原始文档地址
https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html
ETL 管道
提取、转换和加载(ETL)框架是检索增强生成(RAG)用例中数据处理的基础。
ETL 管道协调从原始数据源到结构化向量存储的数据流,确保数据处于最佳格式,以供 AI 模型检索。
RAG 用例是通过从数据体中检索相关信息来增强生成式模型能力的文本,以提高生成输出的质量和相关性。
API 概述
ETL 管道用于创建、转换和存储 Document 实例。
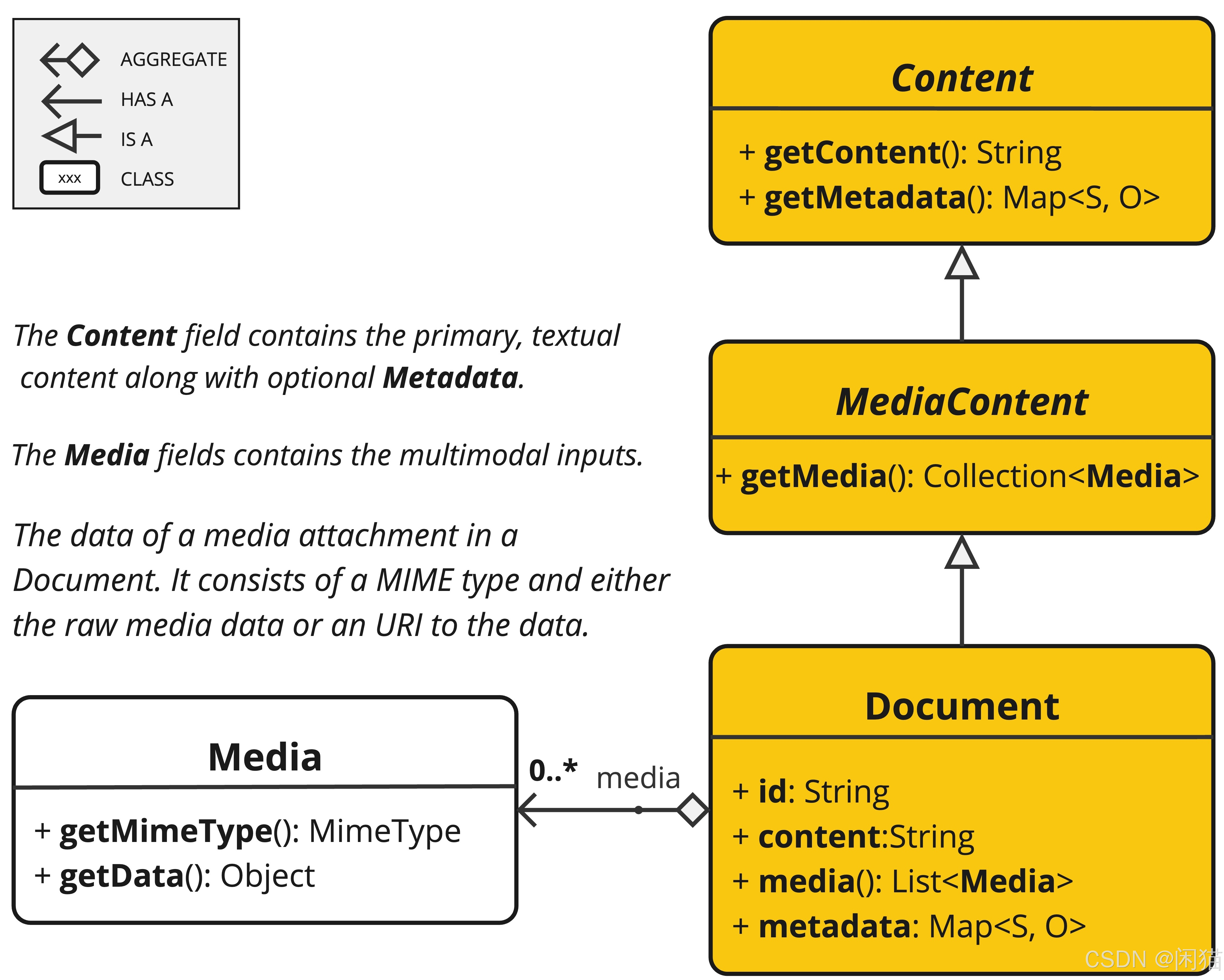
Spring AI 消息 API
Document 类包含文本、元数据,以及可选的图像、音频和视频等附加媒体类型。
ETL 管道有三个主要组件:
DocumentReader:实现Supplier<List<Document>>DocumentTransformer:实现Function<List<Document>, List<Document>>DocumentWriter:实现Consumer<List<Document>>
Document 类的内容是通过 DocumentReader 从 PDF、文本文件和其他文档类型中创建的。
要构建一个简单的 ETL 管道,你可以将每种类型的一个实例串联起来。

假设我们有以下三种 ETL 类型的实例:
PagePdfDocumentReader:DocumentReader的一个实现TokenTextSplitter:DocumentTransformer的一个实现VectorStore:DocumentWriter的一个实现
要执行将数据基本加载到向量数据库中以用于检索增强生成模式,请使用以下 Java 函数式风格语法的代码:
java
vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));或者,你可以使用领域内更自然表达的方法名称:
java
vectorStore.write(tokenTextSplitter.split(pdfReader.read()));ETL 接口
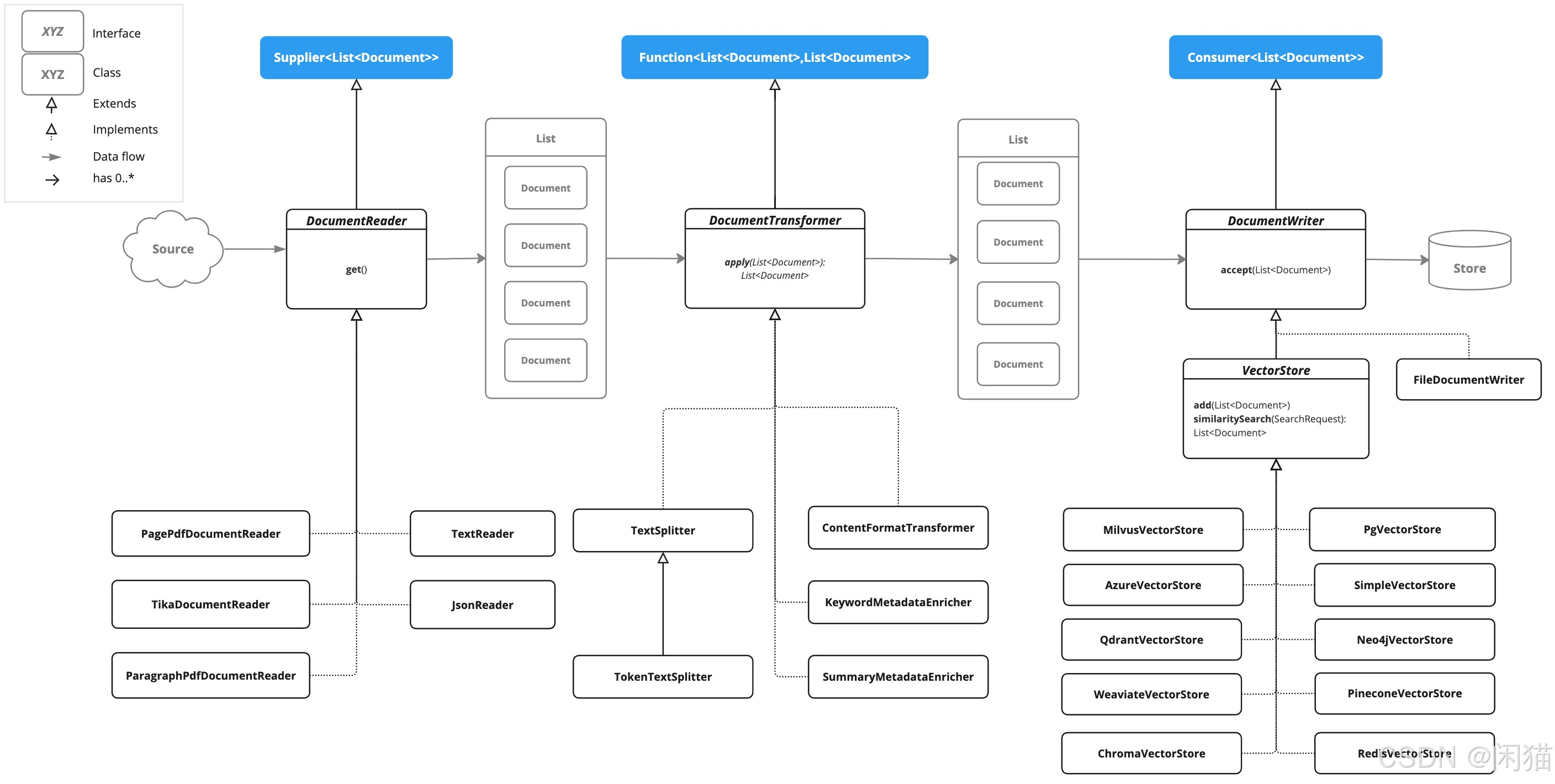
ETL 管道由以下接口和实现组成。详细的 ETL 类图见 ETL 类图部分。
DocumentReader
提供来自不同来源的文档源。
java
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}DocumentTransformer
在处理工作流中转换一批文档。
java
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}DocumentWriter
管理 ETL 过程的最后阶段,准备文档以供存储。
java
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}ETL 类图
以下类图说明了 ETL 接口和实现。
文档读取器(DocumentReaders)
安全提示 :下面描述的大多数
DocumentReader和DocumentWriter实现都是使用Resource或资源模式构建的,并在内部使用DefaultResourceLoader或其变体来访问存储。应注意不要直接使用用户提供的 URL 来构造此类实例,因为这存在安全风险。
JSON
JsonReader 处理 JSON 文档,将其转换为 Document 对象列表。
示例
java
@Component
class MyJsonReader {
private final Resource resource;
MyJsonReader(@Value("classpath:bikes.json") Resource resource) {
this.resource = resource;
}
List<Document> loadJsonAsDocuments() {
JsonReader jsonReader = new JsonReader(this.resource, "description", "content");
return jsonReader.get();
}
}构造函数选项
JsonReader 提供了几个构造函数选项:
JsonReader(Resource resource)JsonReader(Resource resource, String... jsonKeysToUse)JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String... jsonKeysToUse)
参数
resource:指向 JSON 文件的 Spring Resource 对象。jsonKeysToUse:JSON 中应用作文档文本内容的键数组。jsonMetadataGenerator:可选的JsonMetadataGenerator,用于为每个Document创建元数据。
行为
JsonReader 处理 JSON 内容如下:
- 它可以处理 JSON 数组和单个 JSON 对象。
- 对于每个 JSON 对象(无论是在数组中还是单个对象):
- 根据指定的
jsonKeysToUse提取内容。 - 如果未指定键,则使用整个 JSON 对象作为内容。
- 使用提供的
JsonMetadataGenerator生成元数据(如果未提供,则使用空的生成器)。 - 使用提取的内容和元数据创建一个
Document对象。
- 根据指定的
使用 JSON Pointer
JsonReader 现在支持使用 JSON Pointer 检索 JSON 文档的特定部分。此功能允许你轻松地从复杂的 JSON 结构中提取嵌套数据。
get(String pointer) 方法
java
public List<Document> get(String pointer)此方法允许你使用 JSON Pointer 检索 JSON 文档的特定部分。
参数
pointer:一个 JSON Pointer 字符串(根据 RFC 6901 定义),用于在 JSON 结构中定位所需元素。
返回值
返回一个 Document 列表,其中包含从由 pointer 定位的 JSON 元素解析出的文档。
行为
- 该方法使用提供的 JSON Pointer 导航到 JSON 结构中的特定位置。
- 如果 pointer 有效且指向现有元素:
- 对于 JSON 对象:返回包含单个
Document的列表。 - 对于 JSON 数组:返回一个
Document列表,数组中的每个元素对应一个。
- 对于 JSON 对象:返回包含单个
- 如果 pointer 无效或指向不存在的元素,则抛出
IllegalArgumentException。
示例
java
JsonReader jsonReader = new JsonReader(resource, "description");
List<Document> documents = this.jsonReader.get("/store/books/0");示例 JSON 结构
json
[
{
"id": 1,
"brand": "Trek",
"description": "一款用于越野骑行的性能型山地自行车。"
},
{
"id": 2,
"brand": "Cannondale",
"description": "一款为竞赛爱好者设计的空气动力学公路自行车。"
}
]在此示例中,如果 JsonReader 配置了 "description" 作为 jsonKeysToUse,它将创建 Document 对象,其内容为数组中每辆自行车的 "description" 字段的值。
注意事项
JsonReader使用 Jackson 进行 JSON 解析。- 它可以通过对流式处理来高效处理大型 JSON 文件。
- 如果在
jsonKeysToUse中指定了多个键,内容将是这些键对应的值的拼接。 - 该读取器具有灵活性,可以通过自定义
jsonKeysToUse和JsonMetadataGenerator来适配各种 JSON 结构。
文本(Text)
TextReader 处理纯文本文档,将其转换为 Document 对象列表。
示例
java
@Component
class MyTextReader {
private final Resource resource;
MyTextReader(@Value("classpath:text-source.txt") Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TextReader textReader = new TextReader(this.resource);
textReader.getCustomMetadata().put("filename", "text-source.txt");
return textReader.read();
}
}构造函数选项
TextReader 提供了两个构造函数选项:
TextReader(String resourceUrl)TextReader(Resource resource)
参数
resourceUrl:表示要读取的资源 URL 的字符串。resource:指向文本文件的 Spring Resource 对象。
配置
setCharset(Charset charset):设置读取文本文件时使用的字符集。默认为 UTF-8。getCustomMetadata():返回一个可变映射,你可以在其中为文档添加自定义元数据。
行为
TextReader 处理文本内容如下:
- 它将整个文本文件的内容读取到一个单一的
Document对象中。 - 文件内容成为
Document的内容。 - 元数据自动添加到
Document中:charset:读取文件时使用的字符集(默认为"UTF-8")。source:源文本文件的文件名。
- 通过
getCustomMetadata()添加的任何自定义元数据都会包含在Document中。
注意事项
TextReader将整个文件内容读入内存,因此可能不适用于非常大的文件。- 如果你需要将文本拆分成更小的块,可以在读取文档后使用
TokenTextSplitter等文本分割器:
java
List<Document> documents = textReader.get();
List<Document> splitDocuments = TokenTextSplitter.builder().build().apply(documents);- 该读取器使用 Spring 的
Resource抽象,允许它从各种来源(类路径、文件系统、URL 等)读取。 - 可以使用
getCustomMetadata()方法为读取器创建的所有文档添加自定义元数据。
HTML(JSoup)
JsoupDocumentReader 使用 JSoup 库处理 HTML 文档,将其转换为 Document 对象列表。
依赖
使用 Maven 或 Gradle 将依赖项添加到项目中。
Maven
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>Gradle
gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-jsoup-document-reader'
}示例
java
@Component
class MyHtmlReader {
private final Resource resource;
MyHtmlReader(@Value("classpath:/my-page.html") Resource resource) {
this.resource = resource;
}
List<Document> loadHtml() {
JsoupDocumentReaderConfig config = JsoupDocumentReaderConfig.builder()
.selector("article p") // 提取 <article> 标签内的段落
.charset("ISO-8859-1") // 使用 ISO-8859-1 编码
.includeLinkUrls(true) // 在元数据中包含链接 URL
.metadataTags(List.of("author", "date")) // 提取 author 和 date 元标签
.additionalMetadata("source", "my-page.html") // 添加自定义元数据
.build();
JsoupDocumentReader reader = new JsoupDocumentReader(this.resource, config);
return reader.get();
}
}JsoupDocumentReaderConfig 允许你自定义 JsoupDocumentReader 的行为:
charset:指定 HTML 文档的字符编码(默认为"UTF-8")。selector:一个 JSoup CSS 选择器,用于指定要提取文本的元素(默认为"body")。separator:用于连接多个选中元素文本的字符串(默认为"\n")。allElements:如果为true,则提取<body>元素中的所有文本,忽略选择器(默认为false)。groupByElement:如果为true,则为选择器匹配的每个元素创建一个单独的Document(默认为false)。includeLinkUrls:如果为true,提取绝对链接 URL 并将其添加到元数据中(默认为false)。metadataTags:要从中提取内容的<meta>标签名称列表(默认为["description", "keywords"])。additionalMetadata:允许你向所有创建的Document对象添加自定义元数据。
示例文档:my-page.html
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>我的网页</title>
<meta name="description" content="Spring AI 的示例网页">
<meta name="keywords" content="spring, ai, html, 示例">
<meta name="author" content="张三">
<meta name="date" content="2024-01-15">
<link rel="stylesheet" href="style.css">
</head>
<body>
<header>
<h1>欢迎来到我的页面</h1>
</header>
<nav>
<ul>
<li><a href="/">首页</a></li>
<li><a href="/about">关于</a></li>
</ul>
</nav>
<article>
<h2>主要内容</h2>
<p>这是我网页的主要内容。</p>
<p>它包含多个段落。</p>
<a href="https://www.example.com">外部链接</a>
</article>
<footer>
<p>© 2024 张三</p>
</footer>
</body>
</html>行为
JsoupDocumentReader 处理 HTML 内容并根据配置创建 Document 对象:
selector决定使用哪些元素进行文本提取。- 如果
allElements为true,<body>中的所有文本将被提取到一个单一的Document中。 - 如果
groupByElement为true,匹配selector的每个元素将创建一个单独的Document。 - 如果
allElements和groupByElement都为false,则匹配selector的所有元素的文本将使用separator连接起来。 - 文档标题、指定
<meta>标签的内容,以及(可选地)链接 URL 会被添加到Document的元数据中。 - 用于解析相对链接的基础 URI 将从 URL 资源中提取。
- 该读取器保留选中元素的文本内容,但会移除其中的 HTML 标签。
Markdown
MarkdownDocumentReader 处理 Markdown 文档,将其转换为 Document 对象列表。
依赖
使用 Maven 或 Gradle 将依赖项添加到项目中。
Maven
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>Gradle
gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-markdown-document-reader'
}示例
java
@Component
class MyMarkdownReader {
private final Resource resource;
MyMarkdownReader(@Value("classpath:code.md") Resource resource) {
this.resource = resource;
}
List<Document> loadMarkdown() {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", "code.md")
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(this.resource, config);
return reader.get();
}
}MarkdownDocumentReaderConfig 允许你自定义 MarkdownDocumentReader 的行为:
horizontalRuleCreateDocument:当设置为true时,Markdown 中的水平分割线将创建新的Document对象。includeCodeBlock:当设置为true时,代码块将与周围的文本包含在同一个Document中。当为false时,代码块将创建单独的Document对象。includeBlockquote:当设置为true时,引用块将与周围的文本包含在同一个Document中。当为false时,引用块将创建单独的Document对象。additionalMetadata:允许你向所有创建的Document对象添加自定义元数据。
示例文档:code.md
markdown
这是一个 Java 示例应用:
```java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}Markdown 还提供了在整个句子中使用行内代码格式的可能性。
另一种设置是无特定高亮的块代码:
./mvnw spring-javaformat:apply
**行为**
`MarkdownDocumentReader` 处理 Markdown 内容并根据配置创建 `Document` 对象:
- 标题成为 `Document` 对象中的元数据。
- 段落成为 `Document` 对象的内容。
- 代码块可以被分离到它们自己的 `Document` 对象中,或者与周围的文本包含在一起。
- 引用块可以被分离到它们自己的 `Document` 对象中,或者与周围的文本包含在一起。
- 水平分割线可用于将内容拆分为单独的 `Document` 对象。
- 该读取器在 `Document` 对象的内容中保留格式,如行内代码、列表和文本样式。
### PDF 页面(PagePdfDocumentReader)
`PagePdfDocumentReader` 使用 Apache PdfBox 库解析 PDF 文档。
**依赖**
使用 Maven 或 Gradle 将依赖项添加到项目中。
**Maven**
```xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>Gradle
gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}示例
java
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdf() {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}PDF 段落(ParagraphPdfDocumentReader)
ParagraphPdfDocumentReader 使用 PDF 目录(如 TOC)信息将输入的 PDF 拆分为文本段落,并为每个段落输出一个 Document。注意:并非所有 PDF 文档都包含 PDF 目录。
依赖
与 PagePdfDocumentReader 相同。
示例
java
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdfWithCatalog() {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}Tika(DOCX、PPTX、HTML...)
TikaDocumentReader 使用 Apache Tika 从多种文档格式中提取文本,如 PDF、DOC/DOCX、PPT/PPTX 和 HTML。有关支持格式的完整列表,请参阅 Tika 文档。
依赖
使用 Maven 或 Gradle 将依赖项添加到项目中。
Maven
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>Gradle
gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-tika-document-reader'
}示例
java
@Component
class MyTikaDocumentReader {
private final Resource resource;
MyTikaDocumentReader(@Value("classpath:/word-sample.docx")
Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(this.resource);
return tikaDocumentReader.read();
}
}转换器(Transformers)
TextSplitter(文本分割器)
TextSplitter 是一个抽象基类,帮助分割文档以适应 AI 模型的上下文窗口。
TokenTextSplitter(令牌文本分割器)
TokenTextSplitter 是 TextSplitter 的一个实现,根据令牌数量将文本分割成块。它支持可配置的编码类型(如 CL100K_BASE、P50K_BASE、O200K_BASE),默认为 CL100K_BASE。
用法
基本用法
java
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = TokenTextSplitter.builder().build();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(1000)
.withMinChunkSizeChars(400)
.withMinChunkLengthToEmbed(10)
.withMaxNumChunks(5000)
.withKeepSeparator(true)
.build();
return splitter.apply(documents);
}
}自定义编码类型
你可以配置用于令牌化的编码类型。这在处理使用不同令牌化器的模型时非常有用:
java
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withEncodingType(EncodingType.O200K_BASE)
.withChunkSize(1000)
.build();自定义标点符号
你可以自定义用于将文本分割成语义上有意义的块的分割标点符号。这对于国际化特别有用:
java
@Component
class MyInternationalTextSplitter {
public List<Document> splitChineseText(List<Document> documents) {
// 使用中文标点符号
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(800)
.withMinChunkSizeChars(350)
.withPunctuationMarks(List.of('。', '?', '!', ';')) // 中文标点
.build();
return splitter.apply(documents);
}
public List<Document> splitWithCustomMarks(List<Document> documents) {
// 英文和其他标点符号混合
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(800)
.withPunctuationMarks(List.of('.', '?', '!', '\n', ';', ':', '。'))
.build();
return splitter.apply(documents);
}
}配置
使用 TokenTextSplitter.builder() 创建实例。所有构造函数均已弃用,推荐使用构建器。
参数
encodingType:要使用的令牌化器编码类型(默认为CL100K_BASE)。支持的值包括CL100K_BASE、P50K_BASE和O200K_BASE。chunkSize:每个文本块的目标大小,以令牌数计(默认为 800)。minChunkSizeChars:每个文本块的最小大小,以字符数计(默认为 350)。minChunkLengthToEmbed:要包含的块的最小长度(默认为 5)。maxNumChunks:从文本生成的最大块数(默认为 10000)。keepSeparator:是否在块中保留分隔符(如换行符)(默认为true)。punctuationMarks:用作句子边界以进行分割的字符列表(默认为.、?、!、\n)。
行为
TokenTextSplitter 处理文本内容如下:
- 使用
CL100K_BASE编码将输入文本编码为令牌。 - 根据
chunkSize将编码后的文本分割成块。 - 对于每个块:
- 将块解码回文本。
- 仅当总令牌数超过
chunkSize时,它才会尝试在minChunkSizeChars之后找到一个合适的分割点(使用配置的punctuationMarks)。 - 如果找到分割点,则在该点截断块。
- 修剪块,并根据
keepSeparator设置可选地移除换行符。 - 如果结果块的长度大于
minChunkLengthToEmbed,则将其添加到输出中。
- 此过程持续进行,直到所有令牌都被处理或达到
maxNumChunks。 - 如果剩余文本的长度大于
minChunkLengthToEmbed,则将其作为最后一个块添加。
注意 :基于标点的分割仅当令牌数超过
chunkSize时才适用。完全匹配或小于chunkSize的文本将作为单个块返回,不会进行基于标点的截断。这可以防止对小文本进行不必要的分割。
示例
java
Document doc1 = new Document("这是一段需要分割成更小块进行处理的长文本。",
Map.of("source", "example.txt"));
Document doc2 = new Document("另一份文档,其内容将根据令牌数进行分割。",
Map.of("source", "example2.txt"));
TokenTextSplitter splitter = TokenTextSplitter.builder().build();
List<Document> splitDocuments = splitter.apply(List.of(doc1, doc2));
for (Document doc : splitDocuments) {
System.out.println("块: " + doc.getContent());
System.out.println("元数据: " + doc.getMetadata());
}注意事项
TokenTextSplitter使用来自jtokkit库的CL100K_BASE编码,该编码与较新的 OpenAI 模型兼容。- 该分割器尝试通过尽可能在句子边界处断开来创建语义上有意义的块。
- 原始文档中的元数据会被保留,并复制到从该文档派生的所有块中。
- 如果
copyContentFormatter设置为true(默认行为),原始文档的内容格式化程序也会被复制到派生的块中。 - 该分割器特别适用于为具有令牌限制的大型语言模型准备文本,确保每个块都在模型的处理能力之内。
- 自定义标点符号 :默认的标点符号(
.、?、!、\n)适用于英文文本。对于其他语言或专门内容,使用构建器的withPunctuationMarks()方法自定义标点符号。 - 性能考虑:虽然分割器可以处理任意数量的标点符号,但建议保持列表相对较小(少于 20 个字符)以获得最佳性能,因为每个块都会检查每个标记。
- 可扩展性 :
getLastPunctuationIndex(String)方法是受保护的,允许子类为专门用例覆盖标点检测逻辑。 - 小文本处理 :从 2.0 版本开始,令牌数小于或等于
chunkSize的小文本不再在标点符号处分割,防止了已经适合大小限制的内容被不必要的碎片化。
ContentFormatTransformer(内容格式转换器)
确保所有文档中内容格式的统一。
KeywordMetadataEnricher(关键字元数据丰富器)
KeywordMetadataEnricher 是一个 DocumentTransformer,它使用生成式 AI 模型从文档内容中提取关键字,并将其作为元数据添加。
用法
java
@Component
class MyKeywordEnricher {
private final ChatModel chatModel;
MyKeywordEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordCount(5)
.build();
// 或使用自定义模板
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordsTemplate(YOUR_CUSTOM_TEMPLATE)
.build();
return enricher.apply(documents);
}
}构造函数选项
KeywordMetadataEnricher 提供了两个构造函数选项:
KeywordMetadataEnricher(ChatModel chatModel, int keywordCount):使用默认模板并提取指定数量的关键字。KeywordMetadataEnricher(ChatModel chatModel, PromptTemplate keywordsTemplate):使用自定义模板进行关键字提取。
行为
KeywordMetadataEnricher 处理文档如下:
- 对于每个输入文档,它使用文档内容创建一个提示词。
- 它将此提示词发送给提供的
ChatModel以生成关键字。 - 生成的关键字被添加到文档的元数据中,键为
"excerpt_keywords"。 - 返回丰富后的文档。
自定义
你可以使用默认模板,也可以通过 keywordsTemplate 参数自定义模板。默认模板是:
{context_str}. 为此文档提供 %s 个唯一关键字。格式为逗号分隔。关键字:其中 {context_str} 被替换为文档内容,%s 被替换为指定的关键字数量。
示例
java
ChatModel chatModel = // 初始化你的聊天模型
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordCount(5)
.build();
// 或使用自定义模板
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordsTemplate(new PromptTemplate("从以下文本中提取5个重要关键字,并用逗号分隔:\n{context_str}"))
.build();
Document doc = new Document("这是一份关于人工智能及其在现代技术中应用的文档。");
List<Document> enrichedDocs = enricher.apply(List.of(doc));
Document enrichedDoc = enrichedDocs.get(0);
String keywords = (String) enrichedDoc.getMetadata().get("excerpt_keywords");
System.out.println("提取的关键字: " + keywords);注意事项
KeywordMetadataEnricher需要一个正常运行的ChatModel来生成关键字。- 关键字数量必须大于等于 1。
- 该丰富器为每个处理的文档添加
"excerpt_keywords"元数据字段。 - 生成的关键字以逗号分隔的字符串形式返回。
- 该丰富器对于提高文档的可搜索性以及为文档生成标签或分类特别有用。
- 在构建器模式中,如果设置了
keywordsTemplate参数,keywordCount参数将被忽略。
SummaryMetadataEnricher(摘要元数据丰富器)
SummaryMetadataEnricher 是一个 DocumentTransformer,它使用生成式 AI 模型为文档创建摘要并将其作为元数据添加。它可以生成当前文档以及相邻文档(前一个和下一个)的摘要。
用法
java
@Configuration
class EnricherConfig {
@Bean
public SummaryMetadataEnricher summaryMetadata(OpenAiChatModel aiClient) {
return new SummaryMetadataEnricher(aiClient,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
}
}
@Component
class MySummaryEnricher {
private final SummaryMetadataEnricher enricher;
MySummaryEnricher(SummaryMetadataEnricher enricher) {
this.enricher = enricher;
}
List<Document> enrichDocuments(List<Document> documents) {
return this.enricher.apply(documents);
}
}构造函数
SummaryMetadataEnricher 提供了两个构造函数:
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes)SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode)
参数
chatModel:用于生成摘要的 AI 模型。summaryTypes:指示生成哪些摘要的SummaryType枚举值列表(PREVIOUS、CURRENT、NEXT)。summaryTemplate:摘要生成的自定义模板(可选)。metadataMode:指定在生成摘要时如何处理文档元数据(可选)。
行为
SummaryMetadataEnricher 处理文档如下:
- 对于每个输入文档,它使用文档内容和指定的摘要模板创建一个提示词。
- 它将此提示词发送给提供的
ChatModel以生成摘要。 - 根据指定的
summaryTypes,它将以下元数据添加到每个文档中:section_summary:当前文档的摘要。prev_section_summary:前一个文档的摘要(如果可用且被请求)。next_section_summary:后一个文档的摘要(如果可用且被请求)。
- 返回丰富后的文档。
自定义
可以通过提供自定义的 summaryTemplate 来自定义摘要生成的提示词。默认模板是:
"""
这是该部分的内容:
{context_str}
总结该部分的关键主题和实体。
摘要:
"""示例
java
ChatModel chatModel = // 初始化你的聊天模型
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
Document doc1 = new Document("文档1的内容");
Document doc2 = new Document("文档2的内容");
List<Document> enrichedDocs = enricher.apply(List.of(doc1, doc2));
// 检查丰富后的文档的元数据
for (Document doc : enrichedDocs) {
System.out.println("当前摘要: " + doc.getMetadata().get("section_summary"));
System.out.println("前一个摘要: " + doc.getMetadata().get("prev_section_summary"));
System.out.println("下一个摘要: " + doc.getMetadata().get("next_section_summary"));
}提供的示例展示了预期行为:
- 对于包含两个文档的列表,两个文档都获得
section_summary。 - 第一个文档获得
next_section_summary,但没有prev_section_summary。 - 第二个文档获得
prev_section_summary,但没有next_section_summary。 - 第一个文档的
section_summary与第二个文档的prev_section_summary匹配。 - 第一个文档的
next_section_summary与第二个文档的section_summary匹配。
注意事项
SummaryMetadataEnricher需要一个正常运行的ChatModel来生成摘要。- 该丰富器可以处理任意大小的文档列表,正确处理第一个和最后一个文档的边缘情况。
- 该丰富器对于创建上下文感知的摘要特别有用,有助于更好地理解序列中文档之间的关系。
MetadataMode参数允许控制在摘要生成过程中如何整合现有的元数据。
写入器(Writers)
FileDocumentWriter(文件文档写入器)
FileDocumentWriter 是一个 DocumentWriter 实现,将 Document 对象列表的内容写入文件。
用法
java
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}构造函数
FileDocumentWriter 提供了三个构造函数:
FileDocumentWriter(String fileName)FileDocumentWriter(String fileName, boolean withDocumentMarkers)FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append)
参数
fileName:要将文档写入的文件的名称。withDocumentMarkers:是否在输出中包含文档标记(默认为false)。metadataMode:指定要将哪些文档内容写入文件(默认为MetadataMode.NONE)。append:如果为true,数据将被写入文件末尾而不是开头(默认为false)。
行为
FileDocumentWriter 处理文档如下:
- 它为指定的文件名打开一个
FileWriter。 - 对于输入列表中的每个文档:
- 如果
withDocumentMarkers为true,它写入一个包含文档索引和页码的文档标记。 - 根据指定的
metadataMode写入文档的格式化内容。
- 如果
- 所有文档写入完成后关闭文件。
文档标记
当 withDocumentMarkers 设置为 true 时,写入器为每个文档包含以下格式的标记:
### Doc: [index], pages:[start_page_number,end_page_number]元数据处理
写入器使用两个特定的元数据键:
page_number:表示文档的起始页码。end_page_number:表示文档的结束页码。
这些在写入文档标记时使用。
示例
java
List<Document> documents = // 初始化你的文档
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, true);
writer.accept(documents);这将所有文档写入 "output.txt",包括文档标记,使用所有可用的元数据,并追加到文件末尾(如果文件已存在)。
注意事项
- 该写入器使用
FileWriter,因此它使用操作系统的默认字符编码写入文本文件。 - 如果在写入过程中发生错误,会抛出
RuntimeException,原始异常作为其原因。 metadataMode参数允许控制如何将现有元数据合并到写入的内容中。- 该写入器对于调试或创建文档集合的人类可读输出特别有用。
VectorStore(向量存储)
提供与各种向量存储的集成。有关完整列表,请参阅