1、背景
在上一篇文章中《NET环境使用PaddleSharp的入门Demo-控制台》,以控制台的方式实现的,但是在实际工作中,不是每台电脑都有GPU或较高性能的CPU,因此在服务端提供API的接口,供客户端调用,是比较可行的。
2、具体实现
1、整个项目的目录文件
2、安装的package
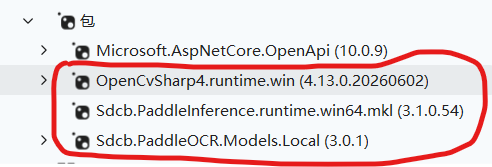
安装的package如上图所示
3、appsettings.json的设置
csharp
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"AllowedHosts": "*",
"PaddleDevice": "CPU"
}4、在Program中以单例模式注册
csharp
// Add services to the container.
builder.Services.AddSingleton(s => {
Action<PaddleConfig> device =
builder.Configuration["PaddleDevice"] == "GPU"
? PaddleDevice.Gpu()
: PaddleDevice.Mkldnn();
return new QueuedPaddleOcrAll(
()=>new PaddleOcrAll(LocalFullModels.ChineseV5,device)
{
Enable180Classification= true,
AllowRotateDetection= true
},
consumerCount:1 //这个参数是指能进行的最大并发数,若资源充足,可调整增大
);
});5、在Controller中注册及实现
csharp
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using OpenCvSharp;
using PaddleOCRAPI.Models;
using Sdcb.PaddleOCR;
namespace PaddleOCRAPI.Controllers
{
[Route("api/[controller]/[action]")]
[ApiController]
public class OCRTestController : ControllerBase
{
private readonly QueuedPaddleOcrAll _ocr;
public OCRTestController(QueuedPaddleOcrAll queuedPaddleOcrAll)
{
_ocr = queuedPaddleOcrAll;
}
[HttpPost]
public async Task<OcrResponse> Ocr(IFormFile file)
{
using MemoryStream ms = new();
using Stream stream=file.OpenReadStream();
stream.CopyTo(ms);
using Mat src = Cv2.ImDecode(ms.ToArray(), ImreadModes.Color);
PaddleOcrResult result = await _ocr.Run(src);
return new OcrResponse
{
Text = result.Text,
Regions = result.Regions
};
}
}
}6、设置返回结果OcrResponse.cs。返回的可以是string,也可以是其他的内容。此处自定义了一个类,用于包装返回结果
csharp
using Sdcb.PaddleOCR;
namespace PaddleOCRAPI.Models
{
public class OcrResponse
{
public string? Text { get; set; }
public PaddleOcrResultRegion[]? Regions { get; set; }
}
}7、测试
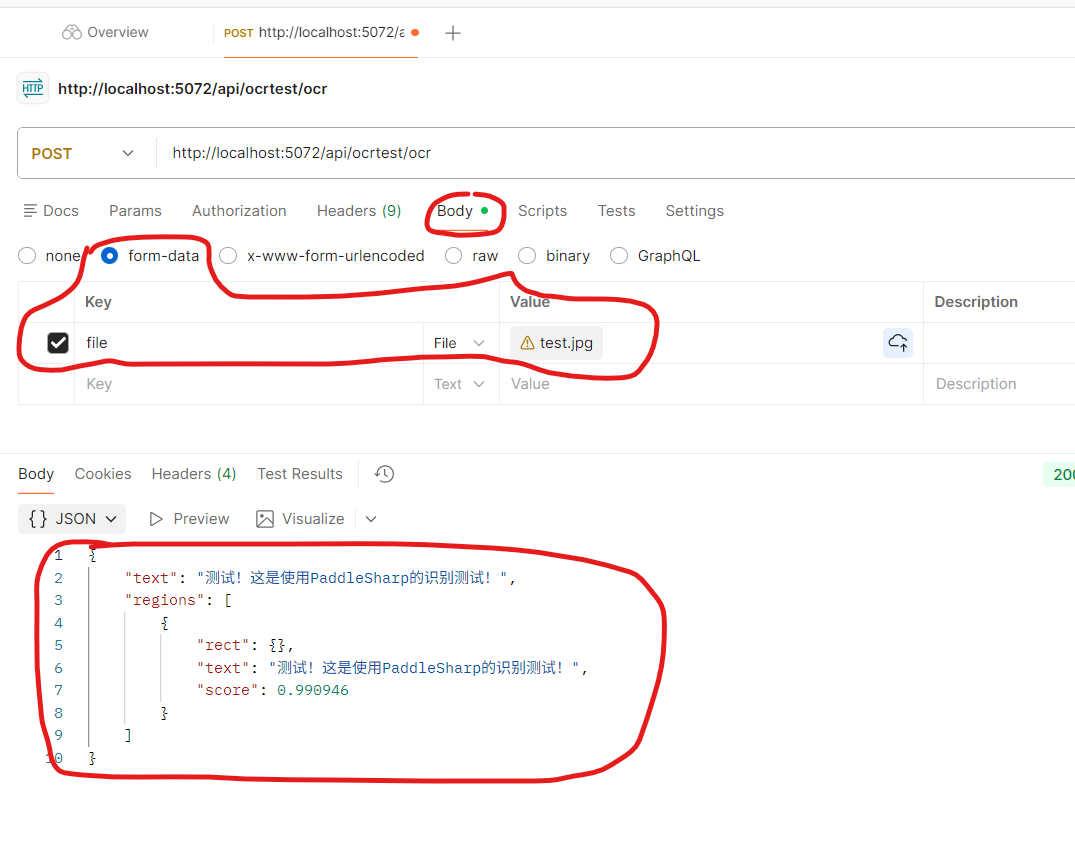
运行程序,使用postman进行测试
3、总结
1、还是非常适合作为整个项目的基础功能,赋能各业务系统
2、这个PaddleSharp是针对图片的OCR识别,那PDF如何识别呢?可以搜索PDFtoImage,非常简单,直接调用其静态方法既可