_gpu:
return "jax"
elif supports.torch and supports.torch_gpu:
return "torch"
elif supports.jax:
return "jax"
elif supports.torch:
return "torch"然后,系统从 RL 配置注册表中加载对应环境的 PPO 超参数。每个环境都有预调好的配置,以 CartPole 为例:
python
@rlcfg("cartpole")
@dataclass
class CartPolePPO(PPOCfg):
max_env_steps: int = 10_000_000
policy_hidden_layer_sizes: tuple = (32, 32)
value_hidden_layer_sizes: tuple = (32, 32)
rollouts: int = 32
learning_epochs: int = 5
mini_batches: int = 4这里的配置揭示了一个重要的工程决策:CartPole 这样的简单任务只需要两层 32 个神经元的网络,而四足机器人行走任务(Go1)则需要三层 256-128-64 的网络,Shadow Hand 灵巧手操作甚至需要四层 512-512-256-128 的网络。网络容量与任务复杂度的匹配是强化学习调参中最关键的环节之一------网络太小学不到复杂策略,太大则容易过拟合或训练不稳定。
7. 策略网络与价值网络:Actor-Critic 的具体实现
PPO 属于 Actor-Critic 架构,需要同时维护两个神经网络:策略网络(Actor)负责根据观测输出动作,价值网络(Critic)负责估计当前状态的长期回报。MotrixLab 中这两个网络的定义直接嵌入在 Trainer 类内部,以 JAX/Flax 后端为例:
python
class Policy(GaussianMixin, Model):
@nn.compact
def __call__(self, inputs, role):
x = inputs["states"]
for size in rlcfg.policy_hidden_layer_sizes:
x = nn.elu(nn.Dense(size)(x))
x = nn.Dense(self.num_actions)(x)
log_std = self.param("log_std", lambda _: jnp.ones(self.num_actions))
return x, log_std, {}这段代码的结构值得逐行分析。输入是环境的观测向量,经过若干全连接层(层数和宽度由配置决定),每层使用 ELU 激活函数。最后一层输出动作的均值,同时维护一个可学习的 log_std 参数表示动作分布的标准差。策略网络输出的不是一个确定的动作,而是一个高斯分布的参数------均值和标准差。训练时从这个分布中采样动作,推理时可以直接使用均值作为确定性动作。
价值网络的结构与策略网络类似,但输出是一个标量,表示对当前状态价值的估计:
python
class Value(DeterministicMixin, Model):
@nn.compact
def __call__(self, inputs, role):
x = inputs["states"]
for size in rlcfg.value_hidden_layer_sizes:
x = nn.elu(nn.Dense(size)(x))
x = nn.Dense(1)(x)
return x, {}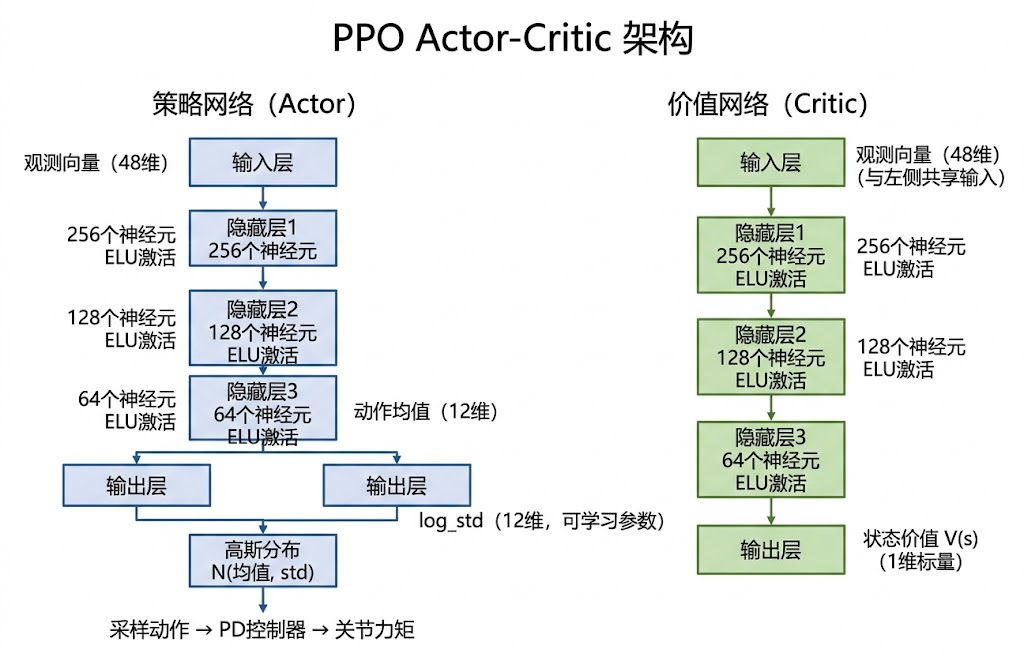
选择 ELU 而非 ReLU 作为激活函数并非偶然。在强化学习的连续控制任务中,ELU 的负半轴有非零梯度,能够避免 ReLU 的"神经元死亡"问题,这对训练稳定性有实际帮助。
完整的训练流程在 Trainer.train() 方法中串联起来:
python
def train(self):
env = env_registry.make(self._env_name, num_envs=rlcfg.num_envs)
skrl_env = wrap_env(env, self._enable_render)
models = self._make_model(skrl_env, rlcfg)
ppo_cfg = _get_cfg(rlcfg, skrl_env, log_dir=get_log_dir(self._env_name))
agent = self._make_agent(models, skrl_env, ppo_cfg)
trainer = SequentialTrainer(cfg=cfg_trainer, env=skrl_env, agents=agent)
trainer.train()这里的 wrap_env 是一个关键的适配层。MotrixLab 的环境基于 NumPy,而 SKRL 期望的是符合其 Wrapper 接口的环境。SkrlNpWrapper 负责在两者之间做转换,将 NumPy 数组转为 JAX 数组,并将 NpEnvState 的各个字段拆解为 SKRL 期望的元组格式:
python
class SkrlNpWrapper(SkrlWrapper):
def step(self, actions):
actions = np.array(actions) # JAX -> NumPy
state = self._env.step(actions)
return (
state.obs, # 观测
state.reward.reshape(-1, 1), # 奖励(列向量)
state.terminated.reshape(-1, 1), # 终止标志
state.truncated.reshape(-1, 1), # 截断标志
state.info, # 附加信息
)这种 Wrapper 模式在强化学习工程中极为常见。不同的 RL 库对环境接口的要求略有差异,通过一层薄薄的适配器就能让同一个环境在不同框架间复用,而不需要为每个框架重写环境逻辑。
8. 四足机器人行走:奖励工程的艺术
如果说 CartPole 是强化学习的"Hello World",那么四足机器人行走就是真正的工程挑战。MotrixLab 内置了对宇树科技 Go1、Go2 以及 ANYbotics ANYmal-C 三款四足机器人的支持,涵盖平坦地面、崎岖地形和楼梯三种场景。
四足行走任务的复杂度远超倒立摆。Go1 机器人有 12 个关节(每条腿 3 个自由度:髋关节、大腿、小腿),观测空间包含关节角度、关节速度、机身角速度、重力方向投影、速度指令等数十个维度。动作空间是 12 维的连续向量,每个维度对应一个关节的目标角度偏移量。
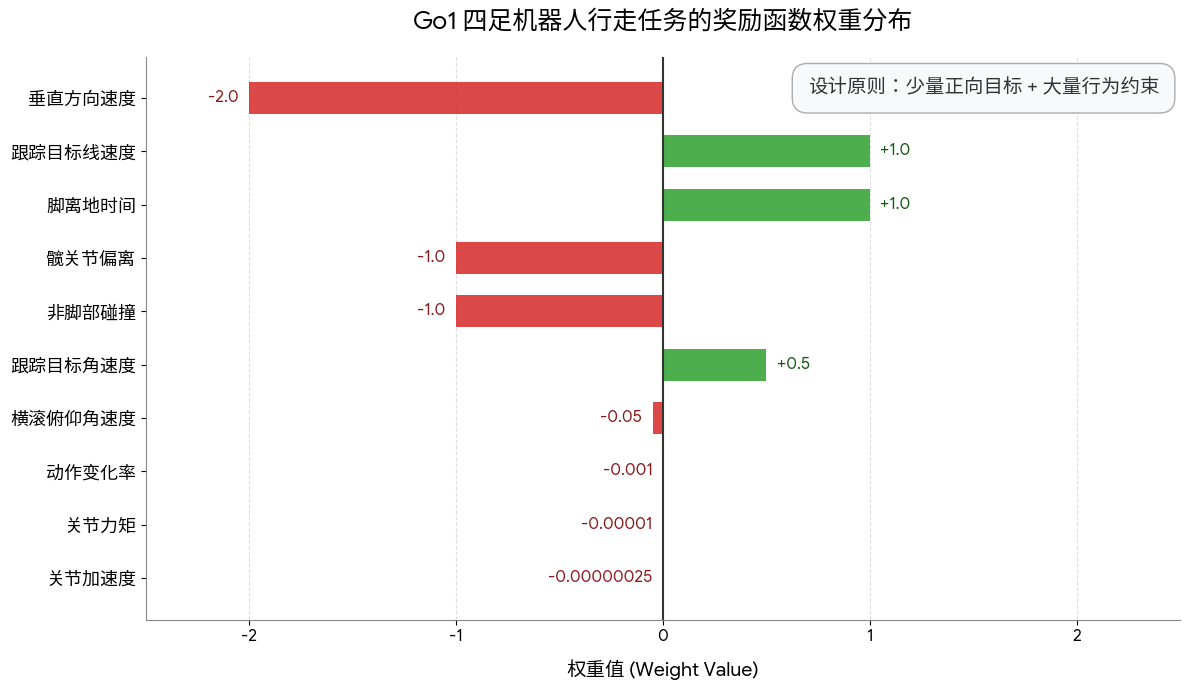
但真正决定训练成败的是奖励函数的设计。Go1 行走环境的奖励配置如下:
python
@dataclass
class RewardConfig:
scales: dict[str, float] = field(default_factory=lambda: {
"tracking_lin_vel": 1.0, # 跟踪目标线速度(正向激励)
"tracking_ang_vel": 0.5, # 跟踪目标角速度(正向激励)
"lin_vel_z": -2.0, # 惩罚垂直方向速度(防止跳跃)
"ang_vel_xy": -0.05, # 惩罚横滚和俯仰角速度
"torques": -0.00001, # 惩罚关节力矩(节能)
"dof_acc": -2.5e-7, # 惩罚关节加速度(平滑运动)
"feet_air_time": 1.0, # 奖励脚离地时间(鼓励抬腿)
"collision": -1.0, # 惩罚非脚部碰撞
"action_rate": -0.001, # 惩罚动作变化率(平滑控制)
"hip_pos": -1.0, # 惩罚髋关节偏离默认位置
})
tracking_sigma: float = 0.25
max_foot_height: float = 0.1