运动估计(Motion Estimation, ME)是视频编码的核心模块,其性能直接决定了整个编码器的压缩效率和实时性。在 HEVC(High Efficiency Video Coding)标准中,为了应对高分辨率(4K/8K)和高帧率视频的挑战,运动估计算法在块划分结构、预测模式、搜索策略以及硬件友好性方面进行了颠覆性的革新。
一图总结
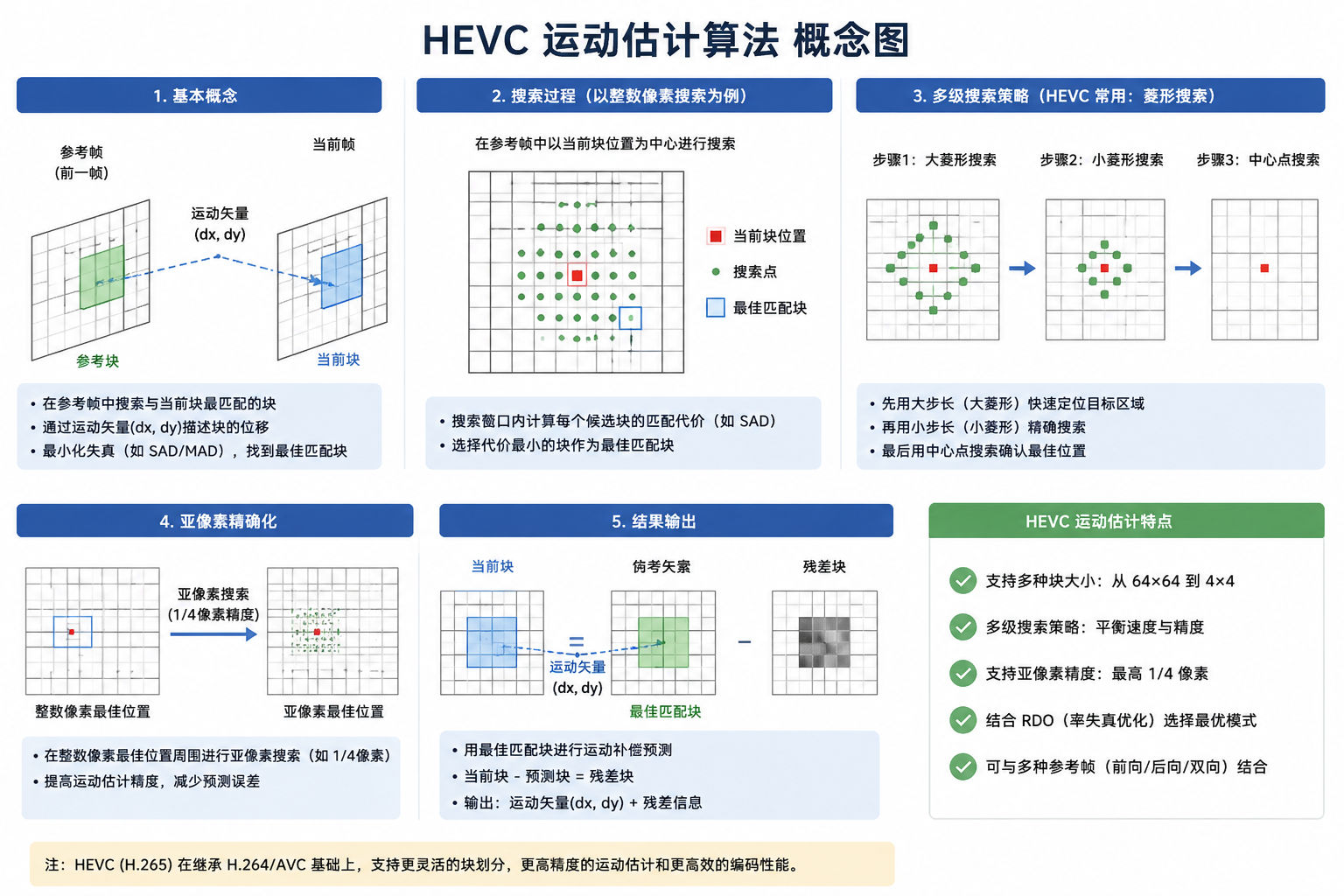
一句话总结
HEVC 运动估计算法以四叉树块划分为核心,通过高精度的 Merge/AMVP 矢量预测与 8 抽头分数像素内插,在率失真优化(RDO)驱动下实现高压缩效率与硬件并行性的最佳平衡。
基于树状划分的运动估计基本架构
HEVC 彻底摒弃了 H.264/AVC 沿用多年的 16×1616 \times 1616×16 固定宏块(Macroblock)限制,引入了基于四叉树(Quad-tree)的灵活划分结构。这一改变直接重构了运动估计的执行单元。
CTU、CU 与 PU 的层级关系
- CTU(Coding Tree Unit,编码树单元): 运动估计的基础阵列,尺寸最高可达 64×6464 \times 6464×64。对于高清/超高清视频中的大面积平滑区域(如天空、背景),大尺寸的 CTU 能极大地提高运动矢量的压缩率。
- CU(Coding Unit,编码单元): CTU 通过四叉树递归划分形成的叶子节点,尺寸从 64×6464 \times 6464×64 到 8×88 \times 88×8 不等。CU 是选择帧内或帧间预测的决策单元。
- PU(Prediction Unit,预测单元): 运动估计与运动补偿的实际执行单元。在 CU 层级决定采用帧间预测后,CU 会根据纹理复杂程度进一步划分为一个或多个 PU。
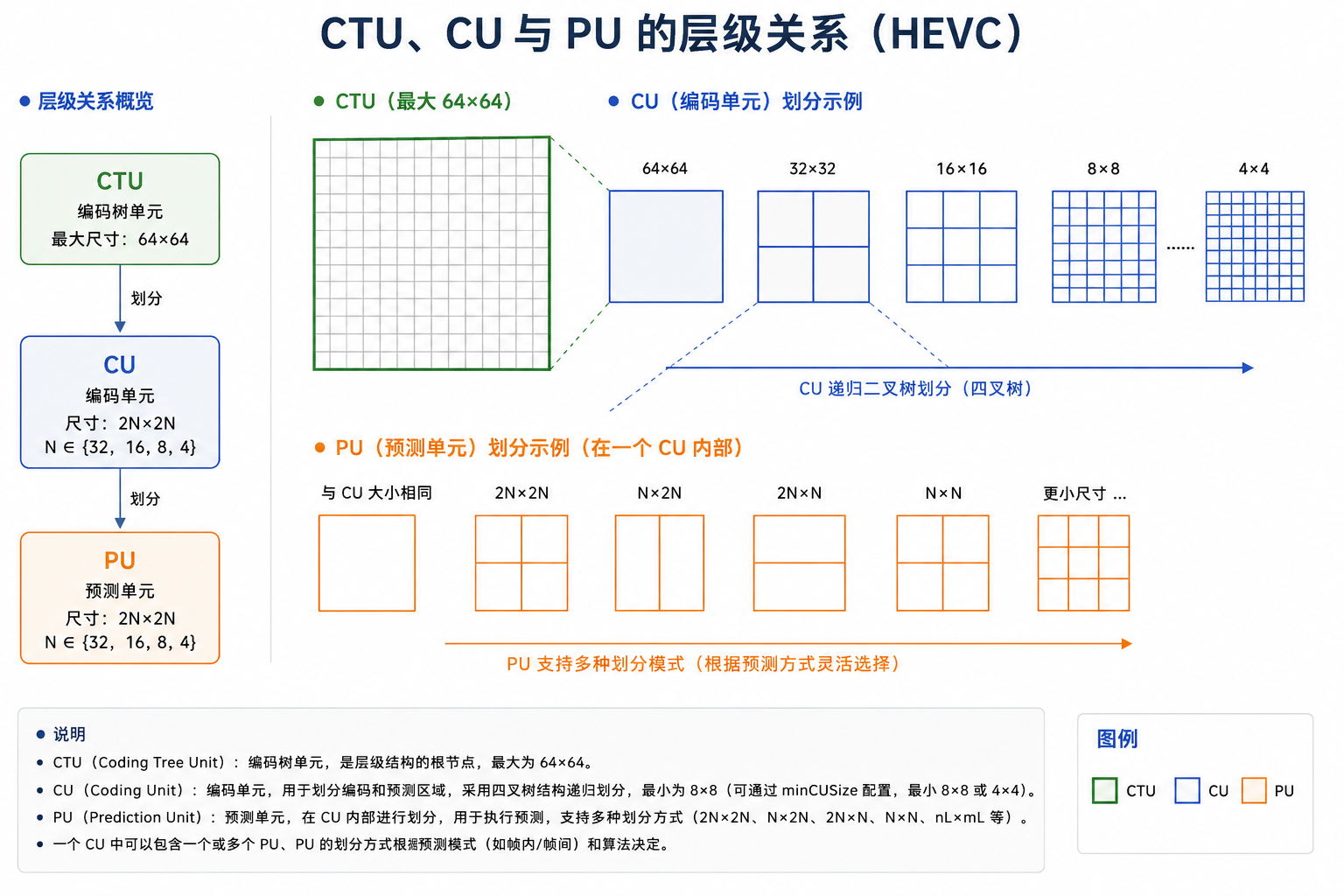
PU 的划分模式(Partition Modes)
HEVC 为帧间预测提供了 8 种 PU 划分模式,分为两大类:
- 对称划分(SMP):
2Nx2N、2NxN、Nx2N以及仅在最小 CU(SCU)中使用的NxN。 - 非对称划分(AMP):
2NxnU、2NxnD、nLx2N、nRx2N。AMP 的引入能够精准拟合非中心对称的复杂边缘运动(例如车辆在地平线上移动),大幅减少预测残差。
运动估计的挑战: 这种多层级、多模式的嵌套使得运动估计的搜索空间呈指数级增长。编码器必须在成百上千种可能的块组合中,为每一个 PU 寻找到最优的运动矢量(Motion Vector, MV)。
现代运动矢量预测机制:Advanced MV Prediction
为了减少传输 MV 所占用的码流,HEVC 设计了极具创新性的运动矢量预测技术。通过重用时域和空域相邻块的运动信息,运动估计算法可以建立极高精度的预测起点。
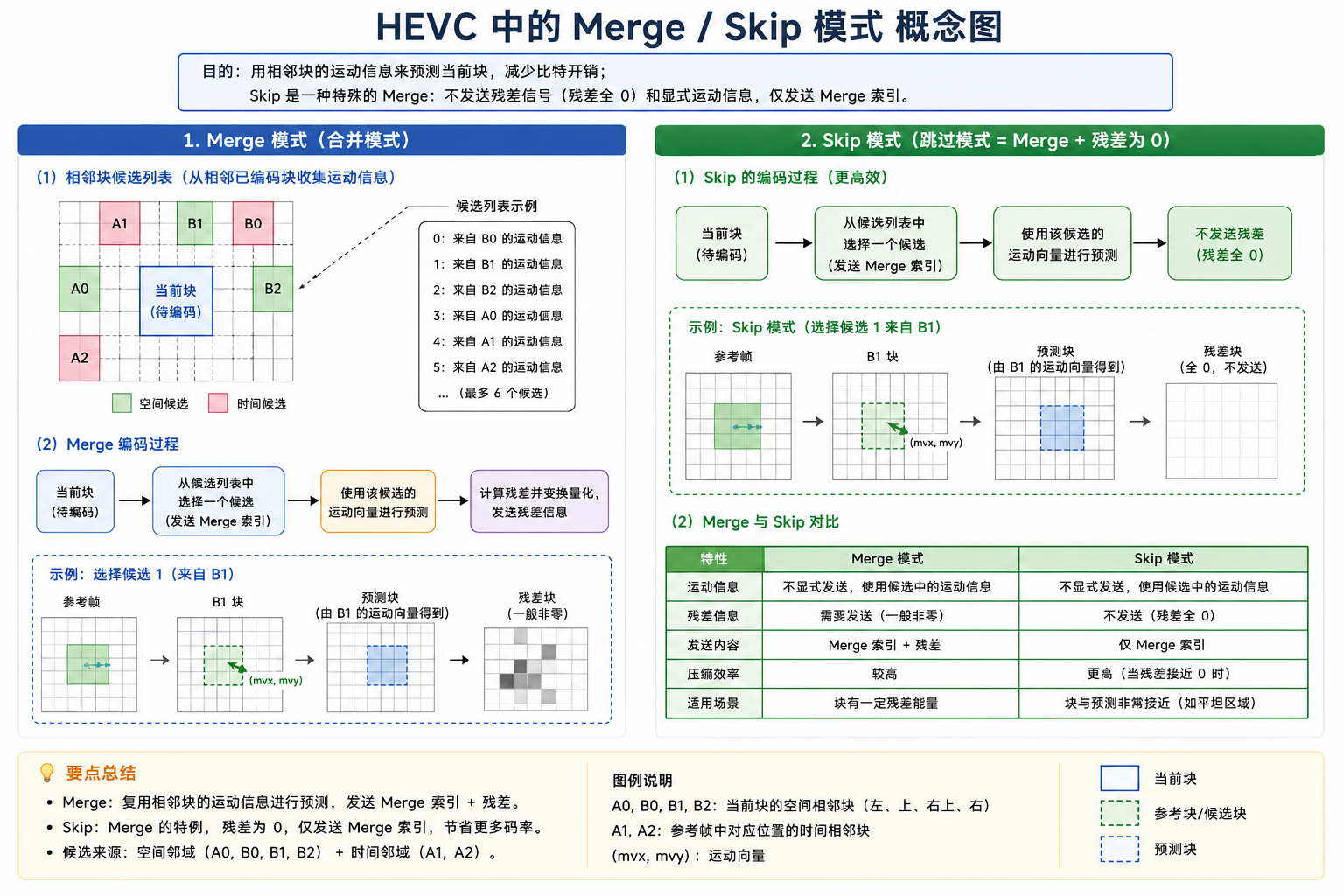
Merge / Skip 模式
Merge 模式是 HEVC 提升压缩效率的杀手锏。它不直接编码当前 PU 的 MV,而是建立一个候选列表(Candidate List),直接"借用"相邻块的运动参数(包括 MV、参考帧索引、单向/双向预测方向)。
- 空间候选(Spatial): 检查左、上、右上、左下、左上五个相邻 PU 的运动信息(取最多 4 个)。
- 时域候选(TMVP): 利用前/后参考帧中对应位置(Collocated)的 PU 运动矢量,并通过时域距离进行线性缩放。
- 组合与零候选: 若列表未满,通过组合双向或填充零向量补齐。
- Skip 模式: 当 Merge 模式下的预测残差接近于零时,直接触发 Skip 模式,此时不传输任何残差和 MV 差值,仅传输一个候选列表索引,极大节省了码字。
AMVP(Advanced Motion Vector Prediction)模式
当当前 PU 无法直接借用相邻块的 MV 时,采用 AMVP 模式。AMVP 同样构建空域和时域候选列表(容量固定为 2),选出最佳的运动矢量预测值(MVP)。
- 运动估计模块仅需对实际搜索到的 MVMVMV 与 MVPMVPMVP 的差值(MVD=MV−MVPMVD = MV - MVPMVD=MV−MVP)进行编码。
- 通过高精度的 AMVP,使得 MVDMVDMVD 的能级降到最低,从而优化了熵编码的效率。
多层次运动检索算法:从整像素到分数像素
在确定了预测起点(MVP)后,运动估计进入实质性的像素搜索阶段。HEVC 采用了"粗定位 + 精细调优"的两阶段搜索架构。
整像素运动搜索(Integer-Pixel ME)
整像素搜索阶段的目标是在搜索窗口内快速锁定最佳匹配块的大致位置。为了平衡计算复杂度和全局最优性,业界和标准参考软件(HM)主要采用以下算法:
- TZSearch(Test Zone Search)算法: HM 软件中默认的非全字搜索算法。它结合了菱形搜索(Diamond Search)和光栅扫描(Raster Scan)。首先以 MVP 为中心进行步长为 1, 2, 4, 8... 的菱形搜索,若发现局部最优解,则启动两点细化;为防陷入局部最优,还会定期进行全局光栅扫描。
- 三步搜索(3SS)与新三步搜索(N3SS): 硬件流水线设计中常用的启发式搜索,通过逐步缩小步长和搜索窗口来降低计算量。
高精度分数像素内插与搜索
真实世界中的物体运动极少精准落在整像素网格上。HEVC 将运动估计的精度提升到了 1/4 像素(Quarter-Pixel),并对内插滤波器进行了重大升级。
- 亮度内插滤波器: * 1/2 像素位置: 采用 8 抽头(8-tap) 严格推导的 DCT 抽头滤波器(H.264 为 6 抽头)。
- 1/4 像素位置: 采用 7 抽头(7-tap) 滤波器。
- 更长、更精确的滤波器能够有效保留高频纹理,避免多次内插导致的图像模糊,从而使运动补偿的残差能量大幅下降。
- 色度内插滤波器: 针对 4:2:0 采样,色度达到 1/8 像素精度,采用 4 抽头滤波器。
- 分数像素搜索策略: 通常以整像素最佳点为中心,先对周围 8 个 1/2 像素点进行搜索评估;锁定最优 1/2 像素点后,再在其周围的 1/4 像素点中进行最终的精细搜索。
率失真优化(RDO)驱动的决策准则
运动估计的核心不是一味寻找残差最小的点,而是在"残差失真(Distortion)"与"编码码流(Rate)"之间寻找最佳平衡点。
率失真代价函数(RD Cost)
在运动估计过程中,每一个候选 MV 的评估都遵循以下代价公式:
JME=D+λmotion⋅RmotionJ_{ME} = D + \lambda_{motion} \cdot R_{motion}JME=D+λmotion⋅Rmotion
- JMEJ_{ME}JME:当前运动估计的综合代价。
- DDD(失真):代表预测残差的轻重。在整像素搜索阶段,为了提高计算速度,通常使用 SAD(绝对误差和) 或 SATD(哈达玛变换后的绝对误差和) 代替真正的 SSE(平方误差和)。
- RmotionR_{motion}Rmotion(码率):编码当前 MVDMVDMVD 序列以及参考帧索引所需的估计比特数。
- λmotion\lambda_{motion}λmotion:拉格朗日乘子,由当前量化参数(QP)决定。
模式决策的阶梯性筛选
由于 RDO 计算(尤其是带有量化和熵编码的完整线)代价极高,HEVC 运动估计采用了多级剪枝策略。首先利用 SAD 快速排除绝大多数整像素点,接着用 SATD 在分数像素和 PU 模式选择间进行细筛,最后仅对极少数表现最优的组合进行完整的 RDO 算力评估,在保证压缩率的同时极大地扼制了算力暴涨。
算法的硬件友好性优化与演进趋势
尽管 HEVC 的运动估计算法带来了极高的压缩比,但其恐怖的计算复杂度给实际落地(特别是实时超高清编码)带来了巨大挑战。因此,现代 HEVC 运动估计的设计重点已向硬件流水线兼容性倾斜。
硬件友好型优化设计
- 数据依赖性消除: 在时域运动矢量预测(TMVP)中,限制参考缓存的访问范围,防止硬件设计中 DDR 带宽因频繁读取前向帧的 MV 而崩溃。
- 并行合并/预测(Merge Estimation Region, MER): 允许并行计算相邻块的 Merge 列表,打破了传统的逐块串行依赖,使 GPU/FPGA 上的大规模并行处理成为可能。
- AMP 模式的快速跳过: 通过分析
2Nx2N块的残差能量和运动向量均匀度,提前预测是否需要启动复杂的非对称划分,从而跳过 70% 以上不必要的运动搜索。
总结与未来演进
HEVC 运动估计算法通过四叉树灵活拓扑 、高精度的 AMVP/Merge 预测机制 、8-tap 高级分数像素内插 以及严格的 RDO 决策,相比 H.264 提升了近 50% 的压缩效率。
随着 4K/8K 视频和超低延时直播场景的全面普及,当下的 HEVC 运动估计正在深度融合 机器学习与 AI 预测(如利用神经网络提前预测 CU/PU 划分剪枝),并为下一代 VVC(H.266)中更复杂的仿射运动估计(Affine ME)和光流修正(BIO)奠定了坚实的架构基础。