2026 年 6 月 23 日,火山引擎在北京举办 2026 夏季 FORCE 原动力大会,豆包视频生成模型 Seedance 2.5 在会上首次亮相。公开报道里披露的关键信息很集中:模型预计 7 月正式上线或 7 月初上线;能力侧强调 30 秒单段原生视频直出、最多 50 个全模态素材联合生成、保持画面一致性的局部编辑;应用侧提到具身智能、工业制造、智能驾驶等产业场景,用于数据合成、场景仿真、流程演示等任务。
这篇文章不把 Seedance 2.5 写成一个已经可直接调用的通用接口,也不虚构它的正式 API 路径。更实际的问题是:当视频生成模型从 5 秒、10 秒演示走向 30 秒单段、多素材、局部编辑和产业流程时,团队原来那套"前端填 prompt,后端转发一次请求"的接入方式会很快不够用。需要重新设计任务队列、素材清单、回调签名、幂等更新、成本台账和人工复核。
本文用一个可落地的工程方案来拆解:先用统一模型入口完成文本侧脚本、分镜、审核说明和复核报告,再把视频生成任务抽象成异步作业。向量引擎中转站可以作为候选 API 接入方案之一,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。本文的重点不是"把某个视频接口马上跑通",而是把 Seedance 2.5 发布会释放出来的三个能力点,转成开发团队上线前应该补齐的工程结构。
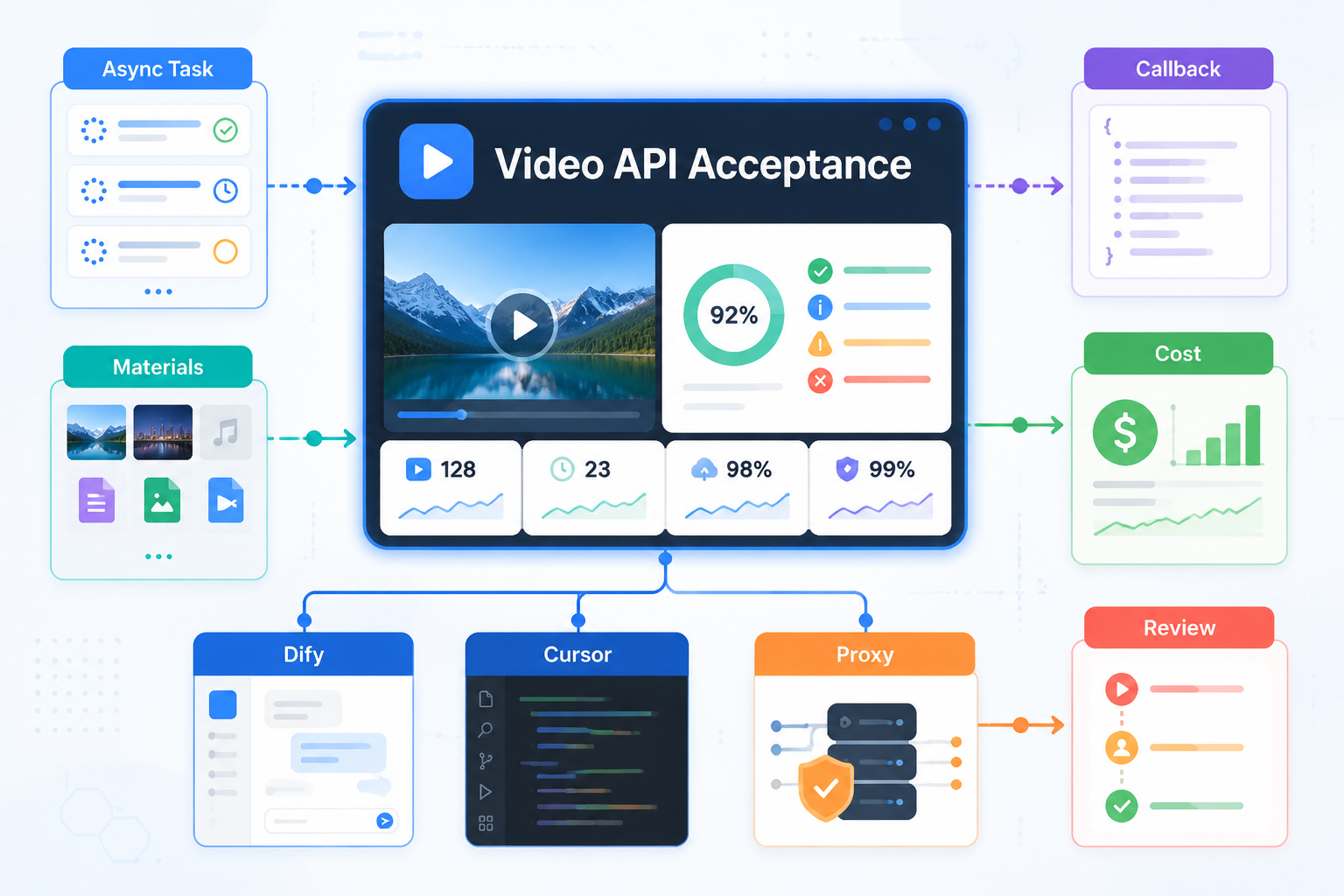
本文的实测边界
先把边界讲清楚,避免误导。
| 项目 | 本文状态 |
|---|---|
| Seedance 2.5 正式视频 API | 截至本文写作时未在本文中调用,不虚构正式路径 |
| 统一模型入口连通性 | 使用 OpenAI 兼容聊天接口做最小请求设计 |
| 文章发布环境 | Windows PowerShell,CSDN 编辑器,10 张新生成技术信息图 |
| 工程示例 | 给出可直接落库、排队、回调、签名和成本归因的后端骨架 |
| 适用读者 | 准备把视频生成接入业务系统的后端、工具链、内容平台和企业研发团队 |
我建议把本文当成"Seedance 2.5 上线前的接入设计审查表",而不是把它当成某个已公开视频接口的 SDK 文档。
Seedance 2.5 的三个能力,分别会压到哪些工程环节
发布会里提到的能力如果只从产品角度看,是 30 秒、多素材、局部编辑。如果从后端角度看,它们会分别落到三个系统约束上。
| 发布会能力 | 产品含义 | 工程含义 | 必须补的系统能力 |
|---|---|---|---|
| 30 秒单段原生视频直出 | 不再依赖多段拼接获得较长片段 | 任务耗时、排队时间、下载文件、失败重试成本都变大 | 异步任务队列、超时策略、结果转存、成本台账 |
| 50 个全模态参考素材 | 图片、视频、音频、文本、动作等可以共同约束生成 | 输入从一个 prompt 变成素材包,权限和冲突都更复杂 | 素材 manifest、哈希、授权来源、过期时间、数量限制 |
| 保持画面一致性的局部编辑 | 修改局部而不是重做整段 | 需要版本管理、编辑区域、父任务、差异复核 | 版本链、局部编辑记录、人工复核、回滚策略 |
这三个能力共同指向一个结论:视频生成不适合被写成"同步函数调用"。它应该被设计成一个有状态的任务系统。
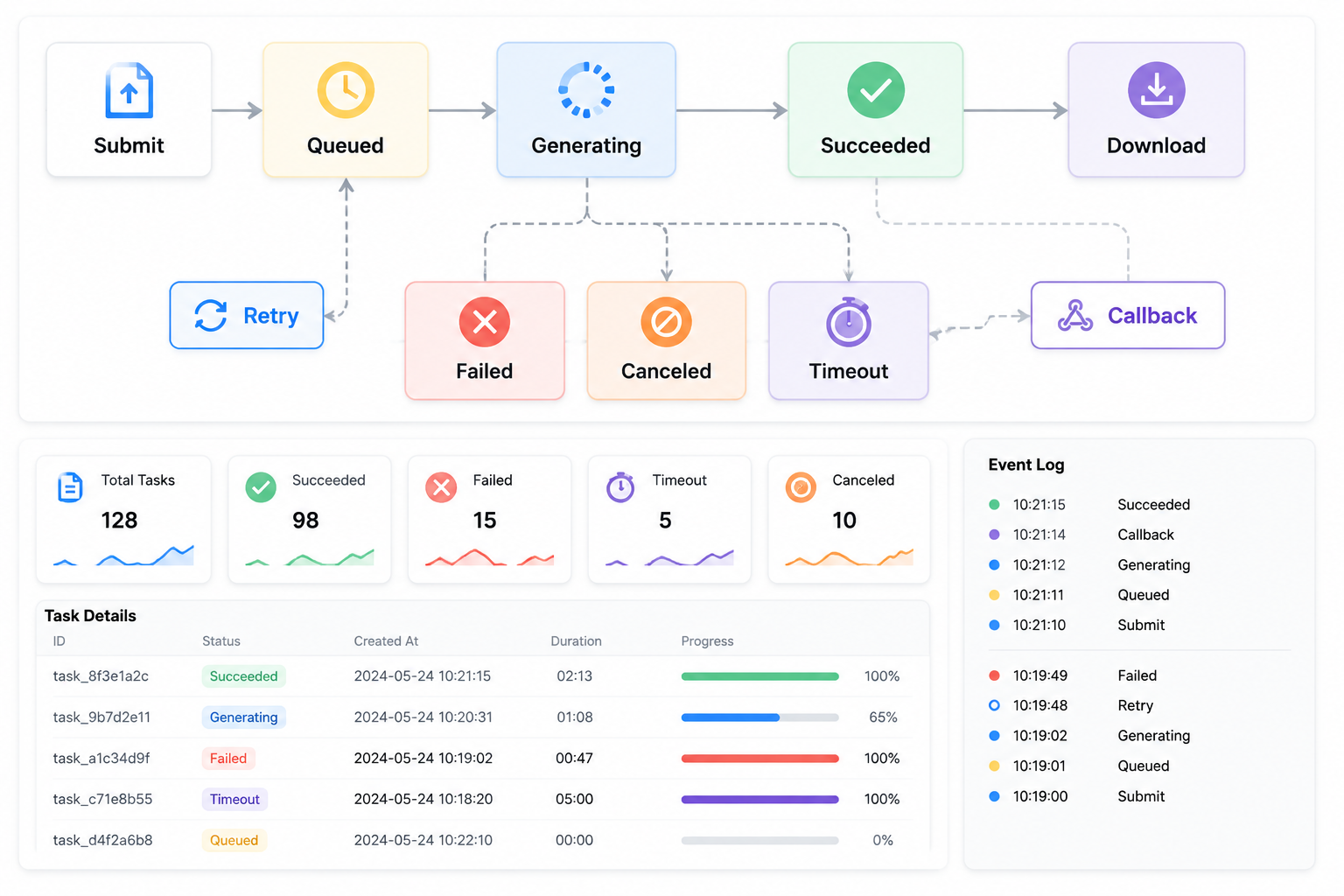
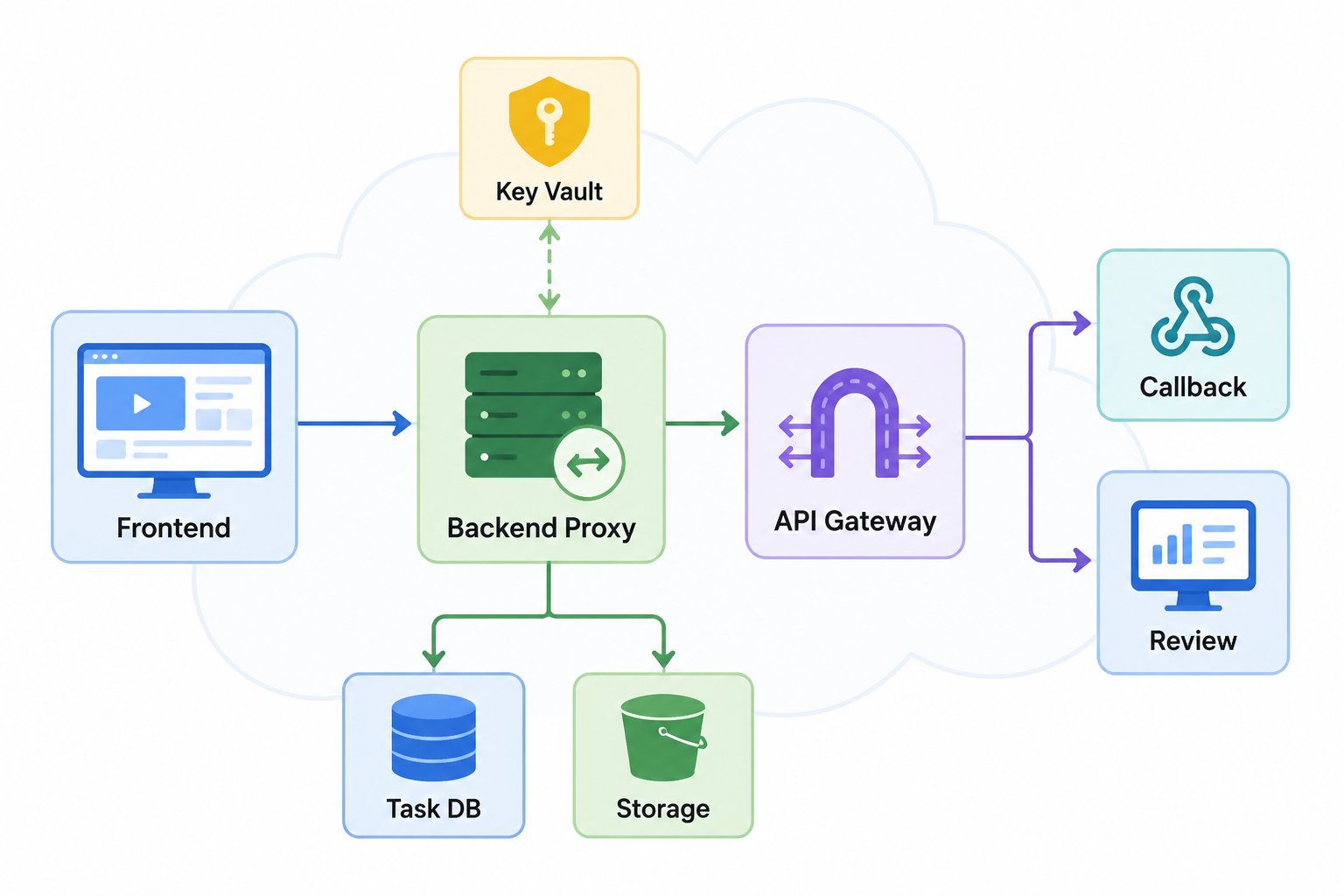
推荐架构:把视频生成拆成 6 个服务边界
一个可维护的视频生成接入系统,至少要把下面 6 个边界分开。
text
业务入口
-> Prompt/分镜生成
-> 素材清单校验
-> 视频任务队列
-> 上游模型适配器
-> 回调与轮询补偿
-> 结果复核与成本台账这里的"上游模型适配器"很重要。Seedance 2.5 正式接口、其他视频模型接口、内部素材库接口,未来字段都可能不同。业务系统不应该到处散落上游字段,而应该只认识自己的 video_task_id、material_manifest_id、project_id 和 cost_record_id。
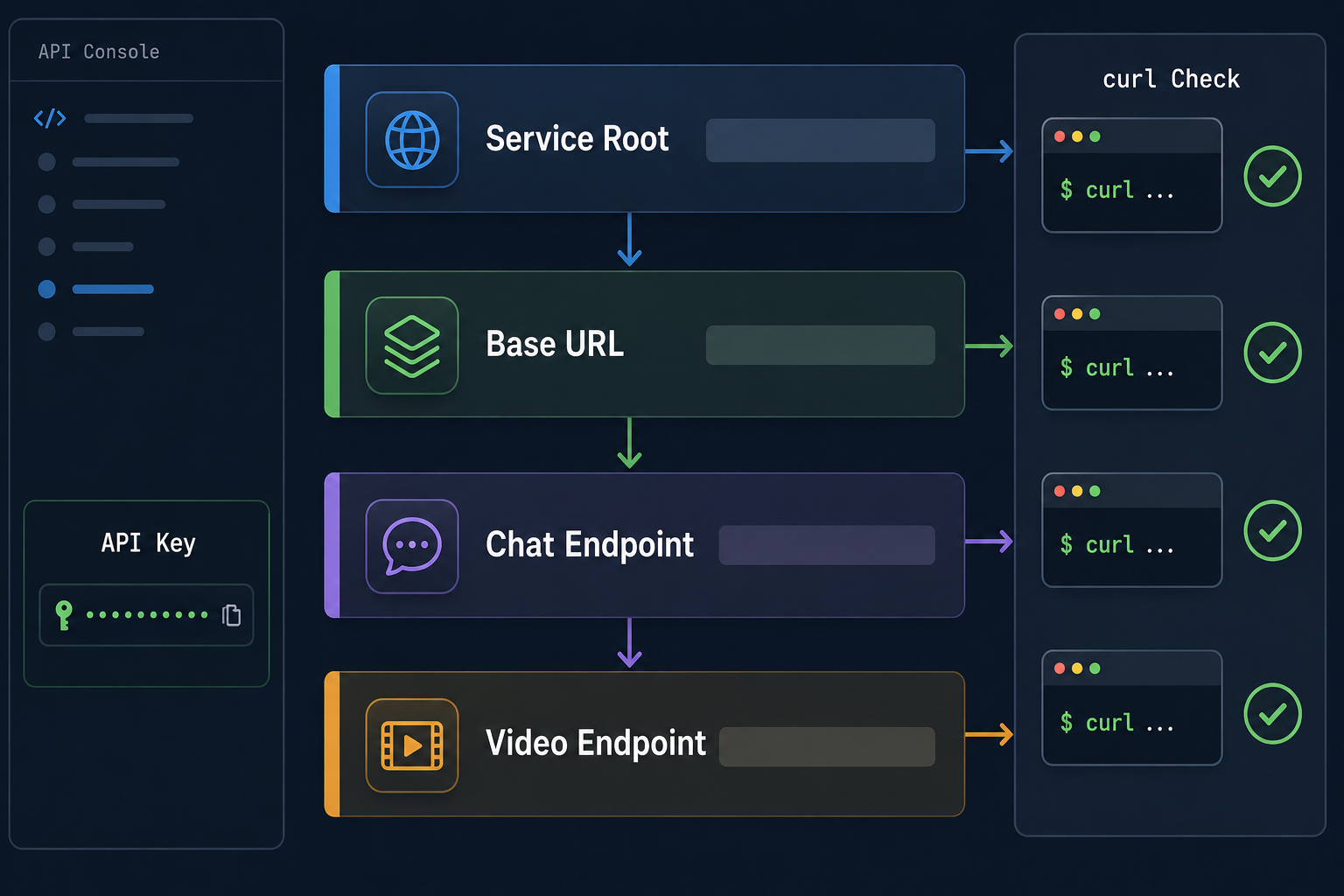
地址层级:先用统一入口跑通文本侧,而不是冒充视频接口
视频生成前后通常离不开文本模型:生成脚本、镜头表、分镜说明、风险提示、发布标题、摘要和复核报告。因此团队可以先用 OpenAI 兼容接口把文本侧工作流跑通。
本篇文章分配的注册试用入口是:
text
https://178.nz/awa接入验收时固定记录这三个地址:
text
服务根地址:https://api.vectorengine.cn
OpenAI 兼容 Base URL:https://api.vectorengine.cn/v1
聊天补全接口:https://api.vectorengine.cn/v1/chat/completions多数工具里填写的是 https://api.vectorengine.cn/v1。自建脚本发聊天补全请求时使用完整的 https://api.vectorengine.cn/v1/chat/completions。视频生成接口的正式路径应以对应平台文档为准,不要在业务系统里提前写死一个未经确认的地址。
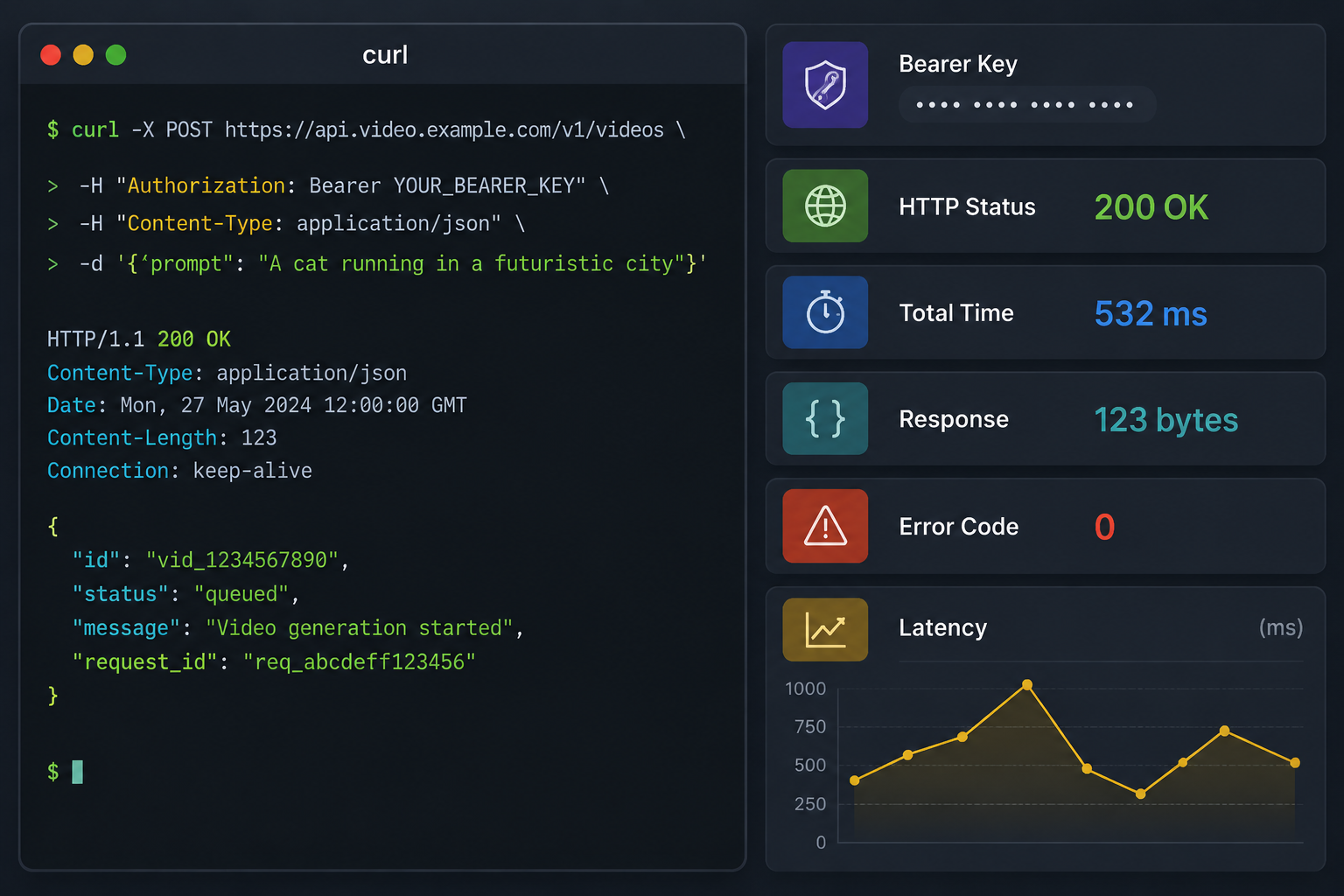
第一步:用 curl 做文本侧最小验收
下面这个请求不是 Seedance 2.5 视频生成请求,而是统一入口的最小连通性检查。它可以帮助团队确认 Key、Base URL、网络和鉴权方式没有问题。
bash
curl -sS -w "\nHTTP_STATUS=%{http_code}\nTOTAL_TIME=%{time_total}\n" \
https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer $VECTOR_ENGINE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "请把一个30秒产品演示视频拆成6个镜头,每个镜头给出画面、动作、旁白和风险点。"
}
],
"temperature": 0.2
}'建议把结果记录到验收表里。
| 验收项 | 记录字段 |
|---|---|
| 基础连通 | HTTP 状态码、总耗时、错误体 |
| 模型可用 | 请求模型、返回模型、返回摘要 |
| 提示词稳定 | 同一输入跑 3 次,检查镜头数和结构是否稳定 |
| 后续接入 | 是否能被 Dify 工作流、后端脚本、人工审核表复用 |
数据库设计:先把 30 秒视频当成任务,而不是文件
很多低质量接入方案只会存一个视频 URL。30 秒、多素材、局部编辑场景下,这远远不够。建议至少建 4 张表。
sql
CREATE TABLE video_tasks (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
task_no VARCHAR(64) NOT NULL UNIQUE,
project_id VARCHAR(64) NOT NULL,
user_id VARCHAR(64) NOT NULL,
scene_type VARCHAR(64) NOT NULL,
prompt_hash CHAR(64) NOT NULL,
material_manifest_id VARCHAR(64) NOT NULL,
parent_task_no VARCHAR(64) NULL,
edit_type VARCHAR(64) NULL,
duration_seconds INT NOT NULL DEFAULT 30,
status VARCHAR(32) NOT NULL,
upstream_provider VARCHAR(64) NULL,
upstream_task_id VARCHAR(128) NULL,
retry_count INT NOT NULL DEFAULT 0,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL
);
CREATE TABLE video_materials (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
material_id VARCHAR(64) NOT NULL UNIQUE,
material_type VARCHAR(32) NOT NULL,
source_type VARCHAR(64) NOT NULL,
license_scope VARCHAR(128) NOT NULL,
sha256 CHAR(64) NOT NULL,
uri TEXT NOT NULL,
expire_at DATETIME NULL,
created_at DATETIME NOT NULL
);
CREATE TABLE video_task_materials (
task_no VARCHAR(64) NOT NULL,
material_id VARCHAR(64) NOT NULL,
role_name VARCHAR(64) NOT NULL,
sort_no INT NOT NULL,
PRIMARY KEY (task_no, material_id)
);
CREATE TABLE video_cost_records (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
task_no VARCHAR(64) NOT NULL,
project_id VARCHAR(64) NOT NULL,
user_id VARCHAR(64) NOT NULL,
model_name VARCHAR(128) NOT NULL,
duration_seconds INT NOT NULL,
material_count INT NOT NULL,
retry_count INT NOT NULL,
estimated_cost DECIMAL(12, 4) NULL,
final_cost DECIMAL(12, 4) NULL,
created_at DATETIME NOT NULL
);这 4 张表分别解决任务状态、素材来源、任务与素材关系、费用归属。等正式视频接口开放后,只需要在 upstream_provider 和 upstream_task_id 上挂接外部任务编号。
50 个素材的正确用法:用 manifest,而不是直接塞数组
发布会里提到 50 个全模态参考素材。工程上最容易犯的错,是把前端传来的素材数组原样交给上游。更稳妥的方式是先生成素材 manifest。
json
{
"manifest_id": "vm_20260624_001",
"project_id": "demo_product_video",
"materials": [
{
"material_id": "mat_role_001",
"type": "character_image",
"role": "main_character",
"sha256": "b2f1...",
"license_scope": "internal_demo",
"expire_at": "2026-12-31T23:59:59+08:00"
},
{
"material_id": "mat_product_001",
"type": "product_image",
"role": "product_reference",
"sha256": "9a18...",
"license_scope": "commercial_allowed",
"expire_at": null
}
],
"limits": {
"max_materials": 50,
"max_video_seconds": 30
}
}提交视频任务前,后端先检查:
- 素材总数是否超过 50。
- 是否混入过期素材。
- 是否有不允许商用的音乐、人物或品牌素材。
- 同一个角色是否出现互相冲突的参考图。
- 是否给每个素材写明角色,例如主角、产品、背景、动作、音频节奏。
这样做不是多此一举。视频生成失败或局部编辑跑偏时,最先要查的往往不是模型,而是素材冲突。
Node.js 队列:用幂等任务替代同步等待
下面示例只写团队自己的任务队列,不写任何未经确认的 Seedance 2.5 正式路径。等正式文档明确后,把 providerAdapter.submit() 这一层替换成真实实现即可。
javascript
import crypto from "crypto";
function taskNo() {
return "vt_" + crypto.randomUUID().replaceAll("-", "");
}
function hashPrompt(prompt) {
return crypto.createHash("sha256").update(prompt, "utf8").digest("hex");
}
export async function createVideoTask(db, queue, input) {
const materialCount = input.materials.length;
if (materialCount > 50) {
throw new Error("material_count_exceeded");
}
const task = {
task_no: taskNo(),
project_id: input.projectId,
user_id: input.userId,
scene_type: input.sceneType,
prompt_hash: hashPrompt(input.prompt),
material_manifest_id: input.manifestId,
duration_seconds: 30,
status: "created",
retry_count: 0,
created_at: new Date(),
updated_at: new Date()
};
await db.insert("video_tasks", task);
await queue.add("submit-video-task", { taskNo: task.task_no }, {
jobId: task.task_no,
attempts: 3,
backoff: { type: "exponential", delay: 10_000 }
});
return { taskNo: task.task_no, status: task.status };
}这里有三个关键点。
jobId使用内部任务号,避免用户重复点击导致重复提交。attempts和backoff由队列控制,避免前端刷新造成重复扣费。prompt_hash只存摘要,不把完整敏感提示词到处暴露。
回调签名:视频任务完成后不能只信一个 URL
视频生成任务完成后,常见做法是上游回调一个结果地址。如果后端只接受 URL,不做签名校验,就可能被伪造状态或污染结果库。
一个简单可用的 HMAC 校验如下。
javascript
import crypto from "crypto";
function verifySignature(rawBody, timestamp, signature, secret) {
const now = Math.floor(Date.now() / 1000);
if (Math.abs(now - Number(timestamp)) > 300) {
return false;
}
const base = `${timestamp}.${rawBody}`;
const expected = crypto
.createHmac("sha256", secret)
.update(base)
.digest("hex");
return crypto.timingSafeEqual(
Buffer.from(signature, "hex"),
Buffer.from(expected, "hex")
);
}回调处理时要做到幂等:
| 回调状态 | 处理方式 |
|---|---|
succeeded |
校验签名,下载或转存结果,更新成本记录,进入人工复核 |
failed |
记录失败类型,不立即无限重试 |
canceled |
标记取消,不再进入下载流程 |
| 重复回调 | 根据 task_no + upstream_task_id + status 幂等忽略 |
| 超时未回调 | 后台补偿轮询,不让任务永久停在 generating |
局部编辑:要保存父任务和差异,而不是覆盖原视频
Seedance 2.5 的局部编辑能力如果用于企业流程,最不能做的是"覆盖原视频"。每一次局部编辑都应该生成一个子任务。
text
vt_001 原始 30 秒视频
-> vt_001_edit_01 更换背景
-> vt_001_edit_02 修正产品边缘
-> vt_001_edit_03 调整角色动作数据库里 parent_task_no 用来记录父任务,edit_type 用来记录修改类型。人工复核时至少看三项:
- 修改区域是否真的只影响目标区域。
- 产品、人物、字幕、品牌元素是否发生非预期变化。
- 新版本是否仍然符合原始素材授权和发布场景。
局部编辑的价值不是"想改哪里就改哪里",而是减少整段重做的成本。要让这个价值在业务里成立,就必须保留版本链。

Dify、Cursor、Chatbox、Cherry Studio 应该放在什么位置
这几类工具更适合服务视频任务的前后环节,而不是都直接去调用视频模型。
| 工具 | 建议职责 | 可复用的统一入口 |
|---|---|---|
| Dify | 收集需求、生成脚本、组织审核工作流 | OpenAI 兼容文本模型 |
| Cursor | 开发任务队列、回调服务、成本报表 | 代码辅助和接口调试 |
| Chatbox | 内容同事讨论脚本、标题和复核清单 | 自定义 OpenAI 兼容服务 |
| Cherry Studio | 对比脚本版本、整理素材说明 | 多模型文本输出对比 |
Dify 工作流可以先做 5 个节点:
- 读取视频需求表。
- 生成 30 秒镜头表。
- 检查素材 manifest 是否完整。
- 输出人工审核清单。
- 调用公司后端创建视频任务。
这样,内容同事看到的是"任务申请表",后端看到的是结构化任务,财务和项目负责人看到的是成本台账。
成本台账:30 秒视频要记录重试、编辑和转存
视频生成的成本不能只看"生成一次多少钱"。尤其在 30 秒、多素材和局部编辑场景下,成本来自多处。
| 成本来源 | 为什么要记录 |
|---|---|
| 首次生成 | 主要模型调用成本 |
| 失败重试 | 排队、审核失败、素材冲突都会导致额外尝试 |
| 局部编辑 | 每次局部编辑都可能产生新任务 |
| 结果转存 | 视频文件较大,存储和 CDN 都有成本 |
| 人工复核 | 企业场景里复核也是交付成本 |
| 文本辅助 | 脚本、分镜、标题、摘要、审核报告也会消耗文本模型额度 |
建议每天生成一张项目级报表。
sql
SELECT
project_id,
COUNT(*) AS task_count,
SUM(duration_seconds) AS total_video_seconds,
SUM(retry_count) AS total_retries,
SUM(final_cost) AS total_cost
FROM video_cost_records
WHERE created_at >= CURRENT_DATE
GROUP BY project_id;如果团队问"公司多人一起用 AI API,怎么知道谁在用、花了多少钱、怎么管理",这张表就是答案的起点。
故障排查:按状态机定位,而不是只看报错文案
| 阶段 | 常见问题 | 排查证据 |
|---|---|---|
| 创建任务前 | Key、Base URL、权限、余额异常 | curl 最小请求、账户权限、错误体 |
| 素材入库 | 文件过大、格式不支持、授权不清 | MIME、sha256、license_scope、expire_at |
| 提交上游 | 模型暂不可用、参数不匹配 | provider、request_id、upstream_task_id |
| 排队生成 | 队列拥堵、任务过重 | queued_at、started_at、material_count |
| 回调结果 | 签名错误、重复回调、下载失败 | signature、timestamp、callback_log |
| 人工复核 | 人物变形、产品细节错误、品牌风险 | review_status、reviewer、reason |
| 局部编辑 | 修改越界、版本混乱 | parent_task_no、edit_type、diff_note |
这个排查表比"失败就重试"更重要。因为视频生成任务越贵、越长、越依赖素材,盲目重试越容易把问题放大。
什么时候适合小范围接入 Seedance 2.5 这类模型
可以用下面 9 个条件判断是否进入小范围试用。
- 已经有明确场景,例如产品演示、工业流程、仿真数据、培训视频,而不是只想试试看。
- 能把 30 秒视频拆成镜头表,而不是只写一句 prompt。
- 每个素材都有来源、授权和过期时间。
- 有后端任务队列,不依赖前端长时间等待。
- 有回调签名或等价的可信结果更新机制。
- 结果文件能转存到团队自己的素材库。
- 能按人和项目记录费用。
- 有人工复核流程。
- 有失败后停止、重试、改素材、改脚本的判断标准。
如果这些条件都没有,建议先别急着把视频生成接到生产系统。先用 Dify 或表单把脚本、素材和审核流程跑通,风险会低很多。
FAQ
1. Seedance 2.5 已经能直接调用了吗?
公开报道显示它预计 7 月正式上线或 7 月初上线,本文不声称已经调用到正式视频接口。本文给的是上线前工程设计和验收流程。
2. 为什么还要写 OpenAI 兼容接口?
因为视频生成前后的脚本、分镜、复核、标题、摘要、审核报告通常需要文本模型。先把统一文本入口跑通,可以让后续视频任务更容易接入已有工具和后端流程。
3. 50 个素材是不是每次都应该传满?
不是。50 个素材代表上限和复杂场景能力,不代表最佳实践。生产流程里应该先用少量高质量素材跑通,再逐步增加角色、产品、动作、音频和背景参考。
4. 局部编辑为什么要单独建任务?
因为局部编辑会产生新版本。如果覆盖原视频,后续无法比较效果、追溯成本、回滚版本,也无法解释某个错误是原始生成造成的还是编辑造成的。
5. 前端能不能直接调用视频生成接口?
不建议。视频生成涉及高成本、素材权限、结果下载和审核,Key 应该留在服务端,前端只提交业务任务。
6. 向量引擎适合放在哪一层?
向量引擎中转站可以作为候选统一模型入口评估。文本侧可以先用 OpenAI 兼容接口跑脚本、分镜、复核和工具配置;视频侧等正式接口明确后,再通过后端适配器纳入同一套任务和成本治理。
7. 这篇文章和普通 API 中转站选型文有什么区别?
普通选型文常看价格、稳定性、Base URL 和工具接入。本文关注视频生成上线后的任务系统:30 秒任务、50 素材 manifest、局部编辑版本链、回调签名、幂等更新和成本台账。
8. 企业最应该先做什么?
先选一个明确场景,写出 30 秒镜头表,整理素材授权,再用后端任务表记录一次完整流程。不要一开始就让所有人自由生成视频。
总结
Seedance 2.5 发布会值得关注的地方,不只是"视频更长了"或"素材更多了"。对开发团队来说,它真正推动的是视频生成从 Demo 走向生产任务:30 秒意味着更长的状态管理,50 个素材意味着更复杂的权限和冲突校验,局部编辑意味着版本链和成本追踪。
如果团队要认真接入这类视频生成模型,建议先做三件事:第一,用 https://api.vectorengine.cn、https://api.vectorengine.cn/v1、https://api.vectorengine.cn/v1/chat/completions 跑通文本侧统一入口;第二,把视频生成抽象成异步任务,不把上游字段散落在业务代码里;第三,建立素材 manifest、回调签名、版本链和成本台账。
等 Seedance 2.5 正式接口、价格和权限边界明确后,这套结构可以直接承接真实调用。否则,再好的模型效果也很难稳定进入企业工作流。