本文接续上一篇文章Gemma4基于LORA的情绪分类单卡微调,继续使用垃圾邮件分类数据集进行LoRA微调测试。
一、垃圾邮件数据集介绍
SMS Spam Collection 是一个公开的带标签短信数据集,专门用于基于内容的垃圾短信检测研究。数据集包含 5,574 条 真实英文短信,每条都被标记为 ham(正常短信)或 spam(垃圾短信),是自然语言处理与文本分类领域最经典的基准数据集之一。
-
数据来源:UCI Machine Learning Repository
-
官方链接:https://archive.ics.uci.edu/dataset/228/sms+spam+collection
-
格式:制表符分隔的文本文件(TSV),无表头,每行一条消息,两列分别为标签和文本内容。
-
文件名称:SMSSpamCollection(可重命名为 .tsv)
二、微调
1、修改PROMPT
将SYSTEM_PROMPT和LABEL_PATTERN修改为如下形式:
python
SYSTEM_PROMPT = """You are an spam classification assistant.
Read the user's text and answer with exactly one label.
Only choose from: spam, ham.
Return only the label and nothing else.""" # change
LABEL_PATTERN = re.compile(r"(spam|ham)", re.IGNORECASE)2、修改数据集配置
python
# load dataset
import urllib.request
import zipfile
import os
from pathlib import Path
os.makedirs("./datasets/classify_finetune", exist_ok=True)
url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip"
zip_path = "./datasets/classify_finetune/sms_spam_collection.zip"
extracted_path = "./datasets/classify_finetune/sms_spam_collection"
data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv"
save_root_path = "./datasets/classify_finetune"
save_train_path = os.path.join(save_root_path, "train.csv")
save_val_path = os.path.join(save_root_path, ".validation.csv")
save_test_path = os.path.join(save_root_path, "test.csv")
def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):
if data_file_path.exists():
print(f"{data_file_path} already exists. Skipping download and extraction.")
return
# 下载文件
with urllib.request.urlopen(url) as response:
with open(zip_path, "wb") as out_file:
out_file.write(response.read())
# 解压文件
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extracted_path)
# 添加 .tsv 文件扩展
original_file_path = Path(extracted_path) / "SMSSpamCollection"
os.rename(original_file_path, data_file_path)
print(f"File downloaded and saved as {data_file_path}")
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
import pandas as pd
df = pd.read_csv(data_file_path, sep="\t", header=None, names=["Label", "Text"])
print(df['Label'].value_counts())
def create_balanced_dataset(df):
# 计算"spam"实例的数量
num_spam = df[df["Label"] == "spam"].shape[0]
# 随机采样"ham"实例以匹配"spam"实例的数量
ham_subset = df[df["Label"] == "ham"].sample(num_spam, random_state=123)
# 将"ham"子集与"spam"结合起来z
balanced_df = pd.concat([ham_subset, df[df["Label"] == "spam"]])
return balanced_df
balanced_df = create_balanced_dataset(df)
print(balanced_df["Label"].value_counts())
balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1})
# import ipdb; ipdb.set_trace()
# 数据集划分
def random_split(df, train_frac, validation_frac):
# 打乱整个 DataFrame
df = df.sample(frac=1, random_state=123).reset_index(drop=True)
# 计算切分索引
train_end = int(len(df) * train_frac)
validation_end = train_end + int(len(df) * validation_frac)
# 切分 DataFrame
train_df = df[:train_end]
val_df = df[train_end:validation_end]
test_df = df[validation_end:]
return train_df, val_df, test_df
train_df, val_df, test_df = random_split(balanced_df, 0.7, 0.1)
# 测试大小默认为 0.2
train_df.to_csv(save_train_path, index=None)
val_df.to_csv(save_val_path, index=None)
test_df.to_csv(save_test_path, index=None)
# import json
# 【可选】加载已划分好的 CSV
# train_df = pd.read_csv("./data/classify_finetune/train.csv")
# val_df = pd.read_csv("./data/classify_finetune/validation.csv")
# test_df = pd.read_csv("./data/classify_finetune/test.csv")
# 将 Label 映射为文本标签
label_map = {0: "ham", 1: "spam"} # 定义标签类别
def csv_to_sharegpt(df, system_prompt="You are a spam classifier. Reply with only 'spam' or 'ham'."):
"""将 DataFrame 转换为 ShareGPT 格式的列表"""
records = []
for _, row in df.iterrows():
text = row["Text"]
label = label_map[row["Label"]]
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"SMS: {text}"},
{"role": "assistant", "content": label}
]
records.append({"messages": messages}) # 这里需要区别与情感分类数据集中的text
return records
# 转换并保存为 JSONL
for name, df in [("train", train_df), ("validation", val_df), ("test", test_df)]:
sharegpt_data = csv_to_sharegpt(df)
out_path = os.path.join(save_root_path, f"{name}.jsonl")
with open(out_path, "w", encoding="utf-8") as f:
for item in sharegpt_data:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"Saved {len(sharegpt_data)} samples to {out_path}")数据集设置也同样需要变更,变更内容如下:
python
import glob
EMOTION_LABEL_NAMES = ["spam", "ham"]
# 直接把魔搭上的数据集仓库(parquet 文件)整体下载到本地,然后用 datasets 库从本地 parquet 加载。
# 不走 MsDataset.load -> datasets.load_dataset 的桥接路径,可以规避 modelscope 与 datasets 之间
# `as_dataset() got an unexpected keyword argument 'verification_mode'` 这类版本错配错误。
print("Downloading dataset from ModelScope...")
print("ModelScope dataset id:", MODELSCOPE_DATASET_ID)
raw_dataset = load_dataset(
"json",
data_files={
"train": os.path.join(save_root_path, "train.jsonl"),
"validation": os.path.join(save_root_path, "validation.jsonl"),
"test": os.path.join(save_root_path, "test.jsonl"),
},
)
def extract_label_from_messages(example):
# 取 assistant 的最后一条消息内容作为标签
last_assistant = [msg["content"] for msg in example["messages"] if msg["role"] == "assistant"]
example["label"] = last_assistant[-1] if last_assistant else "INVALID"
return example
raw_dataset = raw_dataset.map(extract_label_from_messages)
# 从 parquet 加载时,label 字段类型会退化成普通整数,这里显式 cast 成 ClassLabel,
# 这样后续 `dataset["train"].features["label"].names` 和原始 HF 版接口完全一致。
for split_name in list(raw_dataset.keys()):
if not isinstance(raw_dataset[split_name].features.get("label"), ClassLabel):
raw_dataset[split_name] = raw_dataset[split_name].cast_column(
"label", ClassLabel(names=EMOTION_LABEL_NAMES)
)
print("Raw dataset:", raw_dataset)
def maybe_limit(split, limit):
split = split.shuffle(seed=SEED)
if limit is None:
return split
return split.select(range(min(limit, len(split))))
dataset = DatasetDict({
"train": maybe_limit(raw_dataset["train"], TRAIN_LIMIT),
"validation": maybe_limit(raw_dataset["validation"], VALIDATION_LIMIT),
"test": maybe_limit(raw_dataset["test"], TEST_LIMIT),
})
label_names = dataset["train"].features["label"].names
VALID_LABELS = set(label_names)
ALL_EVAL_LABELS = label_names + ["INVALID"]
print(dataset)
print("label_names:", label_names)
print("example:", dataset["train"][0])3、构造prompt-completion 格式数据
python
def to_prompt_completion(example):
text = example["messages"] # change
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)
print(sft_dataset)
print(sft_dataset["train"][0])4、其他部分
其他部分与上一篇文章Gemma4基于LORA的情绪分类单卡微调中的内容一致,读者可自行拷贝,或者直接访问https://github.com/Reversev/attempts/tree/main/Gemma4_LoRA_ROCm获取项目文件。
笔者在用LoRA进行微调的时候由于数据集比较简单,为了避免过拟合的情况,使用Early Stopping,仅微调了不到一个epoch。
5、微调前后评估对比
微调前的评估结果如下:
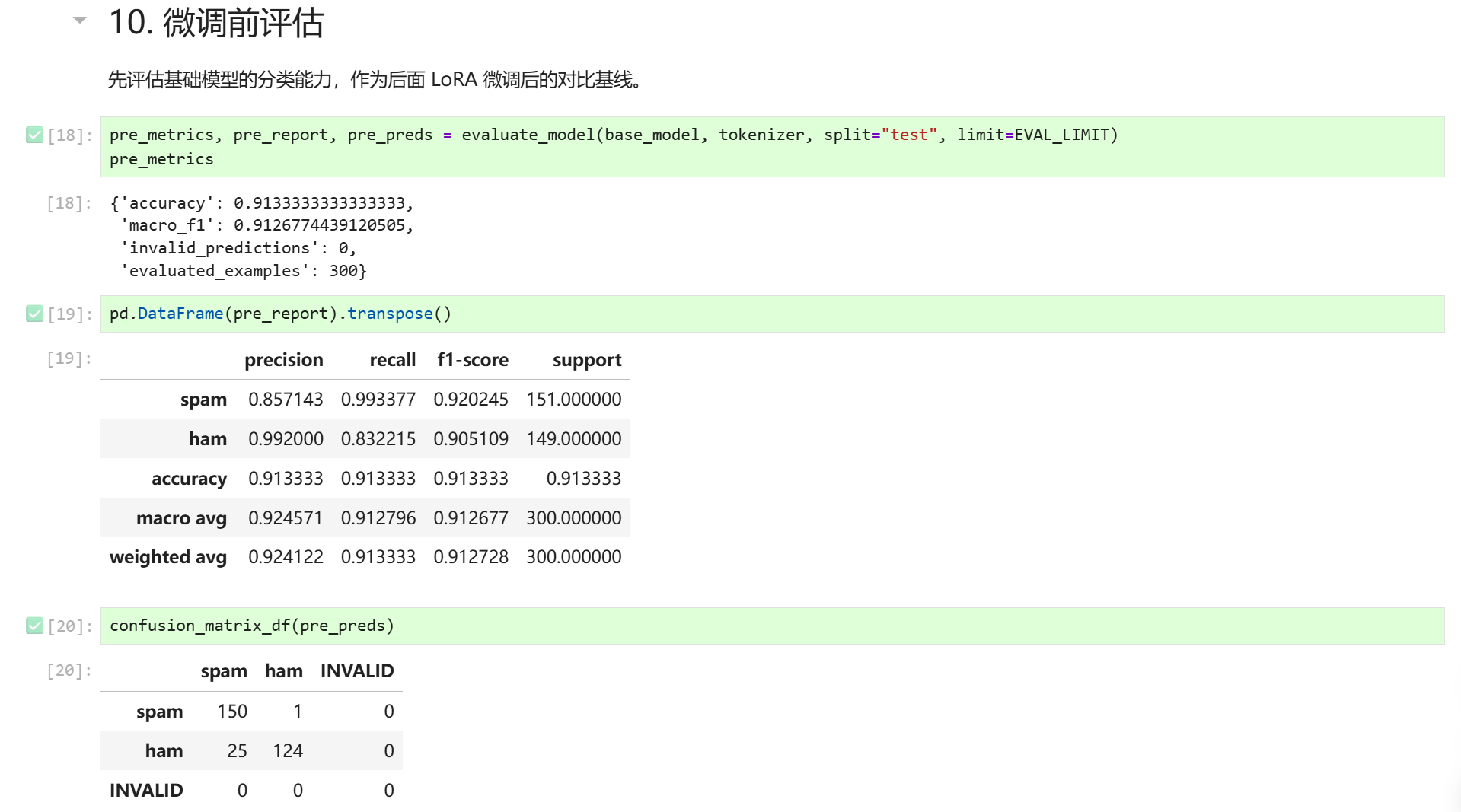
微调后的评估结果如下:

结论:微调前后Gemma4对垃圾邮件分类的准确率等都有所提升,甚至达到了100%,看来这个任务果然很简单。
三、部署测试
本节部署测试主要说明手动测试微调模型和加载本地 LoRA adapter 推理的过程,验证微调后模型的能力。
1、手动测试微调模型
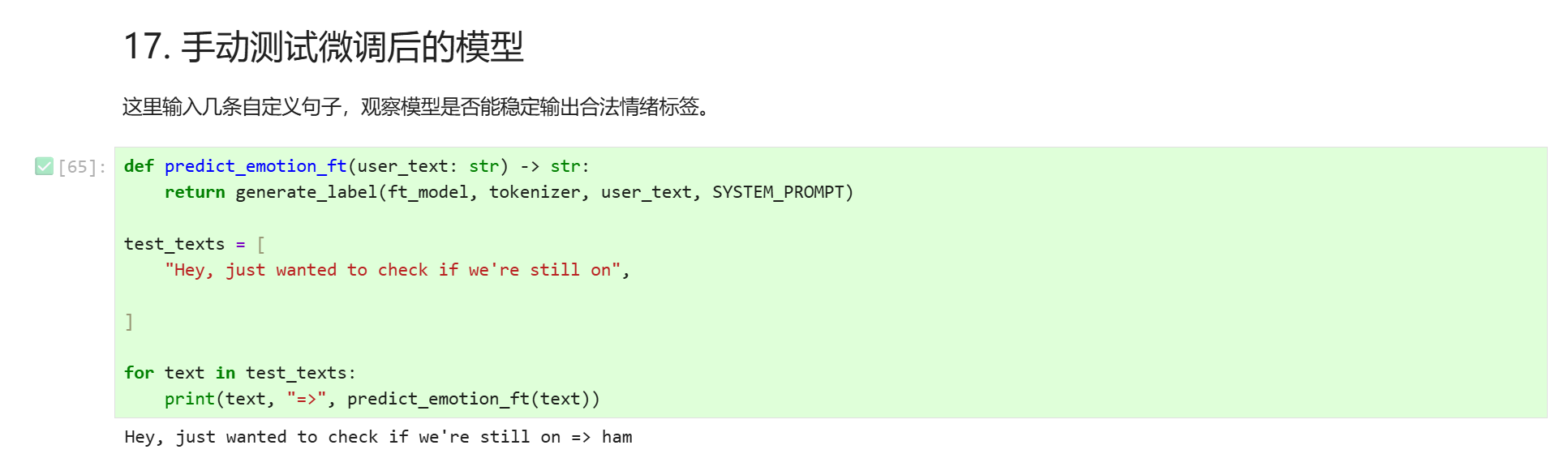
运行代码如下所示:
python
def predict_emotion_ft(user_text: str) -> str:
return generate_label(ft_model, tokenizer, user_text, SYSTEM_PROMPT)
test_texts = [
"Hey, just wanted to check if we're still on",
]
for text in test_texts:
print(text, "=>", predict_emotion_ft(text))运行上述代码结果如下:
2、加载本地 LoRA adapter 推理
运行代码如下所示:
python
RUN_RELOAD_TEST = True
if RUN_RELOAD_TEST:
reload_tokenizer = AutoTokenizer.from_pretrained(
OUTPUT_DIR,
use_fast=True,
trust_remote_code=True,
)
if reload_tokenizer.pad_token is None:
reload_tokenizer.pad_token = reload_tokenizer.eos_token
reload_base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
reload_model = PeftModel.from_pretrained(
reload_base_model,
OUTPUT_DIR,
)
reload_model.eval()
print(generate_label(reload_model, reload_tokenizer, "You are a winner you have been specially selected to receive $1000 cash or a $2000 award.."))运行上述代码结果如下:
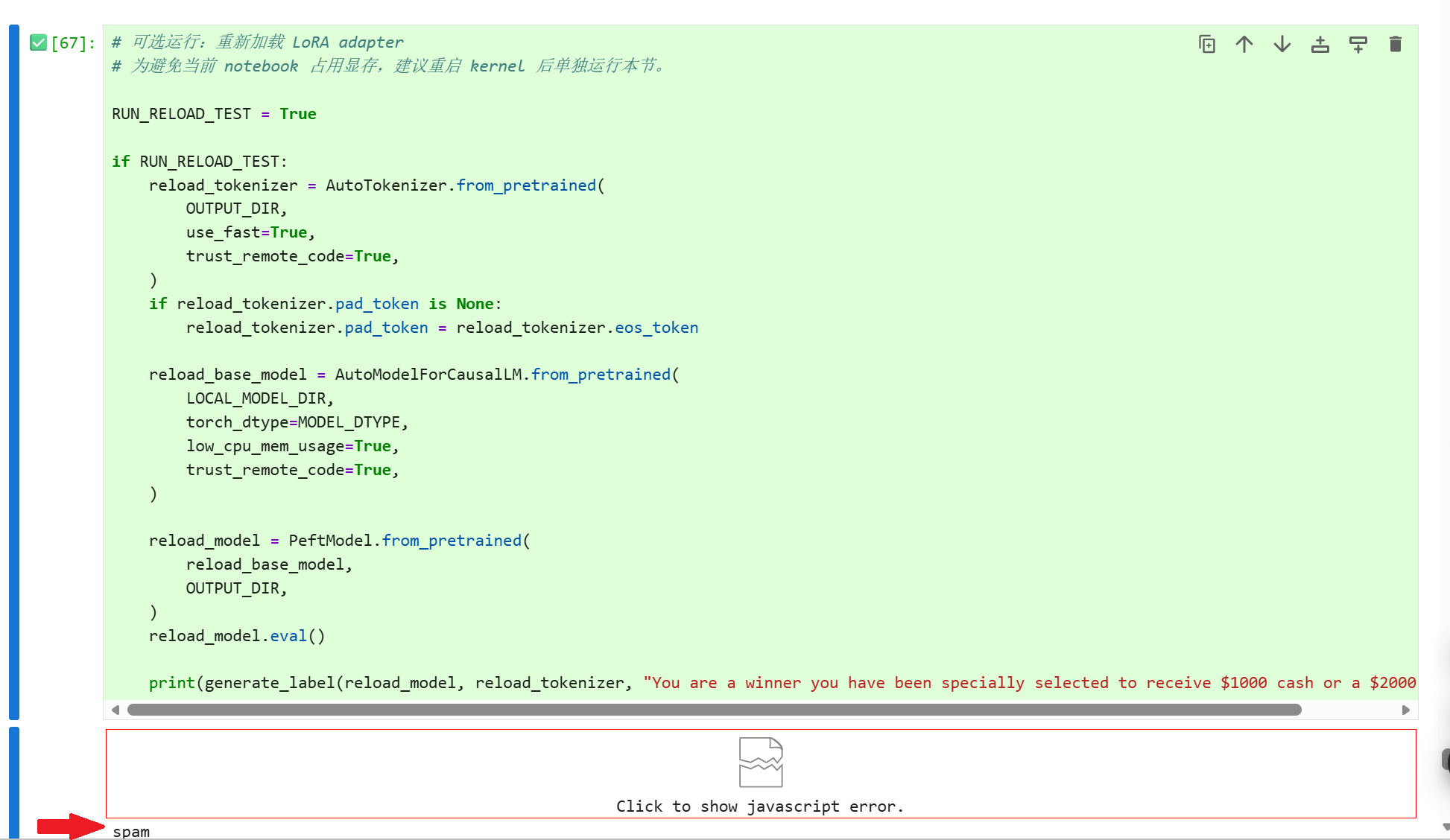
从测试结果可以看出,模型对垃圾邮件的内容还是能够准确且有效区分。后续也可使用其他复杂数据集或者模型进行测试。
如需要保存权重文件,也可以用以下命令将所需文件打包到一个tar文件中。
python
tar -czvf archive.tar.gz 文件名或者*(当前目录下所有文件)四、参考链接
1 https://archive.ics.uci.edu/dataset/228/sms+spam+collection (https://archive.ics.uci.edu/dataset/228/sms+spam+collection)