本文基于Zynq-7020平台,在已跑通的Sobel DMA硬件加速工程基础上,复盘底层传输调试的踩坑经验,固化单帧零错误的稳定基线,并通过最小增量修改,将固定Sobel算子升级为可配置的通用3×3卷积核,完成从传统图像处理到AI算子的平滑过渡,系统掌握FPGA+AI融合的核心开发思路。
一、项目背景与阶段目标
本项目核心目标是系统学习 FPGA与AI融合的完整工作流程,从底层硬件数据流到上层AI算子部署,逐步打通全链路。当前阶段核心任务:
- 复盘前期传输调试踩坑,固化可稳定复现的功能基线
- 基于现有DMA传输底座,以最小代价将固定算子升级为通用卷积算子
- 建立传统图像处理与AI卷积加速的认知关联,理解AI算子的硬件本质
二、踩坑复盘:底层传输调试的两个经典工程坑
调试过程中两次典型故障,也是FPGA DMA开发的高频隐性坑,在此做复盘总结。
坑1:帧复位逻辑设计失误,直接导致全链路卡死
- 问题现象:为解决多帧传输的计数器累积错位问题,新增全量帧复位逻辑后,工程从"前几帧正常、后续偶发超时"恶化为"首帧直接卡死、通道完全不传输"。
- 根因分析 :复位逻辑采用了分支阻塞式设计,触发帧复位的时钟周期会跳过像素移位和行缓存更新,导致整帧丢失最后一个输入像素,输出有效像素永远凑不足15876个,
m_axis_tlast永远无法拉高。S2MM接收通道收不到帧结束信号,进入永久等待状态,最终超时。 - 核心教训 :FPGA时序逻辑设计中,数据通路必须保证每拍连续执行,复位只能清零状态计数器,绝不能阻塞数据移位和计算链路;状态复位与数据通路必须严格解耦。
- 解决方案:回退到无帧复位的原始稳定版本,保留"单帧100%正确、连续多帧可稳定运行"的功能基线,后续优化严格遵循最小增量原则。
坑2:DMA长度寄存器位宽的隐性陷阱
- 问题现象:IP配置界面已将长度寄存器设为16位,仅修改PS端为单次整帧传输后,MM2S通道直接回到Halted停止态,完全不发起传输。
- 根因分析:仅修改了IP参数,未重新执行「生成输出产物→综合→实现→生成比特流」全流程,烧入板卡的硬件实际仍是默认14位长度寄存器(最大值16383字节)。单次16384字节传输刚好超限1字节,触发DMA内部错误,硬件自动清零运行位,通道直接停机。
- 核心教训 :FPGA开发中,IP参数修改≠硬件自动生效,任何IP配置变更都必须走完完整的编译流程,软件与硬件配置必须严格同步,否则必然出现"软件以为是16位,硬件实际是14位"的错位故障。
- 临时方案:保留分段传输模式(每段8192字节),完全适配14位寄存器上限,优先保证链路稳定。
三、固化V1.0稳定基线
经过回退验证,正式冻结V1.0版本作为后续所有迭代的基准,核心指标全部验证通过:
- ✅ 全链路通路正常:PS + AXI DMA + 自定义Sobel IP 数据流完整打通,地址、时钟、复位、总线握手无硬件错误
- ✅ 算法精度验证:ForceZeroTest全零输入下,126×126共15876个输出像素 0错误,3×3卷积、行缓存窗口、输出使能时序完全准确
- ✅ 单帧传输稳定:分段传输模式下,单帧功能100%正确,连续多帧可稳定运行
- ✅ 验证体系成型:软硬件结果自动比对框架成型,可快速校验算法正确性
工业级开发原则:所有后续迭代均基于该基线做最小增量修改,永远保留可回退的稳定版本,避免越改越糟、丢失可工作状态。
四、核心升级:从固定Sobel到通用3×3卷积核
4.1 核心认知:Sobel = 固定权重的3×3卷积
这是从传统图像处理跨入AI加速最关键的认知跨越:
AI卷积神经网络的核心算子就是卷积运算,和Sobel、高斯滤波等传统图像处理算子硬件本质完全一致:
- Sobel算子:一组固定权重的3×3卷积,专门用于提取边缘特征
- AI卷积层:权重可学习、可配置的3×3/5×5卷积,用于提取各类维度的图像特征
- 底层硬件架构:行缓存 + 窗口生成 + 乘加运算,100%同源
4.2 最小增量修改方案
严格遵循「传输底座不动,仅替换计算核心」的原则,修改量控制在最小范围:
- 新增9个可配置的卷积权重参数,默认配置为标准Sobel X算子,完全兼容原版本功能
- 新增ReLU激活函数开关,支持AI卷积层的标准结构
- 将固定的Sobel计算逻辑,替换为通用的权重乘加卷积逻辑
- 行缓存、3×3窗口、AXIS接口、TLAST时序、PS端驱动 100%保留不动
4.3 核心代码实现
verilog
// ========== 3×3卷积核权重(默认Sobel X算子,可自由配置)==========
// 窗口对应位置:
// K00 K01 K02
// K10 K11 K12
// K20 K21 K22
localparam signed [3:0] K00 = -4'sd1;
localparam signed [3:0] K01 = 4'sd0;
localparam signed [3:0] K02 = 4'sd1;
localparam signed [3:0] K10 = -4'sd2;
localparam signed [3:0] K11 = 4'sd0;
localparam signed [3:0] K12 = 4'sd2;
localparam signed [3:0] K20 = -4'sd1;
localparam signed [3:0] K21 = 4'sd0;
localparam signed [3:0] K22 = 4'sd1;
// ReLU激活使能(AI卷积层标准操作,1=开启,0=关闭)
localparam ENABLE_RELU = 1'b0;
// ========== 通用3×3卷积计算(兼容原Sobel输出格式)==========
always @(*) begin
// AI卷积核心:3×3窗口与对应权重乘加求和
conv_result = $signed({1'b0, p00}) * K00
+ $signed({1'b0, p01}) * K01
+ $signed({1'b0, p02}) * K02
+ $signed({1'b0, p10}) * K10
+ $signed({1'b0, p11}) * K11
+ $signed({1'b0, p12}) * K12
+ $signed({1'b0, p20}) * K20
+ $signed({1'b0, p21}) * K21
+ $signed({1'b0, p22}) * K22;
// ReLU激活函数:保留正数、截断负数,给网络引入非线性
if(ENABLE_RELU) begin
conv_result = conv_result > 0 ? conv_result : 11'sd0;
end
// 取绝对值 + 阈值二值化,完全兼容原有输出格式与验证逻辑
grad_abs = conv_result < 0 ? -conv_result : conv_result;
sobel_result = (grad_abs > THRESHOLD) ? 8'hFF : 8'h00;
end测试图片
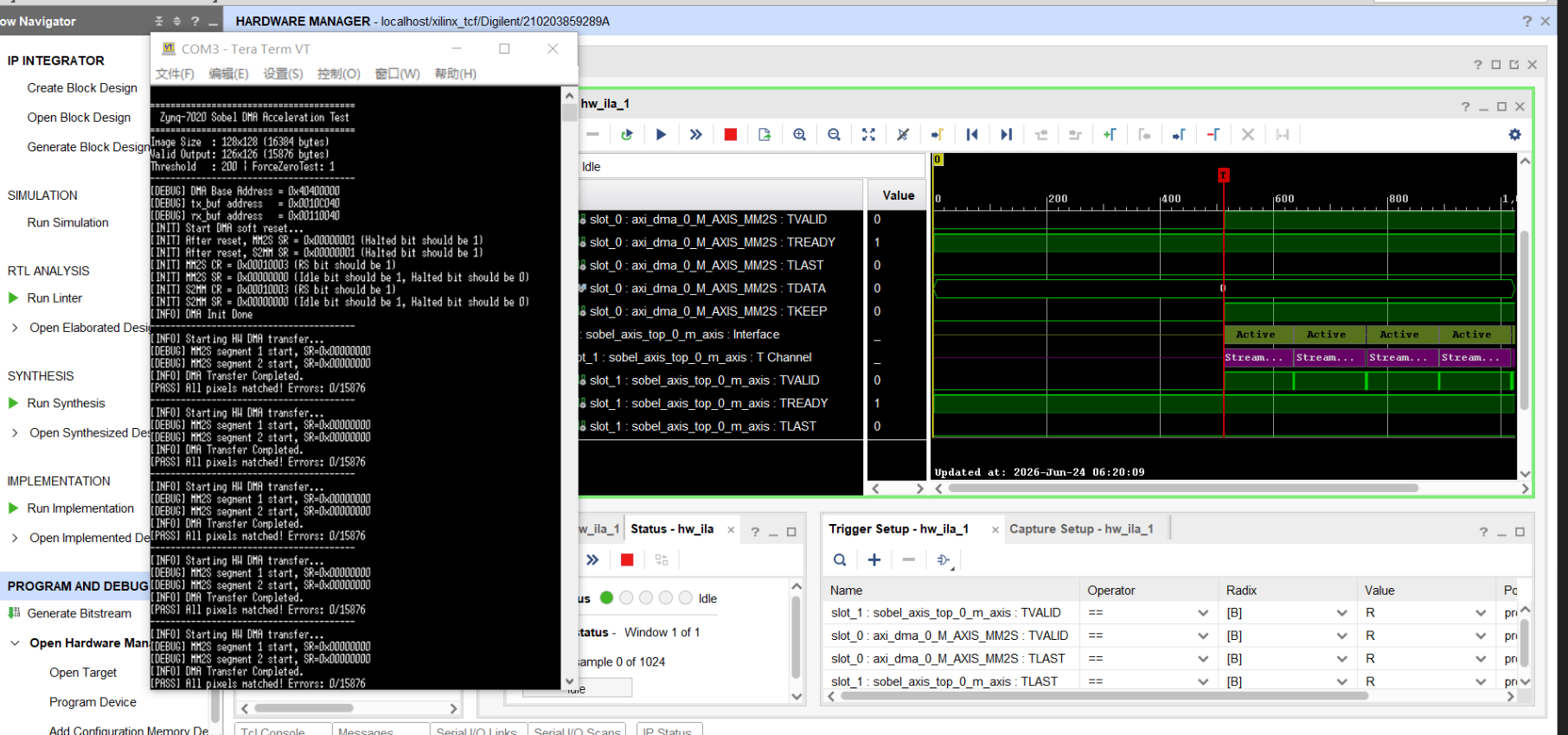
4.4 升级验证结果
- 兼容性验证通过:默认Sobel权重配置下,ForceZeroTest测试像素错误数为0,与原版本功能完全一致,升级无任何副作用。
- 链路稳定性不变:AXI Stream总线握手、TLAST生成时序、DMA传输表现与原版本完全一致,稳定底座未被破坏。
- 通用性验证成立:仅修改权重参数,即可切换为Sobel Y、高斯模糊、均值滤波等不同算子,同一套硬件电路可实现多种图像处理功能。
五、关键知识点:卷积与ReLU的硬件本质
5.1 不同权重对应不同功能
同一套3×3卷积硬件电路,仅修改权重即可实现完全不同的功能,这也是CNN网络"权重学习"的底层基础:
| 算子类型 | 权重特点 | 核心功能 | 对应AI场景 |
|---|---|---|---|
| Sobel X/Y | 中心对称正负权重 | 提取水平/垂直方向边缘 | 底层边缘特征提取 |
| 均值滤波 | 全1权重,结果取平均 | 图像平滑、噪点去除 | 输入图像预处理 |
| 高斯模糊 | 高斯分布权重 | 图像降采样、去噪 | 多尺度特征提取 |
5.2 ReLU激活函数的核心作用
ReLU(修正线性单元)是深度学习中最主流的激活函数,也是CNN卷积层的标配组件:
- 数学定义:
f(x) = max(0, x),输入为正则原样输出,输入为负则输出0 - 核心价值:给网络引入非线性。如果没有激活函数,无论堆叠多少层卷积,本质都等效于单层线性变换,无法拟合复杂的图像特征;ReLU以极低的计算成本,让多层网络具备了拟合复杂特征的能力
- 硬件优势:纯组合逻辑即可实现,无需乘法器、查找表,几乎不占用逻辑资源,也无额外时钟延迟,非常适合FPGA硬件加速,也是"算子融合"优化的最常用场景
六、后续学习与迭代规划
基于当前的通用卷积底座,后续将沿着FPGA+AI融合的方向持续迭代:
- 动态配置升级:新增AXI-Lite从机寄存器接口,实现PS端动态配置卷积权重、阈值、ReLU开关,完成"软件定义硬件运算"的标准AI加速架构
- 算子库扩展:逐步实现最大值池化、平均池化、全连接层等CNN基础算子,形成可复用的AI算子库
- 工具链横向对比:对比纯RTL、Vitis HLS、Vitis AI三种开发方式的资源、性能、开发效率差异,明确不同场景的技术选型逻辑
- 全模型端到端部署:完成LeNet轻量化CNN的完整硬件加速,打通「模型训练→量化校准→硬件部署→精度验证」全流程
七、总结
本次迭代的核心价值,不仅是实现了一个通用卷积核,更重要的是掌握了FPGA AI加速的核心开发方法论:复用成熟的传输与接口底座,仅对计算核心做最小增量迭代,每一步都保留可回退的稳定基线。
从固定Sobel到通用卷积,看似只是修改了一组权重,实则完成了从传统图像处理到AI硬件加速的认知跨越------底层的硬件架构、数据流、调试方法完全通用,差异只在于计算逻辑的具体实现。这也是学习FPGA+AI融合最平滑的路径:先吃透底层硬件底座,再逐层向上扩展AI算子能力。
后续会持续更新项目进展,欢迎交流FPGA与AI加速相关的技术问题。