用工程化方法量化 AI 搜索曝光、引用质量、检索命中与内容收益
适用对象:GEO / SEO / AI 产品 / 数据工程 / 技术运营团队
内容范围:技术实现、系统架构、部署方式、代码示例、落地清单
版本:2026 技术发布版
GEO 技术文章增强版
GEO 可观测性与评估体系:指标、日志、实验与自动化诊断
用工程化方法量化 AI 搜索曝光、引用质量、检索命中与内容收益
适用对象:GEO / SEO / AI 产品 / 数据工程 / 技术运营团队
内容范围:技术实现、系统架构、部署方式、代码示例、落地清单
版本:2026 技术发布版
一、核心定位
GEO 可观测性用于回答三个问题:品牌是否被 AI 提及?提及时是否准确、有利、可点击?当曝光下降或答案错误时,系统能否定位原因并触发修复?因此,GEO 评估不能只看流量,还要看 AI 引用、答案忠实度、证据覆盖率、查询意图覆盖和内容更新效率。
- ● 建立标准查询集:品牌词、品类词、场景词、比较词、风险词。
- ✓ 同时评估检索侧和生成侧:只看最终答案无法定位问题。
- ◆ 日志要保留 prompt、检索命中、引用、模型版本和页面版本。
- ▲ 监控异常:错误引用、负面摘要、竞品替代、品牌缺失、过期内容。
- ↻ 每次内容更新都要做 A/B 或前后对比。
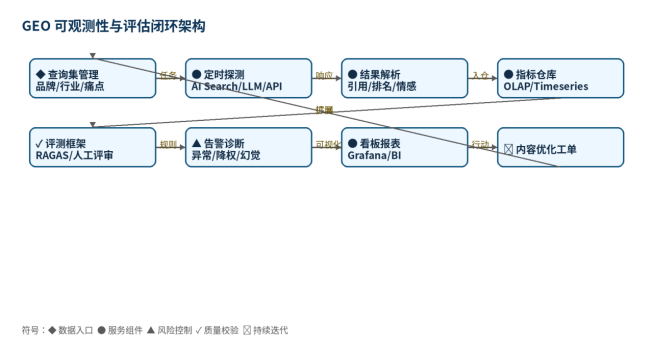
二、系统架构与模块划分
可观测性平台建议由"探测任务调度器、结果采集器、解析器、指标仓库、评测引擎、告警系统和看板"组成。定时任务向 AI 搜索或内部 RAG 系统发起标准问题,解析回答中的品牌、链接、引用和情感,再写入指标仓库。评测引擎对答案做忠实度、相关性、完整性、引用质量评分,最终驱动内容优化工单。
图 1 技术架构与流程闭环
三、关键数据模型与工程逻辑
|-----------|-----------------|----------------------------------|--------|
| 模块/指标 | 技术含义 | 计算/实现 | 频率 |
| 品牌提及率 | AI 回答中出现品牌的比例 | mention_count / total_queries | 日级/周级 |
| 自有引用占比 | 引用中来自官网/自有内容的比例 | owned_citations / all_citations | 日级 |
| 答案忠实度 | 回答是否被证据支持 | LLM Judge + 人工抽检 | 批次级 |
| 意图覆盖率 | 查询集覆盖业务场景的程度 | covered_intents / target_intents | 月级 |
| 内容修复时长 | 从发现问题到发布修复的时间 | resolved_at - detected_at | 工单级 |
工程实现时建议把 GEO 拆成"离线处理"和"在线服务"两条链路。离线处理负责采集、清洗、质量评分、切块、嵌入和索引构建;在线服务负责权限过滤、混合检索、重排序、上下文压缩、答案生成和审计记录。这样的拆分可以让内容更新和用户访问互不阻塞,也便于扩容和故障隔离。
符号说明:◆ 表示数据入口,● 表示核心服务,▲ 表示风险控制,✓ 表示质量校验,↻ 表示持续迭代。
四、技术实现代码示例
指标事件 JSON
{
"query_id": "q_brand_001",
"query": "GEO 系统怎么搭建?",
"engine": "ai_search",
"brand_mentioned": true,
"citation_count": 3,
"owned_citation_count": 1,
"sentiment": "positive",
"answer_faithfulness": 0.87,
"retrieval_hit_rate": 0.75,
"model_version": "2026-06",
"observed_at": "2026-06-24T10:00:00+08:00"
}Python 解析与评分示例
python
def score_geo_result(result, owned_domains):
citations = result.get("citations", [])
owned = [c for c in citations if any(d in c["url"] for d in owned_domains)]
brand_hit = result["brand"].lower() in result["answer"].lower()
citation_share = len(owned) / max(len(citations), 1)
faithfulness = judge_faithfulness(result["answer"], citations)
return {
"brand_mentioned": brand_hit,
"owned_citation_share": round(citation_share, 4),
"answer_faithfulness": faithfulness,
"risk_level": "high" if faithfulness < 0.65 else "normal",
}Prometheus 指标定义
bash
# HELP geo_brand_mention_rate Brand mention rate in AI answers
# TYPE geo_brand_mention_rate gauge
geo_brand_mention_rate{engine="ai_search",intent="category"} 0.42
# HELP geo_owned_citation_share Owned domain citation share
# TYPE geo_owned_citation_share gauge
geo_owned_citation_share{engine="ai_search"} 0.31
# HELP geo_answer_faithfulness Faithfulness score of generated answer
# TYPE geo_answer_faithfulness gauge
geo_answer_faithfulness{query_group="brand"} 0.86Kubernetes CronJob 探测任务
html
apiVersion: batch/v1
kind: CronJob
metadata:
name: geo-observer
spec:
schedule: "0 */6 * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: observer
image: geo-observer:1.0
env:
- name: QUERY_SET
value: "brand,category,comparison,risk"
- name: METRICS_ENDPOINT
value: "http://geo-metrics:8080/events"五、部署方式与运行环境
小团队可以先使用 Docker Compose 启动 API、数据库、向量库、缓存和任务队列,适合 PoC、内部测试和单品牌场景。进入生产后建议迁移到 Kubernetes,以 Deployment 承载 API 服务,以 CronJob 承载探测/索引任务,以 StatefulSet 或托管云服务承载数据库和向量库。
|--------|----------------------------------|--------------------|---------------|
| 阶段 | 部署方式 | 资源建议 | 适用场景 |
| PoC 单机 | Docker Compose | 1 台 4C8G 服务器即可验证流程 | 成本低、部署快、适合演示 |
| 中小规模生产 | Kubernetes + 托管 PostgreSQL + 向量库 | API 多副本,索引任务独立扩容 | 可灰度、可回滚、可监控 |
| 集团级多租户 | Kubernetes + 消息队列 + 数据湖 + 多区域灾备 | 按租户隔离索引和密钥 | 权限、审计、SLA 更完整 |
推荐发布路径:dev 环境做单元测试和样例索引,staging 环境做完整查询集评估,production 环境启用灰度发布、错误预算和自动回滚。索引发布建议采用 blue/green index:新索引构建完成并通过评估后再切流,避免半成品知识进入线上回答。
六、落地检查清单
- 每个指标必须绑定 query_id、engine、model_version 和 content_version。
- 不要只看单次 AI 回答,要看多次采样后的稳定性。
- 告警阈值应区分品牌词、品类词和风险词。
- 评估结果要能反向定位到具体页面、知识块或引用源。
- 看板至少包含趋势、异常列表、Top 问题、竞品对比和修复状态。