AI测试Agent的技术选型,开源和自研是同一条路线上的不同起点,选型偏差的代价是时间和人力成本。本文拆解三个问题:开源和自研各自的能力边界在哪、不同场景该走哪条路、选了开源后续会不会走向自研。
01 行业格局:开源框架已经够多了,但没一个能直接用
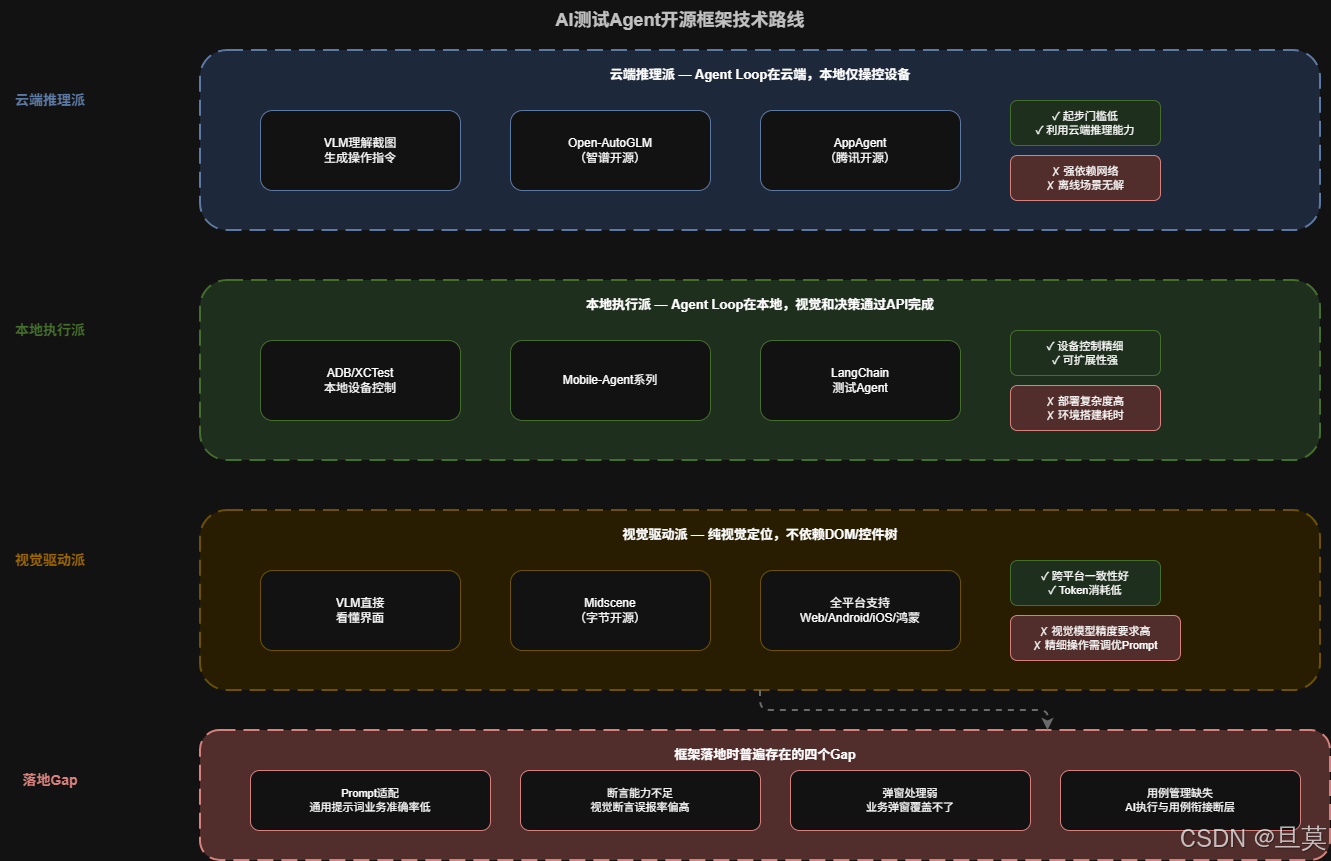
先看现状。2024-2026年间,AI测试Agent领域的开源框架出现了爆发式增长,按技术路线大致分三派:
云端推理派:Agent Loop跑在云端,通过视觉语言模型(VLM)理解截图、生成操作指令,本地只负责接收指令和操控设备。代表项目有Open-AutoGLM(智谱开源)、AppAgent(腾讯)。优势是利用云端大模型推理能力,起步门槛低;劣势是强依赖网络,离线场景无解,响应延迟受网络影响。
本地执行派:Agent Loop在本地运行,视觉理解和决策推理通过调用模型API完成,设备控制通过ADB/XCTest等本地工具链实现。代表项目有Mobile-Agent系列、部分基于LangChain的测试Agent。优势是对设备控制更精细,可扩展性强;劣势是需要自行搭建本地环境,部署复杂度更高。
视觉驱动派 :纯视觉定位,不依赖DOM结构或控件树,通过VLM直接"看懂"界面。代表项目有Midscene(字节开源),支持Web/Android/iOS/桌面/鸿蒙全平台。优势是跨平台一致性好、Token消耗低(据官方数据比传统方案降低约80%);劣势是对视觉模型精度要求高,精细化操作场景需要调优Prompt。
此外还有一批Agent评测框架(AgentBench、AgentBoard、WebArena、SWE-bench等),专注评估Agent能力而非执行测试,本文不做展开。
框架够多,但直接拿来做项目落地时普遍存在四个Gap:
- Prompt适配问题:开源方案的提示词是通用的,每个项目的测试场景各有特点,通用提示词在你的业务上准确率可能只有50-60%
- 断言能力不足:现有方案多聚焦于操作执行,缺少灵活的业务级断言能力,视觉断言误报率偏高(据行业实测数据约15-20%)
- 弹窗处理弱:弹窗是移动端测试的高频干扰因素,开源框架大多只提供通用弹窗关闭规则,业务弹窗覆盖不了
- 用例管理缺失:测试用例如何与AI执行无缝衔接、如何做增量维护、如何量化覆盖率,开源方案较少涉及
这四个Gap意味着:开源框架能帮你快速"跑起来",但"跑好"还需要大量定制工作。
02 开源框架的边界:哪些问题它解决不了
模型绑定------换模型的隐性成本
不少开源框架跟特定模型深度绑定。调用方式专为某个模型API写,提示词针对某个模型优化,输出格式按某个模型的返回结构解析。看起来换模型只需改个API Key,实际上:
- 提示词可能要重写(不同模型对指令格式的偏好不同)
- 解析逻辑可能要改(不同模型的输出格式、思维链位置不同)
- 甚至Agent Loop的交互方式都要调整(有些模型支持Function Calling,有些不支持,交互方式完全不同)
一个典型问题:思维链格式不统一。有些模型把思维链放在独立的reasoning_content字段返回,有些直接塞在content里用特殊标签(如<think>...</think>)包裹。如果你的解析层只处理content字段,就会把思维过程当成动作指令去执行,导致Agent行为异常。这类兼容性问题只有在具体对接时才能暴露,无法提前穷举。
动作指令集固定------扩展牵连多层
框架预定义了Tap、Swipe、Type、Back、Home等基础动作,覆盖常见的APP交互场景。但更复杂的操作------长按拖拽、多指手势、截取特定区域做OCR验证、读取短信验证码、切换系统开关------框架动作集不支持,需要自行扩展。
扩展动作涉及三层联动:
- 提示词层:指令描述要加新动作的说明,Agent才知道有这个能力可用
- 解析层:正则匹配或JSON解析要加新动作的格式识别
- 执行层:方法映射要加新动作到具体API调用的对应关系
改一处联动三层,且修改后原有动作的解析可能受到影响。
异常处理与业务不匹配------通用逻辑的盲区
开源框架的异常处理是通用的:元素找不到就重试、弹窗出现就按规则关闭、页面卡住就Back。但特定业务场景的异常远比这复杂:
- 车机测试:CAN信号丢失导致黑屏、TSP接口超时导致状态不一致
- 支付场景:风控弹窗、支付密码键盘、网络中断后重试幂等性
- 金融合规:特定操作需要二次确认、敏感数据不能出现在日志里
通用异常处理逻辑覆盖不了这些场景,而在框架外部叠加补丁逻辑,维护成本会随补丁数量快速增长。
什么时候开源框架是正确起点
尽管有上述边界,开源框架在以下场景仍然是合理选择:
| 条件 | 说明 |
|---|---|
| 第一次做AI测试Agent | 需要快速跑通一个能用的基线,验证"AI测试行不行" |
| 测试场景通用 | 常见APP交互、标准UI操作,不需要复杂异常处理 |
| 团队技术储备有限 | Python基础能力有,但不熟悉Agent架构和LLM API对接 |
| 时间压力大 | 2-4周内必须看到效果 |
| 探索阶段 | 目标是验证可行性,不是建设生产级系统 |
03 自研的成本构成:可见部分与隐性部分
自研的优势在于完全可控------架构、模型、提示词、动作集都可以按需设计。但可控性的代价容易被低估。
可见成本
架构设计和基础编码。 一个完整的AI测试Agent框架至少包含:Agent Loop主循环、截图和设备信息获取、模型调用封装、动作指令解析、设备操作执行、上下文管理、步数保护、结果返回。仅基础模块的代码量就在3000行以上,还不算提示词调优和异常处理。
从零到第一版可用的框架,1-2人投入通常需要2-3个月,后续调优和异常处理再追加1-2个月------前提是团队已有LLM API调用经验,学习成本另计。
提示词工程。 系统提示词(角色定义+动作指令集+执行规则)、测试用例提示词、AI验证提示词------三层提示词都需要反复调试。而且提示词不是写完就固定,模型在迭代、业务在变、场景在扩展,提示词得跟着调。实际项目中提示词模板迭代数十版属于常态,每版通常在批量测试后才会暴露问题。
模型对接。 不同模型的API调用方式、输入格式、输出格式、思维链处理都不一样。自研意味着要自己处理这些差异:在线API和本地部署(Ollama/vLLM)的接口适配、流式响应的解析、JSON格式不稳定时的兼容处理、思维链的提取和过滤。
隐性成本
异常处理的工程量。 框架跑起来之后会持续遇到异常:截图时页面未加载完成、模型返回动作格式错误、坐标偏移点到相邻元素、弹窗打断操作流程、网络波动导致API超时、设备离线导致ADB断连。实测数据显示,框架中约30%的代码在处理异常和边界情况,正常流程的代码占比反而更小。
调试Agent跑偏的投入。 Agent跑偏属于高频问题。自研框架没有现成的调试工具,需要逐条分析日志、追踪Agent每一步的决策路径、定位跑偏原因。其中一类情况特别耗费精力:Agent的行为跟预期不一致但逻辑自洽,无法直接判定为缺陷,需要设计专门的测试用例来确认。
持续维护的精力。 模型在更新(API变更、返回格式变更、能力变化),框架在迭代(新功能、新异常、新场景),依赖库在升级。自研意味着这些全要自行跟进。自研框架长期不维护会导致兼容性劣化,严重时无法正常运行。
什么时候自研是合理选择
| 条件 | 说明 |
|---|---|
| 有明确且深度的定制需求 | 开源框架的能力结构满足不了(特殊设备控制、特殊断言逻辑、多模型协同) |
| 团队有足够技术储备 | Python+异步编程+LLM API调用+测试框架经验,至少2人具备这些能力 |
| 长期投入的决心 | 持续迭代、作为基础设施建设 |
| 安全合规硬约束 | 数据必须本地部署,不能出内网;需要过安全审计 |
| 多场景/多客户交付 | 定制需求多、变化快,开源框架的约束成为负担 |
04 场景匹配:不同场景到底该选哪条路
不是所有项目都适合同一条路线。以下按五个典型场景分析。
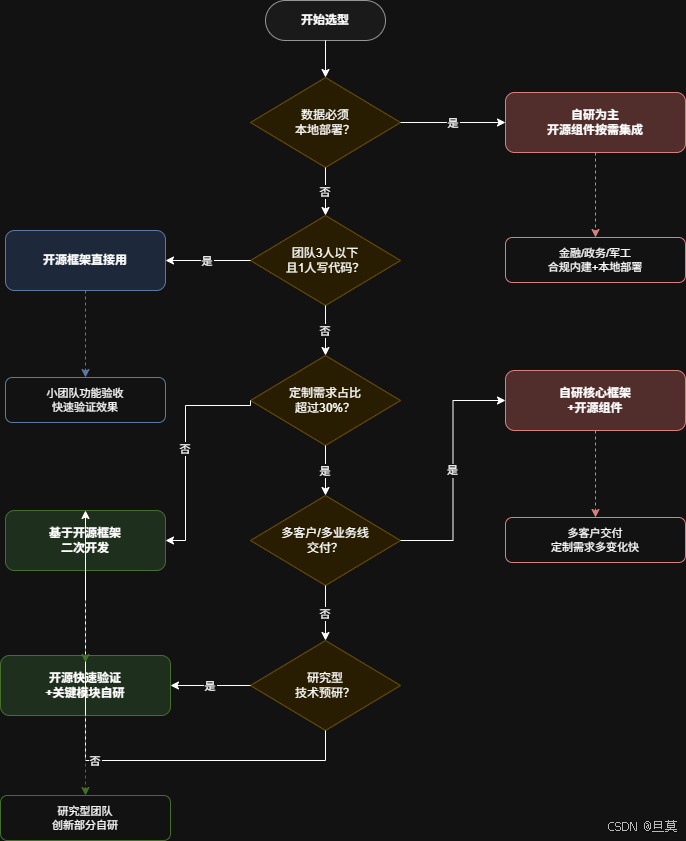
场景A:小团队功能验收(3人以下,1人能写代码)
特征:SaaS产品每周发版,发版前手动回归核心流程。需求是AI帮忙跑主流程,省人力。
推荐路线:开源框架直接用。
理由:需求明确(核心流程冒烟测试),步骤固定,不需要复杂异常处理。开源框架装好、配好API Key、写几条测试步骤就能跑。省下来的时间应该去验证业务价值,而不是搭框架。
注意点:这个阶段不宜在框架层面过度投入,目标是验证效果而非构建架构。等跑顺了、发现框架满足不了的时候,再考虑二次开发。
场景B:中型团队持续回归(5-10人,2-3人能写代码)
特征:产品迭代频繁,200+条用例需回归,弹窗类型多,设备种类多,传统自动化维护成本太高。
推荐路线:基于开源框架二次开发。
理由:场景有定制需求(特定弹窗规则、跨设备适配、业务级断言),纯开源满足不了;但团队规模有限,从零自研投入过大。二次开发能在开源底座上快速补上业务定制层。
二次开发的重点投入方向:
- 提示词层:加入业务上下文和执行约束,投入产出比最高
- 弹窗处理层:补充业务特定的弹窗规则
- 验证层:加文本分析模型做交叉验证,降低视觉断言误报
场景C:多客户/多业务线交付(10人以上,5人以上能写代码)
特征:给不同客户提供AI测试服务,每个客户的APP不同、测试需求不同、安全要求不同。有的要本地部署模型,有的要对接特定缺陷管理系统,有的需要多Agent并行执行。
推荐路线:自研核心框架+开源组件。
理由:定制需求多、变化快,开源框架的约束成为负担。但并非全部自研------设备控制用Airtest、OCR用PaddleOCR、本地模型推理用Ollama,成熟的开源组件直接用,避免重复造轮子。自研的是Agent调度层、任务编排层、多租户配置层这些业务逻辑。
场景D:合规敏感行业(金融/政务/军工)
特征:数据不能出内网,所有模型必须本地部署,操作日志要可审计,特定操作需要二次确认。
推荐路线:自研为主,开源组件按需集成。
理由:合规约束是硬性的,开源框架在安全审计层面的专门设计较少。即使框架本身开源可审计,其依赖链(模型调用、数据传输、日志格式)是否满足合规要求也需要逐一验证。从架构设计阶段就把合规要求内建进去,成本更低、风险更可控。
关键设计点:模型推理全部走本地(Ollama/vLLM部署)、敏感数据脱敏在Agent层面强制执行、操作日志结构化记录支持审计回溯、二次确认机制在执行层硬编码。
场景E:研究型团队/技术预研
特征:不做生产级交付,目标是验证新方法、新模型、新架构的可行性。比如探索多Agent协同测试、RAG增强测试知识库、视觉自愈能力等前沿方向。
推荐路线:开源框架快速验证+关键模块自研。
理由:研究型工作需要快速迭代,开源框架提供基础设施让团队聚焦在创新点上。但创新部分(比如新的记忆架构、新的断言策略)需要自研,开源框架无法提供参考实现。
05 演进路径:从开源走向深度定制是大概率事件
选了开源,后续是否一定会走向自研?结论是:未必走向纯自研,但走向深度定制是大概率事件。
演进的触发信号
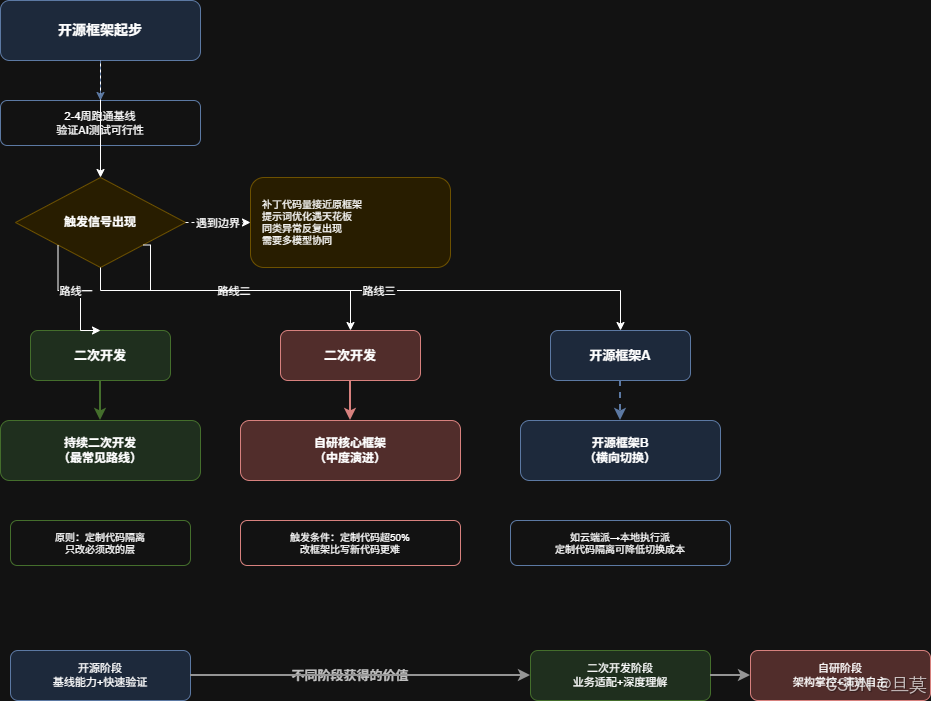
从开源起步的团队,出现以下信号时说明纯开源已经不够用了:
信号一:补丁代码量接近原框架代码量。 这意味着框架外部叠加的定制逻辑已经跟框架本身同等复杂,维护两套逻辑的成本高于维护一套。
信号二:提示词优化到某个点后效果不再提升。 通用提示词在业务场景下优化到一定阶段后,继续调整提示词已经无法带来显著提升。此时的瓶颈往往在框架架构层面------比如动作解析方式限制了指令设计空间、上下文管理方式限制了信息传递效率。
信号三:同类异常反复出现,框架层面无法根治。 业务弹窗框架处理不了,每次在外部叠加补丁逻辑,补丁之间可能互相影响。这是架构层面的局限,局部修补无法解决。
信号四:需要多模型协同,但框架只支持单模型。 当前行业趋势是"专用模型做专用事"------Agent执行用一个模型、视觉验证用另一个模型、文本分析用第三个模型。如果框架在架构上不支持多模型协同,你要么放弃这个能力,要么大改框架。
三条演进路线
路线一:开源→二次开发→持续二次开发(最常见)
保留框架核心组件(Agent Loop、设备控制层、动作解析层),在业务相关层做持续定制。这是性价比最高的路线,也是多数团队实际走的路线。
关键原则:将定制代码隔离。 建立独立目录或模块,所有定制代码放在其中,与框架原版代码保持清晰边界。上游框架更新时可选择性地合入,避免被更新牵着走。
风险点:框架大版本升级(如v1到v2)且架构有变化时,定制代码可能需要大幅调整。此风险无法完全消除,但可通过控制定制范围来降低------只改必须改的层,不碰框架核心。
路线二:开源→二次开发→自研核心框架(中度演进)
当二次开发的代码量超过框架原版的50%以上,且修改框架代码的难度已超过编写新代码时,可考虑自研核心框架。这里的"自研核心框架"并非从零开始,而是将开源框架中积累的理解、已知的边界、调优过的提示词,沉淀到更贴合业务的架构中。
触发条件:团队对框架的理解深度已超过框架作者对特定业务的理解深度。
路线三:开源→开源→换开源(横向切换)
演进路径不限于纵向深化。当前框架的架构约束过强但需求尚未达到自研程度时,切换到更灵活的开源框架可能是更合理的选择。
比如从云端推理派框架切换到本地执行派框架,获得对设备控制层和模型调用层的完全掌控;或者从单一Agent框架切换到支持多Agent协同的框架,获得更灵活的任务编排能力。
切换成本取决于定制代码与框架的耦合程度。遵循"定制代码隔离"原则的情况下,切换时只需重新适配接口层,核心业务逻辑可复用。
实际演进模式
项目中的演进很少是纯线性的,更常见的模式:
- 开源框架起步(2-4周跑通)
- 发现边界,开始二次开发(持续1-3个月)
- 二次开发到一定程度,评估是否需要自研核心层
- 如果自研,用开源框架作为参照和基线,逐步替换核心组件
- 自研核心框架稳定后,开源组件仍然在使用(Airtest、PaddleOCR等)
这个过程中,不同阶段获得的价值也不同:
- 开源阶段:获得基线能力和快速验证
- 二次开发阶段:获得业务适配能力和深度理解
- 自研阶段:获得架构掌控力和演进自主权
06 二次开发的技术边界:改哪些层,不动哪些层
二次开发是多数团队最终到达的位置。技术上存在明确的分界线。
值得改的层
提示词层------投入产出比最高。通用提示词缺少业务上下文,Agent不知道在测什么APP、页面上应该有什么元素、哪些操作不可逆。补上这些信息,同样的Agent Loop,执行效果差距可达20-30%。
动作扩展层。在框架预定义动作之外加自定义动作:读取短信验证码、切换WiFi开关、截取特定区域做OCR验证。只要符合框架的动作格式规范就能接入,不需要改解析逻辑。
验证层。加文本分析模型做交叉验证------视觉模型看截图判断界面状态,文本模型分析执行结果描述是否语义匹配。两种验证互补,漏判概率显著降低。
弹窗处理层。补充业务特定的弹窗规则,每条规则包含触发文字、操作文字、置信度阈值和操作后等待时间。这些规则跟通用规则并行运行。
不要动的层
Agent Loop主循环。感知→决策→执行→判断的循环设计已经过充分验证,退出条件、步数保护、上下文管理逻辑无需重写。修改主循环容易引入新的问题。
模型调用封装。框架的模型调用层通常已处理流式响应解析、超时重试、错误处理。换模型只需改配置参数,重写调用层会丢失已验证的容错逻辑------实践中曾出现重写后遗漏超时重试逻辑,导致Agent在API超时场景下无限等待的问题。
动作解析层。结构化指令的解析逻辑是框架的骨架。加新动作可在现有解析逻辑中增加分支,但不应修改解析规则本身。
07 行业趋势:"开源vs自研"二元框架正在失效
2026年的行业趋势正在使"开源vs自研"的二元选型框架逐渐不合时宜。三个方向值得重点关注:
趋势一:协议层标准化
MCP(Model Context Protocol,Anthropic 2024年底提出)正在成为Agent调用外部工具的事实标准。它统一了工具接入的接口规范------只要工具实现了MCP Server,就能被任何支持MCP的Agent发现和调用。
这意味着"自研"的颗粒度变细了。以往自研意味着从Agent Loop到设备控制全自行编写,现在可以自研MCP Server暴露测试能力,然后让任何Agent框架来调用。自研的重点从"造框架"转向"造工具"。
据微软Build 2026大会发布的信息,开源评估标准和运行时控制协议正在推进标准化,目标是让Agent的可信评估和可控执行不依赖特定框架。这进一步削弱了"选框架"的权重------框架可替换,能力和协议才是团队的核心资产。
趋势二:专用模型分化
当前行业正在走向"专用模型做专用事"的多模型协同模式:Agent执行用一个模型、视觉验证用另一个模型、文本分析用第三个模型。据CSDN上的实测数据,多模型协同方案的断言准确率比单模型方案高10-15个百分点。
这个趋势对选型的影响是:框架是否支持多模型协同,正在成为新的分水岭。 不支持多模型协同的框架,能力天花板会更早到来。
趋势三:Agent能力评测走向专业化
AgentBench、WebArena、SWE-bench等评测基准正在从学术走向工程。据清华大学CoAI实验室的评测数据,当前主流Agent框架在标准测试集上的任务完成度差异很大(从45%到85%不等),但这个数据不能直接等同于"在你的业务上表现如何"。
评测标准化的意义在于:无需依赖框架的README或GitHub Star数做判断,而是可以用标准化评测集对方案做基线测试,用数据驱动选型决策。
08 选型决策框架
五维度评估
| 维度 | 适合开源起步 | 适合自研起步 |
|---|---|---|
| 团队技术能力 | Python基础,能改脚本但不熟悉Agent架构 | 有Agent开发经验,熟悉LLM API和异步编程 |
| 定制需求强度 | 通用UI测试,标准操作流程 | 特殊设备控制、特殊断言逻辑、多模型协同 |
| 时间预期 | 2-4周内要看到效果 | 可以接受2-3个月的建设期 |
| 维护投入 | 有专人但不充裕 | 有持续迭代的精力,框架本身也是产品 |
| 安全合规 | 数据可以走公网API | 数据必须本地部署,不能出内网 |
一个实用的判断方法
将计划实现的AI测试能力逐项列出,标注每项是通用能力还是业务特有能力。通用能力占比超过70%,开源起步;特有能力占比超过30%,认真考虑自研或二次开发。
还有一个易忽略的维度:维护责任的归属。 开源框架出问题可以查issue、看文档、等社区修复。自研框架出问题只能自行排查和修复。如果团队中只有一个人能维护自研框架,人员变动会直接影响框架的可持续性。
演进规划
选型应视为路线规划而非一次性决策:
- 起步:开源框架直接用,快速验证可行性(2-4周)
- 遇到边界:在开源基础上做二次开发,补上业务定制层(1-3个月)
- 定制需求超过框架承载力:自研核心框架+开源组件
这三个阶段不要求严格按序执行,但多数团队的实际路径确实是从左到右逐步演进。关键是在每个阶段选对路线,不提前投入也不滞后修补。
起步阶段的目标是跑通验证,迭代优化在跑通之后。两个阶段的顺序不应颠倒。